【古诗生成AI实战】之四——模型包装器与模型的训练
在上一篇博客中,我们已经利用任务加载器task成功地从数据集文件中加载了文本数据,并通过预处理器processor构建了词典和编码器。在这一过程中,我们还完成了词向量的提取。
接下来的步骤涉及到定义模型、加载数据,并开始训练过程。
为了确保项目代码能够快速切换到不同的模型,并且能够有效地支持transformers库中的预训练模型,我们不仅仅是定义模型那么简单。为此,我们采取了进一步的措施:在模型外面再套上一个额外的层,我称之为模型包装器NNModelWrapper。此外,为了提高配置的灵活性和可维护性,我们将所有的配置项(如批量大小、数据集地址、训练周期数、学习率等)抽取出来,统一放置在一个名为WrapperConfig的配置容器中。通过这种方式,我们就可以避免直接在代码中修改配置参数,而是通过更改配置文件来实现,从而使得整个项目更加模块化和易于管理。
本章内容属于模型训练阶段,将分别介绍包装器配置WrapperConfig、模型包装器NNModelWrapper和模型Model。

[1] 包装器配置WrapperConfig
我们把配置全部放在yaml文件里,然后读取里面的配置,赋值给WrapperConfig类。定义如下:
class WrapperConfig(object):"""A configuration for a :class:`NNModelWrapper`."""def __init__(self,tokenizer,max_seq_len: int,vocab_num: int,word2vec_path: str,batch_size: int = 1,epoch_num: int = 1,learning_rate: float = 0.001):self.tokenizer = tokenizerself.max_seq_len = max_seq_lenself.batch_size = batch_sizeself.epoch_num = epoch_numself.learning_rate = learning_rateself.word2vec_path = word2vec_pathself.vocab_num = vocab_num
WrapperConfig 类用于配置神经网络模型包装器(NNModelWrapper)。类的构造函数接受多个参数来初始化配置:
tokenizer: 分词器对象,用于文本处理或文本转换为模型可理解的格式。其实就是预处理器processor提供的tokenizer。
max_seq_len (int): 模型可以处理的最大序列长度。
vocab_num (int): 词汇表的大小。
word2vec_path (str):预训练的词向量模型的文件路径。即上文提取的词向量。
batch_size (int): 每个批次处理的数据样本数量。
epoch_num (int): 训练轮次。
learning_rate (float): 学习率。
[2] 模型包装器NNModelWrapper
模型包装器NNModelWrapper接受2个参数,一个是包装器配置WrapperConfig,另外一个是自定义模型Model。代码如下:
class NNModelWrapper:"""A wrapper around a Transformer-based language model."""def __init__(self, config: WrapperConfig, model):"""Create a new wrapper from the given config."""self.config = configself.model = model(self.config)def generate_dataset(self, data, labeled=True):"""Generate a dataset from the given examples."""features = self._convert_examples_to_features(data)feature_dict = {'input_ids': torch.tensor([f.input_ids for f in features], dtype=torch.long),'labels': torch.tensor([f.labels for f in features], dtype=torch.long),}if not labeled:del feature_dict['labels']return DictDataset(**feature_dict)def _convert_examples_to_features(self, examples) -> List[InputFeatures]:"""Convert a set of examples into a list of input features."""features = []for (ex_index, example) in tqdm(enumerate(examples)):if ex_index % 5000 == 0:logging.info("Writing example {}".format(ex_index))input_features = self.get_input_features(example)features.append(input_features)# logging.info(f"最终数据构造形式:{features[0]}")return featuresdef get_input_features(self, example) -> InputFeatures:"""Convert the given example into a set of input features"""text = example.textinput_ids = self.config.tokenizer(text)labels = np.copy(input_ids)labels[:-1] = input_ids[1:]assert len(input_ids) == self.config.max_seq_lenreturn InputFeatures(input_ids=input_ids, attention_mask=None, token_type_ids=None, labels=labels)
NNModelWrapper 类是围绕一个神经网络语言模型的封装器,提供了模型的初始化和数据处理的方法。
· 类初始化 (init):
config: 接收一个 WrapperConfig 类的实例,包含模型的配置信息。
model: 接收一个模型构造函数,该函数使用配置信息来初始化模型。
· 生成数据集 (generate_dataset):从给定的数据样本中生成一个数据集。首先把数据样本转换为特征(通过 _convert_examples_to_features 方法),然后根据这些特征创建一个 DictDataset 对象。如果数据未标记(labeled=False),则从特征字典中删除 labels 键。
· 转换样本为特征 (_convert_examples_to_features):这是个私有方法,把数据样本转换为模型可以理解的输入特征。对于每个样本,使用 get_input_features 方法来生成输入特征。使用 tqdm 显示处理进度,并利用 logging 记录处理信息。
· 获取输入特征 (get_input_features):此方法将单个数据样本转换为输入特征。首先获取文本内容,然后使用配置中的分词器(tokenizer)将文本转换为 input_ids。标签(labels)是 input_ids 的一个变体,其中每个元素都向右移动一个位置。用断言确保 input_ids 的长度与配置中的 max_seq_len 相等。
[3] 模型Model
模型包装器NNModelWrapper里面的第二个参数Model才是我们真正的模型。
在古诗生成AI任务中,RNN是比较适配任务的模型,我们定义的RNN模型如下:
class Model(nn.Module):def __init__(self, config):super(Model, self).__init__()V = config.vocab_num # vocab_numE = 300 # embed_dimH = 256 # hidden_sizeembedding_pretrained = torch.tensor(np.load(config.word2vec_path)["embeddings"].astype('float32'))self.embedding = nn.Embedding.from_pretrained(embedding_pretrained, freeze=False)self.lstm = nn.LSTM(E, H, 1, bidirectional=False, batch_first=True, dropout=0.1)self.fc = nn.Linear(H, V)self.loss = nn.CrossEntropyLoss()def forward(self, input_ids, labels=None):embed = self.embedding(input_ids) # [batch_size, seq_len, embed_dim]out, _ = self.lstm(embed) # [batch_size, seq_len, hidden_size]logit = self.fc(out) # [batch_size, seq_len, vocab_num]if labels is not None:loss = self.loss(logit.view(-1, logit.shape[-1]), labels.view(-1))return loss, logitelse:return logit[None, :]
在我们的模型中,特别值得一提的是嵌入层(embedding layer)。在初始化这一层时,我们使用的是之前提取出的词向量。这种做法有助于模型更好地理解和处理文本数据。
此次我们定义的模型是一个基于RNN的结构,它包括三个主要部分:embedding层、lstm层和fc(全连接)层。
在模型的前向传播(forward)过程中,输入input_ids的形状为[batch_size, seq_len],即每个批次有多少文本,每个文本的序列长度是多少。输入数据首先通过嵌入层处理,输出的embed的形状为[batch_size, seq_len, embed_dim],即每个单词都被转换成了对应的嵌入向量。接着,数据通过一个单层的lstm网络,得到输出out,最后经过全连接层fc,得到最终的概率分布logit。
这个概率分布logit的含义是:对于每个批次中的文本,每个文本在序列的每个位置上,都有vocab_num个可能的词可以填入,而logit中存储的正是这些词的概率。为了生成文本,我们提取每个位置上概率最高的词的索引,然后根据这些索引在词典中查找对应的词。这就是我们通过模型运行文本生成得到的结果。
[4] 训练
所有的工作都准备好了,下面我们正式开始模型的训练。
对于神经网络的训练、验证、测试、优化等等操作,我采用了transformers的Trainer极大的简化了项目操作。
第一步,加载yaml配置文件,读取所有配置项:
with open('config.yaml', 'r', encoding='utf-8') as f:conf = yaml.load(f.read(),Loader=yaml.FullLoader)conf_train = conf['train']conf_sys = conf['sys']
第二步,初始化任务加载器,加载数据集:
Task = TASKS[conf_train['task_name']]()data = Task.get_train_examples(conf_train['dataset_url'])index = int(len(data) * conf_train['rate'])train_data, dev_data = data[:index], data[index:]
第三步,初始化数据预处理器,并向外提供tokenizer:
Processor = PROCESSORS[conf_train['task_name']](data, conf_train['max_seq_len'], conf_train['vocab_path'])tokenizer = lambda text: Processor.tokenizer(text)
第四步,初始化模型包装配置:
wrapper_config = WrapperConfig(tokenizer=tokenizer,max_seq_len=conf_train['max_seq_len'],batch_size=conf_train['batch_size'],epoch_num=conf_train['epoch_num'],learning_rate=conf_train['learning_rate'],word2vec_path=conf_train['word2vec_path'],vocab_num=len(Processor.vocab))
第五步,加载模型,初始化模型包装器:
x = import_module(f'main.model.{conf_train["model_name"]}')wrapper = NNModelWrapper(wrapper_config, x.Model)print(f'模型有 {sum(p.numel() for p in wrapper.model.parameters() if p.requires_grad):,} 个训练参数')
第六步,使用模型包装器生成数据集向量:
train_dataset = wrapper.generate_dataset(train_data)val_dataset = wrapper.generate_dataset(dev_data)
第七步,创建训练器:
# 构建trainer
def create_trainer(wrapper, train_dataset, val_dataset):# 模型model = wrapper.modelargs = TrainingArguments('./checkpoints', # 模型保存的输出目录save_strategy=IntervalStrategy.STEPS, # 模型保存策略save_steps=50, # 每n步保存一次模型 1步表示一个batch训练结束evaluation_strategy=IntervalStrategy.STEPS,eval_steps=50,overwrite_output_dir=True, # 设置overwrite_output_dir参数为True,表示覆盖输出目录中已有的模型文件logging_dir='./logs', # 可视化数据文件存储地址log_level="warning",logging_steps=50, # 每n步保存一次评价指标 1步表示一个batch训练结束 | 还控制着控制台的打印频率 每n步打印一下评价指标 | n过大时,只会保存最后一次的评价指标disable_tqdm=True, # 是否不显示数据训练进度条learning_rate=wrapper.config.learning_rate,per_device_train_batch_size=wrapper.config.batch_size,per_device_eval_batch_size=wrapper.config.batch_size,num_train_epochs=wrapper.config.epoch_num,dataloader_num_workers=2, # 数据加载的子进程数weight_decay=0.01,save_total_limit=2,load_best_model_at_end=True)# 早停设置early_stopping = EarlyStoppingCallback(early_stopping_patience=3, # 如果8次验证集性能没有提升,则停止训练early_stopping_threshold=0, # 验证集的性能提高不到0时也停止训练)trainer = Trainer(model,args,train_dataset=train_dataset,eval_dataset=val_dataset,callbacks=[early_stopping], # 添加EarlyStoppingCallback回调函数)return trainertrainer = create_trainer(wrapper, train_dataset, val_dataset)
第八步,开始训练并设置保存模型:
trainer.train()trainer.save_model(conf_train['model_save_dir'] + conf_train['task_name'] + '/' + conf_train['model_name'])
训练的整体代码如下:
# 构建trainer
def create_trainer(wrapper, train_dataset, val_dataset):# 模型model = wrapper.modelargs = TrainingArguments('./checkpoints', # 模型保存的输出目录save_strategy=IntervalStrategy.STEPS, # 模型保存策略save_steps=50, # 每n步保存一次模型 1步表示一个batch训练结束evaluation_strategy=IntervalStrategy.STEPS,eval_steps=50,overwrite_output_dir=True, # 设置overwrite_output_dir参数为True,表示覆盖输出目录中已有的模型文件logging_dir='./logs', # 可视化数据文件存储地址log_level="warning",logging_steps=50, # 每n步保存一次评价指标 1步表示一个batch训练结束 | 还控制着控制台的打印频率 每n步打印一下评价指标 | n过大时,只会保存最后一次的评价指标disable_tqdm=True, # 是否不显示数据训练进度条learning_rate=wrapper.config.learning_rate,per_device_train_batch_size=wrapper.config.batch_size,per_device_eval_batch_size=wrapper.config.batch_size,num_train_epochs=wrapper.config.epoch_num,dataloader_num_workers=2, # 数据加载的子进程数weight_decay=0.01,save_total_limit=2,load_best_model_at_end=True)# 早停设置early_stopping = EarlyStoppingCallback(early_stopping_patience=3, # 如果8次验证集性能没有提升,则停止训练early_stopping_threshold=0, # 验证集的性能提高不到0时也停止训练)trainer = Trainer(model,args,train_dataset=train_dataset,eval_dataset=val_dataset,callbacks=[early_stopping], # 添加EarlyStoppingCallback回调函数)return trainerdef main():# ### @通用配置# ##with open('config.yaml', 'r', encoding='utf-8') as f:conf = yaml.load(f.read(),Loader=yaml.FullLoader)conf_train = conf['train']conf_sys = conf['sys']# 系统设置初始化System(conf_sys).init_system()# 初始化任务加载器Task = TASKS[conf_train['task_name']]()data = Task.get_train_examples(conf_train['dataset_url'])index = int(len(data) * conf_train['rate'])train_data, dev_data = data[:index], data[index:]# 初始化数据预处理器Processor = PROCESSORS[conf_train['task_name']](data, conf_train['max_seq_len'], conf_train['vocab_path'])tokenizer = lambda text: Processor.tokenizer(text)# 初始化模型包装配置wrapper_config = WrapperConfig(tokenizer=tokenizer,max_seq_len=conf_train['max_seq_len'],batch_size=conf_train['batch_size'],epoch_num=conf_train['epoch_num'],learning_rate=conf_train['learning_rate'],word2vec_path=conf_train['word2vec_path'],vocab_num=len(Processor.vocab))x = import_module(f'main.model.{conf_train["model_name"]}')wrapper = NNModelWrapper(wrapper_config, x.Model)print(f'模型有 {sum(p.numel() for p in wrapper.model.parameters() if p.requires_grad):,} 个训练参数')# 生成数据集train_dataset = wrapper.generate_dataset(train_data)val_dataset = wrapper.generate_dataset(dev_data)# 训练与保存trainer = create_trainer(wrapper, train_dataset, val_dataset)trainer.train()trainer.save_model(conf_train['model_save_dir'] + conf_train['task_name'] + '/' + conf_train['model_name'])if __name__ == '__main__':main()
运行之后,看到下面输出代表项目成功运行:
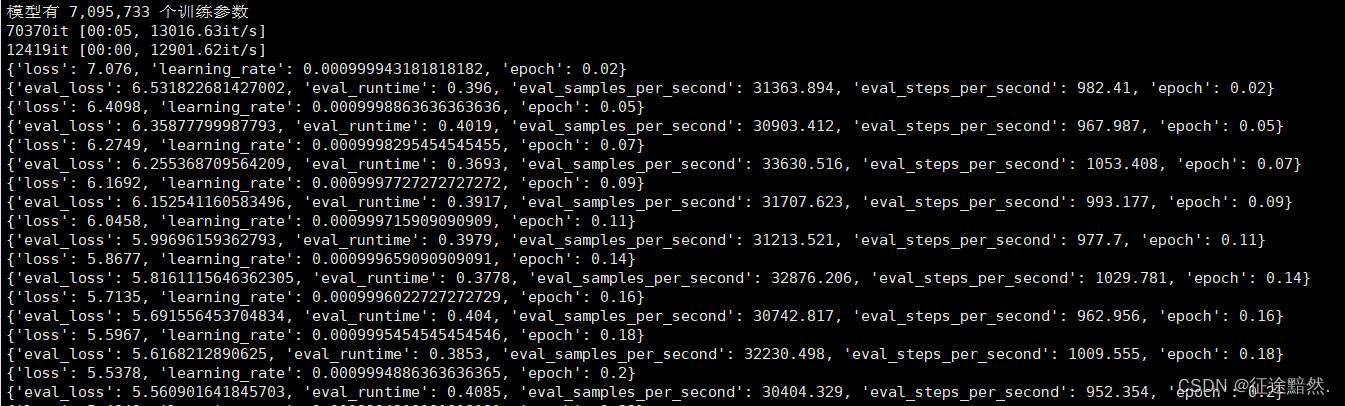
[5] 进行下一篇实战
【古诗生成AI实战】之五——加载模型进行古诗生成
相关文章:
【古诗生成AI实战】之四——模型包装器与模型的训练
在上一篇博客中,我们已经利用任务加载器task成功地从数据集文件中加载了文本数据,并通过预处理器processor构建了词典和编码器。在这一过程中,我们还完成了词向量的提取。 接下来的步骤涉及到定义模型、加载数据,并开始训练过程。…...

redis实现消息延迟队列
业务场景 在很多软件系统功能中都会出现定时任务的业务场景,比如提前点单,比如定时发布动态,文章等而出现这样的的定时的任务为延迟队任务 代码模块 任务的持久化一般都需要建立一个任务表和任务日志表,避免宕机导致任务失效,先新建立一个数据库,创建基本的任务表和任务日志表…...

keyof
// 在TypeScript中,keyof是一个操作符, // 它允许你从一个类型中提取所有的可枚举属性名,并将它们组成一个联合类型。 // 例如,假设你有这样一个类型: type Person { firstName: string; lastName: string; age: n…...

Centos 7 更改 PostgreSQL 14 默认存储路径
前言: 默认PostgreSQL数据存储路径为:/var/lib/pgsql/14/data 迁移到新的存储路径:/mnt/postgresql/data 1、关闭PostgreSQL服务 systemctl stop postgresql-142、创建目录 # 创建新目录 mkdir -p /mnt/postgresql/data# 更改目录权限 chow…...
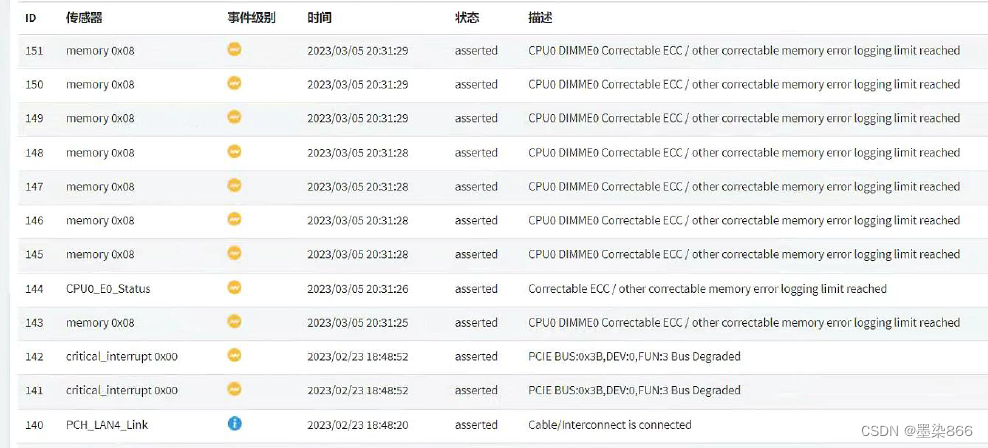
深信服超融合一体机提示:内存ECC
PS:此事件分享主要来源于季度巡检时发现的超融合一体机红灯闪烁异常,接入IPMI端口查看日志发现持续提示内存ECC; 因为是只有3.05这一天发现了有这个告警的提示,所以当时清除了日志以后重启了BMC服务就解决了;但是如果清…...

STK Components 二次开发-地面站传感器
上一篇我们说了创建地面站,那么这次我们在地面站添加一些特效。 1. 创建地面站 var locationPoint1 new PointCartographic(m_earth, new Cartographic(Trig.DegreesToRadians(117.17066), Trig.DegreesToRadians(31.84056), 240.359)); m_facility new Platfor…...
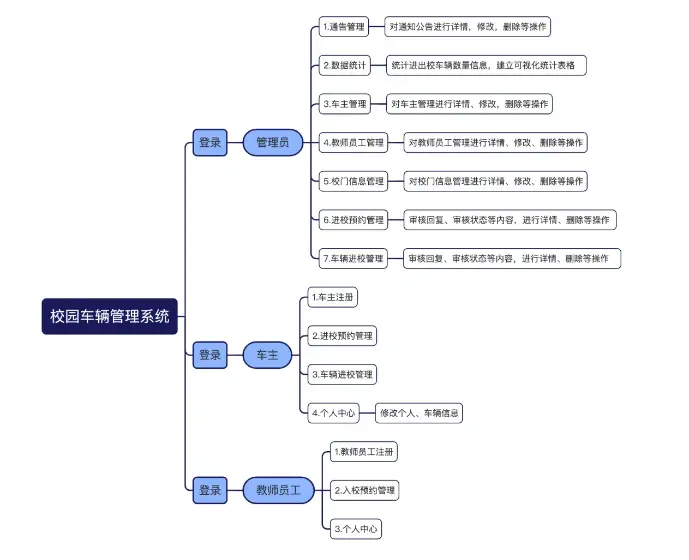
基于springboot校园车辆管理系统
背景 伴随着社会经济的快速发展,机动车保有量不断增加。不断提高的大众生活水平以及人们不断增长的自主出行需求,人们对汽车的 依赖性在不断增强。汽车已经发展成为公众日常出行的一种重要的交通工具。在如此形势下,高校校园内的机动车数量也…...
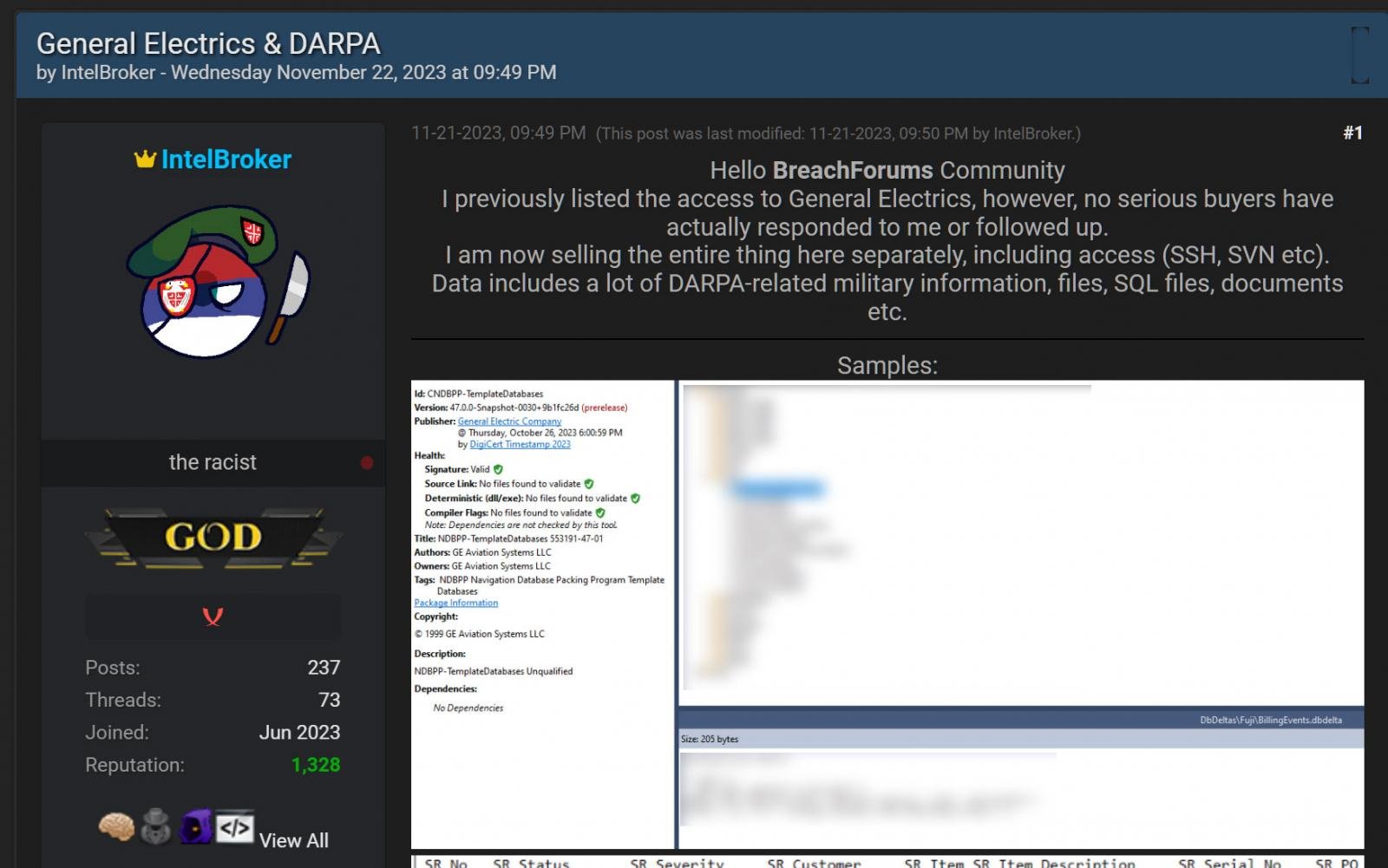
通用电气调查网络攻击和数据盗窃指控
通用电气正在调查有关威胁行为者在网络攻击中破坏了公司开发环境并泄露据称被盗数据的指控。 通用电气 (GE) 是一家美国跨国公司,业务涉及电力、可再生能源和航空航天行业。 本月早些时候,一个名为 IntelBroker 的威胁行为者试图在黑客论坛上以 500 美…...

2023亚太赛数学建模A题:采果机器人的图像识别技术思路模型代码
亚太A题:采果机器人的图像识别技术 A题完整思路获取 :获取见文末名片,第一时间更新 中国是世界上最大的苹果生产国,年产量约为3500万吨。与此同时,中国也是世 界上最大的苹果出口国,全球每两个苹果中就有…...

C++ 协程
经典协程辅助入门代码: typedef cotask::task my_task_t; int main() { // create a task using factory function [with lambda expression] my_task_t::ptr_t task my_task_t::create([]() { //创建协程 std::cout ()->get_id() cotask::this_task::get…...
EventBus的使用)
Flutter学习(六)EventBus的使用
背景 项目开发过程中,有些场景,需要跨页面进行数据传递。按照安卓开发的思路,在flutter实现一个事件总线EventBus,进行数据传递 原理 通过dart的签名函数,进行监听集合设置,然后post分发的时候ÿ…...

Linux系统---僵尸进程、孤儿进程
顾得泉:个人主页 个人专栏:《Linux操作系统》 《C/C》 键盘敲烂,年薪百万! 有了上一篇博客的学习,我们已经简单了解了进程的基础知识,今天我们再来学习两个特殊的进程,僵尸进程和孤儿进程。 …...

SpringBoot中如何优雅地使用重试
1 缘起 项目中使用了第三方的服务, 第三方服务偶尔会出现不稳定、连接不上的情况, 于是,在调用时为了保证服务的相对高可用,添加了超时连接重试, 当连接第三方服务超时时,多重试几次,比如3次&a…...

数据库日志解析:深入了解MySQL中的各类日志
**> 🎏:你只管努力,剩下的交给时间 🏠 :小破站 数据库日志解析:深入了解MySQL中的各类日志 前言第一:错误日志❌1. 错误日志的作用2. 记录内容3. 故障排查的方法 第二:查询日志1.…...

操作系统题目分类总结 | 进程管理 内存管理 文件系统 设备管理
系列文章如下 学习过程中一定要有系统观念(知识框架,每一章开头都会有一个思维导图),知道目前自己在学习的是哪一板块的内容,和前面有什么样的联系 操作系统的很多知识点前后都是联系非常紧密的,去一点一…...
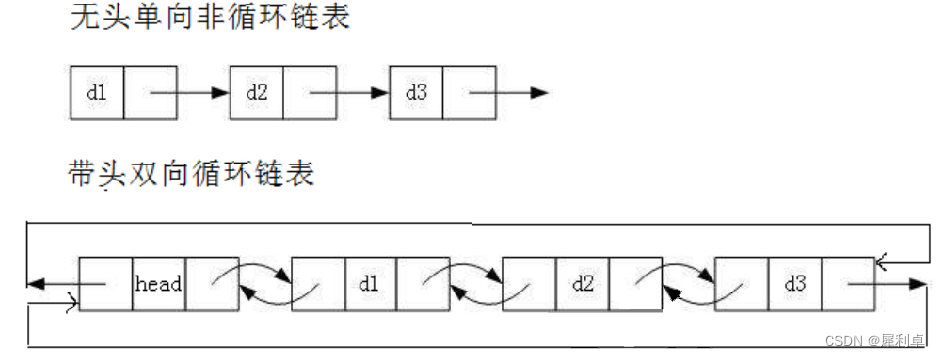
数据结构——单链表(Singly Linked List)
1.链表介绍 链表是一种物理储存上非连续、非顺序的存储结构。数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。 对于上图,每一个结点都是一个结…...

4面试题--数据库(补充)
隔离性问题 若不考虑隔离性则会出现以下问题 1. 脏读:指⼀个事务在处理数据的过程中,读取到另⼀个 未提交 事务的数据 2. 不可重复读:指对于数据库中的某个数据(同⼀个数据项),⼀个事务内的多次查询却…...
人力资源管理后台 === 左树右表
1.角色管理-编辑角色-进入行内编辑 获取数据之后针对每个数据定义标识-使用$set-代码位置(src/views/role/index.vue) // 针对每一行数据添加一个编辑标记this.list.forEach(item > {// item.isEdit false // 添加一个属性 初始值为false// 数据响应式的问题 数据变化 视图…...
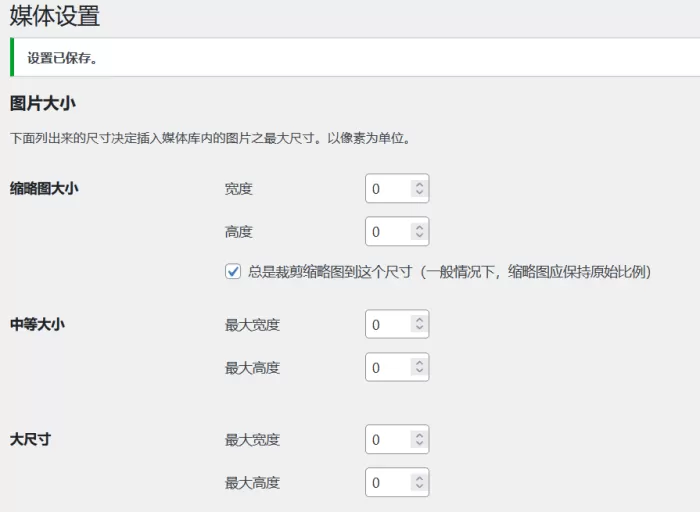
WordPress无需插件禁用WP生成1536×1536和2048×2048尺寸图片
我们在使用WordPress上传图片媒体文件的时候,是不是看到媒体库中有15361536和20482048的图片文件,当然这么大的文件会占用我们的服务器空间,如何禁止掉呢? function remove_default_image_sizes( $sizes) {unset( $sizes[1536x15…...
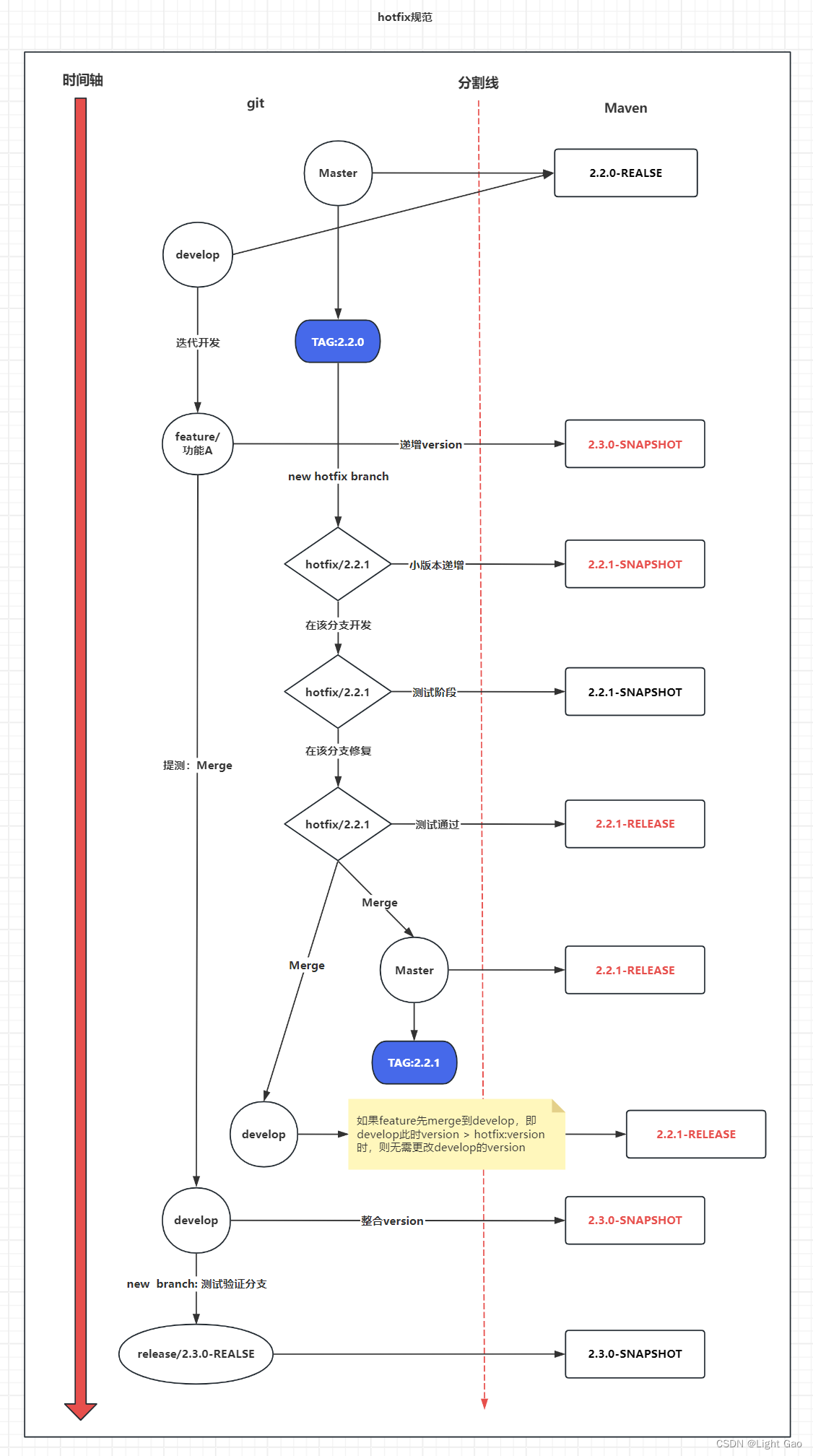
Git 与 Maven:企业级版本管理与版本控制规范设计
一、背景 当今,许多开发人员熟悉 GitFlow 工作流程,但往往忽略了 GitFlow 如何与 Maven 版本控制结合,尤其是在管理 snapshot 和 release 版本时的最佳实践。本文旨在整合 GitFlow 工作流程与 Maven 版本管理,提出一个统一的企业…...

线性规划实战指南:从基础理论到优化应用
1. 线性规划基础:从菜市场砍价到数学建模 第一次听说线性规划时,我正蹲在菜市场跟大妈讨价还价。大妈说:"西红柿3块一斤,买5斤送半斤",我脑子里瞬间闪过一道光——这不就是典型的线性约束条件吗?…...

TMSpeech:Windows平台离线语音转文字的终极解决方案
TMSpeech:Windows平台离线语音转文字的终极解决方案 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 还在为会议记录而手忙脚乱吗?还在为在线课程笔记而烦恼吗?今天我要向你介绍一…...

第X篇:COZE实战指南 【基于COZE工作流打造智能视频素材提取引擎】全流程解析
1. 为什么需要智能视频素材提取引擎 最近两年短视频内容爆发式增长,我身边很多做自媒体的朋友每天都要花大量时间处理视频素材。有个做科普视频的团队告诉我,他们剪辑一个5分钟的视频,光是找素材、截取片段就要耗费大半天。这种重复性工作不仅…...
)
别再写CompletableFuture了!Loom时代响应式编程新范式:结构化并发+协程式错误传播(附可运行Demo仓库)
第一章:Loom时代响应式编程的范式跃迁Project Loom 的正式落地标志着 JVM 并发模型的根本性重构——虚拟线程(Virtual Threads)将轻量级协程原生引入 Java 生态。这一变革不再仅是“提升吞吐量”的工程优化,而是直接重塑响应式编程…...

claw-code 源码分析:结构化输出与重试——`structured_output` 一类开关如何改变「可解析性」与失败语义?
涉及源码:src/query_engine.py、src/runtime.py、src/main.py;Rust rust/crates/tools/src/lib.rs(StructuredOutput 工具);对照 rust/crates/claw-cli/src/app.rs(OutputFormat,与 Python 开关…...

PMSM滑模控制仿真优化:无位置传感器永磁电机文档分享,包括界面调整、波形记录与程序内部原理解析
PMSM滑模控制仿真无位置 永磁电机 可提供文档if启动 如果没有收敛,将1e-4搞小一点 e-6或者e-5试下 本次滑模模型文档包括: 1 simulink界面调整,由于使用这个仿真的时候很可能会出现因为软件环境不同导致无法使用, 或者导致的波形错…...

深入Verilog-axi源码:手把手教你读懂开源AXI4-Lite Crossbar的仲裁与路由逻辑
深入Verilog-axi源码:手把手教你读懂开源AXI4-Lite Crossbar的仲裁与路由逻辑 在数字IC设计领域,AXI总线协议已成为SoC内部模块通信的黄金标准。而作为AXI协议的精简版本,AXI4-Lite凭借其轻量级特性,在寄存器配置、低速外设控制等…...

GLM-4.1V-9B-Base辅助电路设计:解读Multisim仿真图并生成设计报告
GLM-4.1V-9B-Base辅助电路设计:解读Multisim仿真图并生成设计报告 1. 电子工程师的新助手 作为一名电子工程师,你是否经常遇到这样的场景:完成电路仿真后,需要花费大量时间整理设计文档?或者评审会议上,面…...

互动小游戏一般多少天能上线?附详细流程 + 案例 + 避坑
本文由长沙圣捷信息技术有限公司(简称:圣捷游戏)整理,以下统称圣捷游戏。🔥 用户核心疑问:互动小游戏多久上线?费用与流程怎么定?当下互动小游戏成品牌引流、活动运营、私域增长的标…...

【信奥业余科普】02:给机器注入灵魂的两位天才——图灵与冯·诺依曼
第二篇信奥基础知识科普:了解“计算机科学之父”图灵与“现代计算机之父”冯诺依曼的伟大构想,以及现代计算机体系结构的基础奠定。 计算机硬件 写在前面的话:这是一系列专为对信奥(信息学奥赛)感兴趣的中小学生及家…...