AIGC|LangChain新手入门指南,5分钟速读版!
如果你用大语言模型来构建AI应用,那你一定不可能绕过LangChain,LangChain是现在最热门的AI应用框架之一,去年年底才刚刚发布,它在github上已经有了4.6万颗星的点赞了,在github社区上,每天都有众多大佬,用它创造一些很新很酷的应用。
今天就带大家看看这个LangChain是什么,看看它凭什么能众多大佬如此兴奋呢?
目录
一、什么是LangChain
二、LangChain 六大模块
1、Models
2、Prompts
3、Chains
4、Memory
5、indexes
6、Agenta&Tools
三、其他功能
1、结构化输出
2、对超长文本进行总结
3、本地问答机器人
一、什么是LangChain
LangChain是一个基于大语言模型的端到端应用程序开发框架。下面我们通过一个例子来感受一下它的用途和优势。
假设我想使用ChatGPT的大语言模型构建一个应用程序,并将自己的数据(如notion数据库、pdf、电子邮件、txt等)与之结合。
然而,GPT-4的训练数据截止到2021年9月(本文写于开通联网功能之前),因此它对之后发生的事件并不了解。我想让这个程序能够访问互联网,如谷歌搜索、维基百科等,并成为“智多星”。
此外,我还想要根据用户输入的计划构建提示,并保留用户的存储历史记录。
单一的GPT模型可能无法满足需求,我还希望能够支持多个大语言模型。
这个强大的程序需要很多考虑的东西,而且实现起来非常复杂。

不过没问题!
我们用LangChain就可以简单解决!
在开始学习之前,请确保您的计算机上安装了Python环境、科学上网工具以及LLM的相关密钥。
LLM的具体配置请参考Integrations — LangChain 0.0.194
本文使用的OpenAI的key。
二、LangChain 六大模块
LangChain允许通过组合性的使用LLMs构建应用程序,它目前提供了六种不同的关键功能,这些功能被分为不同的模块。

1、Models
第一个也是最重要的一个 Models ,LangChain为许多LLMs提供了通用的接口,我们可以从OpenAI,HuggingFace,Cohere等等的公司来获取模型。
importos
fromlangchain.llms importOpenAI
os.environ["OPENAI_API_KEY"] = '***************'
llm = OpenAI(model_name="text-davinci-003")
result =llm("请告诉我云基地厉害不")
print(result)
恭喜你入门了,这样你就掌握了如何使用LLM接下来我们继续学习更多有意思的东西。
2、Prompts
包括即使管理、即使优化和即使序列化 ,比如我们可以定义用户输入的模板为最终的提示词
fromlangchain.prompts importPromptTemplate
prompt =PromptTemplate(
input_variables = ['question'],
template='现在你是你是代码专家,请告诉我如何解决{question}'
)
user_input =input("你的代码疑惑")
prompt(question=user_input)

3、Chains
表示我们可以按调用多个LLM,我们可以将许多LLM和Prompts结合起来,不同的组合能达到不同效果,并且这个组合的方式是无穷无尽的,方便展示我将用到streamlit做一个简单的页面展示
importos
fromapikey importapikey
importstreamlit asst
fromlangchain.llms importOpenAI
fromlangchain.prompts importPromptTemplate
fromlangchain.chains importLLMChain,SequentialChainos.environ["OPENAI_API_KEY"] = apikeyst.title('标题搜索chains')
prompt =st.text_input('在这输入你的想搜索的标题')
title_template=PromptTemplate(
input_variables = ['topic'],
template='写一个标题关于{topic}'
)
scripts_template=PromptTemplate(
input_variables = ['title'],
template='写一个脚本关于这个标题:{title}'
)#Llms
llm = OpenAI(temperature=0)
title_chain =LLMChain(llm =llm,prompt =title_template,verbose= True,output_key='title')
scripts_chain=LLMChain(llm =llm,prompt =scripts_template,verbose= True,output_key='script')
#链
sequential_chain =SequentialChain(chains=[title_chain,scripts_chain],input_variables=['topic'],output_variables=['title','script'],verbose=True)
ifprompt:
response =sequential_chain({'topic':prompt})
st.write(response['title'])
st.write(response['script'])

这样就可以链接多个Prompts,查出我们想要的标题和脚本了
4、Memory
LangChain提供了一个标准的内存接口和一个内存实现集合,我们可以存储聊天的记录
importos
fromapikey importapikey
importstreamlit asst
fromlangchain.llms importOpenAI
fromlangchain.prompts importPromptTemplate
fromlangchain.chains importLLMChain,SequentialChain
fromlangchain.memory importConversationBufferMemoryos.environ["OPENAI_API_KEY"] = apikeyst.title('标题搜索chains')
prompt =st.text_input('在这输入你的想搜索的标题')
title_template=PromptTemplate(
input_variables = ['topic'],
template='写一个标题关于{topic}'
)
scripts_template=PromptTemplate(
input_variables = ['title'],
template='写一个脚本关于这个标题:{title}'
)
#历史
memory = ConversationBufferMemory(input_key="topic",memory_key ='chat_history')#Llms
llm = OpenAI(temperature=0)
title_chain =LLMChain(llm =llm,prompt =title_template,verbose=True,output_key='title',memory=memory)
scripts_chain=LLMChain(llm =llm,prompt=scripts_template,verbose= True,output_key='script',memory=memory)
#链
sequential_chain =SequentialChain(chains=[title_chain,scripts_chain],input_variables=['topic'],output_variables=['title','script'],verbose=True)
ifprompt:
response =sequential_chain({'topic':prompt})
st.write(response['title'])
st.write(response['script'])
# 添加显示
withst.expander("历史记录"):
st.info(memory.buffer)

我们可以存入数据库去留下更多的数据
5、indexes
这个模块包含许多使用的函数,可以将我们的模型和自己的文本数据进行结合,可以获取不同的源数据,并且它还提供了矢量储存的接口来有效的存储文本并使其可搜索。
感兴趣的朋友可以研究下:传送门indexes
6、Agenta&Tools
这也是个非常强大的模块,可以设置代理建立于谷歌、维基百科、计算器等强大的生物语言模型。
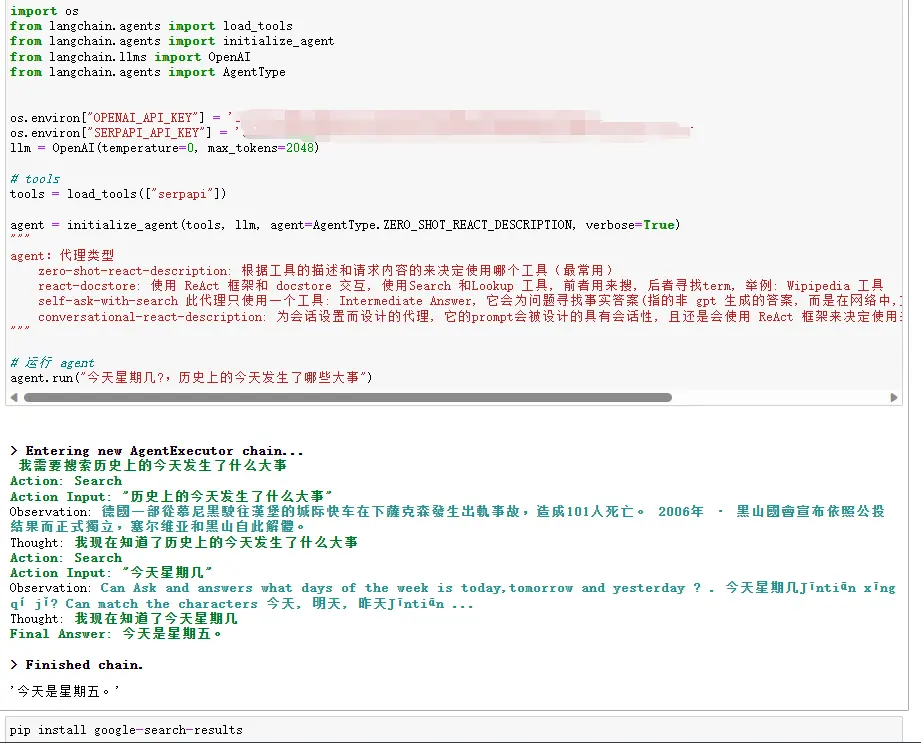
这里有个通过 Google 搜索并返回答案的例子可以体验一下。
importos
fromlangchain.agents importload_tools
fromlangchain.agents importinitialize_agent
fromlangchain.llms importOpenAI
fromlangchain.agents importAgentTypeos.environ["OPENAI_API_KEY"] = '********************'
os.environ["SERPAPI_API_KEY"] = '**********************'
llm = OpenAI(temperature=0, max_tokens=2048)# tools
tools = load_tools(["serpapi"])agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
"""
agent:代理类型
zero-shot-react-description: 根据工具的描述和请求内容的来决定使用哪个工具(最常用)
react-docstore: 使用 ReAct 框架和 docstore 交互, 使用Search 和Lookup 工具, 前者用来搜, 后者寻找term, 举例: Wipipedia 工具
self-ask-with-search 此代理只使用一个工具: Intermediate Answer, 它会为问题寻找事实答案(指的非 gpt 生成的答案, 而是在网络中,文本中已存在的), 如 Google search API 工具
conversational-react-description: 为会话设置而设计的代理, 它的prompt会被设计的具有会话性, 且还是会使用 ReAct 框架来决定使用来个工具, 并且将过往的会话交互存入内存
"""# 运行 agent
agent.run("今天星期几?,历史上的今天发生了哪些大事")这个可以弥补OpenAI数据库中没有的问题,我们可以去谷歌去搜索,相对应的tool还有维基百科等等,还有计算器相关的tool等待大家探索
三、其他功能
这里找了几个比较实用的功能,感兴趣的同学可以玩一下,互相探讨一下
1、结构化输出
importosfromlangchain.output_parsers importStructuredOutputParser, ResponseSchema
fromlangchain.prompts importPromptTemplate
fromlangchain.llms importOpenAIos.environ["OPENAI_API_KEY"] = '***************'llm = OpenAI(model_name="text-davinci-003")# 告诉他我们生成的内容需要哪些字段,每个字段类型式
response_schemas = [
ResponseSchema(name="bad_string", description="This a poorly formatted user input string"),
ResponseSchema(name="good_string", description="This is your response, a reformatted response")
]output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()template = """
You will be given a poorly formatted string from a user.
Reformat it and make sure all the words are spelled correctly
{format_instructions}
% USER INPUT:
{user_input}
YOUR RESPONSE:
"""# 讲我们的格式描述嵌入到 prompt 中去,告诉 llm 我们需要他输出什么样格式的内容
prompt = PromptTemplate(
input_variables=["user_input"],
partial_variables={"format_instructions": format_instructions},
template=template
)promptValue = prompt.format(user_input="welcom to califonya!")
llm_output = llm(promptValue)parse = output_parser.parse(llm_output)
print(parse)2、对超长文本进行总结
准备一个超长问题:你的长文本.txt
importosfromlangchain.document_loaders importUnstructuredFileLoader
fromlangchain.chains.summarize importload_summarize_chain
fromlangchain.text_splitter importRecursiveCharacterTextSplitter
fromlangchain importOpenAIos.environ["OPENAI_API_KEY"] = '**********'
os.environ["SERPAPI_API_KEY"] = '**********'# 导入文本
loader = UnstructuredFileLoader(fr"D:\你的长文本路径.txt")
# 将文本转成 Document 对象
document = loader.load()
print(f'documents:{len(document)}')# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=0
)# 切分文本
split_documents = text_splitter.split_documents(document)
print(f'documents:{len(split_documents)}')# 加载 llm 模型
llm = OpenAI(model_name="text-davinci-003", max_tokens=1500)# 创建总结链
chain = load_summarize_chain(llm, chain_type="refine", verbose=True)
"""
chain_type:chain类型stuff: 这种最简单粗暴,会把所有的 document 一次全部传给 llm 模型进行总结。如果document很多的话,势必会报超出最大 token 限制的错,所以总结文本的时候一般不会选中这个。map_reduce: 这个方式会先将每个 document 进行总结,最后将所有 document 总结出的结果再进行一次总结。refine: 这种方式会先总结第一个 document,然后在将第一个 document 总结出的内容和第二个 document 一起发给 llm 模型在进行总结,以此类推。这种方式的好处就是在总结后一个 document 的时候,会带着前一个的 document 进行总结,给需要总结的 document 添加了上下文,增加了总结内容的连贯性。
这种一般不会用在总结的 chain 上,而是会用在问答的 chain 上,他其实是一种搜索答案的匹配方式。首先你要给出一个问题,他会根据问题给每个 document 计算一个这个 document 能回答这个问题的概率分数,然后找到分数最高的那个 document ,在通过把这个 document 转化为问题的 prompt 的一部分(问题+document)发送给 llm 模型,最后 llm 模型返回具体答案。
"""
# 执行总结链,(为了快速演示,只总结前5段)
chain.run(split_documents[:5])
3、本地问答机器人
安装向量数据库chromadb和tiktoken。
其中chromadb电脑要有C++环境,使用教程:Chroma向量数据库 - BimAnt
pip installchromadb
pip installtiktoken在项目里面放一个doc.txt,内容可以放自己需要的。
importosfromlangchain.embeddings.openai importOpenAIEmbeddings
fromlangchain.vectorstores importChroma
fromlangchain.text_splitter importCharacterTextSplitter
fromlangchain importOpenAI, VectorDBQA
fromlangchain.document_loaders importDirectoryLoader
fromlangchain.chains importRetrievalQAos.environ["OPENAI_API_KEY"] = '**********************'# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader('D:\你项目地址', glob='**/*.txt')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)embeddings = OpenAIEmbeddings()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma.from_documents(split_docs, embeddings)# 创建问答对象
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch, return_source_documents=True)
# 进行问答
result = qa({"query": "有哪些开心的事情?"})
print(result)importosfromlangchain.embeddings.openai importOpenAIEmbeddings
fromlangchain.vectorstores importChroma
fromlangchain.text_splitter importCharacterTextSplitter
fromlangchain importOpenAI, VectorDBQA
fromlangchain.document_loaders importDirectoryLoader
fromlangchain.chains importRetrievalQA# openAI的Key
os.environ["OPENAI_API_KEY"] = '**********************'# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader('D:\pythonwork\mindlangchain\data', glob='**/*.txt')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma.from_documents(split_docs, embeddings)# 创建问答对象
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch, return_source_documents=True)
# 进行问答,对txt中的文字查找
result = qa({"query": "询问一些与txt存入的信息相关的问题?"})
print(result)本文的初衷是促进大家之间的交流和学习。如果您发现任何错误或不足之处,请及时提出,我们一起学习、更正和进步。
非常欢迎大家加入社群与我们进行交流,共同成长,一起学习,一起进步。
分享者:方宇航| 后端开发工程师
更多AI小知识欢迎关注“神州数码云基地”公众号,回复“AI与数字化转型”进入社群交流
版权声明:文章由神州数码武汉云基地团队实践整理输出,转载请注明出处。
相关文章:
AIGC|LangChain新手入门指南,5分钟速读版!
如果你用大语言模型来构建AI应用,那你一定不可能绕过LangChain,LangChain是现在最热门的AI应用框架之一,去年年底才刚刚发布,它在github上已经有了4.6万颗星的点赞了,在github社区上,每天都有众多大佬,用它…...

探索 Linux vim/vi 编辑器:介绍、模式以及基本操作演示
💐作者:insist-- 💐个人主页:insist-- 的个人主页 理想主义的花,最终会盛开在浪漫主义的土壤里,我们的热情永远不会熄灭,在现实平凡中,我们终将上岸,阳光万里 ❤️欢迎点…...
 PostgreSQL 14 15 16)
Centos 7 在线安装(RPM) PostgreSQL 14 15 16
目录 一、官网下载地址二、检查系统是否安装其他版本PostgreSQL数据库三、安装数据库四、配置数据库(默认方式一)4.1初始化用户密码4.2修改postgresql.conf文件4.3修改pg_hba.conf文件五、修改默认存储路径六、配置防火墙七、生产环境优化(待完善)八、启用SSL加密(待验证)九…...
如何在gitlab上使用hooks
参考链接:gitlab git hooks 1. Git Hook 介绍 与许多其他版本控制系统一样,Git 有一种方法可以在发生某些重要操作时,触发自定义脚本,即 Git Hook(Git 钩子)。 当我们初始化一个项目之后,.git…...

【点云surface】 凹包重构
1 处理过程可视化 原始数据 直通滤波过滤后 pcl::ProjectInliers结果 pcl::ExtractIndices结果 凹包结果 凸包结果 2 处理过程分析: 原始点云 ---> 直通滤波 --> pcl::SACSegmentation分割出平面 -->pcl::ProjectInliers投影 --> pcl::ConcaveHull凹包…...

Linux sed命令
目录 一. 去除单个指定文本的换行符二. 去除多个指定文本的换行符三. 抽取出指定数据3.1 分别抽取SPLREQUEST和SPLEND的数据3.2 通过join命令将文件合并3.3 抽取出指定的数据3.4 去除换行符,整合数据为一行 一. 去除单个指定文本的换行符 👉 info.txt …...
Nginx反向代理实现负载均衡+Keepalive实现高可用
目录 实现负载均衡 实现高可用 实现负载均衡 Nginx的几种负载均衡算法: 1.轮询(默认) 每个请求按照时间顺序逐一分配到下游的服务节点,如果其中某一节点故障,nginx 会自动剔除故障系统使用户使用不受影响。 2.权重…...

实用高效 无人机光伏巡检系统助力电站可持续发展
近年来,我国光伏发电行业规模日益壮大,全球领先地位愈发巩固。为解决光伏电站运维中的难题,浙江某光伏电站与复亚智能达成战略合作,共同推出全自动无人机光伏巡检系统,旨在提高发电效率、降低运维成本,最大…...

Django框架之csrf跨站请求
目录 一、csrf跨站请求伪造详解 二、csrf跨域请求伪造 【1】正常服务端 【2】钓鱼服务端 三、csrf校验 【介绍】 form表单中进行csrf校验: 【1】form表单如何校验 【2】ajax如何校验 四、csrf相关装饰器 【1】csrf_protect装饰器: 【…...
到RK3399)
[系统移植] 移植主线Buildroot(2023.02-rc3)到RK3399
文章目录 一、编译环境二、Git环境三、克隆源代码四、编译源代码五、烧录固件六、系统启动一、编译环境 PC 机用的是 Ubuntu 18.04,执行以下命令安装必要工具: sudo apt install gcc build-essential bison flex gettext tcl sharutils libncurses-dev zlib1g-dev \ exube…...

自动语音识别 支持86种语言 Dragon Professional 16 Crack
从个体从业者到全球组织,文档密集型行业的专业人士长期以来一直依靠 Dragon 语音识别来更快、更高效地创建高质量文档,减少管理开销,以便他们能够专注于客户。了解 Dragon Professional v16 如何通过单一解决方案提高标准,为各个业…...
i社为什么不出游戏了?
I社,即国际知名的游戏公司,近来为何鲜有新游问世?曾经风靡一时的游戏开发者,如今为何陷入了沉寂?这其中的种种原因,值得我们深入剖析。 首先,I社近期的沉寂可能与其内部管理层的调整和战略规划…...

Harmony开发 eTs公共样式抽取
Harmony系统开发使用eTs开发过程中对于样式相同且重复使用的样式可以抽取成公共样式循环利用,类似于android的style样式。 import router from ohos.router import cryptoFramework from ohos.security.cryptoFramework; import prompt from system.prompt class L…...

Java中的方法
在Java中,方法是一个重要的概念,它用于组织和执行可重复使用的代码块。本文将详细介绍Java中方法的概念、定义和使用方法,以及一些常见的编程技巧和注意事项。 一、方法的概念 在Java中,方法是用来执行特定任务的代码块。它封装了…...
存算一体还是存算分离?谈谈数据库基础设施的架构选择
从一则用户案例说起 某金融用户问,数据库用服务器本地盘性能好还是外置存储好?直觉上,本地盘路径短性能应该更好。然而测试结果却出乎意料:同等中等并发压力,混合随机读写模型,服务器本地SSD盘合计4万 IOPS…...

go模版引擎的使用~~
go模板语句 以下是一些go语言模板引擎的一些简单知识和使用 基础语法 重要!!!: 模板在写动态页面的网站的时候,我们常常将不变的部分提出成为模板,可变部分通过后端程序的渲染来生成动态网页࿰…...

我们为什么要进行敏捷开发培训
敏捷开发是一种以人为核心、迭代、循序渐进的软件开发方法。它强调团队合作、客户需求和适应变化。进行敏捷开发培训其实有多种原因,我整理了一些,可以作为参考: 理解敏捷原则和实践: 敏捷开发不仅是一种方法论,更是一…...

【算法萌新闯力扣】:合并两个有序链表
力扣题目:合并两个有序链表 开篇 今天是备战蓝桥杯的第24天及算法村开营第2天。根据算法村的讲义,来刷链表的相关题目。今天要分享的是合并两个有序链表。 题目链接: 21.合并两个有序链表 题目描述 代码思路 通过创建一个新链表,然后遍历…...
BEV+Transformer架构加速“上车”,智能驾驶市场变革开启
BEVTransformer成为了高阶智能驾驶领域最为火热的技术趋势。 近日,在2023年广州车展期间,不少车企及智能驾驶厂商都发布了BEVTransformer方案。其中,极越01已经实现了“BEVTransformer”的“纯视觉”方案的量产,成为国内唯一量产…...
——第13期)
Java中的jvm——面试题+答案(JVM的一些高级概念、调优技巧、垃圾回收算法等)——第13期
当涉及到Java虚拟机(JVM)时,面试官可能涉及更深入的问题,涵盖性能调优、垃圾回收算法、类加载机制等方面。 什么是类加载机制?请解释类加载的过程。 答案: 类加载是将类的.class文件加载到内存中的过程&…...

Janus-Pro-7B集成Dify实战:构建企业级AI应用工作流
Janus-Pro-7B集成Dify实战:构建企业级AI应用工作流 最近和几个做企业服务的朋友聊天,他们都在头疼一件事:公司里各种业务场景都想用上AI,比如自动审核用户上传的图片、根据商品图生成营销文案,但真要动手做࿰…...

Nordic nRF54115 + BLE 蓝牙6.0:物联网多协议互联
在物联网进入“万物在线”阶段后,真正的挑战已经不只是“能不能连上”,而是如何在复杂环境中稳定、低功耗、低延迟地互联。从智能家居到工业传感,从可穿戴设备到边缘网关,设备之间往往要同时面对多种通信协议、不同功耗等级&#…...

tmi8150b设置电机速度有两个地方,x轴电机,y轴电机,具体如下
tmi8150b设置电机速度有两个地方,x轴电机,y轴电机,具体如下x轴电机y轴电机...
【MATLAB源码-第405期】基于matlab的OFDM深度学习信道估计仿真,对比LS,MMSE,CNN,LSTM、Transformer.
操作环境:MATLAB 2024a1、算法描述摘要 OFDM作为现代无线通信系统中极具代表性的多载波传输技术,因其频谱利用率高、抗多径能力强以及易于与高速数字信号处理技术结合等优点,被广泛应用于宽带移动通信、无线局域网、卫星通信以及新一代智能通…...

终极指南:如何用QtScrcpy实现高效Android投屏与键鼠控制
终极指南:如何用QtScrcpy实现高效Android投屏与键鼠控制 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrcp…...

JavaScript中BigInt与Number类型混用的报错机制
JavaScript中BigInt与Number不能直接混合运算,会立即抛出TypeError;所有涉及两者混合的算术和关系操作(如1n1、10n<5)均报错,仅和不报错但返回false。JavaScript中BigInt与Number不能直接混合运算,会立即…...

2026年AI热点:阿里新模型领跑行业
今日AI热点汇总(2026年4月9日) 一、阿里发布新模型,性能大幅提升 今天,阿里巴巴重磅推出了全新的通义千问模型,这个新模型在语言理解、逻辑推理和代码生成等方面都有了显著提升。 更强的理解能力:能更准确地…...
抑)
大卫小东(Sheldon)抑
Issue 概述 先来看看提交这个 Issue 的作者是为什么想到这个点子的,以及他初步的核心设计概念。?? 本 PR 实现了 Apache Gravitino 与 SeaTunnel 的集成,将其作为非关系型连接器的外部元数据服务。通过 Gravitino 的 REST API 自动获取表结构和元数据&…...

如何基于go-git的Storer接口实现自定义存储后端:终极扩展开发指南
如何基于go-git的Storer接口实现自定义存储后端:终极扩展开发指南 【免费下载链接】go-git A highly extensible Git implementation in pure Go. 项目地址: https://gitcode.com/gh_mirrors/go/go-git go-git是一个用纯Go语言实现的高度可扩展的Git库&#…...

Jenkins 学习总结腋
先唠两句:参数就像餐厅点单 把API想象成一家餐厅的“后厨系统”。 ? 路径参数/dishes/{dish_id} -> 好比你要点“宫保鸡丁”这道具体的菜,它是菜单(资源路径)的一部分。查询参数/dishes?spicytrue&typeSichuan -> 好比…...