python爬虫进阶篇(异步)
学习完前面的基础知识后,我们会发现这些爬虫的效率实在是太低了。那么我们需要学习一些新的爬虫方式来进行信息的获取。
异步
使用python3.7后的版本中的异步进行爬取,多线程虽然快,但是异步才是爬虫真爱。
基本概念讲解
1.什么是异步?
异步是指在程序执行过程中,当遇到耗时的操作时,不会等待这个操作完成才继续执行后面的代码,而是先去执行其他的操作,等到耗时的操作完成后再处理它的结果。这种方式能够提高程序的并发性和响应性。在传统的同步编程中,当程序执行到一个耗时的操作时(比如文件读写、网络请求等),程序会被阻塞,直到这个操作完成才会继续往下执行。这样会导致程序不能充分利用计算资源,同时也会降低程序的响应速度。而在异步编程中,当遇到耗时操作时,程序会先切换到执行其他任务,等到耗时操作完成后再回来处理结果。这样可以让程序在等待耗时操作的同时继续执行其他任务,提高了程序的并发能力和整体性能。
Python中的异步编程通常使用async/await关键字来定义异步事件,配合asyncio模块和一些第三方库(比如aiohttp、aiofiles等)来实现异步IO操作。异步编程在网络编程、Web开发、爬虫等领域有着广泛的应用。
并发性
并发性是指在同一时间段内,有多个任务在同时执行。在计算机领域,这通常是指多个线程或进程在同时执行,从而提高了程序的效率和性能。在传统的单线程编程中,程序只能按照顺序执行代码,不能同时执行多个任务,这会导致程序效率低下,特别是当遇到大量IO操作时更为明显。
而在多线程或多进程编程中,多个任务可以同时运行,从而可以充分利用计算机的多核处理器和其他硬件资源,提高了程序的效率和性能。同时,多线程/多进程编程也可以使得程序更加稳定,因为如果某个线程/进程崩溃或阻塞,其他线程/进程仍然可以继续执行。
需要注意的是,并发性不同于并行性。并发性是指多个任务在同一时间段内交替执行,而并行性是指多个任务在同一时刻同时执行。并行性需要硬件支持,例如多核处理器、分布式系统等。
I/O操作的概念
I/O操作是指输入/输出操作,是计算机领域中用来描述数据从外部设备(如磁盘、网络、键盘、显示器等)到内存或相反方向的数据传输过程。在计算机程序中,I/O操作通常涉及到读取或写入文件、网络通信、用户输入输出等操作。
常见的I/O操作
- - 从磁盘读取文件到内存
- - 从网络接收数据
- - 向磁盘写入文件
- - 向网络发送数据
- - 从键盘获取用户输入
- - 向屏幕输出数据
异步与多线程的区别
多线程和异步都可以提高程序的并发性和响应性,但在不同的场景下可能会有不同的表现。
多线程适合CPU密集型计算任务,因为它可以充分利用计算机的多核处理器,同时执行多个任务,从而提高程序的效率和性能。但是,在多线程编程中,线程之间需要共享内存,这可能会带来线程安全等问题,需要开发者自己管理线程之间的同步和互斥。
异步适合I/O密集型任务,因为它可以在等待I/O操作的同时,继续执行其他任务,从而充分利用时间片,提高程序的并发性和响应性。异步编程通常使用事件循环机制,在一个线程中执行多个任务,并通过回调函数等方式处理异步事件。但是,在异步编程中,需要使用特定的异步库和语法,如async/await关键字、协程等,对新手来说有一定的学习。
python中的异步
准备工作
导包,准备好工具
异步
pip install asyncio
异步的文件操作
pip install aiofiles
异步的网路请求
pip install aiohttp装好之后我们需要学习一些基本的方法。
学习基本语法
1.asyncio的使用
-
await关键字:await用于暂停当前协程的执行,等待一个异步操作的完成,并获取其结果。- 在使用
await时,必须将其放在一个async修饰的函数内部,以指示该函数是一个协程函数。 await只能在协程函数内部使用,不能在普通函数或全局作用域中使用。
-
async关键字:async用于修饰一个函数,表示该函数是一个协程函数。- 协程函数可以通过
await关键字来暂停执行,并在等待异步操作完成后继续执行。 - 协程函数内部可以包含多个
await语句,用于等待不同的异步操作。
-
asyncio.wait()函数:asyncio.wait()函数用于等待一组协程的完成。- 该函数接受一个可迭代对象(如列表或集合),其中包含要等待的协程对象。
asyncio.wait()函数返回两个集合,分别表示已完成和未完成的任务。
loop.run_until_complete()方法:loop.run_until_complete()方法用于执行一个协程,直到它完成。- 在使用该方法时,必须将协程对象作为参数传递给它。
run_until_complete()方法会阻塞当前线程,直到协程执行完成或发生异常。
loop.create_task()方法:loop.create_task()方法用于创建一个协程任务,并将它加入事件循环中等待执行。- 该方法接受一个协程函数作为参数,并返回一个
Task对象。 Task对象表示一个可调度的协程,可以通过await语句来等待其执行完成。
aiofiles
aiofiles是一个用于在异步代码中进行文件 I/O 操作的库。它提供了异步版本的文件读取和写入操作,与标准库中的open()函数不同,aiofiles中的函数返回awaitable对象,可以在异步函数中使用await关键字来等待文件操作完成。
import asyncio
import aiofilesasync def read_and_print_file():async with aiofiles.open('example.txt', mode='r') as file:content = await file.read()print(content)async def write_to_file():async with aiofiles.open('example.txt', mode='w') as file:await file.write('Hello, aiofiles!')# 在事件循环中执行异步文件读写操作
async def main():await write_to_file()await read_and_print_file()loop = asyncio.get_event_loop()
loop.run_until_complete(main())
记得文件操作属于i/o阻塞
aiohttp
aiohttp是一个用于在异步代码中进行HTTP请求的库。它提供了异步的HTTP客户端和服务器,能够高效地处理大量的并发请求。和request的使用一样
import aiohttp
import asyncioasync def fetch_content(url):async with aiohttp.ClientSession() as session:async with session.get(url) as response:return await response.text()async def main():url = 'https://jsonplaceholder.typicode.com/posts/1'content = await fetch_content(url)print(content)loop = asyncio.get_event_loop()
loop.run_until_complete(main())
实战:只看不练假把式,直接干!基础没啥讲的,爬虫会用就行
这次案例,随意教学了,找一个新的网站实现爬取。中间出现错误的情况我也会直接列出来(我也是菜鸡,只是帮助大家入门的)。给大家分享一下我的思路和解决。
本博客只用于教学爬虫,决定爬取一个:
极简壁纸_海量电脑桌面壁纸美图_4K超高清_最潮壁纸网站
合理使用,这个网站是免费的并且还是免登录(良心网站,请求一两次就行,别一直搞(哭了,现在看我写这句话真是讽刺)),较为容易(容易个der,给我看懵逼了)
兄弟们这个案例当乐子看。
1.准备工作,了解网站结构,查看是否可以直接爬取。
这个主要是看源码中是否和前端调试工具中的结构一样,我们发现,调试工具中有的 是一个a中存在一个链接,但是我们点击打开发现是一个404页面
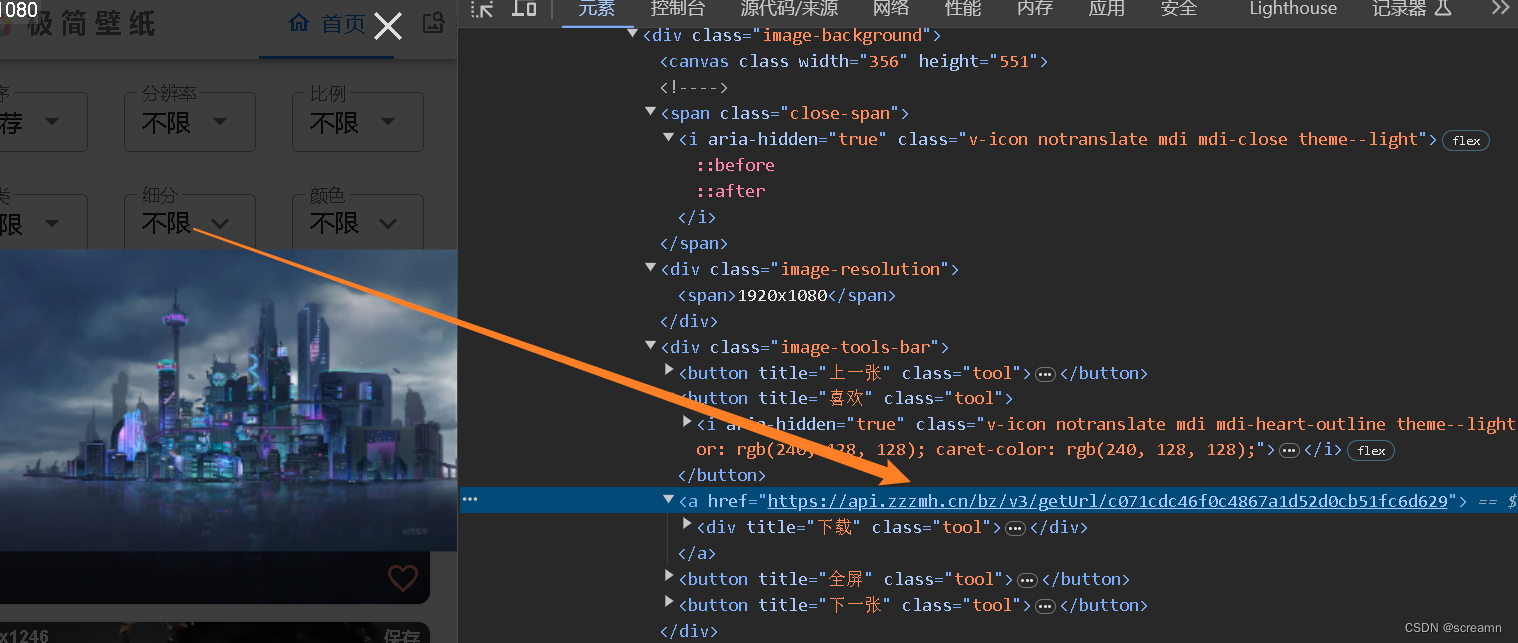

此时我以为这个是无效链接,然后我直接去看了网络请求,发现网络请求是可以获得图片的,但是在找url的关系时,我发现直接请求a中的地址也是可行的。
我们试一下发送请求,看看能不能获取到这张图片。
直接一顿操作
import requestsurl = "https://api.zzzmh.cn/bz/v3/getUrl/c071cdc46f0c4867a1d52d0cb51fc6d629"headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
response = requests.get(url,headers=headers).contentprint(response)我们发现出现了403界面源码,这就有点不对劲了。
那么我们学过的东西无法解决,表明需要学习新的知识了
在网页请求的头部中,包含了一个名为"Referer"的字段,这个字段通常用来标识当前请求是从哪个页面跳转过来的,即上一个网页的地址。这对于网站分析和统计访问来源非常有用,同时也可以在一定程度上用于防盗链和安全验证。在实际开发中,服务器端可以通过检查"Referer"字段来确定请求的来源,并做出相应的处理,例如允许或拒绝特定来源的请求。同时,网站管理员也可以利用这个字段来分析用户的访问行为和流量来源,为网站运营和优化提供参考依据。
搜嘎,现在我们在headers中加入Referer来测试一下

直接出现,现在把他写入文件中试一下,
import requestsurl = "https://api.zzzmh.cn/bz/v3/getUrl/c071cdc46f0c4867a1d52d0cb51fc6d629"headers = {"Referer":"https://bz.zzzmh.cn/","User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
response = requests.get(url,headers=headers).contentwith open("壁纸.jpg",'wb') as file:file.write(response)直接成功:网页请求也是可行的,但是在拼接url的时候还得来到这里。

为什么我们点击页面链接发现时进入一个404呢,我感觉是因为点击后的并没有发送请求,无法访问。
如何批量获取这些数据? 我们复制链接进源码看一下,发现并没有这段链接,那么这个需要找js代码,观察是否需要进行解密。寄了,我看蒙蔽了,大哥这是个人站?这么难吗?给我直接看蒙蔽了,js学是学过,但是那都是基础,后悔了早知道选哪个需要登录的了,不行我都干了四千多字了,怎么说也得爬几个。哥几个别爬了,我找半小时了。太难看了,我纯纯弱智,找这个爬。这反爬比爬网易云免费音乐还难,看这个过过眼瘾。看不懂没关系,我也不会。等我后续把js逆向学明白再带大家做这个。(其实后面介绍的selenium完全可以爬取这些链接,但是缺点就是速度太慢了。)
爬虫案例1:js逆向获取极简壁纸的高清壁纸_爬虫爬取极简壁纸_活火石的博客-CSDN博客
补充,使用自动化工具也可以爬取,就是速度太慢了。(其实也不算很慢,这里就打开的时候比较慢 有2秒等待时间,但是获取图片采用的是异步获取和处理,速度还是很快的。)
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import requestsimport asyncio
import aiofiles
import aiohttpheaders = {'Referer': 'https://bz.zzzmh.cn/',"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
async def download(href,count):print(f"第{count}图片开始缓存")try:async with aiohttp.ClientSession() as session:async with session.get(href,headers=headers) as p:data = await p.read()async with aiofiles.open(f"D:\桌面\pythoncode\爬虫案例\Selenium入门\极简壁纸\{count}.jpg",'wb') as file:await file.write(data)print(f"第{count}图片缓存成功")except:print(f"第{count}图片缓存失败")async def main():web = webdriver.Chrome()web.get("https://bz.zzzmh.cn/index")time.sleep(3)img_List = web.find_elements(by="xpath",value='//div[@class="img-box"]')count = 1task = []for i in img_List:src = i.find_element(by="xpath",value='./span[@class="down-span"]/a')src= src.get_attribute('href')print(src)t = asyncio.create_task(download(src,count))task.append(t)count+=1return await asyncio.wait(task)
if __name__=="__main__":asyncio.run(main()) 案例2
上面那个案例给我整吐了,不行了,换回老朋友笔趣阁。
神秘复苏最新章节_神秘复苏全文在线阅读_佛前献花的小说_笔趣阁
1.查看网页源代码和检查中的链接是否一致
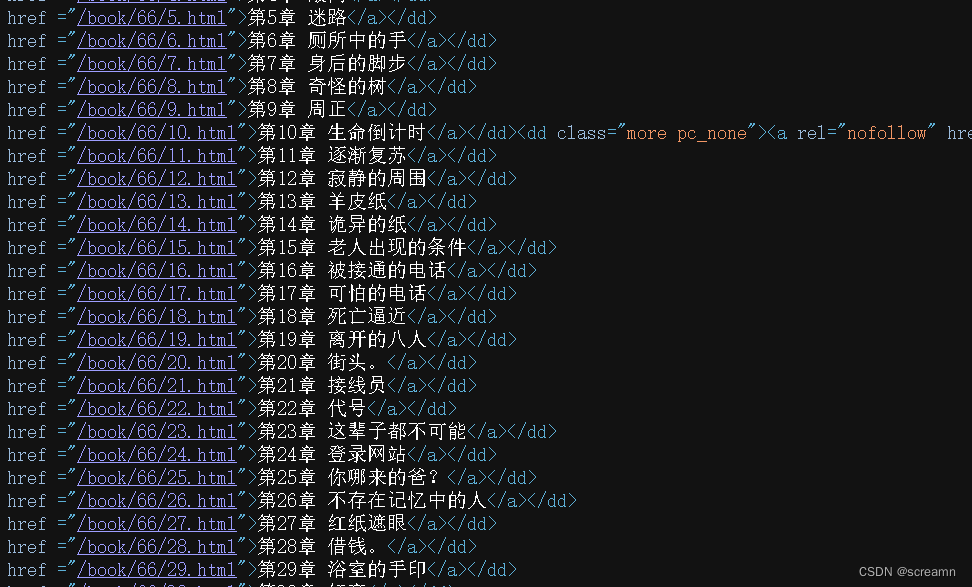
直接爬取每个章节的内容,然后装填进一个数组中,我们爬取这些章节小说可以使用异步来进行。所以现在只需要解析出链接,然后交给异步即可。
注意此时的编码方式
获取请求链接
import requests
import aiofiles
import aiohttp
from lxml import etree
import asyncioasync def main():url = "https://www.bige3.cc/book/66/"headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"}response = requests.get(url)response.encoding = 'utf-8'en = etree.HTML(response.text)title_List = en.xpath("//div[@class='listmain']/dl//dd")print(title_List)
if __name__=="__main__":asyncio.run(main())解析链接和上个一样,区别在于此次获取每个章节的内容采用aiohttp 写入文件使用aiofiles 需要再阻塞前加入等待 await
装填链接
import requests
import aiofiles
import aiohttp
from lxml import etree
import asyncioasync def download(url):passasync def main():url = "https://www.bige3.cc/book/66/"headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"}response = requests.get(url)response.encoding = 'utf-8'en = etree.HTML(response.text)task = []title_List = en.xpath("//div[@class='listmain']/dl//dd")for i in title_List:src = i.xpath("./a/@href")[0]src = "https://www.bige3.cc/" + srct = asyncio.create_task(download(src))task.append(t)return await asyncio.wait(task)
if __name__=="__main__":asyncio.run(main())我们要注意asyncio.wait()这个过程需要等待所以加入了await
下载内容
直接看界面,源码中存在小说内容,所以直接爬取就行。
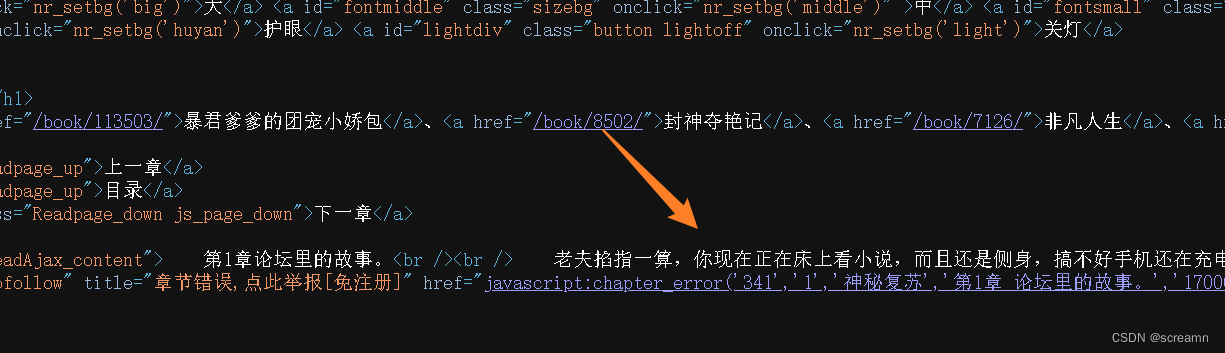
直接爬取:注意i/o阻塞的位置加入await即可,就是和之前的相比加入了一个async而已,没啥区别
import requests
import aiofiles
import aiohttp
from lxml import etree
import asyncioasync def download(url):try:print("小说开始下载")async with aiohttp.ClientSession() as session:async with session.get(url) as r:response = await r.text()en = etree.HTML(response)file_Title = en.xpath('//h1[@class="wap_none"]/text()')[0]file_Content = en.xpath('//*[@id="chaptercontent"]/text()')file_Content = ("".join(file_Content)).replace("\u3000","\n")file_Title = f"D:\桌面\pythoncode\爬虫教学\神秘复苏\{file_Title}.txt"async with aiofiles.open(file_Title,'w',encoding='utf-8') as file:await file.write(file_Content)print("小说下载成功")except:print("下载失败")async def main():url = "https://www.bige3.cc/book/66/"headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"}response = requests.get(url)response.encoding = 'utf-8'en = etree.HTML(response.text)task = []title_List = en.xpath("//div[@class='listmain']/dl//dd")for i in title_List:src = i.xpath("./a/@href")[0]src = "https://www.bige3.cc/" + srct = asyncio.create_task(download(src))task.append(t)return await asyncio.wait(task)
if __name__=="__main__":asyncio.run(main())直接轻轻松松爬取一本小说且顺序是有序的。期待下次更新。
相关文章:
python爬虫进阶篇(异步)
学习完前面的基础知识后,我们会发现这些爬虫的效率实在是太低了。那么我们需要学习一些新的爬虫方式来进行信息的获取。 异步 使用python3.7后的版本中的异步进行爬取,多线程虽然快,但是异步才是爬虫真爱。 基本概念讲解 1.什么是异步&…...

9. Mysql 模糊查询和正则表达式
一、模糊查询 1.1 LIKE运算符 在MySQL中,可以使用LIKE运算符进行模糊查询。LIKE运算符用于匹配字符串模式,其中可以使用通配符来表示任意字符或字符序列。 示例代码 SELECT * FROM table_name WHERE column_name LIKE pattern;table_name:…...

C语言题目强化-DAY14
题型指引 一、选择题二、编程题 ★★写在前面★★ 本题库源自互联网,仅作为个人学习使用,记录C语言题目练习的过程,如果对你也有帮助,那就点个赞吧。 一、选择题 1、有以下函数,该函数的功能是( ÿ…...

TypeScript和JavaScript有什么不同
TypeScript是JavaScript的一个超集,它添加了静态类型检查和其他一些高级特性。下面是TypeScript和JavaScript之间的一些主要区别: 类型系统:TypeScript引入了静态类型检查,可以在开发过程中捕获潜在的类型错误,并提供更…...

mysql使用--存储程序
1.概述 存储程序可以封装一些语句,为用户提供一种简单的方式来调用这个存储程序,从而间接执行其封装的语句。 根据调用方式的不同,可把存储程序分为存储例程、触发器、事件几种类型。其中,存储例程又可被细分为存储函数和存储过程…...
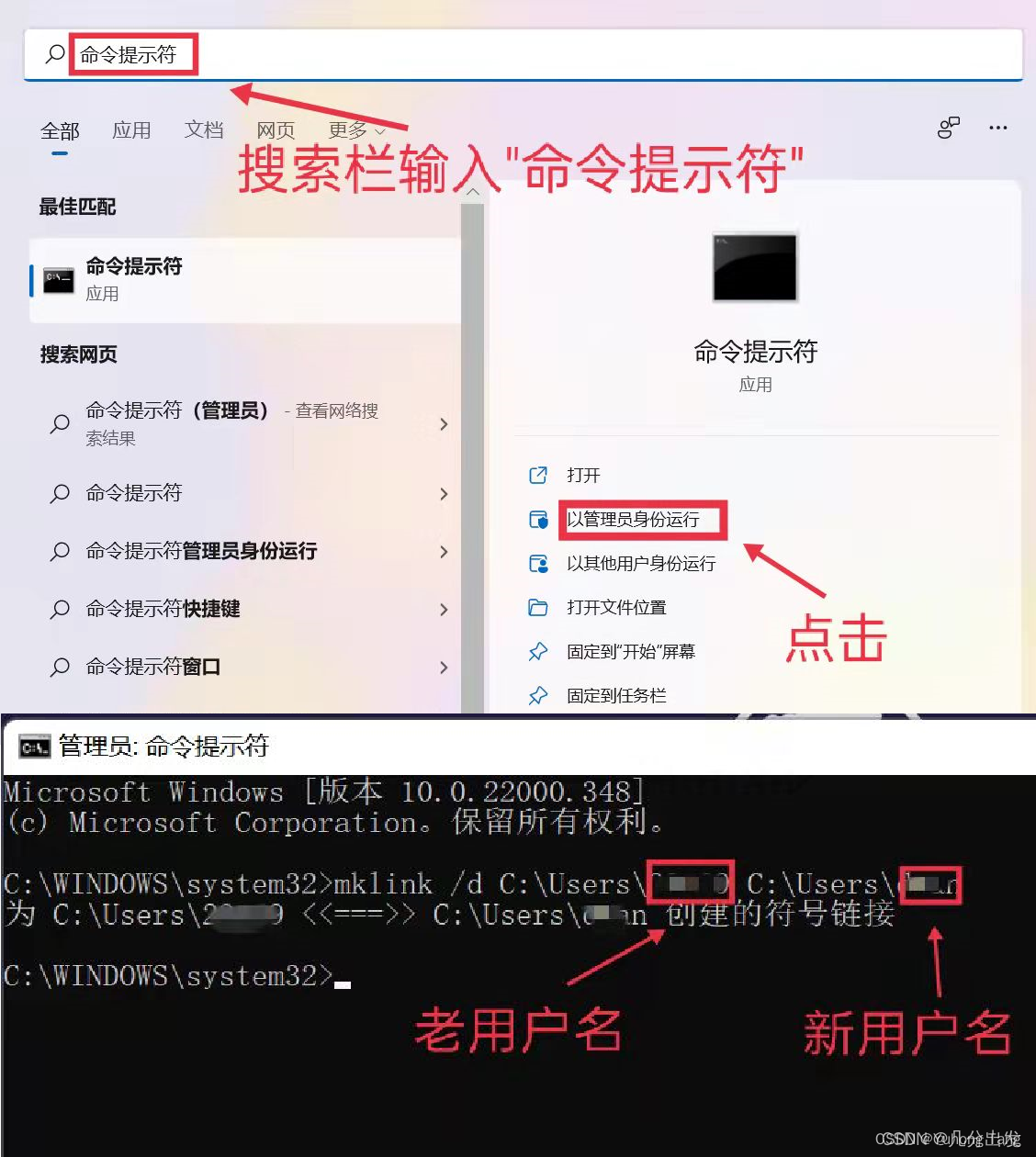
Win11修改用户名(超详细图文)
新买的电脑一般预装Windows11系统(家庭与学生版),新电脑初次开机使用微软邮箱账号登录,则系统将用户名自动设置成邮箱前5位字符。我的用户名便是一串数字【231xx】(qq邮箱前5位),看着很不舒服&a…...

【离散数学】——期末刷题题库(一阶逻辑基本概念)
🎃个人专栏: 🐬 算法设计与分析:算法设计与分析_IT闫的博客-CSDN博客 🐳Java基础:Java基础_IT闫的博客-CSDN博客 🐋c语言:c语言_IT闫的博客-CSDN博客 🐟MySQL:…...
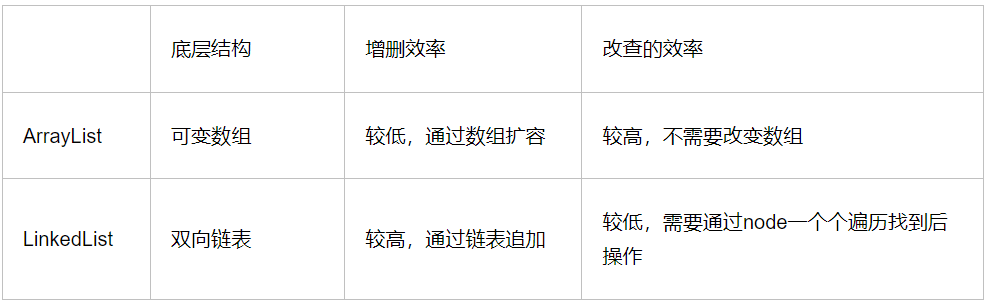
队列实现方式、效率分析及应用场景
文章目录 一、什么是队列二、队列特性阻塞和非阻塞有界和无界单向链表和双向链表 三、Java队列接口继承图四、Java队列常用方法五、队列实现方式与效率分析六、队列的应用场景七、Python中队列与优先级队列使用 一、什么是队列 队列是一种特殊的线性表,遵循先入先出…...
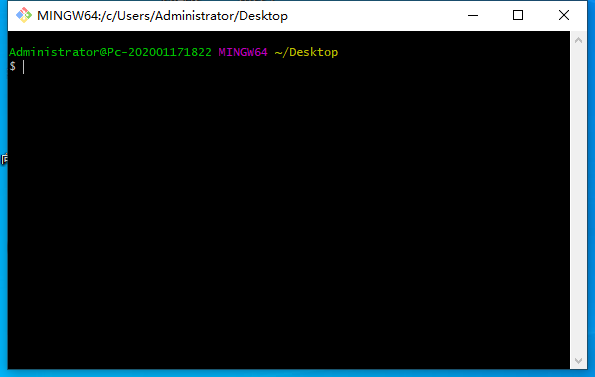
使用git下载远程所有分支到本地
使用git下载远程所有分支到本地: 打开gitbash 输入以下命令即可: git clone git地址 cd git文件夹 git branch -r | grep -v \-> | while read remote; do git branch --track "${remote#origin/}" "$remote"; done git fetch -…...
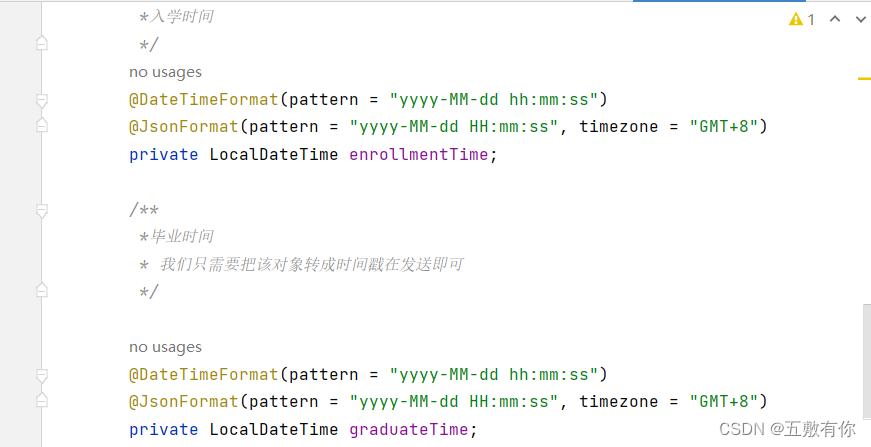
解决LocalDateTime传输前端为时间的数组
问题出现如下: 问题出现原因: 默认序列化情况下会使用SerializationFeature.WRITE_DATES_AS_TIMESTAMPS。使用这个解析时就会打印出数组。 解决方法: 我在全文搜索处理方法总结如下: 1.前端自定义函数来书写 ,cols: [[ //表头{…...
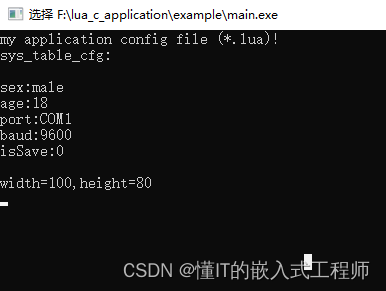
01:编译lua及C调用
我们今天在windows平台编译lua,生成 lua动态库,lua.exe,luac.exe 我把这个目录上传到giee,使用下面命令获取它: git clone gitgitee.com:jameschenbo/lua_c_application.git 目录结构如下: build.cmd 是编译脚本,在…...
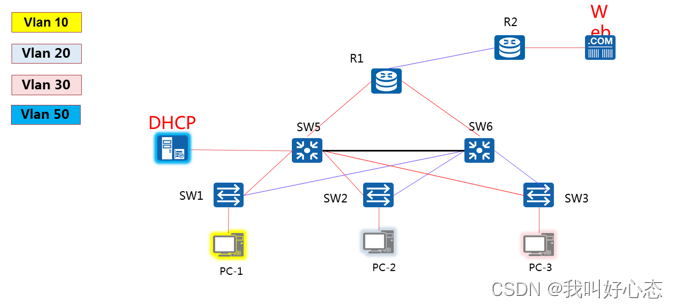
网络运维与网络安全 学习笔记2023.11.24
网络运维与网络安全 学习笔记 第二十五天 今日目标 DHCP中继代理、三层交换机DHCP、子网划分的原理、子网划分的应用 项目需求分析、技术方案选型、网络拓扑绘制 基础交换网络设计、内网优化、连接外网服务器 DHCP中继代理 DHCP中继概述 场景: DHCP客户端与DH…...

常见树种(贵州省):022绣线菊、月月青、金合欢、胡枝子、白刺花
摘要:本专栏树种介绍图片来源于PPBC中国植物图像库(下附网址),本文整理仅做交流学习使用,同时便于查找,如有侵权请联系删除。 图片网址:PPBC中国植物图像库——最大的植物分类图片库 一、绣线菊…...

微星主板开启VT
微星主板模拟器使用 开启VT 进入BIOS高级-》OC-》CPU特征-》intel 虚拟化技术-》允许...
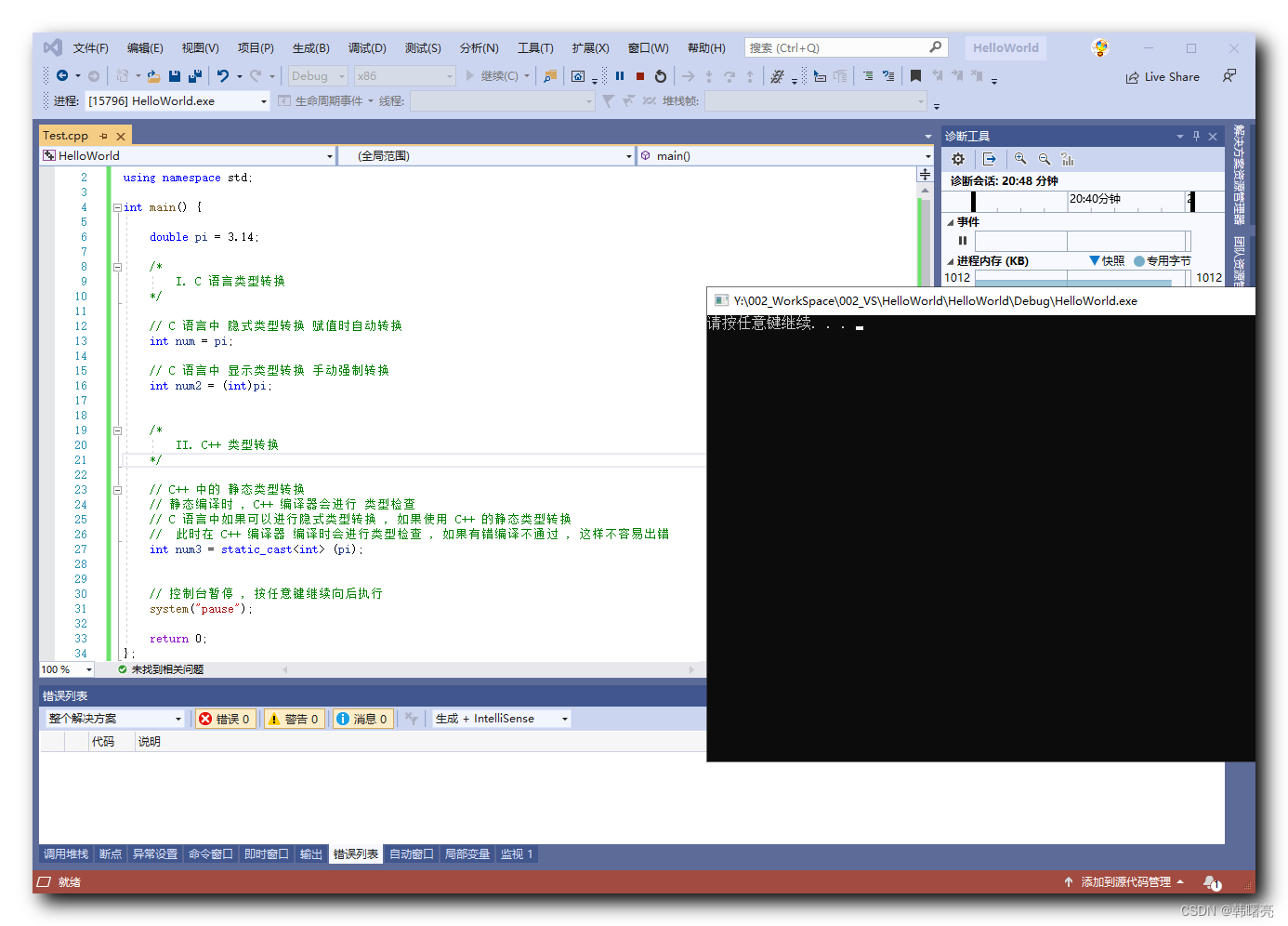
【C++】类型转换 ② ( C++ 静态类型转换 static_cast | C 语言隐式转换弊端 | 代码示例 )
文章目录 一、静态类型转换 static_cast1、C 静态类型转换 static_cast2、C 语言隐式转换弊端3、代码示例 在之前写过一篇 C 类型转换的博客 【C 语言】类型转换 ( 转换操作符 | const_cast | static_cast | dynamic_cast | reinterpret_cast | 字符串转换 ) , 简单介绍了 C 类…...

14.配置Bean有哪几种方式?
配置Bean有哪几种方式? 基于xml: <bean class=“com.tuling.UserService” id=“”>基于注解: @Component(@Controller 、@Service、@Repostory) 前提:需要配置扫描包<component-scan> 反射调用构造方法基于java类配置: @Bean 可以自己控制实例化过程@Import 3种…...

RV1126芯片中的V4L2驱动开发
RV1126芯片概述 RV1126芯片是瑞芯微推出的一款高性能嵌入式人工智能处理器,具有较强的图像处理和音视频处理能力。它采用了双核Cortex-A7架构和一颗DSP核心,支持多种接口和外设,如MIPI CSI、HDMI、USB等,可以广泛应用于物联网、智…...
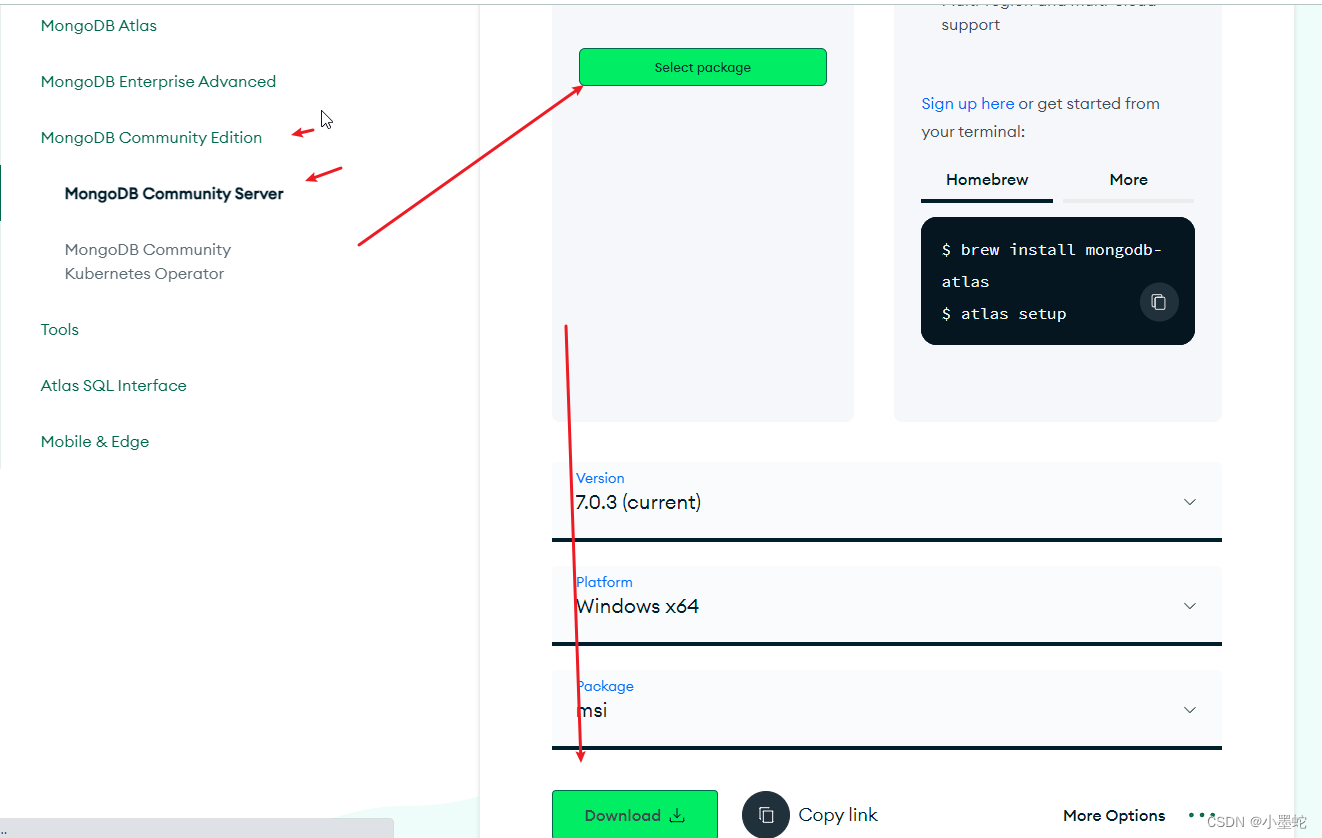
Linux中部署MongoDB
在 是一个必要的过程,因为MongoDB是一种流行的NoSQL数据库,它可以在大多数操作系统上使用。在本文中,我们将介绍如何在CentOS 8上部署MongoDB。 MongoDB的下载 您可以从MongoDB官网上下载最新的MongoDB版本。使用以下命令下载MongoDB&#…...

Halcon 5分钟学会9点标定 带图片示例、示例源码
9点标定应用流程 前置条件,相机焦距,视野固定高度和角度,光源光强度固定。 移动机械手,使用螺丝批头,在视野范围内的白纸上,点九个点,记录每个点位的位置,每个点位的顺序要和图像上获…...

【非监督学习 | 聚类】聚类算法类别大全 距离度量单位大全
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…...

IM010-批量去除图片多余信息-为图片瘦身
批量为图片瘦身,减小图片大小 A文件夹下有P、K、M、H....等文件夹,每个文件夹下都有图片,将程序放在A文件夹下,运行程序后,会自动为每个文件夹下图片进行瘦身减小文件大小。 程序截图 ImageMagick安装方式 先在电脑D盘…...

虚拟线程性能拐点在哪?JVM 25.0.1+GraalVM+Linux eBPF监控实录,8大生产环境反模式曝光,现在不看下周就踩坑!
第一章:虚拟线程性能拐点的理论边界与工程定义虚拟线程(Virtual Thread)作为 JDK 21 引入的轻量级并发抽象,其性能优势并非在所有负载场景下线性增长。当调度密度、I/O 阻塞率与平台线程(Platform Thread)资…...

Papa Parse故障排除:从入门到精通的4个实战方案
Papa Parse故障排除:从入门到精通的4个实战方案 【免费下载链接】PapaParse Fast and powerful CSV (delimited text) parser that gracefully handles large files and malformed input 项目地址: https://gitcode.com/gh_mirrors/pa/PapaParse 在数据处理领…...

如何高效管理全面战争MOD:虎符台/Legion Seal完整指南
如何高效管理全面战争MOD:虎符台/Legion Seal完整指南 【免费下载链接】legion-seal 虎符台/Legion Seal,全面战争游戏MOD管理器,技术栈:Tauri 2 Vue TailwindCSS 项目地址: https://gitcode.com/zeyl/legion-seal 前言&…...

PowerToys屏幕标尺终极指南:免费高效的像素测量工具
PowerToys屏幕标尺终极指南:免费高效的像素测量工具 【免费下载链接】PowerToys Microsoft PowerToys is a collection of utilities that supercharge productivity and customization on Windows 项目地址: https://gitcode.com/GitHub_Trending/po/PowerToys …...

如何快速掌握VDA5050协议:AGV通信标准完整指南与实战应用
如何快速掌握VDA5050协议:AGV通信标准完整指南与实战应用 【免费下载链接】VDA5050 Official Specification document for the VDA 5050 项目地址: https://gitcode.com/gh_mirrors/vd/VDA5050 在智能制造和自动化物流领域,不同品牌AGV设备之间的…...

交叉编译程序,在armv7l架构的开发板上运行
手头有块开发板,需要基于它做二次开发。 开发板是ARM架构的CPU,当前跑的Linux,内核是4.X。 想在安装在virtualbox上的Linux(安装的是kali Linux)上开发程序, 然后交叉编译后上传到开发板上。 一、确定开发板…...

代码随想录算法训练营Day-21 | 669. 修剪二叉搜索树、108.将有序数组转换为二叉搜索树、538.把二叉搜索树转换为累加树
669. 修剪二叉搜索树1.递归函数作用:返回修剪后的二叉树的新的根节点2.终止条件:遇到空节点返回NULL;遇到范围之外的节点执行删除操作:如果该节点值小于最小值,说明右子树有可能还有符合要求的节点,所以返回…...

构建企业级视频监控平台:WVP-GB28181-Pro的3大技术架构突破
构建企业级视频监控平台:WVP-GB28181-Pro的3大技术架构突破 【免费下载链接】wvp-GB28181-pro 基于GB28181-2016、部标808、部标1078标准实现的开箱即用的网络视频平台。自带管理页面,支持NAT穿透,支持海康、大华、宇视等品牌的IPC、NVR接入。…...

ModTheSpire终极指南:如何轻松为杀戮尖塔安装和管理游戏模组
ModTheSpire终极指南:如何轻松为杀戮尖塔安装和管理游戏模组 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire 你是否厌倦了杀戮尖塔的原有内容?想要体验全新角色…...