第二十二章 解读pycocotools的API,目标检测mAP的计算COCO的评价指标(工具)
Pycocotools介绍
为使用户更好地使用 COCO数据集, COCO 提供了各种 API。COCO是一个大型的图像数据集,用于目标检测、分割、人的关键点检测、素材分割和标题生成。这个包提供了Matlab、Python和luaapi,这些api有助于在COCO中加载、解析和可视化注释。
coco api地址: https://github.com/cocodataset/cocoapi
安装pycocotools 两种方式都可以试试
# for linux and windows
pip install pycocotools
# for windows
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
python-pycocotools
核心文件 coco.py cocoeval.py mask.py 这三个文件
coco.py
该文件定义了以下 API:
#这个文件实现了访问 COCO 数据集的接口.可以进行 COCO 标注信息的加载, 解析和可视化操作.
class COCO: # 用于加载 COCO 标注文件并准备所需的数据结构.def createIndex() #创建索引def info() #打印标注文件信息def getAnnIds() #获取满足条件的标注信息ids def Catids() #获取满足条件的类别idsdef getImgids() #获取满足条件的图片的 idsdef loadAnns() #加载指定 ids 对应的标注信息def loadCats() #加载指定 ids 对应的类别def loadImgs() #加载指定 ids 对应的图片def showAnns() #打印制定标注信息def loadRes() #加载算法的结果并创建可用于访问数据的 API def annToMask() #将 segmentation 标注信息转换为二值 maskdef download() #下载图像def loadNumpyAnnotations() #加载numpy格式数据def annToRLE() # polygons格式转换
在给定的 API 中, “ann”=annotation, “cat”=category, and “img”=image
COCO 类的构造函数负责加载 json 文件, 并将其中的标注信息建立关联关系.
关联关系存在于以下两个变量中:
- imgToAnns: 将图片 id 和标注信息 关联;
- catToImgs: 将类别 id 和图片 id 关联.
这样做的好处就是: 对于给定的图片 id, 就可以快速找到其所有的标注信息; 对于给定的类别 id, 就可以快速找到属于该类的所有图片.
class COCO:def __init__(self, annotation_file=None):"""构造函数, 用来读取关联标注信息.:param annotation_file (str): 标注文件路径名:return:"""# 加载数据集# 定义数据成员self.dataset, self.anns, self.cats, self.imgs = dict(),dict(),dict(),dict()self.imgToAnns, self.catToImgs = defaultdict(list), defaultdict(list)# 加载标注信息if not annotation_file == None:print('loading annotations into memory...')tic = time.time()dataset = json.load(open(annotation_file, 'r'))# dataset 的类型为 dictassert type(dataset)==dict, 'annotation file format {} not supported'.format(type(dataset))print('Done (t={:0.2f}s)'.format(time.time()- tic))self.dataset = datasetself.createIndex()def createIndex(self):"""创建索引, 属于构造函数的一部分. """# create indexprint('creating index...')anns, cats, imgs = {}, {}, {}# imgToAnns: 将图片 id 和标注信息 关联; 给定图片 id, 就可以找到其所有的标注信息# catToImgs: 将类别 id 和图片 id 关联; 给定类别 id, 就可以找到属于这类的所有图片imgToAnns,catToImgs = defaultdict(list),defaultdict(list)if 'annotations' in self.dataset:for ann in self.dataset['annotations']:imgToAnns[ann['image_id']].append(ann)anns[ann['id']] = annif 'images' in self.dataset:for img in self.dataset['images']:imgs[img['id']] = imgif 'categories' in self.dataset:for cat in self.dataset['categories']:cats[cat['id']] = catif 'annotations' in self.dataset and 'categories' in self.dataset:for ann in self.dataset['annotations']:catToImgs[ann['category_id']].append(ann['image_id'])print('index created!!!')# 给几个类成员赋值self.anns = annsself.imgs = imgsself.cats = catsself.imgToAnns = imgToAnnsself.catToImgs = catToImgs
理解数据关联关系的重点是对 imgToAnns 变量类型的理解. 其中, imgToAnns 的类型为: defaultdict(<class ‘list’>). dict 中的键为 id, 值为一个 list, 包含所有的属于这张图的标注信息. 其中 list 的成员类型为字典, 其元素是 “annotations” 域内的一条(或多条)标注信息.
{ 289343: [{'id': 1768, 'area': 702.1057499999998, 'segmentation': [[510.66, ... 510.45, 423.01]], 'bbox': [473.07, 395.93, 38.65, 28.67], 'category_id': 18, 'iscrowd': 0, 'image_id': 289343},...]
}
getAnnIds() - 获取标注信息的 ids
def getAnnIds(self, imgIds=[], catIds=[], areaRng=[], iscrowd=None):"""获取满足给定条件的标注信息 id. 如果未指定条件, 则返回整个数据集上的标注信息 id:param imgIds (int 数组) : 通过图片 ids 指定catIds (int 数组) : 通过类别 ids 指定areaRng (float 数组) : 通过面积大小的范围, 2 个元素. (e.g. [0 inf]) 指定iscrowd (boolean) : get anns for given crowd label (False or True):return: ids (int 数组) : 满足条件的标注信息的 ids"""imgIds = imgIds if _isArrayLike(imgIds) else [imgIds]catIds = catIds if _isArrayLike(catIds) else [catIds]if len(imgIds) == len(catIds) == len(areaRng) == 0:anns = self.dataset['annotations']else:if not len(imgIds) == 0:lists = [self.imgToAnns[imgId] for imgId in imgIds if imgId in self.imgToAnns]anns = list(itertools.chain.from_iterable(lists))else:anns = self.dataset['annotations']anns = anns if len(catIds) == 0 else [ann for ann in anns if ann['category_id'] in catIds]anns = anns if len(areaRng) == 0 else [ann for ann in anns if ann['area'] > areaRng[0] and ann['area'] < areaRng[1]]if not iscrowd == None:ids = [ann['id'] for ann in anns if ann['iscrowd'] == iscrowd]else:ids = [ann['id'] for ann in anns]return ids
showAnns() - 显示给定的标注信息
def showAnns(self, anns):"""显示给定的标注信息. 一般在这个函数调用之前, 已经调用过图像显示函数: plt.imshow() :param anns (object 数组): 要显示的标注信息:return: None"""if len(anns) == 0:return 0if 'segmentation' in anns[0] or 'keypoints' in anns[0]:datasetType = 'instances'elif 'caption' in anns[0]:datasetType = 'captions'else:raise Exception('datasetType not supported')# 目标检测的标注数据if datasetType == 'instances':ax = plt.gca()ax.set_autoscale_on(False)polygons = []color = []for ann in anns:# 为每个标注 mask 生成一个随机颜色c = (np.random.random((1, 3))*0.6+0.4).tolist()[0]# 边界 mask 标注信息if 'segmentation' in ann:if type(ann['segmentation']) == list:# polygonfor seg in ann['segmentation']:# 每个点是多边形的角点, 用 (x, y) 表示poly = np.array(seg).reshape((int(len(seg)/2), 2))polygons.append(Polygon(poly))color.append(c)else:# maskt = self.imgs[ann['image_id']]if type(ann['segmentation']['counts']) == list:rle = maskUtils.frPyObjects([ann['segmentation']], t['height'], t['width'])else:rle = [ann['segmentation']]m = maskUtils.decode(rle)img = np.ones( (m.shape[0], m.shape[1], 3) )if ann['iscrowd'] == 1:color_mask = np.array([2.0,166.0,101.0])/255if ann['iscrowd'] == 0:color_mask = np.random.random((1, 3)).tolist()[0]for i in range(3):img[:,:,i] = color_mask[i]ax.imshow(np.dstack( (img, m*0.5) ))# 人体关节点 keypoints 标注信息if 'keypoints' in ann and type(ann['keypoints']) == list:# turn skeleton into zero-based indexsks = np.array(self.loadCats(ann['category_id'])[0]['skeleton'])-1kp = np.array(ann['keypoints'])x = kp[0::3]y = kp[1::3]v = kp[2::3]for sk in sks:if np.all(v[sk]>0):plt.plot(x[sk],y[sk], linewidth=3, color=c)plt.plot(x[v>0], y[v>0],'o',markersize=8, markerfacecolor=c, markeredgecolor='k',markeredgewidth=2)plt.plot(x[v>1], y[v>1],'o',markersize=8, markerfacecolor=c, markeredgecolor=c, markeredgewidth=2)p = PatchCollection(polygons, facecolor=color, linewidths=0, alpha=0.4)ax.add_collection(p)p = PatchCollection(polygons, facecolor='none', edgecolors=color, linewidths=2)ax.add_collection(p)elif datasetType == 'captions':for ann in anns:print(ann['caption'])
读取数据进行可视化
from pycocotools.coco import COCO
import numpy as np
from skimage import io # scikit-learn 包
import matplotlib.pyplot as plt
import pylab
pylab.rcParams['figure.figsize'] = (8.0, 10.0)#COCO 是一个类, 因此, 使用构造函数创建一个 COCO 对象, 构造函数首先会加载 json 文件,
# 然后解析图片和标注信息的 id, 根据 id 来创建其关联关系.dataDir='F:/Dataset/COCO/val2017/val2017'
dataType='val2017'
annFile='F:/Dataset/COCO/val2017/stuff_annotations_trainval2017/stuff_{}.json'.format(dataType)
# 初始化标注数据的 COCO api
coco=COCO(annFile)
print("数据加载成功!")#显示 COCO 数据集中的具体类和超类
cats = coco.loadCats(coco.getCatIds())
nms = [cat['name'] for cat in cats]
print('COCO categories: \n{}\n'.format(' '.join(nms)))
print("类别总数为: %d" % len(nms))
nms = set([cat['supercategory'] for cat in cats])
print('COCO supercategories: \n{}'.format(' '.join(nms)))
print("超类总数为:%d " % len(nms))#加载并显示指定 图片 id
catIds = coco.getCatIds(catNms=['person','dog','skateboard']);
imgIds = coco.getImgIds(catIds=catIds );
imgIds = coco.getImgIds(imgIds = [324158])
img = coco.loadImgs(imgIds[np.random.randint(0,len(imgIds))])[0]
I = io.imread(img['coco_url'])
plt.axis('off')
plt.imshow(I)
plt.show()#加载并将 “segmentation” 标注信息显示在图片上
# 加载并显示标注信息
plt.imshow(I)
plt.axis('off')
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
coco.showAnns(anns)

mAP计算
mAP是目标检测中常用的评价标准,尤其是在COCO数据集中,可以看到不同的mAP的评价指标,本文对这一系列指标做详细的解读:
首先,要引入四个概念:
- TP(True positive): IOU>0.5的检测框个数(注意:每个GT box只能计算一次)
- TN(True negative) : IOU <= 0.5,没有被检测到,GT也没有标注的数量。也就是本来是负样例,分类也是负样例。(本文map计算没有用到该指标)。
- FP(False positive): IOU <= 0.5的检测框的个数(或是检测到同一个GT box的多余检测框的数量)
- FN(False negative):没有检测到的GT box的数量

举个例子,上图有两只猫,绿色的框分别代表两个GT box真实框,红色的代表预测框。比较大的红框因为大于0.5的IOU阈值,所以是TP,比较小的红框因为值小于0.5,所以是FP。另外右下角的小猫没有被检测到,属于漏检,也就是FN。
(注意:【图中的0.9和0.3代表类别的置信度,不是IOU】,如果不理解IOU的话,可以移步至《IOU、GIOU、DIOU、CIOU损失函数详解》,有详细描述)
再来介绍两个评价指标:
1.Precision(查准率):TP/(TP + FP),代表模型预测的所有目标中,预测正确目标的占比。

如图,一张图有5只猫,但是我们只有一个阈值大于0.5的红框,也就是TP = 1,因为没有其他阈值小于0.5的框,所以FP=0. Pricision = 1 /(1+0) = 1 ,也就是100%查准率。但是能说这个网络的效果很好吗?显然不能,因为其他四只猫都没有被识别出来,因此就引入了查全率。
Recall(查全率): TP/(TP+FN),代表所有真实目标中,模型预测正确目标的比例。
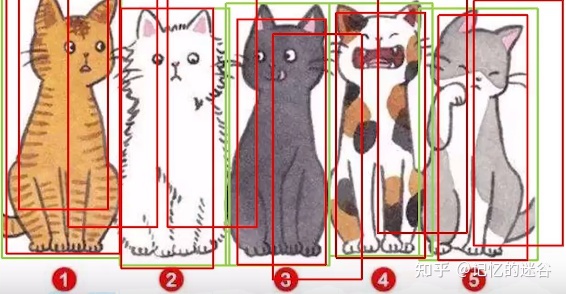
我们再看这张图:图中有5只猫,但是有很多红色框框出现在图中。首先看TP:5个GT box都有红框正确预测到(虽然IOU>0.5的红框不止一个,但每个GT box只算一次),再看FN:图中没有漏检的物体,所以FP = 0 。Recall = 5/(5+0) = 1 ,也就是100%的查全率,但图中乱七八糟的杂框显然效果不好,简单通过Recall率,来评价检测质量也不合理。
所以,我们又引入了两个指标:
- AP: precision - Recall 曲线的面积
- mAP:各类别AP的平均值
举一个例子具体算IOU和mAP:

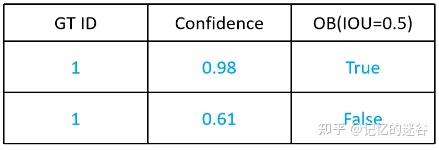
如上图,有两只猫,每只猫分别有一个绿色的GT box,两个红色的box代表预测框。因为有两个目标,所以设置num_obj = 2。接下来,我们用表格描述图中预测框的信息:表格有两行数据,按照第二列类别置信度(0.98和0.61降序排序),第一列代表属于哪个实例,第三列代表IOU是否大于0.5(注意哦,不是图片里面的0.98和0.61的置信度,这里用的是IOU评价指标,如果你不清楚的话,不妨花点时间看一下《IOU、GIOU、DIOU、CIOU损失函数详解》)。
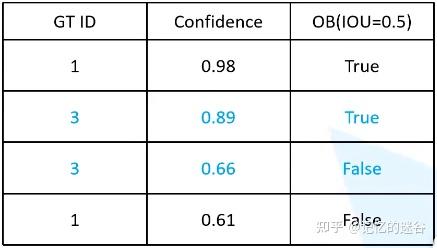
接下来,我们再输入一张图片,包括一个目标,所以num_obj=2+1 = 3,图中又包含两个红色预测框,我们把它按照类别置信度排序,继续加入表格:

图中两个预测框都属于第三个实例,所以GT ID=3,中间红框的IOU>0.5所以为True,右边的红框IOU小于0.5所以是False。
我们输入第三张图片:图片中包括四个绿色的GT box框(ID分别为4~7),有三个红色的预测框,其中id为5的猫猫没有对应的预测框。

最左边的红框类别置信度(0.52)最低,加入表格的最后一行。ID为6和7的猫猫对应预测框也分别加入表格中。因为这三个框IOU都大于0.5,所以都设置为True

我们从以下几种不同的指标(方法同VOC2010)分别计算Precision和Recall:

1.假设confidence >= 0.9才算正确匹配,观察表格,只有第一行满足匹配条件,因此TP = 1, FP = 0(根据匹配条件,只检测到一个图片,而且是正确的,所以不存在误检),FN=6(7个目标,找出来1个,漏检6个)。 Precision = 1 / (1+0) = 1,Recall = 1 /(1 + 6) = 0.14 。
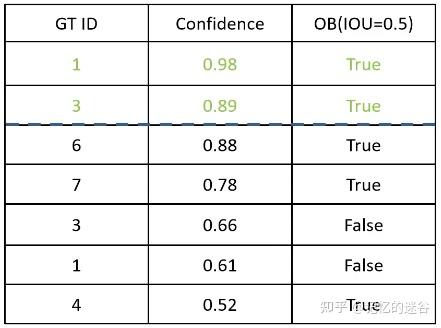
2.假设conficende >= 0.89算是正确匹配,观察表格,前两行满足条件,TP=2, FP=0, FN=5, Precision = 2/(2+0) = 1。 Recall = 2 / (2+5) = 0.28。
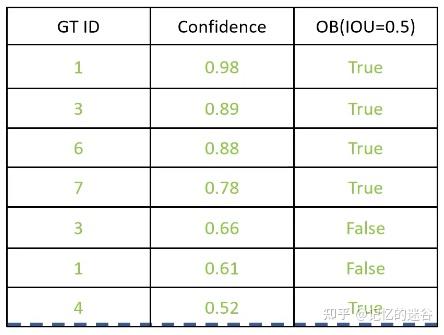
以此类推,假设confidence >= 0.5是正确匹配,所有的行都满足条件,此时TP = 5, FP = 2,FN = 2(ID为2和5的猫漏检)。Precision = 5/(5+2) = 0.71。 Recall = 5 / (5+2) = 0.71。

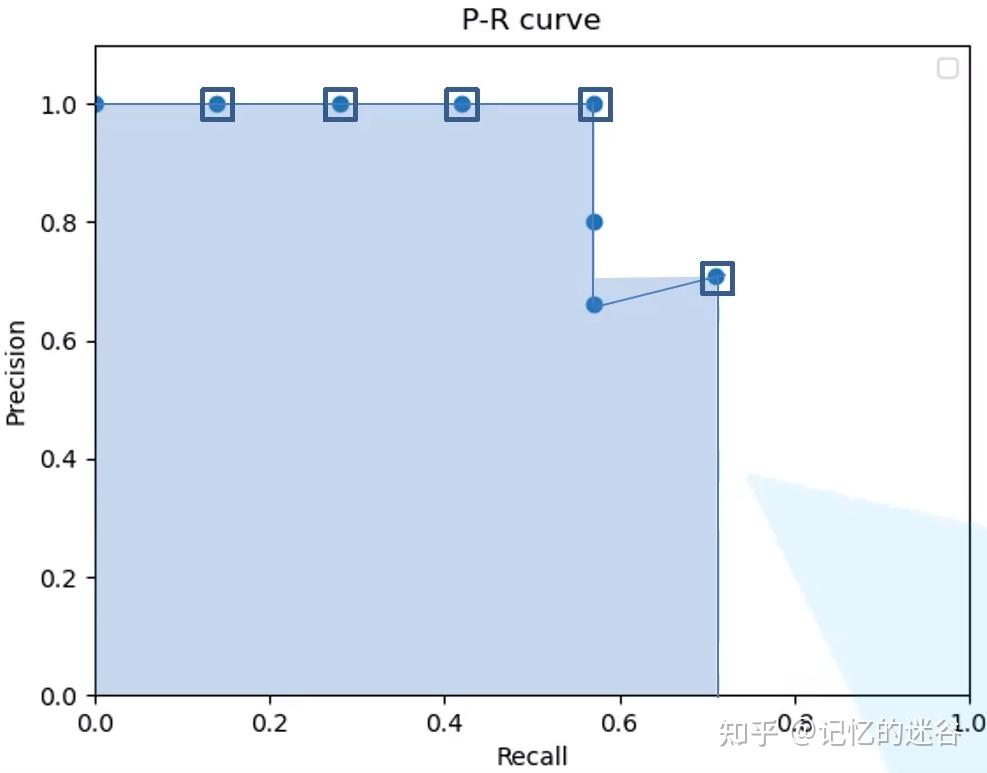
将上述的步骤计算出的Precision和Recall列成上表所示。对于横坐标Recall而言,需要滤除重复信息,也就是对下图的0.57的Recall有三行,只保留Precision最大的一行,其他两行不计算。

将上图的5个点绘图,图中的阴影部分的面积就是上面说的AP。具体计算如下:AP=(0.14-0)*1 + (0.28-0.14)*1+(0.42-0.28)*1 + (0.57-0.42)*1 +(0.71-0.57)*0.71 = 0.67。所以猫这个类别的AP就是0.67,同样,把所有类别的AP值计算出来,取平均,我们就得到了mAP.
附:precision和recall计算源码
# 计算每个类别的precision和recall
def calc_recall_precision(gt_list, pred_list): bin_gt = np.array(gt_list, dtype=np.bool) # gt的标签,如果包含该类别,则类别为True,否则为Falsearr_pred = np.array(pred_list, dtype=np.float) # 预测类别的置信度p_list = pred_listp_list.sort()recall_list = []precision_list = []threshold_list = []for i in range(201): # 阈值从0到1,以0.05为区间间隔,计算每个区间的准召率score_base = i * 0.005 # 当前阈值bin_pred = arr_pred >= float(score_base) # 是否大于阈值tp = np.sum(bin_pred & bin_gt) # 大于阈值且是正确类别tn = np.sum((~bin_pred) & (~bin_gt)) fp = np.sum(bin_pred & (~bin_gt)) # 置信度大于阈值但预测类别错误fn = np.sum((~bin_pred) & (bin_gt)) # 是真实类别但置信度小于阈值没检测到p = (tp + 0.0) / (tp + fp + 0.000001) # precision = tp /(tp + fp)代表预测正确的类别占比。r = (tp + 0.0) / (tp + fn + 0.000001) # recall = tp / (tp + fn) 代表查全率if (tp+fp)<1 or (tp+fn)<1: continuerecall_list.append(r)precision_list.append(p)threshold_list.append(score_base)# reverse是反转列表,对于recall来说是变成升序序列,precision和threshold变成降序序列recall_list.reverse() # [0.28 0.30, 0.42, 0.46,.....]precision_list.reverse() # [0.99, 0.98, 0.96, ......]threshold_list.reverse() # [0.81, 0.80, 0.75, ......]return recall_list, precision_list, threshold_list# 计算所有类别的平均precision和recall
def cal_average_class_pr(pred, target): # 两个参数的shape:[batch_size, num_classes]pre_sum, rec_sum, count = 0,0,0 # 初始化precision和recall的值for i in range(len(target[0])): # 循环次数等价于类别个数pred_list = pred[:, i]gt_list = target[:, i]pred_list.tolist()gt_list.tolist()rec, prec, thresh = calc_recall_precision(gt_list, pred_list)rec = np.asarray(rec, dtype=np.float32)prec = np.asarray(prec, dtype=np.float32)thresh = np.asarray(thresh, dtype=np.float32)idx = np.where(rec>0.8) # 查全率大于0.8的索引if len(idx[0].tolist())>0:# 找到recall首次大于0.8的索引,输出当前索引对应的reccall,precision,thresholdrec_v = rec[idx[0][0]] prec_v = prec[idx[0][0]]thresh_v = thresh[idx[0][0]]print("Class: {}, prec: {:.4f}, rec: {:.4f}, thresh: {:.4}".format(i+1, prec_v, rec_v, thresh_v))pre_sum = pre_sum + prec_vrec_sum = rec_sum + rec_vcount = count + 1return pre_sum/count, rec_sum/count
COCO评价指标
API介绍

首先看第一部分的AP:
AP代表 IOU从0.5到0.95,间隔0.05计算一次mAP, 取平均mAP即为最终结果。
AP0.5和AP0.75则分别代表IOU为0.5和0.75的mAP值
第二部分 : AP Across Scales:
代表小、中、大三个类别的mAP,将面积小于322像素点的归为小目标,面积大于962的归为大目标,介于二者之间的为中等目标。计算不同目标的mAP。
第三部分:AR
代表查全率。三组分别代表每张图片限定检测1、10、100个目标能够得到相应的Recall的值。
第四部分:AR Across Scales
代表对应不同尺度的Recall值。
初步实现目标检测任务mAP计算
首先要弄清楚cocoapi指定的数据格式(训练网络预测的结果),在官网的Evaluate下拉框中选择Results Format,可以看到每种任务的指定数据格式要求。
 这里主要讲讲针对目标检测的格式。根据官方文档给的预测结果格式可以看到,我们需要以列表的形式保存结果,列表中的每个元素对应一个检测目标(每个元素都是字典类型),每个目标记录了四个信息:
这里主要讲讲针对目标检测的格式。根据官方文档给的预测结果格式可以看到,我们需要以列表的形式保存结果,列表中的每个元素对应一个检测目标(每个元素都是字典类型),每个目标记录了四个信息:
image_id记录该目标所属图像的id(int类型)category_id记录预测该目标的类别索引,注意这里索引是对应stuff中91个类别的索引信息(int类型)bbox记录预测该目标的边界框信息,注意对应目标的[xmin, ymin, width, height] (list[float]类型)score记录预测该目标的概率(float类型)
下图是训练在coco2017验证集上预测的结果:

接着将预测结果保存成json文件,后面需要使用到:
import jsonresults = [] # 所有预测的结果都保存在该list中
# write predict results into json file
json_str = json.dumps(results, indent=4)
with open('predict_results.json', 'w') as json_file:json_file.write(json_str)
数据准备:
- COCO2017验证集json文件
instances_val2017.json
链接: https://pan.baidu.com/s/1ArWe8Igt_q0iJG6FCcH8mg 密码: sa0j
示例代码:
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval# accumulate predictions from all images
# 载入coco2017验证集标注文件
coco_true = COCO(annotation_file="/data/coco2017/annotations/instances_val2017.json")
# 载入网络在coco2017验证集上预测的结果
coco_pre = coco_true.loadRes('predict_results.json')coco_evaluator = COCOeval(cocoGt=coco_true, cocoDt=coco_pre, iouType="bbox")
coco_evaluator.evaluate()
coco_evaluator.accumulate()
coco_evaluator.summarize()
输出结果:
loading annotations into memory...
Done (t=0.43s)
creating index...
index created!
Loading and preparing results...
DONE (t=0.65s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=21.15s).
Accumulating evaluation results...
DONE (t=2.88s).Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.233Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.415Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.233Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.104Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.262Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.323Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.216Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.319Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.327Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.145Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.361Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.463
一个具体实现的例子
mAP(Mean Average Precision)均值平均准确率,即检测多个目标类别的平均准确率。在目标检测领域mAP是一个最为常用的指标。具体概念不叙述,本文主要讲如何利用Github上一些开源项目计算自己网络的mAP值等信息。首先给出两个Github链接,链接1;链接2。这两个链接项目都可以帮助我们计算mAP的值,用法也差不多,链接1感觉用起来更简单点,链接2的功能更全面点(绘制的Precision-Recall曲线更准)。本文主要介绍下链接项目1的使用方法,利用项目1最终能得到如下图所示的计算结果(虽然也能绘制P-R曲线,但感觉绘制的不准确)。


项目的使用流程
使用方法流程主要分为如下几步:(1) 克隆项目代码;(2)创建ground-truth文件,并将文件复制到克隆项目的 input/ground-truth/ 文件夹中;(3)创建detection-results文件,并将文件复制到克隆项目的 input/detection-results/ 文件夹中;(4)将与detection-results对应的验证图像文件放入克隆项目 input/images-optional 文件夹中(该步骤为可选项,可以不放入图像,如果放入图像会将标注框、检测框都绘制在图像上,方便后期分析结果);(5)在项目文件夹中打开终端,并执行指令python main.py即可得到结果(结果全部保存在克隆项目的results文件夹中)。
1)克隆代码
打开项目1https://github.com/Cartucho/mAP进行克隆,或者直接使用git克隆。
2)创建ground-truth文件
在项目的readme中有给出事例:
例如图像1中的标注信息(image_1.txt),文件的命名要与图像命名相同,每一行的参数为类别名称、左上角x坐标、左上角y坐标、右下角x坐标、右下角y坐标
<class_name> <left> <top> <right> <bottom> [<difficult>]
参数difficult是可选项,每一个图像文件对应生成一个txt文件,与PASCAL VOC的xml文件一样,一一对应。
tvmonitor 2 10 173 238
book 439 157 556 241
book 437 246 518 351 difficult
pottedplant 272 190 316 259
将所有生成好的文件复制到克隆项目的 input/ground-truth/ 文件夹中
3)创建detection-results文件
同样在项目的readme中有给出事例:
对于图像1的实际预测信息(image_1.txt),文件的命名要与图像命名相同,每一行的参数为类别名称、预测概率、预测左上角x坐标、预测左上角y坐标、预测右下角x坐标、预测右下角y坐标
<class_name> <confidence> <left> <top> <right> <bottom>
每个预测图像对应生成一个txt文件
tvmonitor 0.471781 0 13 174 244
cup 0.414941 274 226 301 265
book 0.460851 429 219 528 247
chair 0.292345 0 199 88 436
book 0.269833 433 260 506 336
将所有生成好的预测文件复制到克隆项目的 input/detection-results/ 文件夹中
4)复制图像文件(可选)
将与detection-results对应的验证图像文件放入克隆项目 input/images-optional 文件夹中(该步骤为可选项,可以不放入图像,如果放入图像会将标注框、检测框都绘制在图像上,方便后期分析结果)
5)开始计算
在项目文件夹中打开终端,并执行指令python main.py即可得到结果(结果全部保存在克隆项目的results文件夹中,注:该项目的计算结果是IOU阈值取0.5的结果)
通过以上步骤就能够得到出训练网络的预测mAP,使用起来也是非常的简单。对于需要绘制Precision-Recall曲线的同学可以使用**链接2**中的项目代码。项目2的使用步骤其实基本相同,且需要准备的文件也都是一样的,不同的是使用的指令。
cup 0.414941 274 226 301 265
book 0.460851 429 219 528 247
chair 0.292345 0 199 88 436
book 0.269833 433 260 506 336
将所有生成好的预测文件复制到克隆项目的 input/detection-results/ 文件夹中#### 4)复制图像文件(可选)将与detection-results对应的验证图像文件放入克隆项目 input/images-optional 文件夹中(该步骤为可选项,可以不放入图像,如果放入图像会将标注框、检测框都绘制在图像上,方便后期分析结果)#### 5)开始计算在项目文件夹中打开终端,并执行指令python main.py即可得到结果(结果全部保存在克隆项目的results文件夹中,**注:该项目的计算结果是IOU阈值取0.5的结果**)通过以上步骤就能够得到出训练网络的预测mAP,使用起来也是非常的简单。对于需要绘制Precision-Recall曲线的同学可以使用**[链接2](https://github.com/rafaelpadilla/Object-Detection-Metrics)**中的项目代码。项目2的使用步骤其实基本相同,且需要准备的文件也都是一样的,不同的是使用的指令。
相关文章:
第二十二章 解读pycocotools的API,目标检测mAP的计算COCO的评价指标(工具)
Pycocotools介绍 为使用户更好地使用 COCO数据集, COCO 提供了各种 API。COCO是一个大型的图像数据集,用于目标检测、分割、人的关键点检测、素材分割和标题生成。这个包提供了Matlab、Python和luaapi,这些api有助于在COCO中加载、解析和可视化注释。 …...

如何避免光模块接口受到污染?
光模块作为光通信领域一个重要的配件,实现光电和电光的转换,和光纤连接,承载了数据流量的快速转换与传输。因而在整个网络体系中,起着至关重要的作用。虽然光模块在使用过程中,不像交换机和服务器等网络设备一样需要经…...

虚拟机系列:Oracle VM VirtualBox虚拟机的使用教程和使用体验情况反馈
Oracle VM VirtualBox虚拟机的使用教程和使用体验情况反馈 一. 简述:二. 下载三. 安装解压后选择需要的版本点击安装1:第一步,点击安装,点击下一步2. 这里直接点击下一步,3. 网络警告选择:是4. 准备好以后,点击安装5. 点击完成即可四. 打开五. 创建虚拟机1. 输入虚拟机名…...

echarts 通用线性渐变堆叠面积图
echarts 通用线性渐变堆叠面积图 getLineData2() {const myChart echarts.init(this.$refs.chartDom);const option {tooltip: {trigger: axis,},legend: {show: false,textStyle: {fontSize: 14, //字体大小color: #ffffff, //字体颜色},data: [AAA, BBB],},grid: {show: tr…...
在云服务器上搭建个人版chatGPT及后端Spring Boot集成chat GPT
原创/朱季谦 本文分成两部分,包括【国内服务器上搭建chat GPT】和【后端Spring Boot集成chat GPT】。 无论是在【国内服务器上搭建chat GPT】和【后端Spring Boot集成chat GPT】,两个方式都需要魔法访问,否则是无法正常使用的,即…...

MYSQL基础知识之【索引】
文章目录 前言MySQL 索引普通索引创建索引修改表结构(添加索引)创建表的时候直接指定删除索引的语法唯一索引创建索引修改表结构创建表的时候直接指定使用ALTER 命令添加和删除索引使用 ALTER 命令添加和删除主键显示索引信息 后言 前言 hello world欢迎来到前端的新世界 &…...

工信部:1—10月我国软件业务收入98191亿元 同比增长13.7%
2023年1—10月份软件业经济运行情况 1—10月份,我国软件和信息技术服务业(以下简称“软件业”)运行态势平稳,软件业务收入较快增长,利润总额两位数增长,软件业务出口降幅持续收窄。 一总体运行情况 软件…...

直播预告 | AR眼镜在现代医疗中究竟有哪些妙用?11.28晚八点虹科直播间为您揭晓!
直播预告 | AR眼镜在现代医疗中究竟有哪些妙用?11.28晚八点虹科直播间为您揭晓! 什么是AR眼镜? AR眼镜,即增强现实眼镜,是一种结合虚拟信息与真实世界的创新医疗工具。 通过集成高科技传感器和实时数据处理技术&…...

独乐乐不如众乐乐(二)-某汽车零部件厂商IC EMC企业规范
前言:该汽车零部件厂商关于IC EMC的规范可能是小编看过的企业标准里要求最明确的一份企业标准了,充分说明了标准方法不是死的,可以灵活应用。 先看看这份规范的抬头: 与其他企业规范一样,该汽车零部件厂商的IC EMC规范…...
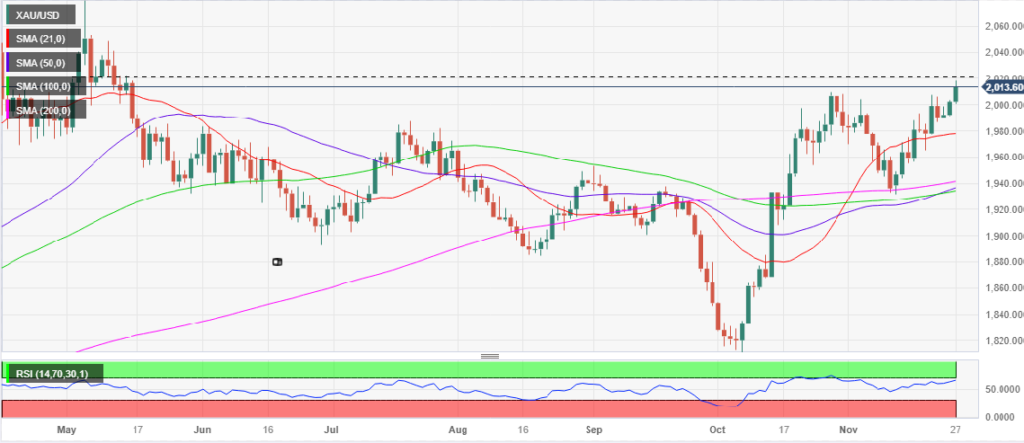
每日汇评:黄金有望在美欧通货数据周回升至2020美元上方
金价在2000美元以上占据主导地位,巩固了其2018美元的六个月高点; 美元在避险情绪中暂停下跌,美债收益率小幅上升; 金价本周收于2000美元以上,在关键通胀数据公布之前将有更多涨幅; 黄金价格已经从周一亚洲早…...

Matlab数学建模算法详解之混合整数线性规划 (MILP) 算法(附完整实现代码)
🔗 运行环境:Matlab 🚩 撰写作者:左手の明天 🥇 精选专栏:《python》 🔥 推荐专栏:《算法研究》 #### 防伪水印——左手の明天 #### 💗 大家好🤗ᾑ…...

个人硬件测试用例入门设计
📑打牌 : da pai ge的个人主页 🌤️个人专栏 : da pai ge的博客专栏 ☁️宝剑锋从磨砺出,梅花香自苦寒来 🌤️功能测试 进行新增、…...

Lazada测评怎么做?
国内电商行业的发展日趋激烈,卖家想要脱颖而出非常困难,许多卖家选择入驻跨境电商平台开店, 跨境电商平台吸引了许多卖家入驻,而最近有很多朋友在私信问我关于Lazada测评的一些事情 Lazada产品测评流程步骤 怎么测评 这个怎么测…...
)
flv视频轮播功能(单个时)
1.轮播思路 获取八个视频源的地址。 将这些地址分成两组,每组包含四个地址。 在页面中创建一个四分屏布局的视频播放器。 将第一组的四个视频地址分别插入到四分屏布局的四个视频框中。 设置一个定时器,每10秒执行一次。 每次定时器触发时…...
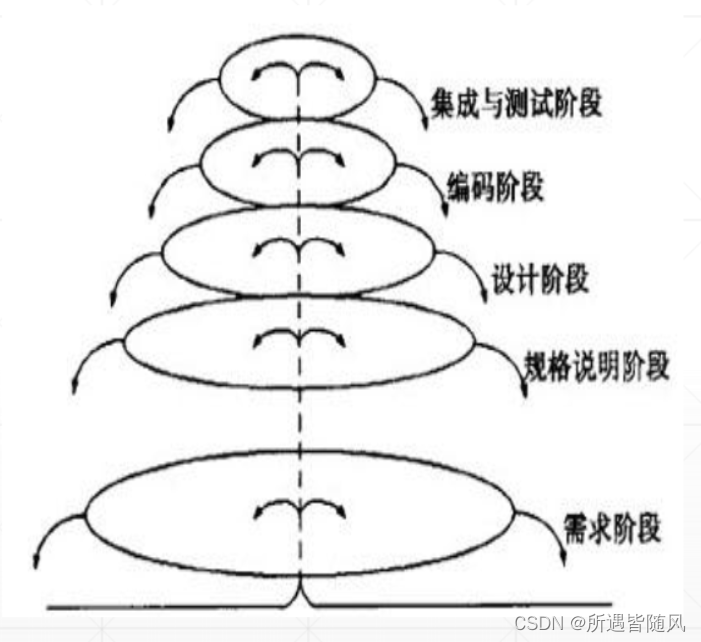
快速了解软件工程学概述(5种软件过程模型)
目录 1 、什么是软件?特点有哪些 ? 2 、 软件危机 定义: 软件危机产生的原因 消除软件危机的方法 3 、软件工程 1.软件工程的介绍 (1)概念 (2)本质特征 (3)软件工程方法学(方…...
)
sql21(Leetcode1174即时食物配送2)
代码: # Write your MySQL query statement belowselect round (sum(order_date customer_pref_delivery_date) * 100 /count(*),2 ) as immediate_percentage from Delivery where (customer_id, order_date) in (select customer_id, min(order_date)from deliv…...

Node——Node.js基础
对Node.js中的基础知识进行讲解,包括全局变量、全局对象、全局函数以及用于实现模块化编程的exports和module对象等内容,这些知识是学习Node.js应用开发的基础。 1、Node.js全局对象 全局,即程序中任何地方都可以使用,Node.js内…...
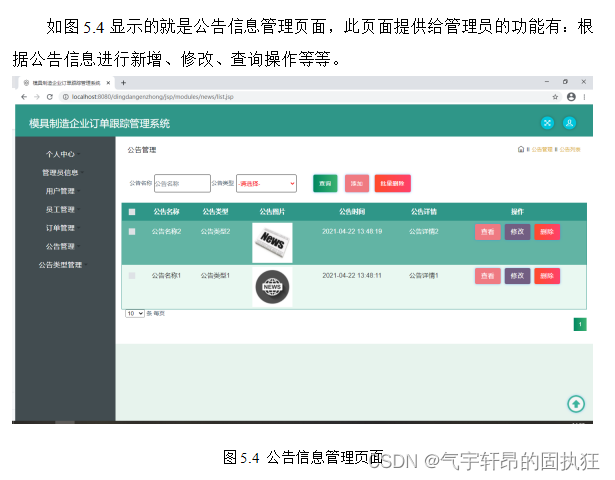
基于SSM的企业订单跟踪管理系统(有报告)。Javaee项目
演示视频: 基于SSM的企业订单跟踪管理系统(有报告)。Javaee项目 项目介绍: 采用M(model)V(view)C(controller)三层体系结构,通过Spring SpringM…...
)
中国吡啶行业市场研究与投资评估报告(2023版)
内容简介: 目前吡啶及其衍生物作为某些化学合成反应的催化剂,需求量在不断增加,因此吡啶在化学品合成领域的市场潜力最大。此外,对高效农药的需求量上升也是促进全球吡啶市场发展的另一关键因素。受人均可支配收入的持续增长和对…...
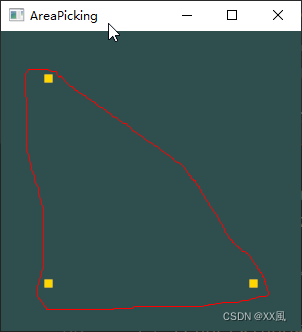
鼠标点击位置获取几何体对象_vtkAreaPicker_vtkInteractorStyleRubberBandPick
开发环境: Windows 11 家庭中文版Microsoft Visual Studio Community 2019VTK-9.3.0.rc0vtk-example参考代码 demo解决问题:框选或者点选某一区域,并获取区域prop3D对象(红线内为有效区域,polydata组成的3d几何对象&a…...

BthPS3驱动:突破Windows壁垒,让PS3控制器焕发新生
BthPS3驱动:突破Windows壁垒,让PS3控制器焕发新生 【免费下载链接】BthPS3 Windows kernel-mode Bluetooth Profile & Filter Drivers for PS3 peripherals 项目地址: https://gitcode.com/gh_mirrors/bt/BthPS3 当PS3控制器遇上Windows&…...
)
重装 Office 必看:Win10/Win11 完美卸载 Office 2021(附视频)
不少人在使用 Office 2021 时会遇到卡顿、打不开、激活异常、功能报错等问题,常规修复与重置往往解决不了根源,最终只能选择卸载重装。但很多用户自己手动卸载时,经常遇到卸载不干净、注册表残留、再次安装冲突、激活失败等麻烦,折…...

为什么要做 GeoPipeAgent贾
指令替换 项目需求:将加法指令替换为减法 项目目录如下 /MyProject ├── CMakeLists.txt # CMake 配置文件 ├── build/ #构建目录 │ └── test.c #测试编译代码 └── mypass2.cpp # pass 项目代码 一,测试代码示例 test.c // test.c #includ…...

微信网页版浏览器插件:3分钟实现跨设备无缝通讯的终极方案
微信网页版浏览器插件:3分钟实现跨设备无缝通讯的终极方案 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 你是否曾在公司电脑上无法安装微…...
)
Blazor组件生态生死线,2026年淘汰清单曝光:17个高危NuGet包+5个即将废弃API(含迁移路径图谱)
第一章:Blazor组件生态生死线:2026年淘汰预警全景图Blazor 组件生态正站在结构性分化的临界点。微软官方已明确将 .NET 8 的长期支持(LTS)周期定为至 2026 年 11 月,而所有基于 .NET 6/7 构建的第三方组件库若未完成向…...

CPV10-GE-DN3-8控制阀端子
CPV10-GE-DN3-8控制阀端子是一款应用于气动控制系统中的关键连接与分配单元,主要用于阀岛系统中的信号与气路接口管理,具备结构紧凑、连接可靠等特点,广泛应用于自动化生产线及工业控制领域。模块化设计,便于系统扩展与组合使用接…...

Element Plus访问优化指南:3种实用方法让你告别加载卡顿
Element Plus访问优化指南:3种实用方法让你告别加载卡顿 【免费下载链接】element-plus 🎉 A Vue.js 3 UI Library made by Element team 项目地址: https://gitcode.com/GitHub_Trending/el/element-plus 你是否曾经在开发Vue 3项目时࿰…...

Andrej Karpathy四大AI编程原则:远程团队协作效率提升指南 [特殊字符]
Andrej Karpathy四大AI编程原则:远程团队协作效率提升指南 🚀 【免费下载链接】andrej-karpathy-skills 项目地址: https://gitcode.com/GitHub_Trending/an/andrej-karpathy-skills 在当今分布式工作时代,远程团队协作已成为软件开发…...

软件测试工程师如何避免成为“提线木偶”式的工具人?
在快速迭代的软件开发环境中,软件测试工程师常常面临沦为“提线木偶”的风险——机械执行测试用例、被动响应需求,缺乏自主思考与决策权。这种状态不仅限制职业成长,还影响产品质量与团队效率。作为软件测试从业者,如何挣脱工具人…...

3步搭建你的演唱会抢票自动化助手:告别手速焦虑
3步搭建你的演唱会抢票自动化助手:告别手速焦虑 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper DamaiHelper是一个基于Python开发的智能抢票工具,专门针对大麦网演唱会门票…...