一篇文章完成Hbase入门
文章目录
- 一、简介
- 1、数据模型结构
- 2、物理存储结构
- 3、数据模型
- 4、基本架构
- 二、安装
- 1、下载解压安装包
- 2、修改配置文件
- 3、启动服务(单机、集群)
- 4、配置高可用(HA)
- 三、命令行操作
- 1、建表
- 2、新增/更新数据
- 3、查看表数据
- 4、删除数据
- 5、修改默认保存的数据版本
- 四、架构
- 1、RegionServer 架构
- 2、写流程
- 3、MemStore Flush
- 4、读流程
- 5、Region Split(Region切分)
- 五、API
- 1、获取链接
- 2、获取Table对象
- 3、Put
- 4、Get
- 5、Scan
- 6、Delete删除
- 7、完整代码
- 六、HBase使用设计
- 1、预分区
- 2、RowKey设计
- 3、内存优化
- 4、基础优化
一、简介
HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库。
1、数据模型结构
逻辑上,HBase的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从HBase的底层物理存储结构(K-V)来看,HBase更像是一个multi-dimensional map(多维地图)
HBase逻辑结构

2、物理存储结构
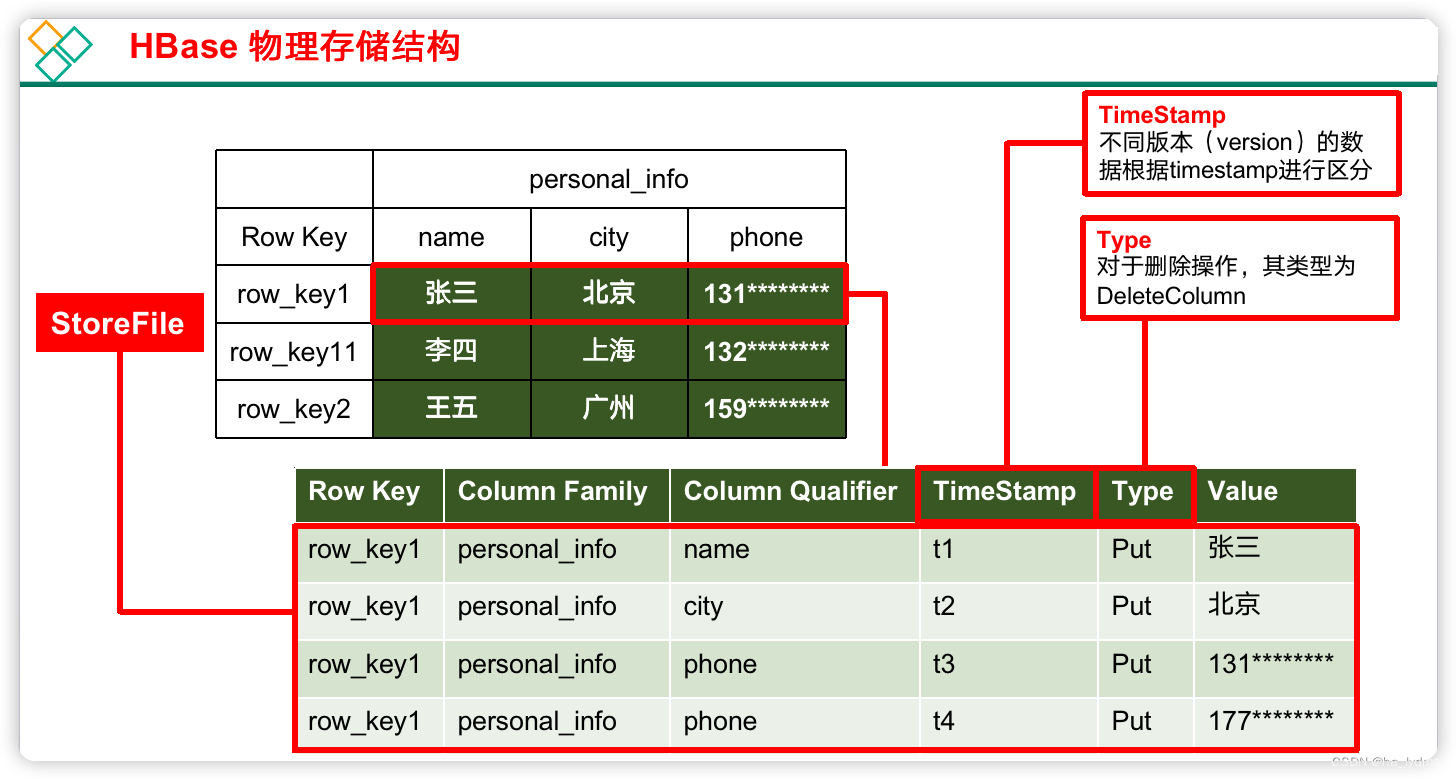
3、数据模型
- Name Space:命名空间
- Table:表
- Row:行
- RowKey:
- Column Family:列簇
- Column Qualifier
- Time Stamp:版本(时间戳)
- Cell:单元格
- Region:若干行(按行划分存储)
1)Name Space
命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。一个表可以自由选择是否有命名空间,如果创建表的时候加上了命名空间后,这个表名字以<Namespace>:<Table>作为区分。
2)Table
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
3)Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
4) RowKey
Rowkey由用户指定的一串不重复的字符串定义,是一行的唯一标识!数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
如果使用了之前已经定义的RowKey,那么会将之前的数据更新掉。
5)Column Family
列族是多个列的集合。一个列族可以动态地灵活定义多个列。表的相关属性大部分都定义在列族上,同一个表里的不同列族可以有完全不同的属性配置,但是同一个列族内的所有列都会有相同的属性。
列族存在的意义是HBase会把相同列族的列尽量放在同一台机器上,所以说,如果想让某几个列被放到一起,你就给他们定义相同的列族。
官方建议一张表的列族定义的越少越好,列族太多会极大程度地降低数据库性能,且目前版本Hbase的架构,容易出BUG。
6) Column Qualifier
Hbase中的列是可以随意定义的,一个行中的列不限名字、不限数量,只限定列族。因此列必须依赖于列族存在!列的名称前必须带着其所属的列族!例如info:name,info:age。
因为HBase中的列全部都是灵活的,可以随便定义的,因此创建表的时候并不需要指定列!列只有在你插入第一条数据的时候才会生成。其他行有没有当前行相同的列是不确定,只有在扫描数据的时候才能得知。
7)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间。在读取单元格的数据时,版本号可以省略,如果不指定,Hbase默认会获取最后一个版本的数据返回。
8)Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell中的数据全部是字节码形式存贮。
9)Region
Region由一个表的若干行组成。在Region中行的排序按照行键(rowkey)字典排序。Region不能跨RegionSever,且当数据量大的时候,HBase会拆分Region。
Region由RegionServer进程管理。HBase在进行负载均衡的时候,一个Region有可能会从当前RegionServer移动到其他RegionServer上。
Region是基于HDFS的,它的所有数据存取操作都是调用了HDFS的客户端接口来实现的。
4、基本架构
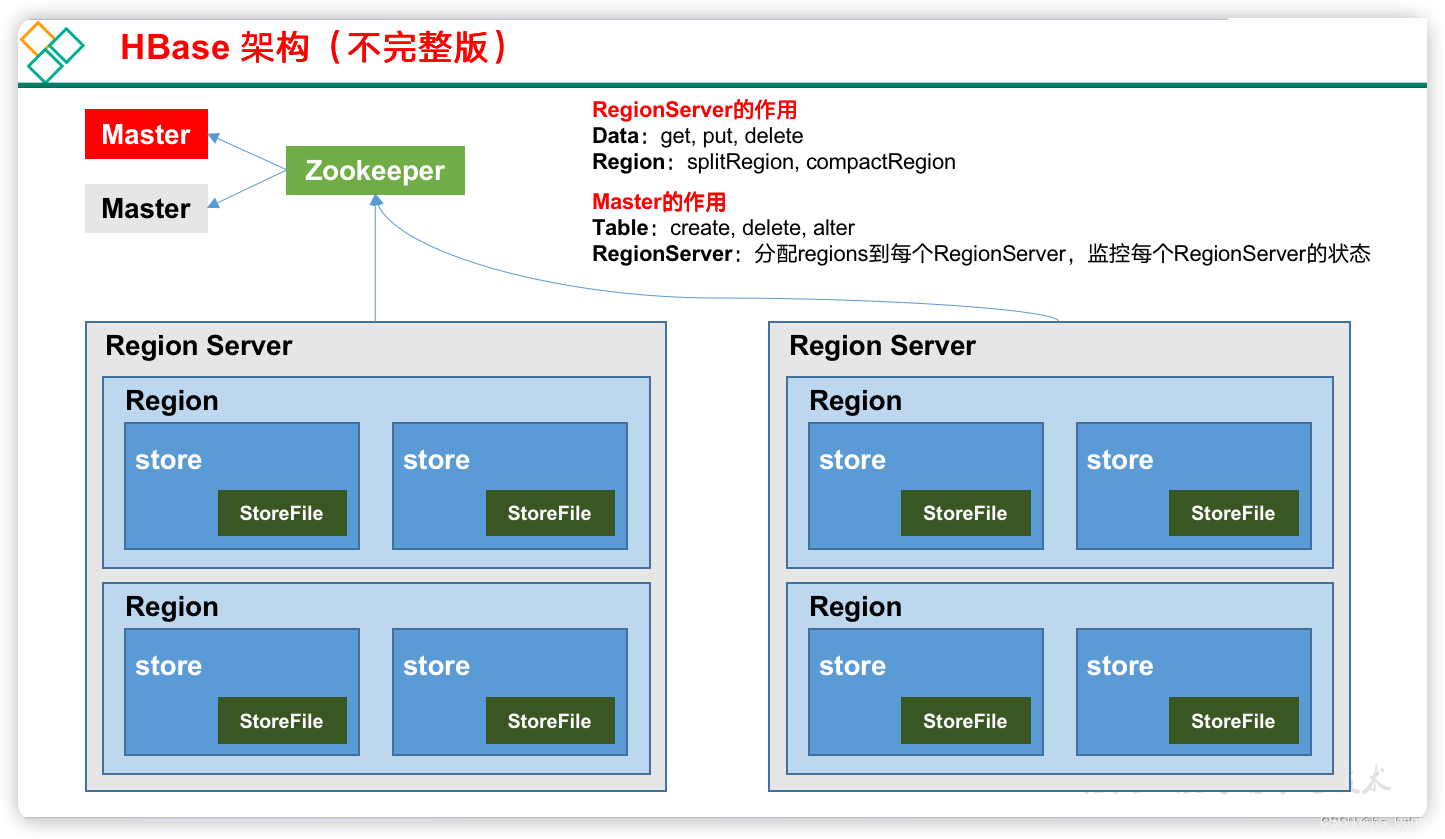
1)Region Server
Region Server为 Region的管理者,其实现类为HRegionServer,主要作用如下:
- 对于数据的操作:get, put, delete;
- 对于Region的操作:splitRegion、compactRegion。
2)Master
Master是所有Region Server的管理者,其实现类为HMaster,主要作用如下:
- 对于表的操作:create, delete, alter
- 对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
3)Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
4)HDFS
HDFS为HBase提供最终的底层数据存储服务,同时为HBase提供高容错的支持。
二、安装
下面的安装配置都是在所有节点都需要配置的
1、下载解压安装包
下载Hbase
wget https://gitcode.net/weixin_44624117/software/-/raw/master/software/Linux/Hbase/hbase-2.0.5-bin.tar.gz
解压安装包
tar -zxvf hbase-2.0.5-bin.tar.gz -C /opt/module
修改文件目录
mv /opt/module/hbase-2.0.5 /opt/module/hbase
2、修改配置文件
配置环境变量
sudo vim /etc/profile.d/my_env.sh#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
修改配置文件
cd /opt/module/hbase/conf
vim hbase-env.sh# 修改内容
export HBASE_MANAGES_ZK=false
修改配置文件hbase-site.xml
vim hbase-site.xml# 修改内容
<configuration><property><name>hbase.rootdir</name><value>hdfs://hadoop101:8020/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.quorum</name><value>hadoop101,hadoop102,hadoop103</value></property><property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property><property><name>hbase.wal.provider</name><value>filesystem</value></property>
</configuration>
3、启动服务(单机、集群)
启动(单节点启动)
cd /opt/module/hbase
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
关闭节点
bin/hbase-daemon.sh stop master
bin/hbase-daemon.sh stop regionserver
启动(启动集群)(Hadoop101主节点)
cd /opt/module/hbase
bin/start-hbase.sh
关闭集群
bin/stop-hbase.sh
查看页面:
http://hadoop101:16010/
4、配置高可用(HA)
关闭集群
cd /opt/module/hbase
bin/stop-hbase.sh
在conf目录下创建backup-masters文件
touch conf/backup-masters
在backup-masters文件中配置高可用HMaster节点
echo hadoop102 > conf/backup-masters
重启hbase
cd /opt/module/hbase
bin/start-hbase.sh
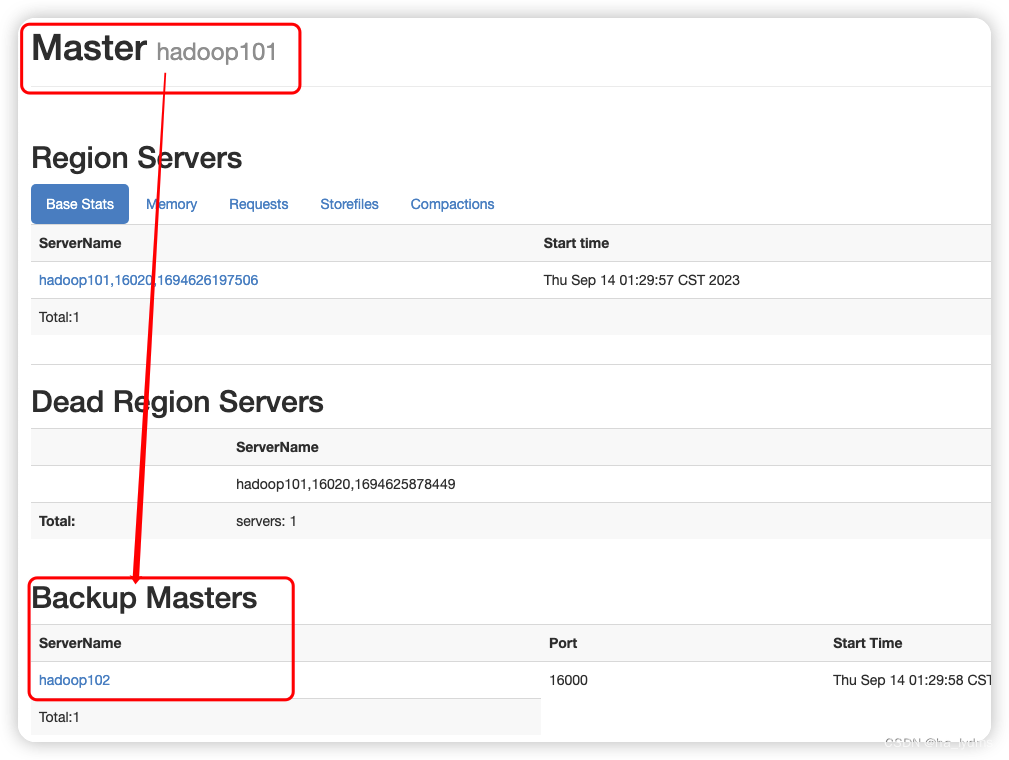
打开页面测试查看(多了一个back Master节点)
http://hadooo102:16010
三、命令行操作
1、建表
登录Hbase
bin/hbase shell
查看帮助
help
查看表列表
list
创建表
- 表名:
student - 列簇:
info、address
create 'student','info'
create 'student', 'info', 'address'
新增列簇
alter 'student', 'address'
2、新增/更新数据
插入数据
- 命名空间:
default - 表明:
student - rowKey:
1001 - 列簇:
info - 列名:
info、sex - 值:
18
put 'student','1001','info','male'
put 'student','1001','info:sex','male'
put 'student','1001','info:age','18'
put 'student','1002','info:name','Janna'
put 'student','1002','info:sex','female'
put 'student','1002','info:age','20'
更新数据
put 'student','1001','info:name','Zhangsan'
3、查看表数据
扫描表数据
scan 'student'
# 指定开始和结束rowKey
scan 'student',{STARTROW => '1001', STOPROW => '1001'}
scan 'student',{STARTROW => '1001'}
只显示指定的列
scan 'student', {LIMIT => 3, COLUMNS => ['info:name', 'info:age'], FORMATTER => 'toString'}
查看表数据
get '表名','rowkey'# 查看列数据
get 'student','1001'
# 查看列簇中列数据
get 'student','1001','info:name'
查看数据并且显示中文(shell默认十六进制)
get 'student','1001', {FORMATTER => 'toString'}
查看表结构
describe 'student'
查看数据行数(rowKey数量)
count 'student'
4、删除数据
删除某rowkey的某一列数据:
delete 'student','1002','info:sex'
删除某rowKey数据
deleteall 'student','1001'
清空表数据
truncate 'student'
该表为disable状态
disable 'student'
删除表(需先将表置为disable)
drop 'student'
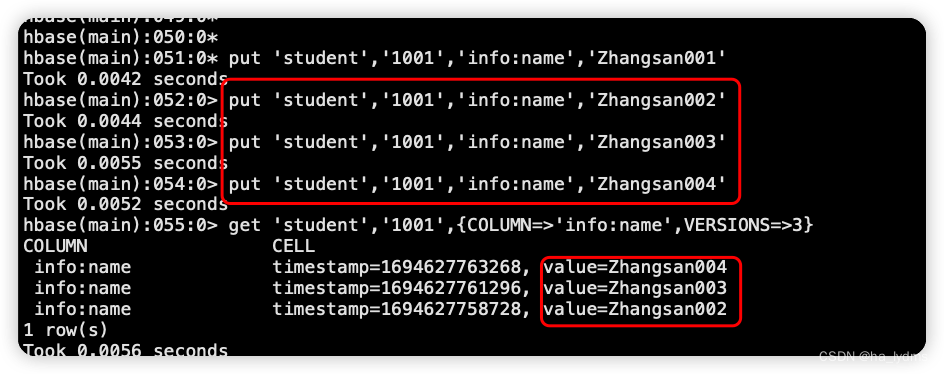
5、修改默认保存的数据版本
修改保存数据版本数量
alter 'student',{NAME=>'info',VERSIONS=>3}
更新4个版本的数据
put 'student','1001','info:name','Zhangsan001'
put 'student','1001','info:name','Zhangsan002'
put 'student','1001','info:name','Zhangsan003'
put 'student','1001','info:name','Zhangsan004'
查看保留的数据版本
get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3}
四、架构
1、RegionServer 架构
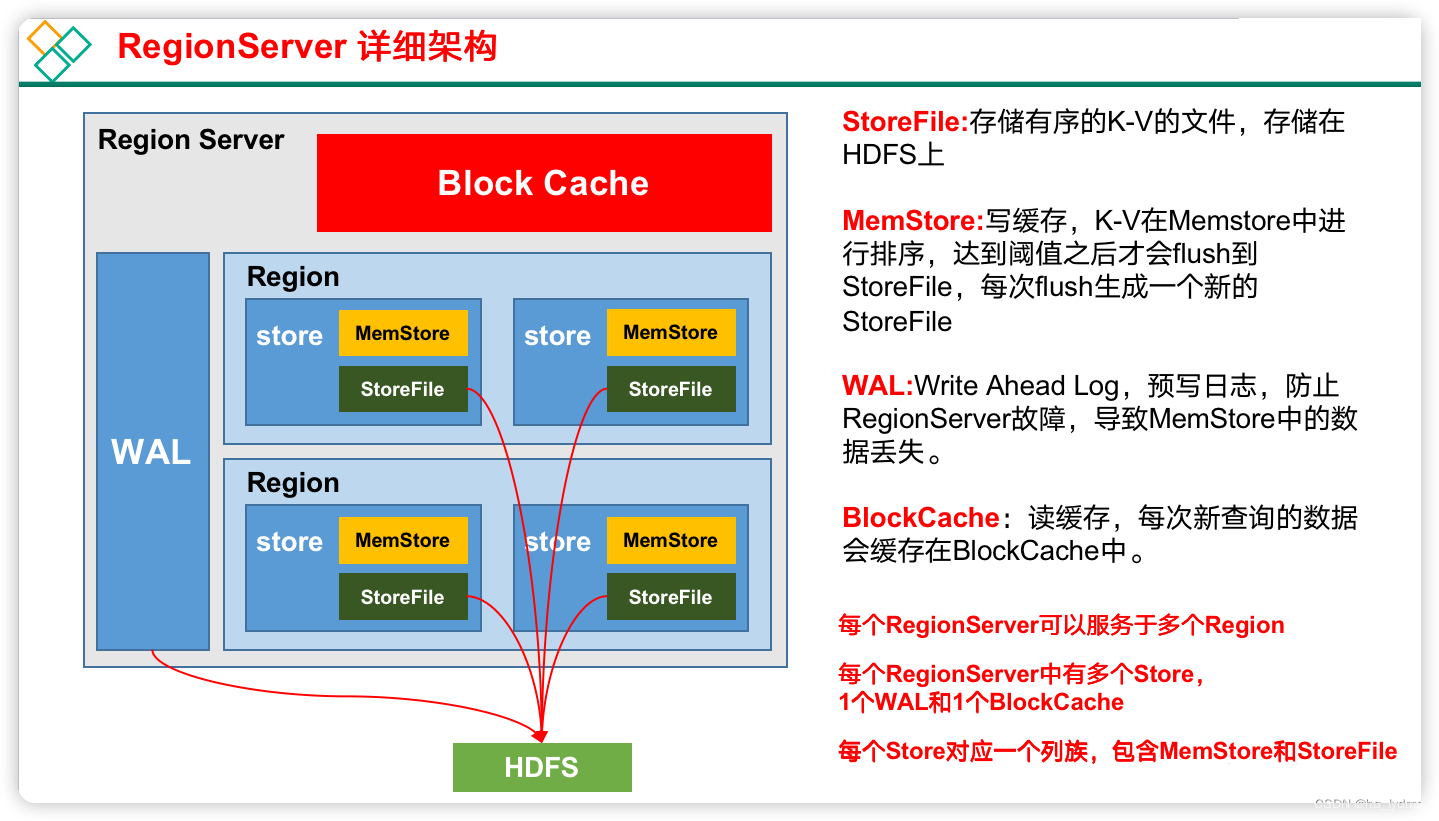
1)StoreFile
保存实际数据的物理文件,StoreFile以Hfile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。
2)MemStore
写缓存,由于HFile中的数据要求是有序的,所以数据是先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。
3)HLog
由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个实现了Write-Ahead logfile机制的文件HLog中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
4)BlockCache
读缓存,每次查询出的数据会缓存在BlockCache中,方便下次查询。
2、写流程
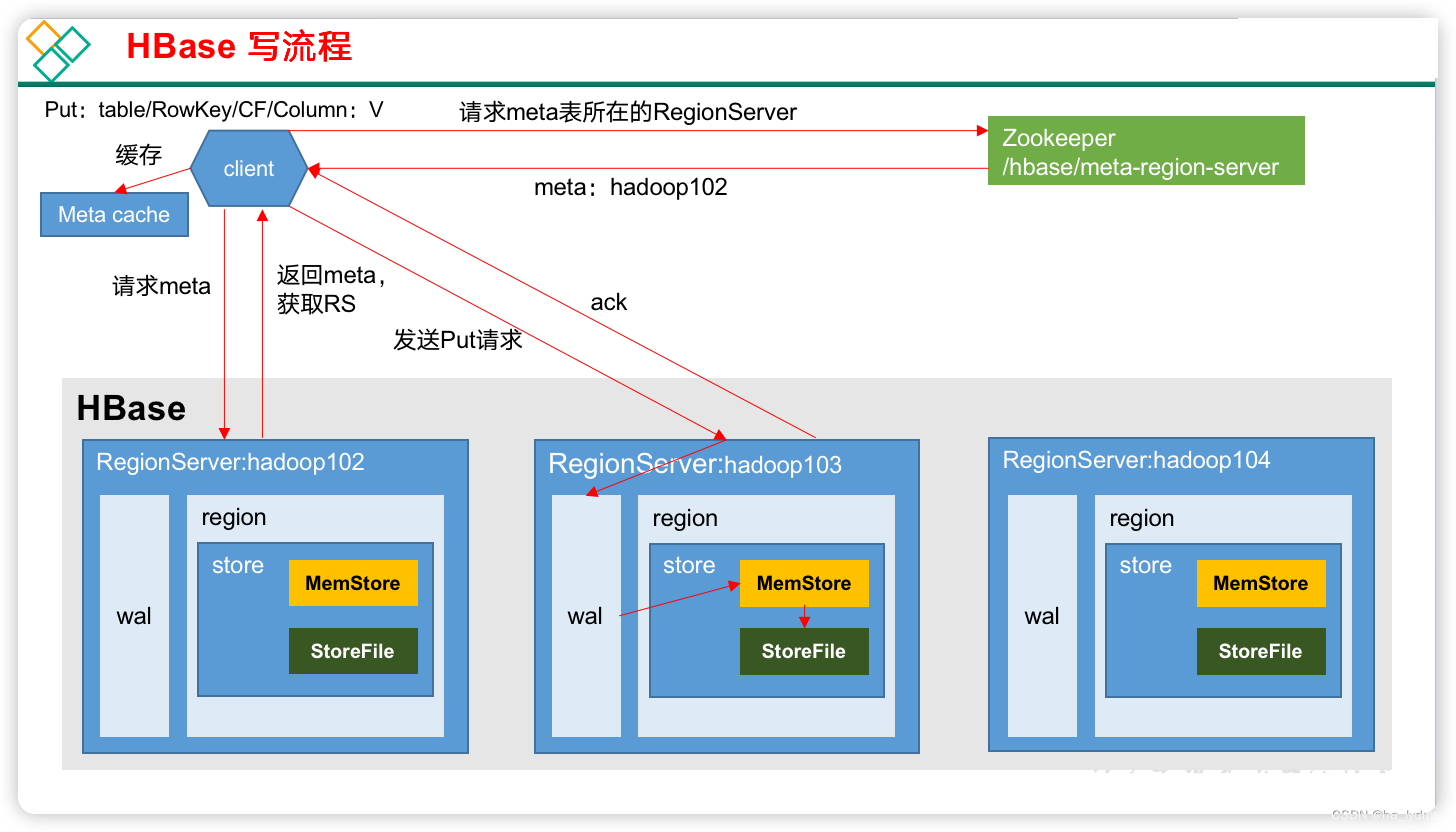
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
2)访问对应的Region Server,获取hbase:meta表,根据写请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标Region Server进行通讯;
4)将数据顺序写入(追加)到HLog;
5)将数据写入对应的MemStore,数据会在MemStore进行排序;
6)向客户端发送ack;
7)等达到MemStore的刷写时机后,将数据刷写到HFile。
3、MemStore Flush
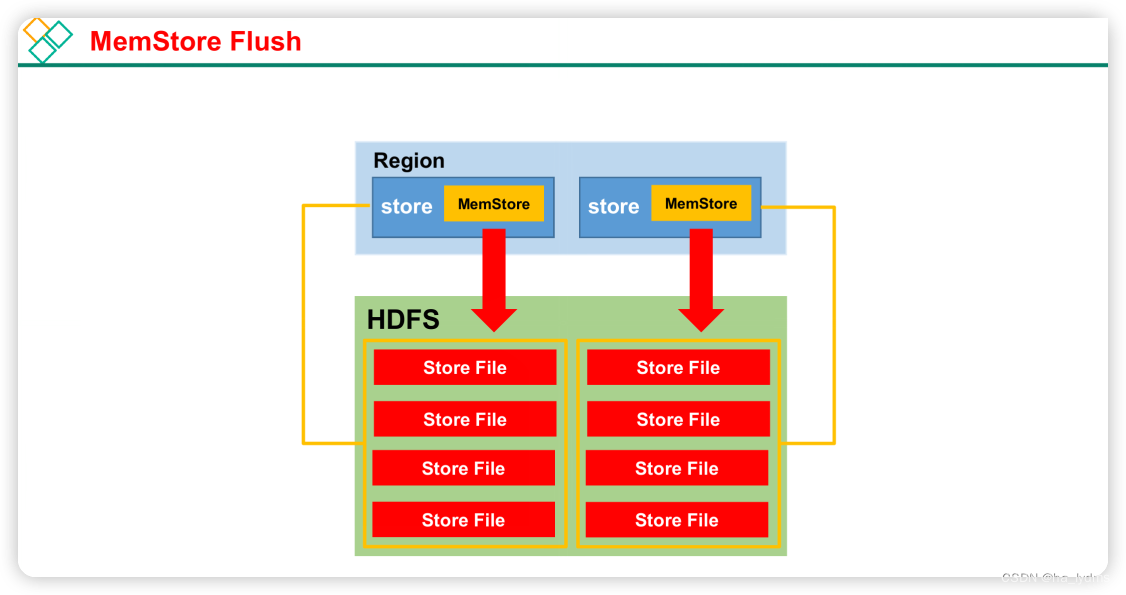
Memstore级别
当某个memstroe的大小达到了hbase.hregion.memstore.flush.size(默认值128M),其所在region的所有memstore都会刷写。因此不建议创建太多的列族。
Region级别
当一个Region中所有的memstore的大小达到了hbase.hregion.memstore.flush.size(默认值128M) * hbase.hregion.memstore.block.multiplier(默认值4)时,会阻止继续往该Region写数据,进行所有Memstore的刷写。
RegionServer级别
一个RegionServer中的阈值大于java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)* hbase.regionserver.global.memstore.size.lower.limit(默认值0.95)。region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下。
当regionserver中memstore的总大小达到java_heapsize * hbase.regionserver.global.memstore.size(默认值0.4)时,会阻止继续往所有的memstore写数据。
HLog数量上限
当WAL文件的数量超过hbase.regionserver.max.logs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.log以下(该属性名已经废弃,现无需手动设置,最大值为32)
定时刷写
到达自动刷写的时间,也会触发memstore flush。自动刷新的时间间隔由该属性进行配置hbase.regionserver.optionalcacheflushinterval(默认1小时)
手动刷写
可以在客户端手动flush 表名 或 region名 或regionserver名
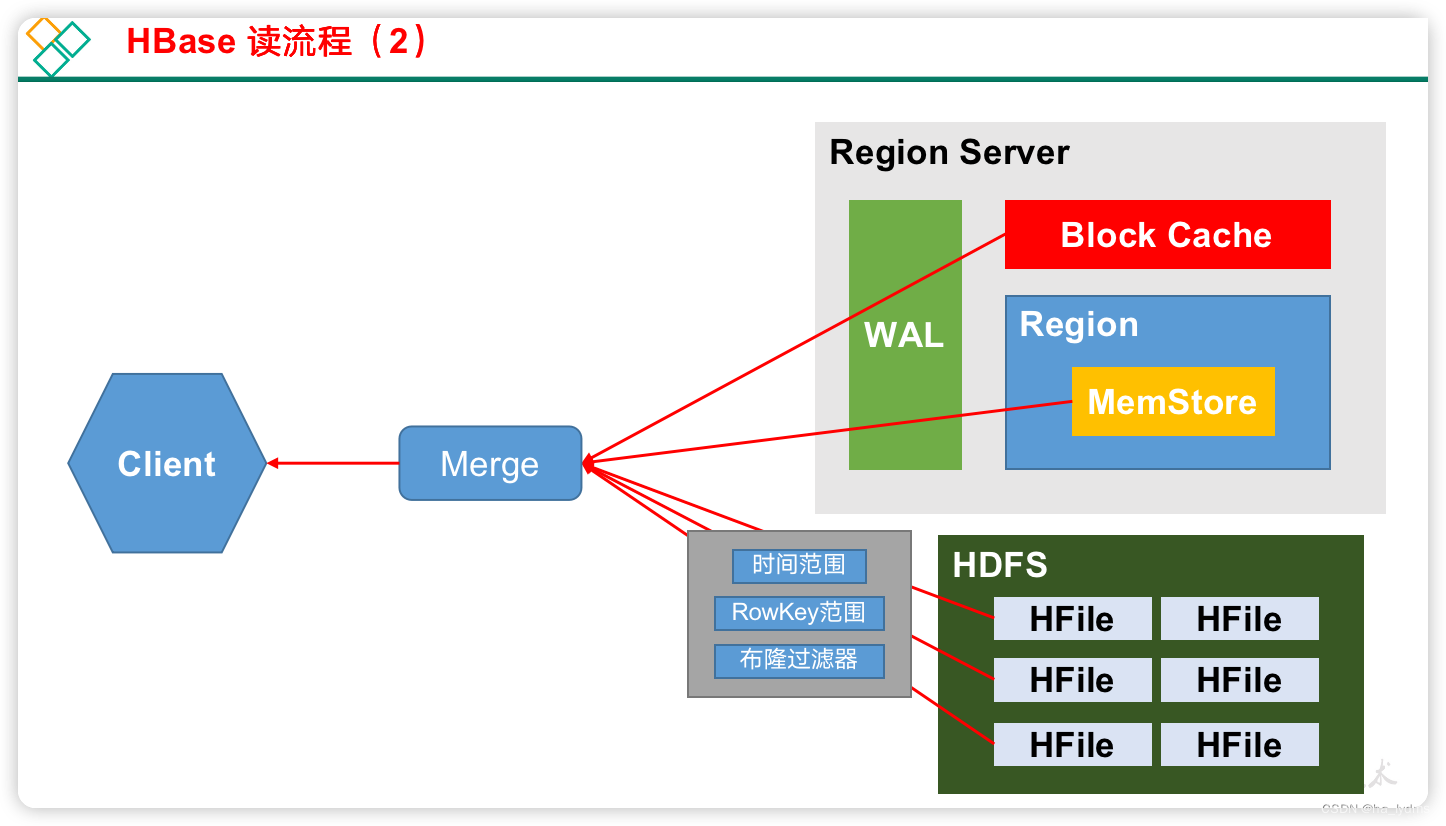
4、读流程
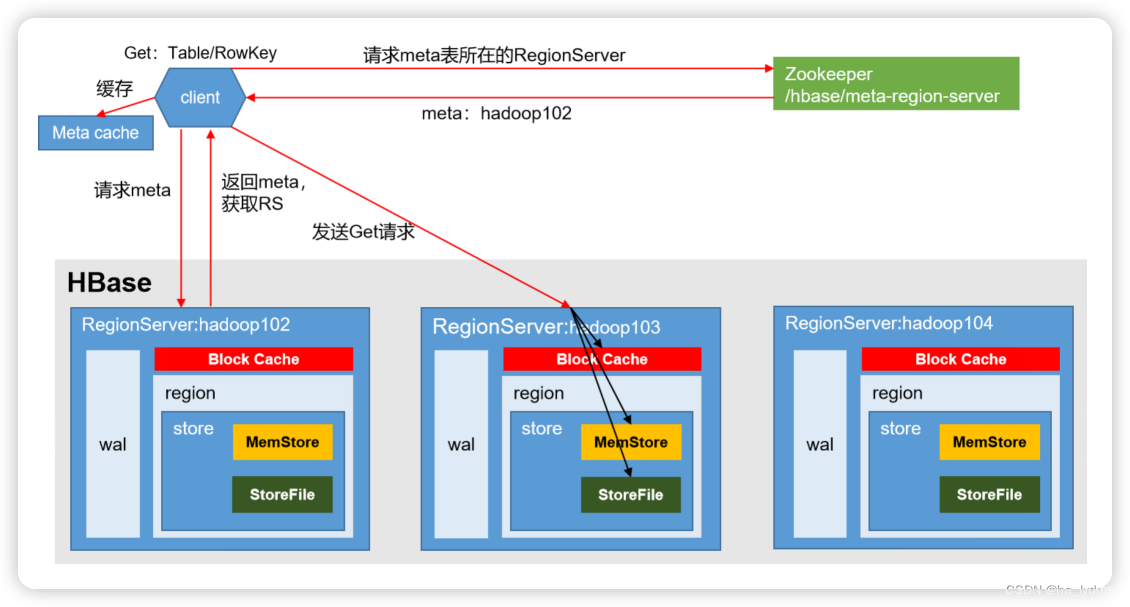
RegionServer返回数据
-
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
-
2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
-
3)向目标Region Server发送读请求;
-
4)分别在MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
-
5)将查询到的新的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache。
-
6)将合并后的最终结果返回给客户端。
5、Region Split(Region切分)
默认情况下,每个Table起初只有一个Region,随着数据的不断写入,Region会自动进行拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。
0.94版本之前的策略
0.94版本之前采取的是 ConstantSizeRegionSplitPolicy , 当一个Store(对应一个列族)的StoreFile大小大于配置hbase.hregion.max.filesize(默认10G)时就会拆分。
0.94版本之后的策略
0.94版本之后的切分策略取决于hbase.regionserver.region.split.policy参数的配置,默认使用IncreasingToUpperBoundRegionSplitPolicy策略切分region。
该策略分为两种情况,第一种为如果在当前RegionServer中某个Table的Region个数介于 0-100之间,那么当1个region中的某个Store下所有StoreFile的总大小超过Min(initialSize*R^3 ,hbase.hregion.max.filesize"),该Region就会进行拆分。其中initialSize的默认值为2*hbase.hregion.memstore.flush.size,R为当前Region Server中属于该Table的Region个数。
具体的切分策略为:
- 第一次split:1^3 * 256 = 256MB
- 第二次split:2^3 * 256 = 2048MB
- 第三次split:3^3 * 256 = 6912MB
- 第四次split:4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
- 后面每次split的size都是10GB了。
第二种为如果当前RegionServer中某个Table的Region个数超过100个,则超过10GB才会切分一次region。
2.0版本之后的策略
Hbase 2.0引入了新的split策略:SteppingSplitPolicy。如果当前RegionSer ver上该表只有一个Region,按照2 * hbase.hregion.memstore.flush.size分裂,否则按照hbase.hregion.max.filesize分裂。

禁止分裂
region的分裂需要消耗一定的性能,因此如果对region已经提前预分区,那么可以设置禁止region自动分裂,即使用DisableSplitPolicy。
五、API
1、获取链接
public Connection getConn() {Connection connection = null;try {connection = ConnectionFactory.createConnection();} catch (IOException e) {e.printStackTrace();}return connection;
}
2、获取Table对象
/*** 1、获取表对象*/
@Test
public void getTable() throws IOException {Connection conn = new HbaseUtils().getConn();String tableName = "student";if (StringUtils.isBlank(tableName)) {throw new RuntimeException("表名非法");}Table table = conn.getTable(TableName.valueOf(tableName));
}
3、Put
/*** 2、新增行数据** @throws IOException*/
@Test
public void testPUt() throws IOException {Connection conn = new HbaseUtils().getConn();String tableName = "student";Table table = conn.getTable(TableName.valueOf(tableName));ArrayList<Put> puts = new ArrayList<>();puts.add(createPut("a3", "info", "name", "jack"));puts.add(createPut("a3", "info", "age", "20"));puts.add(createPut("a3", "info", "gender", "male"));table.put(puts);table.close();
}
public Put createPut(String rowkey, String cf, String cq, String value) {Put put = new Put(Bytes.toBytes(rowkey));return put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cq), Bytes.toBytes(value));
}

4、Get
/*** 3、get获取值** @throws IOException*/
@Test
public void getTables() throws IOException {Connection conn = new HbaseUtils().getConn();TableName tableName = TableName.valueOf("student");Table table = conn.getTable(tableName);Get get = new Get(Bytes.toBytes("a3"));Result result = table.get(get);// 打印结果parseResult(result);table.close();
}
/*** 遍历Get的一行结果* 一行由若干列组成,每个列都有若干个cell*/
public void parseResult(Result result) {//获取一行中最原始的cellCell[] cells = result.rawCells();//遍历for (Cell cell : cells) {System.out.print(" rowkey:" + Bytes.toString(CellUtil.cloneRow(cell)));System.out.print(" 列名" + Bytes.toString(CellUtil.cloneFamily(cell)) + ":" + Bytes.toString(CellUtil.cloneQualifier(cell)));System.out.print(" 值:" + Bytes.toString(CellUtil.cloneValue(cell)));System.out.println();}
}
5、Scan
/*** 4、Scan查询数据** @throws IOException*/
@Test
public void testScan() throws IOException {// 创建表对象Connection conn = new HbaseUtils().getConn();TableName tableName = TableName.valueOf("student");Table table = conn.getTable(tableName);// 封装查询条件Scan scan = new Scan();scan.withStartRow(Bytes.toBytes("a1"));scan.withStopRow(Bytes.toBytes("z1"));ResultScanner scanner = table.getScanner(scan);// 返回结果处理for (Result result : scanner) {parseResult(result);}table.close();
}

6、Delete删除
/*** 4、删除数据** @throws IOException*/
@Test
public void testDelete() throws IOException {Connection conn = new HbaseUtils().getConn();Table table = conn.getTable(TableName.valueOf("student"));Delete delete = new Delete(Bytes.toBytes("a3"));// 删一列的最新版本 向指定的列添加一个cell (type = Delete, ts = 最新的cell的ts)delete.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));// 删除这列的所有版本 向指定的列添加一个cell (type = DeleteColumn, ts = 当前时间)delete.addColumns(Bytes.toBytes("f1"), Bytes.toBytes("age"));// 删除列族的所有版本 向指定的行添加一个cell f1:,timestamp = 当前时间, type = DeleteFamilydelete.addFamily(Bytes.toBytes("f1"));// 删除一行的所有列族table.delete(delete);table.close();
}
7、完整代码
建表语句
create 'student','info'
代码测试类
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.jupiter.api.Test;import java.io.IOException;
import java.util.ArrayList;class HbaseUtilsTest {/*** 1、获取表对象*/@Testpublic void getTable() throws IOException {Connection conn = new HbaseUtils().getConn();String tableName = "student";if (StringUtils.isBlank(tableName)) {throw new RuntimeException("表名非法");}Table table = conn.getTable(TableName.valueOf(tableName));}/*** 2、新增行数据** @throws IOException*/@Testpublic void testPUt() throws IOException {Connection conn = new HbaseUtils().getConn();String tableName = "student";Table table = conn.getTable(TableName.valueOf(tableName));ArrayList<Put> puts = new ArrayList<>();puts.add(createPut("a3", "info", "name", "jack"));puts.add(createPut("a3", "info", "age", "20"));puts.add(createPut("a3", "info", "gender", "male"));table.put(puts);table.close();}public Put createPut(String rowkey, String cf, String cq, String value) {Put put = new Put(Bytes.toBytes(rowkey));return put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cq), Bytes.toBytes(value));}/*** 3、get获取值** @throws IOException*/@Testpublic void getTables() throws IOException {Connection conn = new HbaseUtils().getConn();TableName tableName = TableName.valueOf("student");Table table = conn.getTable(tableName);Get get = new Get(Bytes.toBytes("a3"));Result result = table.get(get);// 打印结果parseResult(result);table.close();}/*** 遍历Get的一行结果* 一行由若干列组成,每个列都有若干个cell*/public void parseResult(Result result) {//获取一行中最原始的cellCell[] cells = result.rawCells();//遍历for (Cell cell : cells) {System.out.print(" rowkey:" + Bytes.toString(CellUtil.cloneRow(cell)));System.out.print(" 列名" + Bytes.toString(CellUtil.cloneFamily(cell)) + ":" + Bytes.toString(CellUtil.cloneQualifier(cell)));System.out.print(" 值:" + Bytes.toString(CellUtil.cloneValue(cell)));System.out.println();}}/*** 4、Scan查询数据** @throws IOException*/@Testpublic void testScan() throws IOException {// 创建表对象Connection conn = new HbaseUtils().getConn();TableName tableName = TableName.valueOf("student");Table table = conn.getTable(tableName);// 封装查询条件Scan scan = new Scan();scan.withStartRow(Bytes.toBytes("a1"));scan.withStopRow(Bytes.toBytes("z1"));ResultScanner scanner = table.getScanner(scan);// 返回结果处理for (Result result : scanner) {parseResult(result);}table.close();}/*** 4、删除数据** @throws IOException*/@Testpublic void testDelete() throws IOException {Connection conn = new HbaseUtils().getConn();Table table = conn.getTable(TableName.valueOf("student"));Delete delete = new Delete(Bytes.toBytes("a3"));// 删一列的最新版本 向指定的列添加一个cell (type = Delete, ts = 最新的cell的ts)delete.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));// 删除这列的所有版本 向指定的列添加一个cell (type = DeleteColumn, ts = 当前时间)delete.addColumns(Bytes.toBytes("f1"), Bytes.toBytes("age"));// 删除列族的所有版本 向指定的行添加一个cell f1:,timestamp = 当前时间, type = DeleteFamilydelete.addFamily(Bytes.toBytes("f1"));// 删除一行的所有列族table.delete(delete);table.close();}}
HbaseUtils工具类
package com.lydms.demohbase.utils;import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;import java.io.IOException;public class HbaseUtils {public Connection getConn() {Connection connection = null;try {connection = ConnectionFactory.createConnection();} catch (IOException e) {e.printStackTrace();}return connection;}public void closeConn(Connection connection) throws IOException {if (connection != null) {connection.close();}}}
Resource目录下创建hbase-site.xml文件
<configuration><property><name>hbase.zookeeper.quorum</name><value>hadoop101,hadoop102,hadoop103</value></property>
</configuration>
pom文件
<!-- Hbase-->
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>2.0.5</version><exclusions><exclusion><groupId>org.glassfish</groupId><artifactId>javax.el</artifactId></exclusion></exclusions>
</dependency>
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.0.5</version>
</dependency>
<dependency><groupId>org.glassfish</groupId><artifactId>javax.el</artifactId><version>3.0.1-b06</version>
</dependency>
六、HBase使用设计
1、预分区
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能。
- 手动设定分区
create 'staff1','info', SPLITS => ['1000','2000','3000','4000']
- 生成16进制序列预分区
create 'staff2','info',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
- 按照文件中设置的规则预分区
新建文件splits.txt
aaaa
bbbb
cccc
dddd
执行脚本命令
create 'staff3', 'info',SPLITS_FILE => 'splits.txt'
2、RowKey设计
一条数据的唯一标识就是rowkey,那么这条数据存储于哪个分区,取决于rowkey处于哪个region的区间内,设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。接下来我们就谈一谈如何让rowkey足够散列。
- 生成随机数、hash、散列值
原本rowKey为1001的,SHA1后变成:dd01903921ea24941c26a48f2cec24e0bb0e8cc7
原本rowKey为3001的,SHA1后变成:49042c54de64a1e9bf0b33e00245660ef92dc7bd
原本rowKey为5001的,SHA1后变成:7b61dec07e02c188790670af43e717f0f46e8913
- 字符串反转
20170524000001转成10000042507102
20170524000002转成20000042507102
- 字符串拼接
a12e_20170524000001
93i7_20170524000001
3、内存优化
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~36G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
内存优化需要修改HBase家目录conf中的hbase-env.sh文件
#对master和regionserver都有效
export HBASE_HEAPSIZE=1G#只对master有效
export HBASE_MASTER_OPTS=自定义的jvm虚拟机参数#只对regionserver有效
export HBASE_REGIONSERVER_OPTS=自定义的jvm虚拟机参数
4、基础优化
1) RPC监听数量
hbase-site.xml
属性:hbase.regionserver.handler.count
解释:默认值为30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
2)手动控制Major Compaction
hbase-site.xml
属性:hbase.hregion.majorcompaction解释:默认值:604800000秒(7天), Major Compaction的周期,若关闭自动Major Compaction,可将其设为0
3)优化HStore文件大小
hbase-site.xml
属性:hbase.hregion.max.filesize解释:默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。
4)优化HBase客户端缓存
hbase-site.xml
属性:hbase.client.write.buffer解释:默认值2097152bytes(2M)用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。
5)指定scan.next扫描HBase所获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching解释:用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。
6)BlockCache占用RegionServer堆内存的比例
hbase-site.xml
属性:hfile.block.cache.size解释:默认0.4,读请求比较多的情况下,可适当调大
7)MemStore占用RegionServer堆内存的比例
hbase-site.xml
属性:hbase.regionserver.global.memstore.size
解释:默认0.4,写请求较多的情况下,可适当调大
相关文章:
一篇文章完成Hbase入门
文章目录 一、简介1、数据模型结构2、物理存储结构3、数据模型4、基本架构 二、安装1、下载解压安装包2、修改配置文件3、启动服务(单机、集群)4、配置高可用(HA) 三、命令行操作1、建表2、新增/更新数据3、查看表数据4、删除数据5、修改默认保存的数据版本 四、架构1、RegionS…...
使用PotPlayer播放器查看软解和硬解4K高清视频时的CPU及GPU占用情况
目录 1、问题说明 2、PotPlayer播放器介绍 3、视频的软解与硬解 4、使用PotPlayer查看4K高清视频软解和硬解时的CPU占用情况 4.1、使用软解时CPU和GPU占用情况 4.2、使用硬解时CPU和GPU占用情况 5、最后 VC常用功能开发汇总(专栏文章列表,欢迎订阅…...
怎么做excel表格的二维码?文件快速做二维码的教程
Excel表格怎么做成二维码来扫码插看呢?Excel是工作中常用的一种文件格式,想要将表格内容分享给其他人查看,那么将表格生成二维码的方法会更加的方便快捷,其他人只需要扫描二维码就可以查看或者下载文件。表格excel二维码可以通过文…...

Clion取消double shift(按两下shift键)全局搜索
Clion 取消 double shift(按两下 shift 键)全局搜索。 如下图所示打开 setting。 点击 advanced setting,搜索 disable,取消勾选左侧复选框,点击 ok。...
Spring RabbitMQ那些事(2-两种方式实现延时消息订阅)
目录 一、序言二、死信交换机和消息TTL实现延迟消息1、死信队列介绍2、代码示例(1) 死信交换机配置(2) 消息生产者(3) 消息消费者 3、测试用例 三、延迟消息交换机实现延迟消息1、安装延时消息插件2、代码示例(1) 延时消息交换机配置(2) 消息生产者(3) 消息消费者 3、测试用例 …...
免费SSL证书有效期只有90天?太短?
随着网络安全问题日益受到重视,SSL证书成为了网站安全的必需品。然而,在许多情况下,免费提供的SSL证书往往只有90天的有效期,这种期限对于很多用户来说显得过于短暂。 首先,我们要理解为什么 SSL 证书的有效期设定为90…...
Java小游戏 王者荣耀
GameFrame类 所需图片: package 王者荣耀;import java.awt.*; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.awt.event.KeyAdapter; import java.awt.event.KeyEvent; import java.io.File; import java.util.ArrayLis…...

Python:diskcache实现基于文件的数据缓存
diskcache是一个基于Sqlite文件的数据缓存 文档 https://grantjenks.com/docs/diskcache/https://github.com/grantjenks/python-diskcachehttps://pypi.org/project/diskcache/ 示例 from diskcache import Cache# 指定文件夹 cache Cache(./cache)# 存 cache.set(name, …...
)
微信小程序 - 一篇带你解读小程序强制更新(冷/热启动)
在小程序开发中,我们会不可避免的涉及到小程序新版本迭代的问题,因为小程序的更新机制是异步的,新版本发布后并不会立刻应用到所有的现有用户,部分用户用的可能还是原来的旧版本,但如果是急需修复的 bug 或其他急需上线…...
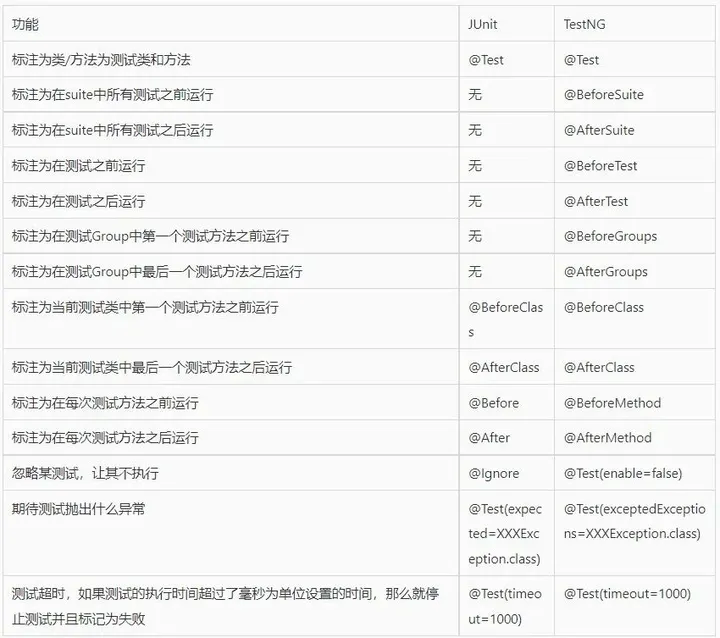
关于接口测试自动化的总结与思考!
序 近期看到阿里云性能测试 PTS 接口测试开启免费公测,本着以和大家交流如何实现高效的接口测试为出发点,本文包含了我在接口测试领域的一些方法和心得,希望大家一起讨论和分享,内容包括但不仅限于: 服务端接口测试介…...
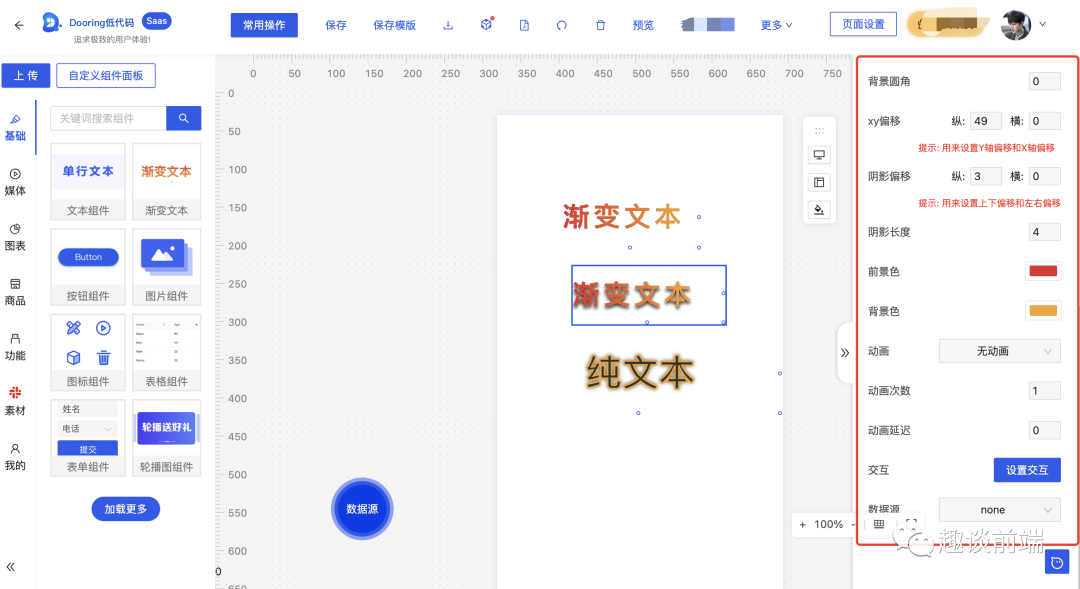
如何用低代码的思路设计文字描边渐变组件
前言 文字特效设计一直是困扰 Web 前端 Css 世界多年的问题, 比如如何用纯 Css 实现文字描边, 渐变, 阴影等, 由于受限于浏览器兼容性的问题, 我们不得不使用其他替代方案来实现. 平时工作中我们使用 PS 等设计工具能很容易的实现文字渐变等特效, 但是随着可视化技术的成熟, 我…...

Linux 网络通信
(一)套接字Socket概念 Socket 中文意思是“插座”,在 Linux 环境下,用于表示进程 x 间网络通信的特殊文件 类型。本质为内核借助缓冲区形成的伪文件。 既然是文件,那么理所当然的,我们可以使用文件描述符引用套接字。Linux 系统…...
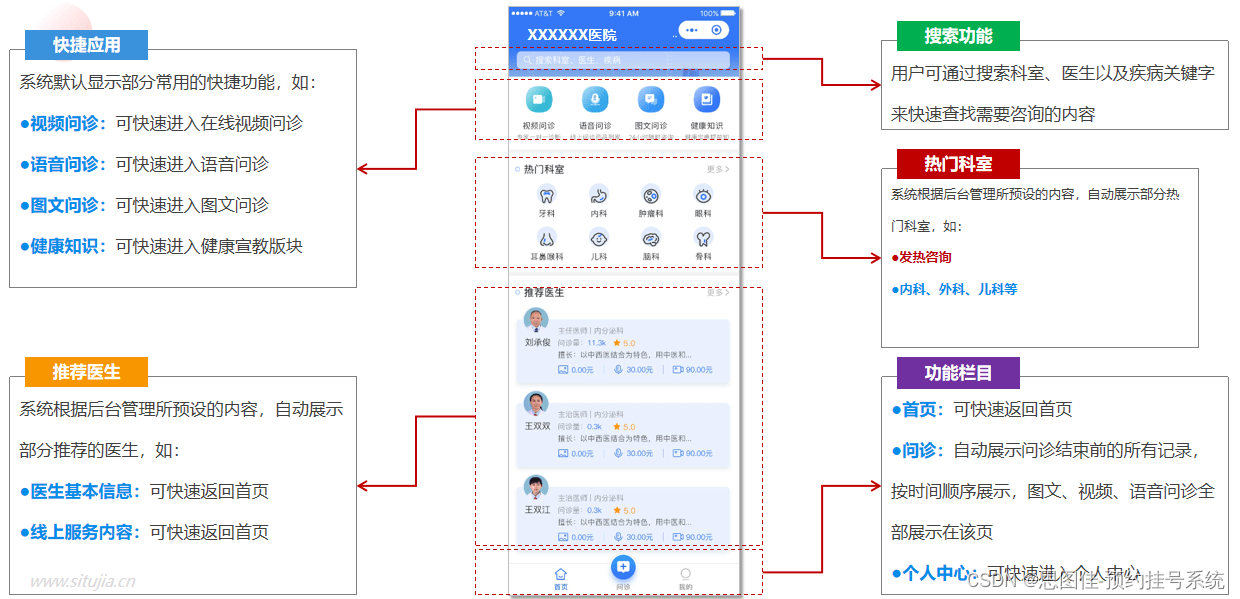
借力互联网,民营医院探索互联网医疗服务的发展方向
民营医院互联网医疗服务是指利用互联网技术和平台,为患者提供更加便捷、高效的医疗服务。在当前数字化时代,互联网医疗服务正逐渐成为医疗行业的新趋势,也为民营医院开拓了更广阔的发展空间。下面将围绕这一主题进行讨论: 首先&a…...
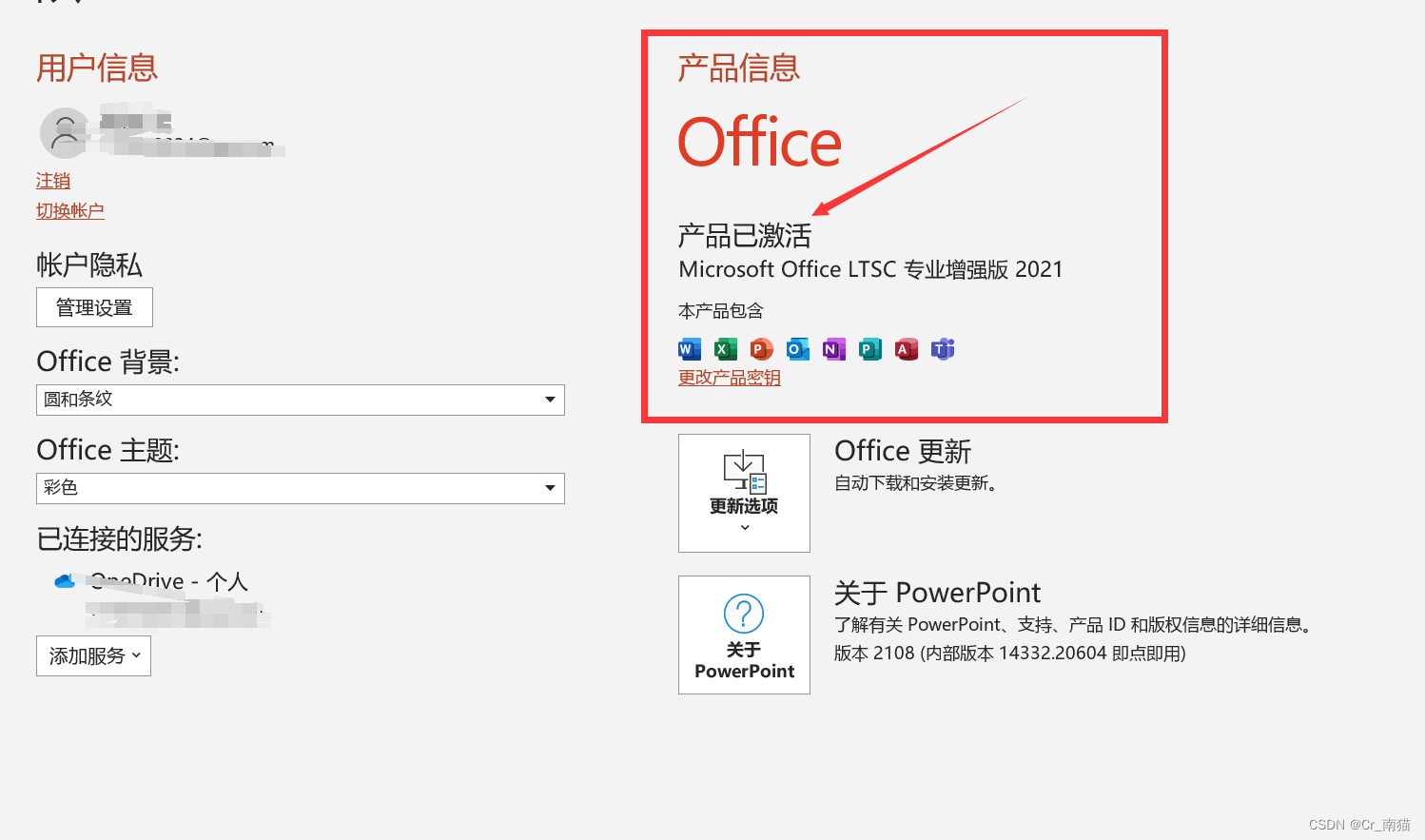
office tool plus工具破解word、visio等软件步骤
第一步:下载工具 破解需要用到office tool plus软件 office tool plus软件下载地址:Office Tool Plus 官方网站 - 一键部署 Office 选择其中一个下载到本地(本人选择的是第一个的云图小镇下载方式) 第二步:启动工具 …...

python之pyqt专栏5-信号与槽1
在上一篇文章,我们了解到如果想要用代码改变QLabel的文本内容,可以调用QLabel类的text()函数。 但是现在有个这样的需求,界面中有一个Button与一个Label,当点击Button时,将Label的内容改变为“Hello world!…...
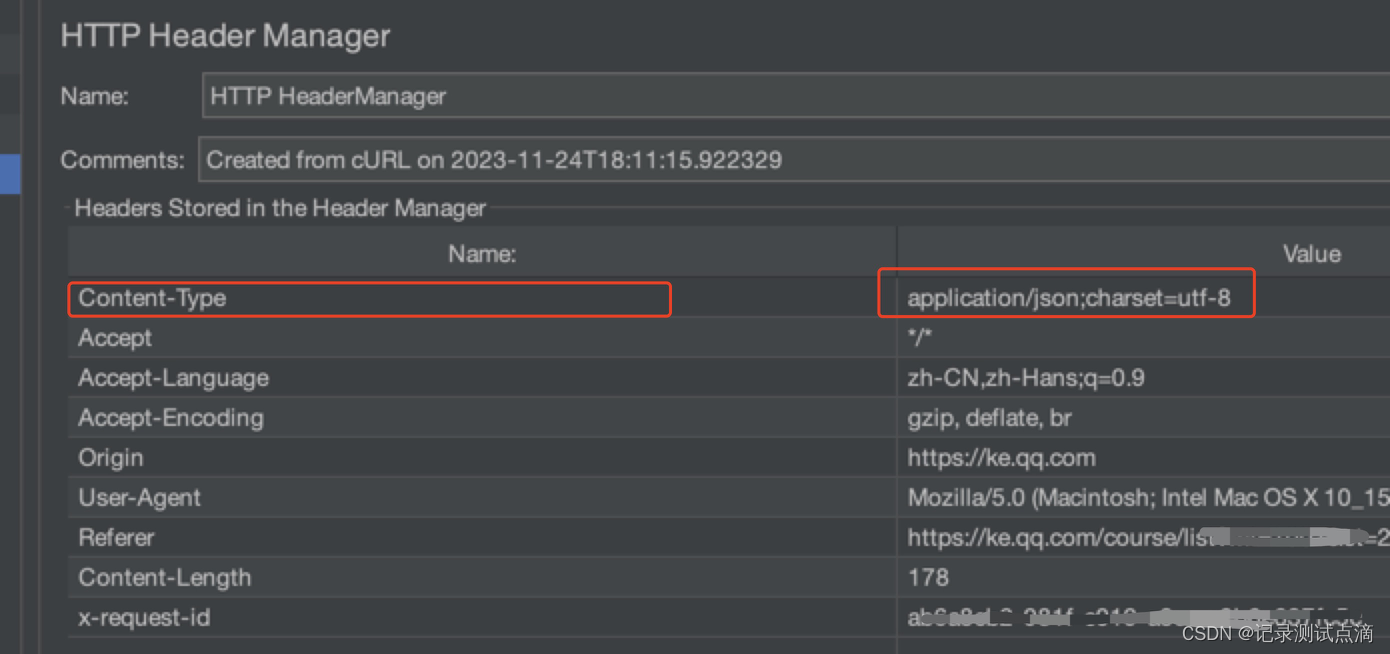
【JMeter】不同场景下的接口请求
场景1: 上传文件接口即Content-Type=multipart/form-data 步骤: 1. 接口url,method以及path正常填写 2.文件上传content-type是multipart/form-data,所以可以勾选【use multipart/form-data】,如果还有其他请求头信息可以添加一个请求头元件 3.请求参…...

十八数字文化受邀参加版博会“区块链+版权”创新应用试点研讨会
2023年11月23日至25日,以“版权新时代 赋能新发展”为主题的第九届中国国际版权博览会在成都市中国西部国际博览城和天府国际会议中心举办。版博会是我国版权领域唯一的综合性、国际性、国家级版权专业博览会,本届版博会由国家版权局主办,四川…...
 NodeJS 16 和 Vue)
Centos 7 离线安装(tar) NodeJS 16 和 Vue
目录 一、下载Nodejs二、安装Nodejs2.1、创建安装目录2.2、上传安装包(无网络) or 直接下载(有网络)2.3、解压缩2.4、配置环境变量2.5、创建软连接2.6、更换镜像源2.7、验证是否安装成功 三、安装Vue四、卸载Nodejs 一、下载Nodejs Nodejs:https://nodejs.org/en/ …...
卸载软件最最最彻底的工具——Uninstall Tool
卸载软件最最最彻底的工具——Uninstall Tool Uninstall Tool 是一款功能强大的专业卸载工具。针对一些普通卸载不彻底的问题,它可以做到最优,比如Matlab等软件的卸载难的问题也可以较好地解决。 它比 Windows 自带的“添加/删除程序”功能快 3 倍&…...

2022年MathorCup大数据竞赛B题北京移动用户体验影响因素研究求解全过程文档及程序
2022年MathorCup高校数学建模挑战赛—大数据竞赛 B题 北京移动用户体验影响因素研究 原题再现: 移动通信技术飞速发展,给人们带来了极大便利,人们也越来越离不开移动通信技术带来的各种便捷。随着网络不断的建设,网络覆盖越来越…...

Linux Kernel Debugging专栏概览
专栏介绍 Linux Kernel Debugging专栏,正如其名,这是一个讲解Linux内核调试技术的专栏,从最基础的调试技术一直到高级调试技术,都会讲到,而且,我相信,这不仅对于学习内核知识有极大的帮助&…...

Cursor无限制使用解决方案:cursor-free-vip完全指南
Cursor无限制使用解决方案:cursor-free-vip完全指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...

如何用Diablo Edit2打造暗黑破坏神II完美角色:全版本角色编辑器使用指南
如何用Diablo Edit2打造暗黑破坏神II完美角色:全版本角色编辑器使用指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit Diablo Edit2是一款功能强大的暗黑破坏神II角色存档编辑器&…...

告别C盘空间焦虑:手把手教你将MySQL和PATSTAT专利库完整部署到移动硬盘
告别C盘空间焦虑:手把手教你将MySQL和PATSTAT专利库完整部署到移动硬盘 当你的研究项目需要处理数百GB的专利数据,而笔记本电脑的C盘只剩下可怜的几GB空间时,那种焦虑感堪比论文截止日期前夜的打印机卡纸。PATSTAT这样的专利数据库就像知识宝…...

若依3.8.6项目里,@RateLimiter注解报‘服务器限流异常’?别慌,手把手教你修复这个Redis坑
若依3.8.6项目中RateLimiter注解的Redis限流异常深度解析与修复实战 当你正在使用若依框架开发一个需要接口限流的功能时,突然在测试环境遇到RateLimiter注解抛出"服务器限流异常"的错误,而Redis服务明明运行正常——这种看似矛盾的场景往往让…...

复古设备新生:树莓派运行OpenClaw轻量版+Phi-3-vision服务
复古设备新生:树莓派运行OpenClaw轻量版Phi-3-vision服务 1. 为什么要在树莓派上折腾OpenClaw? 去年收拾书房时,我在抽屉深处发现了吃灰多年的树莓派4B。这块曾经风靡极客圈的小板子,如今性能早已被现代硬件碾压。但当我看到Ope…...

【算法三十八】200. 岛屿数量
200. 岛屿数量 DFS: class Solution {public int numIslands(char[][] grid) {int ans 0;for(int i 0;i<grid.length;i){for(int j 0;j<grid[0].length;j){if(grid[i][j]1){dfs(grid,i,j);ans;}}}return ans;}private void dfs(char[][] grid,int i,int …...

C语言编程手机版 随时编译代码
社会持续向前发展,当下那些在进行编程学习的用户数量日益增多,然而借助电脑去学习会相对麻烦些。鉴于此,小编给大伙带来了C语言编译器手机版,它是一款功能表现非常强,操作实施较为简便的C语言编程软件,其主…...

L2-2、构建高效可复用的 AI 指令集 —— Prompt 模板化与结构化输出
1. 为什么需要构建可复用的AI指令集 第一次用ChatGPT时,我像个无头苍蝇一样反复输入相似的指令。早上要数据分析报告,下午要会议纪要,每次都得从头解释需求。直到有次同事发来一个txt文件,里面全是格式统一的提问模板——那一刻我…...

MVT协议深度解析:从Protobuf编码到GISBox实战,看它如何碾压传统栅格瓦片
MVT协议技术内幕:从二进制编码到百万级数据渲染实战 当我们打开手机地图App,双指放大查看小区楼栋轮廓时,很少有人会思考这流畅体验背后的技术革命。传统栅格瓦片就像打印在纸上的地图,放大后必然出现马赛克;而MVT协议…...