JAVA 算法面试总结
1、二分查找
二分查找又叫折半查找,要求待查找的序列有序。每次取中间位置的值与待查关键字比较,如果中间位置
的值比待查关键字大,则在前半部分循环这个查找的过程,如果中间位置的值比待查关键字小,
则在后半部分循环这个查找的过程。直到查找到了为止,否则序列中没有待查的关键字。
示例:
public static int biSearch(int []array,int a){int lo=0;int hi=array.length-1;int mid;while(lo<=hi){mid=(lo+hi)/2;//中间位置if(array[mid]==a){return mid+1;}else if(array[mid]<a){ //向右查找lo=mid+1;}else{ //向左查找hi=mid-1;}}return -1;}
2、冒泡排序算法
(1)比较前后相邻的二个数据,如果前面数据大于后面的数据,就将这二个数据交换。
(2)这样对数组的第 0 个数据到 N-1 个数据进行一次遍历后,最大的一个数据就“沉”到数组第
N-1 个位置。
(3)N=N-1,如果 N 不为 0 就重复前面二步,否则排序完成。
public static void bubbleSort1(int[] a, int n) {int i, j;for (i = 0; i < n; i++) {//表示 n 次排序过程for (j = 1; j < n - i; j++) {if (a[j - 1] > a[j]) {//前面的数字大于后面的数字就交换//交换 a[j-1]和 a[j]int temp;temp = a[j - 1];a[j - 1] = a[j];a[j] = temp;}}}}
3、插入排序算法
通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应的位置并插入。
插入排序非常类似于整扑克牌。在开始摸牌时,左手是空的,牌面朝下放在桌上。接着,一次从
桌上摸起一张牌,并将它插入到左手一把牌中的正确位置上。为了找到这张牌的正确位置,要将
它与手中已有的牌从右到左地进行比较。无论什么时候,左手中的牌都是排好序的。
如果输入数组已经是排好序的话,插入排序出现最佳情况,其运行时间是输入规模的一个线性函
数。如果输入数组是逆序排列的,将出现最坏情况。平均情况与最坏情况一样,其时间代价是(n2)。

public void sort(int arr[]){for (int i = 1; i < arr.length; i++) {//插入的数int insertVal = arr[i];//被插入的位置(准备和前一个数比较)int index = i - 1;//如果插入的数比被插入的数小while (index >= 0 && insertVal < arr[index]) {//将把 arr[index] 向后移动arr[index + 1] = arr[index];//让 index 向前移动index--;}//把插入的数放入合适位置arr[index + 1] = insertVal;}}
4、快速排序算法
快速排序的原理:选择一个关键值作为基准值。比基准值小的都在左边序列(一般是无序的),
比基准值大的都在右边(一般是无序的)。一般选择序列的第一个元素。
一次循环:从后往前比较,用基准值和最后一个值比较,如果比基准值小的交换位置,如果没有
继续比较下一个,直到找到第一个比基准值小的值才交换。找到这个值之后,又从前往后开始比
较,如果有比基准值大的,交换位置,如果没有继续比较下一个,直到找到第一个比基准值大的
值才交换。直到从前往后的比较索引>从后往前比较的索引,结束第一次循环,此时,对于基准值
来说,左右两边就是有序的了
public void sort(int[] a, int low, int high) {int start = low;int end = high;int key = a[low];while (end > start) {//从后往前比较while (end > start && a[end] >= key)//如果没有比关键值小的,比较下一个,直到有比关键值小的交换位置,然后又从前往后比较end--;if (a[end] <= key) {int temp = a[end];a[end] = a[start];a[start] = temp;}//从前往后比较while (end > start && a[start] <= key)//如果没有比关键值大的,比较下一个,直到有比关键值大的交换位置start++;if (a[start] >= key) {int temp = a[start];a[start] = a[end];a[end] = temp;}//此时第一次循环比较结束,关键值的位置已经确定了。左边的值都比关键值小,右边的值都比关键值大,但是两边的顺序还有可能是不一样的,进行下面的递归调用}//递归if (start > low) sort(a, low, start - 1);//左边序列。第一个索引位置到关键值索引-1if (end < high) sort(a, end + 1, high);//右边序列。从关键值索引+1 到最后一个}
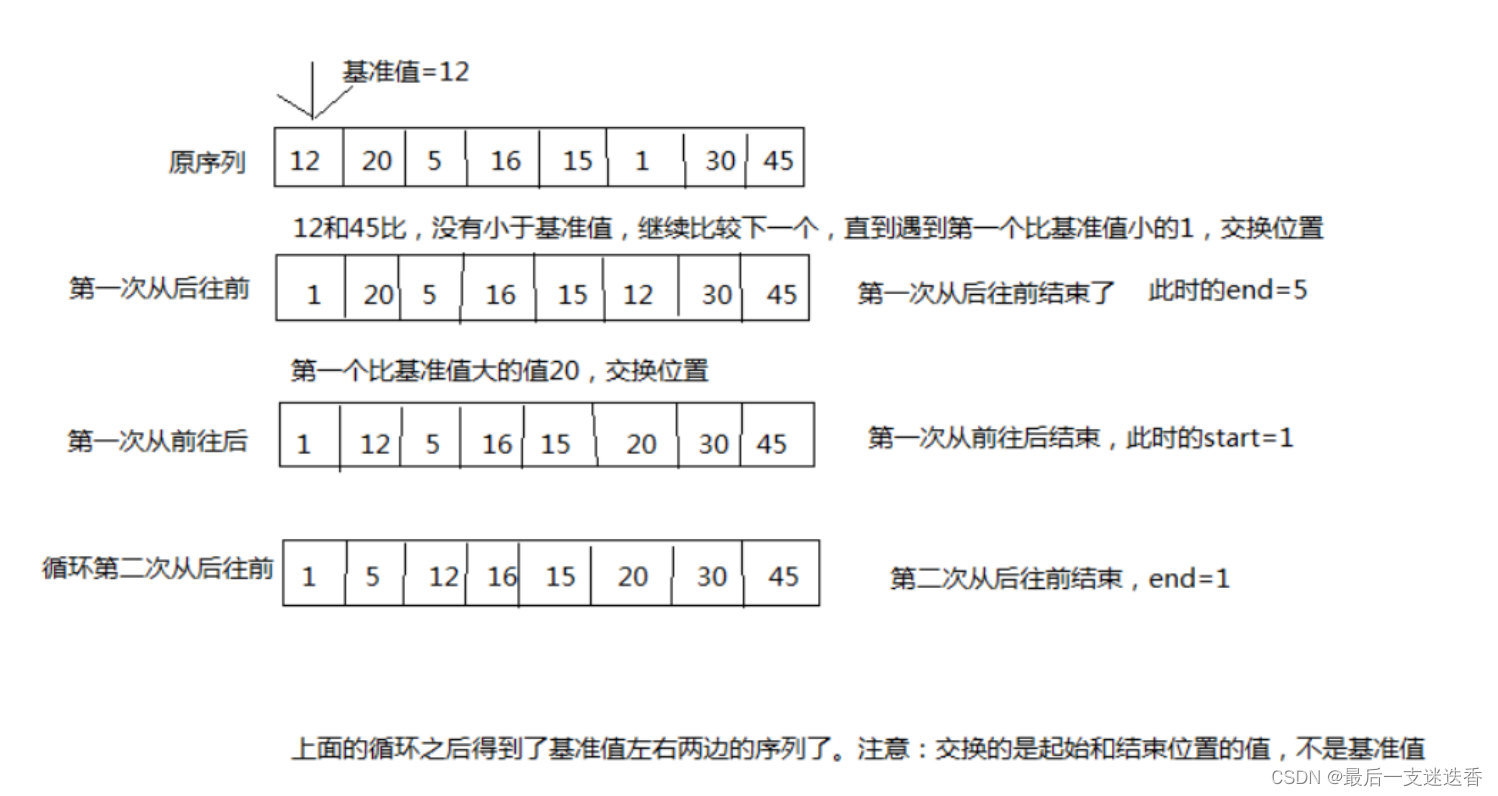
5、希尔排序算法
基本思想:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列
中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
- 操作方法:
选择一个增量序列 t1,t2,…,tk,其中 ti>tj,tk=1; - 按增量序列个数 k,对序列进行 k 趟排序;
- 每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进
行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长
度。
private void shellSort(int[] a) {int dk = a.length / 2;while (dk >= 1) {ShellInsertSort(a, dk);dk = dk / 2;}}private void ShellInsertSort(int[] a, int dk) {
//类似插入排序,只是插入排序增量是 1,这里增量是 dk,把 1 换成 dk 就可以了for (int i = dk; i < a.length; i++) {if (a[i] < a[i - dk]) {int j;int x = a[i];//x 为待插入元素a[i] = a[i - dk];for (j = i - dk; j >= 0 && x < a[j]; j = j - dk) {
//通过循环,逐个后移一位找到要插入的位置。a[j + dk] = a[j];}a[j + dk] = x;//插入}}}
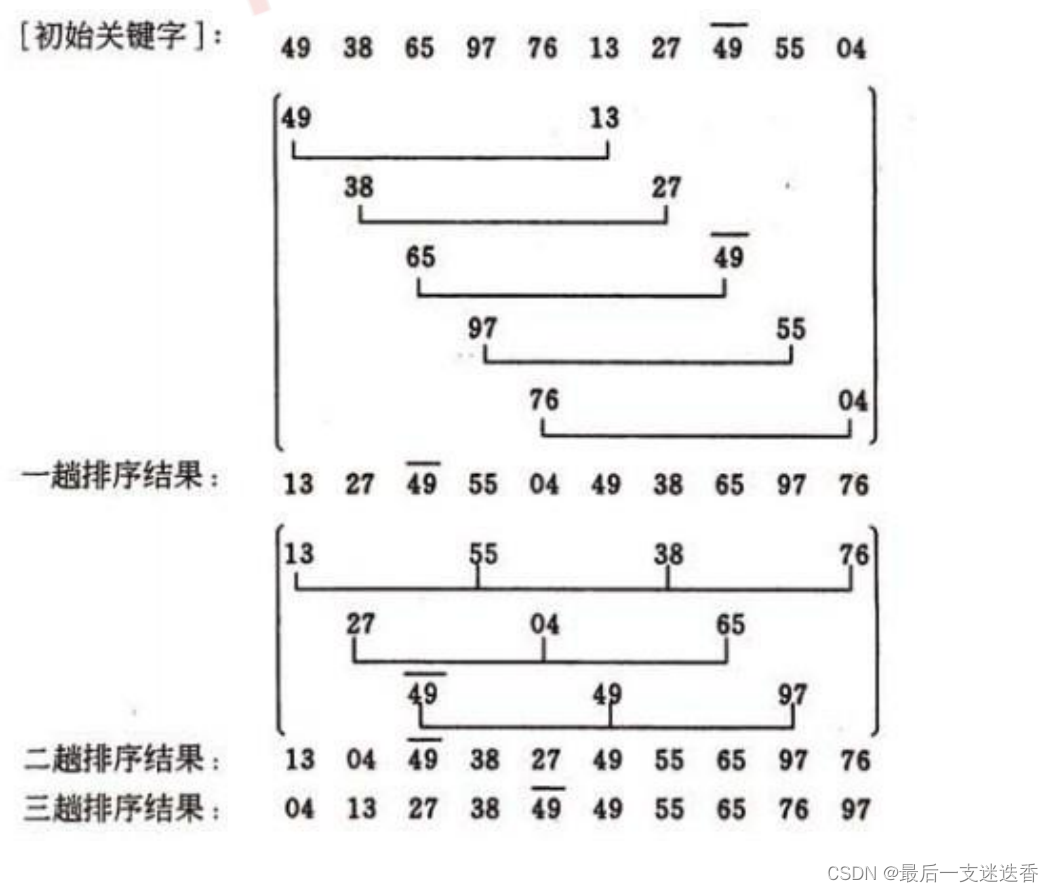
6、归并排序算法
归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列
分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
public static void main(String[] args) {int[] data = new int[]{5, 3, 6, 2, 1, 9, 4, 8, 7};print(data);mergeSort(data);System.out.println("排序后的数组:");print(data);}public static void mergeSort(int[] data) {sort(data, 0, data.length - 1);}public static void sort(int[] data, int left, int right) {if (left >= right)return;// 找出中间索引int center = (left + right) / 2;// 对左边数组进行递归sort(data, left, center);// 对右边数组进行递归sort(data, center + 1, right);// 合并merge(data, left, center, right);print(data);}/*** 将两个数组进行归并,归并前面 2 个数组已有序,归并后依然有序* Page 239 of 283** @param data 数组对象* @param left 左数组的第一个元素的索引* @param center 左数组的最后一个元素的索引,center+1 是右数组第一个元素的索引* @param right 右数组最后一个元素的索引*/public static void merge(int[] data, int left, int center, int right) {// 临时数组int[] tmpArr = new int[data.length];// 右数组第一个元素索引int mid = center + 1;// third 记录临时数组的索引int third = left;// 缓存左数组第一个元素的索引int tmp = left;while (left <= center && mid <= right) {// 从两个数组中取出最小的放入临时数组if (data[left] <= data[mid]) {tmpArr[third++] = data[left++];} else {tmpArr[third++] = data[mid++];}}// 剩余部分依次放入临时数组(实际上两个 while 只会执行其中一个)while (mid <= right) {tmpArr[third++] = data[mid++];}while (left <= center) {tmpArr[third++] = data[left++];}// 将临时数组中的内容拷贝回原数组中// (原 left-right 范围的内容被复制回原数组)while (tmp <= right) {data[tmp] = tmpArr[tmp++];}}public static void print(int[] data) {for (int i = 0; i < data.length; i++) {System.out.print(data[i] + "\t");}System.out.println();}
7、桶排序算法
桶排序的基本思想是: 把数组 arr 划分为 n 个大小相同子区间(桶),每个子区间各自排序,最
后合并 。计数排序是桶排序的一种特殊情况,可以把计数排序当成每个桶里只有一个元素的情况。
1.找出待排序数组中的最大值 max、最小值 min
2.我们使用 动态数组 ArrayList 作为桶,桶里放的元素也用 ArrayList 存储。桶的数量为(maxmin)/arr.length+1
3.遍历数组 arr,计算每个元素 arr[i] 放的桶
4.每个桶各自排序
public static void bucketSort(int[] arr) {int max = Integer.MIN_VALUE;int min = Integer.MAX_VALUE;for (int i = 0; i < arr.length; i++) {max = Math.max(max, arr[i]);min = Math.min(min, arr[i]);}//创建桶int bucketNum = (max - min) / arr.length + 1;ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNum);for (int i = 0; i < bucketNum; i++) {bucketArr.add(new ArrayList<Integer>());}//将每个元素放入桶for (int i = 0; i < arr.length; i++) {int num = (arr[i] - min) / (arr.length);bucketArr.get(num).add(arr[i]);}for (int i = 0; i < bucketArr.size(); i++) {Collections.sort(bucketArr.get(i));}}
8、基数排序算法
将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位
开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
public class radixSort {int a[] = {49, 38, 65, 97, 76, 13, 27, 49, 78, 34, 12, 64, 5, 4, 62, 99, 98, 54, 101, 56, 17, 18, 23, 34, 15, 35, 25, 53, 51};public radixSort() {sort(a);for (int i = 0; i < a.length; i++) {System.out.println(a[i]);}}public void sort(int[] array) {//首先确定排序的趟数;int max = array[0];for (int i = 1; i < array.length; i++) {if (array[i] > max) {max = array[i];}}int time = 0;//判断位数;while (max > 0) {max /= 10;time++;}//建立 10 个队列;List<ArrayList> queue = new ArrayList<ArrayList>();for (int i = 0; i < 10; i++) {ArrayList<Integer> queue1 = new ArrayList<Integer>();queue.add(queue1);}//进行 time 次分配和收集;for (int i = 0; i < time; i++) {//分配数组元素;for (int j = 0; j < array.length; j++) {//得到数字的第 time+1 位数;int x = array[j] % (int) Math.pow(10, i + 1) / (int) Math.pow(10, i);ArrayList<Integer> queue2 = queue.get(x);queue2.add(array[j]);queue.set(x, queue2);}int count = 0;//元素计数器;//收集队列元素;for (int k = 0; k < 10; k++) {while (queue.get(k).size() > 0) {ArrayList<Integer> queue3 = queue.get(k);array[count] = queue3.get(0);queue3.remove(0);count++;}}}}}
9、剪枝算法
在搜索算法中优化中,剪枝,就是通过某种判断,避免一些不必要的遍历过程,形象的说,就是
剪去了搜索树中的某些“枝条”,故称剪枝。应用剪枝优化的核心问题是设计剪枝判断方法,即
确定哪些枝条应当舍弃,哪些枝条应当保留的方法
10、回溯算法
回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现
已不满足求解条件时,就“回溯”返回,尝试别的路径。
11、最短路径算法
从某顶点出发,沿图的边到达另一顶点所经过的路径中,各边上权值之和最小的一条路径叫做最
短路径。解决最短路的问题有以下算法,Dijkstra 算法,Bellman-Ford 算法,Floyd 算法和 SPFA
算法等。
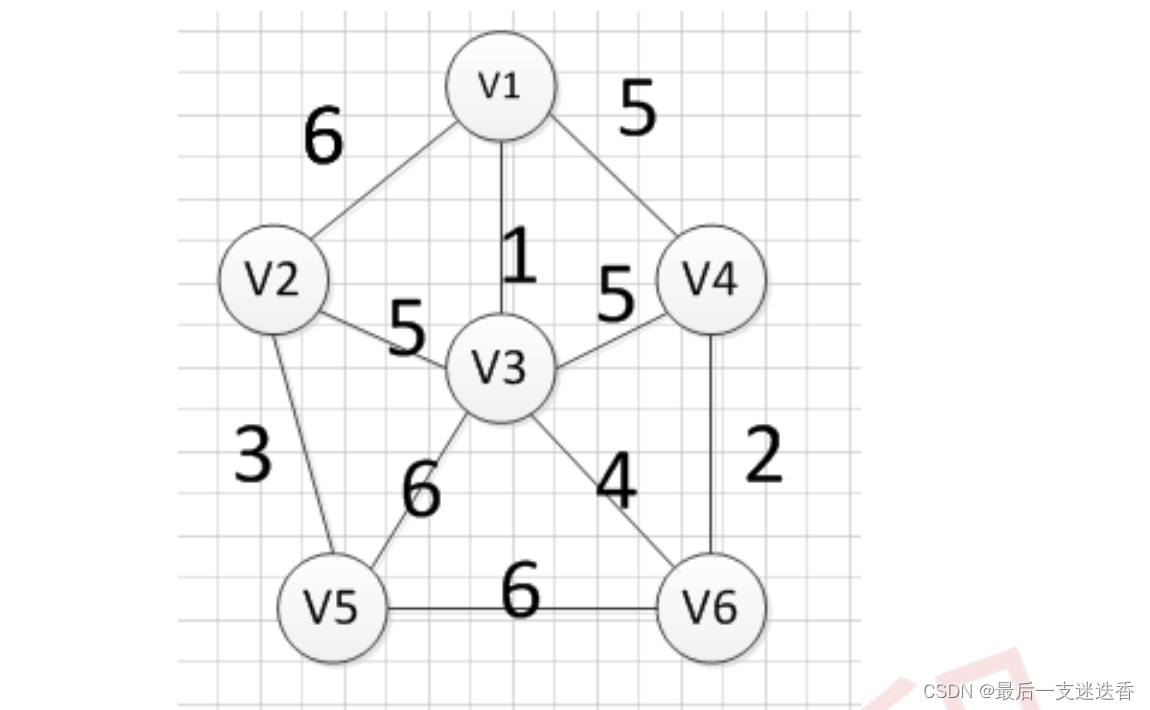
12、最小生成树算法
现在假设有一个很实际的问题:我们要在 n 个城市中建立一个通信网络,则连通这 n 个城市需要
布置 n-1 一条通信线路,这个时候我们需要考虑如何在成本最低的情况下建立这个通信网?
于是我们就可以引入连通图来解决我们遇到的问题,n 个城市就是图上的 n 个顶点,然后,边表示
两个城市的通信线路,每条边上的权重就是我们搭建这条线路所需要的成本,所以现在我们有 n 个
顶点的连通网可以建立不同的生成树,每一颗生成树都可以作为一个通信网,当我们构造这个连
通网所花的成本最小时,搭建该连通网的生成树,就称为最小生成树。
构造最小生成树有很多算法,但是他们都是利用了最小生成树的同一种性质:MST 性质(假设
N=(V,{E})是一个连通网,U 是顶点集 V 的一个非空子集,如果(u,v)是一条具有最小权值的边,
其中 u 属于 U,v 属于 V-U,则必定存在一颗包含边(u,v)的最小生成树),下面就介绍两种使
用 MST 性质生成最小生成树的算法:普里姆算法和克鲁斯卡尔算法。
相关文章:
JAVA 算法面试总结
1、二分查找 二分查找又叫折半查找,要求待查找的序列有序。每次取中间位置的值与待查关键字比较,如果中间位置 的值比待查关键字大,则在前半部分循环这个查找的过程,如果中间位置的值比待查关键字小, 则在后半部分循环…...
【Docker】安装MySQL 通俗易懂 亲测没有任何问题
目录 1.拉取镜像 2.运行容器 3.创建mysql配置文件 4.测试 1.拉取镜像 dockerhub官网:Docker 如果需要其他版本mysql docker pull mysql:xxx(版本) docker pull mysql #默认拉取最新版本 latest 2.运行容器 docker run -d -p 3306:33…...

【React】打包优化-配置CDN
CDN 是一种内容分发网络服务,当用户请求网站内容时,由离用户最近的服务器将缓存的资源内容传递给用户。 哪些资源可以放到CDN服务器?(比如react、 react-dom) 体积较大,需要利用CDN文件在浏览器的缓存特性…...
上手 Promethus - 开源监控、报警工具包
名词解释 Promethus 是什么 开源的【系统监控和警报】工具包 专注于: 1)可靠的实时监控 2)收集时间序列数据 3)提供强大的查询语言(PromQL),用于分析这些数据 功能: 1࿰…...
三)
Linux学习教程(第十二章 Linux系统管理)三
第十二章 Linux系统管理(进程管理、工作管理和系统定时任务)(三) 十九、Linux 定时执行任务(at命令) Linux at命令详解:定时执行任务 要想使用 at 命令,读者需提前安装好 at 软件…...

网络篇---第三篇
系列文章目录 文章目录 系列文章目录前言一、说一下HTTP的长连接与短连接的区别二、TCP 为什么要三次握手,两次不行吗?为什么?三、说一下 TCP 粘包是怎么产生的?怎么解决粘包问题的?前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大…...

tensorflow和pytorch的联系与区别
TensorFlow和PyTorch是两个流行的深度学习框架,它们在很多方面都有相似之处,因为它们都旨在解决相同的问题,即构建和训练神经网络。 以下是它们之间的一些联系: 1.深度学习框架: TensorFlow和PyTorch都是开源的深度学…...

为什么选择美国VPS服务器
企业、个人和组织都需要一个稳定高效的服务器来托管他们的网站、应用程序和数据。而对于中国用户来说,寻找一个性价比高的便宜美国VPS服务器,既能满足需求,又能节约成本,成为了一个非常重要的问题。 VPS即虚拟专用服务器…...
StarRocks Evolution:One Data,All Analytics
在 11 月 17 日举行的 StarRocks Summit 2023上,StarRocks TSC Member、镜舟科技 CTO 张友东详细介绍了 StarRocks 社区的发展情况,并全面解析了 StarRocks 的核心技术与未来规划;我们特意将他的精彩演讲整理出来,以帮助大家更深入…...

微信小程序富文本拓展rich-text
微信小程序富文本插件 功能介绍 支持解析<style>标签中的全局样式支持自定义默认的标签样式支持自动设置标题 若html中存在title标签,将自动把title标签的内容设置到页面的标题上,并在回调bindparse中返回,可以用于转发支持添加加载提示 可以在Parser标签内添加加载提…...
Postman:专业API测试工具,提升Mac用户体验
如果你是一名开发人员或测试工程师,那么你一定知道Postman。这是一个广泛使用的API测试工具,适用于Windows、Mac和Linux系统。今天,我们要重点介绍Postman的Mac版本,以及为什么它是你进行API测试的理想选择。 一、强大的功能和易…...

3.golang数组以及切片
数组 数组的声明 数组是具有相同 唯一类型 的一组以编号且长度固定的数据项序列。一个数组的表示形式为 T[n]。n 表示数组中元素的数量,T 代表每个元素的类型。 var a [3]int fmt.Println(a)var a[3]int 声明了一个长度为 3 的整型数组。数组中的所有元素都被自动…...
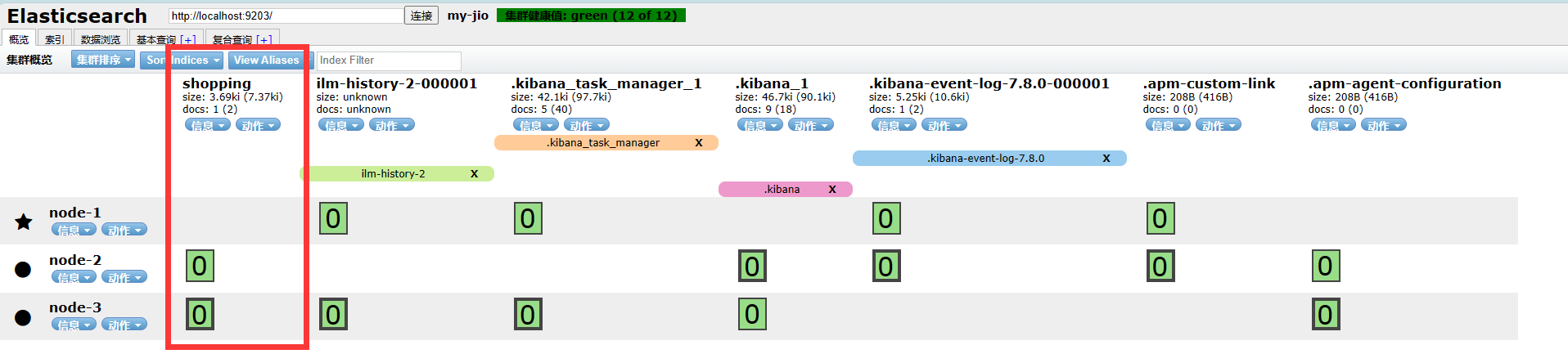
ElasticSearch02
ElasticSearch客户端操作 ElasticSearch 版本:7.8 学习视频:尚硅谷 笔记:https://zgtsky.top/ 实际开发中,主要有三种方式可以作为elasticsearch服务的客户端: 第一种,使用elasticsearch提供的Restful接口…...

比特币挖矿过程,双花攻击,女巫攻击,DID聚合身份
目录 比特币挖矿过程 双花攻击 双花攻击的原理 双花攻击的类型 双花攻击防范措施:...
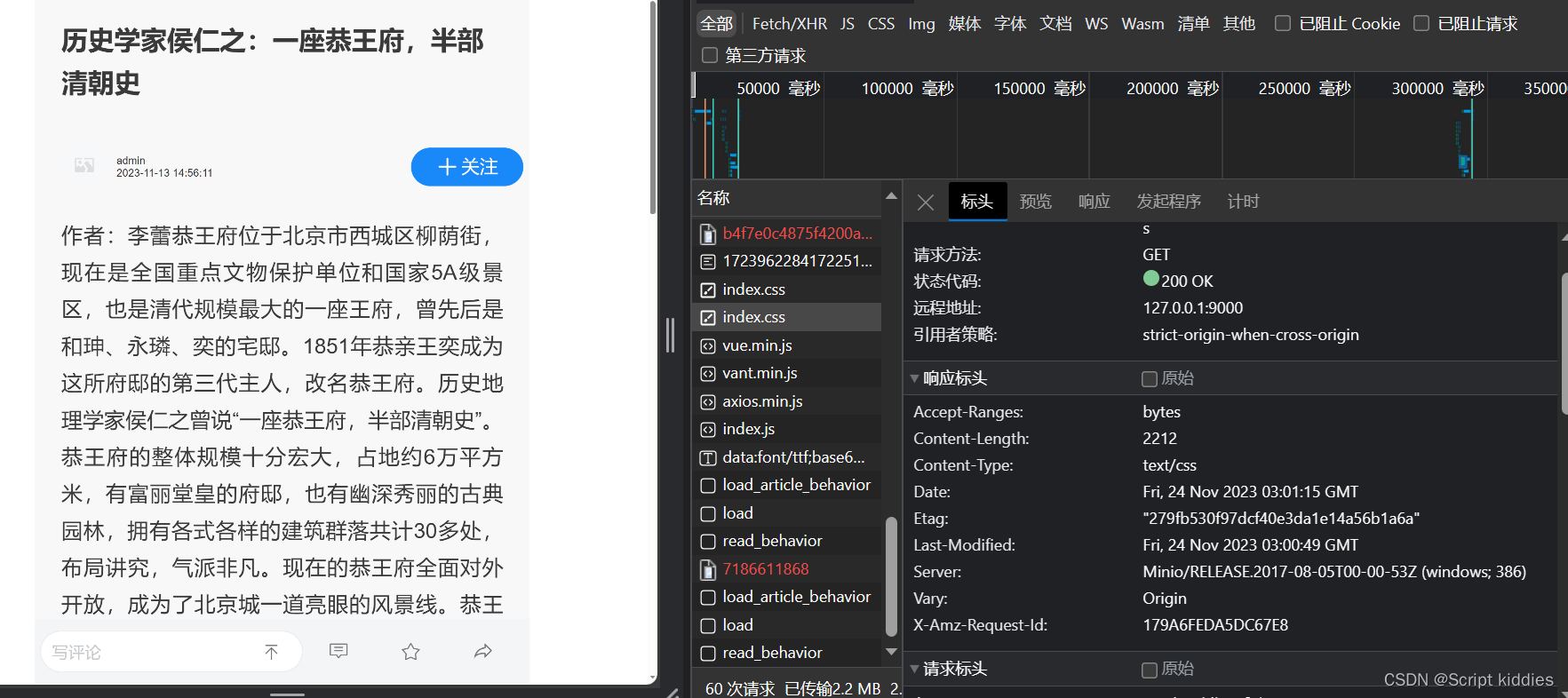
加载minio中存储的静态文件html,不显示样式与js
问题描述:点击链接获取的就是纯静态文件,但是通过浏览器可以看到明明加载了css文件与js文件 原因:仔细看你会发现加载css文件显示的contentType:text/html文件,原来是minio上传文件时将所有文件的contentType设置成了text/html 要在上传时指定文件,根据文章的类型指定的Conten…...
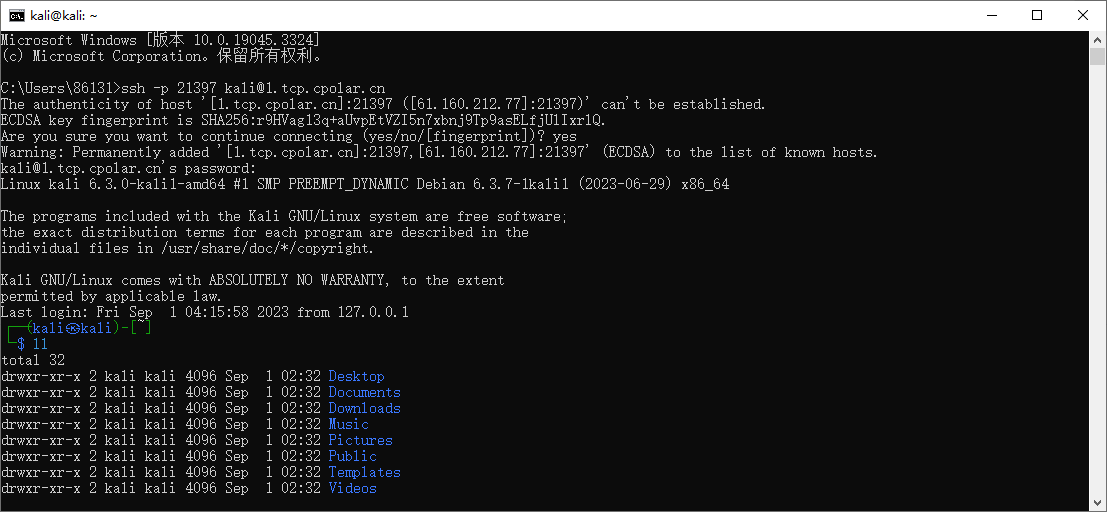
kali安装内网穿透工具并实现ssh远程连接
文章目录 1. 启动kali ssh 服务2. kali 安装cpolar 内网穿透3. 配置kali ssh公网地址4. 远程连接5. 固定连接SSH公网地址6. SSH固定地址连接测试 简单几步通过[cpolar 内网穿透](cpolar官网-安全的内网穿透工具 | 无需公网ip | 远程访问 | 搭建网站)软件实现ssh远程连接kali 1…...

机器学习探索计划——KNN实现Iris鸢尾花分类
文章目录 1. 加载数据集2.拆分数据集3.预测4.评价 1. 加载数据集 import numpy as np from sklearn import datasetsiris datasets.load_iris()iris.keys()dict_keys([data, target, frame, target_names, DESCR, feature_names, filename, data_module])X iris.data X.shap…...

鸿蒙(HarmonyOS)应用开发——装饰器
简介 ArkTS是HarmonyOS优选的主力应用开发语言。它在TypeScript(简称TS)的基础上,扩展了声明式UI、状态管理等相应的能力,让开发者可以以更简洁、更自然的方式开发高性能应用。TS是JavaScript(简称JS)的超…...

使用脚手架创建Vue3项目
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: Vue ✨特色专栏: MySQL学习…...
SpringBoot 2 系列停止维护,Java8 党何去何从?
SpringBoot 2.x 版本正式停止更新维护,官方将不再提供对 JDK8 版本的支持 SpringBoot Logo 版本的新特性 3.2 版本正式发布,亮点包括: 支持 JDK17、JDK21 版本 对虚拟线程的完整支持 JVM Checkpoint Restore(Project CRaC&…...

快速入门:Ollama部署Yi-Coder-1.5B,5分钟搭建编程助手
快速入门:Ollama部署Yi-Coder-1.5B,5分钟搭建编程助手 1. 为什么选择Yi-Coder-1.5B? Yi-Coder-1.5B是一个轻量级但功能强大的开源代码生成模型,特别适合开发者日常使用。它最大的优势是在保持小体积(仅15亿参数&…...

科研助手实战:OpenClaw+Phi-3-vision自动整理文献图表数据
科研助手实战:OpenClawPhi-3-vision自动整理文献图表数据 1. 为什么需要自动化文献整理 作为一名经常需要阅读大量论文的研究者,我发现自己花费在整理文献数据上的时间越来越长。每次下载几十篇PDF,手动截图关键图表、复制数据表格、整理参…...

反向海淘商家必看!精细拍照服务,帮你降本留客不踩坑
做反向海淘生意的商家都懂,最头疼的莫过于用户投诉与跨境退货——海外用户担心货不对版不敢下单,下单后因实物与图片不符发起退货,高额跨境运费、人力成本,不仅压缩利润,还会拉低店铺口碑,甚至流失核心客群…...

Sokol动画系统:如何在跨平台C/C++项目中实现流畅的2D与3D动画效果
Sokol动画系统:如何在跨平台C/C项目中实现流畅的2D与3D动画效果 【免费下载链接】sokol minimal cross-platform standalone C headers 项目地址: https://gitcode.com/gh_mirrors/so/sokol Sokol是一个极简的跨平台独立C头文件库,专门为游戏和图…...

5. 你是怎么理解ES6中 Promise的?使用场景?
一、先给面试官一个结论版如果面试官问 "你怎么理解 Promise?" ,不要上来就背 API。 更好的开场是先说本质:Promise 是 ES6 引入的一种用于处理异步操作的解决方案。 它的核心价值是:把异步操作的最终结果(成…...

Qwen3.5-9B高效编码:OpenClaw自动补全Python函数
Qwen3.5-9B高效编码:OpenClaw自动补全Python函数 1. 为什么需要AI代码补全? 作为一个长期与Python打交道的开发者,我经常陷入这样的困境:在深夜赶项目时,明明知道要实现什么功能,却卡在具体函数实现的细节…...
)
Modbus协议避坑指南:功能码06写入失败的5个常见原因及解决方法(附Wireshark抓包分析)
Modbus协议避坑指南:功能码06写入失败的5个常见原因及解决方法(附Wireshark抓包分析) 在工业自动化领域,Modbus协议因其简单可靠的特点,成为设备通信的基石。而功能码06(写单个寄存器)作为最常用…...

2024版:从零到一,手把手教你完成UniApp支付宝支付功能配置
1. 为什么需要UniApp支付宝支付功能? 移动应用开发中,支付功能几乎是必备模块。作为国内主流支付方式之一,支付宝支付覆盖了超过10亿用户,接入支付宝意味着你的应用可以触达绝大多数国内用户。UniApp作为跨平台开发框架࿰…...

双Token无感刷新:从登录到重试的完整链路解析
1. 双Token机制的核心原理 想象一下你住在一个高档小区,门禁卡就是你的通行证。普通门禁卡(Access Token)有效期只有30分钟,而物业还给你一张备用卡(Refresh Token)有效期长达7天。当普通卡过期时ÿ…...
)
Aseprite新手必看:5分钟搞定像素角色基础动画(附完整工程文件)
Aseprite像素动画速成指南:从静态角色到生动动作的5分钟魔法 第一次打开Aseprite时,我被它简洁的界面和强大的功能震撼了——作为一个独立游戏开发者,我需要快速制作角色动画,但又不想陷入复杂的美术流程。经过多次实践ÿ…...