竞赛选题 题目:基于LSTM的预测算法 - 股票预测 天气预测 房价预测
文章目录
- 0 简介
- 1 基于 Keras 用 LSTM 网络做时间序列预测
- 2 长短记忆网络
- 3 LSTM 网络结构和原理
- 3.1 LSTM核心思想
- 3.2 遗忘门
- 3.3 输入门
- 3.4 输出门
- 4 基于LSTM的天气预测
- 4.1 数据集
- 4.2 预测示例
- 5 基于LSTM的股票价格预测
- 5.1 数据集
- 5.2 实现代码
- 6 lstm 预测航空旅客数目
- 数据集
- 预测代码
- 7 最后
0 简介
🔥 优质竞赛项目系列,今天要分享的是
基于LSTM的预测算法 - 股票预测 天气预测 房价预测
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 基于 Keras 用 LSTM 网络做时间序列预测
时间序列预测是一类比较困难的预测问题。
与常见的回归预测模型不同,输入变量之间的“序列依赖性”为时间序列问题增加了复杂度。
一种能够专门用来处理序列依赖性的神经网络被称为 递归神经网络(Recurrent Neural
Networks、RNN)。因其训练时的出色性能,长短记忆网络(Long Short-Term Memory
Network,LSTM)是深度学习中广泛使用的一种递归神经网络(RNN)。
在本篇文章中,将介绍如何在 R 中使用 keras 深度学习包构建 LSTM 神经网络模型实现时间序列预测。
- 如何为基于回归、窗口法和时间步的时间序列预测问题建立对应的 LSTM 网络。
- 对于非常长的序列,如何在构建 LSTM 网络和用 LSTM 网络做预测时保持网络关于序列的状态(记忆)。
2 长短记忆网络
长短记忆网络,或 LSTM 网络,是一种递归神经网络(RNN),通过训练时在“时间上的反向传播”来克服梯度消失问题。
LSTM 网络可以用来构建大规模的递归神经网络来处理机器学习中复杂的序列问题,并取得不错的结果。
除了神经元之外,LSTM 网络在神经网络层级(layers)之间还存在记忆模块。
一个记忆模块具有特殊的构成,使它比传统的神经元更“聪明”,并且可以对序列中的前后部分产生记忆。模块具有不同的“门”(gates)来控制模块的状态和输出。一旦接收并处理一个输入序列,模块中的各个门便使用
S 型的激活单元来控制自身是否被激活,从而改变模块状态并向模块添加信息(记忆)。
一个激活单元有三种门:
- 遗忘门(Forget Gate):决定抛弃哪些信息。
- 输入门(Input Gate):决定输入中的哪些值用来更新记忆状态。
- 输出门(Output Gate):根据输入和记忆状态决定输出的值。
每一个激活单元就像是一个迷你状态机,单元中各个门的权重通过训练获得。
3 LSTM 网络结构和原理
long short term memory,即我们所称呼的LSTM,是为了解决长期以来问题而专门设计出来的,所有的RNN都具有一种重复神
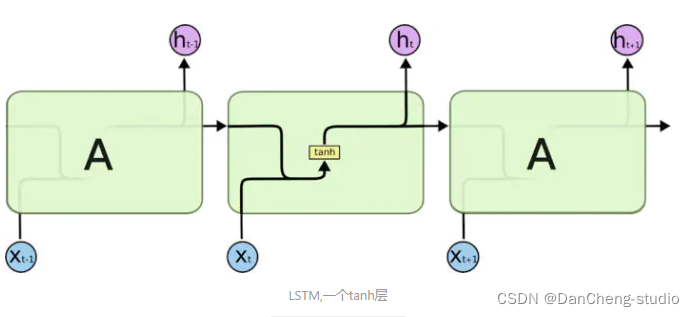
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
不必担心这里的细节。我们会一步一步地剖析 LSTM 解析图。现在,我们先来熟悉一下图中使用的各种元素的图标。
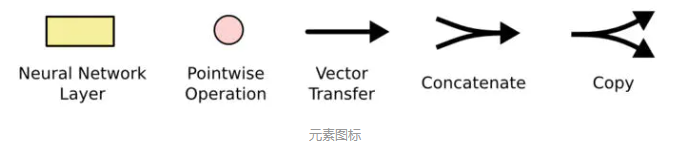
在上面的图例中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。粉色的圈代表 pointwise
的操作,诸如向量的和,而黄色的矩阵就是学习到的神经网络层。合在一起的线表示向量的连接,分开的线表示内容被复制,然后分发到不同的位置。
3.1 LSTM核心思想
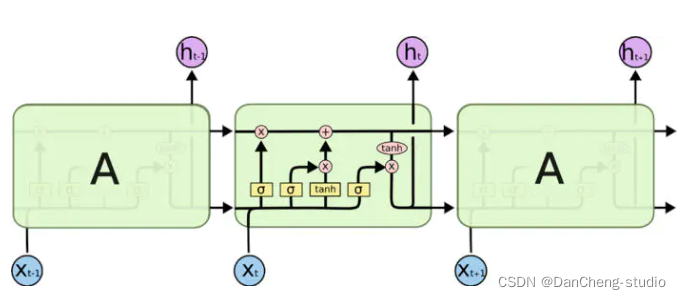
LSTM的关键在于细胞的状态整个(如下图),和穿过细胞的那条水平线。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。

门可以实现选择性地让信息通过,主要是通过一个 sigmoid 的神经层 和一个逐点相乘的操作来实现的。
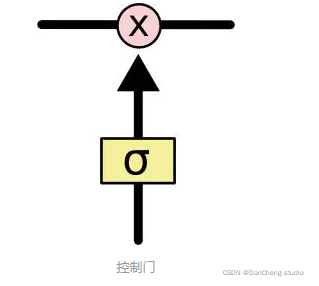
sigmoid 层输出(是一个向量)的每个元素都是一个在 0 和 1 之间的实数,表示让对应信息通过的权重(或者占比)。比如, 0
表示“不让任何信息通过”, 1 表示“让所有信息通过”。
LSTM通过三个这样的本结构来实现信息的保护和控制。这三个门分别输入门、遗忘门和输出门。
3.2 遗忘门
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取和,输出一个在 0到
1之间的数值给每个在细胞状态中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
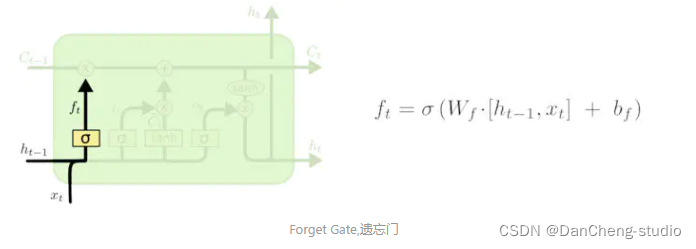
其中
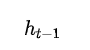
表示的是 上一时刻隐含层的 输出,
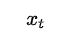
表示的是当前细胞的输入。σ表示sigmod函数。
3.3 输入门
下一步是决定让多少新的信息加入到 cell 状态 中来。实现这个需要包括两个步骤:首先,一个叫做“input gate layer ”的 sigmoid
层决定哪些信息需要更新;一个 tanh 层生成一个向量,也就是备选的用来更新的内容。在下一步,我们把这两部分联合起来,对 cell 的状态进行一个更新。

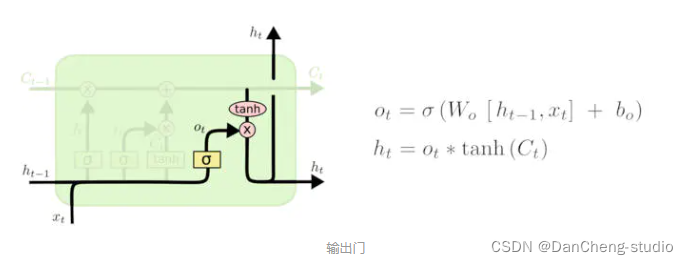
3.4 输出门
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid
层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid
门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
在语言模型的例子中,因为他就看到了一个代词,可能需要输出与一个动词相关的信息。例如,可能输出是否代词是单数还是负数,这样如果是动词的话,我们也知道动词需要进行的词形变化。
4 基于LSTM的天气预测
4.1 数据集
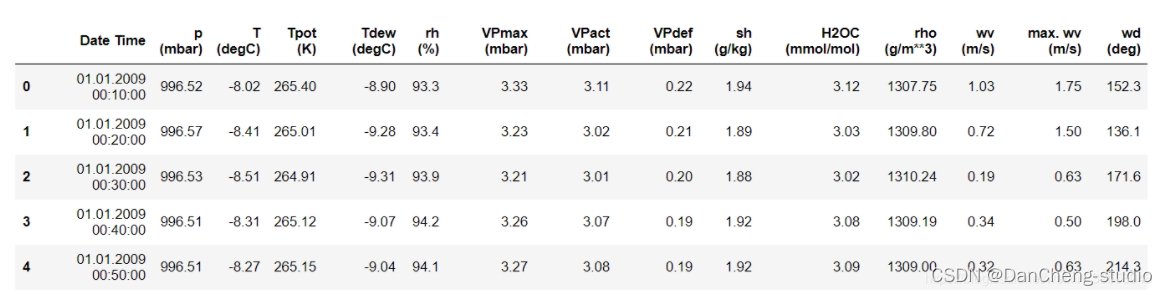
如上所示,每10分钟记录一次观测值,一个小时内有6个观测值,一天有144(6x24)个观测值。
给定一个特定的时间,假设要预测未来6小时的温度。为了做出此预测,选择使用5天的观察时间。因此,创建一个包含最后720(5x144)个观测值的窗口以训练模型。
下面的函数返回上述时间窗以供模型训练。参数 history_size 是过去信息的滑动窗口大小。target_size
是模型需要学习预测的未来时间步,也作为需要被预测的标签。
下面使用数据的前300,000行当做训练数据集,其余的作为验证数据集。总计约2100天的训练数据。
4.2 预测示例
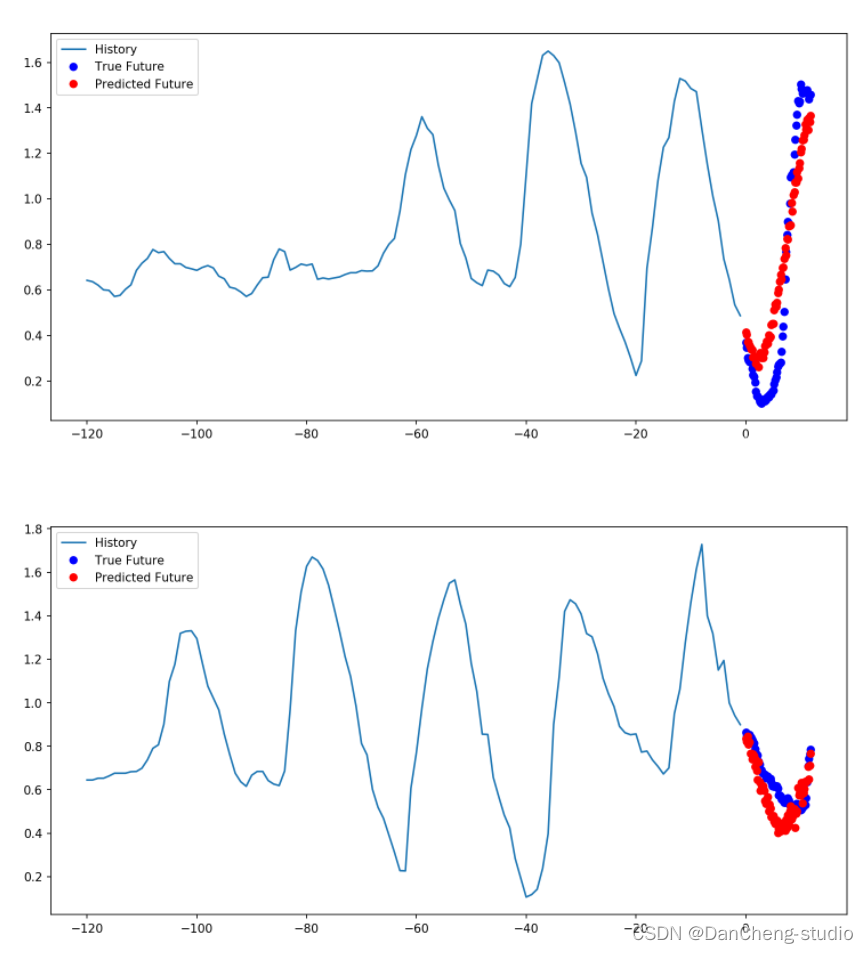
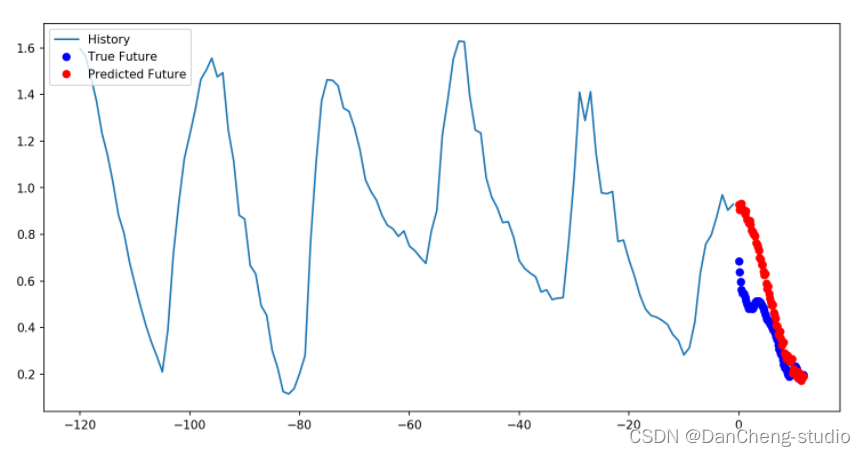
多步骤预测模型中,给定过去的采样值,预测未来一系列的值。对于多步骤模型,训练数据再次包括每小时采样的过去五天的记录。但是,这里的模型需要学习预测接下来12小时的温度。由于每10分钟采样一次数据,因此输出为72个预测值。
future_target = 72
x_train_multi, y_train_multi = multivariate_data(dataset, dataset[:, 1], 0,TRAIN_SPLIT, past_history,future_target, STEP)
x_val_multi, y_val_multi = multivariate_data(dataset, dataset[:, 1],TRAIN_SPLIT, None, past_history,future_target, STEP)
划分数据集
train_data_multi = tf.data.Dataset.from_tensor_slices((x_train_multi, y_train_multi))
train_data_multi = train_data_multi.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()val_data_multi = tf.data.Dataset.from_tensor_slices((x_val_multi, y_val_multi))
val_data_multi = val_data_multi.batch(BATCH_SIZE).repeat()
绘制样本点数据
def multi_step_plot(history, true_future, prediction):plt.figure(figsize=(12, 6))num_in = create_time_steps(len(history))num_out = len(true_future)plt.plot(num_in, np.array(history[:, 1]), label='History')plt.plot(np.arange(num_out)/STEP, np.array(true_future), 'bo',label='True Future')if prediction.any():plt.plot(np.arange(num_out)/STEP, np.array(prediction), 'ro',label='Predicted Future')plt.legend(loc='upper left')plt.show()
for x, y in train_data_multi.take(1):multi_step_plot(x[0], y[0], np.array([0]))

此处的任务比先前的任务复杂一些,因此该模型现在由两个LSTM层组成。最后,由于需要预测之后12个小时的数据,因此Dense层将输出为72。
multi_step_model = tf.keras.models.Sequential()
multi_step_model.add(tf.keras.layers.LSTM(32,return_sequences=True,input_shape=x_train_multi.shape[-2:]))
multi_step_model.add(tf.keras.layers.LSTM(16, activation='relu'))
multi_step_model.add(tf.keras.layers.Dense(72))multi_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(clipvalue=1.0), loss='mae')
训练
multi_step_history = multi_step_model.fit(train_data_multi, epochs=EPOCHS,steps_per_epoch=EVALUATION_INTERVAL,validation_data=val_data_multi,validation_steps=50)
5 基于LSTM的股票价格预测
5.1 数据集
股票数据总共有九个维度,分别是

5.2 实现代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
plt.rcParams['font.sans-serif']=['SimHei']#显示中文
plt.rcParams['axes.unicode_minus']=False#显示负号def load_data():test_x_batch = np.load(r'test_x_batch.npy',allow_pickle=True)test_y_batch = np.load(r'test_y_batch.npy',allow_pickle=True)return (test_x_batch,test_y_batch)#定义lstm单元
def lstm_cell(units):cell = tf.contrib.rnn.BasicLSTMCell(num_units=units,forget_bias=0.0)#activation默认为tanhreturn cell#定义lstm网络
def lstm_net(x,w,b,num_neurons):#将输入变成一个列表,列表的长度及时间步数inputs = tf.unstack(x,8,1)cells = [lstm_cell(units=n) for n in num_neurons]stacked_lstm_cells = tf.contrib.rnn.MultiRNNCell(cells)outputs,_ = tf.contrib.rnn.static_rnn(stacked_lstm_cells,inputs,dtype=tf.float32)return tf.matmul(outputs[-1],w) + b#超参数
num_neurons = [32,32,64,64,128,128]#定义输出层的weight和bias
w = tf.Variable(tf.random_normal([num_neurons[-1],1]))
b = tf.Variable(tf.random_normal([1]))#定义placeholder
x = tf.placeholder(shape=(None,8,8),dtype=tf.float32)#定义pred和saver
pred = lstm_net(x,w,b,num_neurons)
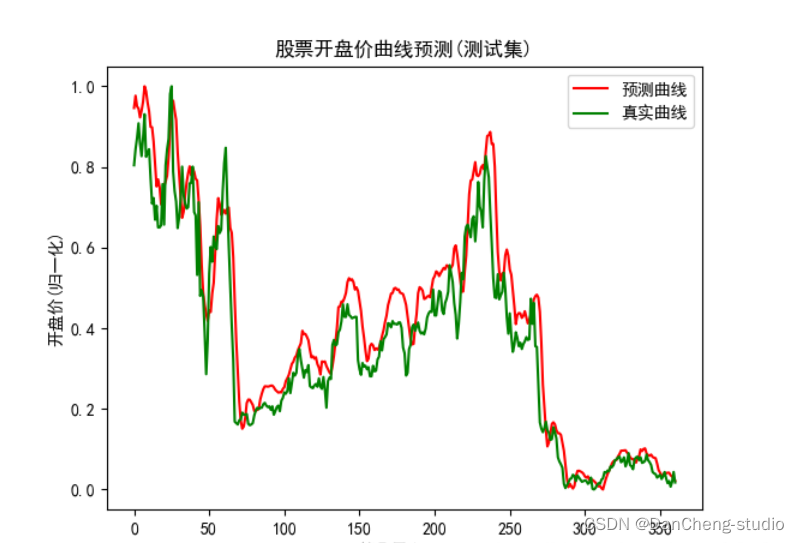
saver = tf.train.Saver(tf.global_variables())if __name__ == '__main__':#开启交互式Sessionsess = tf.InteractiveSession()saver.restore(sess,r'D:\股票预测\model_data\my_model.ckpt')#载入数据test_x,test_y = load_data()#预测predicts = sess.run(pred,feed_dict={x:test_x})predicts = ((predicts.max() - predicts) / (predicts.max() - predicts.min()))#数学校准#可视化plt.plot(predicts,'r',label='预测曲线')plt.plot(test_y,'g',label='真实曲线')plt.xlabel('第几天/days')plt.ylabel('开盘价(归一化)')plt.title('股票开盘价曲线预测(测试集)')plt.legend()plt.show()#关闭会话sess.close()
6 lstm 预测航空旅客数目
数据集
airflights passengers dataset下载地址
https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-
passengers.csv
这个dataset包含从1949年到1960年每个月的航空旅客数目,共12*12=144个数字。
下面的程序中,我们以1949-1952的数据预测1953的数据,以1950-1953的数据预测1954的数据,以此类推,训练模型。
预测代码
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import torch
import torch.nn as nn
from sklearn.preprocessing import MinMaxScaler
import os# super parameters
EPOCH = 400
learning_rate = 0.01
seq_length = 4 # 序列长度
n_feature = 12 # 序列中每个元素的特征数目。本程序采用的序列元素为一年的旅客,一年12个月,即12维特征。# data
data = pd.read_csv('airline-passengers.csv') # 共 "12年*12个月=144" 个数据
data = data.iloc[:, 1:5].values # dataFrame, shape (144,1)
data = np.array(data).astype(np.float32)
sc = MinMaxScaler()
data = sc.fit_transform(data) # 归一化
data = data.reshape(-1, n_feature) # shape (12, 12)trainData_x = []
trainData_y = []
for i in range(data.shape[0]-seq_length):tmp_x = data[i:i+seq_length, :]tmp_y = data[i+seq_length, :]trainData_x.append(tmp_x)trainData_y.append(tmp_y)# model
class Net(nn.Module):def __init__(self, in_dim=12, hidden_dim=10, output_dim=12, n_layer=1):super(Net, self).__init__()self.in_dim = in_dimself.hidden_dim = hidden_dimself.output_dim = output_dimself.n_layer = n_layerself.lstm = nn.LSTM(input_size=in_dim, hidden_size=hidden_dim, num_layers=n_layer, batch_first=True)self.linear = nn.Linear(hidden_dim, output_dim)def forward(self, x):_, (h_out, _) = self.lstm(x) # h_out是序列最后一个元素的hidden state# h_out's shape (batchsize, n_layer*n_direction, hidden_dim), i.e. (1, 1, 10)# n_direction根据是“否为双向”取值为1或2h_out = h_out.view(h_out.shape[0], -1) # h_out's shape (batchsize, n_layer * n_direction * hidden_dim), i.e. (1, 10)h_out = self.linear(h_out) # h_out's shape (batchsize, output_dim), (1, 12)return h_outtrain = True
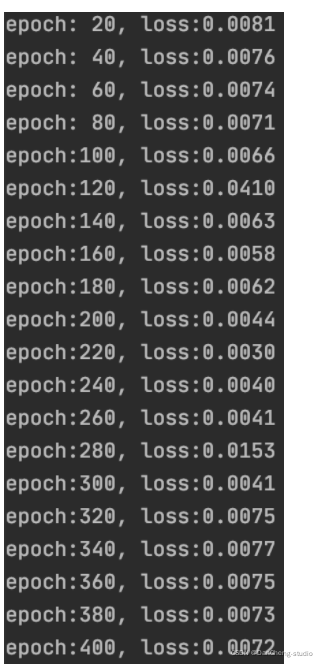
if train:model = Net()loss_func = torch.nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# trainfor epoch in range(EPOCH):total_loss = 0for iteration, X in enumerate(trainData_x): # X's shape (seq_length, n_feature)X = torch.tensor(X).float()X = torch.unsqueeze(X, 0) # X's shape (1, seq_length, n_feature), 1 is batchsizeoutput = model(X) # output's shape (1,12)output = torch.squeeze(output)loss = loss_func(output, torch.tensor(trainData_y[iteration]))optimizer.zero_grad() # clear gradients for this training iterationloss.backward() # computing gradientsoptimizer.step() # update weightstotal_loss += lossif (epoch+1) % 20 == 0:print('epoch:{:3d}, loss:{:6.4f}'.format(epoch+1, total_loss.data.numpy()))# torch.save(model, 'flight_model.pkl') # 这样保存会弹出UserWarning,建议采用下面的保存方法,详情可参考https://zhuanlan.zhihu.com/p/129948825torch.save({'state_dict': model.state_dict()}, 'checkpoint.pth.tar')else:# model = torch.load('flight_model.pth')model = Net()checkpoint = torch.load('checkpoint.pth.tar')model.load_state_dict(checkpoint['state_dict'])# predict
model.eval()
predict = []
for X in trainData_x: # X's shape (seq_length, n_feature)X = torch.tensor(X).float()X = torch.unsqueeze(X, 0) # X's shape (1, seq_length, n_feature), 1 is batchsizeoutput = model(X) # output's shape (1,12)output = torch.squeeze(output)predict.append(output.data.numpy())# plot
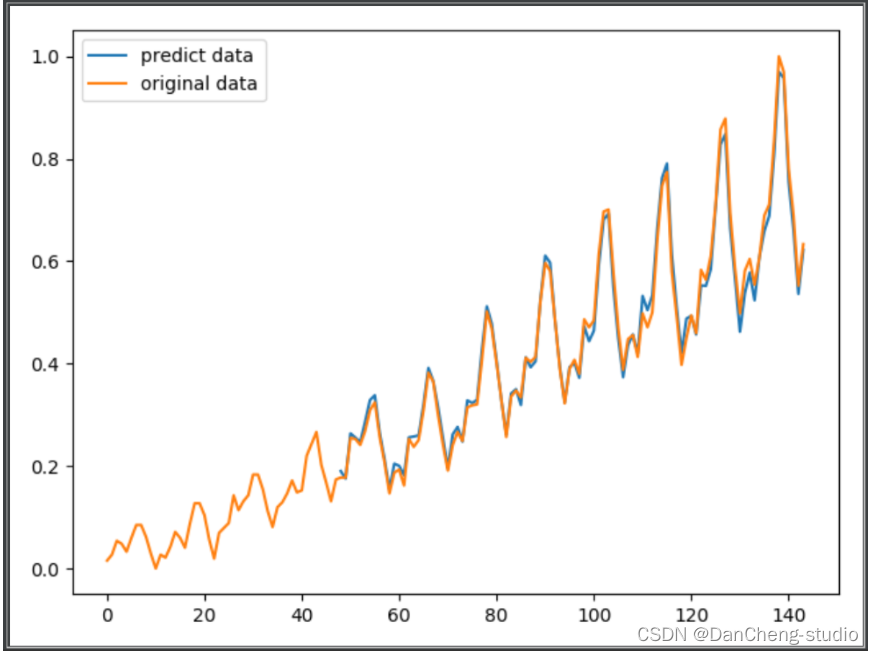
plt.figure()
predict = np.array(predict)
predict = predict.reshape(-1, 1).squeeze()
x_tick = np.arange(len(predict)) + (seq_length*n_feature)
plt.plot(list(x_tick), predict, label='predict data')data_original = data.reshape(-1, 1).squeeze()
plt.plot(range(len(data_original)), data_original, label='original data')plt.legend(loc='best')
plt.show()
运行结果
7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛选题 题目:基于LSTM的预测算法 - 股票预测 天气预测 房价预测
文章目录 0 简介1 基于 Keras 用 LSTM 网络做时间序列预测2 长短记忆网络3 LSTM 网络结构和原理3.1 LSTM核心思想3.2 遗忘门3.3 输入门3.4 输出门 4 基于LSTM的天气预测4.1 数据集4.2 预测示例 5 基于LSTM的股票价格预测5.1 数据集5.2 实现代码 6 lstm 预测航空旅客数目数据集预…...

开源WIFI继电器之源代码
源代码:WiFiRelay: 基于ESP8285的WiFi继电器代码 1、环境搭建 开发环境搭建请参照win10搭建ESP8266_RTOS_SDK编译环境_xtensa-lx106 下载-CSDN博客 2、下载代码 在sdk路径下创建一个projects的文件夹,将WiFiRelay的代码克隆到此目录下: mkdir projec…...

NX二次开发UF_CURVE_create_arc_point_point_radius 函数介绍
文章作者:里海 来源网站:https://blog.csdn.net/WangPaiFeiXingYuan UF_CURVE_create_arc_point_point_radius Defined in: uf_curve.h int UF_CURVE_create_arc_point_point_radius(tag_t point1, tag_t point2, double radius, UF_CURVE_limit_p_t l…...

Unsupervised MVS论文笔记(2019年)
Unsupervised MVS论文笔记(2019年) 摘要1 引言2 相关工作3 实现方法3.1 网络架构3.2 通过光度一致性学习3.3 MVS的鲁棒光度一致性3.4 学习设置和实施的细节3.5.预测每幅图像的深度图 4 实验4.1 在DTU上的结果4.2 消融实验4.3 在ETH3D数据集上的微调4.4 在…...

2-Python与设计模式--前言
0-Python与设计模式–前言 一 什么是设计模式 设计模式是面对各种问题进行提炼和抽象而形成的解决方案。这些设计方案是前人不断试验, 考虑了封装性、复用性、效率、可修改、可移植等各种因素的高度总结。它不限于一种特定的语言, 它是一种解决问题的思…...

如何判别使用的junit是4还是5
Junit4与Junit5的版本中,Test注解的包位置不同。 Junit4的Test注解是在org.junit包下,儿Junit5的Test注解是在org.junit.jupiter.api包下。 可据此判定是使用的Junit4还是Junit5。 Junit4 import org.junit.Test;Junit5 import org.junit.jupiter.api…...
C#-创建用于测试的父类StartupBase用于服务注入
当写完C#代码,需要对某个方法进行测试。 创建一个XXXTests.cs文件之后,发现需要注入某个服务怎么办? 再创建一个StartupBase.cs文件: public abstract class StartupBase {public IConfiguration Configuration { get; }public …...
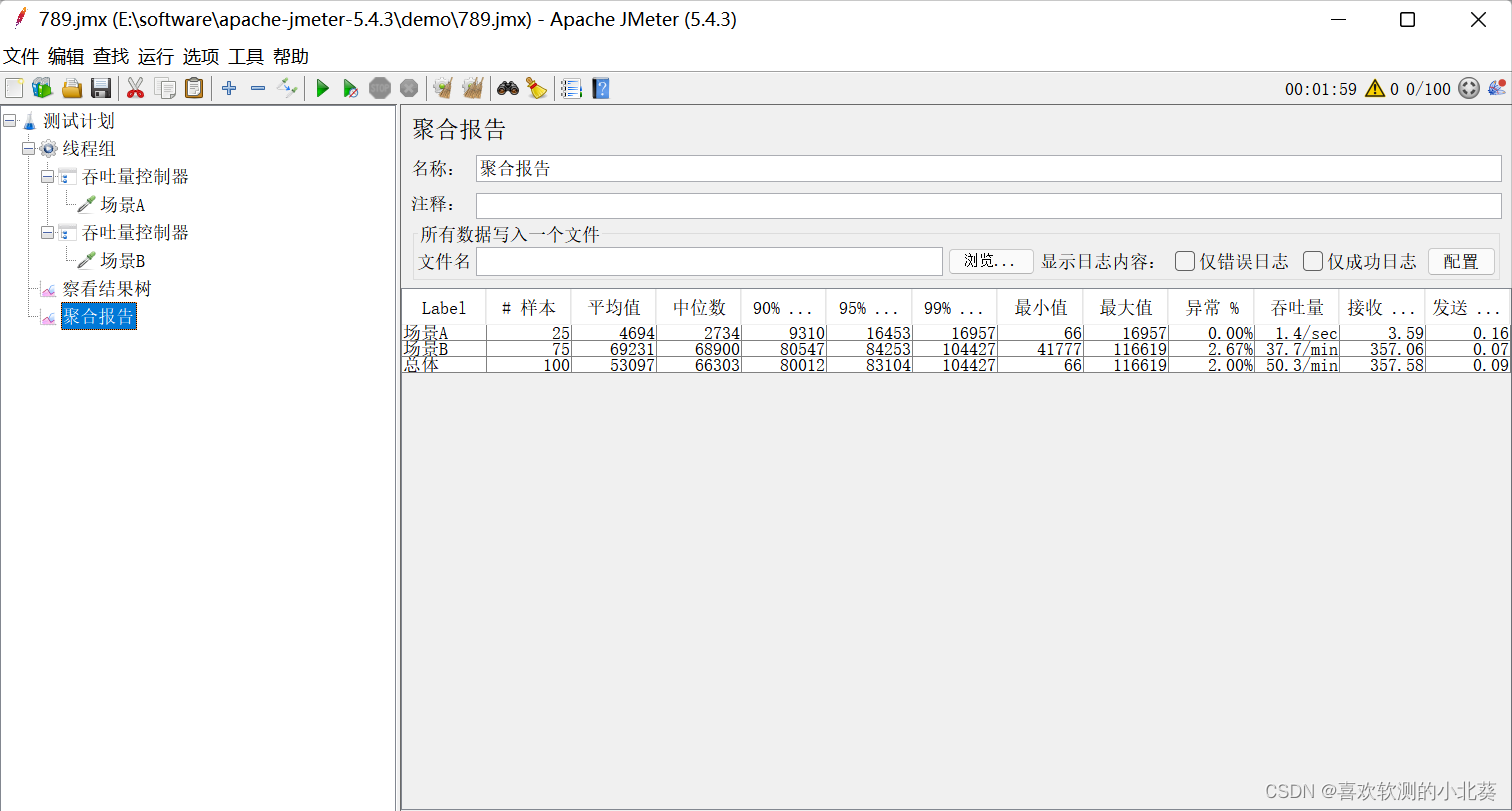
JMeter之压力测试——混合场景并发
在实际的压力测试场景中,有时会遇到多个场景混合并发的情况,这时就需要设置不同的并发比例对不同场景请求数量的控制,下面提供两种方案。 一、多线程组方案 1.业务场景设计如下:场景A、场景B、场景C,三个场景按照并发…...

Python入门04字符串
目录 1 字符串的定义2 转义字符3 字符串的常见方法4 分割字符串5 字符串反转6 字符串的链式调用7 格式化字符串8 多行字符串总结 1 字符串的定义 在Python中,字符串表示一个字符的序列,比如 str "hello,world"这里我们定义了一个字符串&…...
-基础入门之 fetch 与 axios)
vue3(四)-基础入门之 fetch 与 axios
一、fetch 1、axios和fetch的区别 Axios 和 Fetch 都是 JavaScript 中用于发送 HTTP 请求的 API,它们的主要区别在以下方面: 1.Axios 支持更广泛的浏览器和 Node.js 版本,而 Fetch 只能在较新的浏览器中使用,或需要使用 polyfi…...
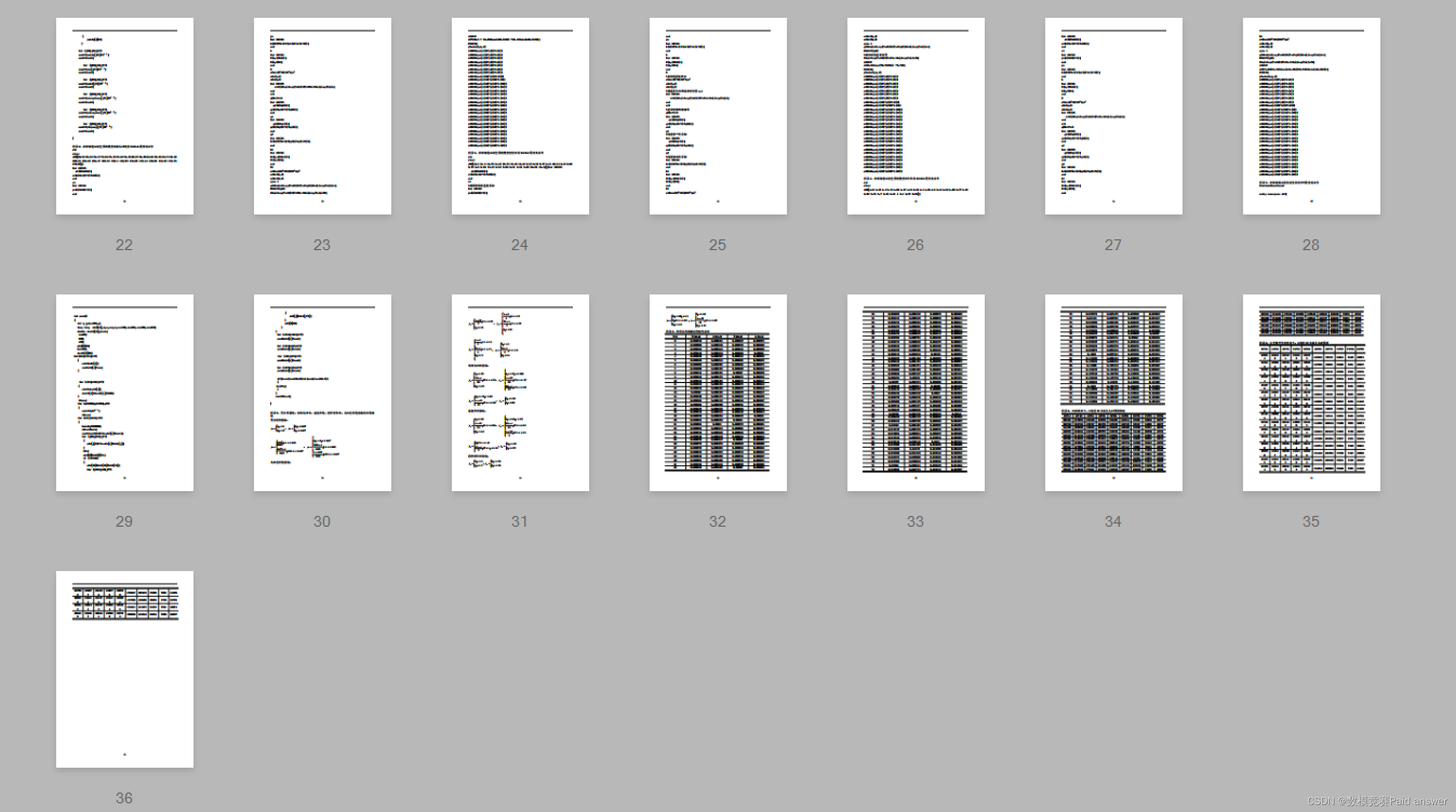
2016年五一杯数学建模C题二孩政策问题解题全过程文档及程序
2016年五一杯数学建模 C题 二孩政策问题 原题再现 多年来实施的严、紧计划生育政策对控制人口增长起到关键作用。在优生优育政策的指引下,我国人口质量显著提高,但也带来了不利影响,生育率偏低、男女比例失衡、人口老龄化情况严重等问题。2…...

学习c#的第二十四天
目录 C# 事件(Event) 事件概述 如何订阅和取消订阅事件 以编程方式订阅事件 使用匿名函数订阅事件 取消订阅 如何发布符合 .NET 准则的事件 发布基于 EventHandler 模式的事件 如何在派生类中引发基类事件 如何实现接口事件 如何实现自定义事…...
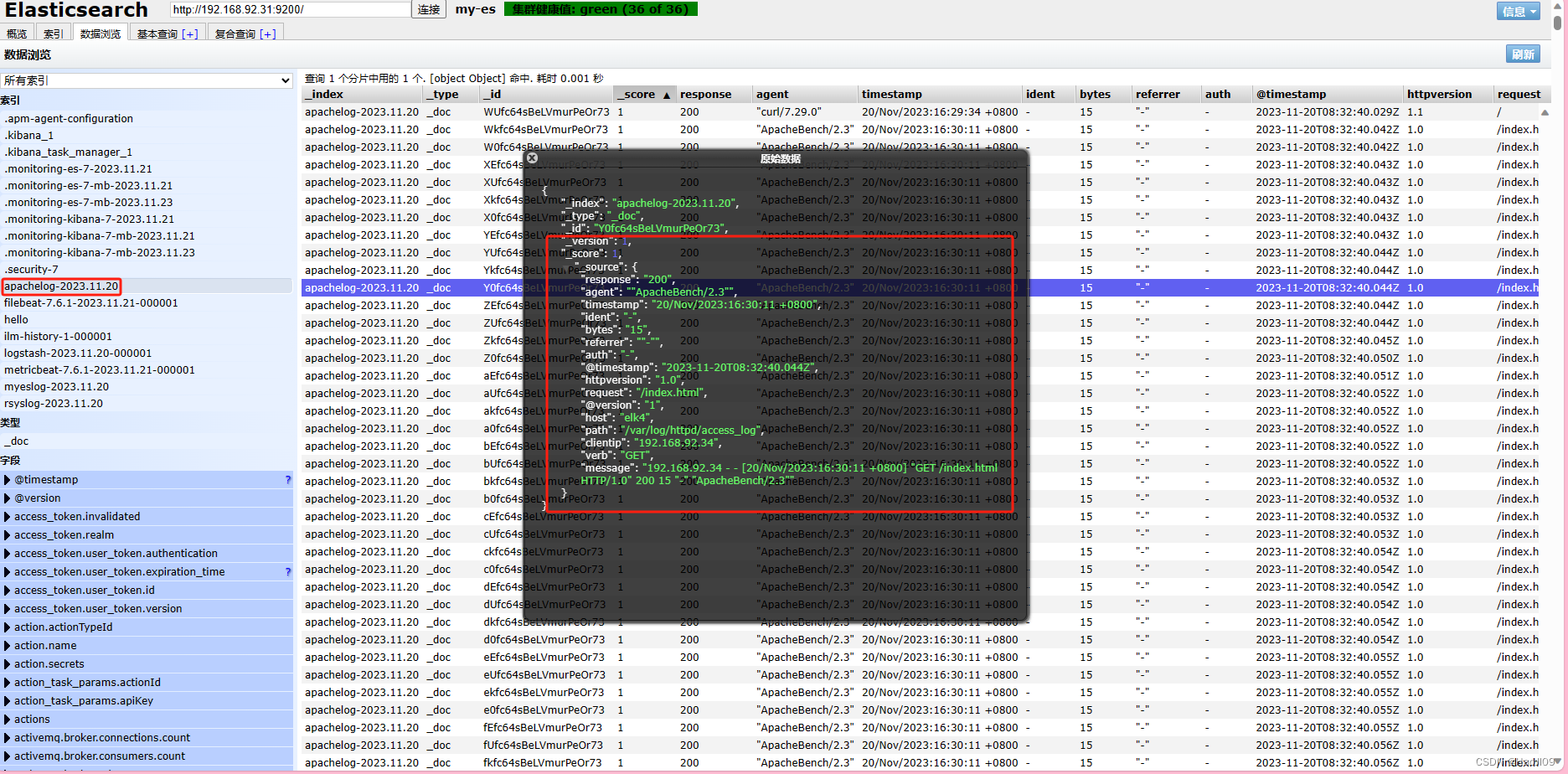
ELK企业级日志分析平台——logstash
部署 新建一台虚拟机elk4部署logstash [rootelk4 ~]# yum install -y jdk-11.0.15_linux-x64_bin.rpm[rootelk4 ~]# yum install -y logstash-7.6.1.rpm 命令方式 [rootelk4 bin]# /usr/share/logstash/bin/logstash -e input { stdin { } } output { stdout {} } elasticsearc…...
laravel8中常用路由使用(笔记四)
目录 1、框架路由目录统一放该目录 2、基本路由,路由都调用Route方法 3、控制器使用路由 4、路由参数 5、路由组 6、命名路由 7、命令查看当前路由列表 8、路由缓存 在Laravel 8中,路由定义了应用程序中接受请求的方式。它们定义了URL和相应的控制器方法之间的…...

理解 <script> 标签的 defer 和 async 属性
当我们在编写网页时,经常需要在 HTML 文件中引入 JavaScript 文件。这时候,我们通常会使用 开始 在介绍 defer 和 async 属性之前,我们先来看一下 <script src"path/to/script.js"></script>这段代码会在浏览器解…...
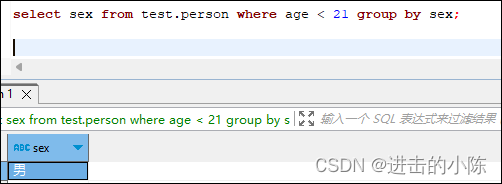
sql中group by和having的使用
group by:按照某个字段或者某些字段进行分组。 having:对分组之后的数据进行再次过滤,having必须和group by一起用,且在group by后面。 比如person表如下(以下查询均基于此表): 1.group by 用法…...
)
用python自行开发的流星监控系统meteor_monitor(第二篇)
代码: GitHub - xingxinghuo1000/meteor_monitor_scripts 本篇为最新代码的方案介绍和使用介绍。第一篇已经过时了,不建议看 。只看这一篇即可。 背景 著名的流星监控软件ufocapturehd2有几个缺陷,不能忍 1、吃性能,我的工控电脑…...
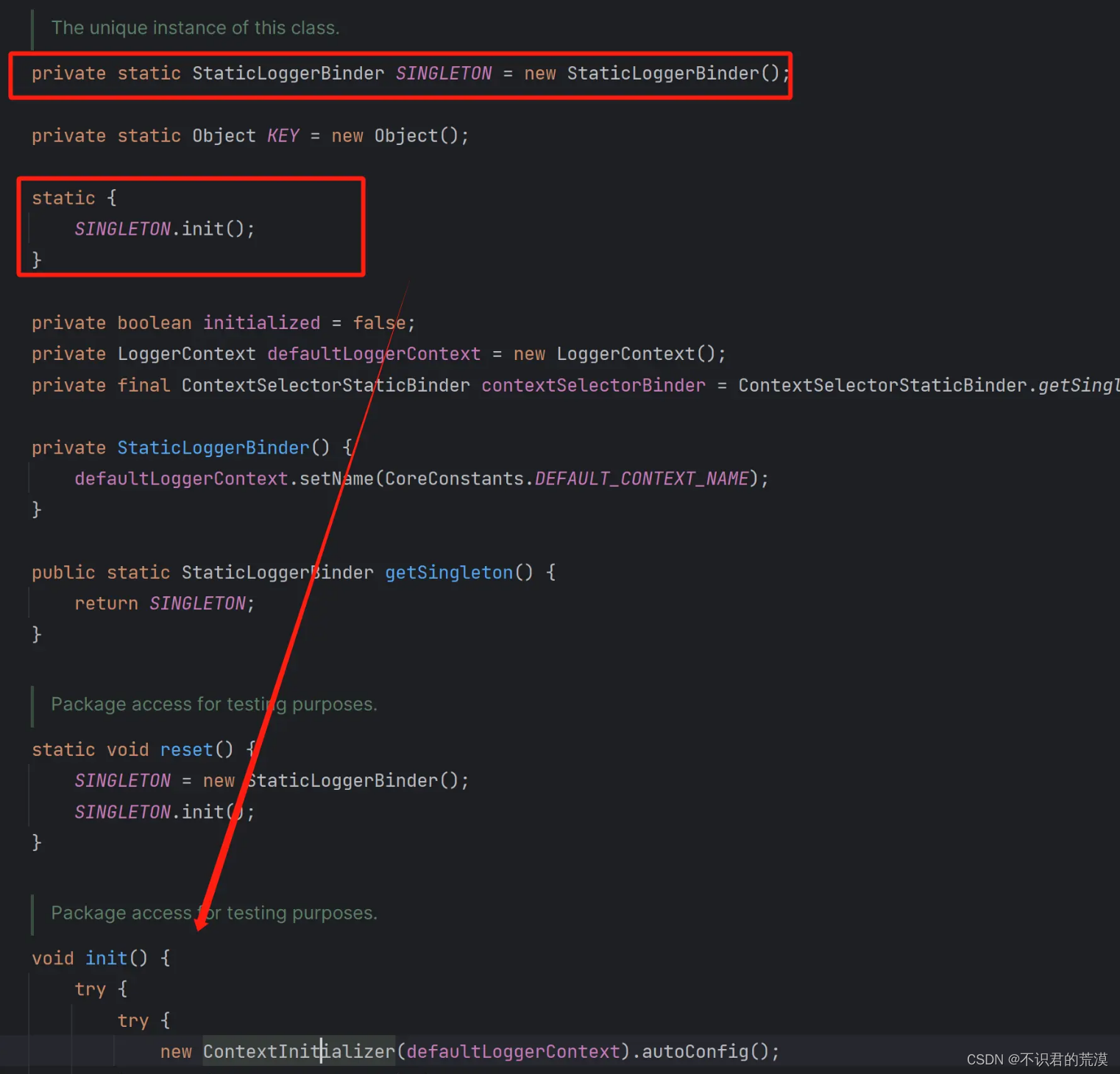
Slf4j使用Logback时,Logback如何初始化
前言 Slf4j SLF4J,全称 Simple Logging Facade for Java,是一个用于Java编程语言的日志系统抽象层。它为多种现有日志框架(例如Log4j、java.util.logging等)提供了统一的接口, 但自身并不实现日志功能。 SLF4J 允许用户在部署时…...

css之svg 制作圆及旋转
1.代码 <template><div class"loading-box"><div class"circle-container"><svg width"75" height"75" class"move-left-to-right"><circle cx"37.5" cy"37.5" r"26&…...

学习.NET验证模块FluentValidation的基本用法(续1:其它常见用法)
FluentValidation模块支持链式验证方法调用,也就是说,除了 RuleFor(r > r.UserName).NotEmpty()调用方式之外,还可以将对单个属性的多种验证函数以链式调用方式串接起来,比如UserName属性不能为空,长度在5~10之间&a…...

Speakeasy与Google Authenticator深度集成:QR码生成与扫描全流程
Speakeasy与Google Authenticator深度集成:QR码生成与扫描全流程 【免费下载链接】speakeasy **NOT MAINTAINED** Two-factor authentication for Node.js. One-time passcode generator (HOTP/TOTP) with support for Google Authenticator. 项目地址: https://g…...

【源-荷-储协同互动】考虑源-荷-储协同互动的主动配电网优化调度研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。👇 关注我领取海量matlab电子书和数学建模资料🍊个人信条:格物致知,完整Matl…...

2026届毕业生推荐的六大降重复率神器推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 基于人工智能产出内容越来越普遍的当前状况,文本里常常出现的模式化表达形态&…...
:第一次进京,从高铁上的微信到鸟巢旁的工位)
【人生底稿】08:2018 北京创业 180 天(上):第一次进京,从高铁上的微信到鸟巢旁的工位
2018年6月11日,天津到北京的高铁上,我第一次踏上去北京的路。 89年生的我,天津人,家离北京不过半小时高铁,活了快30年,居然从来没正经去过北京。 这不是什么逆袭爽文,是一个30岁程序员ÿ…...

爱邦保险:全国全牌照保险经纪领航者
爱邦保险经纪有限公司(以下简称“爱邦保险”)作为一家全国性保险经纪公司,据公开的工商信息及金融监管备案显示,爱邦保险是是经江苏省人民政府同意、中国保险监督管理委员会批准设立的一家全国性全牌照保险经纪公司,具…...

我的编程启程之路
一、自我简绍我是一名大三数学专业学生,在学习一点Python后对于代码有了兴趣,从而开始依据网上的视频学习编程。二、编程目标短期内目标是学习c语言等去准备408备战2027考研争取上岸。长期目标是能够进入一个大厂工作。三、学习规划脚踏实地,…...

BaGet实战教程:如何配置和使用镜像功能加速包下载
BaGet实战教程:如何配置和使用镜像功能加速包下载 【免费下载链接】BaGet A lightweight NuGet and symbol server 项目地址: https://gitcode.com/gh_mirrors/ba/BaGet BaGet是一款轻量级的NuGet和符号服务器,通过配置其镜像功能,开发…...

SecGPT-14B快速部署:镜像预置vLLM+Gradio+Supervisor,真正开箱即用
SecGPT-14B快速部署:镜像预置vLLMGradioSupervisor,真正开箱即用 1. 模型介绍 SecGPT-14B是一款专注于网络安全领域的文本生成大模型,基于Qwen2ForCausalLM架构开发,参数规模达到140亿。该模型经过大量网络安全相关数据的训练&a…...

基于下垂控制的光储直流微电网模型 1.模型由光伏和储能以及直流负载组成 2.光伏采用扰动观测法...
基于下垂控制的光储直流微电网模型1.模型由光伏和储能以及直流负载组成 2.光伏采用扰动观测法实现最大功率输出,储能刚开始采用恒定电压控制,电压稳定在额定电压附近,2s之后采用下垂控制,母线电压降低,达到目标光伏板在…...
 和 position 到底谁先? (错误位置触发物理事件))
Godot 4 2D 物理引擎位置初始化踩坑:add_child() 和 position 到底谁先? (错误位置触发物理事件)
Godot 4 2D 物理引擎位置初始化踩坑:add_child() 和 position 到底谁先? 在 Godot 4 做 2D 游戏时,很多人都会遇到一个很诡异的问题: 我明明想把一个 PackedScene 实例生成在 B 点,结果它却会在默认位置 A 点 短暂触发…...