二十九、微服务案例完善(数据聚合、自动补全、数据同步)
目录
一、定义
二、分类
1、桶(Bucket)聚合:
2、度量(Metric)聚合:
3、管道聚合(Pipeline Aggregation):
4、注意:
参与聚合的字段类型必须是:
三、使用DSL实现聚合
聚合所必须的三要素:
聚合可配置属性:
1、桶聚合
(1)自定义排序规则
(2)限定聚合范围
2、度量聚合
四、使用RestAPI实现聚合
1、对品牌进行聚合
2、对品牌、城市、星级进行聚合
1、在service中添加方法
2、在实现类中编写聚合方法
3、运行测试
3、与前端进行对接
1、增加controller方法
2、更改service方法
3、更改实现类方法
4、运行测试
五、拼音分词器
1、将py插件复制到此目录
2、重启es
3、测试
六、自定义分词器
1、自动补全字段
七、实现自动补全功能
1、删除原索引库
2、新建索引库
3、修改HotelDoc类,增加suggestion属性
4、重新做批处理
5、词条做切割处理,修改HotelDoc类
6、编写RestAPI
7、实现搜索框的输入补全
1、在controller中新增方法
2、在service中新建方法
3、实现方法
8、测试
八、数据同步
1、定义:
2、特点:
3、数据同步方案
(1)同步调用
优点:
缺点:
(2)异步通知
优点:
缺点:
(3)监听binlog
优点:
缺点:
一、定义
聚合( aggregations)可以实现对文档数据的统计、分析、运算。
二、分类
1、桶(Bucket)聚合:
-
用来对文档做分组
TermAggregation:按照文档字段值分组
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
2、度量(Metric)聚合:
- 用以计算一些值,比如:最大值、最小值、平均值等
- 计数(COUNT):计算指定列中非空值的数量。
- 求和(SUM):计算指定列中所有数值的总和。
- 平均值(AVG):计算指定列中所有数值的平均值。
- 最大值(MAX):查找指定列中的最大值。
- 最小值(MIN):查找指定列中的最小值。
3、管道聚合(Pipeline Aggregation):
- 管道聚合是MongoDB中一种强大的数据聚合工具,它可用于通过将多个聚合操作连接在一起来对文档进行处理。
- 通过管道聚合,MongoDB用户可以使用多个聚合操作按顺序执行,以生成更为复杂、细致和灵活的数据查询和汇总结果。
- 管道聚合可以处理来自单个或多个集合的数据。
一般而言,MongoDB 的聚合管道通过 $ 开头的操作符来实现数据聚合操作。以下是一些常见的聚合管道操作:
1. $match:用于选择满足条件的文档,可以通过使用查询条件来过滤文档。
2. $group:用于将文档分组,通过指定一个或多个字段进行分组,对每个分组执行聚合操作,最终返回每个组的统计结果。
3. $project:用于选择文档的特定字段,并输出指定的字段。
4. $sort:用于对文档进行排序,可以根据指定字段进行升序或降序排列。
5. $limit:用于限制输出文档的数量。
6. $skip:用于跳过指定数量的文档,并返回剩余的文档。
7. $unwind:用于展开数组属性,将数组属性的每个元素转换为一个单独的文档。
- 使用管道聚合,可以将以上操作有机地组合在一起,以实现各种复杂的聚合查询需求。
- 此外,MongoDB 还提供了许多其他的聚合管道操作,可以根据具体场景自由组合使用,方便用户进行数据处理和分析。
4、注意:
参与聚合的字段类型必须是:
- keyword
- 数值
- 日期
- 布尔
三、使用DSL实现聚合
聚合所必须的三要素:
- 聚合名称
- 聚合类型
- 聚合字段
聚合可配置属性:
- size:指定聚合结果数量
- order:指定聚合结果排序方式f
- ield:指定聚合字段
1、桶聚合
GET /hotel/_search
{"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandagg": { //给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", // 参与聚合的字段"size": 20 // 希望获取的聚合结果数量}}}
}
运行后,数据被按照品牌(brand)划分了

(1)自定义排序规则

(2)限定聚合范围

2、度量聚合
在分类的同时,进行了分数的计算,并且按照平均分做降序

GET /hotel/_search
{"size": 0,"aggs": {"brandagg": {"terms": {"field": "brand", "size": 20,"order": {"scoreAgg.avg": "desc"}},"aggs": {"scoreAgg": {"stats": {"field": "score"}}}}}
}四、使用RestAPI实现聚合
1、对品牌进行聚合

@Testvoid testAggregation() throws IOException {// 准备请求对象SearchRequest request = new SearchRequest();// 初始化 SearchSourceBuilderSearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// 设置 sizesourceBuilder.size(0);// 聚合sourceBuilder.aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(10));// 将 SearchSourceBuilder 设置到 SearchRequest 中request.source(sourceBuilder);// 发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 解析结果Aggregations aggregations = response.getAggregations();// 根据聚合名称获取聚合结果Terms brandTerms = aggregations.get("brandAgg");// 获取桶List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 遍历for (Terms.Bucket bucket : buckets) {String key = bucket.getKeyAsString();System.out.println(key);}}成功提取出品牌名
2、对品牌、城市、星级进行聚合
1、在service中添加方法

Map<String , List<String>> filters() throws IOException;2、在实现类中编写聚合方法
@Overridepublic Map<String, List<String>> filters() throws IOException {// 准备请求对象SearchRequest request = new SearchRequest();// 初始化 SearchSourceBuilderSearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// 设置 sizesourceBuilder.size(0);// 聚合buildAggs(sourceBuilder);// 将 SearchSourceBuilder 设置到 SearchRequest 中request.source(sourceBuilder);// 发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 解析结果HashMap<String, List<String>> result = new HashMap<>();Aggregations aggregations = response.getAggregations();// 根据名称,获得结果List<String> brandList = getAggByName(aggregations,"brandAgg");result.put("品牌",brandList);List<String> cityList = getAggByName(aggregations,"cityAgg");result.put("城市",cityList);List<String> starList = getAggByName(aggregations,"starAgg");result.put("星级",starList);return result;}private List<String> getAggByName(Aggregations aggregations,String aggName) {// 根据聚合名称获取聚合结果Terms brandTerms = aggregations.get(aggName);// 获取桶List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 遍历List<String > brandList = new ArrayList<>();for (Terms.Bucket bucket : buckets) {String key = bucket.getKeyAsString();brandList.add(key);}return brandList;}private void buildAggs(SearchSourceBuilder sourceBuilder) {sourceBuilder.aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));sourceBuilder.aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));sourceBuilder.aggregation(AggregationBuilders.terms("starAgg").field("starName").size(100));}3、运行测试

3、与前端进行对接
1、增加controller方法
@PostMapping("filters")public Map<String , List<String >> getFilters(@RequestBody RequestParams params){return service.filters(params);}2、更改service方法
Map<String , List<String>> filters(RequestParams params);3、更改实现类方法

@Overridepublic Map<String, List<String>> filters(RequestParams params) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.querybuildBasicQuery(params, request);// 2.2.设置sizerequest.source().size(0);// 2.3.聚合buildAggs(request);// 3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Map<String, List<String>> result = new HashMap<>();Aggregations aggregations = response.getAggregations();// 4.1.根据品牌名称,获取品牌结果List<String> brandList = getAggByName(aggregations, "brandAgg");result.put("brand", brandList);// 4.2.根据品牌名称,获取品牌结果List<String> cityList = getAggByName(aggregations, "cityAgg");result.put("city", cityList);// 4.3.根据品牌名称,获取品牌结果List<String> starList = getAggByName(aggregations, "starAgg");result.put("starName", starList);return result;} catch (IOException e) {throw new RuntimeException(e);}}4、运行测试

五、拼音分词器
1、将py插件复制到此目录
/var/lib/docker/volumes/es-plugins/_data/
2、重启es
docker restart es
3、测试
POST /_analyze
{"text": ["西巴仙人爱桃树"],"analyzer": "pinyin"
}把每个字都拆成了拼音

六、自定义分词器
elasticsearch中分词器(analyzer)的组成包含三部分:
lcharacter filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
ltokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
ltokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
// 自定义拼音分词器
PUT /test
{"settings": {"analysis": {"analyzer": { "my_analyzer": { "tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": { "type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}}
}1、自动补全字段
- elasticsearch提供了Completion Suggester查询来实现自动补全功能。
- 这个查询会匹配以用户输入内容开头的词条并返回。
为了提高补全查询的效率,对于文档中字段的类型有一些约束:
- 参与补全查询的字段必须是completion类型。
- 字段的内容一般是用来补全的多个词条形成的数组。
语法:
// 自动补全查询
GET /test/_search
{"suggest": {"title_suggest": {"text": "s", // 关键字"completion": {"field": "title", // 补全查询的字段"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
七、实现自动补全功能
1、删除原索引库
DELETE /hotel2、新建索引库
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}3、修改HotelDoc类,增加suggestion属性
private List<String> suggestion;this.suggestion = Arrays.asList(this.brand,this.business);
4、重新做批处理
@Testvoid testBulkRequest() throws IOException{
// 批量查询酒店数据List<Hotel> hotelList = iHotelService.list();
// 创建RequestBulkRequest request = new BulkRequest();
// 准备参数for (Hotel hotel : hotelList){
// 转换为文档类型HotelDocHotelDoc hotelDoc = new HotelDoc(hotel);
// 创建新增文档的Request对象request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSONString(hotelDoc),XContentType.JSON));}
// 发送请求client.bulk(request,RequestOptions.DEFAULT);}
5、词条做切割处理,修改HotelDoc类
// 有多个值,做切割String[] arr = this.business.split("/");this.suggestion = new ArrayList<>();this.suggestion.add(this.brand);Collections.addAll(this.suggestion,arr);}else {this.suggestion = Arrays.asList(this.brand,this.business);}
6、编写RestAPI
@Testvoid testSuggest() throws IOException {SearchRequest request = new SearchRequest("hotel");request.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix("h").skipDuplicates(true).size(10)));SearchResponse response = client.search(request, RequestOptions.DEFAULT);Suggest suggest = response.getSuggest();CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();for (CompletionSuggestion.Entry.Option option : options) {String string = option.getText().toString();System.out.println(string);}}
7、实现搜索框的输入补全
1、在controller中新增方法
@PostMapping("suggestion")public List<String> getSuggestion(@RequestParam("key") String prefix){return service.getSuggestions(prefix);}
2、在service中新建方法
List<String> getSuggestions(String prefix);
3、实现方法
@Overridepublic List<String> getSuggestions(String prefix) {try {
// 准备RequestSearchRequest request = new SearchRequest("hotel");request.source().suggest(new SuggestBuilder().addSuggestion("suggestions",SuggestBuilders.completionSuggestion("suggestion").prefix(prefix).skipDuplicates(true).size(10)));
// 发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 得到响应Suggest suggest = response.getSuggest();CompletionSuggestion suggestions = suggest.getSuggestion("suggestions");List<CompletionSuggestion.Entry.Option> options = suggestions.getOptions();ArrayList<String> list = new ArrayList<>(options.size());
// 遍历for (CompletionSuggestion.Entry.Option option : options) {String string = option.getText().toString();list.add(string);}return list;} catch (IOException e) {throw new RuntimeException(e);}}
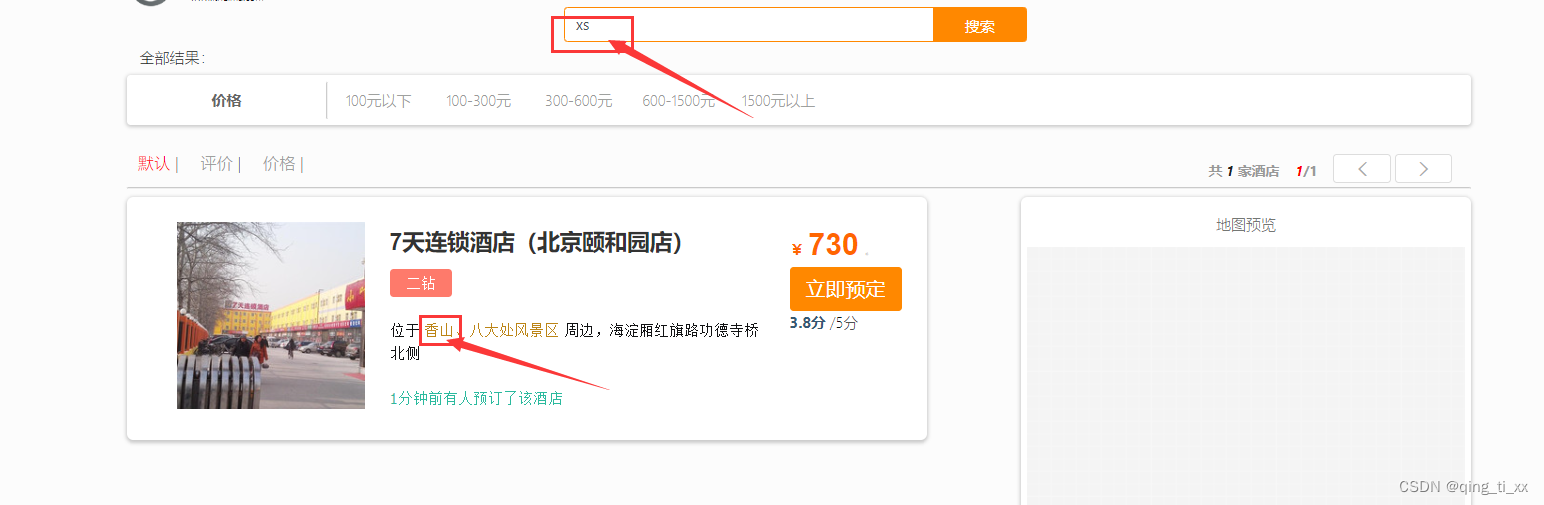
8、测试
八、数据同步
1、定义:
- 数据同步是指将一个数据源的数据与另一个数据存储系统中的数据保持更新的过程。
- 数据同步确保不同数据存储系统中的数据保持一致,从而支持企业在不同数据存储系统中的数据共享和协作。
2、特点:
数据同步是一个周期性的过程。数据同步通常需要从源系统读取数据,然后将数据传递到目标系统。这个过程可能需要经过多个步骤,如数据转换、数据清洗、数据映射等。一般情况下,数据同步是一个周期性的过程,定期将目标系统中的数据更新到最新状态。
数据同步的目标是确保数据的一致性。在数据同步的过程中,目标是确保源系统中的数据与目标系统中的数据保持一致。这样可以保证不同应用之间使用相同的数据。
数据同步需要考虑数据的安全性和完整性。在数据同步的过程中,数据的安全性和完整性必须得到保障。例如,在数据传输过程中,需要使用加密技术来保护敏感数据的机密性。
数据同步通常需要使用专业工具或平台。数据同步的过程需要使用专业工具或平台来完成。这些工具或平台通常提供了丰富的功能和技术,如数据清洗、数据转换、数据映射等,以确保数据同步的质量和效率。
数据同步可以提高企业效率和降低成本。通过数据同步,企业可以在不同部门和团队之间共享数据,从而更好地理解业务趋势和市场需求,进一步提高效率和降低成本。
3、数据同步方案
(1)同步调用

优点:
实现简单
缺点:
粗暴业务耦合度高
(2)异步通知

优点:
低耦合,实现难度一般依赖
缺点:
mq的可靠性
(3)监听binlog
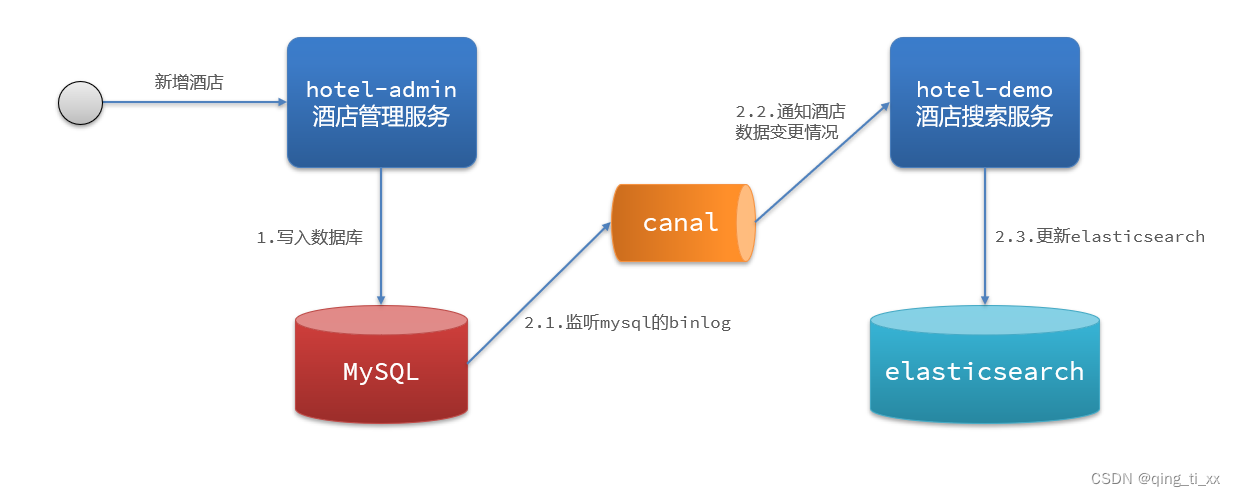
优点:
完全解除服务间耦合
缺点:
开启binlog增加数据库负担、实现复杂度高
数据同步案例实现方案
相关文章:
二十九、微服务案例完善(数据聚合、自动补全、数据同步)
目录 一、定义 二、分类 1、桶(Bucket)聚合: 2、度量(Metric)聚合: 3、管道聚合(Pipeline Aggregation): 4、注意: 参与聚合的字段类型必须是: 三、使用DSL实现聚合 聚合所必须的三要素: 聚合可配…...

vue 目录树的展开与关闭
目录 1、翻页方法中控制目录树节点的展开与关闭2、搜索目录树节点名称控制节点的展开与关闭 <el-tree:data"data_option"ref"tree":props"defaultProps"node-click"handleNodeClick":default-expanded-keys"needExpandedKeys&…...
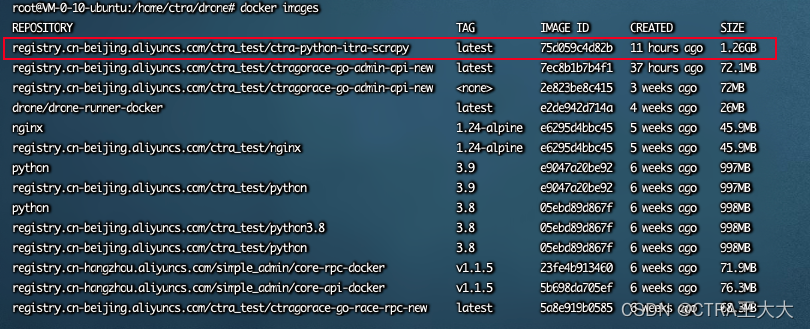
【Docker】python flask 项目如何打包成 Docker images镜像 上传至阿里云ACR私有(共有)镜像仓库 集成Drone CI
一、Python环境编译 1、处理好venv环境 要生成正常的 requirements.txt 文件,我们就需要先将虚拟环境处理好 创建虚拟环境(可选): 在项目目录中,你可以选择使用虚拟环境,这样你的项目依赖将被隔离在一个…...

力扣labuladong——一刷day55
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣951. 翻转等价二叉树二、力扣124. 二叉树中的最大路径和三、力扣112. 路径总和(遍历)四、力扣112. 路径总和(分解&a…...

springboot实现验证码功能
转载自 : www.javaman.cn 1、编写工具类生成4位随机数 该工具类主要生成从0-9,a-z,A-Z范围内产生的4位随机数 /*** 产生4位随机字符串*/public static String getCheckCode() {String base "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmn…...

内测分发平台是否支持应用的微服务化部署
内测分发平台的微服务化部署支持是现代应用开发和部署的一个重要特性。首先我们得知道什么是微服务化部署都有哪些关键功能,如何实施微服务化的部署。下文以我自己理解总结了几点。 图片来源:news.gulufenfa.com 微服务是一种基于独立运行的小型服务来构建应用程序…...

1140. 最短网络,prim算法,模板题
1140. 最短网络 - AcWing题库 农夫约翰被选为他们镇的镇长! 他其中一个竞选承诺就是在镇上建立起互联网,并连接到所有的农场。 约翰已经给他的农场安排了一条高速的网络线路,他想把这条线路共享给其他农场。 约翰的农场的编号是1…...

升级jdk17过程中,原来的jdk8下的webservice客户端怎样处理
背景:之前jdk8环境下,使用的cxf框架,而且是动态加载解析作为客户端。大家一直相处的很愉快。但是最近升级jdk17,发现cxf不好用了。网上百度,大部分都是说升级cxf版本,并且添加jaxb的相关依赖就可以了。但是…...

Verilog基本语法概述
一、概述 Verilog 是一种用于数字逻辑电路设计的硬件描述语言,可以用来进行数字电路的仿真验证、时序分析、逻辑综合。 既是一种 行为级(可用于电路的功能描述) 描述语言又是一种 结构性(可用于元器件及其之间的连接)…...
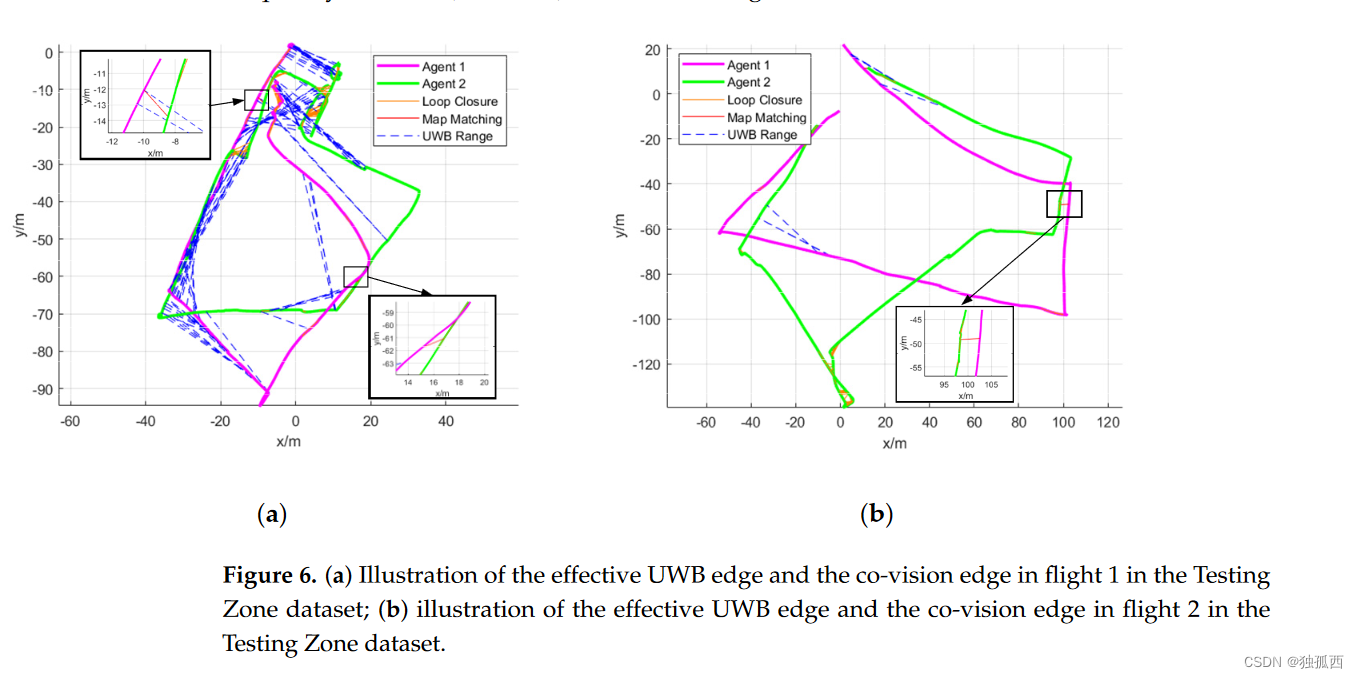
论文阅读:C2VIR-SLAM: Centralized Collaborative Visual-Inertial-Range SLAM
前言 论文全程为C2VIR-SLAM: Centralized Collaborative Visual-Inertial-Range Simultaneous Localization and Mapping,是发表在MDPI drones(二区,IF4.8)上的一篇论文。这篇文章使用单目相机、惯性测量单元( IMU )和UWB设备作为…...

蓝桥杯刷题day01——字符串中的单词反转
题目描述 你在与一位习惯从右往左阅读的朋友发消息,他发出的文字顺序都与正常相反但单词内容正确,为了和他顺利交流你决定写一个转换程序,把他所发的消息 message 转换为正常语序。 注意:输入字符串 message 中可能会存在前导空…...
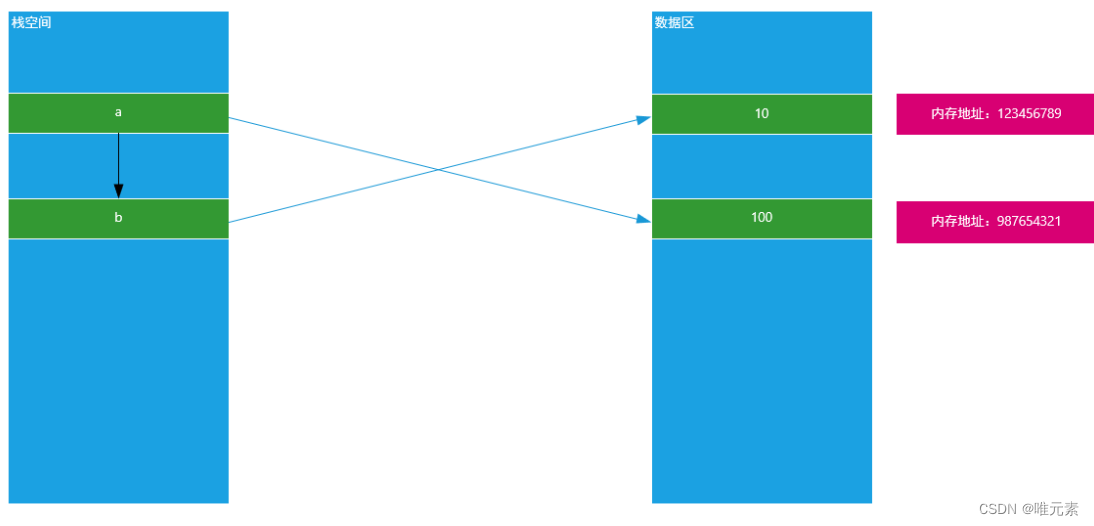
Python---引用变量与可变、非可变类型
引用变量 在大多数编程语言中,值的传递通常可以分为两种形式“ 值 传递 与 引用 传递”,但是在Python中变量的传递基本上都是引用传递。 变量在内存底层的存储形式 a 10 第一步:首先在计算机内存中创建一个数值10(占用一块…...

GDOUCTF2023-Reverse WP
文章目录 [GDOUCTF 2023]Check_Your_Luck[GDOUCTF 2023]Tea[GDOUCTF 2023]easy_pyc[GDOUCTF 2023]doublegame[GDOUCTF 2023]L!s![GDOUCTF 2023]润!附 [GDOUCTF 2023]Check_Your_Luck 根据 if 使用z3约束求解器。 EXP: from z3 i…...
Day43力扣打卡
打卡记录 子数组的最小值之和(乘法原理 单调栈) 大佬的题解 class Solution:def sumSubarrayMins(self, arr: List[int]) -> int:n len(arr)# 左边界 left[i] 为左侧严格小于 arr[i] 的最近元素位置(不存在时为 -1)left, s…...
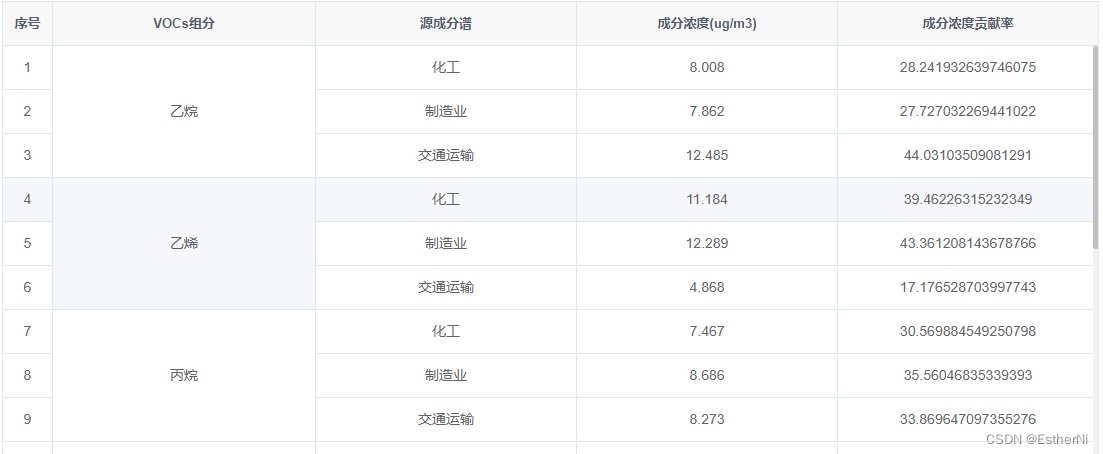
elementui的table合并列,三个一组
<el-table :span-method"objectSpanMethod" :cell-style"iCellStyle" :data"tableData" height"63vh" border style"width: 100%; margin-top: 6px"><el-table-column type"index" label"序号"…...

HarmonyOS-Service服务开发(一)
文章目录 创建新项目启动Serviceets获取service的bundleName DataAbility开发指导开发Data步骤创建Data 创建新项目 ServiceAbility开发指导 在config.json中也有配置出现 启动Service ets获取service的bundleName 项目的bundleName service的bundleName 这里serviceAbil…...

FLASK博客系列4——再谈路由
最近好像拖更有点久了。抱歉抱歉~ 今天我们继续来聊聊路由(其实就是我上次偷懒剩下一点没讲完)。 通过上次的文章,我们基本了解了Flask中的路由,是不是比较简单呢?别急,今天来点猛料。 一、路由之HTTP方法绑…...

sql之left join、right join、inner join的区别
sql之left join、right join、inner join的区别 left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录 right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录 inner join(等值连接) 只返回两个表中联结字段相等的行 举例如下࿱…...
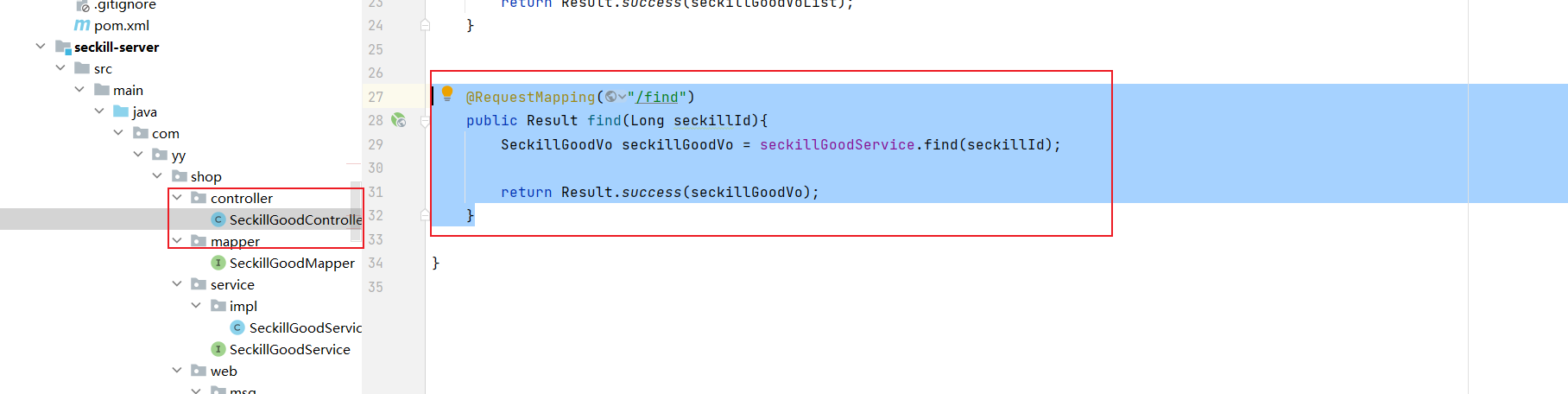
京东秒杀之秒杀详情
1 编写前端页面(商品详情) <!DOCTYPE html> <head><title>商品详情</title><meta http-equiv"Content-Type" content"text/html; charsetUTF-8" /><script type"text/javascript" src&…...
mobaxterm 下载、安装、使用
下载 官网 MobaXterm free Xserver and tabbed SSH client for Windows 下载页面 MobaXterm Xserver with SSH, telnet, RDP, VNC and X11 - Download 点击下载 安装 双击安装 勾选协议 修改安装路径 ,等待安装完成 使用 启动 新建连接 输入主机用户名和密…...

DeepSeek-OCR-2参数详解:DeepEncoder V2架构与vLLM推理优化实践
DeepSeek-OCR-2参数详解:DeepEncoder V2架构与vLLM推理优化实践 1. 引言:重新定义OCR的智能视觉理解 如果你还在用传统的OCR工具,每次处理复杂文档时都要忍受识别不准、版面混乱的烦恼,那么今天介绍的DeepSeek-OCR-2可能会彻底改…...

互联网大厂Java面试:从Spring Boot到Kafka的业务场景深度剖析
互联网大厂Java面试:从Spring Boot到Kafka的业务场景深度剖析 场景概述 谢飞机今天来到了一家知名互联网大厂参与Java开发岗位的面试,面试官是一位技术严谨且经验丰富的资深架构师。在这次面试中,问题围绕“电商场景”展开,涉及Sp…...
SQLZOO答案)
SQL学习记录(一)SQLZOO答案
SQL学习记录(一) 包含SELECT basics、SELECT names/zh、SELECT Quiz/zh 文章目录SQL学习记录(一)[0、SELECT basics](https://sqlzoo.net/wiki/SELECT_basics/zh)[1.1、 SELECT names/zh](https://sqlzoo.net/wiki/SELECT_names/z…...

逆向实战:药监局瑞数6vmp算法解析与突破
1. 瑞数6vmp算法初探 第一次接触药监局网站的瑞数6vmp防护时,我整个人都是懵的。打开开发者工具,熟悉的debugger断点就像机关枪一样疯狂弹出,控制台还时不时跳出"禁止输出"的警告。这种体验就像试图拆解一个会咬人的俄罗斯套娃&…...
)
收藏!8年开发转型AI大模型,踩遍坑后的真心话(小白/程序员必看)
做了8年后端开发,前几年一直在重复写业务逻辑、调接口、对接需求,在明确的需求边界里完成功能交付;直到两年前转型AI应用开发,从面对大模型“幻觉”时的手足无措,到如今能独立设计高可用、高可靠的AI服务,这…...

OpCore Simplify终极指南:3步快速构建黑苹果EFI配置
OpCore Simplify终极指南:3步快速构建黑苹果EFI配置 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 想在普通PC上运行macOS系统却担心复杂…...

高端局!追觅电视多项首创技术斩获10+国际国内大奖,实力封神
近期,追觅电视交出亮眼业绩成绩单,全球累计出货、专利申请、国际大奖等多项数据表现突出;同时,品牌集中推出五大全球首创及首发技术,将画质、护眼、动态声擎等可感知创新落地为产品体验,完美呼应“技术业绩…...

收藏!程序员小白必看:向量数据库VS知识图谱,大模型问答系统怎么选?
收藏!程序员小白必看:向量数据库VS知识图谱,大模型问答系统怎么选? 本文对比了向量数据库与知识图谱在代码知识库问答系统中的应用差异。向量数据库擅长捕捉语义相似性,但处理实体间结构化关系查询时存在局限ÿ…...

为什么选择Choices.js?轻量级选择框插件如何完胜Select2
为什么选择Choices.js?轻量级选择框插件如何完胜Select2 【免费下载链接】Choices A vanilla JS customisable select box/text input plugin ⚡️ 项目地址: https://gitcode.com/gh_mirrors/ch/Choices 在现代Web开发中,选择框(sele…...

Alienware灯光控制终极指南:轻量级工具完整解决方案
Alienware灯光控制终极指南:轻量级工具完整解决方案 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 还在为臃肿的Alienware Command Center…...