【MySQL】InnoDB中的索引
目录标题
- 索引底层的数据结构:B+树
- B树与B+树的区别
- InnoDB与MyISAM在B+树使用索引结构的不同?
- 聚簇索引
- 非聚簇索引
- 联合索引
- B+树索引适用的条件
- 查询
- 全值匹配
- 匹配左边的列
- 匹配列前缀
- 匹配范围的值
- 精确匹配某一列并范围匹配另外一列
- 避免使用隐式转换
- 排序
- 必须按照索引列的顺序
- 可以只使用索引列中左边 的列
- 不能ASC、DESC混用
- WHERE 子句中不能出现非排序使用到的索引列
- 排序列不能包含非同一个索引的列
- 排序列不能使用了复杂的表达式
- 分组
- 回表
- 回表较少的数据列
- 覆盖索引
- 索引下推
- 如何挑选索引
- 只为用于搜索、排序或分组的列创建索引
- 基数大的列建立索引
- 索引列的类型尽量小
- 考虑使用字符列前缀
- 索引列在比较表达式中单独出现
- 避免冗余和重复索引
- 主键索引拥有 AUTO_INCREMENT 属性
- 最左匹配原则
- 相关阅读
- 本篇以MySQL中的InnoDB引擎为主。
- 建立了索引不一定使用索引,只有在 二级索引 + 回表 的代价比全表扫描的代价更低时才会使用索引。而有一些列没有显式的建立索引,但是却是使用了索引。
- 注意:具体SQL语句是否采用索引、采用什么索引都取决于 查询优化器 。
- 对于使用InnoDB存储引擎的表来说,二级索引的记录只包含索引列和主键列的值,
- 聚簇索引中包含用户定义的全部列以及一些隐藏列,所以扫描二级索引的代价比直接全表扫描, 也就是扫描聚簇索引的代价价更低一些。
- 索引储存的数据结构?
- 建立索引的出发点,该怎么建?
- 索引的命中条件?最左匹配原则?
- 如何减少回表?
索引底层的数据结构:B+树
B树与B+树的区别
- 在叶子节点的存储上,B+树存储的是Key和data。而B树任务节点都可以存放Key和Data。
- B+树的叶子节点的引用链指向相邻的叶子结点(节点也就是双向链表哦,页内的记录是单链表哦),而B树的叶子节点都是孤单节点。
- 在范围查询时,B+树只需要对于叶子结点进行遍历,而 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限
InnoDB与MyISAM在B+树使用索引结构的不同?
在MyISAM中,B+树的data域中存储的是 主键索引 + 数据记录的地址(行号)。在索引检索的时候,首先检查 索引文件中的 叶子结点(存储 主键值 + 行号),如果指定的 Key 存在,则根据行号取出 数据文件 相应的记录(按照插入顺序)。(即:在MyISAM中,索引文件跟数据文件是分离的)
在InnoDB中,索引即数据,也就是聚簇索引的那棵B+树的叶子结点存储了所有完整的用户记录。而在其他二级索引时候,跟MyISAM实现的类似,B+树的叶子节点存储的是二级索引列 + 主键。
聚簇索引
在InnoDB 中,聚簇索引就是主键索引。
聚簇索引的特性:
- 使用 记录(数据列的)主键值的大小进行记录排序和页排序
- B+ 树的叶子节点存储的是完整的用户记录
- 目录项是
主键+页号的搭配。
InnoDB 存储引擎会自动的为我们创建聚簇索引。
在 InnoDB 存储引擎中, 聚簇索引 就是数据的存储方式(所有的用户记录都存储在了 叶子节点 ),也就是所谓的索引即数据,数据即索引。
非聚簇索引
非聚簇索引又称为二级索引,辅助索引。
非聚簇索引的特性:
- 使用记录的二级索引列进行记录排序和页排序
- B+ 树的叶子节点存储的是 记录的
二级索引列 + 主键 - 目录项变成了
记录的二级索引列 + 页号的搭配。
也就是说,我们还需要进行一次回表操作。
联合索引
同时为多个列建立索引,也就是以同时以多个列的大小作为排序规则
根据非聚簇索引的特性,我们很容易的得出:
假定,为 c2 和 c3 列建立的索引
- 每条 目录项记录 都由 c2 、 c3 、 页号 这三个部分组成,各条记录先按照 c2 列的值进行排序,如果记录 的 c2 列相同,则按照 c3 列的值进行排序。
- B+ 树叶子节点处的用户记录由 c2 、 c3 和主键 c1 列组成。
B+树索引适用的条件
CREATE TABLE person_info(id INT NOT NULL auto_increment,name VARCHAR(100) NOT NULL,birthday DATE NOT NULL,phone_number CHAR(11) NOT NULL,country varchar(100) NOT NULL,PRIMARY KEY (id),KEY idx_name_birthday_phone_number (name, birthday, phone_number)
);
- 创建了两颗B+树:聚簇索引
id以及 非聚簇索引idx_name_birthday_phone_number - 其中,
idx_name_birthday_phone_number索引对应的 B+ 树中页面和记录的排序方式就是- 先按照 name 列的值进行排序。
- 如果 name 列的值相同,则按照 birthday 列的值进行排序。
- 如果 birthday 列的值也相同,则按照 phone_number 的值进行排序。
查询
全值匹配
搜索列与索引列完全一致。
SELECT *
FROM person_info
WHERE name = 'Ashburn' AND birthday = '1990-09-27' AND phone_number = '15123983239';
-- 搜索条件的顺序对查询的执行过程没有影响
SELECT *
FROM person_info
WHERE birthday = '1990-09-27' AND phone_number = '15123983239' AND name = 'Ashburn';
匹配左边的列
搜索列只匹配左边的索引列,或包含多个左边的列。
如果我们想使用联合索引中尽可能多的列,搜索条件中的各个列必须是联合索引中 从最左边连续的列
SELECT * FROM person_info
WHERE name = 'Ashburn';SELECT * FROM person_info
WHERE name = 'Ashburn' AND birthday = '1990-09-27';
下面是个不走索引的例子:是因为 根据B+树组合索引的建立规则:name 列的值不同的记录中 birthday 的值可能是无序的。
SELECT *
FROM person_info
WHERE birthday = '1990-09-27';
匹配列前缀
对于字符串类型的索引列来说,我们只匹配 它的前缀也是可以快速定位记录的
SELECT *
FROM person_info
WHERE name LIKE 'As%';
下面是个不走索引的例子:如果只给出后缀或者中间的某个字符串
SELECT *
FROM person_info
WHERE name LIKE '%As%';
匹配范围的值
如果对多个列同时进行范围查找的话,只有对索引最左边的那个 列进行范围查找的时候才能用到 B+ 树索引
SELECT *
FROM person_info
WHERE name > 'Asa' AND name < 'Barlow';
对于联合索引 idx_name_birthday_phone_number 来说,只能用到 name 列的部分,而用不到 birthday 列 的部分,因为只有 name 值相同的情况下才能用 birthday 列的值进行排序,而这个查询中通过 name 进行范围查 找的记录中可能并不是按照 birthday 列进行排序的,所以在搜索条件中继续以 birthday 列进行查找时是用不到 这个 B+ 树索引的。
SELECT *
FROM person_info
WHERE name > 'Asa' AND name < 'Barlow' AND birthday > '1980-01-01';
(注意:

" 继续以 birthday 列进行查找是用不到 这个 B+ 树索引的 ",这句话不代表这个查询不走索引。事实上,使用 explain 会发现,这个查询语句还是执行了索引。为什么呢?这就是我们后面会说到的 索引下推)
精确匹配某一列并范围匹配另外一列
对于同一个联合索引来说,虽然对多个列都进行范围查找时只能用到最左边那个索引列,但是如果左边的列是精 确查找,则右边的列可以进行范围查找。
SELECT *
FROM person_info
WHERE
name = 'Ashburn'AND
birthday > '1980-01-01' AND birthday< '2000-12-31' AND
phone_number > '15100000000';
name = ‘Ashburn’ 和 birthday > ‘1980-01-01’ AND birthday < ‘2000-12-31’ 肯定能够用到索引。
对于 phone_number > ‘15100000000’ ,通过 birthday 的范围查找的记录的 birthday 的值可能不同,所以这个 条件无法再利用 B+ 树索引了,只能遍历上一步查询得到的记录。 (这个就是我们前面提到过一嘴的:即索引下推哦)
SELECT *
FROM person_info
WHERE name = 'Ashburn' AND birthday = '1980-01-01' AND AND phone_number > '15100000000';
避免使用隐式转换
MySQL性能优化:MySQL中的隐式转换造成的索引失效 - 夜月归途
通过上面的测试我们发现 MySQL 使用操作符的一些特性:
- 当操作符左右两边的数据类型不一致时,会发生隐式转换。
- 当 where 查询操作符左边为数值类型时发生了隐式转换,那么对效率影响不大,但还是不推荐这么做。
- 当 where 查询操作符左边为字符类型时发生了隐式转换,那么会导致索引失效,造成全表扫描效率极低。
- 字符串转换为数值类型时,非数字开头的字符串会转化为0,以数字开头的字符串会截取从第一个字符到第一个非数字内容为止的值为转化结果。
排序
索引列用于排序语句。
必须按照索引列的顺序
可以只使用索引列中左边 的列
对于 联合索引 有个问题需要注意, ORDER BY 的子句后边的列的顺序也必须按照索引列的顺序给出,或只使用索引列中左边 的列
SELECT *
FROM person_info
WHERE name = 'A'
ORDER BY birthday, phone_number LIMIT 10;
这个索引使用联合索引进行排序是因为 name 列的值相同的记录是按照 birthday , phone_number 排序的
不能ASC、DESC混用
SELECT *
FROM person_info
ORDER BY name, birthday DESC
LIMIT 10;
这个不会使用索引排序,因为:如果使用索引排序的话过程就是这样的:
- 先从索引的最左边确定 name 列最小的值,然后找到 name 列等于该值的所有记录,然后从 name 列等于该值 的最右边的那条记录开始往左找10条记录。
- 如果 name 列等于最小的值的记录不足10条,再继续往右找 name 值第二小的记录,重复上边那个过程,直 到找到10条记录为止。
WHERE 子句中不能出现非排序使用到的索引列
SELECT *
FROM person_info
WHERE country = 'China'
ORDER BY name
LIMIT 10;
这个查询只能先把符合搜索条件 country = ‘China’ 的记录提取出来后再进行排序,是使用不到索引
排序列不能包含非同一个索引的列
SELECT *
FROM person_info
ORDER BY name, country
LIMIT 10;
name 和 country 并不属于一个联合索引中的列,所以无法使用索引进行排序
排序列不能使用了复杂的表达式
索引进行排序操作,必须保证索引列是以单独列的形式出现,而不是修饰过的形式
SELECT *
FROM person_info
ORDER BY UPPER(name)
LIMIT 10;
使用了 UPPER 函数修饰过的列就不是单独的列啦,这样就无法使用索引进行排序啦。
分组
使用 B+ 树索引进行排序是一个道理,分组列的顺序也需要和索引列的顺序一致,也可以只使用索引列中左边 的列进行分组
SELECT name, birthday, phone_number, COUNT(*)
FROM person_info
GROUP BYname, birthday, phone_number
回表
用 idx_name_birthday_phone_number 索引为例,下面的这个查询就会用到回表
SELECT *
FROM person_info
WHERE name > 'Asa' AND name < 'Barlow';
- 从索引 idx_name_birthday_phone_number 对应的 B+ 树中取出 name 值在 Asa ~ Barlow 之间的用户记录。
- 由于索引idx_name_birthday_phone_number 对应的 B+ 树用户记录中只包含 name 、 birthday 、 phone_number 、 id 这4个字段,而查询列表是 * ,意味着要查询表中所有字段,也就是还要包括 country 字段。
- 这时需要把从上一步中获取到的每一条记录的 id 字段都到聚簇索引对应的 B+ 树中找到完整的用户记 录,也就是我们通常所说的
回表然后把完整的用户记录返回给查询用户。
因此,需要回表的记录越多,使用二级索引的性能就越低,甚至让某些查询宁愿使用全表扫描也不使用 二级索引 。
回表较少的数据列
减少回表的次数,可以查询获取较少的记录数会让优化器更倾向于选择使用 二级索引 + 回表
SELECT *
FROM person_info
WHERE name > 'Asa' AND name < 'Barlow'
LIMIT 10;
覆盖索引
为了彻底告别 回表 操作带来的性能损耗,最好在查询列表里只包含索引列,
比如这样:
SELECT name, birthday, phone_number
FROM person_info
WHERE name > 'Asa' AND name < 'Barlow'
索引下推
索引条件下推(Index Condition Pushdown,ICP),就是过滤的动作由下层的存储引擎层通过使用索引来完成,而不需要上推到Server层进行处理。
例如:对于联合索引 idx_name_birthday_phone_number 来说:
SELECT *
FROM person_info
WHERE name > 'Asa' AND name < 'Barlow' AND birthday > '1980-01-01';
对于上述的查询语句,
- InnoDB使用联合索引查出所有
'Asa' < name < 'Barlow'的二级索引数据,假设得到得到10w个主键值; - 拿到主键索引进行回表,到聚簇索引中拿到这10w个完整的用户记录;
- InnoDB把这10w条完整的用户记录返回给MySQL的Server层,在Server层过滤出
birthday >'1980-01-01'的唯一的用户。
而使用了索引下推:
我们第一步已经通过联合索引查出所有 'Asa' < name < 'Barlow' 的10w个数据,而且birthday字段也恰好在联合索引的叶子节点的记录中。这个时候可以直接在联合索引的叶子节点中进行遍历,筛选出birthday >'1980-01-01'记录,找到唯一的那条记录,最后只需要进行1次回表操作即可找到符合全部条件的1条记录,返回给Server层。
如何挑选索引
只为用于搜索、排序或分组的列创建索引
SELECT birthday, country
FROM person name
WHERE name = 'Ashburn';
像查询列表中的 birthday 、 country 这两个列就不需要建立索引,我们只需要为出现在 WHERE 子句中的 name 列创建索引就可以了。
基数大的列建立索引
列的基数 指的是某一列中不重复数据的个数,比方说某个列包含值 2, 5, 8, 2, 5, 8, 2, 5, 8 ,虽然有 9 条 记录,但该列的基数却是 3 。
最好为那些列的基数大的列建立索引,为基数 太小列的建立索引效果可能不好。
索引列的类型尽量小
- 数据类型越小,在查询时进行的比较操作越快(这是CPU层次的东东)
- 数据类型越小,索引占用的存储空间就越少,在一个数据页内就可以放下更多的记录,从而减少磁盘 I/O 带 来的性能损耗,也就意味着可以把更多的数据页缓存在内存中,从而加快读写效率。
考虑使用字符列前缀
二级索引的记录中只保留字符串前几个字符。
这样在查找记录时虽然不能精确的定位 到记录的位置,但是能定位到相应前缀所在的位置,然后根据前缀相同的记录的主键值回表查询完整的字符串 值,再对比就好了。
这样只在 B+ 树中存储字符串的前几个字符的编码,既节约空间,又减少了字符串的比较时 间,还大概能解决排序的问题
CREATE TABLE person_info(name VARCHAR(100) NOT NULL,birthday DATE NOT NULL,phone_number CHAR(11) NOT NULL,country varchar(100) NOT NULL,KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)
);
name(10) 就表示在建立的 B+ 树索引中只保留记录的前 10 个字符的编码,
索引列在比较表达式中单独出现
也就是索引列进行做了其他操作,例如数值计算、使用函数、(手动或自动)类型转换等操作,会导致索引失效。
1. WHERE my_col * 2 < 4 ×
2. WHERE my_col < 4/2 √
避免冗余和重复索引
冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。
主键索引拥有 AUTO_INCREMENT 属性
尽可能少的让 聚簇索引 发生页面分裂和记录移位的情况
最左匹配原则
从上面就可以得出来最左匹配原则的定义咯:
在使用组合索引时,
- 搜索列必须全部为索引列
- 搜索列可以为部分索引列,但是部分索引列必须满足顺序性
- 搜索列的范围查询,搜索列的最左边的列才会用到索引
- 排序条件、分组条件与搜索列一致,要么全部为索引列,要么部分索引列必须满足顺序性
相关阅读
联合索引的最左匹配原则_:_https://mp.weixin.qq.com/s/8qemhRg5MgXs1So5YCv0fQ
图解|索引覆盖、索引下推以及如何避免索引失效:https://zhuanlan.zhihu.com/p/481750465
MySQL是怎样运行的:https://book.douban.com/subject/35231266/
相关文章:
【MySQL】InnoDB中的索引
目录标题 索引底层的数据结构:B树B树与B树的区别InnoDB与MyISAM在B树使用索引结构的不同? 聚簇索引非聚簇索引联合索引 B树索引适用的条件查询全值匹配匹配左边的列匹配列前缀匹配范围的值精确匹配某一列并范围匹配另外一列避免使用隐式转换 排序必须按照…...
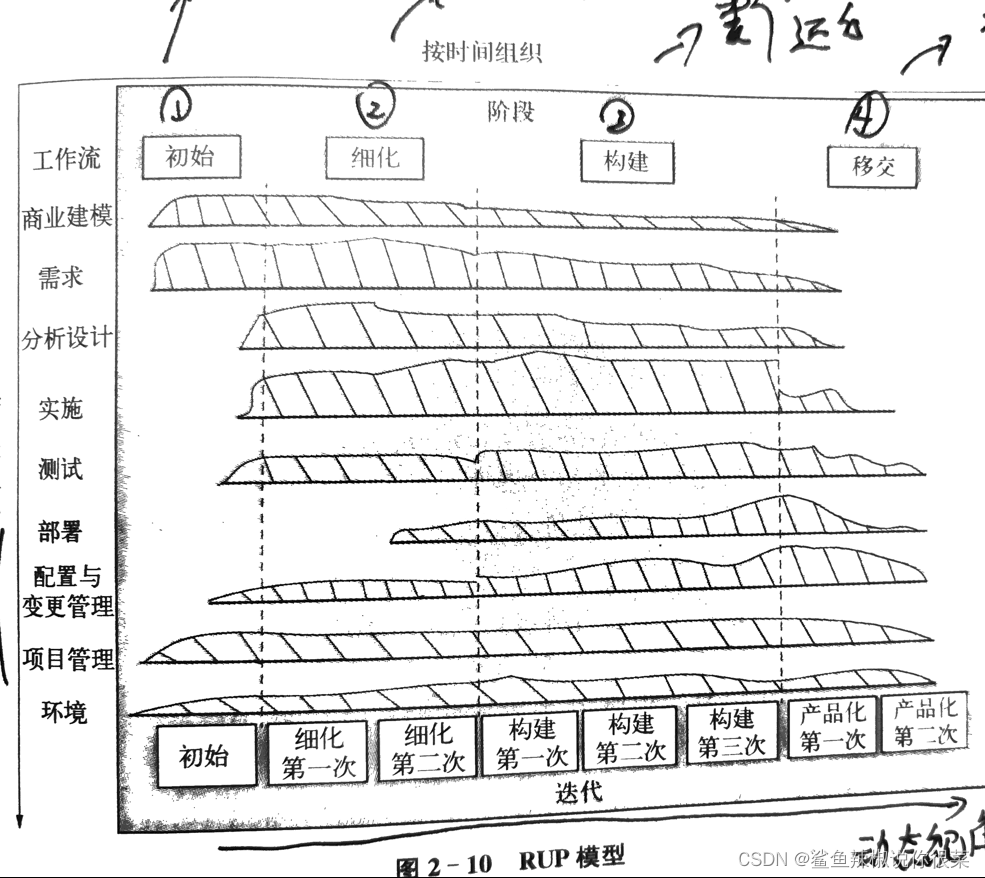
《软件工程原理与实践》复习总结与习题——软件工程
软件生命周期 软件生命周期分为三个时期、八个阶段 软件定义时期: 1)问题定义阶段:要解决什么问题 2)可行性研究阶段:确定软件开发可行 3)需求分析阶段:系统做什么 软件开发时期:…...

软工2021上下午第六题(组合模式)
阅读下列说明和Java代码,将应填入(n)处的字句写在答题纸的对应栏内。 【说明】 层叠菜单是窗口风格的软件系统中经常采用的一种系统功能组织方式。层叠菜单中包含的可能是一个菜单项(直接对应某个功能),也可…...

在Spring Boot中使用不同的日志
前言,本篇就是介绍在Java中使用相关的日志,适合初学者看,如果对这篇不感兴趣的可以移步了,本篇主要围绕我们Java中的几种日志类型,也说不上有多深入,算的上浅入浅出吧,如果你有一段时间的开发经…...

运维知识点-openResty
openResty 企业级实战——畅购商城SpringCloud-网站首页高可用解决方案-openRestynginxlua——实现广告缓存测试企业级实战——畅购商城SpringCloud-网站首页高可用解决方案-openRestynginxlua——OpenResty 企业级实战——畅购商城SpringCloud-网站首页高可用解决方案-openRes…...
微服务中配置Nacos热更新
启动Nacos startup.cmd -m standalone 在IDE中启动服务 打开nacos管理后台并选择配置列表 创建配置(这里以日期格式为例) 因为这里配置的是userservice的服务,所以在userservice服务的pom文件中引入依赖 配置一个bootstrap.yml文件 注意这里bootstrap文件中配置过的内容,在app…...
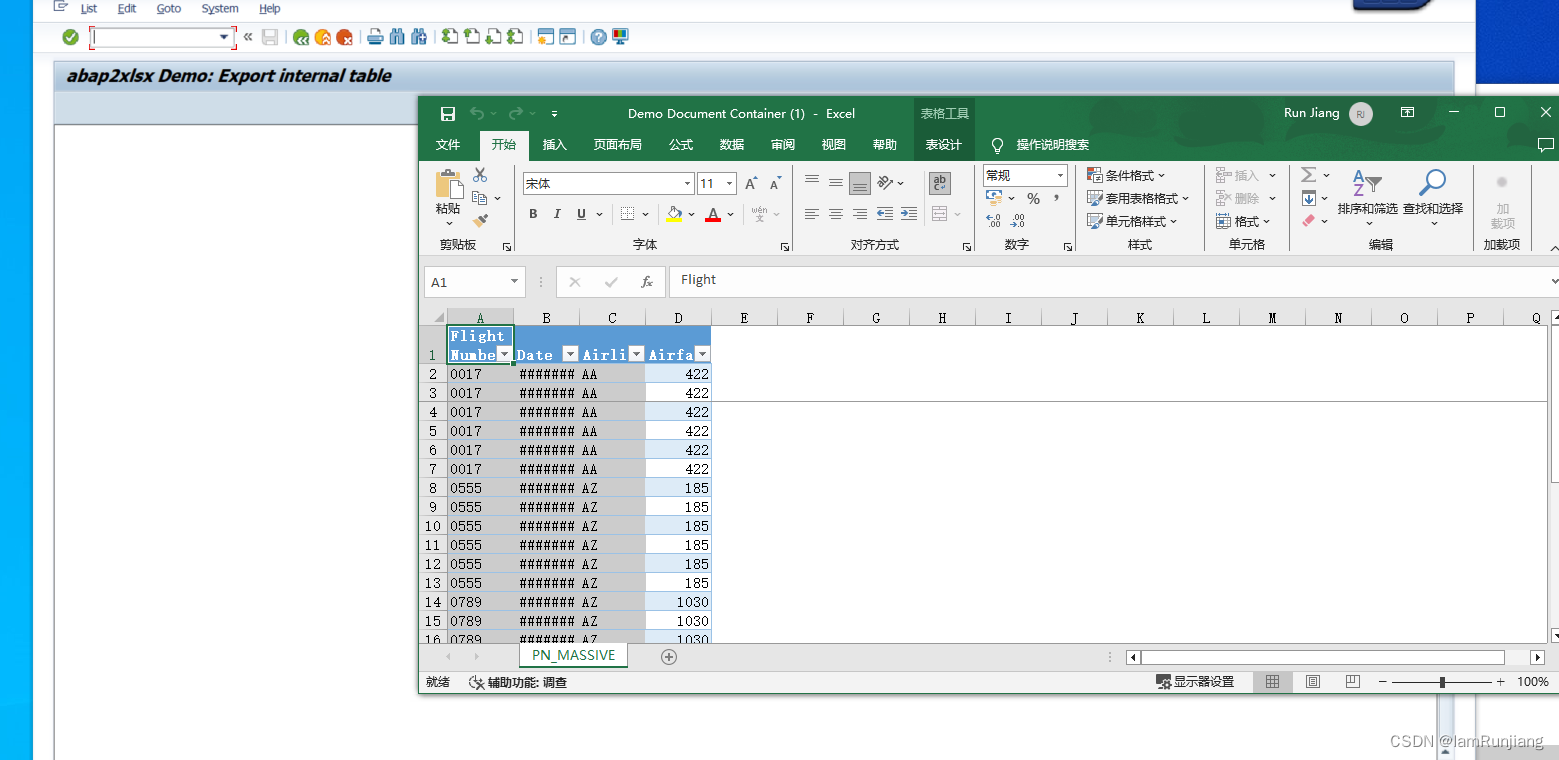
ABAP2XLSX 的安装和demo
ABAP2XLSX 是一个git上面的很好用的工具,它可以帮助abaper们更方便,更简单的生成各种各样复杂的自定义的excel,以满足各企业的信息化建设 在安装这个之前,请先查看之前的博客,去安装abapgit abap2xlsx地址࿱…...
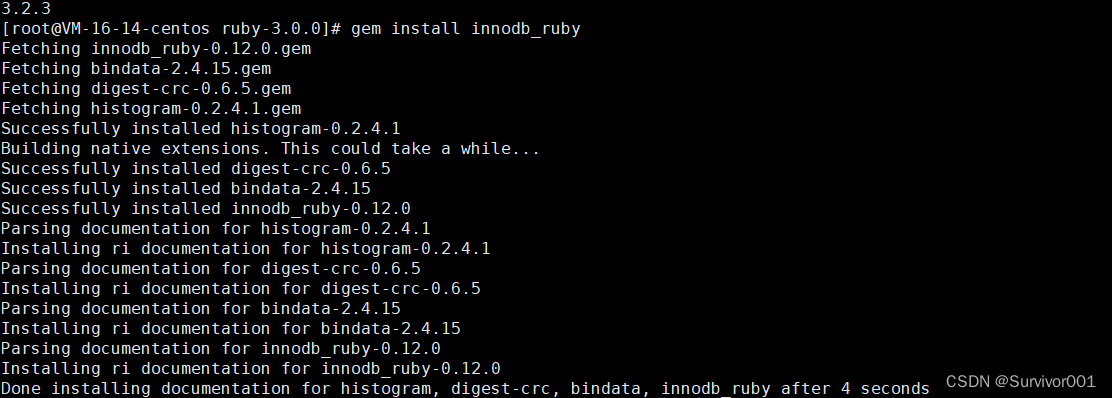
记一篇Centos7安装innodb_ruby
安装innodb_ruby过程非常坎坷,这里记录下安装过程,有些坑当时没有记录下来,主要把完成安装过程就记录下来 yum安装ruby默认的会安装ruby2.0.0版本,但是在安装innodb_ruby时,会报错,提示至少需要2.4版本以上…...
VMware虚拟机安装和使用教程(附最新安装包+以ubuntu为例子讲解)
目录 一、VMware Workstation 17 Pro 简介 二、新功能与改进 三、安装教程 3.1、下载安装包 3.2、运行安装包 四、创建虚拟机 五、启动虚拟机 六、总结与展望 一、VMware Workstation 17 Pro 简介 VMware Workstation 17 Pro是VMware公司为专业用户打造的一款虚拟化软件…...

c语言 / 指针错误的几种情况
1.未初始化的指针,直接释放 int *p; //计算机随机指向一片内存 2.free一个指针,指针没有指向NULL,直接使用 int *p(int *)malloc(sizeof(int)); free(p); //p依旧指向释放前内存的地址, 但是这片内存已经被释放, 被其他变量重新使用, 正…...
Stable-Diffusion——Windows部署教程
Windows 参考文章:从零开始,手把手教你本地部署Stable Diffusion Webui AI绘画(非最新版) 一键脚本安装 默认环境安装在项目路径的venv下 conda create -n df_env python3.10安装pytorch:(正常用国内网就行) python -…...

Day60.算法训练
912. 排序数组 归并排序 class Solution {public int[] sortArray(int[] nums) {int lo 0;int hi nums.length - 1;int[] assist new int[nums.length];sortArray(nums, assist, lo, hi);return nums;}private void sortArray(int[] nums, int[] assist, int lo, int hi) …...

深入了解Java8新特性-日期时间API之TemporalQuery、TemporalQueries
阅读建议 嗨,伙计!刷到这篇文章咱们就是有缘人,在阅读这篇文章前我有一些建议: 本篇文章大概2000多字,预计阅读时间长需要5分钟。本篇文章的实战性、理论性较强,是一篇质量分数较高的技术干货文章&#x…...
记录一次现网问题排查(分享查域名是否封禁小程序)
背景: 收到工单反馈说现网业务一个功能有异常,具体现象是tc.hb.cn域名无法访问,客户地区是河南省,这里记录下排查过程和思路。 首先梳理链路 客户端域名 tc.hb.cn cname—> domainparking-dnspod.cn(新加坡clb)—> snat—&…...

linux下实现Qt程序实现开机自启动
1.原理 要想实现开机自启动,首先,QT是没有这种实现的,最好是靠电脑开机的启动目录启动软件,下面这个目录 /etc/xdg/autostart 这是操作系统中用于配置启动项的目录,该目录下存放着开机自启动的启动器(.desktop)文件…...
TCP 基本认识
1:TCP 头格式有哪些? 序列号:用来解决网络包乱序问题。 确认应答号:用来解决丢包的问题。 2:为什么需要 TCP 协议? TCP 工作在哪一层? IP 层是「不可靠」的,它不保证网络包的交付…...

智慧城市包括哪些内容?有哪些智慧城市物联网方案?
数字城市、智慧城市的发展,离不开对公共基础设施的数字化、智慧化改造升级。通过融合边缘计算、5G、物联网、数字孪生、人工智能等新一代信息技术,助力传统公共基础设施提升增强全流程数据能力、计算能力、服务能力,从而不断丰富公共基础设施…...

Arkts@Watch装饰器与内置组件双向同步深度讲解与实战应用【鸿蒙专栏-14】
文章目录 ArkTS 状态管理深度解析:@Watch 和 $$ 运算符的妙用@Watch 装饰器:状态变量的敏感监听装饰器说明语法说明观察变化和行为表现限制条件使用场景$$ 运算符:内置组件状态的双向同步使用规则使用示例ArkTS 深度探索:@Watch 装饰器与 $$ 运算符的进阶应用进阶应用:@Wa…...
iMazing是什么软件?2024最新版本如何下载
iMazing是一款功能强大的iOS设备管理软件,它可以帮助用户备份和管理他们的iPhone、iPad或iPod Touch上的数据。除此之外,它还可以将备份数据转移到新的设备中、管理应用程序、导入和导出媒体文件等。本文将详细介绍iMazing的功能和安全性,并教…...
LeetCode(40)同构字符串【哈希表】【简单】
目录 1.题目2.答案3.提交结果截图 链接: 同构字符串 1.题目 给定两个字符串 s 和 t ,判断它们是否是同构的。 如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。 每个出现的字符都应当映射到另一个字符࿰…...

无机布防火卷帘门报价透明,包工包料,一次说清所有费用
很多客户在选购无机布防火卷帘门时,最关心实际成交价格,也担心报价不清晰,后期产生各类额外支出。行业内产品定价参差不齐,选材做工不同,最终价位自然存在差距,挑选时不能只看表面低价。 👉 点击…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...
)
从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表)
更多请点击: https://codechina.net 第一章:从单体到事件驱动的生死跃迁:DeepSeek架构委员会认证的6阶段迁移路线图(含风险热力图与回滚触发阈值表) 向事件驱动架构(EDA)演进不是功能迭代&…...

实测对比,使用Taotoken聚合接口后Agent任务延迟与稳定性观感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测记录:使用 Taotoken 聚合接口后 Agent 任务延迟与稳定性观感 效果展示类,记录将原有基于单一 API 的 A…...

使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置多开发环境下的统一模型接入点 在团队协作或管理多个AI应用项目时,一个常见的痛点是每个…...

为什么92%的数据库重构失败?Claude设计辅助如何在48小时内规避反范式陷阱?
更多请点击: https://codechina.net 第一章:为什么92%的数据库重构失败?——反范式陷阱的本质溯源 数据库重构失败率高达92%,其核心症结并非技术能力不足,而是对“反范式”这一设计策略的误读与滥用。许多团队在性能压…...

掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南
掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款开源…...