优化-查询数据接口太慢
有一个查询接口,主业务表有几万多条数据,没超过十万,由于没有使用分页,所以每次查询都要返回大几万的数据,然后问题是前端页面查询数据显示数据要转很久。
压缩响应体大小
我发现查询的时间是1秒多,但是浏览器调式看到接口花的时间是3秒多。
发现是响应体太大了,响应体有21.97MB,下载花了两秒多。

查询资料得知,http请求需要下载响应体,如果响应体太大会导致Content Download时间过长,下载HTTP响应的时间(包含头部和响应体)。
优化措施:
1、通过条件Get请求,对比If-Modified-Since和Last-Modified时间,确定是否使用缓存中的组件,服务器会返回“304 Not Modified”状态码,减小响应的大小;
2、移除重复脚本,精简和压缩代码,如借助自动化构建工具grunt、gulp等;
3、压缩响应内容,服务器端启用gzip压缩,可以减少下载时间;
响应体太大,服务器开启响应压缩:
server:compression:# 开启压缩enabled: true# 压缩的响应内容mime-types:- application/json- application/xml- application/javascript- text/html- text/xml- text/plain- text/css- text/javascript# 响应体大小达到2048kb才压缩min-response-size: 2048开启后确实下载内容花的时间变短了很多:

响应下载的时间的打下来了,但是等待服务器响应的时间还是有点长,就是接口的问题了。先去看程序有没有问题,执行了一下发现窗口一直再打印查询条目,因为查询的条数很多,他会将每条查询出来的条目row打印出来,于是把mybatis的日志配置先注释了,结果真的快了很多。但还是不够快。程序上检查了一圈,感觉没的优化了,就去看查询的sql语句。
#MyBatis相关配置
mybatis:mapperLocations: classpath*:/mapper/*.xmltypeAliasesPackage: com.huishi.entityconfiguration:map-underscore-to-camel-case: false
# log-impl: org.apache.ibatis.logging.stdout.StdOutImpl改用:
logging:level:com.lin.mapper: debugSQL语句
这是这个接口的主要查询sql:
SELECTEC1.CLASS_CODE CLASSCODE1,EC2.CLASS_CODE CLASSCODE2,EC3.CLASS_CODE CLASSCODE3,EI.ID, EI. EQUIPMENT_CODE, EI. ISSUE_SERIES_CODE, EI. OLD_SELF_CODE, EI. EQUIP_NAME, EI. EQUIP_TYPE, EI. USE_DEPART, EI. SCOUT_SYSTEM, EI.CLASS_CODE, EI. "USAGE", EI. MISSION, EI. EQUIP_POS, EI. MANAGER, EI. FIX_DEPART, EI. EQUIP_NUM, EI. EQUIP_UNIT_PRICE, EI.EQUIP_SUM_PRICE, EI. EQUIP_STATUS, EI. USE_STATUS, EI. QUALITY_LEVEL, EI. GIVEN_DATE, EI. START_USE_DATE, EI. PRODUCE_DATE, EI. PRODUCE_FACTORY, EI.BATCH_CODE, EI. USE_DEPART_CODE, EI. SEQUENCE_CODE, EI. COMM_INFO, EI. EQUIP_CONF, EI. COUNT_FLAG, EI. MARK_FLAG, EI. EQUIP_SOURCE, EI. IP_ADDRESS, EI. UPDATE_TIME, EI. CABI_CODE, EI.IS_GENERAL, EI. IMAGE_PATH1, EI. IMAGE_PATH2, EI. FUNDS_SOURCE, EI. FORCE_SYSTEM, EI. SERVICE_LIFE, EI. UNIT_CODE, EI. DOC_IDFROM EQUIPMENT_INFO EILEFT JOIN DICT_EQUIPMENT_CLASS1 EC1 ON EC1.CLASS_NAME = trim(SUBSTR(EI.CLASS_CODE, 1, INSTR(EI.CLASS_CODE, '/', 1, 1) - 1))LEFT JOIN DICT_EQUIPMENT_CLASS2 EC2 ON EC2.CLASS_NAME = trim(SUBSTR(EI.CLASS_CODE, INSTR(EI.CLASS_CODE, '/', 1, 1) + 1, INSTR(EI.CLASS_CODE, '/', 1, 2) - INSTR(EI.CLASS_CODE, '/', 1, 1) - 1))LEFT JOIN DICT_EQUIPMENT_CLASS3 EC3 ON EC3.CLASS_NAME = trim(SUBSTR(EI.CLASS_CODE, INSTR(EI.CLASS_CODE, '/', 1, 2) + 1))where EI.DEL_FLAG = '0' and EI.USE_STATUS != '已报废'索引方案
CREATE INDEX 索引名 ON 表名(列名);除了单列索引,还可以创建包含多个列的复合索引。
CREATE INDEX 索引名 ON 表名(列名1, 列名2, 列名3, ...);删除索引也非常简单。
DROP INDEX 索引名;查看某个表中的所有索引也同样简单。
SELECT * FROM ALL_INDEXES WHERE TABLE_NAME = '表名'还可以查看某个表中建立了索引的所有列。
SELECT * FROM ALL_IND_COLUMNS WHERE TABLE_NAME = '表名'常见的就是给自动添加索引了。
给经常在where后面的字段加了索引,查看sql的执行计划:
EXPLAIN PLAN FOR my_querySql;SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY);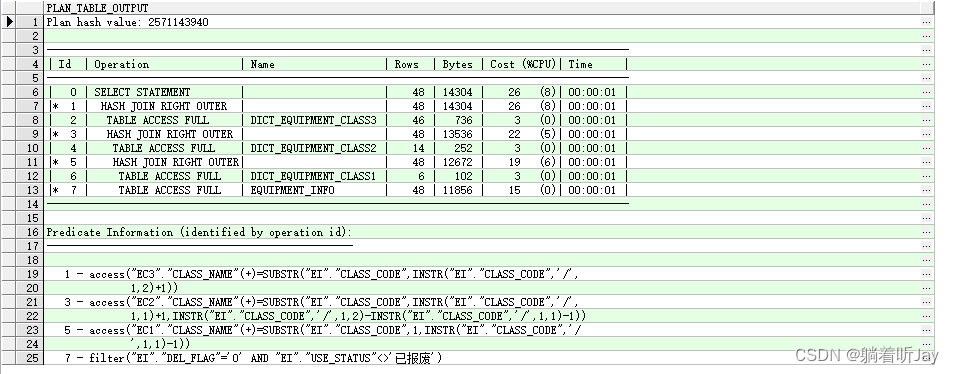
Plan hash value: 查询执行计划的哈希值,用于唯一标识这个执行计划。
Id: 操作的标识符,表示执行计划中每个操作的顺序。
Operation: 执行计划中的操作类型。这里包含了一些操作,如SELECT STATEMENT(选择语句)、HASH JOIN(哈希连接)和TABLE ACCESS FULL(全表扫描)等。
Name: 操作所涉及的表或索引的名称。
Rows: 操作返回的行数估计。
Bytes: 操作返回的数据字节数估计。
Cost (%CPU): 操作的成本估计和 CPU 使用百分比。这是一个估算值,表示执行这个操作的开销。
Time: 操作预计的执行时间。
Id 0-7是执行的序号,缩进最多的最先执行,缩进一样,上面的先执行。
cost越大的说明花费时间越久。
table access full说明还是全表扫描
但是查看sql的执行计划,发现还是全表扫描,那就是索引失效了。
`where EI.DEL_FLAG = '0' and EI.USE_STATUS != '已报废'` != 会导致USE_STATUS索引失效,于是我改成:where EI.DEL_FLAG = '0' and EI.USE_STATUS = '新品' or EI.USE_STATUS = '发料中' or EI.USE_STATUS = '送修中' or EI.USE_STATUS = '调拨中'or EI.USE_STATUS = '发料中' or EI.USE_STATUS = '库存中' or EI.USE_STATUS = '借料中' or EI.USE_STATUS = '故障' or EI.USE_STATUS = '在用'但是好像还是没走索引,查了一下,发现如果查询的数据量超过表数据的30%,索引就会失效,因为全表扫还更快 。这样看加索引这个方案好像不适合当前的业务需求,因为这个接口查询的数据量大,索引根本就没用啊!!!
分区表
查询到分区表也能加快查询速度。
如果 EQUIPMENT_INFO 表非常大,考虑将其分成多个分区表。分区可以减轻查询时需要扫描的数据量。
分区策略:包括按日期范围、按某个特定列的值范围、按地理区域等划分数据。
按使用状态分区:
创建分区表:
CREATE TABLE "EQUIPMENT_INFO_co"( "ID" NUMBER(20,0) NOT NULL ENABLE, ...."USE_STATUS" VARCHAR2(20) DEFAULT '在用', .....)
PARTITION BY LIST ("USE_STATUS")
(PARTITION new_items VALUES ('新品'),PARTITION pending_scrapped VALUES ('待报废'),PARTITION in_repair VALUES ('送修中'),PARTITION in_transfer VALUES ('调拨中'),PARTITION in_issue VALUES ('发料中'),PARTITION in_stock VALUES ('库存中'),PARTITION on_loan VALUES ('借料中'),PARTITION faulty VALUES ('故障'),PARTITION in_use VALUES ('在用'),PARTITION scrapped VALUES ('已报废')
);--查看分区数据,查看use_status是新品的
SELECT * FROM EQUIPMENT_INFO_co PARTITION (new_items);--修改分区表
ALTER TABLE EQUIPMENT_INFO
MODIFY PARTITION BY LIST (USE_STATUS)
(PARTITION new_items VALUES ('新品'),PARTITION pending_scrapped VALUES ('待报废'),PARTITION in_repair VALUES ('送修中'),PARTITION in_transfer VALUES ('调拨中'),PARTITION in_issue VALUES ('发料中'),PARTITION in_stock VALUES ('库存中'),PARTITION on_loan VALUES ('借料中'),PARTITION faulty VALUES ('故障'),PARTITION in_use VALUES ('在用'),PARTITION scrapped VALUES ('已报废')
);--修改分区表,并指定表空间
ALTER TABLE EQUIPMENT_INFO
MODIFY PARTITION BY LIST (USE_STATUS)
(PARTITION new_items VALUES ('新品') TABLESPACE PARTITION1,PARTITION pending_scrapped VALUES ('待报废') TABLESPACE PARTITION1,PARTITION in_repair VALUES ('送修中') TABLESPACE PARTITION1,PARTITION in_transfer VALUES ('调拨中') TABLESPACE PARTITION1,PARTITION in_issue VALUES ('发料中') TABLESPACE PARTITION1,PARTITION in_stock VALUES ('库存中') TABLESPACE PARTITION1,PARTITION on_loan VALUES ('借料中') TABLESPACE PARTITION1,PARTITION faulty VALUES ('故障') TABLESPACE PARTITION1,PARTITION in_use VALUES ('在用') TABLESPACE PARTITION1,PARTITION scrapped VALUES ('已报废') TABLESPACE PARTITION1
);这个分区表搞半天感觉没啥用,
缓存数据
有一些常用的数据可以在项目启动的时候放到redis中,来提高数据查询的响应速度。
因为这个查询接口的数据是读多写少的场景,所以我打算把这个查询的数据在项目启动的时候就放到缓存中,然后在监测这张表,当数据发生变更的时候,更新缓存中的数据。
/*** 项目启动时,会执行PostConstruct注释的方法。将查询的数据缓存到redis中。*/@PostConstructpublic void init(){System.out.println("初始化数据==============");redisCache.setCacheMap(Constants.EQUIPMENT_TYPE_NUM_CACHE_KEY,equipTypeMapNum);}将查询的数据放到缓存后,这个查询的数据直接到redis中取就好,这样查询的速度的确快了挺多。
然后数据库写个触发器,当那张表的数据发生变更使用UTL_HTTP向程序发送http请求接口,接口就会更新redis中的数据。
创建用于发送http请求的存储过程:
CREATE OR REPLACE PROCEDURE send_http_get_request (p_url IN VARCHAR2
) ASreq utl_http.req;res utl_http.resp;
BEGIN-- 打开HTTP请求req := utl_http.begin_request(p_url, 'GET', 'HTTP/1.1');-- 设置请求头utl_http.set_header(req, 'Content-Type', 'application/json');-- 执行HTTP请求res := utl_http.get_response(req);-- 处理HTTP响应,例如提取响应内容-- res.status_code, res.reason_phrase, utl_http.get_response_text(res)-- 关闭HTTP请求utl_http.end_response(res);
EXCEPTIONWHEN OTHERS THEN-- 处理异常NULL;
END;-- 创建触发器,当EQUIPMENT_INFO表发生insert update delete变更时触发
CREATE OR REPLACE TRIGGER equipment_info_change_trigger2
AFTER INSERT OR UPDATE OR DELETE ON EQUIPMENT_INFO
FOR EACH ROW
BEGIN--发送http请求通知程序表变更-- 调用发送HTTP请求的存储过程send_http_get_request('http://127.0.0.1:8082/dataChange?tableName=equipment_info');
END;但是这样还有个问题。如果你数据经常变更就不要这样做,或者你一次变更变更好几条也不要,因为数据变更一条就发送一个http请求,程序更新一次。这样就会导致http请求接口变的非常慢,因为会有很多个请求同时过来,因为这个更新数据的接口本来就执行的慢(要查询数据,更新redis中的数据),你如果很多变更,会卡死程序,别我我为啥呜呜呜。
这边Oracle发送http请求会有个问题
创建或更新访问控制列表(ACL): 在Oracle数据库中,需要配置访问控制列表 (ACL),以允许数据库用户或角色访问外部网络资源。在这里,我们将创建一个新的 ACL。
BEGINDBMS_NETWORK_ACL_ADMIN.create_acl (acl => 'your_acl_name.xml',description => 'ACL for UTL_HTTP',principal => 'YOUR_DATABASE_USER', -- 替换为实际的数据库用户is_grant => TRUE,privilege => 'connect',start_date => NULL,end_date => NULL);DBMS_NETWORK_ACL_ADMIN.assign_acl (acl => 'your_acl_name.xml',host => '127.0.0.1', -- 替换为实际的目标主机lower_port => NULL,upper_port => NULL);COMMIT;
END;授权访问: 确保你的数据库用户拥有执行 UTL_HTTP 包中的过程和函数的权限。你可以使用以下命令为用户授权:
GRANT EXECUTE ON UTL_HTTP TO YOUR_DATABASE_USER; -- 替换为实际的数据库用户批量请求返回数据
最终方案
以上的做法虽然都是方案,但是都有一定缺点,而且是影响挺大的。后面想了想,既然一次性返回这么多数据会慢,那就批量返回。
让前端第一次发送这个查询接口的时候,请求1000条数据回去先展示后,接着马上又发请求请求10000条数据,如果返回的数据条数少于10000,就不要继续发了,反之继续发。这样用户就不会感受到慢,1000先给他看,后面的数据继续发。这样客户就是无感的,不会感受到慢。其实就是隐式分页。
有哪位看到这给指点,看有没有更好的方案。
相关文章:
优化-查询数据接口太慢
有一个查询接口,主业务表有几万多条数据,没超过十万,由于没有使用分页,所以每次查询都要返回大几万的数据,然后问题是前端页面查询数据显示数据要转很久。 压缩响应体大小 我发现查询的时间是1秒多,但是浏…...

c++ 谓词
1. 一元谓词 #include <iostream> #include<vector> #include<algorithm>using namespace std;class CreaterFive{ public:bool operator()(int val){return val>5;} };int main() {vector<int> vec;for(int i0; i<10; i){vec.push_back(i);}ve…...

一篇总结 Linux 系统启动的几个汇编指令
学习 Linux 系统启动流程,必须熟悉几个汇编指令,总结给大家。 这里不是最全的,只列出一些最常用的汇编指令。 一.数据处理指令 1.数据传送指令 【MOV指令】 把一个寄存器的值(立即数)赋给另一个寄存器,或者将一个…...
python技术栈之单元测试中mock的使用
什么是mock? mock测试就是在测试过程中,对于某些不容易构造或者不容易获取的对象,用一个虚拟的对象来创建以便测试的测试方法。 mock的作用 特别是开发过程中上下游未完成的工序导致当前无法测试,需要虚拟某些特定对象以便测试…...
LeetCode(37)矩阵置零【矩阵】【中等】
目录 1.题目2.答案3.提交结果截图 链接: 73. 矩阵置零 1.题目 给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。 示例 1: 输入:matrix [[1,1,1],[1,0,1],[1,1,1]…...

[Python入门系列之十一]在windows上安装OpenCV
1-安装OpenCV 如果是python3.7–python3.9(已测试),直接安装即可 注:conda需要先激活虚拟环境后再安装 pip install opencv-python如果安装速度慢,使用下面的指令: pip install opencv-python -i https://pypi.tuna.tsinghua.e…...
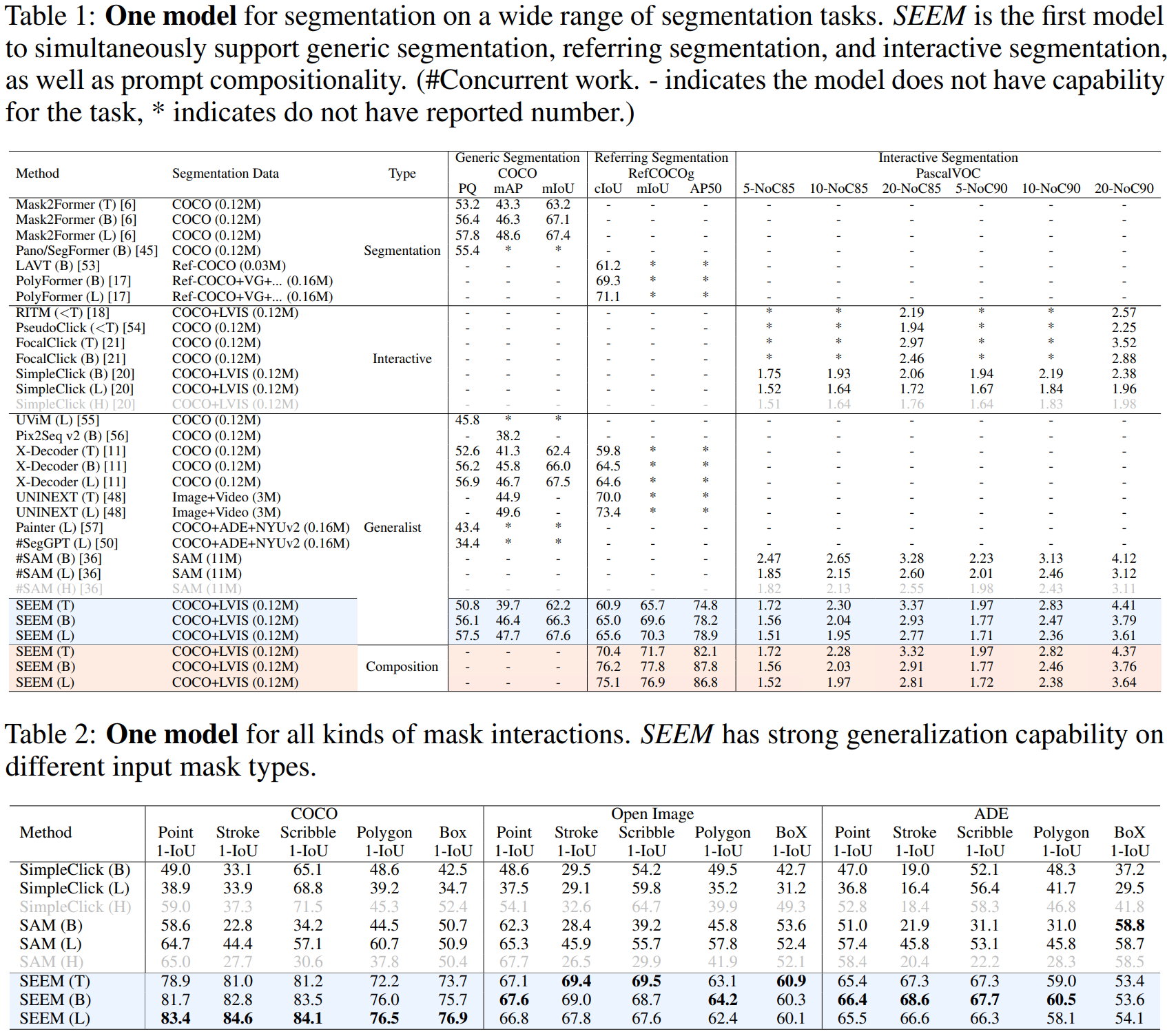
论文阅读——SEEM
arxiv: 分割模型向比较灵活的分割的趋势的转变:封闭到开放,通用到特定、one-shot到交互式。From closed-set to open-vocabulary segmentation,From generic to referring segmentation,From one-shot to interactive segmentati…...
Python入门06布尔值
目录 1 什么是布尔值2 怎么生成布尔值3 在控制程序中使用布尔值4 数据过滤、排序和其他高级操作总结 1 什么是布尔值 首先我们要学习一下布尔值的定义,布尔值是一种数据类型,它只有两个可能的值:True(真)或 False&…...

js查询详情接口控制执行时间的命令
在JavaScript中,可以使用console.time()和console.timeEnd()来控制执行时间的命令。 console.time()用于开始计时,可以指定一个标识符作为参数,用于标识计时器。 console.time(query); // 执行查询操作 console.timeEnd(query); 执行上述代…...
Linux系统iptables
目录 一. 防火墙简介 1. 防火墙定义 2. 防火墙分类 ①. 网络层防火墙 ②. 应用层防火墙 二. iptables 1. iptables定义 2. iptables组成 ①. 规则表 ②. 规则链 3. iptables格式 ①. 管理选项 ②. 匹配条件 ③. 控制类型 四. 案例说明 1. 查看规则表 2. 增加新…...

每日一题 1410. HTML 实体解析器(中等,模拟)
模拟,没什么好说的 class Solution:def entityParser(self, text: str) -> str:entityMap {": ",': "",>: >,<: <,⁄: /,&: &,}i 0n len(text)res []while i < n:isEntity Falseif …...
Docker Swarm总结+service创建和部署、overlay网络以及Raft算法(2/5)
博主介绍:Java领域优质创作者,博客之星城市赛道TOP20、专注于前端流行技术框架、Java后端技术领域、项目实战运维以及GIS地理信息领域。 🍅文末获取源码下载地址🍅 👇🏻 精彩专栏推荐订阅👇🏻…...

对抗产品团队中的认知偏误:给产品经理的专家建议
今天的产品经理面临着独特的挑战。他们不仅需要设计和构建创新功能,还必须了解这些功能将如何为客户带来价值并推进关键业务目标。如果不加以控制,认知偏差可能会导致您构建的内容与客户想要的内容或业务需求之间不一致。本文将详细阐述产品经理可以避免…...

element-ui表格无法横向拖动问题
是不是用到了fixed // 因为我只有在小屏显示不下的时候才会出现这个问题所以我在这里做了适配(建议把样式放在全局) media screen and (max-width: 1800px) {// 由于使用了fixed导致横向条无法拖动出现bug.Table-page .el-table__fixed {height: auto !important;bottom: 2px …...

每天学习一点点之 MySQL TINYINT
我已经不是第一次遇到关于 TINYINT 的问题了。在 MySQL 中,当我们将某个字段设置为 TINYINT,随着业务的扩展,我们可能会发现 TINYINT 的范围无法满足需求。这时需要修改字段属性。但如果表的数据量很大,或者由于分表导致涉及的表数…...

【数据集】未来不同情景下预测数据:如人口、土地利用等
未来不同情景下预测数据:如人口、土地利用等 1 人口数据1.1 Global One-Eighth Degree Population Base Year and Projection Grids Based on the SSPs, v1.01 (2000 – 2100)数据介绍数据下载1.2 Global dataset of gridded population and GDP scenarios数据介绍数据下载2…...

TDA4VM EVM开发板调试笔记
文章目录 1. 前言2. 官网资料导读3. 安装 Linux SDK4. 制作SD 启动卡5. 验证启动1. 前言 TDA4作为一般经典的车规级SOC芯片,基于它的低阶智驾方案目前成为各家智驾方案公司的量产首选,这也使得基于TDA4的开发需求陡增,开发和使用TDA4既要熟悉Linux驱应用开发,还要熟悉传统…...

项目里边更换了同名的图片地址 / 图片没有及时更新 / 什么原因
一、问题分析 1.1、分析一 浏览器缓存 项目里边更换了同名的图片地址,图片没有及时更新 可能是浏览器缓存的原因,浏览器会将之前访问过的文件缓存下来,下次访问同名的文件时会先从缓存中读取。 如果相同的图片地址没有发生变化,…...
RandomAccessFile学习笔记
文章目录 RandomAccessFile学习笔记前言1、RandomAccessFile基本介绍1.1 RandomAccessFile相关基本概念1.2 RandomAccessFile家族体系 2、RandomAccessFile基本使用2.1 RandomAccessFile常用API介绍2.2 RandomAccessFile常用API演示2.3 RandomAccessFile实现断点续传 RandomAcc…...
主流数据库类型总结
前言:随着互联网的高速发展,为了满足不同的应用场景,数据库的种类越来越多容易混淆,所以有必要在此总结一下。数据库根据数据结构可分为关系型数据库和非关系型数据库。非关系型数据库中根据应用场景又可分为键值(Key-…...

OpenWebUI 到底解决了什么,没解决什么?
先说结论OpenWebUI 把多模型切换、对话管理、参数调整从命令行搬到了浏览器,交互体验接近 ChatGPT,但部署本身有硬性前提。免费内网穿透方案有 24 小时域名更换限制,固定域名需付费,远程访问稳定性取决于网络环境。对于只跑单个模…...

2000-2025年地市级数字技术创新水平
数字技术创新水平是衡量地级及以上城市在政府工作报告中系统提及数字技术相关词汇密度的综合指标,用以反映该地区数字技术创新活动的活跃程度与发展态势。本数据集基于全国地级及以上城市的政府工作报告文本构建,覆盖各年度、各城市的官方政策表述。核心…...

Legacy iOS Kit:让旧款iPhone/iPad重获新生的终极指南
Legacy iOS Kit:让旧款iPhone/iPad重获新生的终极指南 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...
ATB:让 Transformer 推理快得像开了挂——昇腾算子加速库技术解析
Transformer 模型推理的瓶颈在哪里?KV Cache 管理、算子融合、分布式调度。ATB(ascend-transformer-boost)把这些问题一次性解决,让推理性能提升 2-3 倍。 上个月帮一个团队做推理优化,他们的 LLaMA-2 70B 模型在 NPU …...

PubMed文献批量下载完整指南:5步快速获取百篇文献的免费工具
PubMed文献批量下载完整指南:5步快速获取百篇文献的免费工具 【免费下载链接】Pubmed-Batch-Download Batch download articles based on PMID (Pubmed ID) 项目地址: https://gitcode.com/gh_mirrors/pu/Pubmed-Batch-Download 你是否曾为手动下载PubMed文献…...

量子机器学习优化微波脉冲:从量子门到物理控制的降噪增效实践
1. 项目概述与核心价值在量子计算这个充满潜力但也布满荆棘的领域里,我们每天都在和两个“天敌”作斗争:噪声和退相干。你辛辛苦苦制备的量子态,可能还没来得及完成一次完整的计算,就已经被环境噪声“污染”得面目全非。传统的纠错…...

如何在Windows电脑上安装安卓应用:APK安装器完整教程
如何在Windows电脑上安装安卓应用:APK安装器完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK安装器是一款专为Windows系统设计的安卓应用安装工…...

Godot 4.0桌面应用开发实战:跨平台GUI工程化落地指南
1. 这不是游戏引擎的“副业”,而是桌面开发的新路径很多人第一次看到“用Godot做桌面应用”时,下意识会皱眉:一个标榜“2D/3D游戏开发”的引擎,去碰文件管理器、RSS阅读器、本地笔记工具这类传统桌面软件?是不是大炮打…...

taotoken api key的权限细分与审计日志对安全管理的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken api key的权限细分与审计日志对安全管理的价值 在构建基于大模型的应用时,API Key 的管理往往是安全链条中最…...

解锁AMD Ryzen隐藏性能:一款开源调试工具如何让你成为硬件调优高手
解锁AMD Ryzen隐藏性能:一款开源调试工具如何让你成为硬件调优高手 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…...