Java开发 - 分页查询初体验
前言
在上一篇,我们对es进行了深入讲解,相信看过的小伙伴已经能基本掌握es的使用方法,我们知道,es主要针对的是搜索条件,在这方面es具有无可比拟的优势,但我们也会注意到,有时候搜索条件过于宽泛的时候,搜索结果集也将是非常庞大的,不仅服务器接口压力大,用户等的也很为难,为了解决这一问题,必须要对返回的数据进行处理,此时,分页就出现了,接下来,博主讲带两大家了解查询时的分页问题,并解决这个问题。
什么是分页查询
如上所述,分页查询是在返回数据量比较庞大时,为了能提高用户的体验,减少等待时间,而产生的一种数据分段方式,体现在展示层上就是数据的上拉加载,我们经常可以在购物类app上见到这样的设定,大多数情况下我们一页数据都为10条,大概是10条基本能满足查看一屏的需求和减少用户的等待时间的缘故,这是在移动端,在pc上可能略有不同,但基本都会以10的倍数存在。这便是分页查询。
分页查询的优点
分页查询的有点其实在上文中都已经说明,此处做一个总结,主要体现在三点上:
服务器
一次性查询所有信息,服务器压力过大,分页查询则可以降低服务器压力。
客户端
一次性显示所有信息,需要更多流量,加载更久,分页显示则可以解决这个问题。
用户体验
良好的用户体验可以让用户在应用上花费更多的时间,才能够提高购买率,也是服务商所希望的。最重要的一点,用户才不会放弃当前使用的应用。而且一般查询的数据都是会排序的,所以有价值的数据都会在前几页。
es的分页查询
前文es中没有对分页查询做说明,我们接上一篇的结尾,在项目中继续操作,但在说分页前,我们需要先对排序做一个了解,es的排序写法其实和SQL很相似,这在前文中我们已经有所见识,下面就一起来看看吧。
排序
排序和上一篇结尾的单条件/多条件查询都属于条件查询,我们在Repository类中来写一下怎么进行排序,在类中添加如下方法:
// 排序查询
// 默认情况下,ES查询结果按score排序,如果想按其他的规则排序可以加OrderBy
// 和数据库一样,默认升序排序 Desc结尾会降序Iterable<People> queryItemsByNameMatchesOrderByBraveDesc(String name, Double brave);接着进行测试,在测试类中添加如下测试方法:
// 排序查询@Testvoid queryOrder(){Iterable<People> items=peopleRepository.queryItemsByNameMatchesOrderByBraveDesc("西游");items.forEach(item -> System.out.println(item));}提示:在测试前,务必保证es处于启动状态,由于不是当天写的,所以es停止了,运行后发现报错,启动es后正常,下面看运行结果:
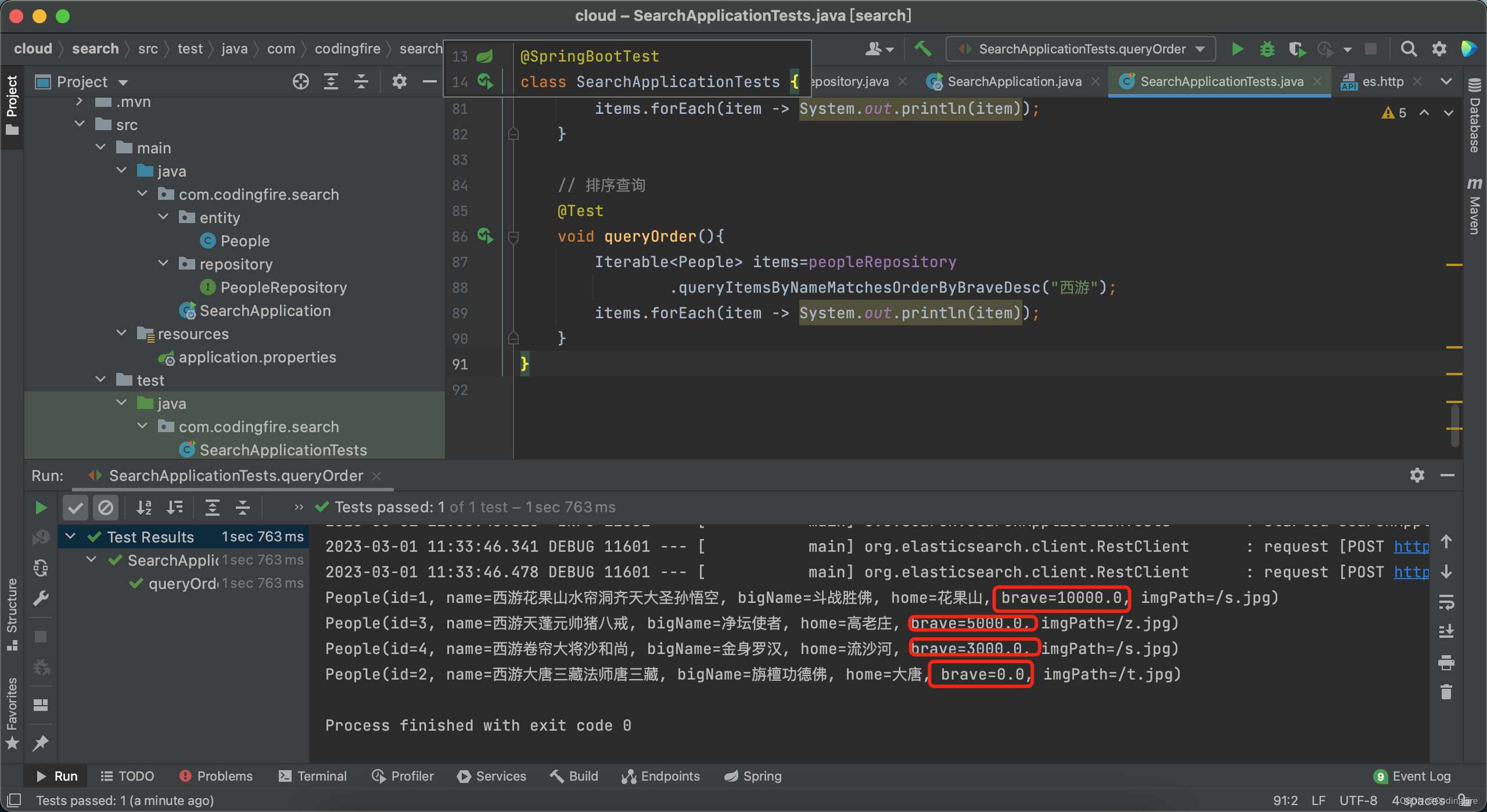
是按照我们想要的战力进行的排序,测试成功,你成功了吗?
来看看底层的代码逻辑:
### 单字段搜索排序
POST http://localhost:9200/peoples/_search
Content-Type: application/json{"query": {"match": { "name": "西游" }},"sort":[{"brave":"desc"}]
}可以在条件中增加其他的条件进行尝试。
分页加排序
我们在使用es时用了SpringData框架,其支持分页查询,只需要修改参数和返回值就能实现自动分页的效果,这就帮我们省去了很多的代码和功夫,下面让我们来看看它是怎么分页的。
我们以刚刚的排序为例,在其基础上进行修改,额外增加一个方法:
// 分页查询
// 当查询数据较多时,我们可以利用SpringData的分页功能,按用户要求的页码查询需要的数据
// 返回值修改为Page类型,这个类型对象除了包含Iterable能够包含的集合信息之外,还包含分页信息Page<People> queryItemsByNameMatchesOrderByBraveDesc(String name, Pageable pageable);接着我们开始进行测试,由于我们数据量比较少,我们会把每页的数据设置的很少,看看代码怎么写:
// 分页查询@Testvoid queryPage(){int pageNum=1; //页码int pageSize=2; //每页条数Page<People> page= peopleRepository.queryItemsByNameMatchesOrderByBraveDesc("西游", PageRequest.of(pageNum-1,pageSize));page.forEach(item -> System.out.println(item));// page对象中还包含了一些基本的分页信息System.out.println("总页数:"+page.getTotalPages());System.out.println("当前页:"+page.getNumber());System.out.println("每页条数:"+page.getSize());System.out.println("当前页是不是首页:"+page.isFirst());System.out.println("当前页是不是末页:"+page.isLast());}我们在这里要注意分页的起始页,程序中我们第一位总是0开始的,但在生活中都是从1开始的,为了让主观上认为从1开始,我们在内部做减1操作。
运行测试代码,查看结果:
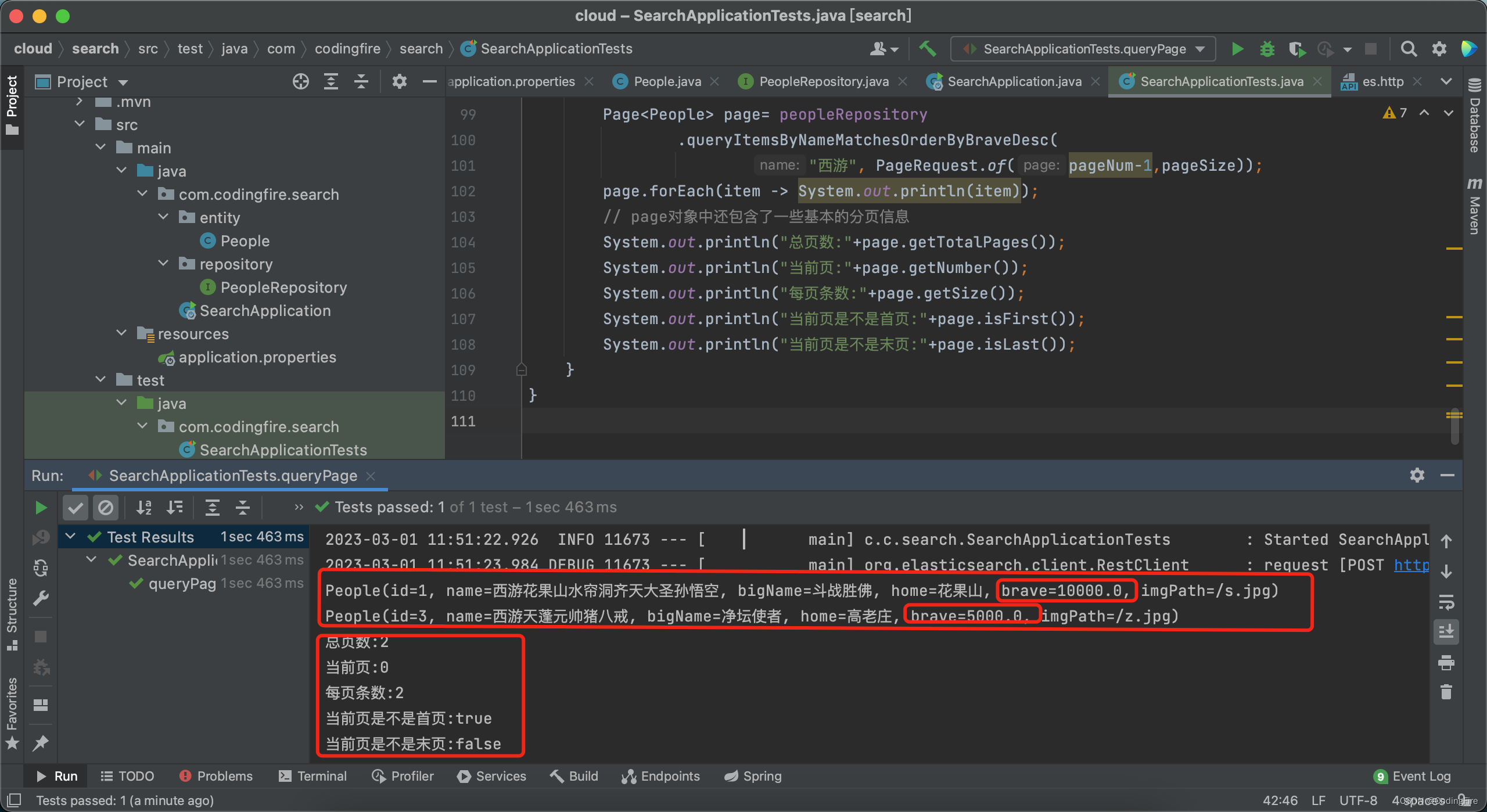
结果是按照排序后进行分页的,数据完全正确,测试成功。es的分页到这里就结束了,你学会了吗?新来的童鞋建议先看前一篇es,结合代码操作一遍,理解会更加的透彻。
数据库分页
PageHelper
SQL中我们通过limit关键字来进行分页查询,但却需要实时进行计算,在Spring Data中,我们通过框架帮我们解决了这个问题,PageHelper也是一个框架,它帮我们自动实现了分页效果,我们可以像Spring Data里那样,通过提供页码和数量来达到分页的目的。
所谓自动实现,也只是PageHelper在程序运行时,通过向SQL语句末尾添加limit的方式来实现分页,不要觉得讽刺,你当然可以选择自己来写,那是你的自由,我们使用框架的目的就是帮助我们降低开发的成本,提高开发的效率。
为了说明PageHelper的用法,我们还是在微服务的项目中进行同步讲解,以代码实战的形式进行。没有看过微服务篇的同学可以先去看看,这里要用到项目的工程,你也可以选择自建一个新的工程。但可能会略微有些麻烦。
添加依赖
我们在order模块进行代码的编写,首先添加依赖如下:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
</dependency>
此依赖在添加senta依赖时已经添加过,我们要知道。
基本使用
持久层
我们在OrderMapper接口中添加查询的方法如下:
@Select("select id,user_id,commodity_code,count,money from order_tbl")List<Order> findAllOrders();需要注意,此方法不需要添加分页相关的参数,如limit,我们使用的框架会自动追加参数进去。他不区分SQL语句是写在注解中还是xml文件中。
业务逻辑层
在实现类OrderServiceImpl中添加此方法:
// 分页查询所有订单的方法
// pageNum是要查询的页码
// pageSize是每页的条数public PageInfo<Order> getAllOrdersByPage(Integer pageNum, Integer pageSize){// 利用PageHelper框架的功能,指定分页的查询的页码和每页条数// pageNum为1时,就是查询第一页,和SpringData的分页不同(SpringData分页0表示第一页)PageHelper.startPage(pageNum,pageSize);// 调用查询所有订单的方法// 因为上面设置了分页查询的条件,所以下面的查询就会自动在sql语句后添加limit关键字// 查询出的list就是需要查询的页码的数据List<Order> list=orderMapper.findAllOrders();// 我们完成了分页数据的查询,但是当前方法要求返回分页信息对象PageInfo// PageInfo中可以包含分页数据和各种分页信息,这些信息都是自定计算出来的// 要想获得这个对象,可以在执行分页查询后实例化PageInfo对象,所有分页信息会自动生成return new PageInfo<>(list);}PageInfo对象既包含查询数据结果,又包含分页信息,我们来看看该类中有哪些属性:
//当前页
private int pageNum;
//每页的数量
private int pageSize;
//当前页的行数量
private int size;
//当前页面第一个元素在数据库中的行号
private int startRow;
//当前页面最后一个元素在数据库中的行号
private int endRow;
//总页数
private int pages;
//前一页页号
private int prePage;
//下一页页号
private int nextPage;
//是否为第一页
private boolean isFirstPage;
//是否为最后一页
private boolean isLastPage;
//是否有前一页
private boolean hasPreviousPage;
//是否有下一页
private boolean hasNextPage;
//导航条中页码个数
private int navigatePages;
//所有导航条中显示的页号
private int[] navigatepageNums;
//导航条上的第一页页号
private int navigateFirstPage;
//导航条上的最后一页号
private int navigateLastPage;根据需要选择需要的参数。
控制器层
业务逻辑层完成后,就需要在控制器层通过接口来调用接口方法,在OrderController类中添加如下控制器方法:
@GetMapping("/page")@ApiOperation("分页查询订单")@ApiImplicitParams({@ApiImplicitParam(value = "页码",name="pageNum",example = "1"),@ApiImplicitParam(value = "每页条数",name="pageSize",example = "10")})public JsonResult<PageInfo<Order>> pageOrders(Integer pageNum, Integer pageSize){// 分页调用PageInfo<Order> pageInfo=orderService.getAllOrdersByPage(pageNum,pageSize);return JsonResult.ok("查询完成",pageInfo);}你可以从方法中看到我们之前写的方法的影子,只是在参数方面我们做了一些调整,加入了分页相关的信息。由于我们这里没有写接口方法,所以为了调用实现类中的方法,我们需要修改此类中IOrderService为OrderServiceImpl,直接调用实现方法。
测试
在这里,启动nacos和seata,如果es还开启着,可以关闭了,博主的电脑都开始烫了。接着运行order
模块,额,报错?看看啥报错:
java.sql.SQLNonTransientConnectionException: Public Key Retrieval is not all以前都没报这个错啊,奇怪了,数据库也没升级,经查询,通过在spring.datasource.url后添加allowPublicKeyRetrieval=true可解决此问题。注意添加的格式:
url: jdbc:mysql://localhost:3306/cloud_db?useSSL=false&useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&allowMultiQueries=true&allowPublicKeyRetrieval=true启动成功后,我们在浏览器输入在线文档的地址:http://localhost:20002/doc.html
打开此页面:
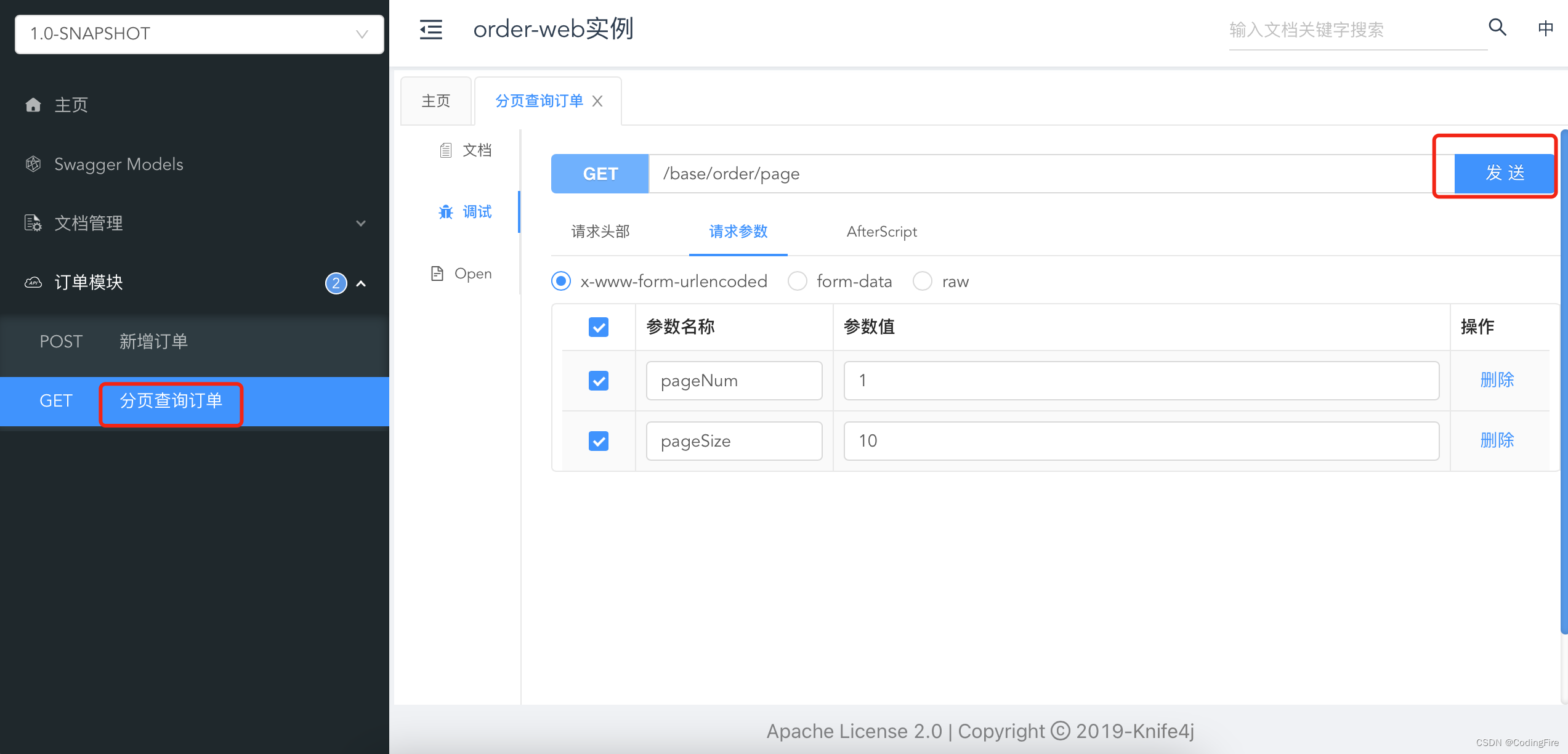
点击发送按钮,可看到如下数据:
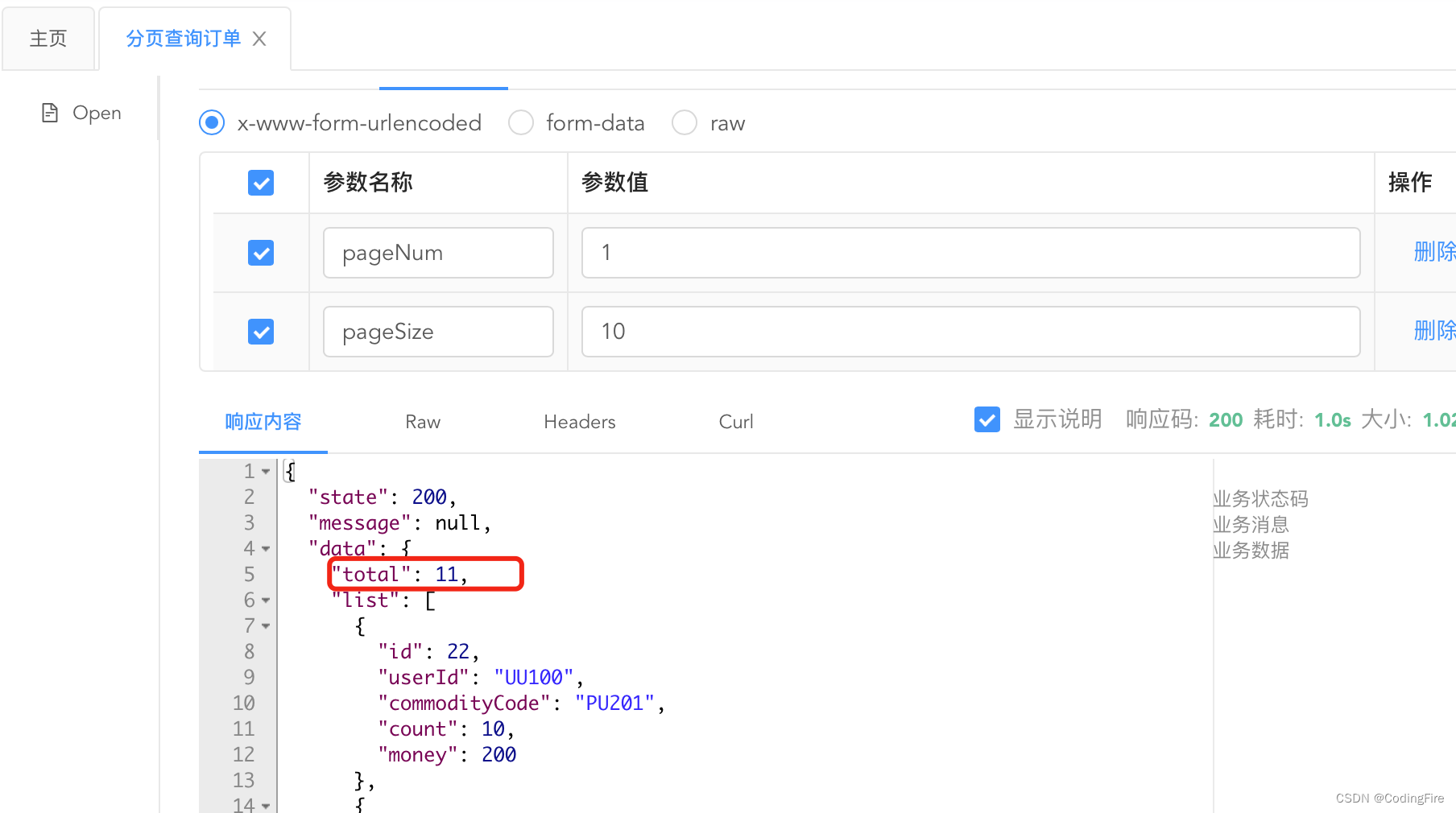
博主的数据库有11条数据,第一页给了10条数据,将页码改为2后,点击发送:

控制台中也打印出了自动追加limit的SQL语句:
==> Preparing: select id,user_id,commodity_code,count,money from order_tbl LIMIT ?, ?
==> Parameters: 10(Long), 10(Integer)
这里只返回了一条数据,就代表我们的测试已经成功了。但,我们注意到,上面的代码中还是存在一定问题,因为我们没有使用接口进行调用,而是直接调用了实现类方法,这是不符合规则的。原因可以看下方数据返回的内容。下面,我们将来完善这个步骤。
数据返回
分页查询我们在上面的方法中使用的PageInfo作为返回值,这是不合适的,因为使用此类,这个类就会出现在任何调用这个方法的模块,这些模块都将添加PageHelper的依赖,而且我们也不方便来做一些自定义的东西,为了解决此问题,我们需要在commons模块中添加一个返回类来代替PageInfo。
添加依赖
所以在PageInfo模块中,我们添加依赖如下:
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.2.0</version>
</dependency>
添加替代类
接着我们在restful包中新建一个JsonPage类,将PageInfo类封装进去:
package com.codingfire.cloud.commons.restful;import com.github.pagehelper.PageInfo;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;import java.io.Serializable;
import java.util.List;// 通用支持分页查询的结果对象类型
@Data
public class JsonPage<T> implements Serializable {// 按照实际需求,定义这个类中的属性@ApiModelProperty(value = "当前页码",name = "pageNum")private Integer pageNum;@ApiModelProperty(value = "每页条数",name = "pageSize")private Integer pageSize;@ApiModelProperty(value = "总条数",name = "totalCount")private Long totalCount;@ApiModelProperty(value = "总页数",name = "totalPages")private Integer totalPages;// 声明一个属性,来承载查询到的分页数据结果@ApiModelProperty(value = "分页数据",name = "list")private List<T> list;// 所有属性写完了,下面要编写将其他框架的分页结果转换成当前类对象的方法// SpringDataElasticsearch或PageHelper等具有分页功能的框架,均有类似PageInfo的对象// 我们可以分别编写方法,将它们转换成JsonPage对象,我们先只编写PageHelper的转换public static <T> JsonPage<T> restPage(PageInfo<T> pageInfo){// 下面开始将pageInfo对象的属性赋值给JsonPage对象JsonPage<T> result=new JsonPage<>();result.setPageNum(pageInfo.getPageNum());result.setPageSize(pageInfo.getPageSize());result.setTotalCount(pageInfo.getTotal());result.setTotalPages(pageInfo.getPages());result.setList(pageInfo.getList());// 返回赋值完毕的JsonPage对象return result;}}
修改业务逻辑层
在IOrderService接口类中添加新接口方法:
// 分页查询所有订单的方法JsonPage<Order> getAllOrdersByPage(Integer pageNum, Integer pageSize);接着在实现类OrderServiceImpl中修改原来的实现方法如下:
public JsonPage<Order> getAllOrdersByPage(Integer pageNum, Integer pageSize){// 利用PageHelper框架的功能,指定分页的查询的页码和每页条数// pageNum为1时,就是查询第一页,和SpringData的分页不同(SpringData分页0表示第一页)PageHelper.startPage(pageNum,pageSize);// 调用查询所有订单的方法// 因为上面设置了分页查询的条件,所以下面的查询就会自动在sql语句后添加limit关键字// 查询出的list就是需要查询的页码的数据List<Order> list=orderMapper.findAllOrders();// 我们完成了分页数据的查询,但是当前方法要求返回分页信息对象PageInfo// PageInfo中可以包含分页数据和各种分页信息,这些信息都是自定计算出来的// 要想获得这个对象,可以在执行分页查询后实例化PageInfo对象,所有分页信息会自动生成// ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓return JsonPage.restPage(new PageInfo<>(list));
}修改控制器层
此时,控制器层因为上面的代码修改已经报错了,然后修改控制器层方法,有两处:
第一处是OrderServiceImpl:
private OrderServiceImpl orderService;private IOrderService orderService;其实就是修改回来,第一行改回第二行。
第二处是原方法修改返回值:
public JsonResult<JsonPage<Order>> pageOrders(Integer pageNum, Integer pageSize){// 分页调用JsonPage<Order> jsonPage=orderService.getAllOrdersByPage(pageNum,pageSize);return JsonResult.ok("查询完成",jsonPage);}一路修改,到这里就结束了。我们可以重新order模块,通过在线文档来进行测试,发现测试结果是一样的,这就可以了,测试成功,这一步是对返回值做了处理,使我们可以自定义返回值的对象,是代码更加的灵活,你可以对比修改前后返回值的结构。
结语
分页查询在开发中的使用非常频繁,就是再小的项目也离不开分页功能,虽然不一定使用es,但分页绝对会用,学完此篇,分页功能你就基本掌握了,剩下的就是在实践中使用此功能,相信你一定已经学会了。另外,分页功能还不算难,和es比起来算是比较基础的功能了,只是涉及es的分页,才展开讲了一下,这是每一个后台开发者都必须会的内容,大家有时间多做练习,自己进行尝试,才能够掌握得更好。又到了和大家说再见的时候,觉得不错,就三连(点赞,收藏,评论)支持一下吧。
相关文章:
Java开发 - 分页查询初体验
前言在上一篇,我们对es进行了深入讲解,相信看过的小伙伴已经能基本掌握es的使用方法,我们知道,es主要针对的是搜索条件,在这方面es具有无可比拟的优势,但我们也会注意到,有时候搜索条件过于宽泛…...
C语言循环语句do while和嵌套循环语句讲解
C do…while 循环 不像 for 和 while 循环,它们是在循环头部测试循环条件。在 C 语言中,do…while 循环是在循环的尾部检查它的条件。 do…while 循环与 while 循环类似,但是 do…while 循环会确保至少执行一次循环。 语法 C 语言中 do…w…...
【7】:拼接图像)
【计算机视觉】OpenCV 4高级编程与项目实战(Python版)【7】:拼接图像
我们已经知道,图像是通过数组描述的,那么拼接图像其实就是拼接数组。NumPy提供了2个拼接数组的函数,分别是hstack函数和vstack函数,这两个拼接函数可以将两个数组水平和垂直拼接在一起,也就相当于将两幅图像水平和垂直拼接在一起,本节将详细讲解如何使用这两个函数水平拼…...
王道操作系统课代表 - 考研计算机 第二章 进程与线程 究极精华总结笔记
本篇博客是考研期间学习王道课程 传送门 的笔记,以及一整年里对 操作系统 知识点的理解的总结。希望对新一届的计算机考研人提供帮助!!! 关于对 “进程与线程” 章节知识点总结的十分全面,涵括了《操作系统》课程里的全…...

C++修炼之练气期三层——函数重载
目录 1.引例 2.函数重载的概念 3.C支持函数重载的原理 1.引例 倘若现在要实现一个加法计算器,用C语言实现的话我们会选择这样的方式: int Add_int(int a, int b) {return a b; }double Add_double(double a, double b) {return a b; } 在使用加…...

在linux上运行jar程序操作记录
1.文件传送 使用ftp把打包后的项目jar包上传到linux服务器的目录上(这里有两个文件,一个pengning.jar,一个配置文件application.yml) 2.进入目录并运行程序 打开终端,进入pengning.jar所在的目录 [rootcampus /]# [rootcampu…...
:实时操作系统RTOS和通用操作系统GPOS的区别)
【STM32】入门(十二):实时操作系统RTOS和通用操作系统GPOS的区别
1、简述 实时操作系统(RTOS,Real Time Operating System) 通用操作系统(GPOS,General Purpose Operating System) 2、区别 1)任务 实时操作系统:使用分时设计,其中每个任务被分配一小段时间,在切换到另一…...

2023-3-1刷题情况
在网格图中访问一个格子的最少时间 题目描述 给你一个 m x n 的矩阵 grid ,每个元素都为 非负 整数,其中 grid[row][col] 表示可以访问格子 (row, col) 的 最早 时间。也就是说当你访问格子 (row, col) 时,最少已经经过的时间为 grid[row][…...

Web前端学习:五 - 练习
四二-四八:baidu糯米 44-48 1、写法1 (1)a.movie1 .Navigation .recommend .listbanner a.movie1{background: url(img/h_1.jpg) no-repeat 63px 9px;}表示a标签且class为movie1的元素 如: <a href"#" class&quo…...

软件测试之测试用例设计方法—等价类划分法
测试用例设计方法—等价类划分法 掌握常用测试用例设计方法,再结合测试用例的要素能给快速的实现测试用例的设计和编写.但是由于软件系统大小的不同我们不可能把所有的单个或组合的情况都进行测试,所以我们测试时应该根据不同的场景设计不同的测试用例,尽可能的覆盖到全部需要…...
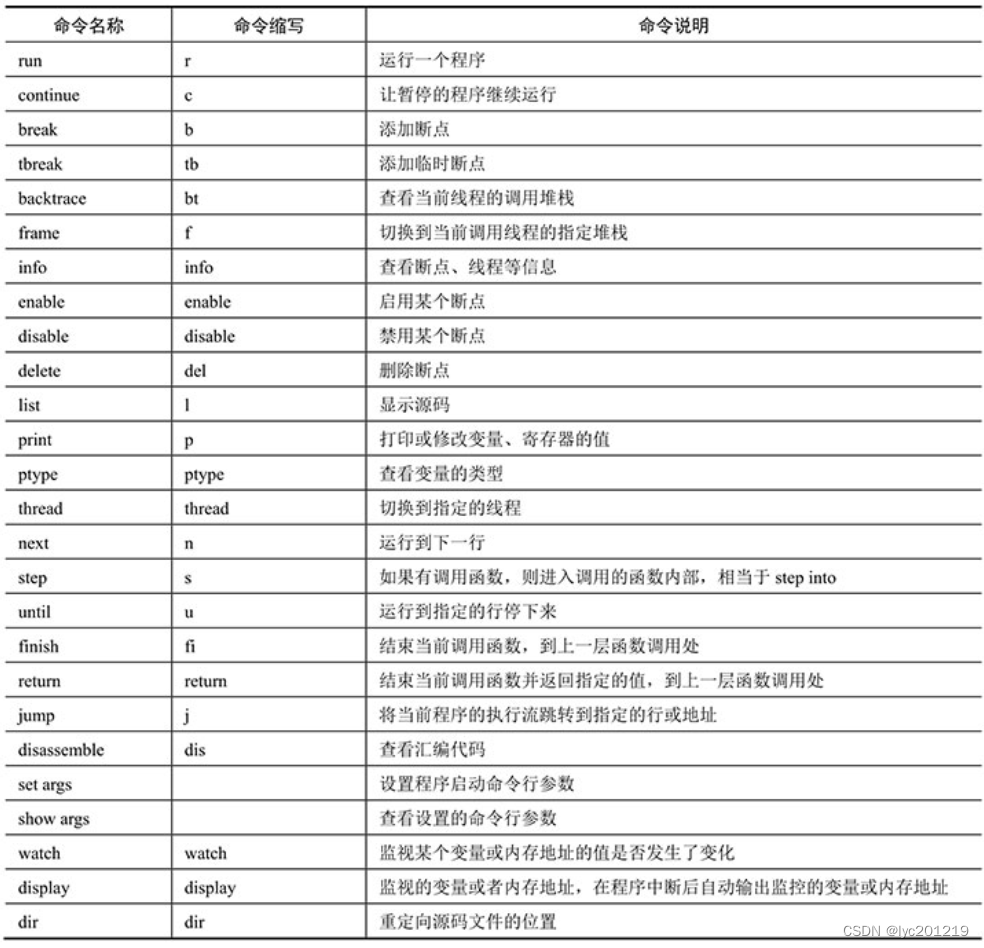
gdb常用命令详解
gdb常用调试命令概览和说明 run命令 在默认情况下,gdbfilename只是attach到一个调试文件,并没有启动这个程序,我们需要输入run命令启动这个程序(run命令被简写成r)。如果程序已经启动,则再次输入 run 命令…...
2022 年江西省职业院校技能大赛高职组“信息安全管理与评估”赛项样题
2022 年江西省职业院校技能大赛高职组 “信息安全管理与评估”赛项样题 一、 赛项信息 第一场比赛: 竞赛阶段 任务阶 段 竞赛任务 竞赛时 间 分值 第一阶段 任务 1 网络平台搭建 90 平台搭建与安全 任务 2 网络安全设备配置与防护 210 设备配置防护…...
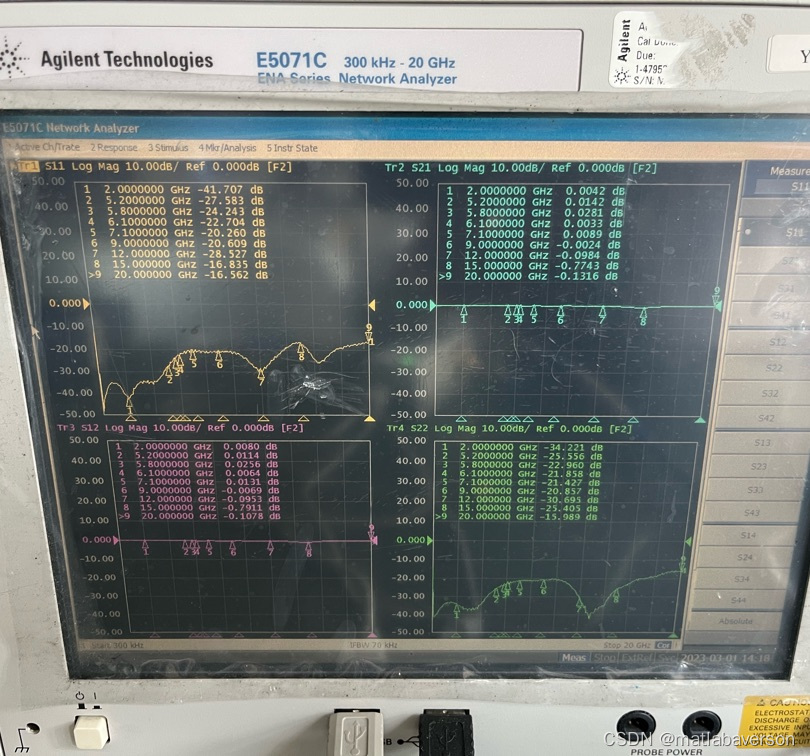
射频调试的习惯
三月开工了,一个月的调试即将开始。其实调试的重心是测试,核心的推动力是做事的习惯和思维。测试很重要,数据不对,能力和时间都浪费了上面了。测试的问题初步解完了,今天吃饭的时候碰到大领导。领导好忙,我…...
centos7上安装mysql8.0
1、检查一下自己电脑上安装了哪些mysql [rootlocalhost ~]# find / -name mysql 2、把安装的mysql全部删掉 [rootlocalhost ~]# rm -rf /usr/lib64/mysql/ [rootlocalhost ~]# rm -rf /usr/local/mysql/ [rootlocalhost ~]# rm -rf /etc/selinux/targeted/active/modules/100…...

如何使用BackupOperatorToDA将Backup Operators用户权限提升为域管理员
关于BackupOperatorToDA BackupOperatorToDA是一款功能强大的红队提权工具,该工具能够在不使用域控制器RDP或WinRM的情况下,帮助广大研究人员将Backup Operators组的成员账号提升为域管理员权限。 如果红队研究人员在渗透测试的过程中,拿到…...

百度文心大模型开发者斩获CCF BDCI大赛唯一『最佳算法能力奖』
2023年2月24日至25日,中国计算机学会(CCF)主办、苏州市吴江区人民政府支持,苏州市吴江区工信局、吴江区东太湖度假区管理办公室、苏州市吴江区科技局、CCF大数据专家委员会及其他专业委员会等多家组织单位共同承办的大数据与AI领…...
:hmeta(本库尚在开发中))
合宙Air780E|硬件元数据|LuatOS-SOC接口|官方demo|学习(21):hmeta(本库尚在开发中)
基础资料 基于Air780E开发板:Air780E文档中心 简介:CSDK开发 探讨重点 本系列主要探讨利用合宙平台进行fota_iot差分包升级的基本操作、编译及上传,升级等操作。 硬件准备 Air780E开发板1块,SIM卡1张。 内容参考 官方wi…...
 (A-C))
Educational Codeforces Round 144 (Rated for Div. 2) (A-C)
文章目录A. Typical Interview Problem【找规律,暴力】B. Asterisk-Minor Template【分类、模拟】C. Maximum Set【数学】A. Typical Interview Problem【找规律,暴力】 链接 传送门 分析 3 5 6 9 10 12 15||||||| 15 3 15 5 ………… F B F F B F FB…...
:033 KD树的Python实现)
机器学习100天(三十三):033 KD树的Python实现
《机器学习100天》完整目录:目录 机器学习100天,今天讲的是:KD 树的Python实现! 打开 spyder,我们新建一个 kd_tree.py 脚本。首先,我们新建一个类,名为Node,它定义了 KD 树节点中包含的数据结构。例如数据、深度、左节点、右节点。 # KD树结点中包含的数据结构 clas…...
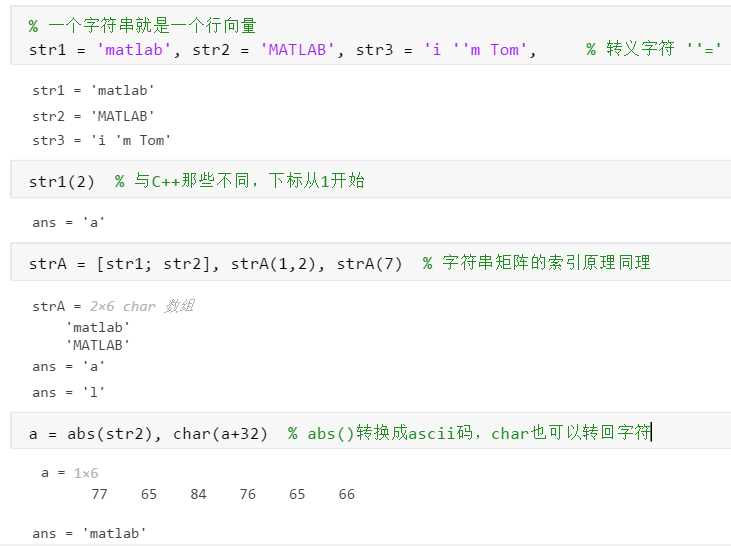
matlab-数据和数据运算
学习视频基本数据类型1.1 整型与浮点型在matlab中同样有8、16、32、64bit的数据大小之分,同时也可以叠加signed(有符号)和unsigned(无符号)的区别,默认数据类型为double(双精度浮点型)参考其他博客的详述1.2 复数还有一些其他常用的函数方法:…...

OpenClaw 的对话系统是否支持对话流程的可视化编辑?如何定义状态机?
关于OpenClaw对话系统是否支持对话流程的可视化编辑,目前公开的技术文档和社区讨论中并没有明确提及这一功能。从技术实现的角度来看,这类系统通常更侧重于底层对话状态管理和自然语言理解引擎的构建,而非面向产品经理或非技术人员的可视化编…...

Vue3+AI聊天室:如何实现消息自动滚动和流式响应?
Vue3AI聊天室:消息自动滚动与流式响应的工程实践 引言:当Vue3遇见AI对话 在构建现代化AI聊天应用时,流畅的交互体验往往比功能堆砌更重要。想象这样一个场景:用户发送问题后,界面立即开始逐字显示AI回复,同…...

Spring Framework测试框架完整指南:从单元测试到集成测试的10个最佳实践
Spring Framework测试框架完整指南:从单元测试到集成测试的10个最佳实践 【免费下载链接】spring-framework spring-projects/spring-framework: 一个基于 Java 的开源应用程序框架,用于构建企业级 Java 应用程序。适合用于构建各种企业级 Java 应用程序…...

OpenClaw语音控制扩展:Qwen3.5-4B-Claude对接Whisper实现声控自动化
OpenClaw语音控制扩展:Qwen3.5-4B-Claude对接Whisper实现声控自动化 1. 为什么需要语音控制自动化 去年冬天的一个深夜,我在赶制项目文档时突发奇想:如果能让AI听懂我的语音指令直接操作电脑,是不是连键盘都不用碰了?…...

3000 字深度拆解:Paperxie AI 期刊写作界面全解析 —— 科研人必看的 “投刊效率密码”
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/期刊论文https://www.paperxie.cn/ai/journalArticleshttps://www.paperxie.cn/ai/journalArticles 一、引言:科研人的投稿困局,藏在每一个被忽略的界面细节里 当科研人熬过无数个深…...
)
语义分割竞赛必备:5种Loss函数组合效果对比(含Dice+Focal Loss调参指南)
语义分割竞赛进阶:5种损失函数组合实战评测与调参策略 在Kaggle等数据竞赛中,语义分割任务的性能提升往往取决于损失函数的巧妙选择与组合。不同于常规分类任务,多类别像素级预测需要处理极端类别不平衡、边界模糊等独特挑战。本文将深入剖析…...
)
Qt5新手必看:3分钟搞定你的第一个控制台程序(附完整代码)
Qt5入门实战:从零构建控制台应用的完整指南 引言:为什么选择Qt5作为开发起点? 对于刚接触C图形界面开发的程序员来说,Qt框架提供了一个绝佳的起点。它不仅拥有跨平台特性,还具备完善的工具链和丰富的模块库。控制台程序…...

别再瞎找了!AI论文软件2026最新测评与推荐
2026年真正好用的AI论文软件,核心看生成的论文质量、低AI味、格式正确、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 一、…...

STM32智能婴儿床系统设计与实现
基于STM32的智能婴儿床系统设计1. 项目概述1.1 系统架构本智能婴儿床系统采用模块化设计架构,以STM32F103RCT6微控制器为核心处理单元,集成多种传感器模块和执行机构。系统通过蓝牙与手机APP建立双向通信,实现环境参数监测、异常报警和远程控…...

别再手动填Token了!用Knife4j的OAuth2配置,一键搞定接口文档自动化认证
告别手动Token时代:Knife4j与OAuth2的自动化认证实战 每次调试API都要复制粘贴Token的日子该结束了。作为后端开发者,我们花了大量时间在接口文档和认证流程之间来回切换——这不仅是效率问题,更是一种思维中断。想象一下,当你的微…...