Whisper
文章目录
- 使后感
- Paper Review
- 个人觉得有趣的
- Log Mel spectrogram & STFT
- Training
- cross-attention输入
- cross-attention输出
- positional encoding
- 数据
- Decoding
- 为什么可以有时间戳的信息
- Test code
使后感
因为运用里需要考虑到时效和准确性,类似于YOLO,只考虑 tiny, base,和small 的模型。准确率基本反应了模型的大小,即越大的模型有越高的准确率
Paper Review
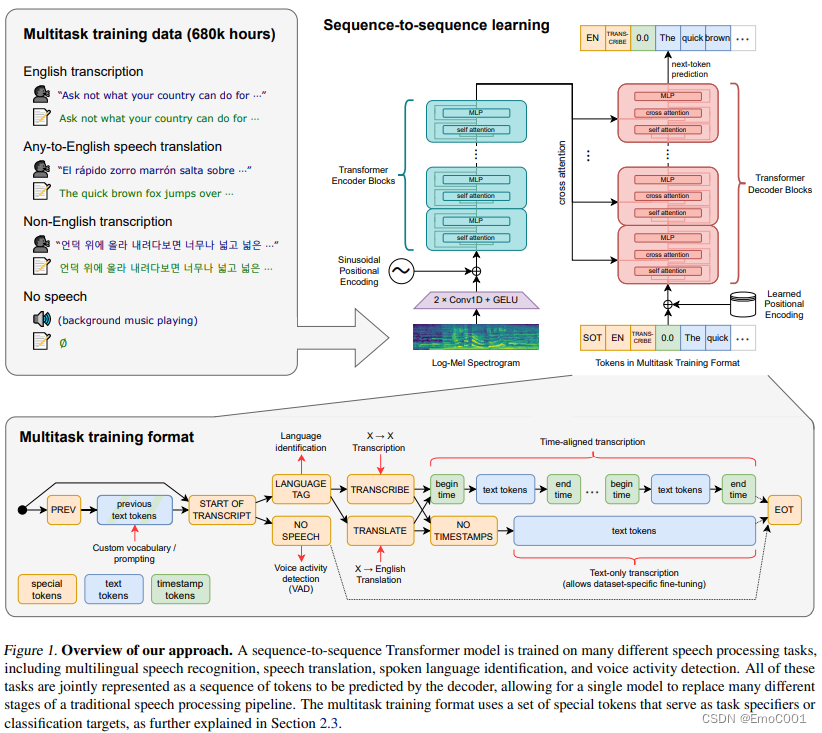
个人觉得有趣的
-
这里的feature不是直接的声音array,但log-mel spectrogram 也不是陌生的。mel 比 STFT更少的特征数量,也更接近人类感知,Mel 频谱通过在较低频率提供更多的分辨率,有助于减少背景噪音的影响。
-
整个结构也是很一目了然,喜闻乐见的transformer。 但是有限制: 16,000Hz的audio sample, 80 channels,25 millisseconds的窗口,移动距离为 10 milliseconds
-
为啥可以得到 时间轴对应的Txt, 这个得感谢decoding.py 里 “begin time” 和 “end time”
Log Mel spectrogram & STFT
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt# 加载音频文件
audio_path = 'your_audio_file.wav'
y, sr = librosa.load(audio_path)
# 计算 STFT
D = librosa.stft(y)
# 将功率谱转换为dB
D_dB = librosa.amplitude_to_db(np.abs(D), ref=np.max)
# 创建 Mel 滤波器组
n_mels = 128
mel_filter = librosa.filters.mel(sr, n_fft=D.shape[0], n_mels=n_mels)
# 应用 Mel 滤波器组
mel_S = np.dot(mel_filter, np.abs(D))
# 对 Mel 频谱取对数
log_mel_S = librosa.power_to_db(mel_S, ref=np.max)# 绘图
plt.figure(figsize=(12, 8))
plt.subplot(2, 1, 1)
librosa.display.specshow(D_dB, sr=sr, x_axis='time', y_axis='log')
plt.title('STFT Power Spectrogram')
plt.colorbar(format='%+2.0f dB')plt.subplot(2, 1, 2)
librosa.display.specshow(log_mel_S, sr=sr, x_axis='time', y_axis='mel')
plt.title('Log-Mel Spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.tight_layout()
plt.show()
Training
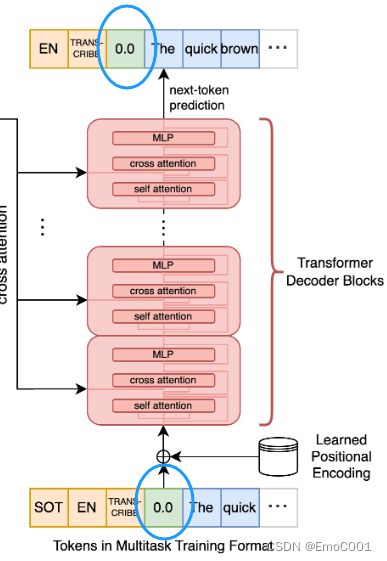
cross-attention输入
SOT: start of trascription token
EN: English token
TRANS-CRIBE: token
timestamp
balabalabala(真的语音转成的文字)
cross-attention输出
EN: English token
TRANS-CRIBE: token
timestamp
balabalabala(真的语音转成的文字)
positional encoding
在这里面用到了不同的positional encoding,只是不确定如果不一样会不会有什么影响。挖个坑先(后面把这里填了)
输入用的是Sinusoidal Positional Encoding
输出用的是 Learned Positional Encoding
数据
- 基本是需要人工参与去检查大数据里的数据质量的(后期有通过使用初训的Whisper过筛数据后加人工检查的操作)
- Whisper还有减翅膀的悲剧(哭哭),本来有显示出可以“猜”说话的人,但是这个应该和NLP大模型里面的“想象力”一样,都是瞎猜,为了减少其影响,后来在fine-tune 时把这个信息从训练里删除了
- 也有比较有趣的是,Speech reg 是依靠WER(word error rate)来的,也就是非常粗暴的word edit distance. 那每个人讲话啊风格不一样,就算是同一个意思的数据也会因为WER过高,导致训练了个寂寞。
- hmmmmm…这个数据处理相当heavily depends on manually inspection. 如果资金不够。。。真的很尴尬
- 在normalise.py 和 paper最后,给了一堆normalization的tricks
Decoding
和NLP的东西环环相扣,基本greedy search都会有那种说车轱辘话的bug, 作者的解决方法是将beam-search size = 5
看完论文后,个人推荐使用 temperature <0.5 (中庸设置)
相比于上个世纪的依靠频谱判断有没有人讲话,Whisper是模型控制和判断。比如作者会将不说话<|nospeech|>的机率调到0.6。
这个训练模式是causal 来的,也就是通过一个upper 三角设置为 -inf 未来的说话是会被忽视的,用前面的内容往后推理
为什么可以有时间戳的信息
它在decoding(decoding.py)阶段,只需要依靠 self.tokenizer.timestamp 里的数据来,只要知道一段语音的开始,就能反推结束,因为一段语音的分割结尾即是另一个语音的开始
# if sum of probability over timestamps is above any other token, sample timestamplogprobs = F.log_softmax(logits.float(), dim=-1)for k in range(tokens.shape[0]):timestamp_logprob = logprobs[k, self.tokenizer.timestamp_begin :].logsumexp(dim=-1)max_text_token_logprob = logprobs[k, : self.tokenizer.timestamp_begin].max()if timestamp_logprob > max_text_token_logprob:logits[k, : self.tokenizer.timestamp_begin] = -np.inf
Test code
import whisper
import speech_recognition as sr
recognizer = sr.Recognizer()
import os
from moviepy.editor import *
import timestart_time = time.time()modeltype = "small"
model = whisper.load_model(modeltype)input_folder = r"D:\xxxxxxx"
output_folder = r"out_"+modeltype+"model_whisper"format = 'mp4'
without_timestamps = Falseif not os.path.exists(output_folder):os.makedirs(output_folder)
for root, dirs, files in os.walk(input_folder):for file in files:if file.endswith(("."+format,)):video_path = os.path.join(root, file)basename = os.path.splitext(file)[0]audio_path = os.path.join(input_folder, f"{basename}.{format}")start_time = time.time()result = model.transcribe(audio_path, language="zh",without_timestamps=without_timestamps)print(basename,time.time()-start_time)with open(output_folder+'/'+basename+'_all.txt', 'w') as res_file:res_file.write(str(time.time()-start_time)+'\n')for seg in result["segments"]:if without_timestamps:line = f"{seg['text']}'\n'"else:line = f"{seg['start']}---{seg['end']}: {seg['text']}'\n'"res_file.write(line)
print("Done")
相关文章:
Whisper
文章目录 使后感Paper Review个人觉得有趣的Log Mel spectrogram & STFT Trainingcross-attention输入cross-attention输出positional encoding数据 Decoding为什么可以有时间戳的信息 Test code 使后感 因为运用里需要考虑到时效和准确性,类似于YOLOÿ…...

Android系统分析
Android工程师进阶第八课 AMS、WMS和PMS 一、Binder通信 【Android Framework系列】第2章 Binder机制大全_android binder-CSDN博客 Android Binder机制浅谈以及使用Binder进行跨进程通信的俩种方式(AIDL以及直接利用Binder的transact方法实现)_bind…...

五、关闭三台虚拟机的防火墙和Selinux
目录 1、关闭每台虚拟机的防火墙 2、关闭每台虚拟机的Selinux 2.1 什么是SELinux...

【从零开始学习Redis | 第六篇】爆改Setnx实现分布式锁
前言: 在Java后端业务中, 如果我们开启了均衡负载模式,也就是多台服务器处理前端的请求,就会产生一个问题:多台服务器就会有多个JVM,多个JVM就会导致服务器集群下的并发问题。我们在这里提出的解决思路是把…...

Kubernetes学习笔记-Part.05 基础环境准备
目录 Part.01 Kubernets与docker Part.02 Docker版本 Part.03 Kubernetes原理 Part.04 资源规划 Part.05 基础环境准备 Part.06 Docker安装 Part.07 Harbor搭建 Part.08 K8s环境安装 Part.09 K8s集群构建 Part.10 容器回退 第五章 基础环境准备 5.1.SSH免密登录 在master01、…...

语义分割 DeepLab V1网络学习笔记 (附代码)
论文地址:https://arxiv.org/abs/1412.7062 代码地址:GitHub - TheLegendAli/DeepLab-Context 1.是什么? DeepLab V1是一种基于VGG模型的语义分割模型,它使用了空洞卷积和全连接条件随机(CRF)来提高分割…...
java设计模式学习之【建造者模式】
文章目录 引言建造者模式简介定义与用途实现方式: 使用场景优势与劣势建造者模式在spring中的应用CD(光盘)的模拟示例UML 订单系统的模拟示例UML 代码地址 引言 建造者模式在创建复杂对象时展现出其强大的能力,特别是当这些对象需…...

Spring Boot中的RabbitMQ死信队列魔法:从异常到延迟,一网打尽【RabbitMQ实战 一】
Spring Boot中的RabbitMQ死信队列魔法:从异常到延迟,一网打尽 前言第一:基础整合实现第二:处理消息消费异常第三:实现延迟消息处理第四:优雅的消息重试机制第五:异步处理超时消息第六࿱…...

nrm : 镜像源工具npm镜像切换
nrm命令 安装nrm:npm i -g nrm 查看镜像源:nrm ls,带*号的为当前使用的源 添加新镜像:nrm add [镜像源名称] <源的URL路径> 切换镜像源:nrm use [镜像源名称] 删除一个镜像源:nrm del [镜像源名称] …...
Star 10.4k!推荐一款国产跨平台、轻量级的文本编辑器,内置代码对比功能
notepad 相信大家从学习这一行就开始用了,它是开发者/互联网行业的上班族使用率最高的一款轻量级文本编辑器。但是它只能在Windows上进行使用,而且正常来说是收费的(虽然用的是pj的)。 对于想在MacOS、Linux上想使用,…...

iOS 17.2:可以修改消息提示音了
时隔2周之后,苹果今日为开发者预览版用户推送了iOS 17.2 Beta4测试版的更新,已经注册Apple Beta版软件计划的用户只需打开设置--通用--软件更新即可在线OTA升级至最新的iOS 17.2测试版。 本次更新包大小为590M左右,内部版本号为(…...
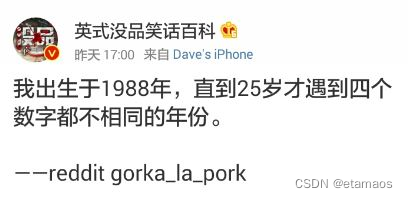
PTA 一维数组7-3出生年(本题请你根据要求,自动填充“我出生于y年,直到x岁才遇到n个数字都不相同的年份”这句话)
以上是新浪微博中一奇葩贴:“我出生于1988年,直到25岁才遇到4个数字都不相同的年份。”也就是说,直到2013年才达到“4个数字都不相同”的要求。本题请你根据要求,自动填充“我出生于y年,直到x岁才遇到n个数字都不相同的…...

【3】基于多设计模式下的同步异步日志系统-设计模式
详细介绍设计模式 单例模式 ⼀个类只能创建⼀个对象,即单例模式,该设计模式可以保证系统中该类只有⼀个实例,并提供⼀个访问它的全局访问点,该实例被所有程序模块共享。⽐如在某个服务器程序中,该服务器的配置信息存放…...

Metasploit的使用和配置
预计更新 第一章 Metasploit的使用和配置 1.1 安装和配置Metasploit 1.2 Metasploit的基础命令和选项 1.3 高级选项和配置 第二章 渗透测试的漏洞利用和攻击方法 1.1 渗透测试中常见的漏洞类型和利用方法 1.2 Metasploit的漏洞利用模块和选项 1.3 模块编写和自定义 第三章 Me…...

测试用例的设计思路
接到提测单后要做的事情: 测试准备阶段 确认提测单内包含的文件、URL地址可以访问确认需求 (迭代目标、用户故事、用户愿望、问题反馈等)确认回归测试范围、更新测试范围、新增测试范围编写测试点思维导图,过程中有问题及时进行沟通与迭代相关人员约一个…...

HCIP——交换综合实验
一、实验拓扑图 二、实验需求 1、PC1和PC3所在接口为access,属于vlan2;PC2/4/5/6处于同一网段,其中PC2可以访问PC4/5/6;但PC4可以访问PC5,不能访问PC6 2、PC5不能访问PC6 3、PC1/3与PC2/4/5/6/不在同一网段 4、所有PC通…...

大学生如何搭建自己的网站
这篇是我在大一的时候,写过的一篇文章。 前言 作为一名大学生,我觉得搭建个人网站很有意义。 这篇博客讲述的是这个寒假,我是如何从零到搭建好个人网站的过程。我提供的主要是具体的思路,也附带了一些零零散散的细节。时间跨度…...

linux 路由表的优先级
[rootlocalhost cc]# ip rule list 0: from all lookup local 32765: from 10.0.19.24 lookup 4096 32766: from all lookup main 32767: from all lookup default 现在有 4 条路由规则,优先级是怎样的,0 代表最低优先级还是最高优先级 在 Linux 的 IP …...

毕业项目分享
大家好,今天给大家分享112个有趣的Python实战项目,可以直接拿来实战练习,涵盖机器学习、爬虫、数据分析、数据可视化、大数据等内容,建议关注、收藏。 项目名称 主要技术 2023招聘数据分析可视化系统爬虫 7种薪资预测模型 Flas…...
Android启动系列之进程杀手--lmkd
本文概要 这是Android系统启动的第三篇文章,本文以自述的方式来讲解lmkd进程,通过本文您将了解到lmkd进程在安卓系统中存在的意义,以及它是如何杀进程的。(文中的代码是基于android13) 我是谁 init:“大…...
:2026奇点大会强制TEE接入新规解读,3类企业必须在Q3前完成可信推理栈升级)
AI模型产权保护进入倒计时(仅剩11个月):2026奇点大会强制TEE接入新规解读,3类企业必须在Q3前完成可信推理栈升级
更多请点击: https://intelliparadigm.com 第一章:AI原生可信执行环境:2026奇点智能技术大会TEE for AI 在2026奇点智能技术大会上,TEE for AI(AI-Native Trusted Execution Environment)正式成为下一代A…...

3分钟掌握Linux桌面便签神器:Sticky让你的数字工作台效率翻倍!
3分钟掌握Linux桌面便签神器:Sticky让你的数字工作台效率翻倍! 【免费下载链接】sticky A sticky notes app for the linux desktop 项目地址: https://gitcode.com/gh_mirrors/stic/sticky 还在为桌面杂乱无章的纸质便利贴烦恼吗?Sti…...

Win10网络适配器里WLAN神秘消失?我整理了这7个真正管用的修复姿势
Win10网络适配器WLAN消失的深度修复指南:从症状到根源的7种解决方案 当WLAN选项从Win10的网络适配器中神秘消失时,大多数用户会陷入反复重启和盲目尝试的困境。本文将带您深入理解这一现象背后的系统机制,并提供一套从简单到复杂的阶梯式解决…...
—— 递归树如何看懂分治算法的运行时间)
算法基础(十一)—— 递归树如何看懂分治算法的运行时间
1. 定位导航 前面已经学习了分治思想: 分解 → 解决 → 合并分治算法经常可以写成递归式。 例如归并排序: 先把数组拆成左右两半; 分别排序左右两半; 再合并两个有序数组。它的运行时间可以粗略写成: T(n)2T(n/2)n T(n…...

xAI解散并入SpaceX,马斯克AI战略转向卖算力,太空AI之梦能否实现?
一、败者食尘xAI解散了?马斯克的Grok难道要凉凉?最近几天,这则新闻在科技圈里刷屏了,消息来源就是马斯克本人,他在社交账号上公布消息称,“xAI将解散并停止作为独立公司运营,会并入SpaceX AI&am…...

5G与4G LTE互操作:无缝衔接,共筑通信新生态
5G与4G LTE互操作:无缝衔接,共筑通信新生态 在移动通信技术日新月异的今天,5G作为新一代通信技术,正逐步融入我们的生活,与4G LTE形成互补共存的局面。5G与4G LTE之间的互操作,不仅关乎用户体验的连续性&am…...

ARM TRCCNTCTLR寄存器详解与调试技巧
1. ARM Trace Counter控制寄存器TRCCNTCTLR深度解析在嵌入式系统调试和性能分析领域,硬件计数器是不可或缺的关键工具。作为ARM架构调试系统的重要组成部分,Trace Counter Control Register(TRCCNTCTLR)系列寄存器为开发者提供了精…...

基于Electron构建macOS效率工具:插件化命令执行与安全实践
1. 项目概述:一个为macOS开发者量身打造的效率工具 最近在GitHub上看到一个挺有意思的项目,叫 zhaobomin/copaw-macapp 。乍一看名字, copaw 这个组合词有点意思,结合 macapp 的后缀,不难猜出这是一个专门为macO…...

嵌入式系统开发TTM困境与优化策略
1. 嵌入式系统开发的TTM困境与破局之道十年前,一个基于8位MCU的温控器开发周期可能只需要3个月;而今天,一个具备联网功能的智能温控系统,开发时间往往超过9个月——尽管我们拥有了更强大的32位处理器、更完善的开发工具和更成熟的…...

基于MCP协议与Playwright的AI智能体网页抓取工具部署与实战
1. 项目概述:一个为AI智能体打造的“网页抓取工具箱” 如果你正在开发或使用基于MCP(Model Context Protocol)的AI智能体,并且经常需要让它们从网页上获取结构化数据,那么你很可能已经遇到了一个核心痛点: …...