Redis实战篇笔记(最终篇)
Redis实战篇笔记(七)
文章目录
- Redis实战篇笔记(七)
- 前言
- 达人探店
- 发布和查看探店笔记
- 点赞
- 点赞排行榜
- 好友关注
- 关注和取关
- 共同关注
- 关注推送
- 关注推荐的实现
- 总结
前言
本系列文章是Redis实战篇笔记的最后一篇,那么到这里Redis实战篇的内容就要结束了,本系列文件涵盖了Redis作为缓存在实战项目中的大多数用法
达人探店
发布和查看探店笔记
这个两个功能就是普通的业务,没有用到 redis,所以我把他们合到一起了
发布探店笔记
我们点击下面的加号就可以发布一篇探店笔记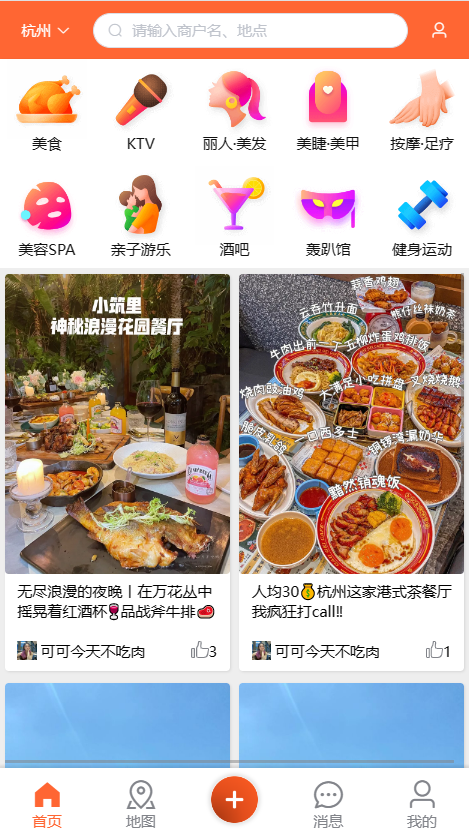
这里的上传图片,如果是一般的业务会上传到一个文件服务器,但是他这里选择上传到了我们的前端服务器
这个 IMAGE_UPLOAD_DIR 就是前端服务器放图片的地方,要改成自己所对应的位置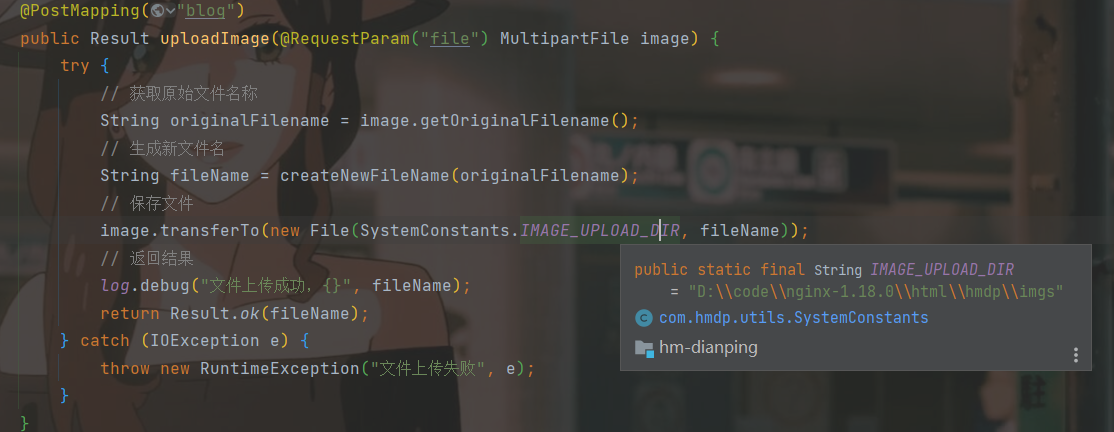
我们像这样就写好了一篇探店笔记,然后我们点发布,就会跳转到个人中心,并且在主页的最后也能看见我们发布的笔记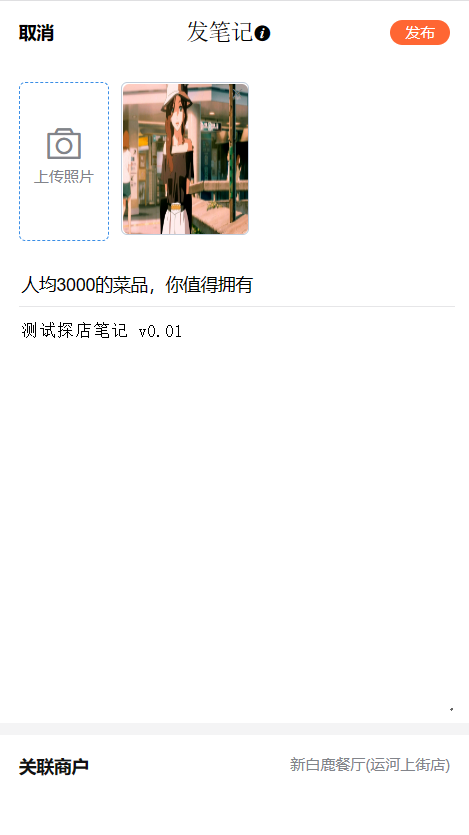
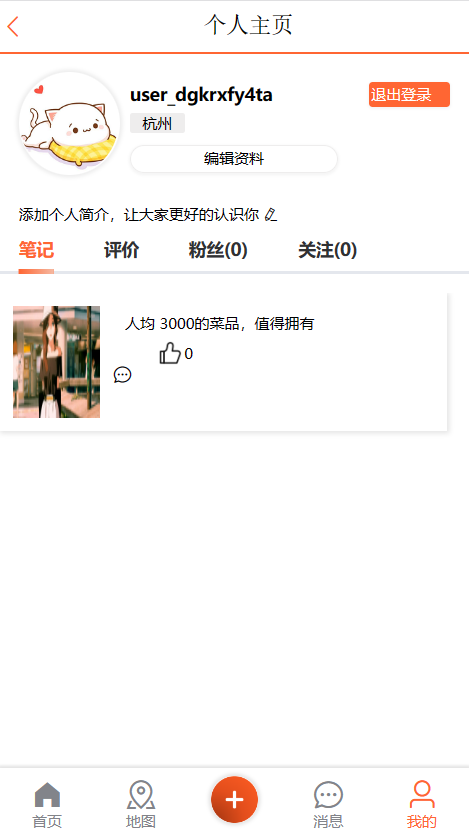
我们点击看我们刚发布的笔记,会报错,是因为我们还没有实现这个功能,我们点击查看,就可以看到前端访问的接口,接下来我们就去实现它
**这就是 查看笔记的方法 ** queryBlogById 是我们要实现的方法, querHotBlog 是代码已经写好的。由于没有涉及到 Redis 的操作,这里就不再过多解释了。
@Resourceprivate IUserService userService;@Overridepublic Result queryHotBlog(Integer current) {// 根据用户查询Page<Blog> page = this.query().orderByDesc("liked").page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));// 获取当前页数据List<Blog> records = page.getRecords();// 查询用户records.forEach(this::queryBlogUser);return Result.ok(records);}@Overridepublic Result queryBlogById(Long id) {// 1. 查询blogBlog blog = getById(id);if(blog==null){return Result.fail("笔记不存在");}// 2. 查询blog有关的用户queryBlogUser(blog);return Result.ok(blog);}private void queryBlogUser(Blog blog) {Long userId = blog.getUserId();User user = userService.getById(userId);blog.setName(user.getNickName());blog.setIcon(user.getIcon());}
实现后,效果就是这样了。
点赞
代码中实现的点赞是 连续点赞的功能,但是这样的功能是不好的,如果有人调用这个接口,一直刷赞,数据库直接就爆了,所以我们要对这个功能进行改造
改造后的需求:
- 同一个用户只能点赞一次,再次点击则取消点赞
- 如果当前用户已经点赞,则点赞按钮高亮显示(前端已实现,判断Blog类的 isLike 属性)
那我们怎样来标记用户是否点赞过? 用 Redis 的 set集合可以实现,set 集合我们已经用了好几次了,set中的元素是不能重复的,可以用来标记
@Overridepublic Result likeBlog(Long id) {// 1.获取登录用户Long userId = UserHolder.getUser().getId();// 2.判断当前登录用户是否已经点赞Boolean isMember = stringRedisTemplate.opsForSet().isMember(BLOG_LIKED_KEY, userId.toString());// 3.如果未点赞,可以点赞if(BooleanUtil.isFalse(isMember)){// 起始这里我觉得也可以做一个异步任务,利用 Redis的高效性,去实现与用户的交互// 用异步任务来去修改数据库,感觉 Redis 和 数据库都可以这么来用// 3.1 数据库点赞数+1boolean isUpdate = update().setSql("liked=liked+1").eq("id", id).update();// 3.2 保存用户到 Redis的 set 集合if(isUpdate){stringRedisTemplate.opsForSet().add(BLOG_LIKED_KEY,userId.toString());}}else {// 4. 如果已经点赞,取消点赞// 4.1 数据库点赞数 -1boolean isUpdate = update().setSql("liked=liked-1").eq("id", id).update();// 4.1 把用户从Redis的 set 集合移除if(isUpdate){stringRedisTemplate.opsForSet().remove(BLOG_LIKED_KEY,userId.toString());}}return Result.ok();}
点赞排行榜
我们在探店笔记的详情页面,应该按照点赞的时间显示出来,比如最早点赞的 TOP5,形成点赞排行榜
但是我们刚才在实现点赞功能的时候,用的是 set 集合,但 set 集合中的元素是无序的,这就不符合我们的功能,所以我们要换一个数据结构,即能保留 set 的无序特点,又会使其中的元素有序,那就是 Redis 的 SortedSet
那接下来,我们就要去改造一下我们之前写的点赞功能
其实就是把之前用 set 集合的操作 换成 SortSet
@Overridepublic Result likeBlog(Long id) {// 1.获取登录用户Long userId = UserHolder.getUser().getId();// 2.判断当前登录用户是否已经点赞Double score = stringRedisTemplate.opsForZSet().score(BLOG_LIKED_KEY, userId.toString());// 3.如果未点赞,可以点赞if(score==null){// 3.1 数据库点赞数+1boolean isUpdate = update().setSql("liked=liked+1").eq("id", id).update();// 3.2 保存用户到 Redis的 set 集合if(isUpdate){stringRedisTemplate.opsForZSet().add(BLOG_LIKED_KEY,userId.toString(),System.currentTimeMillis());}}else {// 4. 如果已经点赞,取消点赞// 4.1 数据库点赞数 -1boolean isUpdate = update().setSql("liked=liked-1").eq("id", id).update();// 4.1 把用户从Redis的 set 集合移除if(isUpdate){stringRedisTemplate.opsForZSet().remove(BLOG_LIKED_KEY,userId.toString());}}return Result.ok();}private void isLiked(Blog blog){// 1.获取登录用户Long userId = UserHolder.getUser().getId();// 2.判断当前登录用户是否已经点赞Double score = stringRedisTemplate.opsForZSet().score(BLOG_LIKED_KEY, userId.toString());blog.setIsLike(score!=null);}
**那接下来我们就去实现这个点赞排行榜
@Overridepublic Result queryBlogLikes(Long id) {String key= BLOG_LIKED_KEY+id;// 1. 查询 top5 的点赞用户 zrange key 0 4Set<String> top5 = stringRedisTemplate.opsForZSet().range(key, 0, 4);if(top5==null||top5.isEmpty()){return Result.ok(Collections.emptyList());}// 这里用了大量的 stream流来处理集合,不太懂 stream流的朋友可以先去学习一下stream流List<Long> ids = top5.stream().map(Long::valueOf).collect(Collectors.toList());String idStr = StrUtil.join(",", ids);// 这里的 sql,没有默认的是因为,默认的排序它会按 id 降序排列,不符合我们的需求。List<UserDTO> userDTOS = userService.query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list().stream() // 这里处理一下是脱敏.map(user -> BeanUtil.copyProperties(user, UserDTO.class)).collect(Collectors.toList());return Result.ok(userDTOS);}
// 因为未登录用户会获取 user失败,所以这里加一下,其实这样做是不好的,业务容易乱,以后未登录
// 用户要使用的地方肯定还会有,所以建议还是写在 拦截器里。private void isLiked(Blog blog){// 1.获取登录用户UserDTO user = UserHolder.getUser();if (user==null){return;}Long userId = user.getId();// 2.判断当前登录用户是否已经点赞Double score = stringRedisTemplate.opsForZSet().score(BLOG_LIKED_KEY, userId.toString());blog.setIsLike(score!=null);}
至此,达人探店的模块我们也学完了,在这个模块,我们主要去使用了 Redis 中关于 set 和 SortedSet 的使用。🤗
好友关注
关注和取关
这个功能也没有用到 Redis, 也只是简单的业务,这里也就简单的记一下
其实这也是个挺常见的功能,不跟视频自己也可以手敲出来,这里就只记录 service层的代码
@Overridepublic Result follow(Long followUserId, Boolean isFollow) {Long userId = UserHolder.getUser().getId();// 1.判断到底是关注还是取关if(isFollow==true){Follow follow = new Follow();follow.setUserId(userId);follow.setFollowUserId(followUserId);save(follow);}else {remove(new QueryWrapper<Follow>().eq("user_id",userId).eq("follow_user_id",followUserId));}return Result.ok();}@Overridepublic Result isFollow(Long followUserId) {Long userId = UserHolder.getUser().getId();// 1.查询是否关注Integer count = query().eq("user_id", userId).eq("follow_user_id", followUserId).count();return Result.ok(count>0);}
共同关注
其实之后的课程有点为了练这个 Redis 而去开发的这个功能😢,但还是学完吧,也没有几节了
既然要实现 共同关注,那肯定要 先获取 两个用户的关注列表,然后去求交集,那在 Redis 中 set 集合是可以求交集的,所以我们这次用 set 集合来实现求共同关注的功能。在实现这个功能之前,我们先来实现下面两段代码
这两段 代码与共同关注没有什么关系,是用来完善用户的一些信息
// UserController
// 这个是用来点击头像,进入主页
@GetMapping("{id}")public Result queryUserById(@PathVariable("id") Long userId){User user = userService.getById(userId);if(user==null){return Result.ok();}UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);return Result.ok(userDTO);}
// BlogController
// 这个是进入主页后,显示这个博主的博客
@GetMapping("/of/user")public Result queryBlogByUserId(@RequestParam(value = "current",defaultValue = "1")Integer current,@RequestParam("id") Long id){Page<Blog> page = blogService.query().eq("user_id", id).page(new Page<>(current, SystemConstants.MAX_PAGE_SIZE));List<Blog> records = page.getRecords();return Result.ok(records);}
下面我们就来写共同关注的代码,首先我们要把之前写的关注稍微改一下,就是操作完数据库后,把关注列表形成一个 set 添加到 Redis 中。
@Overridepublic Result follow(Long followUserId, Boolean isFollow) {Long userId = UserHolder.getUser().getId();// 1.判断到底是关注还是取关if(isFollow==true){Follow follow = new Follow();follow.setUserId(userId);follow.setFollowUserId(followUserId);boolean save = save(follow);if(save){stringRedisTemplate.opsForSet().add("follows:"+userId,followUserId.toString());}}else {remove(new QueryWrapper<Follow>().eq("user_id",userId).eq("follow_user_id",followUserId));stringRedisTemplate.opsForSet().remove("follows:"+userId,followUserId.toString());}return Result.ok();}
然后我们来写 共同关注
@Overridepublic Result followCommons(Long id) {// 这里还是用来一些流操作的,不熟悉的朋友还是建议去看看流。// 其实这里真正要说的也就是求交集了 set 的 intersect命令Long userId = UserHolder.getUser().getId();String key="follows:"+userId;String followedKey="follows:"+id;Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key, followedKey);if(intersect==null||intersect.isEmpty()) return Result.ok(Collections.emptyList());List<Long> ids = intersect.stream().map(Long::valueOf).collect(Collectors.toList());List<UserDTO> users = userService.listByIds(ids).stream().map(user -> BeanUtil.copyProperties(user, UserDTO.class)).collect(Collectors.toList());return Result.ok(users);}
其实上面两个真的没有什么太多新的东西,用到的 Redis 的部分也是比较少的,想要学 Redis 的朋友也可以跳过这两节.
关注推送
关注推送也叫 Feed 流,直译为 投喂,为用户持续的提供 “沉浸式” 的体验,通过无限下拉获取新的信息
Feed 流产品有两种常见模式:
- TimeLine: 不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注.例如朋友圈
- 优点: 信息全面,不会缺失.并且实现也相对简单
- 缺点: 信息噪音较多,用户不一定感兴趣,内容获取效率低
- 智能排序: 利用智能算法屏蔽掉违规的,用户不感兴趣的内容,推送用户感兴趣的信息来吸引用户
- 优点: 投喂用户感兴趣信息,用户粘度高,容易沉迷
- 缺点: 如果算法不精确,可能起反作用
我们这个 个人页面,是基于关注的好友来做 Feed 流,因此采用 TIMELine 的模式,该模式的实现有三种
- 拉模式
- 推模式
- 推拉结合
拉模式
每个博主都会有一个发件箱,当他们发布消息的时候,都会先发到他们自己的发件箱当中,并且都带上时间戳,然后当有一个用户下拉刷新它的收件箱的时候,这时候,系统会从这个用户所关注的博主的发件箱中拉取信息,然后按时间戳排序.下面这个国就演示了这个过程,但是我们想想,它每下拉一次我们就都要给它拉取一次,并且还要排序,那这样性能是不是就不是很好,那我们接下来继续看 推模式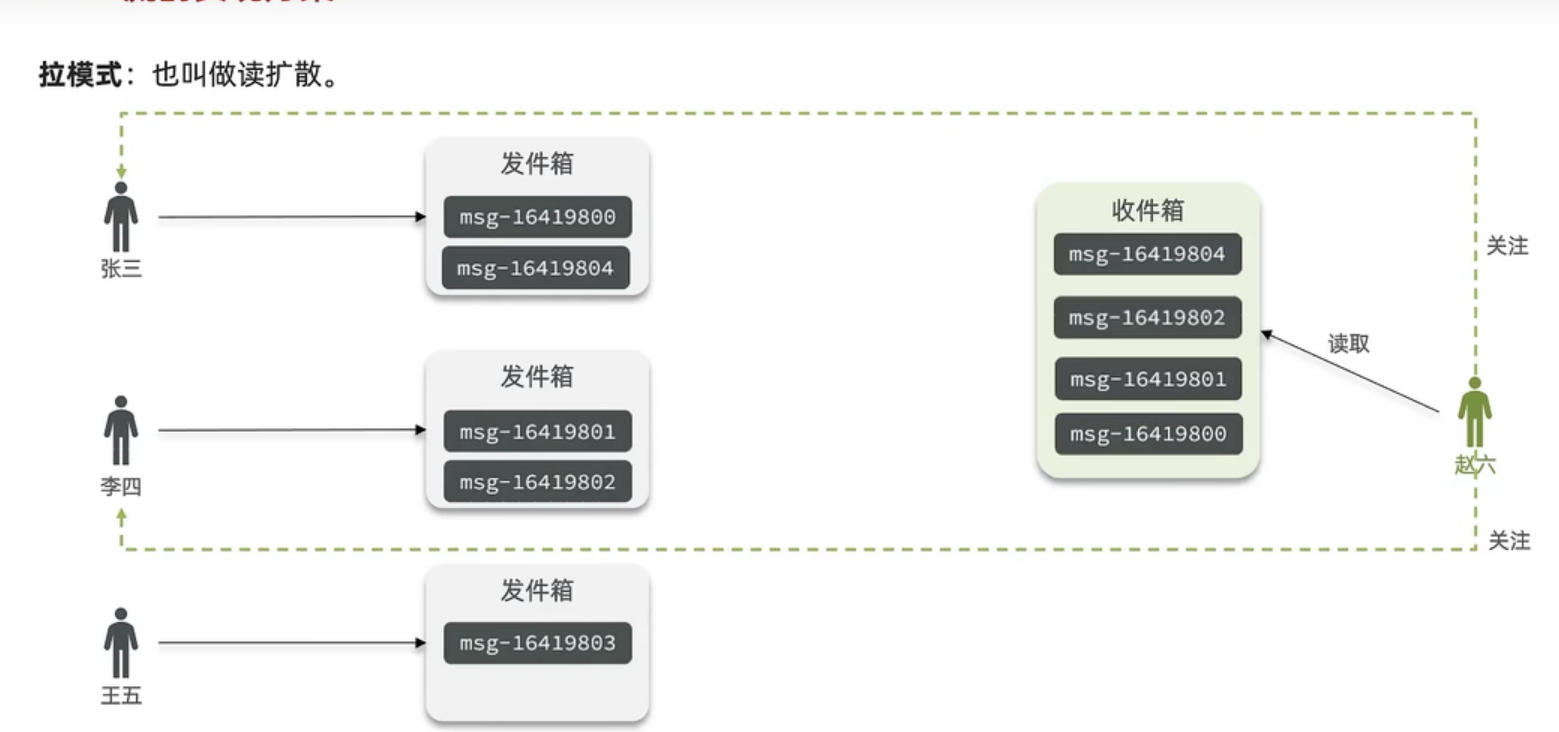
推模式
而推模式就与拉模式不太一样了,每个博主没有收件箱 了,而是把信息直接发给粉丝的收件箱,并且在收件箱内部排好序,这样粉丝下来刷新的时间,就直接从收件箱中取就可以了.这样就弥补了拉模式的效率问题.但是推模式同样有一个问题,就是如果有一个博主的粉丝很多,那它要给粉丝发消息就要发多份,这个数据量上来了,系统也没法承受,那么能不能把 这两种模式的优点结合起来呢,那就是接下的推拉模式了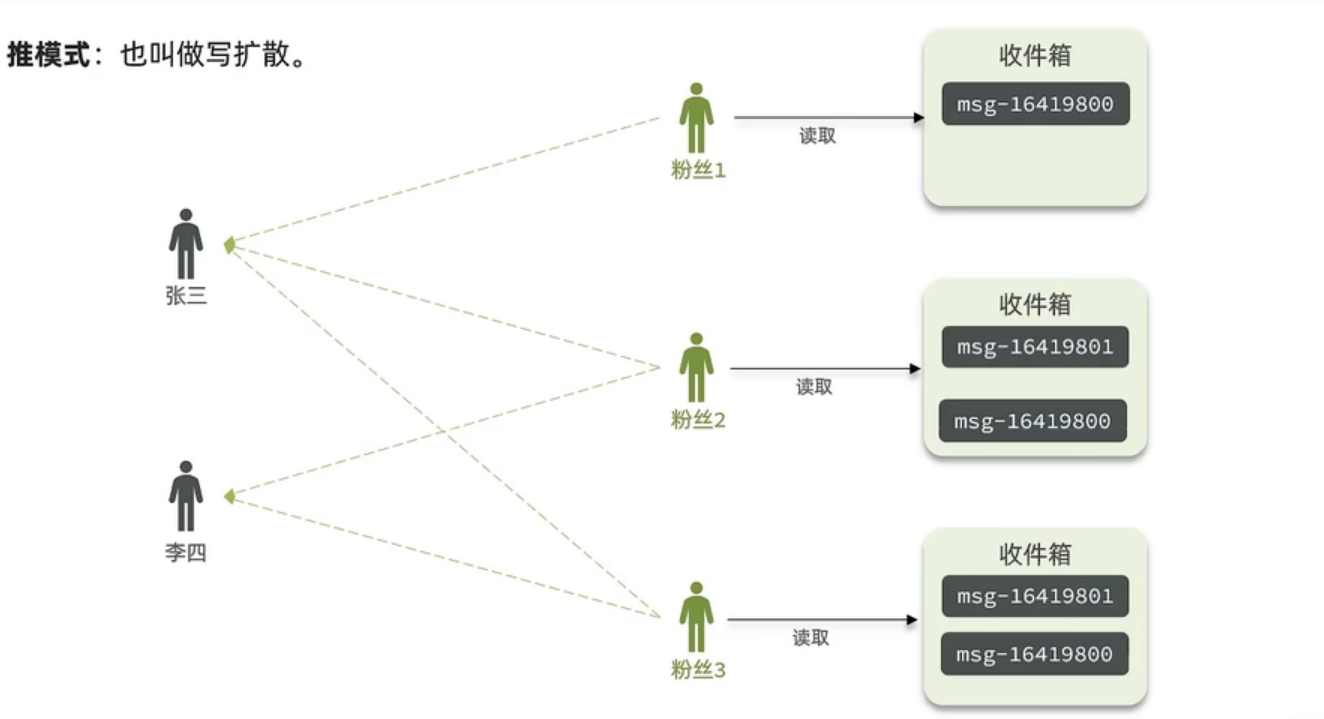
推拉模式
在推拉模式中,我们将博主分为 大V 和普通博主,大V的粉丝数很多,通常几千万,而普通博主的粉丝数就比较少了.
我们也把粉丝分为普通粉丝和活跃粉丝.
对于 大V来说,他的粉丝数很多,所以肯定不能用推模式,所以就用拉模式.但是对于一些活跃粉丝还是用推模式,因为这些活跃粉丝经常取看他们博主的信息,所以效率要高一些,而对于哪些普通粉丝就用拉模式,因为他们对博主的关注也不是很多,所以效率吗,慢一点也就慢一点了,而对于普通博主来说,他的粉丝数目没有那么多,所以用推模式也耗费不少资源.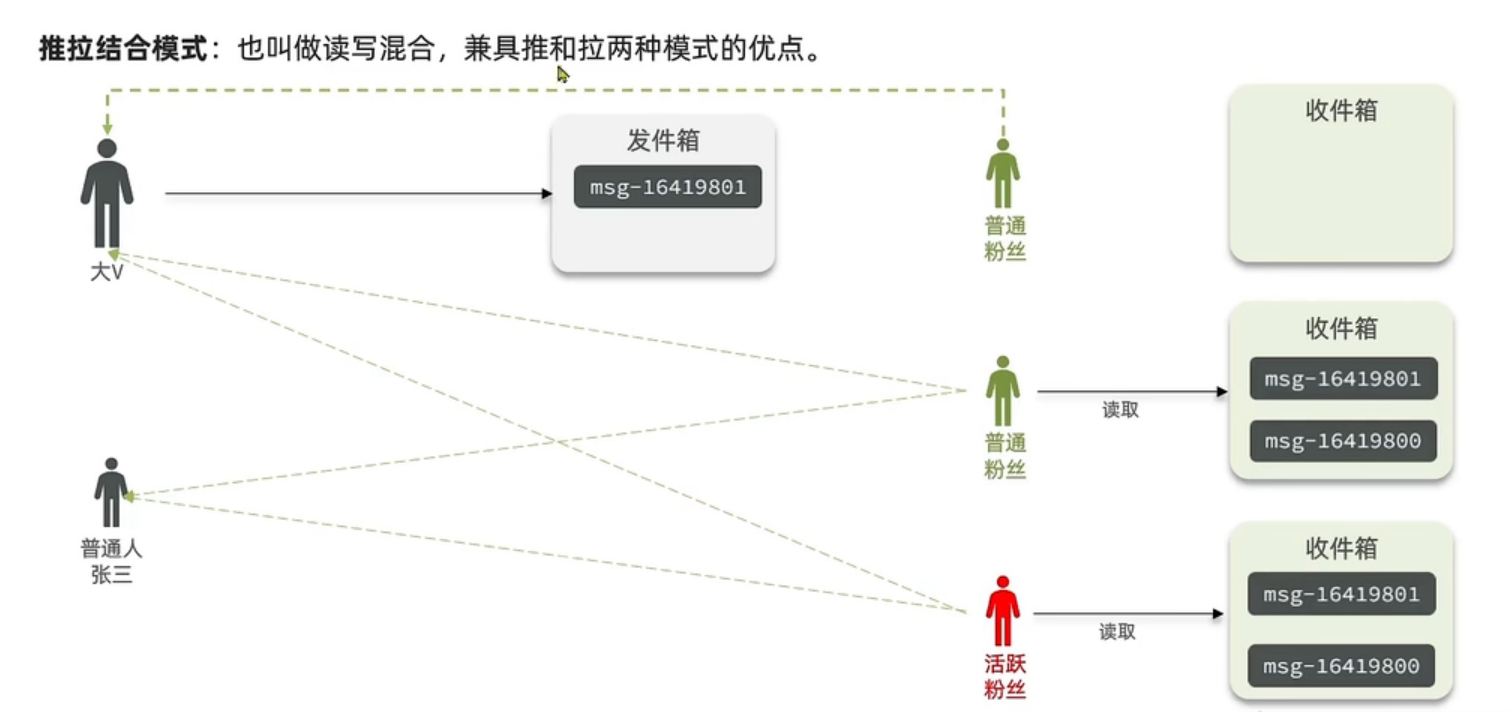
下面我们再来对比一下这三种模式的优缺点.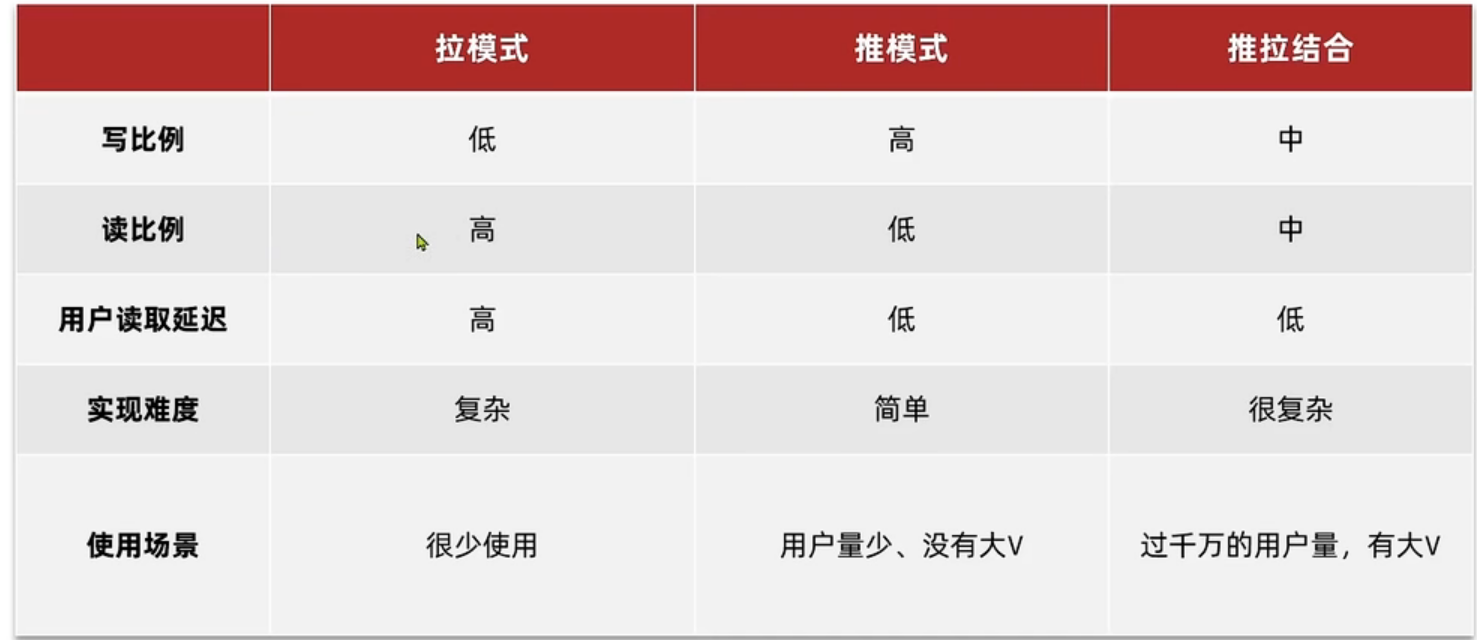
那对于我们这个系统,不会有大v,所以我们这采用推模式来实现.
关注推荐的实现
需求:
- 修改新增探店笔记的业务,在保存 blog 到数据库的时候,推送的收件箱
- 收件箱满足可以根据时间戳排序,必须用 Redis 的数据结构实现
- 查询收件箱时,可以实现分页查询。
我们先来修改新增博客的业务,这个业务用到了 Redis的 set结构来作为用户的收件箱,并把这个博客推送到这个博客的主人的粉丝的收件箱。
@Overridepublic Result saveBlog(Blog blog) {// 获取登录用户UserDTO user = UserHolder.getUser();blog.setUserId(user.getId());// 保存探店博文boolean isSuccess = save(blog);if(!isSuccess){return Result.fail("新增笔记失败");}List<Follow> follows = followService.query().eq("follow_user_id", user.getId().toString()).list();for (Follow follow : follows) {//获取粉丝 idLong userId = follow.getUserId();//推送String key="feeds:"+userId;stringRedisTemplate.opsForZSet().add(key,blog.getId().toString(),System.currentTimeMillis());}// 返回idreturn Result.ok(blog.getId());}
然后我们再来实现粉丝查看自己的收件箱,展示出这个用户所关注的博主的文章
但是我们这里想一下,这里的分页还能是传统的分页吗?
我们看下面这条图,t1时,查询5条,但是 t2这是又传过来了一个数据,t3这时候又查询5条数据,从头开始查的话,会查重一个。这就不是我们想要的,那怎么解决查重,就是滚动查询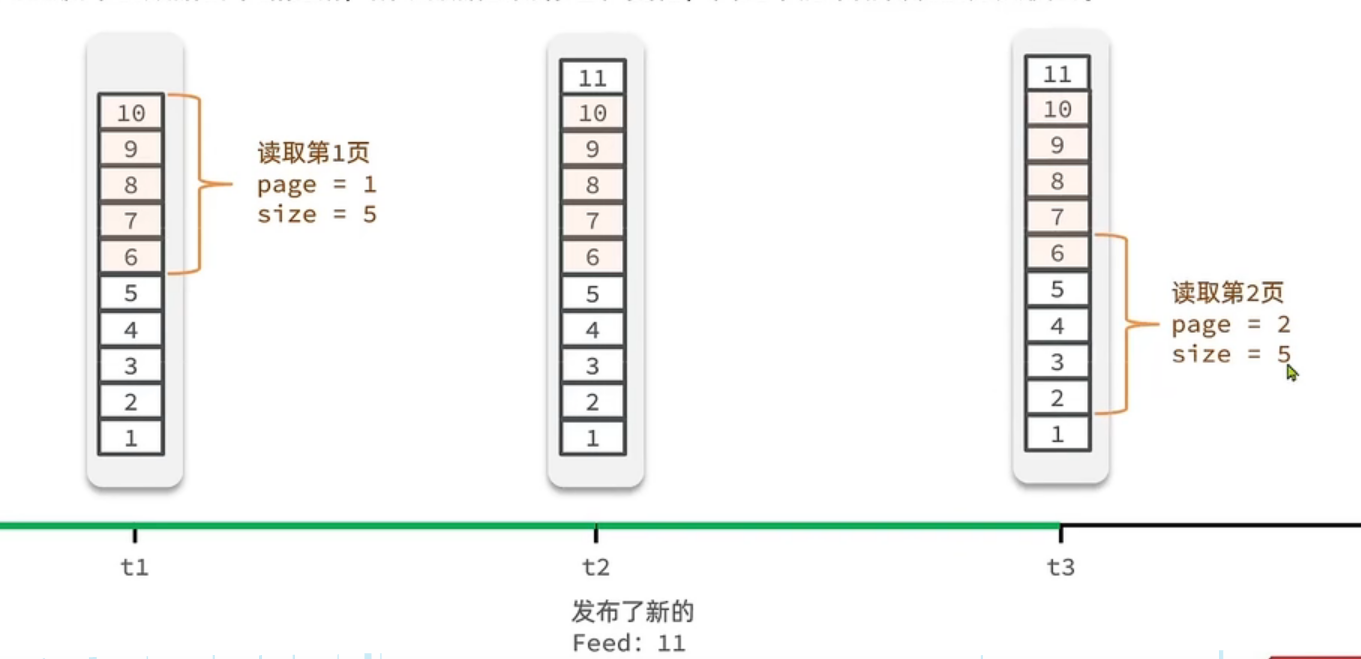
在滚动查询的时候
t1 和 t2 都是与上述一样,但是 t3时刻读取第二页,是从上回 的lastId 的下一个开始查的,这样就避免了查重,但是在 Redis 中如何实现呢,我们可以利用 SortedSet 来实现。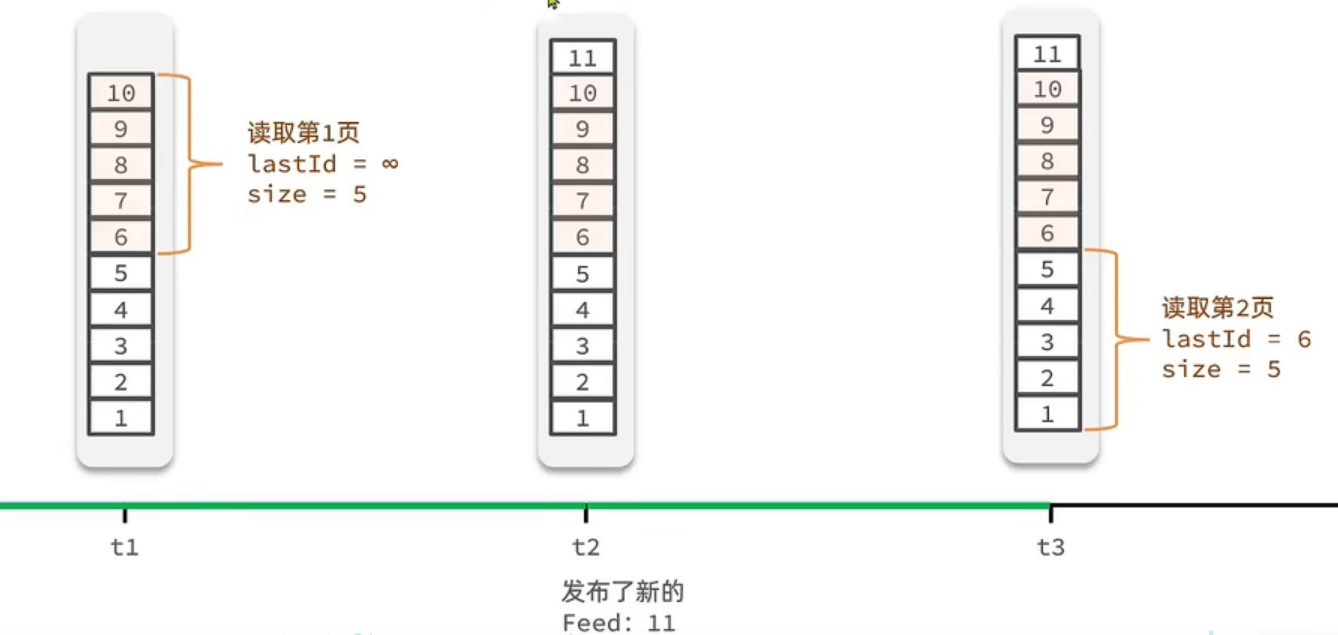
**SortedSet 中有一条命令是 **
ZREVRANGEBYSCORE 是用 score 来搜索
其中 max ,min是排序的范围,max是最大值,min是最小值。WITHSCORES是返回时带着分数 offset是偏移量,是从最大值的哪一个开始排序,0就是从最大值开始,1就是从最大值的下一个开始。count就是查几个。
那么我们就可以用时间戳来当分数,最新的时间戳就是最大的分数,排在第一位。第一次的时候可以拿当前时间戳,因为对于当前来说,当前时间戳是最大的,最小值我们不关心,就用 0. 第一次 offset 用0,因为第一次分数最大的我们也要。
然后往后 max 就应该是上回查询的最小分数,最小还是0,但是这时的 offset就应该是 1了,因为这次的最小分数是上一会的最小元素,我们上回已经查过了,这次不需要了。所以 offset 要用 1. 具体如下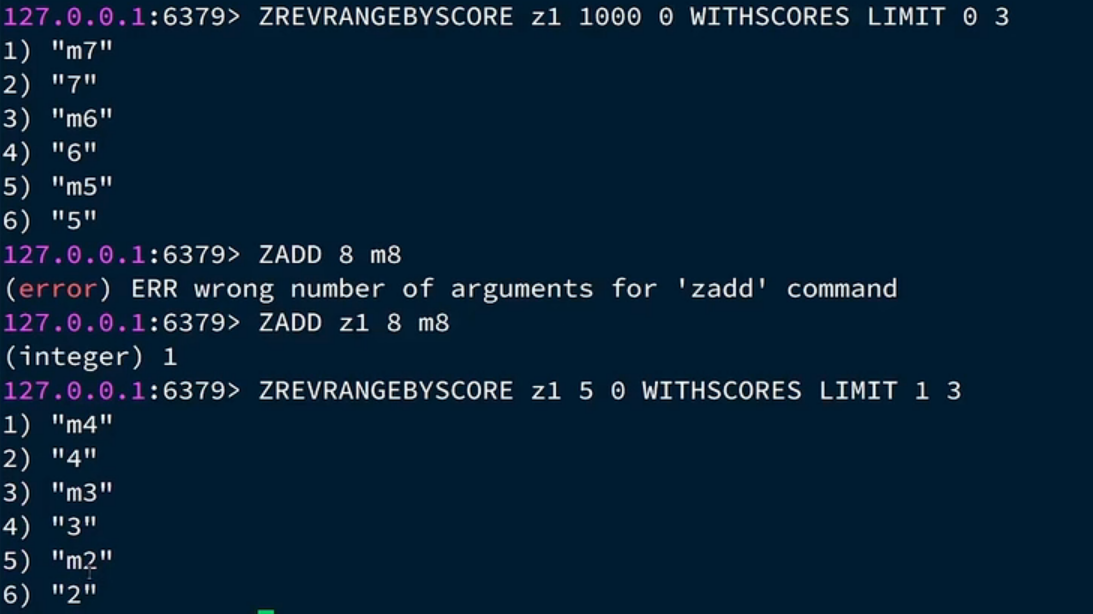
但是如果两个元素的时间戳一样怎么办?如果这个用户关注了很多博主,这些博主可能会在同一时间发布文章,都会推送到这个用户的收件箱。我们看下面的图看一下有什么问题
我们看一下,m7和m6的分数都是 6,第二次查看的时候还是出现了 6,这是为什么,因为,我们第二次查询的时候 max 是上回的 min,上回的 min是6,而我们的第二次的 offser 是 1,也就是 从分数为 6 的下一个开始,那分数为6 的从上往下 第一个是 m7,第二个是 m6,那可不是要从 m6开始查嘛,所以我们的 offset也要改,就是上一次最小分数的个数是多少,我们下一次的 offset就是多少,还是这个我们来开,6有两个,那第二次我们的 offser 就是 2,分数为6的第一个是m7,往下移动 2位,不就刚好把 上一次我们查到的 分数为6的隔过去了嘛、
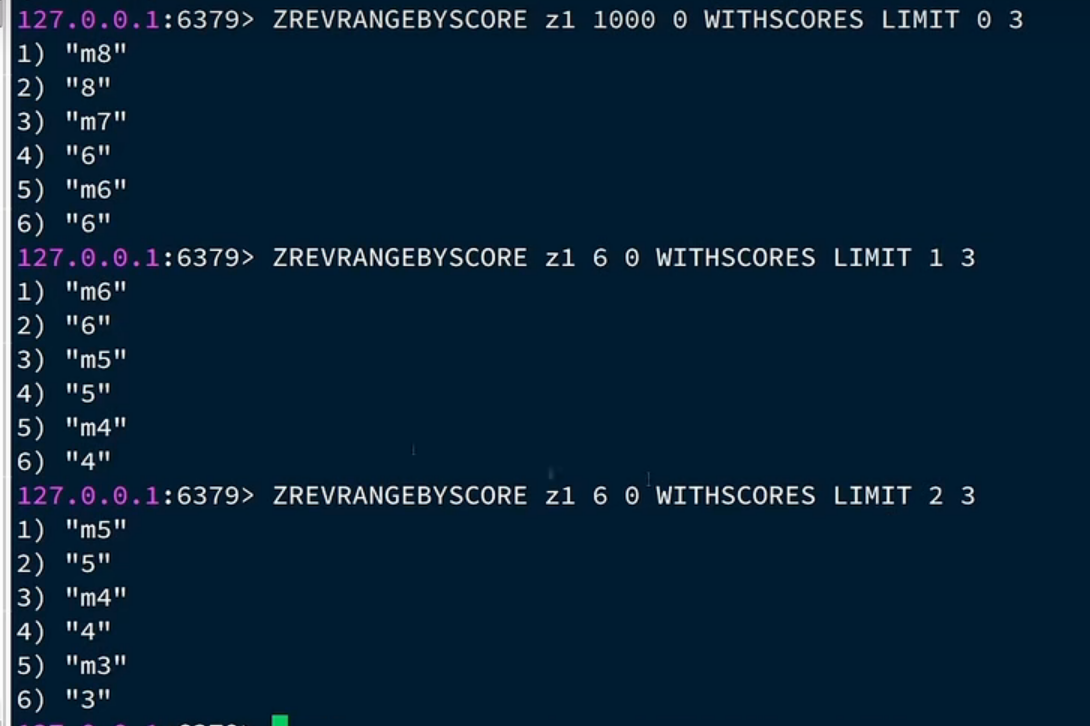
有的朋友可能这里会有的疑惑,如果我 m5 也是 6,你offset不就是 3了,不就把 m5 也隔过去了?
其实不是这样的,查重复的,我们只在上一次我们查到的里面查重复,不是对于整个 set 查。下面看效果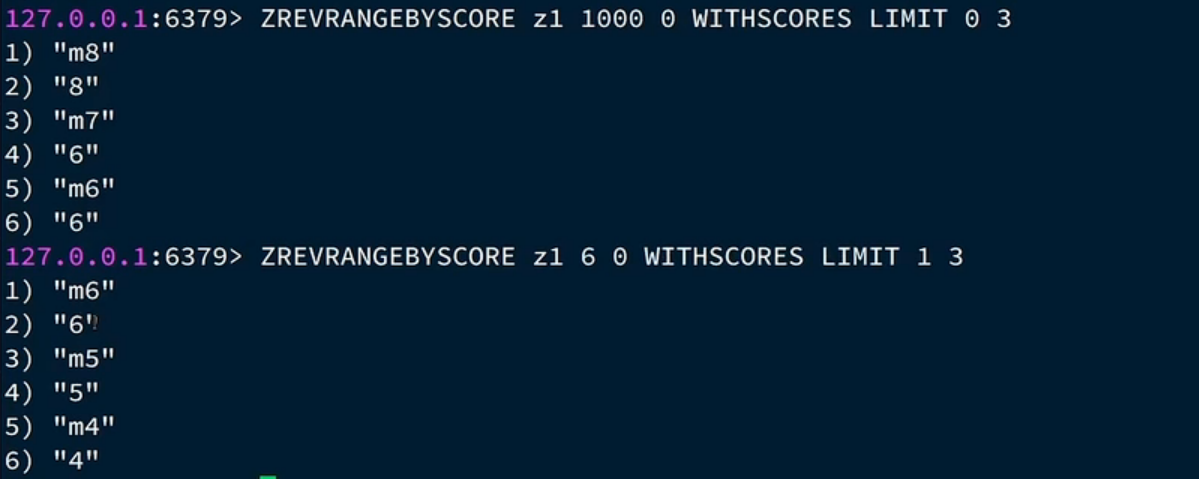
那思路有了,代码怎么实现呢,我们先来看接口的规范

我们在一次查询中,就要把 本次的最小时间戳和下一次要用的偏移量算出来,传给前端,前端下一次再调用这个接口的时候,就用这两个。下面是具体代码实现
@Overridepublic Result queryBlogOfFollow(Long max, Integer offset) {//1. 获取当前用户Long userId = UserHolder.getUser().getId();//2. 查询收件箱 ZREVRANGEBYSCORE key max min LIMIT offset countString key="feeds:"+userId;//3. 解析数据:blogId,timestamp,offset// 这里的 TypedTuple 是一个元组,里面有你要查的数据,以及分数Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 3);// 非空判断if(typedTuples==null||typedTuples.isEmpty()){return Result.ok();}//4. 根据id查询blogList<Long> ids=new ArrayList<>(typedTuples.size());long minTime=0;int os=1;// 接下来就是算 mintime 和 offset,其实这里我们还是用了一点点小算法,用一个 mintime// 变量来接受最小时间戳,然后每次从元组获取到时间戳,我们就赋给 mintime,这样遍历完// 后,mintime 就是最小的// 然后是 算 offset,这里我们根据 mintime,我们刚才不是说了嘛,遍历的过程中每获取一次// time ,就赋给 mintime,那么我们在赋之前,加一步,判断当前获取的这个 time 与 mintime//是否相等,相等,就让 os++,不相等就让 minTime=time,最后重置 os,到最后 os 一定是// 最小的时间戳的重复次数。// 其实else 里面 的赋值可以去掉,因为最后还会赋值。for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {//4.1 获取博客idids.add(Long.valueOf(typedTuple.getValue()));long time = typedTuple.getScore().longValue();if(time==minTime){os++;}else {minTime=time;os=1;}minTime = time;}//5. 封装并返回String idStr = StrUtil.join(",", ids);List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();for (Blog blog : blogs) {// 查询 blog 有关的用户queryBlogUser(blog);// 查询blog 是否被点赞isLiked(blog);}ScrollResult scrollResult = new ScrollResult();scrollResult.setList(blogs);scrollResult.setOffset(os);scrollResult.setMinTime(minTime);return Result.ok(scrollResult);}
那么今天关于好友关注这个模块就学完了,虽然前面的比较简单,但是最后一个理解起来还是有一定难度的
总结
最后的最后,还是希望Redis实战篇系列比较可以对大家的学习以及工作有一定的帮助,那我们的实战篇笔记就到这里撒花完结了,朋友们,我们高级篇再见。
我是Mayphyr,从一点点到亿点点,我们下次再见
相关文章:
Redis实战篇笔记(最终篇)
Redis实战篇笔记(七) 文章目录 Redis实战篇笔记(七)前言达人探店发布和查看探店笔记点赞点赞排行榜 好友关注关注和取关共同关注关注推送关注推荐的实现 总结 前言 本系列文章是Redis实战篇笔记的最后一篇,那么到这里…...

游戏配置表的导入使用
游戏配置表是游戏策划的标配,如下图: 那么程序怎么把这张配置表导入使用? 1.首先,利用命令行把Excel格式的文件转化成Json格式: json-excel\json-excel json Tables\ Data\copy Data\CharacterDefine.txt ..\Clien…...
❀dialog命令运用于linux❀
目录 ❀dialog命令运用于linux❀ msgbox部件(消息框) yesno部件(yesno框) inputbox部件(输入文本框) textbox部件(文本框) menu部件(菜单框) fselect部…...

【算法】蓝桥杯2013国C 横向打印二叉树 题解
文章目录 题目链接题目描述输入格式输出格式样例自己的样例输入自己的样例输出 思路整体思路存储二叉搜索树中序遍历并存储计算目标数的行号dfs遍历并写入数组初始化和处理输入输出初始化处理输入处理输出 完整的代码如下 结束语更新初始化的修改存储二叉搜索树的修改中序遍历和…...

XunSearch 讯搜 error: storage size of ‘methods_bufferevent’ isn’t known
报错: error: storage size of ‘methods_bufferevent’ isn’t known CentOS8.0安装迅搜(XunSearch)引擎报错的解决办法 比较完整的文档 http://www.xunsearch.com/download/xs_quickstart.pdf 官方安装文档 http://www.xunsearch.com/doc/php/guide/start.in…...
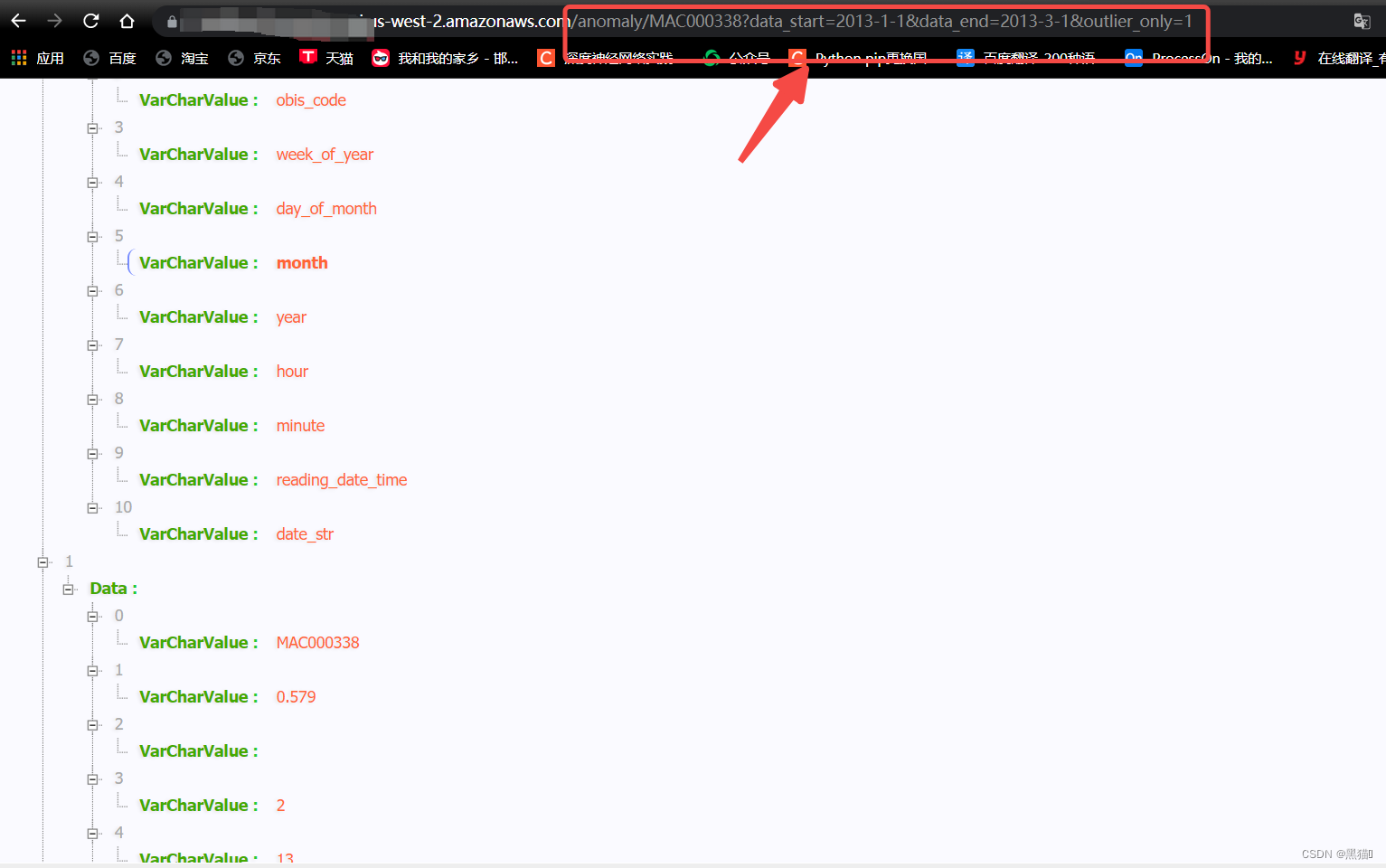
基于AWS Serverless的Glue服务进行ETL(提取、转换和加载)数据分析(三)——serverless数据分析
3 serverless数据分析 大纲 3 serverless数据分析3.1 创建Lambda3.2 创建API Gateway3.3 结果3.4 总结 3.1 创建Lambda 在Lambda中,我们将使用python3作为代码语言。 步骤图例1、入口2、创建(我们选择使用python3.7)3、IAM权限(…...

08、分析测试执行时间及获取pytest帮助
官方用例 # content of test_slow_func.py import pytest from time import sleeppytest.mark.parametrize(delay,(1.1,1.2,1.3,1.4,1.5,1.6,1.7,1.8,1.9,1.0,0.1,0.2,0,3)) def test_slow_func(delay):print("test_slow_func {}".format(delay))sleep(delay)assert…...

视频集中存储/智能分析融合云平台EasyCVR平台接入rtsp,突然断流是什么原因?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...
)
JavaScript 复杂的<三元运算符和比较操作>的组合--案例(一)
在逆向的时候,碰上有些复杂的js代码,逻辑弄得人有点混; 因此本帖用来记录一些棘手的代码,方便自己记忆,也让大家拓展认识~ ----前言 内容: function(e, t, n) {try {1 (e "{" e[0] ? JSON.parse(e) : JSON.parse(webInstace.shell(e))).Status || 200 e.Code…...

uniapp搭建内网映射测试https域名
搭建Https域名服务器 使用github的frp搭建,使用宝塔申请免费https证书,需要先关闭宝塔nginx的反向代理,申请完域名后再开启反向代理即可。 教程 新版frp搭建教程 启动命令 服务器端 sudo systemctl start frps本地 cd D:\软件安装包\f…...

国防科技大博士招生入学考试【50+论文主观题】
目录 回答模板大意创新和学术价值启发 论文分类(根据问题/场景分类)数学问题Efficient Multiset Synchronization(高效的多集同步【简单集合/可逆计数Bloom过滤器】)大意创新和学术价值启发 An empirical study of Bayesian netwo…...
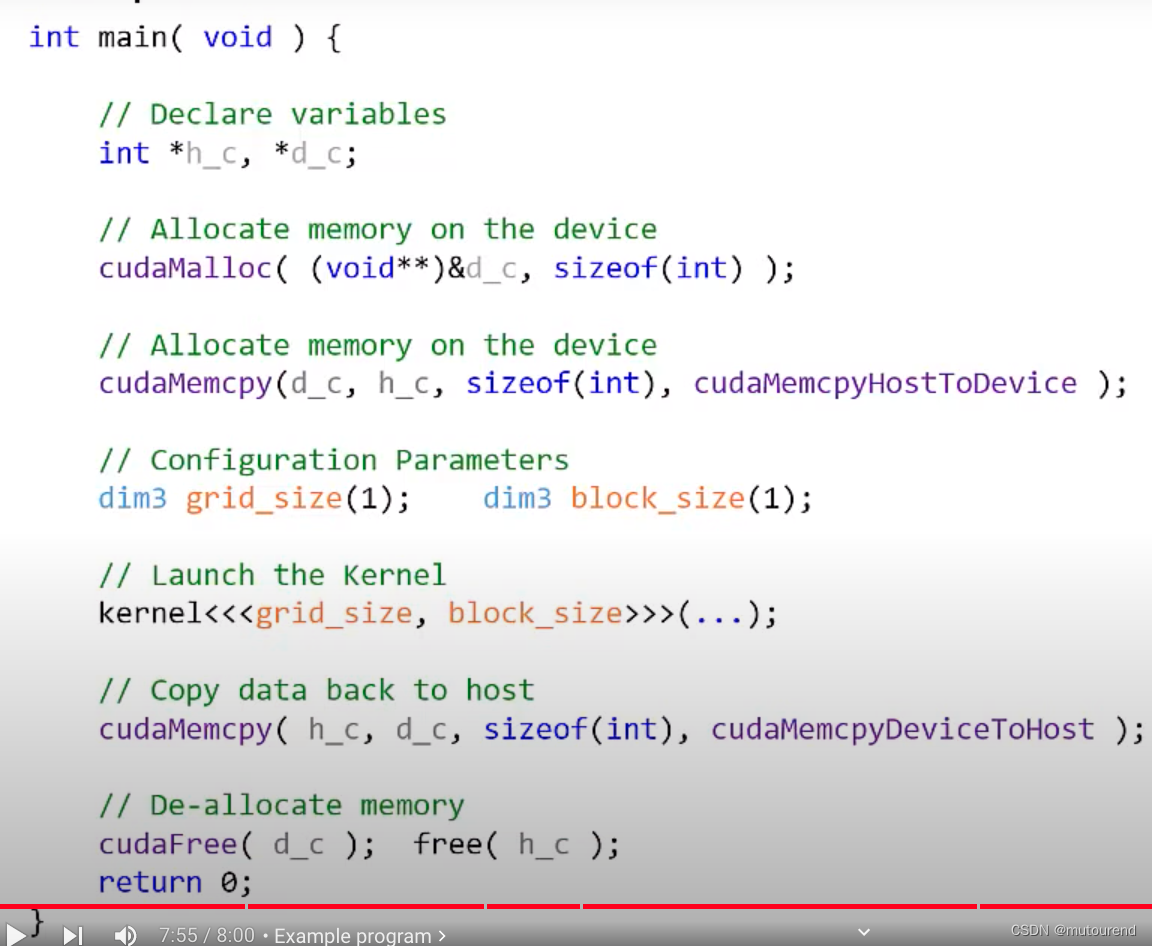
CUDA简介——编程模式
1. 引言 前序博客: CUDA简介——基本概念 CPU是用于控制的。即,host控制整个程序流程: 1)程序以Host代码main函数开始,然后顺序执行。 Host代码是顺序执行的,并执行在CPU之上。Host代码会负责Launch ke…...

Linux 软件安装
目录 一、Linux 1、Linux异常解决 1、JDK安装 1、Linux卸载JDK 2、Linux安装JDK 2、Redis安装 一、Linux 1、Linux异常解决 1、Another app is currently holding the yum lock; waiting for it to exit... 解决办法: rm -f /var/run/yum.pid1、杀死这个应用程序 ps a…...

flask之邮件发送
一、安装Flask-Mail扩展 pip install Flask-Mail二、配置Flask-Mail 格式:app.config[参数]值 三、实现方法 3.1、Mail类 常用类方法 3.2、Message类,它封装了一封电子邮件。构造函数参数如下: flask-mail.Message(subject, recipient…...
【Filament】Filament环境搭建
1 前言 Filament 是一个实时物理渲染引擎,用于 Android、iOS、Linux、macOS、Windows 和 WebGL 平台。该引擎旨在提供高效、实时的图形渲染,并被设计为在 Android 平台上尽可能小而尽可能高效。Filament 支持基于物理的渲染(PBR)&…...
外包干了2个月,技术倒退2年。。。。。
先说一下自己的情况,本科生,20年通过校招进入深圳某软件公司,干了接近4年的功能测试,今年国庆,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试…...

使用 python ffmpeg 批量检查 音频文件 是否损坏或不完整
自用工具,检查下载的音乐是否有损坏 或 下载不完整 使用方法,把 in_dir r’D:\158首无损珍藏版’ 改成你自己的音乐文件夹路径 如果发现文件有损坏,则会在命令行打印错误文件的路径 注意,要求 ffmpeg 命令可以直接在命令行调用…...
)
Django:通过user-agent判断请求是来自移动端还是PC端(电脑端)
第一种思路: 根据博文 Djano的request.META是什么?的研究成果,先判断有无键HTTP_SEC_CH_UA_MOBILE,如果没有,再去按博文 网站如何判断请求是来自手机-移动端还是PC-电脑端?如何让网站能适应不同的客户端&am…...
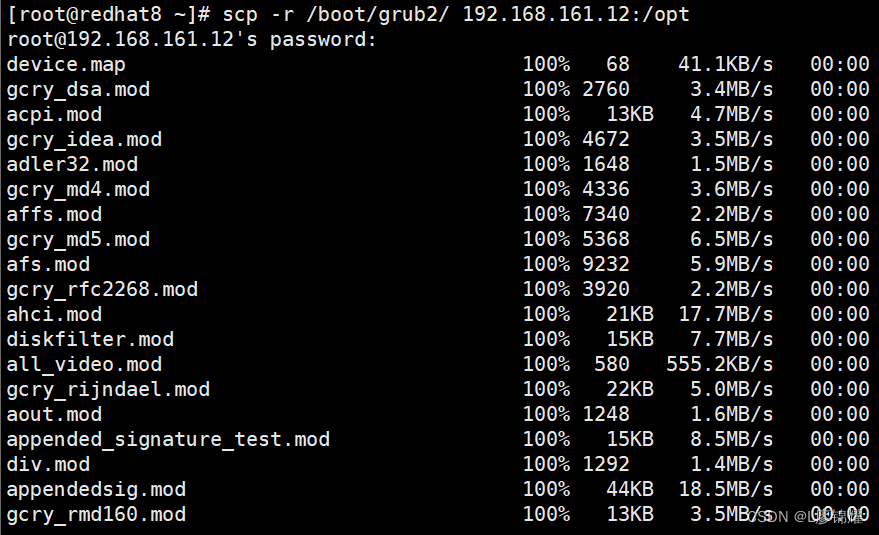
Linux中ssh远程登录系统和远程拷贝
本章主要介绍ssh远程登录系统和远程拷贝的方法 ssh的基本用法打开远程图形化界面ssh无密码登录和安全操作Windows远程登录远程拷贝 很多时候服务器并没有显示器,我们也不可能每次都通过控制台去管理服务器,这时就需 要远程登录。远程登录到服务器可以通…...
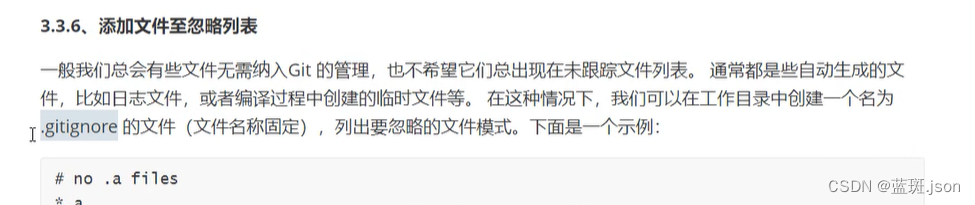
git常用命令小记
(文章正在持续更新中) git init - 在当前目录下初始化一个新的 Git 仓库。 git clone [url] - 克隆远程仓库到本地。 git add [file] - 将文件添加到暂存区。 git commit -m "commit message" - 将添加到暂存区的文件提交到本地仓库。 git pus…...

复杂技术决策如何避免“竞选广告”陷阱?工程师必备的4项流程变革
1. 从一场“选举广告”引发的思考:工程师如何审视复杂系统设计午餐时看新闻,每个广告时段都被政治竞选广告塞满,内容无一例外都在攻击对手,却对自身主张闭口不谈。这场景让我这个在电子设计自动化(EDA)和半…...

Windows 10终极PL2303驱动修复指南:让老旧串口设备重获新生
Windows 10终极PL2303驱动修复指南:让老旧串口设备重获新生 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 还在为Windows 10系统下的PL2303串口设备无法正…...
原理、影响与防护策略全解析)
FPGA单粒子翻转(SEU)原理、影响与防护策略全解析
1. 是什么在“骚扰”我的FPGA?——深入解析单粒子翻转作为一名在电子设计领域摸爬滚打了十几年的工程师,我经手过不少高可靠性的项目,从地面通信基站到近地轨道的载荷设备都有涉及。在这些项目中,有一个幽灵般的问题总是如影随形&…...

书匠策AI课程论文一键生成?我替你们踩了一遍,真香预警!
各位论文困难户们,先别划走! 今天不聊别的,就聊一个让我这个老博主都直呼"离谱"的东西——书匠策AI的课程论文功能。我知道你们一看到AI写论文就条件反射觉得是割韭菜,但这次,我是真的被圈粉了。 先说结论…...

千万级用户购物车系统的架构设计
我们当时搞的购物车服务,其实还是有点庞大的,看似是一个简单的CRUD,但是当你真正去实现一个购物车的时候,发现压根不是那回事。 当商品类型从单一SKU扩展到普通商品、套餐组合、活动商品,拼单等混合的时候,…...

PCI总线‘对话’的艺术:主从设备如何通过FRAME#、STOP#信号优雅地‘开始’与‘结束’传输
PCI总线‘对话’的艺术:主从设备如何通过FRAME#、STOP#信号优雅地‘开始’与‘结束’传输 在计算机系统的内部世界里,总线的数据传输就像一场精心编排的舞会。PCI总线作为这场舞会的舞台,主从设备之间的每一次交互都遵循着严格的礼仪规则。这…...

开发AI智能体时利用Taotoken统一调度多模型提升任务完成率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI智能体时利用Taotoken统一调度多模型提升任务完成率 在构建需要处理复杂、多模态任务的AI智能体时,单一模型的能…...

票据的采集,更新业务 todo 抽空迁移并废弃掉
采集过程 用户校验 参数校验部分 代码号码开票日期校验码(普票或电票必须)金额 是否有id,有id说明已存在,则应该是更新(该用更新接口)如果能查到,说明重复采集了查不到,新增存库...

Open UI5 源代码解析之1378:DestinationField.js
源代码仓库: https://github.com/SAP/openui5 源代码位置:src\sap.ui.integration\src\sap\ui\integration\editor\fields\DestinationField.js DestinationField.js 文件分析 文件定位与整体判断 DestinationField.js 是 sap.ui.integration 编辑器体系中的一个专用字段…...

如何评估Diem投资价值:代币经济学与估值模型终极指南
如何评估Diem投资价值:代币经济学与估值模型终极指南 【免费下载链接】diem Diem’s mission is to build a trusted and innovative financial network that empowers people and businesses around the world. 项目地址: https://gitcode.com/gh_mirrors/di/die…...