数据收集与处理(爬虫技术)
文章目录
- 1 前言
- 2 网络爬虫
- 2.1 构造自己的Scrapy爬虫
- 2.1.1 items.py
- 2.1.2 spiders子目录
- 2.1.3 pipelines.py
- 2.2 构造可接受参数的Scrapy爬虫
- 2.3 运行Scrapy爬虫
- 2.3.1 在命令行运行
- 2.3.2 在程序中调用
- 2.4 运行Scrapy的一些要点
- 3 大规模非结构化数据的存储与分析
- 4 全部代码
1 前言
- 介绍几种常见的数据收集、存储、组织以及分析的方法和工具
- 首先介绍如何构造自己的网络爬虫从网上抓取内容,并将其中按照一定结构组织的信息抽取出来
- 然后介绍如何使用ElasticSearch来有效地存储、组织和查询非结构化数据
- 最后简要介绍和使用Spark对大规模的非结构化数据进行初步分析的方法
2 网络爬虫
2.1 构造自己的Scrapy爬虫
-
在终端输入
scrapy startproject money163,会自动生成一个同名的子目录和一个scrapy.cfg配置文件 -
-
有两个init文件都是空白的,暂时不用管,将经历放在items.py、settings.py、pipelines.py和将要在spiders子目录下生成的爬虫程序上
-
基本结构建立起来之后,需要按照说明的步骤一次完成对内容抽取,爬虫目标和行为以及数据操作的定义,每一个定义都对应一个文件。
2.1.1 items.py
- 在这个文件里面定义需要抽取的内容,这基本上是通过定义一个继承于scrapy.Item的内容类来完成的,每一个内容都属于scrapy.Field(),定义非常简单,即内容名称 = scrapy.Field()
2.1.2 spiders子目录
- 在spiders子目录下新建一个python文件,假设命名为money_spider.py
- 这个文件比较复杂,可以继承不同的类来定义
- 首先使用Scrapy的CrawlSpider类,定义三个内容:一是爬虫的名字,二是目标网站,包括爬取模式和对返回链接的过滤等;三是返回的对象按照其结构抽取所需要的数据
- 在money_spider.py文件中输入以下代码,注意将Stock163换成money163
# encoding: utf-8
import scrapy
import re
from scrapy.selector import Selector
from stock163.items import Stock163Item
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Ruleclass ExampleSpider(CrawlSpider):name = "stocknews" #爬虫的名字为 "stocknews"allowed_domains = ["money.163.com"]#设置允许爬取的域名def __init__(self, id='600000', page='0', *args, **kwargs):#初始化方法,设置了一些初始参数,包括 id(默认为 '600000')、page(默认为 '0'),以及其他可能传递的参数。# allowrule = "/%s/%s\d+/\d+/*" % (year, month)# allowrule = "/%s/%s%s/\d+/*" % (year, month, day) #这个规则匹配类似 "/2022/11/25/" 这样的日期结构allowrule = r"/\d+/\d+/\d+/*"# 定义了一个正则表达式,用于匹配新闻链接的规则。数字 数字 数字 任意字符self.counter = 0 # 初始化一个计数器,可能用于跟踪爬取的新闻数量。self.stock_id = id # 保存股票IDself.start_urls = ['http://quotes.money.163.com/f10/gsxw_%s,%s.html' % (id, page)] # 设置初始爬取的URL,这里使用了 id 和 page 参数构造URL。ExampleSpider.rules = (Rule(LinkExtractor(allow=allowrule), callback="parse_news", follow=False),)# 定义了爬取规则。这里使用了 LinkExtractor 来提取链接,通过正则表达式 allow=allowrule 匹配链接规则,然后指定了回调函数为 parse_news# 最后设置 follow=False 表示不跟踪从当前链接提取的链接。# recompile the rulesuper(ExampleSpider, self).__init__(*args, **kwargs)# 调用父类(CrawlSpider)的初始化方法,确保爬虫的正确初始化。'''rules=Rule(LinkExtractor(allow=r"/\d+/\d+/\d+/*"),callback="parse_news", follow=True)'''# f = open("out.txt", "w")def printcn(suni):for i in suni:print(suni.encode('utf-8'))def parse_news(self, response):item = Stock163Item()item['news_thread'] = response.url.strip().split('/')[-1][:-5]#这行代码从响应的URL中提取新闻线程信息。它首先通过response.url获取当前页面的URL,然后使用strip()方法去除首尾的空格,接着使用split('/')方法根据斜杠切割URL为一个列表,最后通过[-1]#取列表的最后一个元素,即URL中最后一个斜杠后的部分。[: -5] 是为了去掉文件扩展名(假设是.html或类似的扩展名),剩下的部分就是新闻线程的信息,然后将其赋值给item对象的news_thread属性。self.get_thread(response,item)self.get_title(response, item)self.get_source(response, item)self.get_url(response, item)self.get_news_from(response, item)self.get_from_url(response, item)self.get_text(response, item)return item ##############!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!remenber to Retrun Item after parsedef get_title(self, response, item):title = response.xpath("/html/head/title/text()").extract()if title:# print ('title:'+title[0][:-5].encode('utf-8'))item['news_title'] = title[0][:-5]def get_source(self, response, item):source = response.xpath("//div[@class='left']/text()").extract()if source:# print ('source'+source[0][:-5].encode('utf-8'))item['news_time'] = source[0][:-5]def get_news_from(self, response, item):news_from = response.xpath("//div[@class='left']/a/text()").extract()if news_from:# print 'from'+news_from[0].encode('utf-8')item['news_from'] = news_from[0]def get_from_url(self, response, item):from_url = response.xpath("//div[@class='left']/a/@href").extract()if from_url:# print ('url'+from_url[0].encode('utf-8') )item['from_url'] = from_url[0]def get_text(self, response, item):news_body = response.xpath("//div[@id='endText']/p/text()").extract()if news_body:# for entry in news_body:# print (entry.encode('utf-8'))item['news_body'] = news_bodydef get_url(self, response, item):news_url = response.urlif news_url:print(news_url)item['news_url'] = news_url2.1.3 pipelines.py
- 接着需要对所抽取的具体要素进行处理,要么显示在终端的窗口中,要么存入某个地方或者数据库中,现在我们假设将所抽取出来的要素构造成一个词典,以JSON文档的格式存为文本文件,每个页面单独存成一个文件。
- 这个时候需要定义一个类,这个类里面只有一个方法,process_item(self,item,spider)
# -*- coding: utf-8 -*-# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
#encoding: utf-8
import os
def ParseFilePath(url, id):# user should change this folder pathoutfolder = "e:\\data\\FinTech\\News\\Stocks\\%s" % idcomponents = url.split("/")year = components[3]monthday=components[4]month = monthday[:2]day = monthday[2:]idx=components[5]page=idx+"_"+components[6]#folder = outfolder + "\\%s_%s_%s_" % (year, month, day)folder = outfolderif ((year=='') | ('keywords' in page)):filepath='xxx'else:filepath = folder + "\\%s_%s_%s_%s.txt" % (year, month, day, page) filepath=filepath.replace('?', '_')return(folder, filepath)class Stock163Pipeline(object): def process_item(self, item, spider):if spider.name != "stocknews": return itemif item.get("news_thread", None) is None: return itemurl = item['news_url']if 'keywords' in url:return itemfolder, filepath = ParseFilePath(url, spider.stock_id)spider.counter = spider.counter+1counterfilepath = folder+"\\counter.txt"#one a single machine will is virtually no risk of race-conditionif not os.path.exists(folder):os.makedirs(folder) #print(filepath, counterfilepath)#print(spider.stats)fo = open(counterfilepath, "w", encoding="UTF-8")fo.write(str(spider.counter))fo.close()if (filepath!='xxx'):fo = open(filepath, 'w', encoding='utf-8')fo.write(str(dict(item)))fo.close()return None2.2 构造可接受参数的Scrapy爬虫
- 这节内容主要介绍能改变起始网页的地址,从而使得同一个爬虫爬去不同的网站
- 修改来start_urls,同时也修改了allowed_domain,保证爬虫顺利进行,最后通过super方法执行这个类,来更新参数
`class ExampleSpider(CrawlSpider):name = "stocknews"def __init__(self, id='600000', page='0', *args, **kwargs): #allowrule = "/%s/%s\d+/\d+/*" % (year, month)allowrule = "/%s/%s%s/\d+/*" % (year, month, day) self.counter = 0self.stock_id = idself.start_urls = ['http://\%s' \% (site)]ExampleSpider.rules=(Rule(LinkExtractor(allow=allowrule), callback="parse_news", follow=False),)#recompile the rule `
2.3 运行Scrapy爬虫
- 一种是在命令行里面执行crawl命令,一种是在别的程序中调用Scrapy爬虫
- 命令行中是单线程,程序调用是多线程,一次可以同时爬取不同的网站,当然也可以通过twisted包里面的internet.defer方法来将每个爬虫串联起来,同时调用reactor来控制执行顺序
- Scrapy也可以在多台机器上部署分布式
2.3.1 在命令行运行
- 在命令行中非常简单,进入项目的主目录,即包含scrapy.cfg文件的那个目录,输入:scrapy crawl money163,这里的money163是在spider.py程序文件中使用“ name=“money163”定义的爬虫名字,crawl是让Scrapy爬虫开始爬去网页“scrapy craw money163 -a site = money.163.com/stock
2.3.2 在程序中调用
- 在别的程序里调用Scrapy爬虫可以使用不同的类,这里使用CrawlerProcess类,配合get_project_setting方法,就可以在项目目录中非常方面地使用别的程序运行自己的爬虫
-首先引入相应的模块和函数
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
- 然后定义爬虫过程,在定义的过程中,先通过get_project_settings获取项目的信息,再传给所定义的爬虫过程
process = CrawlerProcess(get_project_settings()) - 定义好爬虫过程后,只需调用这个过程对象,包括传递参数,就能运行爬虫了,比如:
process.crawl('stocknews', id=stockid, page=str(page)) - 按照列表中的三个网址定义了三个爬虫,最后通过process.start来启动爬虫,因为使用了get_project_settings,这个python程序需要在项目所在目录下执行才能有效运行
for site in ['money.163.com', 'tech.163.com', 'money.163.com/stock']: process.crawl('myspider', site = site)
process.start()
2.4 运行Scrapy的一些要点
- 有些网站会对网络请求是否是网络爬虫进行识别,如果发现是网络爬虫,则会进行约束,比如限制流量甚至直接拒绝响应
- 因此需要合理设置setting.py和middleware文件里面的选项来实现
3 大规模非结构化数据的存储与分析
- 非结构化的数据是指没有定义结构的数据,一种典型的非结构化数据是文本,包括日期、数字、人名、事件等,这样的数据没有规则可循
- 比如数据挖掘、自然语言处理、文本分析等提供了不同方法从非结构化数据里找出模式,处理文本常用的技巧通常涉及到元数据或者词性标签手动标记
- 非结构化数据一般使用schema.org定义的类型和属性作为标记(比如JSON- LD)
- 当单个网页上有多种实体类型时,这些实体应该都被标记,例如视频schemma.org/VideoObject
4 全部代码
from keras.applications.vgg16 import VGG16
from keras.layers import Input,Flatten,Dense,Dropout
from keras.models import Model
from keras.optimizers import SGDfrom keras.datasets import mnistimport cv2
import h5py as h5py
import numpy as npmodel_vgg = VGG16(include_top=False,weights='imagenet',input_shape=(ishape,ishape,3))
model = Flatten(name='flatten')(model_vgg.output)
model = Dense(4096,activation='relu',name='fc1')(model)
model = Dense(4096,activation='relu',name='fc2')(model)
model = Dropout(0.5)(model)
model = Dense(10,activation='softmax')(model)
model_vgg_mnist = Model(model_vgg.input,model,name='vgg16')model_vgg_mnist.summary()model_vgg = VGG16(include_top=False,weights='imagenet',input_shape=(224,224,3))
for layer in model_vgg.layers:layer.trainable=False
model = Flatten()(model_vgg.output)
model = Dense(4096,activation='relu',name='fc1')(model)
model = Dense(4096,activation='relu',name='fc2')(model)
model = Dropout(0.5)(model)
model = Dense(10,activation='softmax',name='prediction')(model)
model_vgg_mnist_pretrain = Model(model_vgg.input,model,name='vgg16_pretrain')model_vgg_mnist_pretrain.summary()sgd = SGD(lr = 0.05,decay=1e-5)
model_vgg_mnist_pretrain.compile(loss='categorical_crossentropy',optimizer=sgd,metrics=['accuracy'])(x_train,y_train),(x_test,y_test) = mnist.load_data()
x_train = [cv2.cvtColor(cv2.resize(i,(ishape,ishape)),cv2.COLOR_GRAY2BGR) for i in x_train]
x_train = np.concatenate([arr[np.newaxis] for arr in x_train]).astype('float32')
x_test = [cv2.cvtColor(cv2.resize(i,(ishape,ishape)),cv2.COLOR_GRAY2BGR) for i in x_test]
x_test = np.concatenate([arr[np.newaxis] for arr in x_test]).astype('float32')x_test.shape
x_train.shapex_train /= 255
x_test /= 255np.where(x_train[0]!=0)def tran_y(y):y_ohe = np.zeros(10)y_ohe[y] = 1return y_ohey_train_ohe = np.array([tran_y(y_train[i]) for i in range(len(y_train))])
y_test_ohe = np.array([tran_y(y_test[i]) for i in range(len(y_test))])model_vgg_mnist_pretrain.fit(x_train,y_train_ohe,validation_data=(x_test,y_test_ohe),epochs=200,batch_size=128)
相关文章:
数据收集与处理(爬虫技术)
文章目录 1 前言2 网络爬虫2.1 构造自己的Scrapy爬虫2.1.1 items.py2.1.2 spiders子目录2.1.3 pipelines.py 2.2 构造可接受参数的Scrapy爬虫2.3 运行Scrapy爬虫2.3.1 在命令行运行2.3.2 在程序中调用 2.4 运行Scrapy的一些要点 3 大规模非结构化数据的存储与分析4 全部代码 1 …...
C# 雪花算法生成Id工具类
写在前面 传说自然界中并不存在两片完全一样的雪花的,每一片雪花都拥有自己漂亮独特的形状、独一无二;雪花算法也表示生成的ID如雪花般独一无二,该算法源自Twitter。 雪花算法主要用于解决分布式系统的唯一Id生成问题,在生产环境…...
什么是通配符证书?
通配符证书是一种特殊的数字证书,主要用于加密网站与用户之间的通信,以保证数据的私密性和完整性。它的独特之处在于可以使用一个单一的证书来保护无限数量的相关子域名。它使用通配符字符(*)作为占位符,代表任意子域名…...
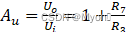
西南科技大学模拟电子技术实验五(集成运算放大器的应用设计)预习报告
一、计算/设计过程 设计一:用集成运放设计一个输入为0.05v,放大为-100的反相比例运算电路。 对于理想电路,反相比例运算电路的输出电压与输入电压之间的关系如下: =-100,所以 =100 若是假定R1为100k,则R2= =1k 为了减小输入级偏置电流引起的运算误差,在同相输入端…...
LeetCode 每日一题 Day 4
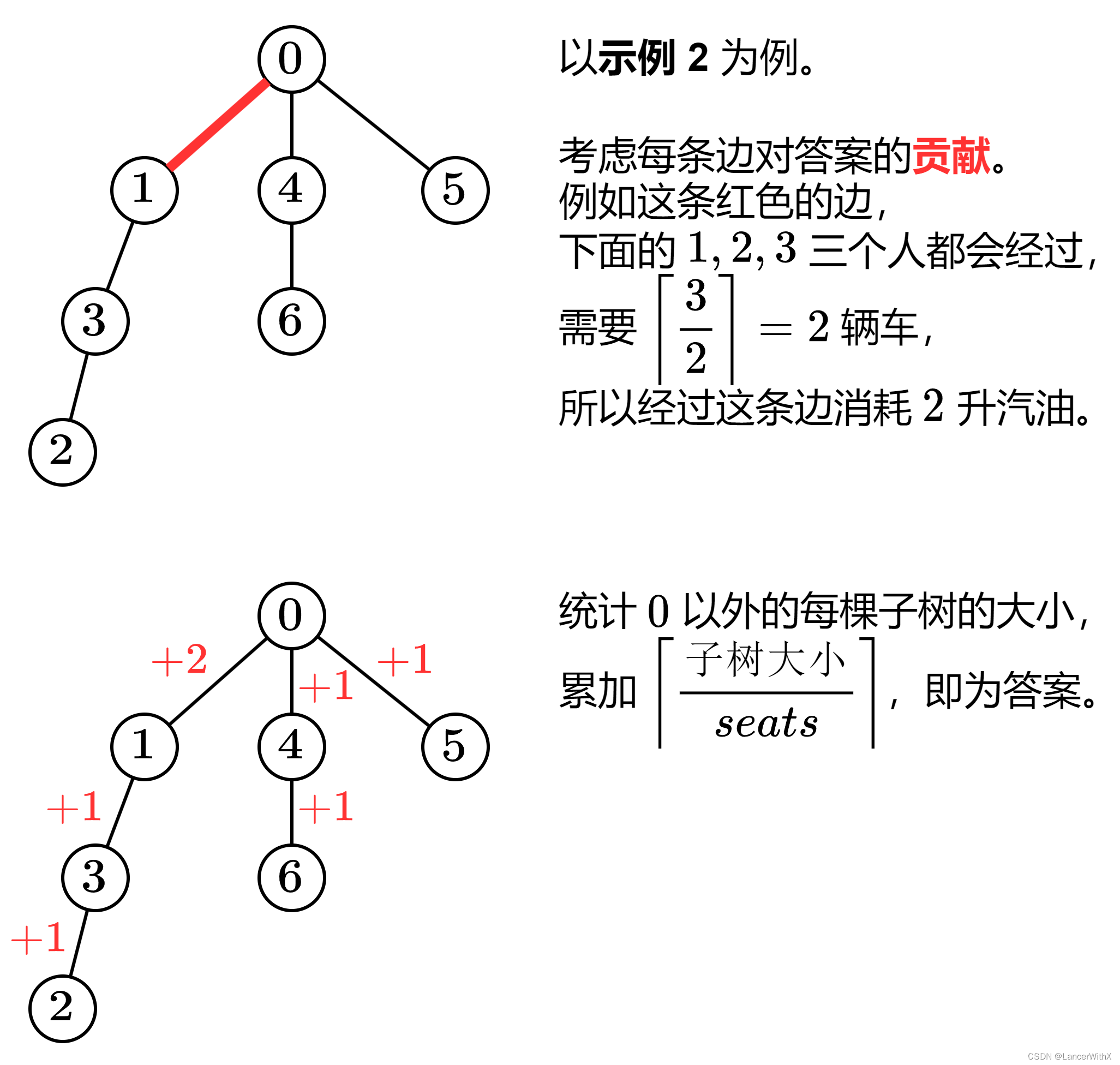
2477. 到达首都的最少油耗 给你一棵 n 个节点的树(一个无向、连通、无环图),每个节点表示一个城市,编号从 0 到 n - 1 ,且恰好有 n - 1 条路。0 是首都。给你一个二维整数数组 roads ,其中 roads[i] [ai,…...
服务器数据恢复—重装系统导致XFS文件系统分区丢失的数据恢复案例
服务器数据恢复环境: 服务器使用磁盘柜RAID卡搭建了一组riad5磁盘阵列。服务器上层分配了一个LUN,划分了两个分区:sdc1分区和sdc2分区。通过LVM扩容的方式,将sdc1分区加入到了root_lv中;sdc2分区格式化为XFS文件系统。…...

Scala 从入门到精通
Scala 从入门到精通 数据类型 pom.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http:…...

华为OD机试 - 九宫格按键输入 - 逻辑分析(Java 2023 B卷 200分)
目录 专栏导读一、题目描述二、输入描述三、输出描述四、解题思路五、Java算法源码六、效果展示1、输入2、输出3、说明 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(A卷B卷&#…...

leetcode:225. 用队列实现栈
一、题目 链接:225. 用队列实现栈 - 力扣(LeetCode) 函数原型: typedef struct { } MyStack; MyStack* myStackCreate() void myStackPush(MyStack* obj, int x) int myStackPop(MyStack* obj) int myStackTop(MyStack* obj) …...
Centos7安装GItLab(在线版)
基础环境准备 1.配置清华大学镜像仓库 新建仓库配置文件使用 vim /etc/yum.repos.d/gitlab-ce.repo 命令,输入以下内容,保存 [gitlab-ce] nameGitlab CE Repository baseurlhttps://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el$releasever/ gpgcheck0 enabl…...
Linux入门笔记
1 Linux概述 Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 UNIX 的多用户、多任务、支持多线程和多 CPU 的操作系统。Linux 能运行主要的 UNIX 工具软件、应用程序和网络协议。它支持 32 位和 64 位硬件。Linux 继承了 Unix 以网络为核心…...

nvm for windows使用与node/npm/yarn的配置
1 下载 nvm for windows download – github 下拉到Assets, 下载.exe文件 2 安装 安装到如下文件夹中 目录可以自己选, 可以换别的名字, 自己记住即可 新手建议全部看完再进行个人配置, 或者使用与博主一致的路径 D:\DevelopEnvironment\nvm3 配置nvm使用的镜像 node_mir…...
打工人副业变现秘籍,某多/某手变现底层引擎-StableDiffusionWebUI界面基本布局和操作
一、界面设置 文生图:根据文本提示生成图像 图生图:图像生成图像;功能很强大,自己在后续使用中探索。 后期处理:图片处理;功能很强大,自己在后续使用中探索。 PNG信息:这是一个快速获取图片生成参数的便捷功能。如果图像是在SD里生成的,您可以使用“发送到”按钮将…...
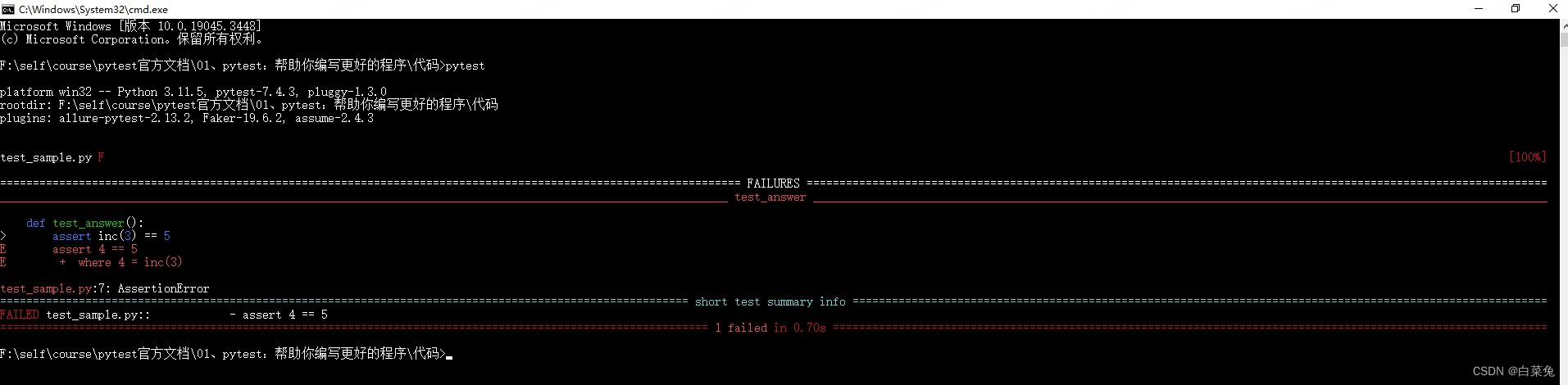
01、pytest:帮助你编写更好的程序
简介 pytest框架可以很容易地编写小型、可读的测试,并且可以扩展以支持应用程序和库的复杂功能测试。使用pytest至少需要安装Python3.7或PyPy3。PyPI包名称为pytest 一个快速的例子 # content of test_sample.py def inc(x):return x1def test_ansewer():asser…...

C语言--每日选择题--Day37
第一题 1. 有以下说明语句:则下面引用形式错误的是() struct Student {int num;double score; };struct Student stu[3] {{1001,80}, {1002,75}, {1003,91}} struct Student *p stu; A:p->num B:(p).num C&#…...
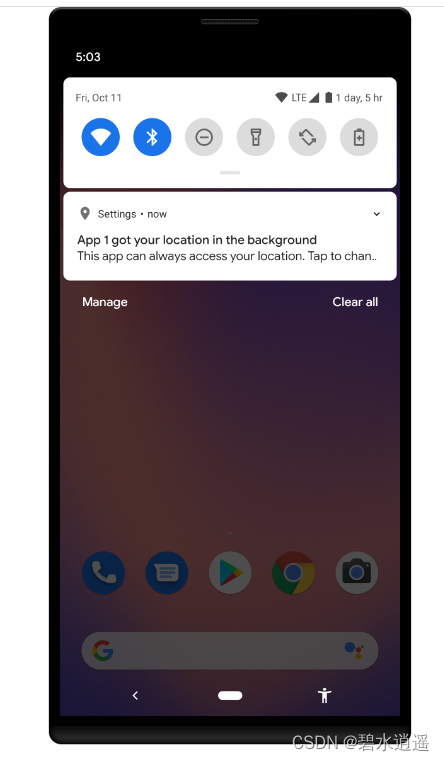
Android 12 及以上授权精确位置和模糊位置
请求位置信息权限 为了保护用户隐私,使用位置信息服务的应用必须请求位置权限。 请求位置权限时,请遵循与请求任何其他运行时权限相同的最佳做法。请求位置权限时的一个重要区别在于,系统中包含与位置相关的多项权限。具体请求哪项权限以及…...

scp 指令详细介绍
目录 1. 基本语法 2. 例子 从本地到远程 从远程到本地 从远程到远程 使用端口和指定私钥 递归复制目录 3. 注意事项 如何拷贝文件的软链接 SCP(Secure Copy Protocol)是一种用于在计算机之间安全地传输文件的协议。它通过加密的方式在网络上安全…...

构建第一个事件驱动型 Serverless 应用
我相信,我们从不缺精彩的应用创意,我们缺少的把这些想法变成现实的时间和付出。 我认为,无服务器技术真的有助于最大限度节省应用开发和部署的时间,并且无服务器技术用可控的成本,实现了我的那些有趣的想法。 在我 2…...

特征与特征图的区别
1.特征图是什么? 特征图是指在卷积神经网络中,通过卷积操作从输入图像中提取出来的图像特征。在卷积神经网络中,每一层的输出都是一个三维张量,其中第三维表示特征图的数量。每个特征图都是由若干个卷积核对上一层的特征图进行卷…...

Linux学习笔记之七(shell脚本的基本语法)
Shell 1、Shell脚本2、常用运算符2、特殊语法4、关于变量的一些命令4.1、echo4.2、export4.3、read4.4、declare/typeset4.5、local4.6、unset 5、基本逻辑语法5.1、if判断5.2、for循环5.3、while循环5.4、case语句 6、函数定义7、多脚本链接 1、Shell脚本 学习shell脚本开发之…...

解锁GitHub极速体验:智能加速插件深度解析
解锁GitHub极速体验:智能加速插件深度解析 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub GitHub加速插件(…...

YimMenu终极配置指南:从零开始掌握GTA V高级菜单工具
YimMenu终极配置指南:从零开始掌握GTA V高级菜单工具 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMe…...

Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧
Allegro 16.6 高效布线实战:Region规则、Xnet等长与模块复用的进阶技巧 在高速PCB设计领域,Allegro 16.6作为行业标杆工具,其深度功能往往决定了设计效率的天花板。当面对BGA封装密度突破1000pin、信号速率迈入10Gbps时代的复杂主板时&#x…...
)
保姆级教程:用Python+NumPy复现经典Laplacian曲面编辑算法(附源码)
从理论到代码:Python实现Laplacian曲面编辑的完整指南 在三维图形处理领域,Laplacian曲面编辑技术因其出色的细节保持能力而备受推崇。这项技术允许开发者对三维模型进行直观的变形操作,同时保持模型表面的几何细节不被破坏。本文将带您从零开…...

U-Boot实战:FAT文件系统五大核心命令详解与应用
1. U-Boot与FAT文件系统基础认知 刚接触嵌入式开发时,我第一次在U-Boot环境下操作FAT文件系统就踩了个大坑——试图用ext4write命令操作FAT32格式的SD卡,结果系统直接报错"Unknown command"。这个经历让我深刻认识到:U-Boot对文件系…...

Deep Lake:AI数据湖实战指南,解决深度学习数据管理难题
1. 项目概述:当数据湖遇上深度学习如果你在深度学习项目里被数据管理搞得焦头烂额过,那你肯定懂我在说什么。模型训练到一半,发现数据版本不对,或者想对海量图像、视频做快速查询和采样,结果被IO速度卡得死死的。传统的…...

从仿生结构到步态算法:8自由度并联腿机器狗行走全解析
1. 8自由度并联腿机器狗的结构奥秘 第一次拆解机器狗时,我对着那些复杂的连杆结构发了半小时呆。直到发现它的腿部运动原理和公园里的跷跷板惊人相似——这个发现让我瞬间理解了8自由度并联腿的精妙之处。这种结构就像给机器人装上了"机械肌腱"࿰…...

IE11富文本兼容——政务系统前端的深渊
IE11富文本兼容——政务系统前端的深渊 背景:为什么还有 IE11 系统要求支持 IE11。 为什么不是 Chrome? 办公电脑全是 Windows 7 IE11单位统一采购,不能随便装浏览器部分内部网站只支持 IE(ActiveX) 现状&#x…...

CFD工程师必看:TVD格式选型指南——从SUPERBEE到UMIST,哪个才是你的菜?
CFD工程师必看:TVD格式选型实战指南——从工程场景到最优解 在计算流体力学(CFD)的世界里,TVD格式就像赛车手的轮胎选择——没有绝对的好坏,只有场景的适配。当你在汽车外气动分析中遇到激波振荡,或在燃烧模拟中面临虚假扩散时&am…...

MQ-3与MiCS-5524气体传感器对比:从原理到实战的选型指南
1. 项目概述与核心价值在嵌入式开发、环境监测乃至一些创意DIY项目中,气体检测是一个常见且关键的需求。无论是为了安全预警(如天然气泄漏),还是进行环境质量评估(如VOC监测),选择一款合适的传感…...