Elasticsearch进阶之(核心概念、系统架构、路由计算、倒排索引、分词、Kibana)
Elasticsearch进阶之(核心概念、系统架构、路由计算、倒排索引、分词、Kibana)
1、核心概念:
1.1、索引(Index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,可以有一个产品目录的索引,还可以有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
能搜索的数据必须索引,这样的好处是可以提高查询速度,比如:新华字典前面的目录就是索引的意思,目录可以提高查询速度
1.2、类型(Type)
在一个索引中,你可以定义一种或多种类型。
一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。不同的版本,类型发生了不同的变化

1.3、文档(Document)
一个文档是一个可被索引的基础信息单元,也就是一条数据。
比如:你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以 JSON(Javascript Object Notation)格式来表示,而 JSON 是一个到处存在的互联网数据交互格式。
在一个 index/type 里面,你可以存储任意多的文档。
1.4、字段(Field)
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
1.5、映射(Mapping)
mapping 在处理数据的方式和规则方面做了一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等等。这些都是映射里面可以设置的,其它就是处理 ES 里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
1.6、分片(Shards)
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有 10 亿文档数据的索引占据 1TB 的磁盘空间,而任一节点都可能没有这样大的磁盘空间。或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,每一份就称之为分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
- 允许你水平分割 / 扩展你的内容容量。
- 允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由 Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的,无需过分关心。
1.7、副本(Replicas)
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
复制分片之所以重要,有两个主要原因:
- 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制 0 次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。默认情况下,Elasticsearch 中的每个索引被分片 1 个主分片和 1 个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有 1 个主分片和另外 1 个复制分片(1 个完全拷贝),这样的话每个索引总共就有 2 个分片,我们需要根据索引需要确定分片个数。
1.8、分配(Allocation)
将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由 master 节点完成的。
2、系统架构:
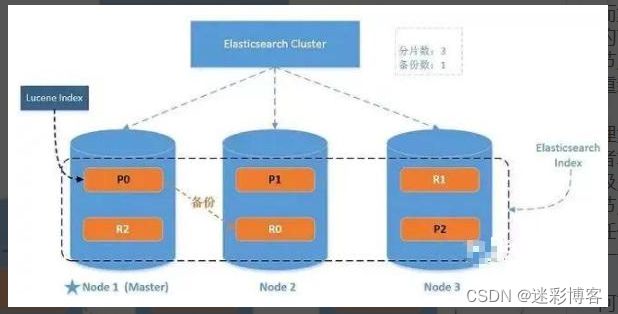
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为主节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。
作为用户,我们可以将请求发送到集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
3、路由计算:
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片1 还是分片 2 中呢?首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:

routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。
这个分布在 0到number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
所有的文档 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一个叫做 routing 的路由参数 ,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档——例如所有属于同一个用户的文档——都被存储到同一个分片中。
4、倒排索引:
什么是倒排索引?倒排索引也叫反向索引,我们通常理解的索引是通过key寻找value,与之相反,倒排索引是通过value寻找key,故而被称作反向索引。
下面我们用一个简单的例子描述一下倒排索引的作用过程:
假如现在有三份数据文档,内容分别是:
 为了创建索引,ES引擎通过分词器将每个文档的内容拆成单独的词(称之为词条,或term),再将这些词条创建成不含重复词条的排序列表,然后列出每个词条出现在哪个文档,结果如下页所示:
为了创建索引,ES引擎通过分词器将每个文档的内容拆成单独的词(称之为词条,或term),再将这些词条创建成不含重复词条的排序列表,然后列出每个词条出现在哪个文档,结果如下页所示:
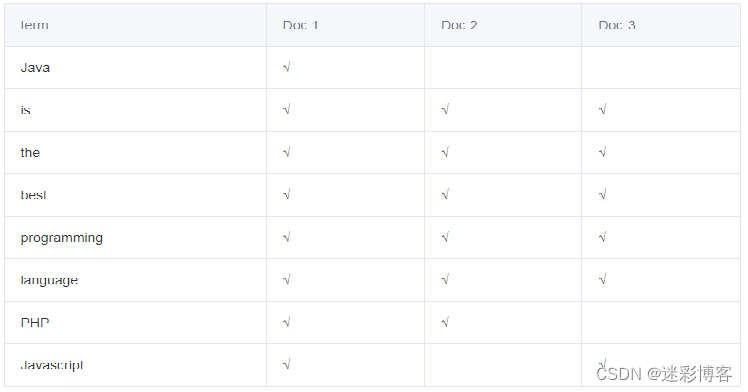
这种结构由文档中所有不重复的词的列表构成,对于其中每个词都有至少一个文档与之关联。这种由属性值来确定记录的位置的结构就是倒排索引,带有倒排索引的文件被称为倒排文件。
将上表转为更直观的图片来展示倒排索引:
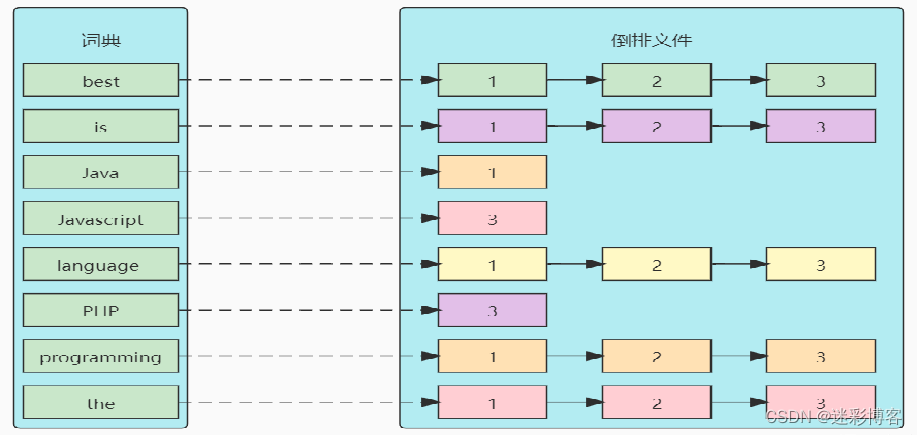
其中,几个核心术语需要着重理解:
词条(term):索引里面最小的存储和查询单元,对于英文来说是一个词,对于中文来说一般指分词后的一个词。
词典(Term Dictionary):也叫字典,是词条的组合。搜索引擎的通常索引单位是单词,单词词典是文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向倒排索引的指针。
倒排表(Post list):一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过及出现的位置。每个记录称为一个倒排项(Posting),倒排表记录的不单单是文档编号,还记录了词频等信息。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
词典和倒排表是 Lucene中很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,词典在内存中而倒排文件存储在磁盘。
5、分词:
5.1、ES分词
前面,我们说了倒排索引的原理,我们需要构建一个单词词典,但是这个词典里面的数据怎么来呢?我们需要对输入的东西进行分词。这个ES已经考虑过了,所以它内置了一些分词器,但是中国文化,博大精深,有时候自己断句都会有误差,所以我们会用一些国人的插件进行中文分词。下面重点介绍ES分词原理、内置分词和中文分词。
5.2、ES分词是如何实现?
Analysis(分析)是通过Analyzer(分析器)实现的,分析也是有步骤的,下面我们说一下Analyzer的组成。
分词器主要由三部分组成:
- Character Filters 字符过滤器 比方说剔除html代码、特殊符号等等,可以有多个字符过滤器
- Tokenizer 分词器 对语句进行分词,只能有一个
- Token Filter token过滤器 对词进行过滤、或者转小写、等等,可以有多个token filter,依次执行
5.3、ES内置分词器分析
我们知道了分词器的组成,只需要再知道它的一些实现即可。我们也列出来方便查看
standard
默认的分词器,按词分类并且小写处理。这里我们举个例子,其余大家照葫芦画瓢就行
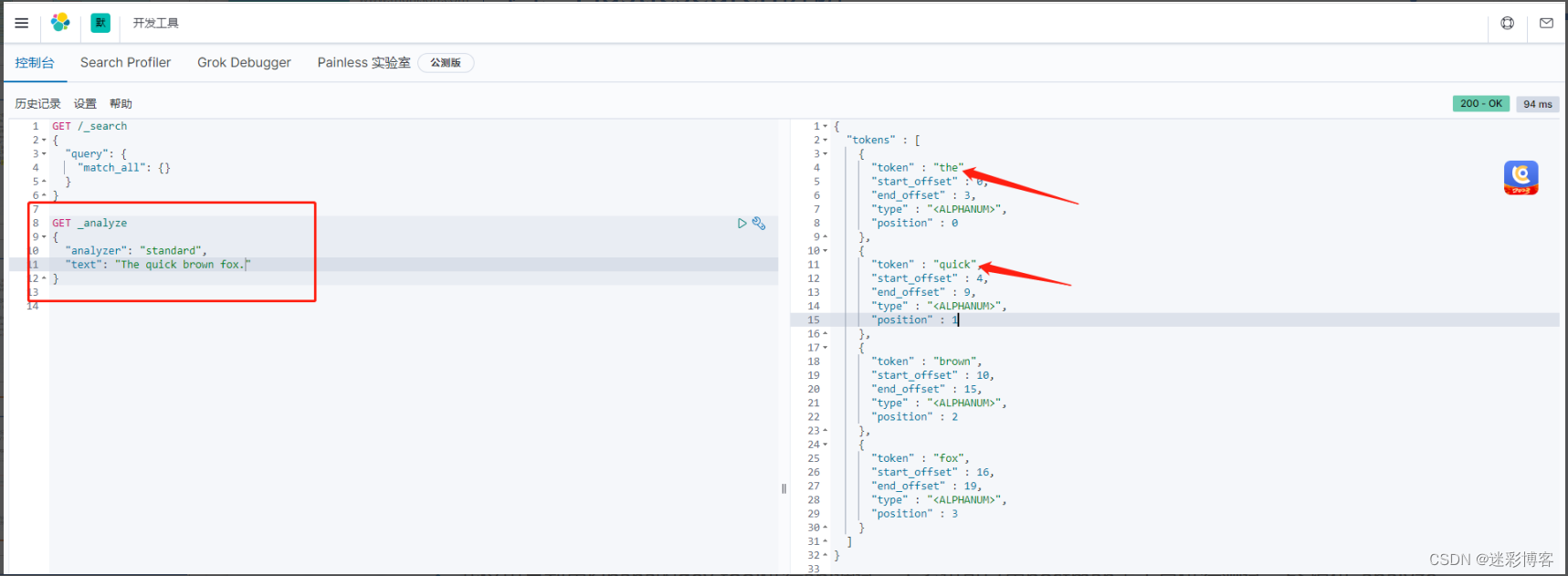
我这里是利用Kibana的dev tool进行api调试,大家也可以用postman等工具进行测试。ES提供_analyze api来测试分词。
5.4、ES指定分析器
举个例子按英文拆分,它支持不同的语言,例如:arabic, armenian, basque, bengali, bulgarian, catalan, czech, dutch, english, finnish, french, galician, german, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, portuguese, romanian, russian, sorani, spanish, swedish, turkish.
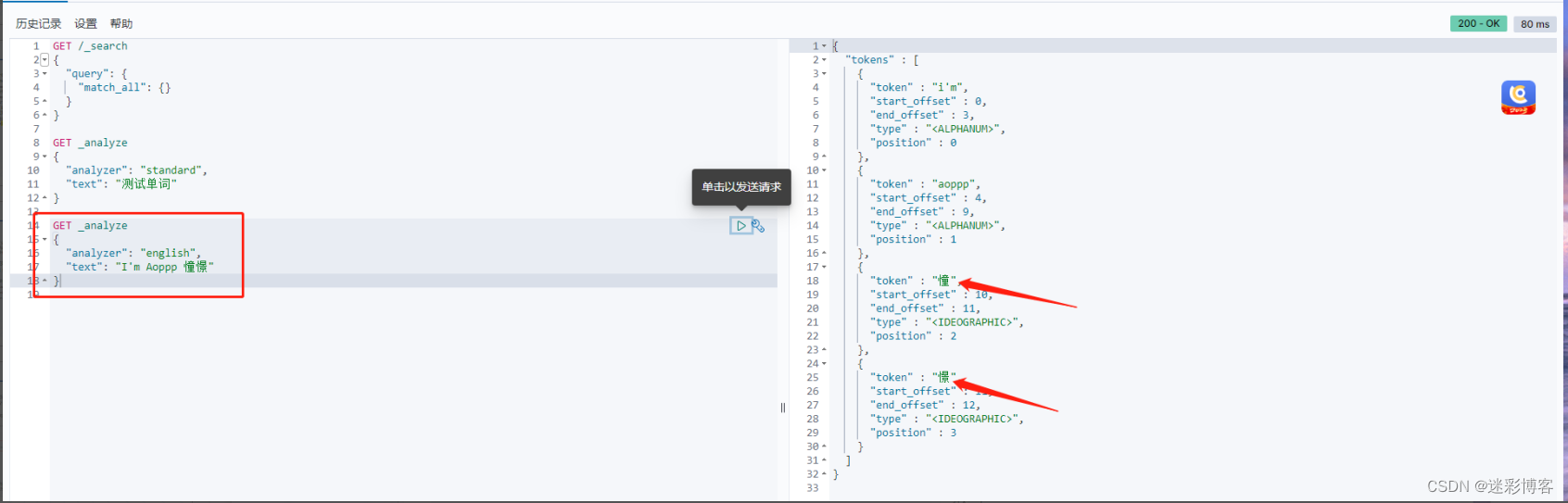
上面例子典型对中文就不太友好,中文分词要比英文分词难,英文都以空格分隔,中文理解通常需要上下文理解才能有正确的理解,比如 [苹果,不大好吃]和[苹果,不大,好吃],这两句意思就不一样。
5.5、IK分词器
前面的结果显然不符合我们的使用要求,所以我们需要下载 ES 对应版本的中文分词器。
我们这里采用 IK 中文分词器,下载地址为: https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.8.0
将解压后的后的文件夹放入 ES 根目录下的 plugins 目录下,重启 ES 即可使用。
我们这次加入新的查询参数"analyzer":“ik_max_word”
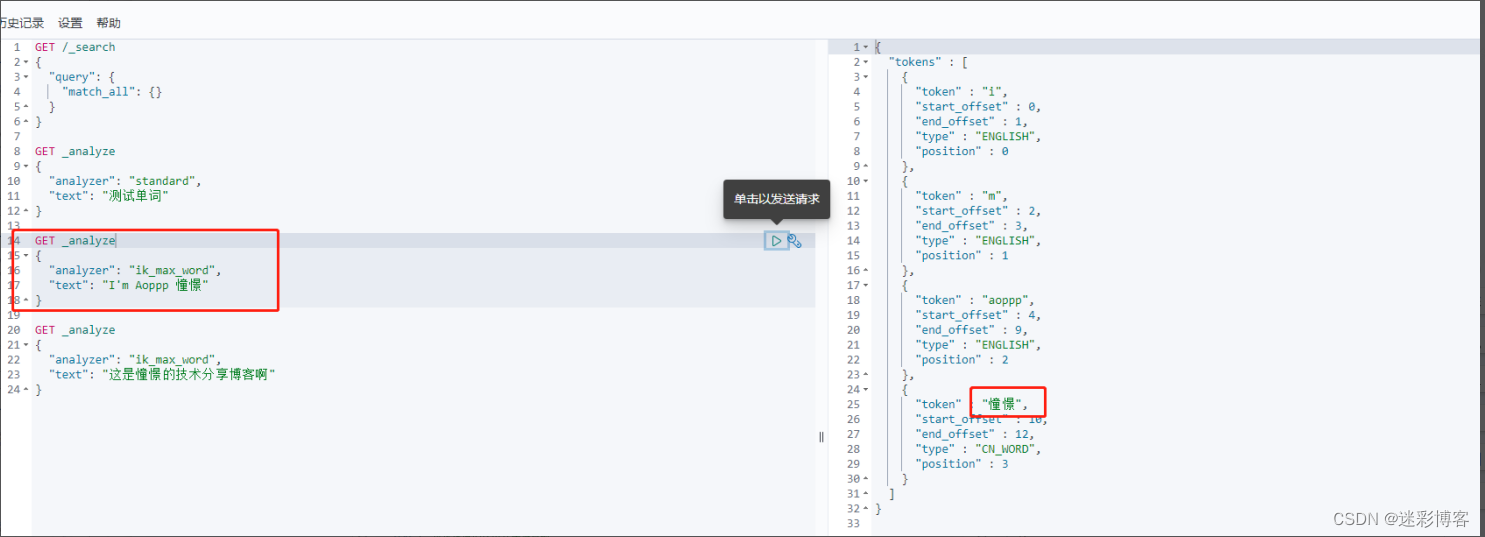
6、Kibana:
Kibana 是一个免费且开放的用户界面,能够让你对 Elasticsearch 数据进行可视化,并让你在 Elastic Stack 中进行导航。你可以进行各种操作,从跟踪查询负载,到理解请求如何流经你的整个应用,都能轻松完成。
Linux(CentOS)下载安装Kibana参考前面的博客即可:https://blog.csdn.net/sxdtzhaoxinguo/article/details/129057179
相关文章:
Elasticsearch进阶之(核心概念、系统架构、路由计算、倒排索引、分词、Kibana)
Elasticsearch进阶之(核心概念、系统架构、路由计算、倒排索引、分词、Kibana) 1、核心概念: 1.1、索引(Index) 一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引&…...

Android包体积缩减
关于减小包体积的方案: 一、所有的图片压缩,采用webp 格式。 (当然有些图片采用webp格式反而变大了,可以仍采用png格式) 二、语音资源过滤 只保留中文 resConfigs "zh-rCN", "zh” 可以减少resourc…...
)
【华为OD机试】 网上商城优惠活动(C++ Java Javascript Python)
文章目录 题目描述输入描述输出描述备注用例题目解析C++JavaScriptJavaPython题目描述 某网上商场举办优惠活动,发布了满减、打折、无门槛3种优惠券,分别为: 每满100元优惠10元,无使用数限制,如100199元可以使用1张减10元,200299可使用2张减20元,以此类推;92折券,1次…...
GWT安装过程
1:安装前准备 (可以问我要) appengine-java-sdk-1.9.8 com.google.gdt.eclipse.suite.4.3.update.site_3.8.0 gwt-2.5.1 eclipse-jee-kepler-SR2-win32-x86_64.zip 2:安装环境上 打开eclipse Help –Install New Software… 选择Add –…...
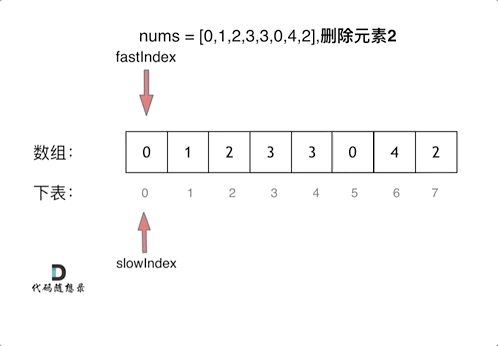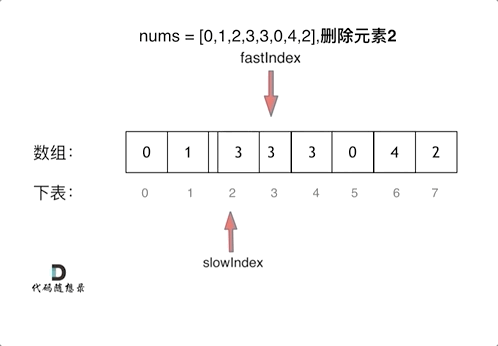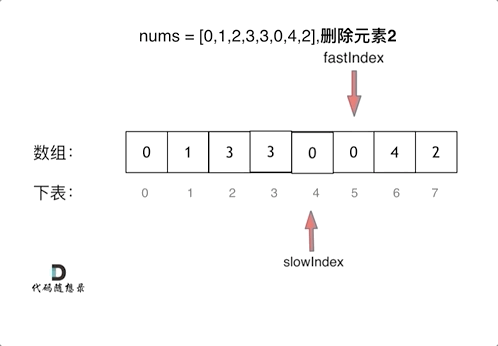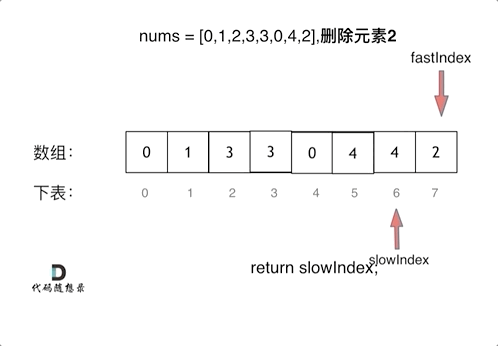
代码随想录算法训练营第一天| 704. 二分查找、27. 移除元素
Leetcode 704 二分查找题目链接:704二分查找介绍给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。思路先看看一个…...

office@word@ppt启用mathtype组件方法整理
文章目录将mathtype添加到word中ref查看office安装路径文件操作法Note附PPT中使用mathtype将mathtype添加到word中 先安装office,再安装mathtype,那么这个过程是自动的如果是先安装mathtype,再安装office,那么有以下选择: 重新安装一遍mathtype(比较简单,不需要说明)执行文件操…...
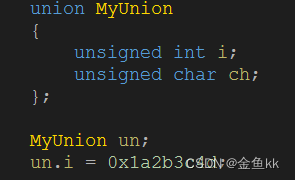
计算机大小端
我们先假定内存结构为上下型的,上代表内存高地址,下代表内存低地址。 电脑读取内存数据时,是从低位地址到高位地址进行读取(从下到上)。 1、何为大小端 大端:数据的高位字节存放在低地址,数据…...
)
Matplotlib绘图从零入门到实践(含各类用法详解)
一、引入 Matplotlib 是一个Python的综合库,用于在 Python 中创建静态、动画和交互式可视化。 本教程包含笔者在使用Matplotlib库过程中遇到的各类完整实例与用法还有遇到的库理论问题,可以根据自己的需要在目录中查询对应的用法、实例以及第四部分关于…...
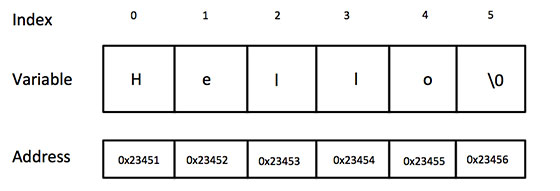
C语言 入门教程||C语言 指针||C语言 字符串
C语言 指针 学习 C 语言的指针既简单又有趣。通过指针,可以简化一些 C 编程任务的执行,还有一些任务,如动态内存分配,没有指针是无法执行的。所以,想要成为一名优秀的 C 程序员,学习指针是很有必要的。 …...

Nacos2.x+Nginx集群配置
一、配置 nacos 集群 注意:需要先配置好 nacos 连接本地数据库 1、拷贝三份 nacos 2、修改配置文件(cluster.conf) 修改启动端口: nacos1:8818 nacos2:8828 nacos3:8838 当nacos客户端升级为…...
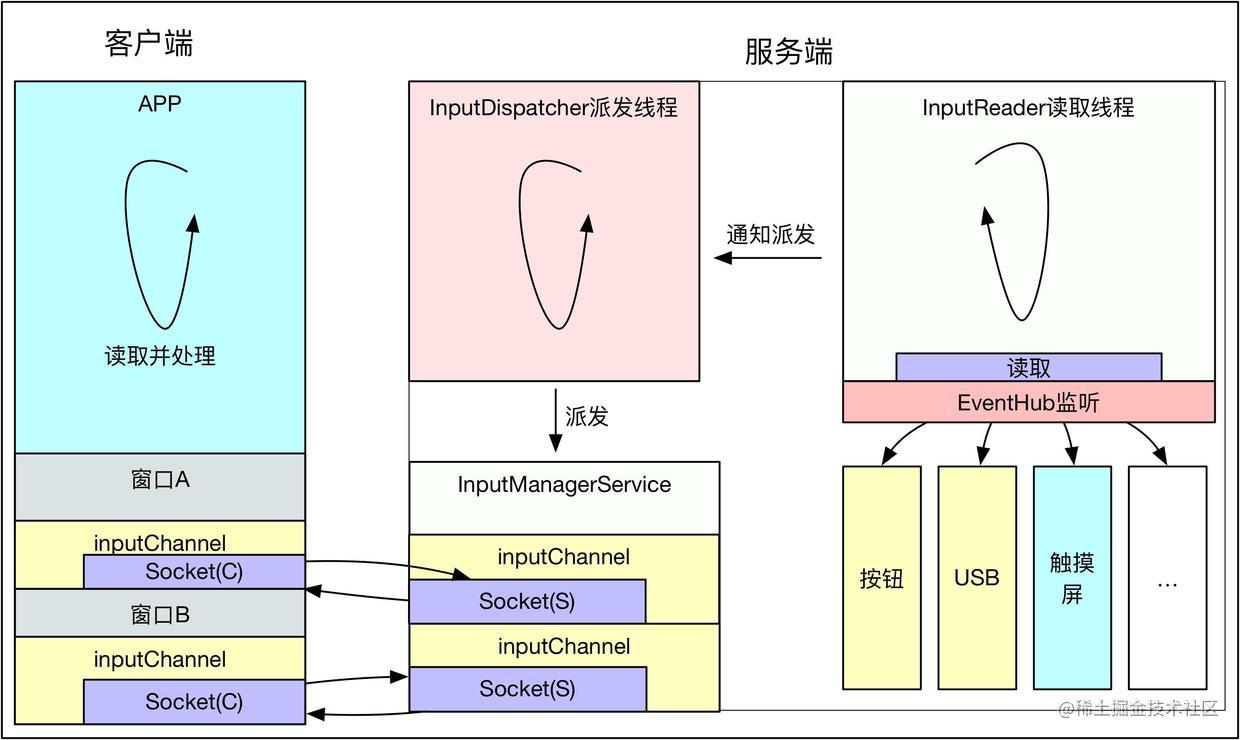
Android源码分析 - InputManagerService与触摸事件
0. 前言 有人问到:“通过TouchEvent,你可以获得到当前的触点,它更新的频率和屏幕刷新的频率一样吗?”。听到这个问题的时候我感到很诧异,我们知道Android是事件驱动机制的设计,可以从多种服务中通过IPC通信…...

python库--urllib
目录 一.urllib导入 二.urllib爬取网页 三.Headers属性 1.使用build_opener()修改报头 2.使用add_header()添加报头 四.超时设置 五.get和post请求 1.get请求 2.post请求 urllib库和request库作用差不多,但比较起来request库更加容易上手,但该了…...

美团前端二面常考react面试题及答案
什么原因会促使你脱离 create-react-app 的依赖 当你想去配置 webpack 或 babel presets。 React 16中新生命周期有哪些 关于 React16 开始应用的新生命周期: 可以看出,React16 自上而下地对生命周期做了另一种维度的解读: Render 阶段&a…...

环境搭建04-Ubuntu16.04更改conda,pip的镜像源
我常用的pipy国内镜像源: https://pypi.tuna.tsinghua.edu.cn/simple # 清华 http://mirrors.aliyun.com/pypi/simple/ # 阿里云 https://pypi.mirrors.ustc.edu.cn/simple/ #中国科技大学1、将conda的镜像源修改为国内的镜像源 先查看conda安装的信息…...

【C++进阶】四、STL---set和map的介绍和使用
目录 一、关联式容器 二、键值对 三、树形结构的关联式容器 四、set的介绍及使用 4.1 set的介绍 4.2 set的使用 五、multiset的介绍及使用 六、map的介绍和使用 6.1 map的介绍 6.2 map的使用 七、multimap的介绍和使用 一、关联式容器 前面已经接触过 STL 中的部分…...
JavaSE学习进阶 day1_01 static关键字和静态代码块的使用
好的现在我们进入进阶部分的学习,看一张版图: 前面我们已经学习完基础班的内容了,现在我们已经来到了第二板块——基础进阶,这部分内容就不是那么容易了。学完第二板块,慢慢就在向java程序员靠拢了。 面向对象进阶部分…...

苹果笔可以不买原装吗?开学必备性价比电容笔
在当今的时代,电容笔日益普及,而且相关的功能也逐渐完善。因此,在使用过程中,怎样挑选一款性价比比较高的电容笔成为大家关心的焦点。随着电容笔的普及,更好更便宜的电容笔成为了一种趋势。那么,哪个品牌的…...
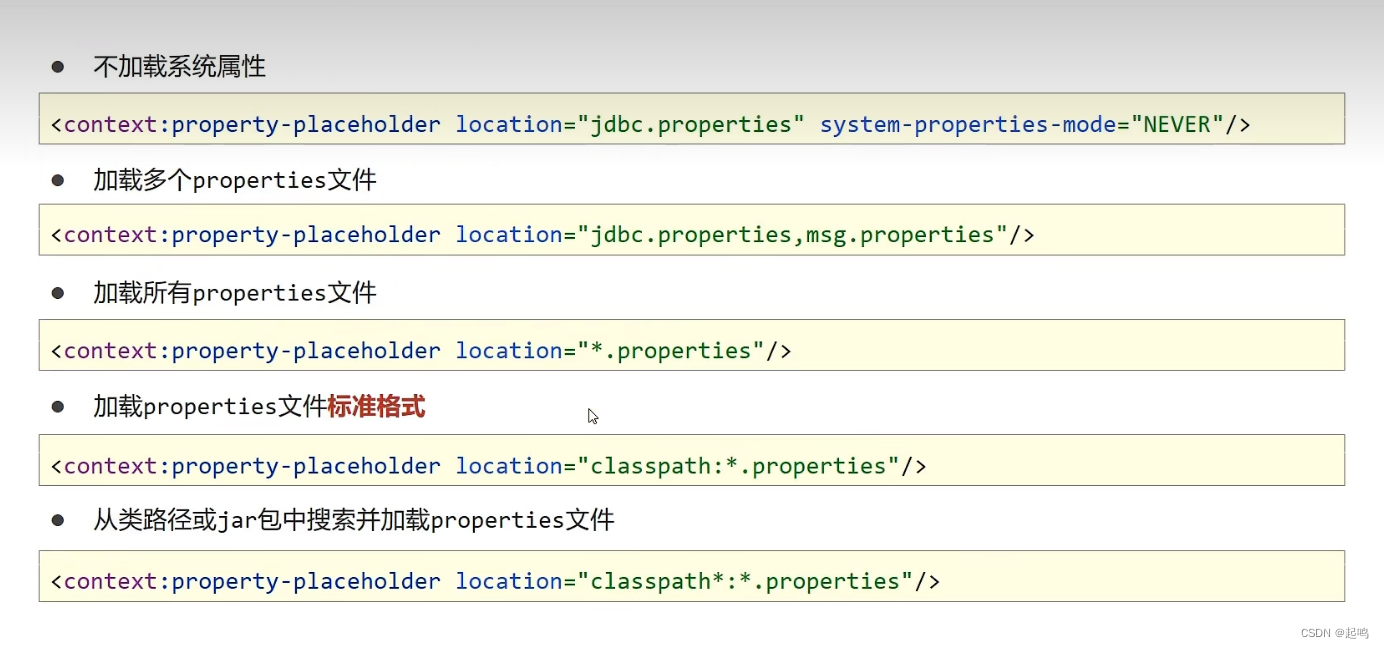
数据库连接与properties文件
管理properties数据库: 现在pom文件中加入Druid的坐标: <dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.8</version></dependency>配置文件中添加相应的数据&…...

Linux上的校验和验证
校验和(checksum)程序用来从文件中生成相对较小的唯一密钥。我们可以重新计算该密钥,用以检查文件是否发生改变。修改文件可能是有意为之(添加新用户会改变密码文件),也可能是无意而为(从CD-ROM…...

杂记——14.git在idea上的使用及其实际开发介绍
这篇文章我们来讲一下git在idea上的使用,以及在实际开发过程中各个分支的使用及其具体的流程 目录 1.git在idea上的使用 1.1 idea上的git提交 1.2 idea上的分支切换 2.git在实际运用时的分支及其流程 2.1分支介绍 2.2具体流程 3.小结 1.git在idea上的使用 …...

从DataFrame到MySQL:利用pandas与pymysql实现高效数据迁移
1. 为什么需要把DataFrame数据写入MySQL? 在日常数据分析工作中,我们经常使用pandas处理数据。DataFrame作为pandas的核心数据结构,提供了丰富的数据操作功能。但分析结果最终需要持久化存储时,MySQL这类关系型数据库仍然是企业级…...

无人机+点云+Civil3D:无控制点场景下的高精度土方算量实战
1. 无人机航测在复杂地形土方算量中的优势 石头山这类复杂地形一直是工程测绘的难点。传统全站仪测量需要测绘人员翻山越岭布设控制点,不仅效率低下,还存在安全隐患。而无人机航测就像给工程装上了"天眼",特别适合解决这类难题。 去…...

LettR编辑器光标增强插件:提升代码编辑效率的智能导航方案
1. 项目概述:一个为LettR编辑器量身定制的光标增强插件如果你和我一样,日常重度依赖代码编辑器,那你一定对光标这个看似不起眼的小东西又爱又恨。爱的是,它是我们与代码世界交互的核心;恨的是,当代码文件越…...

观测Taotoken在每日大赛期间API调用的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观测Taotoken在每日大赛期间API调用的延迟与稳定性表现 在技术社区组织的每日编程挑战赛期间,开发者们通常会集中、高频…...

Markdown基础功能
原文:Markdown基础语法介绍 | Colin Gretzky的博客 本文介绍 Markdown 笔记格式的基础功能,涵盖核心语法和使用要点,适合初学者快速上手。 Markdown 简介 Markdown 是一种轻量级的标记语言,由 John Gruber 于 2004 年设计。它的核…...

MediaCreationTool.bat:解决Windows安装媒体创建痛点的灵活工具
MediaCreationTool.bat:解决Windows安装媒体创建痛点的灵活工具 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...

树莓派+Ollama分离部署OpenClaw:打造家庭局域网AI助手
1. 项目概述:在树莓派上部署OpenClaw,实现本地网络AI助手最近在折腾我的家庭实验室,想把AI助手的能力从主力电脑上解放出来,让它变成一个常驻在角落里的独立服务。我的主力机性能不错,跑大语言模型没问题,但…...
)
蓝桥杯嵌入式备赛:手把手教你用STM32G4的ADC读取光敏电阻(国信长天扩展板)
蓝桥杯嵌入式竞赛实战:STM32G4光敏电阻精准采集与优化策略 在蓝桥杯嵌入式竞赛中,环境光检测是高频考点之一。国信长天扩展板上的光敏电阻模块看似简单,但要在竞赛中稳定发挥,需要深入理解硬件电路设计原理、掌握ADC采集的优化技巧…...
函数绘制三维曲面图)
用surf( )函数绘制三维曲面图
在“用plot3( )函数绘制三维曲线图”中,实现了三维曲线的绘制,得到了一个类似面包圈形状的旋转曲面,很喜欢这个造型,就想到是不是可以直接绘制出曲面,而不只是用曲线方式绘制出看起来像曲面的图形。一看参考书…...

如何在Windows上轻松安装APK文件:告别模拟器的完整指南
如何在Windows上轻松安装APK文件:告别模拟器的完整指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想要在Windows电脑上直接运行Android应用…...