RNN:文本生成
文章目录
- 一、完整代码
- 二、过程实现
- 2.1 导包
- 2.2 数据准备
- 2.3 字符分词
- 2.4 构建数据集
- 2.5 定义模型
- 2.6 模型训练
- 2.7 模型推理
- 三、整体总结
采用RNN和unicode分词进行文本生成

一、完整代码
这里我们使用tensorflow实现,代码如下:
# 完整代码在这里
import tensorflow as tf
import keras_nlp
import numpy as nptokenizer = keras_nlp.tokenizers.UnicodeCodepointTokenizer(vocabulary_size=400)# tokens - ids
ids = tokenizer(['Why are you so funny?', 'how can i get you'])# ids - tokens
tokenizer.detokenize(ids)def split_input_target(sequence):input_text = sequence[:-1]target_text = sequence[1:]return input_text, target_text# 准备数据
text = open('./shakespeare.txt', 'rb').read().decode(encoding='utf-8')
dataset = tf.data.Dataset.from_tensor_slices(tokenizer(text))
dataset = dataset.batch(64, drop_remainder=True)
dataset = dataset.map(split_input_target).batch(64)input, ouput = dataset.take(1).get_single_element()# 定义模型d_model = 512
rnn_units = 1025class CustomModel(tf.keras.Model):def __init__(self, vocabulary_size, d_model, rnn_units):super().__init__(self)self.embedding = tf.keras.layers.Embedding(vocabulary_size, d_model)self.gru = tf.keras.layers.GRU(rnn_units, return_sequences=True, return_state=True)self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax')def call(self, inputs, states=None, return_state=False, training=False):x = inputsx = self.embedding(x)if states is None:states = self.gru.get_initial_state(x)x, states = self.gru(x, initial_state=states, training=training)x = self.dense(x, training=training)if return_state:return x, stateselse:return xmodel = CustomModel(tokenizer.vocabulary_size(), d_model, rnn_units)# 查看模型结构
model(input)
model.summary()# 模型配置
model.compile(loss = tf.losses.SparseCategoricalCrossentropy(),optimizer='adam',metrics=['accuracy']
)# 模型训练
model.fit(dataset, epochs=3)# 模型推理
class InferenceModel(tf.keras.Model):def __init__(self, model, tokenizer):super().__init__(self)self.model = modelself.tokenizer = tokenizerdef generate(self, inputs, length, return_states=False):inputs = inputs = tf.constant(inputs)[tf.newaxis]states = Noneinput_ids = self.tokenizer(inputs).to_tensor()outputs = []for i in range(length):predicted_logits, states = model(inputs=input_ids, states=states, return_state=True)input_ids = tf.argmax(predicted_logits, axis=-1)outputs.append(input_ids[0][-1].numpy())outputs = self.tokenizer.detokenize(lst).numpy().decode('utf-8')if return_states:return outputs, stateselse:return outputsinfere = InferenceModel(model, tokenizer)# 开始推理
start_chars = 'hello'
outputs = infere.generate(start_chars, 1000)
print(start_chars + outputs)
二、过程实现
2.1 导包
先导包tensorflow, keras_nlp, numpy
import tensorflow as tf
import keras_nlp
import numpy as np
2.2 数据准备
数据来自莎士比亚的作品 storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt;我们将其下载下来存储为shakespeare.txt
2.3 字符分词
这里我们使用unicode分词:将所有字符都作为一个词来进行分词
tokenizer = keras_nlp.tokenizers.UnicodeCodepointTokenizer(vocabulary_size=400)# tokens - ids
ids = tokenizer(['Why are you so funny?', 'how can i get you'])# ids - tokens
tokenizer.detokenize(ids)
2.4 构建数据集
利用tokenizer和text数据构建数据集
def split_input_target(sequence):input_text = sequence[:-1]target_text = sequence[1:]return input_text, target_texttext = open('./shakespeare.txt', 'rb').read().decode(encoding='utf-8')
dataset = tf.data.Dataset.from_tensor_slices(tokenizer(text))
dataset = dataset.batch(64, drop_remainder=True)
dataset = dataset.map(split_input_target).batch(64)input, ouput = dataset.take(1).get_single_element()
2.5 定义模型
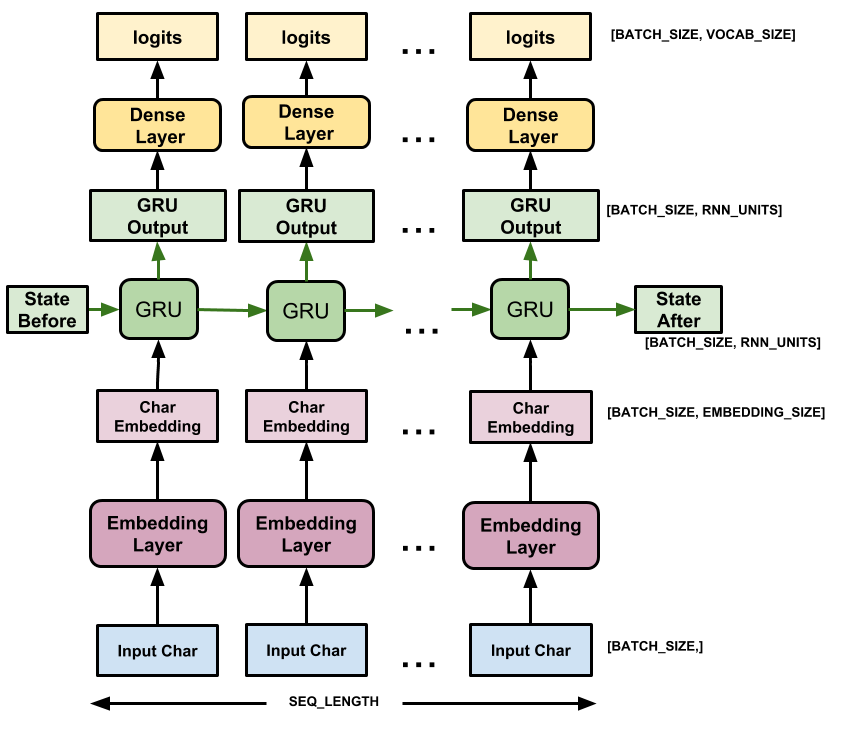
d_model = 512
rnn_units = 1025class CustomModel(tf.keras.Model):def __init__(self, vocabulary_size, d_model, rnn_units):super().__init__(self)self.embedding = tf.keras.layers.Embedding(vocabulary_size, d_model)self.gru = tf.keras.layers.GRU(rnn_units, return_sequences=True, return_state=True)self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax')def call(self, inputs, states=None, return_state=False, training=False):x = inputsx = self.embedding(x)if states is None:states = self.gru.get_initial_state(x)x, states = self.gru(x, initial_state=states, training=training)x = self.dense(x, training=training)if return_state:return x, stateselse:return xmodel = CustomModel(tokenizer.vocabulary_size(), d_model, rnn_units)# 查看模型结构
model(input)
model.summary()
2.6 模型训练
model.compile(loss = tf.losses.SparseCategoricalCrossentropy(),optimizer='adam',metrics=['accuracy']
)model.fit(dataset, epochs=3)
2.7 模型推理
定义一个InferenceModel进行模型推理配置;
class InferenceModel(tf.keras.Model):def __init__(self, model, tokenizer):super().__init__(self)self.model = modelself.tokenizer = tokenizerdef generate(self, inputs, length, return_states=False):inputs = inputs = tf.constant(inputs)[tf.newaxis]states = Noneinput_ids = self.tokenizer(inputs).to_tensor()outputs = []for i in range(length):predicted_logits, states = model(inputs=input_ids, states=states, return_state=True)input_ids = tf.argmax(predicted_logits, axis=-1)outputs.append(input_ids[0][-1].numpy())outputs = self.tokenizer.detokenize(lst).numpy().decode('utf-8')if return_states:return outputs, stateselse:return outputsinfere = InferenceModel(model, tokenizer)start_chars = 'hello'
outputs = infere.generate(start_chars, 1000)
print(start_chars + outputs)
生成结果如下所示,感觉很差:
hellonofur us:
medous, teserwomador.
walled o y.
as
t aderemowate tinievearetyedust. manonels,
w?
workeneastily.
watrenerdores aner'shra
palathermalod, te a y, s adousced an
ptit: mamerethus:
bas as t: uaruriryedinesm's lesoureris lares palit al ancoup, maly thitts?
b veatrt
watyeleditenchitr sts, on fotearen, medan ur
tiblainou-lele priniseryo, ofonet manad plenerulyo
thilyr't th
palezedorine.
ti dous slas, sed, ang atad t,
wanti shew.
e
upede wadraredorenksenche:
wedemen stamesly ateara tiafin t t pes:
t: tus mo at
io my.
ane hbrelely berenerusedus' m tr;
p outellilid ng
ait tevadwantstry.
arafincara, es fody
'es pra aluserelyonine
pales corseryea aburures
angab:
sunelyothe: s al, chtaburoly o oonis s tioute tt,
pro.
tedeslenali: s 't ing h
sh, age de, anet: hathes: s es'tht,
as:
wedly at s serinechamai:
mored t.
t monatht t athoumonches le.
chededondirineared
ter
p y
letinalys
ani
aconen,
t rs:
t;et, tes-
luste aly,
thonort aly one telus, s mpsantenam ranthinarrame! a
pul; bon
s fofuly
三、整体总结
RNN结合unicode分词能进行文本生成但是效果一言难尽!
相关文章:
RNN:文本生成
文章目录 一、完整代码二、过程实现2.1 导包2.2 数据准备2.3 字符分词2.4 构建数据集2.5 定义模型2.6 模型训练2.7 模型推理 三、整体总结 采用RNN和unicode分词进行文本生成 一、完整代码 这里我们使用tensorflow实现,代码如下: # 完整代码在这里 imp…...

Rust UI开发(五):iced中如何进行页面布局(pick_list的使用)?(串口调试助手)
注:此文适合于对rust有一些了解的朋友 iced是一个跨平台的GUI库,用于为rust语言程序构建UI界面。 这是一个系列博文,本文是第五篇,前四篇链接: 1、Rust UI开发(一):使用iced构建UI时…...
Linux学习笔记2
web服务器部署: 1.装包: [rootlocalhost ~]# yum -y install httpd 2.配置一个首页: [rootlocalhost ~]# echo i love yy > /var/www/html/index.html 启动服务:[rootlocalhost ~]# systemctl start httpd Ctrl W以空格为界…...

数据结构算法-插入排序算法
引言 玩纸牌 的时候。往往 需要将牌从乱序排列变成有序排列 这就是插入排序 插入排序算法思想 先看图 首先第一个元素 我默认已有序 那我们从第二个元素开始,依次插入到前面已有序的部分中。具体来说,我们将第二个元素与第一个元素比较,…...
安装Kuboard管理K8S集群
目录 第一章.安装Kuboard管理K8S集群 1.安装kuboard 2.绑定K8S集群,完成信息设定 3.内网安装 第二章.kuboard-spray安装K8S 2.1.先拉镜像下来 2.2.之后打开后,先熟悉功能,注意版本 2.3.打开资源包管理,选择符合自己服务器…...

网络安全行业大模型调研总结
随着人工智能技术的发展,安全行业大模型SecLLM(security Large Language Model)应运而生,可应用于代码漏洞挖掘、安全智能问答、多源情报整合、勒索情报挖掘、安全评估、安全事件研判等场景。 参考: 1、安全行业大模…...
Linux AMH服务器管理面板本地安装与远程访问
最近,我发现了一个超级强大的人工智能学习网站。它以通俗易懂的方式呈现复杂的概念,而且内容风趣幽默。我觉得它对大家可能会有所帮助,所以我在此分享。点击这里跳转到网站。 文章目录 1. Linux 安装AMH 面板2. 本地访问AMH 面板3. Linux安装…...

Sharding-Jdbc(3):Sharding-Jdbc分表
1 分表分库 LogicTable 数据分片的逻辑表,对于水平拆分的数据库(表),同一类表的总称。 订单信息表拆分为2张表,分别是t_order_0、t_order_1,他们的逻辑表名为t_order。 ActualTable 在分片的数据库中真实存在的物理表。即上个示例中的t_…...
zookeeper集群 +kafka集群
1.zookeeper kafka3.0之前依赖于zookeeper zookeeper是一个开源,分布式的架构,提供协调服务(Apache项目) 基于观察者模式涉及的分布式服务管理架构 存储和管理数据,分布式节点上的服务接受观察者的注册,…...

2022年全国大学生数据分析大赛医药电商销售数据分析求解全过程论文及程序
2022年全国大学生数据分析大赛 医药电商销售数据分析 原题再现: 问题背景 20 世纪 90 年代是电子数据交换时代,中国电子商务开始起步并初见雏形,随后 Web 技术爆炸式成长使电子商务处于蓬勃发展阶段,目前互联网信息碎片化以…...
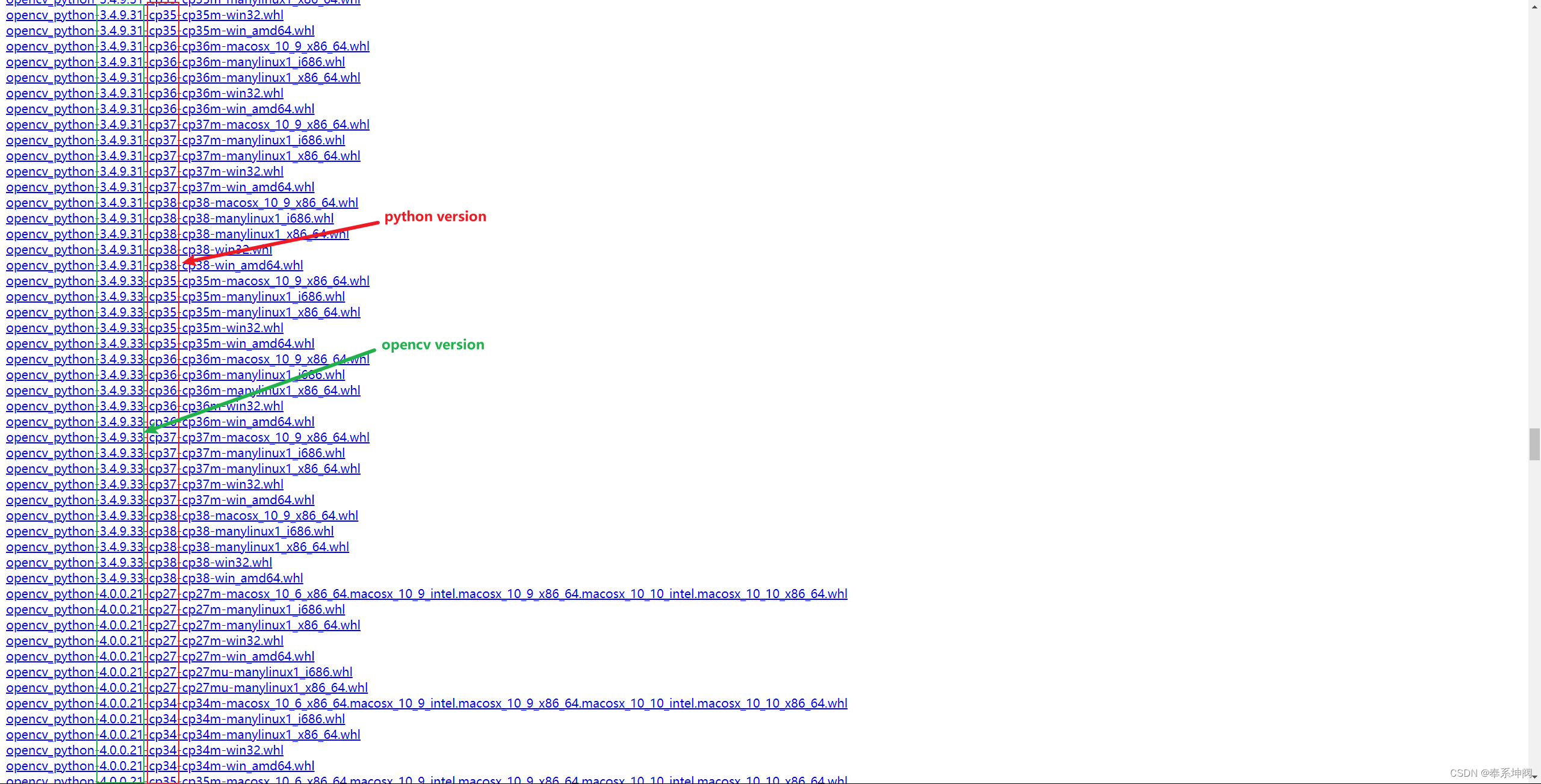
Python版本与opencv版本的对应关系
python版本要和opencv版本相对应,否则安装的时候会报错。 可以到Links for opencv-python上面查看python版本和opencv版本的对应关系,如图,红框内是python版本,绿框内是opencv版本。 查看自己的python版本后,使用下面…...

【开源视频联动物联网平台】LiteFlow
LiteFlow是一个轻量且强大的国产规则引擎框架,可用于复杂的组件化业务的编排领域。它基于规则文件来编排流程,支持xml、json、yml三种规则文件写法方式,再复杂的逻辑过程都能轻易实现。LiteFlow于2020年正式开源,2021年获得开源中…...

家用智能门锁——智能指纹锁方案
智能指纹锁产品功能: 1:指纹识别技术:光学传感器、半导体传感器或超声波传感器等。 2:指纹容量:智能指纹锁可以存储的指纹数量,通常在几十到几百个指纹之间。 3:解锁时间:指纹识别和…...

Qt6 QRibbon 一键美化Qt界面
强烈推荐一个 github 项目: https://github.com/gnibuoz/QRibbon 作用: 在几乎不修改任何你自己代码的情况下,一键美化你的 UI 界面。 代码环境:使用 VS2019 编译 Qt6 GUI 程序,继承 QMainWindow 窗口类 一、使用方法 …...
JAVA IO:NIO
1.阻塞 IO 模型 最传统的一种 IO 模型,即在读写数据过程中会发生阻塞现象。当用户线程发出 IO 请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出 CPU。当…...

Python 在控制台打印带颜色的信息
#格式: 设置颜色开始 :\033[显示方式;前景色;背景色m #说明: 前景色 背景色 颜色 --------------------------------------- 30 40 黑色 31 41 红色 32 …...
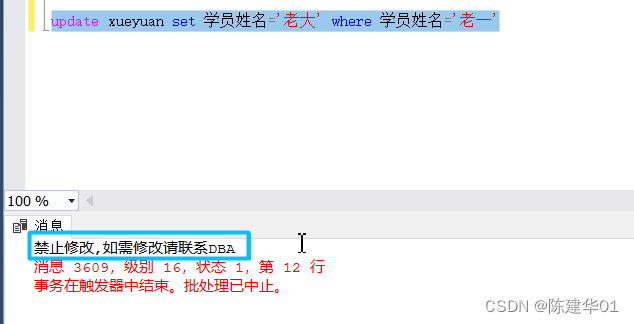
SQL Server 数据库,创建触发器避免数据被更改
5.4触发器 触发器是一种特殊类型的存储过程,当表中的数据发生更新时将自动调用,以响应INSERT、 UPDATE 或DELETE 语句。 5.4.1什么是触发器 1.触发器的概念 触发器是在对表进行插入、更新或删除操作时自动执行的存储过程,触发器通常用于强…...
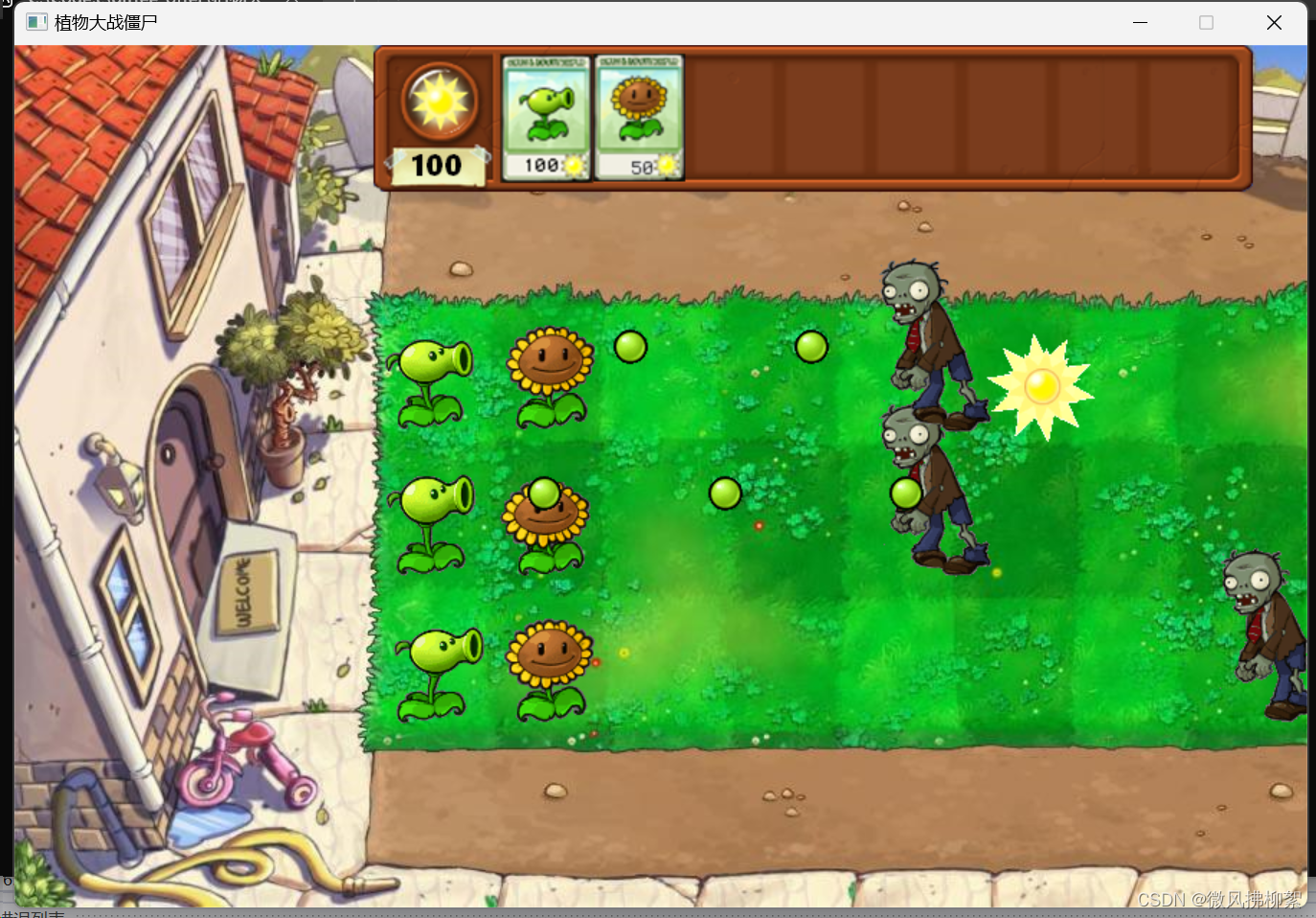
C语言实现植物大战僵尸(完整版)
实现这个游戏需要Easy_X 这个在我前面一篇C之番外篇爱心代码有程序教你怎么下载,大家可自行查看 然后就是需要植物大战僵尸的素材和音乐,需要的可以在评论区 首先是main.cpp //开发日志 //1导入素材 //2实现最开始的游戏场景 //3实现游戏顶部的工具栏…...

基于YOLOv8深度学习的火焰烟雾检测系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

【C++】手撕string思路梳理
目录 基本思路 代码实现 1.构建框架: 2.构建函数重载 3.迭代器: 4.遍历string 5.resetve 开空间,insert任意位置插入push_back,append,(按顺序依次实现) 6.erase删除,clear清除,resize缩容 7.流插入࿰…...


让macOS窗口切换像Windows一样高效:alt-tab-macos完全指南
让macOS窗口切换像Windows一样高效:alt-tab-macos完全指南 【免费下载链接】alt-tab-macos Windows alt-tab on macOS 项目地址: https://gitcode.com/gh_mirrors/al/alt-tab-macos 你是否曾经在macOS上怀念Windows的alttab快捷键?是否觉得macOS…...

Orange Pi i 96开发板实战:从硬件解析到家庭服务器与物联网应用部署
1. 项目概述:为什么是Orange Pi i 96?最近在捣鼓一些边缘计算和轻量级服务器的项目,手头正好需要一块性能足够、接口丰富但又足够小巧、功耗可控的开发板。市面上树莓派当然是首选,但供货和价格嘛,你懂的。于是我把目光…...

如何快速构建高质量平行语料库:Lingtrain Aligner智能文本对齐完全指南
如何快速构建高质量平行语料库:Lingtrain Aligner智能文本对齐完全指南 【免费下载链接】lingtrain-aligner Lingtrain Aligner — ML powered library for the accurate texts alignment. 项目地址: https://gitcode.com/gh_mirrors/li/lingtrain-aligner 平…...

Emacs实时语法检查优化:flymake-cursor插件实现光标悬停提示
1. 项目概述:Emacs 实时语法检查的得力助手如果你是一个 Emacs 用户,并且主要用它来写代码,那么你一定对“实时语法检查”这个功能不陌生。在编写代码时,能够即时看到潜在的错误、拼写问题或者代码风格警告,这能极大地…...

NotebookLM溯源结果不显示原文页码?紧急补丁已部署!2024Q3最新API v2.3溯源增强版深度解读
更多请点击: https://intelliparadigm.com 第一章:NotebookLM溯源功能演进与v2.3核心定位 NotebookLM 自 2023 年初发布以来,其“溯源”能力经历了从静态引用标注到动态上下文感知的显著跃迁。早期版本仅支持对上传文档片段生成粗粒度来源标…...

广告投放ROI断崖式下滑?立即排查ElevenLabs这4个语音合成致命偏差,2小时内修复
更多请点击: https://intelliparadigm.com 第一章:广告投放ROI断崖式下滑的语音归因真相 当广告主发现iOS 17设备上语音搜索转化路径中归因丢失率高达68%,却仍在依赖传统点击归因(Click-Through Attribution)模型时&a…...

应对2026知网维普算法更新:论文降AI全攻略,实测3款主流工具与手动微调方法
自从央视公开探讨初稿写作的AI味儿现象:据相关数据显示,近六成师生习惯使用生成式辅助,其中近三成学生将其用于核心初稿的撰写,各高校针对AIGC的审查便日益严格。 正是因为这种大背景,四月一到,定稿通知刚…...

直播抠图技术100谈之25---调色中曲线是最优解
为什么曲线调色是最优解 蓝松抠图在即将发布的版本中特意重写了曲线调节,把达芬奇的二级曲线重新做了一遍,并模仿达芬奇的节点图做了自己的节点图。我们为什么要重新设计曲线,因为我们认为调色中曲线是最优解; 结论 在所有调色手段…...

设计程序统计城市社区医疗站点接诊数据,优化医疗点位分布,方便居民就近看病,解决就医难问题。
一、实际应用场景描述某城市卫健委希望优化社区卫生服务中心布局,但面临以下现实情况:- 各社区接诊量差异巨大- 部分点位长期排队,部分点位资源闲置- 居民跨区就医成本高- 缺乏基于数据的点位调整依据👉 技术目标:用 P…...