(动手学习深度学习)第13章 实战kaggle竞赛:树叶分类
文章目录
- 实战kaggle比赛:树叶分类
- 1. 导入相关库
- 2. 查看数据格式
- 3. 制作数据集
- 4. 数据可视化
- 5. 定义网络模型
- 6. 定义超参数
- 7. 训练模型
- 8. 测试并提交文件
- 竞赛技术总结
- 1. 技术分析
- 2. 数据方面
- 模型方面
- 3. AutoGluon
- 4. 总结
实战kaggle比赛:树叶分类
kaggle竞赛链接
数据集格式如下:
- image文件夹:27153张叶子图片,编号为: 0到27152
- sample_submission.csv(提交文件): 有8800个样本(18353到27152),2列(图片名称、预测类别)
- test.csv(测试文件):有8800个样本(18353到27152),1列(图片名称)
- train.csv(训练文件): 有18353个样本(0到18352),2列(图片名称,所属类别)
解题思路:
- 首先数据集是打乱随机分布,要通过train.csv将iamge的所有图片按照不同类别分配所属的文件夹
- 然后数据增强、设计模型、训练模型
1. 导入相关库
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
import matplotlib.pyplot as plt
import torchvision.models as models
# 下面时用来画图和显示进度条的两个库
from tqdm import tqdm # 一个用于迭代过程中显示进度条的工具库
import seaborn as sns # 在matplotlib基础上面的封装库,方便直接传参数调用
2. 查看数据格式
# 查看label文件格式
labels_dataframe = pd.read_csv("E:\\219\\22chenxiaoda\\experiment\\pythonProject\\data\\classify-leaves\\classify-leaves/train.csv")
labels_dataframe.head()

# 查看labels摘要:数值列的统计汇总信息
labels_dataframe.describe()

可视化数据集不同类别的样本数
# 用横向柱状图可视化不同类别中图片个数
def barw(ax):for p in ax.patches:val = p.get_width() # 柱状图的高度即种类钟图片的数量x = p.get_x() + p.get_width() # x位置y = p.get_y() + p.get_height() # y位置ax.annotate(round(val, 2), (x, y)) # 注释文本的内容,被注释的坐标点
plt.figure(figsize=(15, 30))
# sns.countplot()函数: 以bar的形式展示每个类别的数量
ax0 = sns.countplot(y=labels_dataframe['label'], order=labels_dataframe['label'].value_counts().index)
barw(ax0)
plt.show()
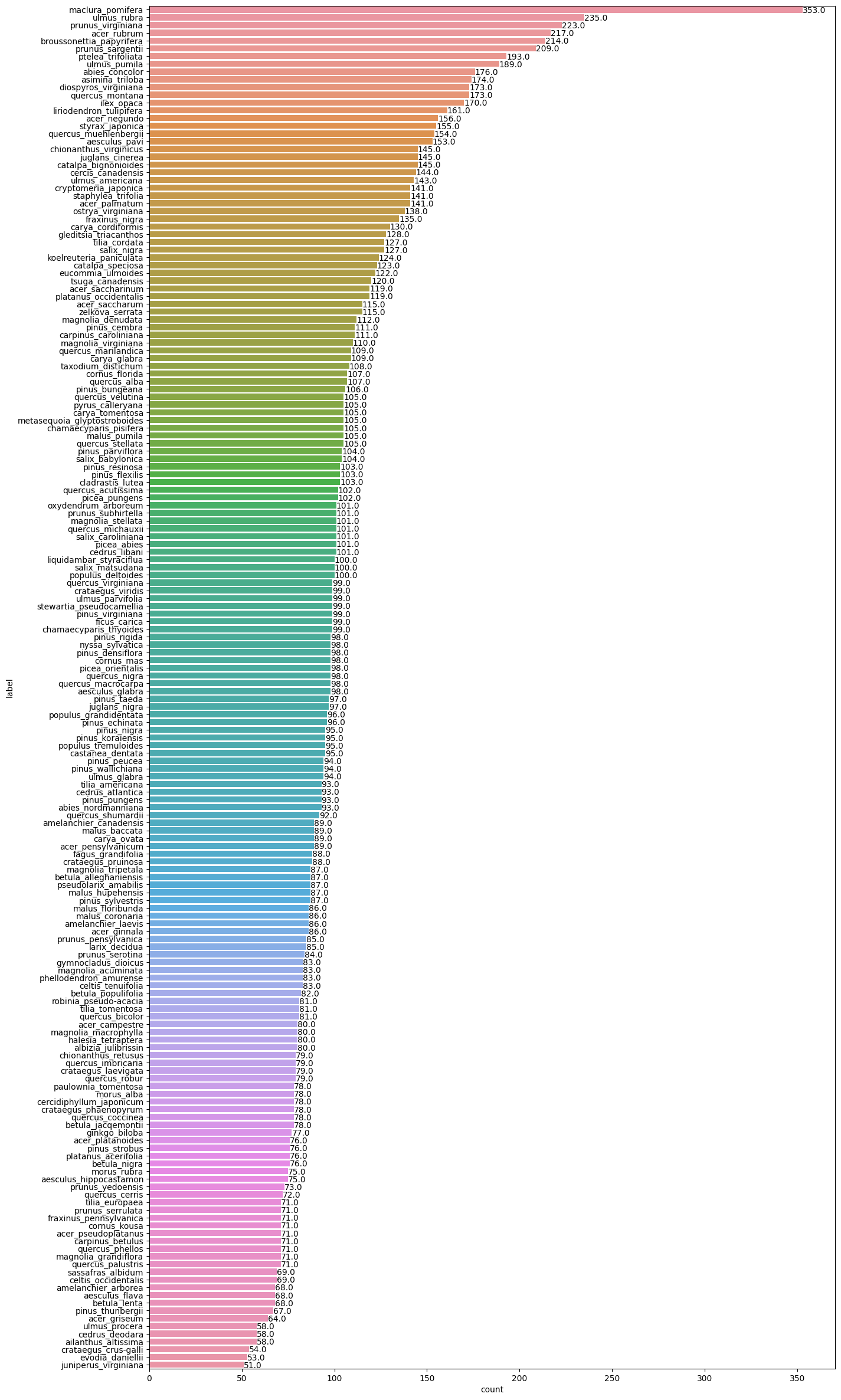
将176个英文类别转换成对应的数据标签,方便训练。
# 将label文件排序
# set():函数创建一个无序不重复元素集
# list():创建列表
# sorted():返回一个排序后的新序列,不改变原始序列(默认按照字母升序)
leaves_labels = sorted(list(set(labels_dataframe['label'])))
n_classes = len(leaves_labels)
print(n_classes)
leaves_labels[:5]

# 将label文件排序
# set():函数创建一个无序不重复元素集
# list():创建列表
# sorted():返回一个排序后的新序列,不改变原始序列(默认按照字母升序)
leaves_labels = sorted(list(set(labels_dataframe['label'])))
n_classes = len(leaves_labels)
print(n_classes)
leaves_labels[:5]

再将数字转换成对应的标签:方便最后预测的时候应用
# 再将数字转换成对应的标签:方便最后预测的时候应用
num_to_class = {v : k for k,v in class_to_num.items()}
num_to_class
3. 制作数据集
# 继承pytorch的dataset,创建自己的
class LeavesData(DataLoader):def __init__(self, csv_path, file_path, mode='train', valid_ratio=0.2, resize_height=256, resize_with=256):""":param csv_path: csv文件路径:param file_path: 图像文件所在路径:param valid_ratio: 验证集比例:param resize_height::param resize_with:"""self.resize_height = resize_heightself.resize_weight = resize_withself.file_path = file_pathself.mode = mode# 读取csv文件# 利用pandas读取csv文件# pandas.read_csv(“data.csv”)默认情况下,会把数据内容的第一行默认为字段名标题。# 添加“header=None”,告诉函数,我们读取的原始文件数据没有列索引。因此,read_csv为自动加上列索引。# self.data_info = pd.read_csv(csv_path, header=None)self.data_info = pd.read_csv(csv_path)# 计算lengthself.data_len = len(self.data_info.index)self.train_len = int(self.data_len * (1 - valid_ratio))if mode == 'train':# 第一列包含图像文件的名称# 数据源是ndarray时,array仍然会copy出一个副本,占用新的内存,但asarray不会。self.train_image = np.asarray(self.data_info.iloc[0: self.train_len, 0])self.train_label = np.asarray(self.data_info.iloc[0:self.train_len, 1])self.image_arr = self.train_imageself.label_arr = self.train_labelelif mode == 'valid':self.valid_image = np.asarray(self.data_info.iloc[self.train_len:, 0])self.valid_label = np.asarray(self.data_info.iloc[self.train_len:, 1])self.image_arr = self.valid_imageself.label_arr = self.valid_labelelif mode == 'test':self.test_image = np.asarray(self.data_info.iloc[0:, 0])self.image_arr = self.test_imageself.real_len = len(self.image_arr)print(f' Finished reading the {mode} set of Leaves Dataset ({self.real_len} samples found)')def __getitem__(self, index):# 从image_arr中得到索引对应的文件名single_image_name = self.image_arr[index]# 读取图像文件img_as_img = Image.open(self.file_path + single_image_name)# 设置好需要转换的变量, 还包括一系列的normalize等操作if self.mode == 'train':transform = transforms.Compose([transforms.Resize(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])else:transform = transforms.Compose([transforms.Resize(224),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])img_as_img = transform(img_as_img)if self.mode == 'test':return img_as_imgelse:# 得到train和valid的字符串labellabel = self.label_arr[index]# 字符串label-->数字labelnumber_label = class_to_num[label]return img_as_img, number_label # 返回每一个index对应的照片数据和对应的labeldef __len__(self):return self.real_len
train_path = "E:\\219\\22chenxiaoda\\experiment\\pythonProject\\data\\classify-leaves\\classify-leaves/train.csv"
test_path = "E:\\219\\22chenxiaoda\\experiment\\pythonProject\\data\\classify-leaves\\classify-leaves/test.csv"
# csv文件中已经定义到image的路径, 因此这里知道上一级目录
img_path = 'E:\\219\\22chenxiaoda\\experiment\\pythonProject\\data\\classify-leaves\\classify-leaves/'train_dataset = LeavesData(train_path, img_path, mode='train')
val_dataset = LeavesData(train_path, img_path, mode='valid')
test_dataset = LeavesData(test_path, img_path, mode='test')print(train_dataset)
print(val_dataset)
print(test_dataset)

# 定义dataloader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=32, shuffle=True
)
val_loader = torch.utils.data.DataLoader(dataset=val_dataset, batch_size=32,shuffle=False
)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=32, shuffle=False
)
4. 数据可视化
# 展示数据
def im_covert(tensor):"""展示数据"""image = tensor.to("cpu").clone().detach()image = image.numpy().squeeze()image = image.transpose(1, 2, 0)image = image * np.array((0.229, 0.224, 0.225)) + np.array((0.485, 0.456, 0.406)) # 还原标准化,先乘再加image = image.clip(0, 1)return imagefig = plt.figure(figsize=(20, 12))
columns = 4
rows = 2dataiter = iter(val_loader)
inputs, classes = dataiter.next()for idx in range(columns * rows):ax = fig.add_subplot(rows, columns, idx+1, xticks=[], yticks=[])ax.set_title(num_to_class[int(classes[idx])])plt.imshow(im_covert(inputs[idx]))
plt.show()

5. 定义网络模型
# 是否使用GPU来训练
def get_device():return 'cuda' if torch.cuda.is_available() else 'cpu'device = get_device()
print(device)
# 是否要冻住模型的前面一些层
def set_parameter_requires_grad(model, feature_extracting):if feature_extracting:model = modelfor param in model.parameters():param.requires_grad = False
# 选用resnet34模型
# 是否要冻住模型的前面一些层
def set_parameter_requires_grad(model, feature_extracting):if feature_extracting:model = modelfor param in model.parameters():param.requires_grad = False
# 使用resnet34模型
def res_model(num_classes, feature_extract=False):model_ft = models.resnet34(weights=models.ResNet34_Weights.IMAGENET1K_V1)set_parameter_requires_grad(model_ft, feature_extract)num_ftrs = model_ft.fc.in_featuresmodel_ft.fc = nn.Linear(num_ftrs, num_classes)return model_ft
# 模型初始化
model = res_model(176)
model = model.to(device)
model.device = device
model
6. 定义超参数
learning_rate = 3e-4
weight_decay = 1e-3
num_epoch = 50
model_path = './pre_res_model_32.ckpt'
criterion = nn.CrossEntropyLoss()
不冻住前面的预训练层
- 对预训练层, 使用较小的学习率训练
- 对自定义的分类输出层, 使用较大的学习率
# 对最后定义的全连接层和之前的层采用不同的学习率训练
params_1x = [param for name, param in model.named_parameters()if name not in ['fc.weight', 'fc.bias']]
optimizer = torch.optim.Adam(# model.parameters(),[{'params': params_1x}, {'params': model.fc.parameters(), 'lr': learning_rate * 10}],lr=learning_rate, weight_decay=weight_decay
)
7. 训练模型
import time# 在开头设置开始时间
start = time.perf_counter() # start = time.clock() python3.8之前可以best_acc, best_epoch = 0.0, 0
train_loss, train_accs = [], []
valid_loss, valid_accs = [], []for epoch in range(num_epoch):# -----------训练-----------model.train()train_loss = []train_accs = []for imgs, labels in tqdm(train_loader):# 一个batch由imgs和相应的labels组成。imgs = imgs.to(device)labels = labels.to(device)# 前向传播predicts = model(imgs)# 计算损失loss = criterion(predicts, labels)# 梯度清空optimizer.zero_grad()# 反向传播loss.backward()# 梯度更新optimizer.step()# 计算当前batch的精度# 转为float就是把true变成1,false变成0;# 然后mean就是求这个向量的均值,也就是true的数目除以总样本数,得到acc。acc =(predicts.argmax(dim=1) == labels).float().mean()# 记录训练损失和精度train_loss.append(loss.item())train_accs.append(acc)# 训练集的平均损失和准确性是一个batch的平均值train_loss = sum(train_loss) / len(train_loss)train_acc = sum(train_accs) / len(train_accs)# 打印训练损失和精度print(f'[Train | {epoch + 1 :03d} / {num_epoch:03d}] Train loss = {train_loss:.5f}, Train acc={train_acc:.5f}')# --------验证--------model.eval()valid_loss = []valid_accs = []for batch in tqdm(val_loader):imgs, labels = batch# 前向传播# 验证不需要计算梯度# 使用torch.no_grad()不计算梯度,能加速前向传播过程with torch.no_grad():predicts = model(imgs.to(device))# 计算损失loss = criterion(predicts, labels.to(device))# 计算精度acc = (predicts.argmax(dim=-1) == labels.to(device)).float().mean()# 记录验证损失和精度valid_loss.append(loss.item())valid_accs.append(acc)# 跟训练集一样: 验证集的平均损失和准确性是一个batch的平均值valid_loss = sum(valid_loss) / len(valid_loss)valid_acc = sum(valid_accs) / len(valid_accs)# 打印验证损失和精度print(f'[Valid | {epoch + 1:03d} / {num_epoch:03d}] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}')# 保存迭代过程中最优的模型参数if valid_acc > best_acc:best_acc = valid_accbest_epoch = epochtorch.save(model.state_dict(), model_path)print(f'Save model with acc{best_acc:.3f}, it is the {epoch} epoch')print(f'The best model with acc{best_acc:.3f}, it is the {best_epoch} epoch')# 在程序运行结束的位置添加结束时间
end = time.perf_counter() # end = time.clock() python3.8之前可以# 再将其进行打印,即可显示出程序完成的运行耗时
print(f'运行耗时{(end-start):.4f}')
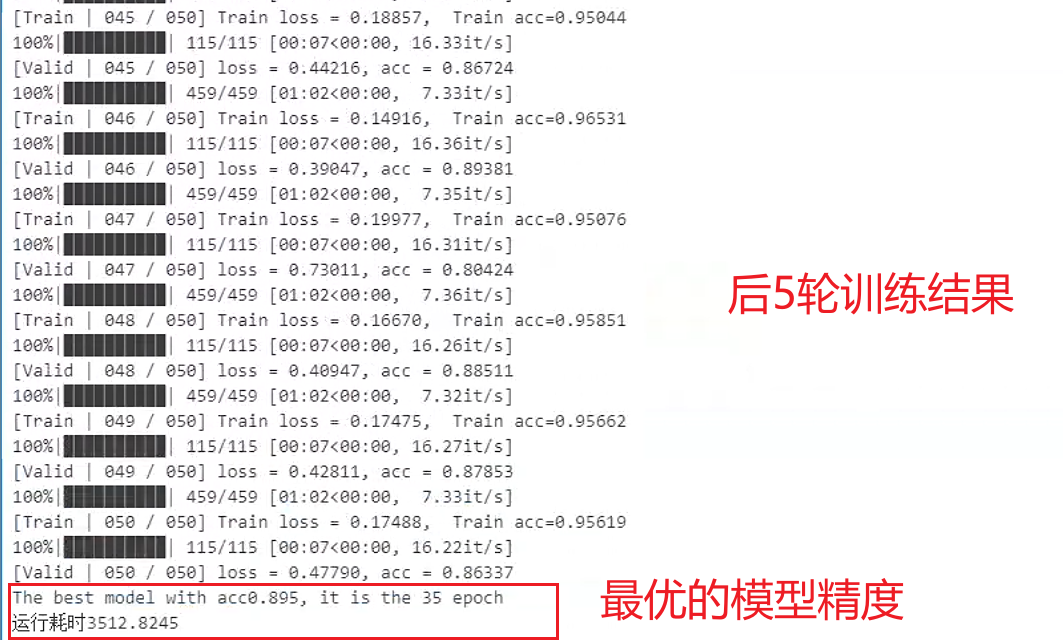
8. 测试并提交文件
# 提交文件
saveFileName = './submission32.csv'
# 预测
model = res_model(176)# 利用前面训练好的模型参数进行预测
model = model.to(device)
model.load_state_dict(torch.load(model_path))# 模型预测
model.eval()# 保存预测结果
predictions = []# 迭代测试集
for batch in tqdm(test_loader):imgs = batchwith torch.no_grad():logits = model(imgs.to(device))# 保存预测结果predictions.extend(logits.argmax(dim=-1).cpu().numpy().tolist())preds = []
for i in predictions:# 将数字标签转换为对应的字符串标签preds.append(num_to_class[i])test_data = pd.read_csv(test_path)
test_data['label'] = pd.Series(preds)
submission = pd.concat([test_data['image'], test_data['label']], axis=1)
submission.to_csv(saveFileName, index=False)
print('Done!!!!!')

竞赛技术总结
1. 技术分析
相比于课程介绍的代码,大家主要做了下面这些加强
- 数据增强,在测试时多次使用稍弱的增强然后取平均
- 使用多个模型预测,最后结果加权平均
- 有使用10种模型的,也有使用单一模型的
- 训练算法和学习率
- 清理数据
2. 数据方面
- 有重复图片,可以手动去除
- 图片背景较多,而且树叶没有方向性,可以做更多数据增强
- 随机旋转、更大的剪裁
- 跨图片增强:
- Mixup: 随机叠加两张图片
- CutMix:随机组合来自不同图片的块
模型方面
- 模型多为ResNet变种
- DenseN儿童, ResNeXt, ResNeSt,···
- EfficientNet
- 优化算法多为Adam或其变种
- 学习率一般是Cosine或者训练不动时往下调
3. AutoGluon
- 15行代码,安装加训练花时100分钟
- AutoGluon链接
- 精度96%
- 可以通过定制化提升精度
- 下一个版本将搜索更多的模型超参数
- AG目前主要仍是关注工业界应用上,非比赛
4. 总结
- 提升精度思路:根据数据挑选增强,使用新模型、新优化算法,多模型融合,测试时使用增强
- 数据相对简单,排名有相对随机性
- 在工业界应用中:
- 少使用模型融合和测试时增强,计算代价过高
- 通常固定模型超参数,而将精力主要花在提升数据质量
相关文章:
(动手学习深度学习)第13章 实战kaggle竞赛:树叶分类
文章目录 实战kaggle比赛:树叶分类1. 导入相关库2. 查看数据格式3. 制作数据集4. 数据可视化5. 定义网络模型6. 定义超参数7. 训练模型8. 测试并提交文件 竞赛技术总结1. 技术分析2. 数据方面模型方面3. AutoGluon4. 总结 实战kaggle比赛:树叶分类 kagg…...

vue中shift+alt+f格式化防止格式掉其它内容
好处就是使得提交记录干净,否则修改一两行代码,习惯性按了一下格式化快捷键,遍地飘红,下次找修改就费时间 1.点击设置图标-设置 2.点击这个转成配置文件 {"extensions.ignoreRecommendations": true,"[vue]":…...
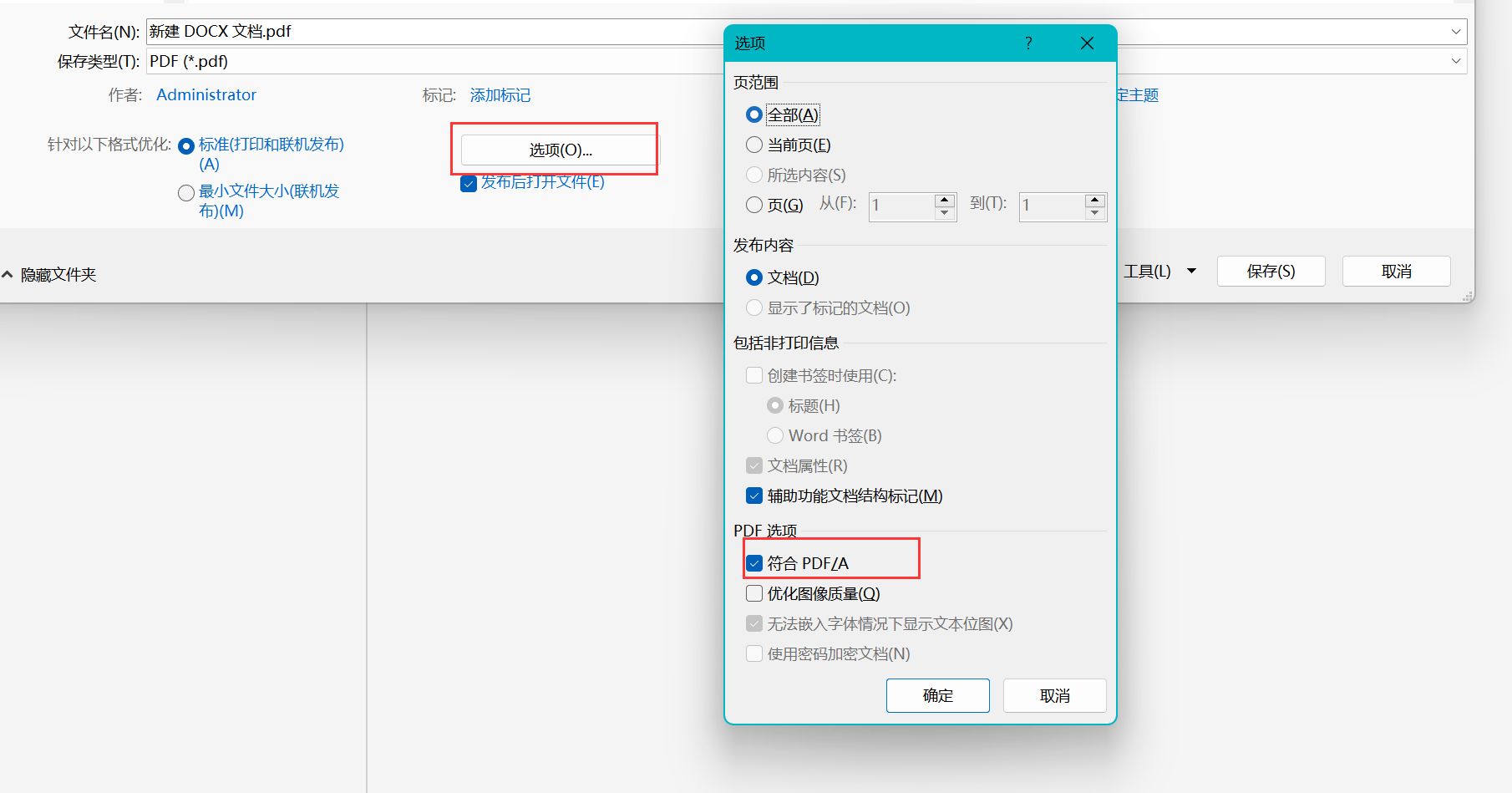
WPS导出的PDF比较糊,和原始的不太一样,将带有SVG的文档输出为PDF
一、在WPS的PPT中 你直接输出PDF可能会导致一些问题(比如照片比原来糊)/ 或者你复制PPT中的图片到AI中类似的操作,得到的照片比原来糊,所以应该选择打印-->高级打印 然后再另存为PDF 最后再使用AI打开PDF文件再复制到你想用…...

Linux /etc/hosts文件
Linux的 /etc/hosts 文件用于静态地映射主机名到 IP 地址。 通常用于本地网络中的名称解析,它可以覆盖 DNS 的设置。当你访问一个域名时,系统会首先检查 /etc/hosts 文件,如果找到了匹配项,就会使用该 IP 地址,否则会…...
webpack学习-3.管理输出
webpack学习-3.管理输出 1.简单练手2.设置 HtmlWebpackPlugin3.清理 /dist 文件夹4.manifest5.总结 1.简单练手 官网的第一个预先准备,是多入口的。 const path require(path);module.exports {entry: {index: ./src/index.js,print: ./src/print.js,},output: …...

【Go语言反射reflect】
Go语言反射reflect 一、引入 先看官方Doc中Rob Pike给出的关于反射的定义: Reflection in computing is the ability of a program to examine its own structure, particularly through types; it’s a form of metaprogramming. It’s also a great source of …...

LC-1466. 重新规划路线(DFS、BFS)
1466. 重新规划路线 中等 n 座城市,从 0 到 n-1 编号,其间共有 n-1 条路线。因此,要想在两座不同城市之间旅行只有唯一一条路线可供选择(路线网形成一颗树)。去年,交通运输部决定重新规划路线,…...
自动数据增广论文笔记 | AutoAugment: Learning Augmentation Strategies from Data
谷歌大脑出品 paper: https://arxiv.org/abs/1805.09501 这里是个论文的阅读心得,笔记,不等同论文全部内容 文章目录 一、摘要1.1 翻译1.2 笔记 二、(第3部分)自动增强:直接在感兴趣的数据集上搜索最佳增强策略2.1 翻译2.2 笔记 三、跳出论文,…...

CTF 7
信息收集 存活主机探测 arp-scan -l 端口探测 nmap -sT --min-rate 10000 -p- 192.168.0.5 服务版本等信息 nmap -sT -sV -sC -O -p22,80,137,138,139,901,5900,8080,10000 192.168.0.5Starting Nmap 7.94 ( https://nmap.org ) at 2023-11-02 21:23 CST Stats: 0:01:30 elaps…...

无公网IP环境Windows系统使用VNC远程连接Deepin桌面
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《Linux》《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,…...

java--枚举
1.枚举 枚举是一种特殊类 2.枚举类的格式 注意: ①枚举类中的第一行,只能写一些合法的标识符(名称),多个名称用逗号隔开。 ②这些名称,本质是常量,每个常量都会记住枚举类的一个对象。 3.枚举类的特点 ①枚举类的…...

JVM垃圾回收机制GC
一句话介绍GC: 自动释放不再使用的内存 一、判断对象是否能回收 思路一:引用计数 给这个对象里安排一个计数器, 每次有引用指向它, 就把计数器1, 每次引用被销毁,计数器-1,当计数器为0的时候…...

详解JAVA中的@ApiModel和@ApiModelProperty注解
目录 前言1. ApiModel注解2. ApiModelProperty注解3. 实战 前言 在Java中,ApiModel和ApiModelProperty是Swagger框架(用于API文档的工具)提供的注解,用于增强API文档的生成和展示。这两者搭配使用更佳 使用两者注解,…...
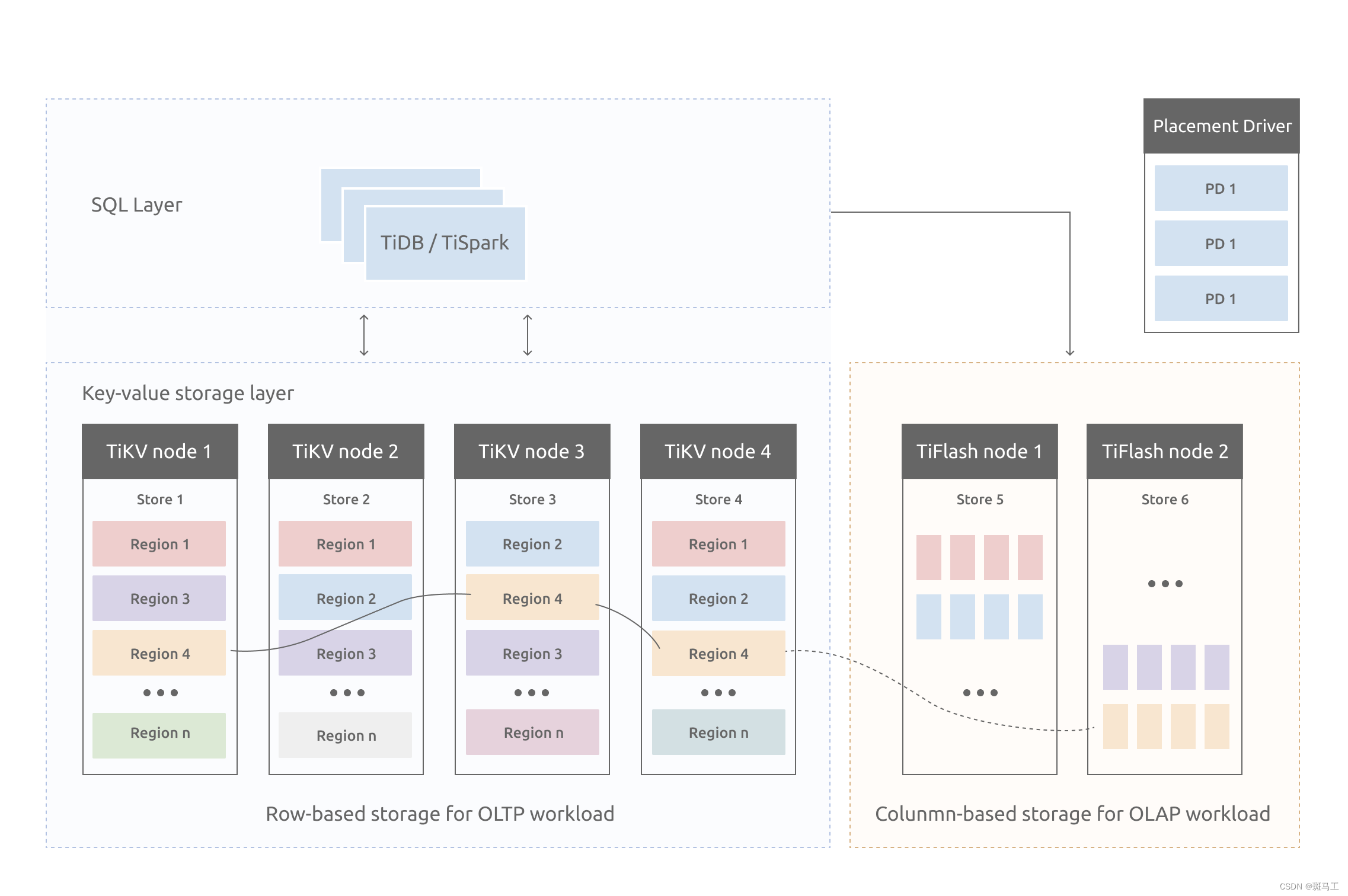
TiDB专题---2、TiDB整体架构和应用场景
上个章节我们讲解了TiDB的发展和特性,这节我们讲下TiDB具体的架构和应用场景。首先我们回顾下TiDB的优势。 TiDB的优势 与传统的单机数据库相比,TiDB 具有以下优势: 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容…...
性能调优入门
从公众号转载,关注微信公众号掌握更多技术动态 --------------------------------------------------------------- 一、性能定律和数理基础 1.三个定律法则 (1)帕累托法则 我它也被称为 80/20 法则、关键少数法则,或者八二法则。人们在生活中发现很多…...

JavaWeb | 验证码 、 文件的“上传”与“下载”
目录: 验证码 和 文件的“上传”与“下载”1.验证码1.1在JSP上开发验证码 2.“文件上传” 和 “文件下载”2.1“文件上传 ”2.2“文件下载” 验证码 和 文件的“上传”与“下载” 1.验证码 验证码:就是由服务器生成的一串随机数字或符号形成一幅图片&am…...

服务器感染了.halo勒索病毒,如何确保数据文件完整恢复?
导言: 随着科技的不断发展,网络安全问题日益突出,而.halo勒索病毒正是这个数字时代的一大威胁。本文将深入介绍.halo勒索病毒的特点,解释在受到攻击后如何有效恢复被加密的数据文件,并提供一些建议以预防未来可能的威…...
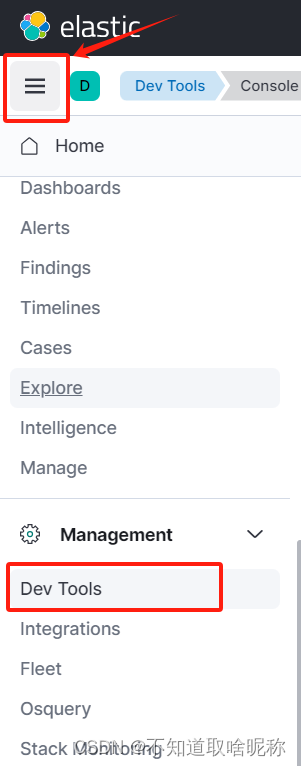
docker安装elasticsearch8.5.0和kibana
服务器环境,centos7 一、安装elasticsearch 1. 创建一个es和kibana通用的网络 docker network create es-net 2. 拉取es镜像,这里选择8.5.0版本 docker pull elasticsearch:8.5.03. 创建挂载目录,并授权 mkdir /usr/local/install/ela…...

如何使用内网穿透工具实现公网访问GeoServe Web管理界面
文章目录 前言1.安装GeoServer2. windows 安装 cpolar3. 创建公网访问地址4. 公网访问Geo Servcer服务5. 固定公网HTTP地址6. 结语 前言 GeoServer是OGC Web服务器规范的J2EE实现,利用GeoServer可以方便地发布地图数据,允许用户对要素数据进行更新、删除…...

koa2项目中封装log4js日志输出
1.日志输出到控制台 npm i log4js -D 封装log4js文件: 注意:每次都要重新获取log4js.getLogger(debug)级别才能生效 const log4js require("log4js");const levels {trace: log4js.levels.TRACE,debug: log4js.levels.DEBUG,info: log4js.…...
)
别再只会用os.listdir了!Python遍历文件夹的3种高效方法(附性能对比)
别再只会用os.listdir了!Python遍历文件夹的3种高效方法(附性能对比) 当你的Python项目需要处理成千上万的文件时,传统的os.listdir()方法可能会成为性能瓶颈。我曾经在一个图像处理项目中,因为使用了不当的遍历方法&a…...
)
WRF-CHEM模拟翻车?可能是你的namelist.chem没设对(附MEIC数据实战配置清单)
WRF-CHEM模拟异常排查指南:MEIC数据与namelist.chem的深度适配 当WRF-CHEM模拟结果出现异常时,很多用户会第一时间怀疑MEIC数据处理环节的问题,但实际上,namelist.chem参数与MEIC特性的匹配度才是更隐蔽的关键因素。本文将带您深入…...
)
告别Vivado依赖!手把手教你用Modelsim独立仿真Vivado IP核(附PLL报错解决方案)
深度解析:如何高效利用Modelsim独立仿真Vivado IP核 在FPGA开发领域,仿真环节往往成为项目进度的瓶颈。许多工程师习惯性地依赖Vivado自带的仿真环境,却忽视了专业仿真工具Modelsim的强大性能。本文将带您突破这一局限,掌握脱离Vi…...

在Windows上轻松安装APK文件:APK Installer完全指南
在Windows上轻松安装APK文件:APK Installer完全指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行Android应用&…...

Netscape 浏览器:互联网时代的先驱者
Netscape 浏览器:互联网时代的先驱者 引言 自互联网诞生以来,浏览器作为连接用户与网络世界的重要工具,见证了互联网的飞速发展。在众多浏览器中,Netscape 浏览器以其创新和引领潮流的特性,成为了互联网时代的先驱者。本文将回顾 Netscape 浏览器的发展历程、技术特点及…...

对比直接使用厂商API,Taotoken在账单清晰度上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API,Taotoken在账单清晰度上的优势 在集成多个大语言模型到业务中时,开发者或团队通常会面…...

从零到一:基于STM32CubeMX与FSMC高效点亮TFT LCD屏的实战指南
1. 硬件准备与环境搭建 第一次接触STM32和TFT LCD屏时,我完全被各种接线和术语搞晕了。后来才发现,只要选对硬件组合,事情就成功了一半。我用的STM32F103ZET6开发板(俗称大容量版)和正点原子2.8寸LCD屏,这套…...

LAMMPS效率翻倍秘籍:从单机到并行,你的MPICH配置真的对了吗?
LAMMPS效率翻倍秘籍:从单机到并行,你的MPICH配置真的对了吗? 在分子动力学模拟领域,LAMMPS因其开源特性和强大的计算能力成为研究者的首选工具。然而,许多用户在使用过程中常遇到一个令人沮丧的现象——明明配置了多核…...

量子强化学习与混合架构在工业控制与缺陷检测中的实践
1. 量子强化学习在工业控制中的实践突破量子强化学习(QRL)作为传统强化学习的量子化延伸,正在工业自动化领域展现出独特优势。以移动通信基站天线选择为例,传统方法需要精确追踪手机运动轨迹,而QRL通过训练智能体基于历…...

零成本替代 Zendesk,个人 / 小团队专属开源客服系统
零成本替代 Zendesk,个人 / 小团队专属开源客服系统 前言 在线客服这个赛道,Intercom、Zendesk 这些产品做得确实成熟,但价格对于小团队来说始终是个门槛。随便看一家,每月订阅费基本从几百到几千不等,企业版功能更是直…...