分布式搜索引擎03
1.数据聚合
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
-
什么品牌的手机最受欢迎?
-
这些手机的平均价格、最高价格、最低价格?
-
这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
1.1.聚合的种类
聚合常见的有三类:
-
桶(Bucket)聚合:用来对文档做分组
-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
-
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
-
Avg:求平均值
-
Max:求最大值
-
Min:求最小值
-
Stats:同时求max、min、avg、sum等
-
-
管道(pipeline)聚合:其它聚合的结果为基础做聚合
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
1.2.DSL实现聚合
现在,我们要统计所有数据中的酒店品牌有几种,其实就是按照品牌对数据分组。此时可以根据酒店品牌的名称做聚合,也就是Bucket聚合。
1.2.1.Bucket聚合语法
语法如下:
GET /hotel/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { // 定义聚合
"brandAgg": { //给聚合起个名字
"terms": { // 聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量
}
}
}
}结果如图:

1.2.2.聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为count,并且按照count降序排序。
我们可以指定order属性,自定义聚合的排序方式:
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"_count": "asc" // 按照_count升序排列
},
"size": 20
}
}
}
}1.2.3.限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,但真实场景下,用户会输入搜索条件,因此聚合必须是对搜索结果聚合。那么聚合必须添加限定条件。
我们可以限定要聚合的文档范围,只要添加query条件即可:
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200 // 只对200元以下的文档聚合
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}这次,聚合得到的品牌明显变少了:

1.2.4.Metric聚合语法
上节课,我们对酒店按照品牌分组,形成了一个个桶。现在我们需要对桶内的酒店做运算,获取每个品牌的用户评分的min、max、avg等值。
这就要用到Metric聚合了,例如stat聚合:就可以获取min、max、avg等结果。
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
},
"aggs": { // 是brands聚合的子聚合,也就是分组后对每组分别计算
"score_stats": { // 聚合名称
"stats": { // 聚合类型,这里stats可以计算min、max、avg等
"field": "score" // 聚合字段,这里是score
}
}
}
}
}
}这次的score_stats聚合是在brandAgg的聚合内部嵌套的子聚合。因为我们需要在每个桶分别计算。
另外,我们还可以给聚合结果做个排序,例如按照每个桶的酒店平均分做排序:
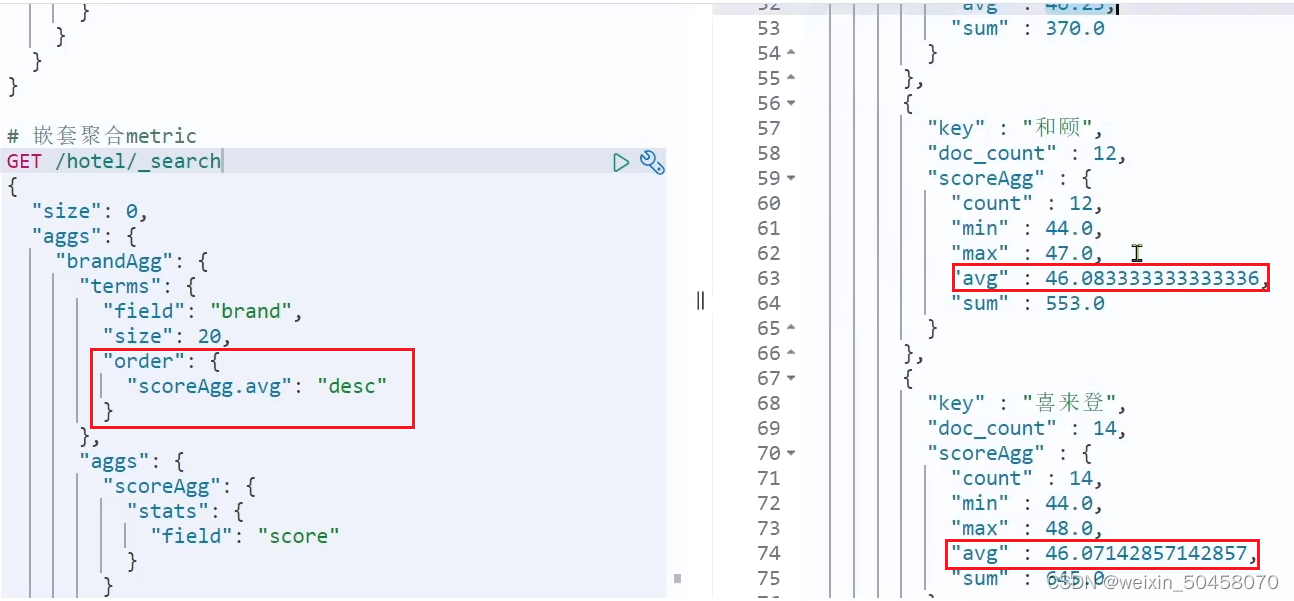
1.2.5.小结
aggs代表聚合,与query同级,此时query的作用是?
限定聚合的的文档范围
聚合必须的三要素:
聚合名称
聚合类型
聚合字段
聚合可配置属性有:
size:指定聚合结果数量
order:指定聚合结果排序方式
field:指定聚合字段
1.3.RestAPI实现聚合
1.3.1.API语法
聚合条件与query条件同级别,因此需要使用request.source()来指定聚合条件。
聚合条件的语法:
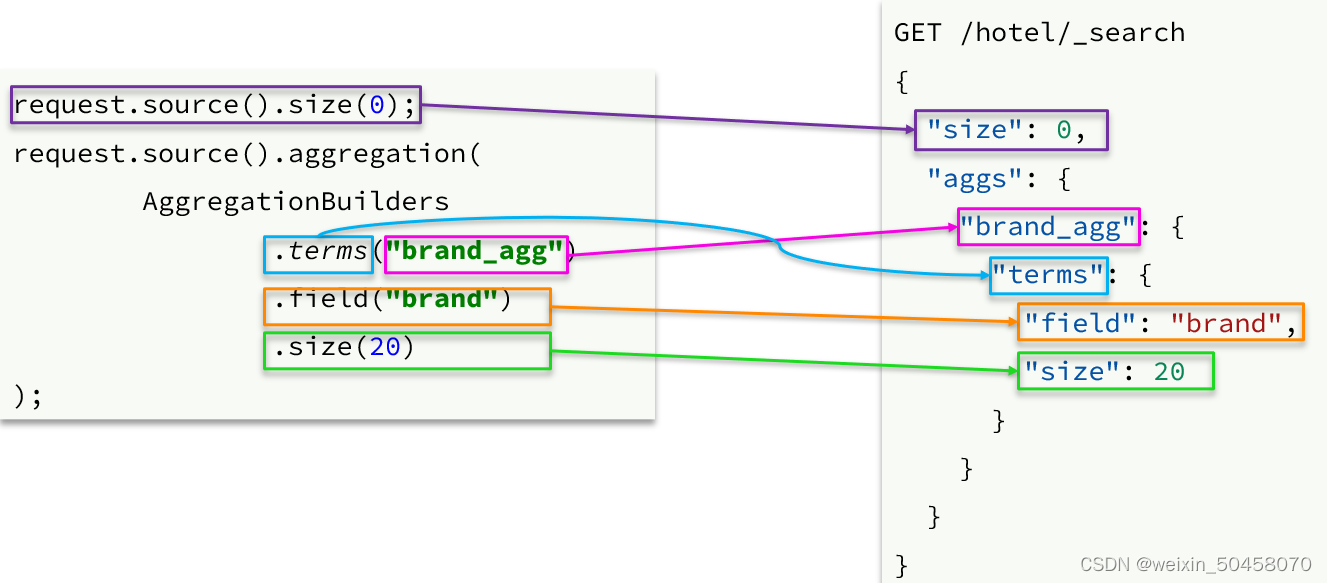
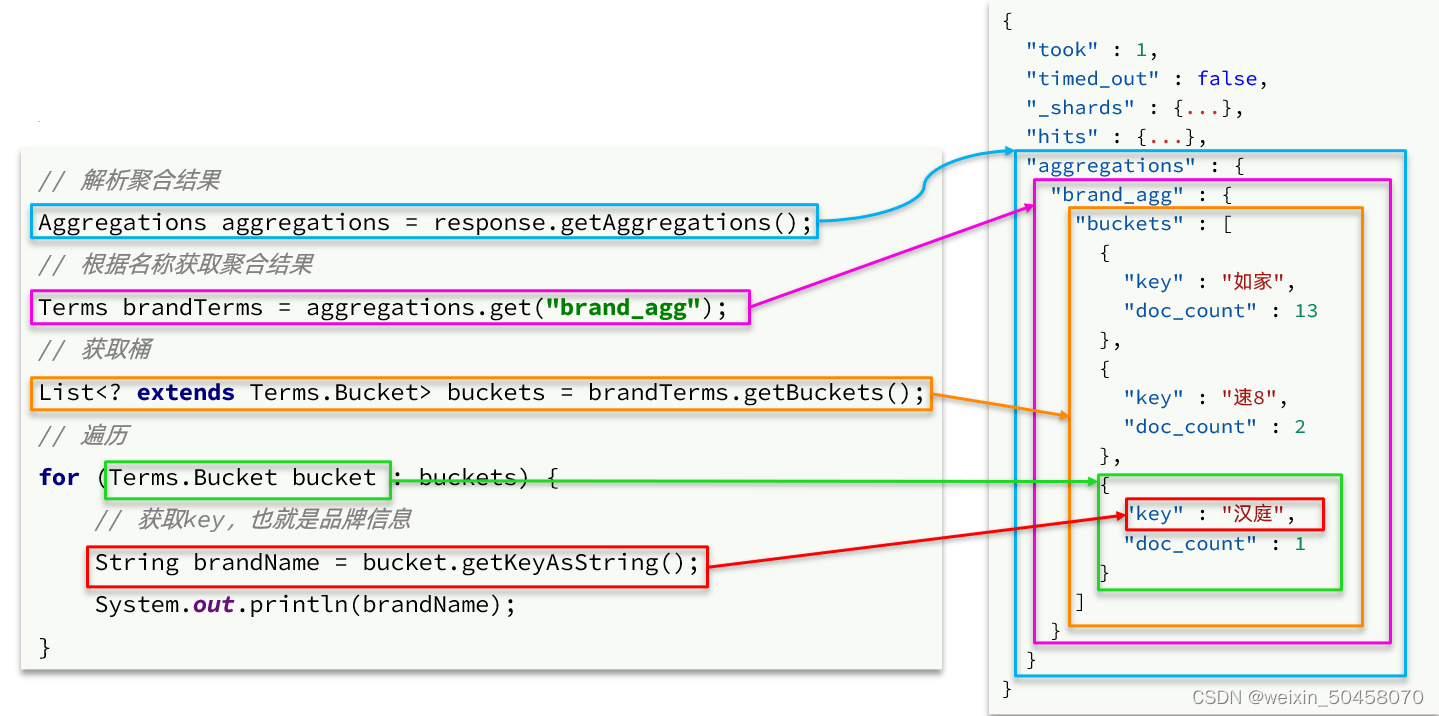
聚合的结果也与查询结果不同,API也比较特殊。不过同样是JSON逐层解析:
1.3.2.业务需求
需求:搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的:
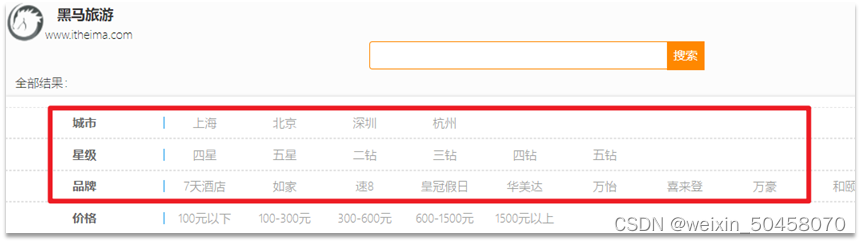
使用聚合功能,利用Bucket聚合,对搜索结果中的文档基于品牌分组、基于城市分组,就能得知包含哪些品牌、哪些城市了。
因为是对搜索结果聚合,因此聚合是限定范围的聚合,也就是说聚合的限定条件跟搜索文档的条件一致。
查看浏览器可以发现,前端其实已经发出了这样的一个请求:

请求参数与搜索文档的参数完全一致。
返回值类型就是页面要展示的最终结果:
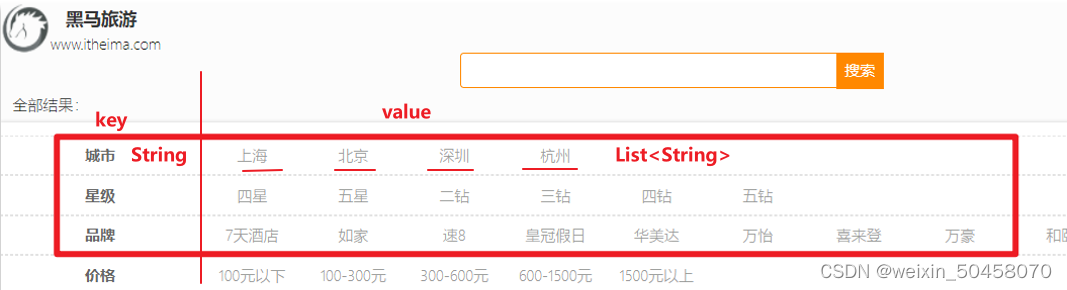
结果是一个Map结构:
-
key是字符串,城市、星级、品牌、价格
-
value是集合,例如多个城市的名称
1.3.3.业务实现
-
请求方式:
POST -
请求路径:
/hotel/filters -
请求参数:
RequestParams,与搜索文档的参数一致 -
返回值类型:
Map<String, List<String>>
代码:
@PostMapping("filters")public Map<String, List<String>> getFilters(@RequestBody RequestParams params){return hotelService.getFilters(params);}这里调用了IHotelService中的getFilters方法,尚未实现。
在IHotelService中定义新方法:
Map<String, List<String>> filters(RequestParams params);在impl.HotelService中实现该方法:
@Override
public Map<String, List<String>> filters(RequestParams params) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备DSL// 2.1.querybuildBasicQuery(params, request);// 2.2.设置sizerequest.source().size(0);// 2.3.聚合buildAggregation(request);// 3.发出请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析结果Map<String, List<String>> result = new HashMap<>();Aggregations aggregations = response.getAggregations();// 4.1.根据品牌名称,获取品牌结果List<String> brandList = getAggByName(aggregations, "brandAgg");result.put("品牌", brandList);// 4.2.根据品牌名称,获取品牌结果List<String> cityList = getAggByName(aggregations, "cityAgg");result.put("城市", cityList);// 4.3.根据品牌名称,获取品牌结果List<String> starList = getAggByName(aggregations, "starAgg");result.put("星级", starList);return result;} catch (IOException e) {throw new RuntimeException(e);}
}private void buildAggregation(SearchRequest request) {request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(100));
}private List<String> getAggByName(Aggregations aggregations, String aggName) {// 4.1.根据聚合名称获取聚合结果Terms brandTerms = aggregations.get(aggName);// 4.2.获取bucketsList<? extends Terms.Bucket> buckets = brandTerms.getBuckets();// 4.3.遍历List<String> brandList = new ArrayList<>();for (Terms.Bucket bucket : buckets) {// 4.4.获取keyString key = bucket.getKeyAsString();brandList.add(key);}return brandList;
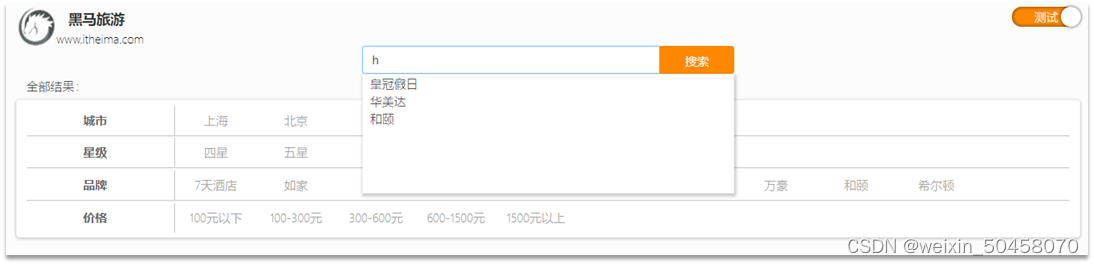
}2.自动补全
当用户在搜索框输入字符时,我们应该提示出与该字符有关的搜索项,如图:
相关文章:
分布式搜索引擎03
1.数据聚合 聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如: 什么品牌的手机最受欢迎? 这些手机的平均价格、最高价格、最低价格? 这些手机每月的销售情况如何? 实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近…...
flex布局的flex为1到底是什么
参考博客:flex:1什么意思_公孙元二的博客-CSDN博客 flex:1即为flex-grow:1,经常用作自适应布局,将父容器的display:flex,侧边栏大小固定后,将内容区flex:1,内…...

class050 双指针技巧与相关题目【算法】
class050 双指针技巧与相关题目【算法】 算法讲解050【必备】双指针技巧与相关题目 code1 922. 按奇偶排序数组 II // 按奇偶排序数组II // 给定一个非负整数数组 nums。nums 中一半整数是奇数 ,一半整数是偶数 // 对数组进行排序,以便当 nums[i] 为…...

计算机操作系统4
1.什么是进程同步 2.什么是进程互斥 3.进程互斥的实现方法(软件) 4.进程互斥的实现方法(硬件) 5.遵循原则 6.总结: 线程是一个基本的cpu执行单元,也是程序执行流的最小单位。 调度算法:先来先服务FCFS、短作业优先、高响应比优先、时间片…...

【ASP.NET CORE】EntityFrameworkCore 数据迁移
如果数据库中已经有数据结构,可以使用Scaffold-DbContext来同步model,-connection是字符串,-outputdir 是输入文件夹名称,举例的脚本使用的是sqlserver数据库 通用 Scaffold-DbContext -Connection "DatabaseAddress;Data …...

说说React jsx转换成真实DOM的过程?
在React中,JSX(JavaScript XML)是一种语法糖,用于描述用户界面的结构和组件关系。当你编写React组件并包含JS JSX解析:React中的JSX代码首先会被解析成JavaScript对象。这个过程通常是通过Babel等工具进行的࿰…...
MongoDB知识总结
这里写自定义目录标题 MongoDB基本介绍MongoDB基本操作数据库相关集合相关增删改查 MongoDB基本介绍 简单介绍 MongoDB是一个基于分布式文件存储的数据库。由C语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。 MongoDB是一个介于关系数据库和非关系数据库之间的产…...

【LeeCode】1.两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你可以按任意顺序返回…...

Python 作业答疑_6.15~6.18
一、Python 一班 1. 比较字符串 1.1 问题描述 比较两个字符串A和B,字符串A和B中的字符都是大写字母,确定A中是否包含B中所有的字符。 1.2 问题示例 例如,给出A"ABCD",B"ACD",返回True&#x…...

Diffusion 公式推导
Diffusion:通过扩散和逆扩散过程生成图像的生成式模型 中已经对 diffusion 的原理进行了直观地梳理,本文对其中的数学推导进行讲解,还是基于 DDPM。 目录 一. 预备知识1. 重参数技巧2. 高斯分布的可加性3. 扩散递推式的由来 二. 扩散过程1. 背…...

【C语言快速学习基础篇】之一基础类型、进制转换、数据位宽
文章目录 一、基础类型(根据系统不同占用字节数会有变化)1.1、有符号整形1.2、无符号整形1.3、字符型1.4、浮点型1.5、布尔型 二、进制转换2.1、二进制2.2、八进制2.3、十进制2.4、十六进制2.5、N进制2.6、进制转换关系对应表 三、数据位宽3.1、位3.2、字节3.3、字3.4、双字3.5…...
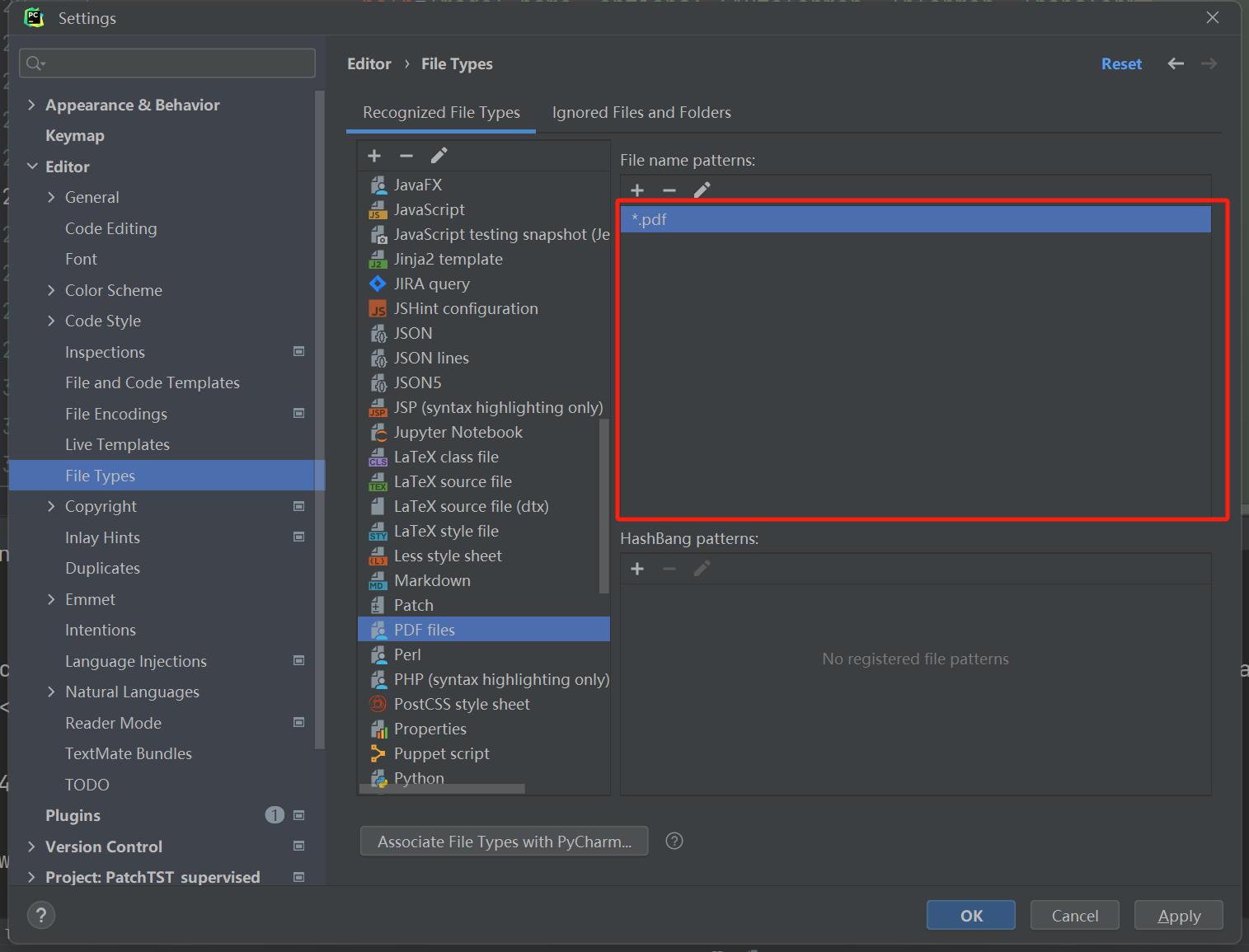
使用GPT-4V解决Pycharm设置问题
pycharm如何实现关联,用中文回答 在PyCharm中关联PDF文件类型,您可以按照以下步骤操作: 1. 打开PyCharm设置:点击菜单栏中的“File”(文件),然后选择“Settings”(设置)。…...

qt 安装
目录 前言 一、QT在线安装包下载 1.官方网站: 2.镜像(清华大学) 二、QT安装 1.更换安装源 2.安装界面 3.组件选择(重点) 参考 Qt2023新版保姆级 安装教程 前言 本文主要介绍2023新版QT安装过程,…...
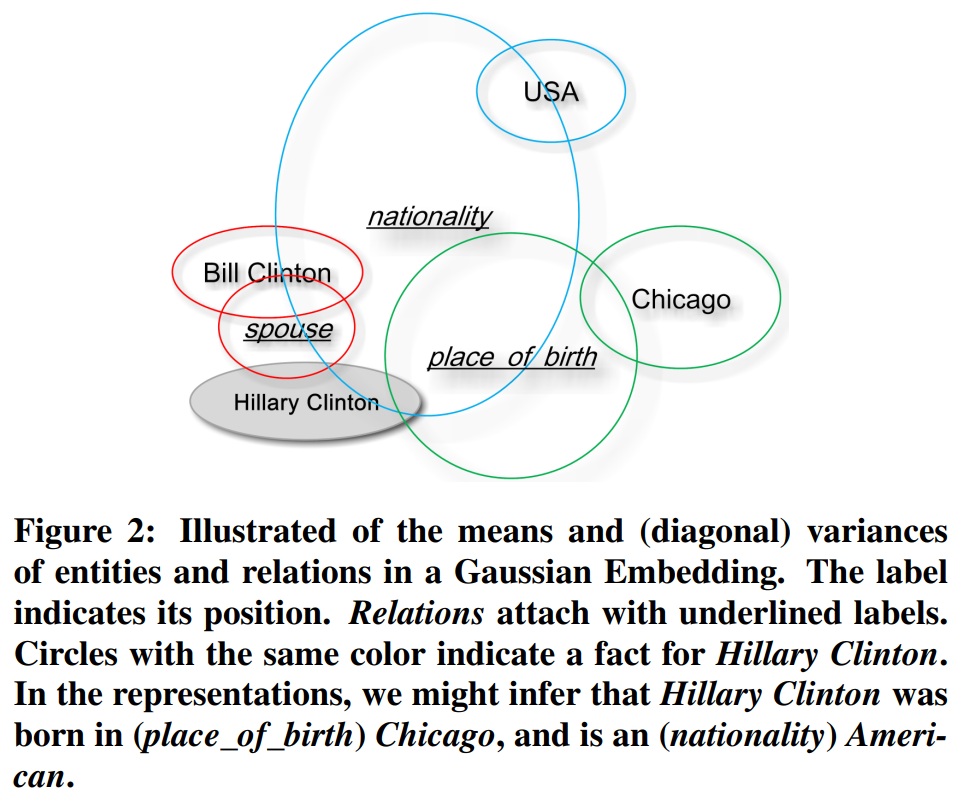
【论文合集】在非欧空间中的图嵌入方法(Graph Embedding in Non-Euclidean Space)
文章目录 1. Hyperbolic Models1.1 Hyperbolic Graph Attention Network1.2 Poincar Embeddings for Learning Hierarchical Representations.1.3 Learning Continuous Hierarchies in the Lorentz Model of Hyperbolic Geometry1.4 Hyperbolic Graph Convolutional Neural Net…...
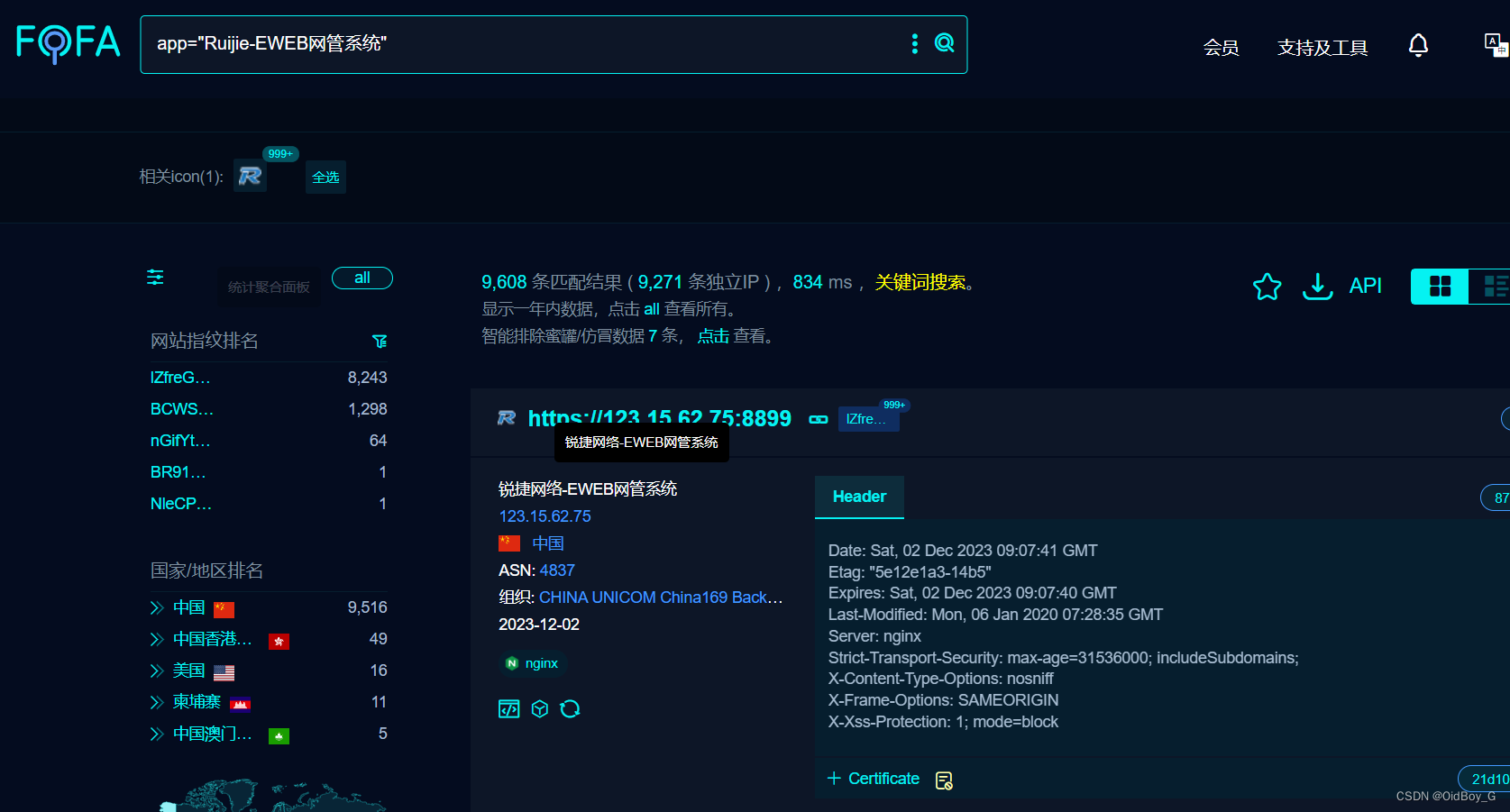
锐捷EWEB网管系统 RCE漏洞复现
0x01 产品简介 锐捷网管系统是由北京锐捷数据时代科技有限公司开发的新一代基于云的网络管理软件,以“数据时代创新网管与信息安全”为口号,定位于终端安全、IT运营及企业服务化管理统一解决方案。 0x02 漏洞概述 Ruijie-EWEB 网管系统 flwo.control.php 中的 type 参数存在…...

Clickhouse在货品标签场景的应用
背景 在电商场景中,我们经常需要对货品进行打标签的操作,简单来说就是对货品进行各种分类,按照价格段进行分组,此时运营人员就可以通过价格段捞取到满足条件的商品了,本文就来简单看下这个场景如何在clickhouse中实现…...

CentOS 7 lvm 更换坏盘操作步骤小记 —— 筑梦之路
背景介绍 硬盘容量不足、硬盘坏道太多等不可控的原因需要更换,要求不能丢失数据进行无损替换硬盘。 操作步骤 1. 将硬盘插入机器,上电连接到服务器 2. 在centos 7 系统中检测是否识别出来硬盘 lsblk 3. 给新插入的硬盘分区 parted /dev/sdc mklabel g…...

zabbix的自动发现和注册、proxy代理和SNMP监控
目录 一、zabbix自动发现与自动注册机制: 1、概念 2、zabbix 自动发现与自动注册的部署 二、zabbix的proxy代理功能: 1、工作流程 2、安装部署 三、zabbix-snmp 监控 1、概念 2、安装部署 四、总结: 一、zabbix自动发现与自动注册…...

以Hub为中心节点的网络技术探析
在计算机网络中,Hub是一个重要的组成部分,它作为中心节点,连接着各个站点,实现数据的传输和通信。本文将对以Hub为中心节点的网络进行深入的技术探析。 首先,我们需要了解什么是Hub。在网络术语中,Hub通常…...

百度推送收录工具-免费的各大搜索引擎推送工具
在互联网时代,网站收录是网站建设的重要一环。百度推送工具作为一种提高网站收录速度的方式备受关注。在这个信息爆炸的时代,对于网站管理员和站长们来说,了解并使用一些百度推送工具是非常重要的。本文将重点分享百度批量域名推送工具和百度…...

3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略
3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 想要快速获取网易云音乐和QQ音乐的歌词吗?1…...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...

深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化
深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish是《环世界》(Rim…...

深度学习图像风格迁移:从Gatys算法到PyTorch工程实践
1. 项目概述:一个基于深度学习的图像风格迁移应用最近在GitHub上闲逛,发现了一个名为“aristoapp/DDalkkak”的项目。单看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于图像风格迁移(Image S…...

告别网络依赖:CircuitJS1桌面版带你体验离线电路仿真的自由
告别网络依赖:CircuitJS1桌面版带你体验离线电路仿真的自由 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circuitjs1…...

基于Claude API构建AI代码生成工具:从API封装到工程化实践
1. 项目概述与核心价值最近在开发者社区里,一个名为ashish200729/claude-code-source-code的项目标题引起了不小的讨论。乍一看,这个标题很容易让人产生误解,以为这是某个知名AI模型的源代码被公开了。但作为一名在软件开发和开源领域摸爬滚打…...

蜘蛛池技术解析:网站收录提速的关键工具与运营策略
在搜索引擎优化领域,蜘蛛池是助力网站收录提速的重要辅助工具,尤其适配新站、低权重站或海量内容站,能有效破解收录慢、收录少、深层页面难抓取等痛点。本文从技术原理、核心价值、搭建要点及合规运营策略四方面,全面解析蜘蛛池的…...

智能游戏助手:League Akari如何彻底改变你的英雄联盟体验
智能游戏助手:League Akari如何彻底改变你的英雄联盟体验 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾在英雄选择阶段手…...

知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧
知乎API完全指南:用Python轻松获取知乎数据的5个核心技巧 【免费下载链接】zhihu-api Zhihu API for Humans 项目地址: https://gitcode.com/gh_mirrors/zh/zhihu-api 在当今数据驱动的时代,知乎数据采集和Python API开发已成为获取高质量中文知识…...

深度解析VS Code Live Server:高效前端开发实时预览配置秘籍
深度解析VS Code Live Server:高效前端开发实时预览配置秘籍 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-serv…...