Kafka中的auto-offset-reset配置
Kafka这个服务在启动时会依赖于Zookeeper,Kafka相关的部分数据也会存储在Zookeeper中。如果kafka或者Zookeeper中存在脏数据的话(即错误数据),这个时候虽然生产者可以正常生产消息,但是消费者会出现无法正常消费消息的情况。
所以在进行下述这个案例进行测试时,为了避免一些错误,可以将两个镜像服务全部进行重装,重装的镜像服务由于未设定数据存储方式(即采用非持久化的匿名数据卷),所以在重装以后会采用新的匿名数据卷,是一个全新的配置信息。
PS:同样是MQ,相比较而言,RabbitMQ针对异常情况的兼容处理比Kafka要好很多,使用Kafka需要有很丰富的经验,生产环境非必要不建议使用这个。
1、earliest
Windosw环境下面使用下述两个命令重装Zookeeper和Kafka:
docker run -d --name zookeeper -p 2181:2181 -t zookeeper:latestdocker run -d --name kafka -p 9092:9092 -e KAFKA_ZOOKEEPER_CONNECT=192.168.1.15:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.1.15:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -e TZ="Asia/Shanghai" wurstmeister/kafka:latest假设前面的环境准备我已经完成了,现在正式进入案例测试流程。当前kafka的版本为2.8.11,Spring Boot的版本为2.7.6,在pom.xml中引入下述依赖:
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.8.11</version>
</dependency>然后在yml配置文件进行如下配置:
spring:kafka:bootstrap-servers: 127.0.0.1:9092consumer:group-id: 0key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerauto-offset-reset: earliestproducer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer在项目中创建一个生产者用于往主题topic0中投递消息,如下所示:
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@Slf4j
@RestController
@RequestMapping("/kafka")
public class KafkaProducer {// 自定义的主题名称public static final String TOPIC_NAME="topic0";@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;@RequestMapping("/send")public String send(@RequestParam("msg")String msg) {log.info("准备发送消息为:{}",msg);// 1.发送消息ListenableFuture<SendResult<String,String>> future=kafkaTemplate.send(TOPIC_NAME,msg);future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {@Overridepublic void onFailure(Throwable throwable) {// 2.发送失败的处理log.error("生产者 发送消息失败:"+throwable.getMessage());}@Overridepublic void onSuccess(SendResult<String, String> stringObjectSendResult) {// 3.发送成功的处理log.info("生产者 发送消息成功:"+stringObjectSendResult.toString());}});return "接口调用成功";}
}项目启动以后,如果Kafka中没有topic0这个主题,那么在利用上述接口首次往Kafka中投递消息时会创建这个主题。此处利用 /kafka/send?msg=xxx 接口往主题topic0中生产10条消息,接着再在项目中创建一个消费者用于消息主题topic0中的消息,如下所示:
import java.util.Optional;import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;@Slf4j
@Component
public class KafkaConsumer {// 自定义topicpublic static final String TOPIC_NAME="topic0";@KafkaListener(topics = TOPIC_NAME, groupId = "ONE")public void topic_one(ConsumerRecord<?, ?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {Optional message = Optional.ofNullable(record.value());if (message.isPresent()) {Object msg = message.get();log.info("消费者One消费了消息:Topic:" + topic + ",Record:" + record + ",Message:" + msg);}}
}然后再重启整个项目, 这时控制台中会打印下述信息,消费者One消费了10条之前投递的消息:
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 0, CreateTime = 1701261195020, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 1),Message:1
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 1, CreateTime = 1701261203540, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 2),Message:2
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 2, CreateTime = 1701261211937, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 3),Message:3
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 3, CreateTime = 1701261429324, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 4),Message:4
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 4, CreateTime = 1701261435706, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 5),Message:5
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 5, CreateTime = 1701261439877, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 6),Message:6
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 6, CreateTime = 1701261444315, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 7),Message:7
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 7, CreateTime = 1701261448213, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 8),Message:8
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 8, CreateTime = 1701261455452, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 9),Message:9
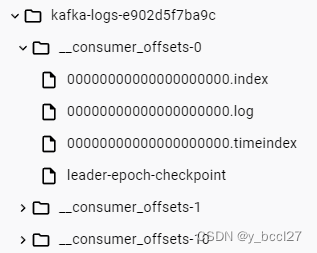
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 9, CreateTime = 1701261459889, serialized key size = -1, serialized value size = 2, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 10),Message:10同时在Kafka服务的日志文件目录中会产生一些记录消息被消费到的偏移量文件,在消息没有被消费之前,是不会产生类似于 __consumer_offsets_x 的文件,如下图所示:
2、latest
再次重装Zookeeper和Kafka,并清空Zookeeper和Kafka中的数据,将上述yml文件中的 auto-offset-reset 配置修改为latest,如下所示:
spring:kafka:bootstrap-servers: 127.0.0.1:9092consumer:group-id: 0key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerauto-offset-reset: latestproducer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer然后屏蔽掉消费者消费消息的监听类,重启整个项目,再次调用 /kafka/send?msg=xxx 接口往主题topic0中生产10条消息。 接着再将消费者消费消息的监听类放开,重启项目,这时可以看到消费者One并没有消费之前发送的10条消息,但是这时在Kafka服务的日志文件目录中会产生一些记录消息被消费到的偏移量文件,类似于 __consumer_offsets_x 的文件。
我们再次调用 /kafka/send?msg=11 接口往主题topic0中生产1条消息,这时控制台中会输出下述内容:
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 10, CreateTime = 1701311220521, serialized key size = -1, serialized value size = 2, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 11),Message:11
可以看到kafka中没有offset时,如果 auto-offset-reset 配置设置为latest,消费者会从最近的offset开始消费,就是新加入到主题中的消息才会被消费。
3、none
再次重装Zookeeper和Kafka,并清空Zookeeper和Kafka中的数据,将上述yml文件中的 auto-offset-reset 配置修改为none,如下所示:
spring:kafka:bootstrap-servers: 127.0.0.1:9092consumer:group-id: 0key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerauto-offset-reset: noneproducer:key-serializer: org.apache.kafka.common.serialization.StringSerializervalue-serializer: org.apache.kafka.common.serialization.StringSerializer然后屏蔽掉消费者消费消息的监听类,重启整个项目,再次调用 /kafka/send?msg=xxx 接口往主题topic0中生产10条消息。 接着再将消费者消费消息的监听类放开,重启项目,可以看到在项目重启过程中控制台中会报下述异常信息:
org.apache.kafka.clients.consumer.NoOffsetForPartitionException: Undefined offset with no reset policy for partitions: [主题名-xxx]虽然消费者One并没有消费之前发送的10条消息,但是在Kafka服务的日志文件目录中仍然也会产生一些记录消息被消费到的偏移量文件,类似于 __consumer_offsets_x 的文件。
同时通过日志打印信息,我们也可以看到由于异常,该消费者服务已经停止了,不能再消费新的消息。
Fatal consumer exception; stopping container所以我们再次调用/kafka/send?msg=11接口往主题topic0中生产1条消息,可以看到控制台是没有任何关于消费者消费消息的日志信息。PS:一般生产环境基本用不到该参数
4、默认配置
如果我们没有在yml文件中显式配置auto-offset-reset,那么其默认值为latest。
5、多个消费者组消费同一个主题,配置为earliest
再次重装Zookeeper和Kafka,并清空Zookeeper和Kafka中的数据,将上述yml文件中的 auto-offset-reset 配置修改为earliest, 构建两个消费者组One和Two来消费同一个主题中的消息:
import java.util.Optional;import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;@Slf4j
@Component
public class KafkaConsumer {// 自定义topicpublic static final String TOPIC_NAME="topic0";@KafkaListener(topics = TOPIC_NAME, groupId = "ONE")public void topic_one(ConsumerRecord<?, ?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {Optional message = Optional.ofNullable(record.value());if (message.isPresent()) {Object msg = message.get();log.info("消费者One消费了消息:Topic:" + topic + ",Record:" + record + ",Message:" + msg);}}@KafkaListener(topics = TOPIC_NAME, groupId = "TWO")public void topic_two(ConsumerRecord<?, ?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {Optional message = Optional.ofNullable(record.value());if (message.isPresent()) {Object msg = message.get();log.info("消费者TwO消费了: +++++++++++++++ Topic:" + topic + ",Record:" + record + ",Message:" + msg);}}
}屏蔽两个消费者组,让它们暂时不监听主题 topic0,重启项目利用生产者往主题 topic0中投递三条消息。
打开消费者组One的屏蔽,重启项目可以看到消费者组One消费了3条数据:
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 0, CreateTime = 1701323282779, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 1),Message:1
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 1, CreateTime = 1701323286219, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 2),Message:2
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 2, CreateTime = 1701323289105, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 3),Message:3
然后打开消费者组Two的屏蔽,重启项目可以看到消费者组Two也消费了3条数据:
消费者TwO消费了: +++++++++++++++ Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 0, CreateTime = 1701323282779, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 1),Message:1
消费者TwO消费了: +++++++++++++++ Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 1, CreateTime = 1701323286219, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 2),Message:2
消费者TwO消费了: +++++++++++++++ Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 2, CreateTime = 1701323289105, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 3),Message:3
所以在Kafka服务的日志文件目录中产生的偏移量文件(__consumer_offsets_x ),针对的是每一个消费者组而言,它记录的是某一个消费者组已经消费到的消息偏移量。
6、多个消费者组消费同一个主题消息,其中一个消费者组没有偏移量
再次重装Zookeeper和Kafka,并清空Zookeeper和Kafka中的数据,构建两个消费者组One和Two来消费同一个主题中的消息:
import java.util.Optional;import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Component;@Slf4j
@Component
public class KafkaConsumer {// 自定义topicpublic static final String TOPIC_NAME="topic0";@KafkaListener(topics = TOPIC_NAME, groupId = "ONE")public void topic_one(ConsumerRecord<?, ?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {Optional message = Optional.ofNullable(record.value());if (message.isPresent()) {Object msg = message.get();log.info("消费者One消费了消息:Topic:" + topic + ",Record:" + record + ",Message:" + msg);}}@KafkaListener(topics = TOPIC_NAME, groupId = "TWO")public void topic_two(ConsumerRecord<?, ?> record, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {Optional message = Optional.ofNullable(record.value());if (message.isPresent()) {Object msg = message.get();log.info("消费者TwO消费了: +++++++++++++++ Topic:" + topic + ",Record:" + record + ",Message:" + msg);}}
}在yml文件中不配置auto-offset-reset(即采用默认配置),打开消费者组One的监听,屏蔽消费者组Two的监听。
重启项目利用生产者往主题 topic0中投递三条消息,消费者组0ne立马消费了三条消息:
准备发送消息为:1
生产者 发送消息成功:SendResult [producerRecord=ProducerRecord(topic=topic0, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=null, value=1, timestamp=null), recordMetadata=topic0-0@0]
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 0, CreateTime = 1701324482632, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 1),Message:1
准备发送消息为:2
生产者 发送消息成功:SendResult [producerRecord=ProducerRecord(topic=topic0, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=null, value=2, timestamp=null), recordMetadata=topic0-0@1]
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 1, CreateTime = 1701324485351, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 2),Message:2
准备发送消息为:3
生产者 发送消息成功:SendResult [producerRecord=ProducerRecord(topic=topic0, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=null, value=3, timestamp=null), recordMetadata=topic0-0@2]
消费者One消费了消息:Topic:topic0,Record:ConsumerRecord(topic = topic0, partition = 0, leaderEpoch = 0, offset = 2, CreateTime = 1701324488104, serialized key size = -1, serialized value size = 1, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = 3),Message:3
这时再在yml文件中配置auto-offset-reset为None,打开消费者Two的屏蔽,然后重启项目这个时候会发现由于消费者组Two没有记录偏移量,所以在项目启动的过程中会报下述异常信息,该消费者组服务会停止监听:
Fatal consumer exception; stopping container
App info kafka.consumer for consumer-TWO-2 unregistered7、总结
做了上述这么多的案例测试,各个消费者组都是按照预期去消费主题消息,其它情况的预期结果的原理都是一样的。
如果kafka服务器记录有消费者消费到的offset,那么消费者会从该offset开始消费。如果Kafka中没有初始偏移量,或者当前偏移量在服务器上不再存在(例如,因为该数据已被删除),那么这时 auto.offset.reset 配置项就会起作用。
- earliest:从最早的offset开始消费,就是partition的起始位置开始消费
- latest:从最近的offset开始消费,就是新加入partition的消息才会被消费
- none:服务启动时会抛出异常,消费者服务会停止
相关文章:
Kafka中的auto-offset-reset配置
Kafka这个服务在启动时会依赖于Zookeeper,Kafka相关的部分数据也会存储在Zookeeper中。如果kafka或者Zookeeper中存在脏数据的话(即错误数据),这个时候虽然生产者可以正常生产消息,但是消费者会出现无法正常消费消息的…...

TCP/IP_整理起因
先分享一个初级的问题;有个客户现场,终端设备使用客户网络更新很慢,使用手机热点更新速度符合预期;网络部署情况如下: 前期花费了很大的精力进行问题排查对比,怀疑是客户网络问题(其他的客户现…...

CG-0A 电子水尺水导电测量原理应用于道路积水监测
CG-0A 电子水尺水导电测量原理应用于道路积水监测产品概述 本产品是一种采用微处理器芯片为控制器,内置通讯电路的数字式水位传感器,具备高的可靠性及抗干扰性能。适用于江、河、湖、水库及蓄水池、水渠等处的水位测量使用。 本产品采用了生产工艺技术…...

openEuler JDK21 部署 Zookeeper 集群
zookeeper-jdk21 操作系统:openEuler JDK:21 主机名IP地址spark01192.168.171.101spark02192.168.171.102spark03192.168.171.103 安装 1. 升级内核和软件 yum -y update2. 安装常用软件 yum -y install gcc gcc-c autoconf automake cmake make \zl…...

前端——html拖拽原理
文章目录 ⭐前言⭐draggable属性💖 api💖 单向拖动示例💖 双向拖动示例 ⭐总结⭐结束 ⭐前言 大家好,我是yma16,本文分享关于 前端——html拖拽原理。 vue3系列相关文章: vue3 fastapi 实现选择目录所有文…...
JVM 执行引擎篇
机器码、指令、汇编语言 机器码 各种用二进制编码方式表示的指令,叫做机器指令码。开始,人们就用它采编写程序,这就是机器语言。机器语言虽然能够被计算机理解和接受,但和人们的语言差别太大,不易被人们理解和记忆&a…...

js中数组对象去重的方法
前端面试题库 (面试必备) 推荐:★★★★★ 地址:前端面试题库 最近工作中需要用到数组对象去重的方法,我是怎么想也没想出来,今天稍微研究了一下,总算找到了2种方法。分享一下&…...

【送书活动四期】被GitHub 要求强制开启 2FA 双重身份验证,我该怎么办?
记得是因为fork了OpenZeppelin/openzeppelin-contracts的项目,之后就被GitHub 要求强制开启 2FA 双重身份验证了,一拖再拖,再过几天帐户操作将受到限制了,只能去搞一下了 目录 2FA是什么为什么要开启 2FA 验证GitHub 欲在整个平台…...
)
GO设计模式——13、享元模式(结构型)
目录 享元模式(Flyweight Pattern) 享元模式的核心角色: 优缺点 使用场景 注意事项 代码实现 享元模式(Flyweight Pattern) 享元模式(Flyweight Pattern)它通过共享对象来减少内存使用和提…...
Linux 网络协议
1 网络基础 1.1 网络概念 网络是一组计算机或者网络设备通过有形的线缆或者无形的媒介如无线,连接起来,按照一定的规则,进行通讯的集合( 缺一不可 )。 5G的来临以及IPv6的不断普及,能够进行联网的设备将会是越来越多(…...
【C语言】7-32 刮刮彩票 分数 20
7-32 刮刮彩票 分数 20 全屏浏览题目 切换布局 作者 DAI, Longao 单位 杭州百腾教育科技有限公司 “刮刮彩票”是一款网络游戏里面的一个小游戏。如图所示: 每次游戏玩家会拿到一张彩票,上面会有 9 个数字,分别为数字 1 到数字 9…...
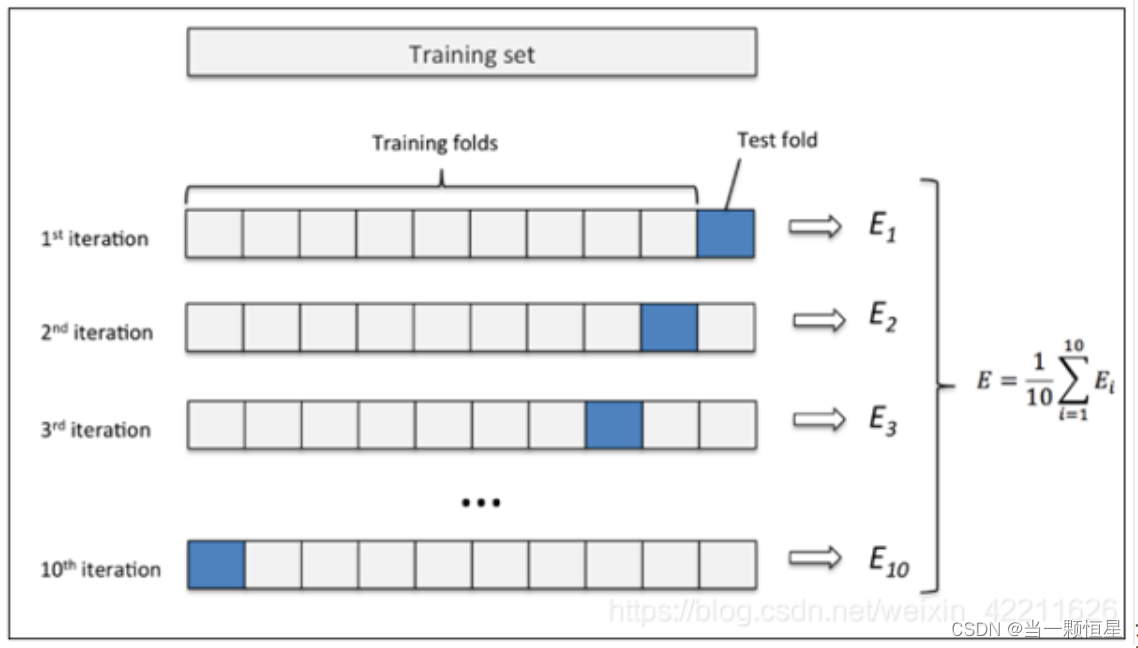
交叉验证以及scikit-learn实现
交叉验证 交叉验证既可以解决数据集的数据量不够大问题,也可以解决参数调优的问题。 主要有三种方式: 简单交叉验证(HoldOut检验)、k折交叉验证(k-fold交叉验证)、自助法。 本文仅针对k折交叉验证做详细解…...

css实现头部占一定高度,内容区占剩余高度可滚动
上下布局: <div class"container"><header class"header">头部内容</header><div class"content">内容区域</div> </div>.container {display: flex;flex-direction: column;height: 100vh; /*…...

redis主从复制模式和哨兵机制
目录 第一章、主从复制模式1.1)Redis 主从复制模式介绍1.2)Redis 主从复制实现、 第二章、哨兵机制2.1)容灾处理之哨兵2.2)Sentinel 配置 第一章、主从复制模式 1.1)Redis 主从复制模式介绍 ①单点故障:数…...

WebStorm:Mac/Win上强大的JavaScript开发工具
WebStorm是JetBrains公司开发的针对Mac和Windows系统的JavaScript开发工具。它为开发者提供了一站式的代码编辑、调试、测试和版本控制等功能,帮助你更高效地进行Web开发。新版本的WebStorm 2023在性能和用户体验方面都做出了重大改进,让你的JavaScript开…...

传世SUN引擎如何安装
大家在搭建的时候一定要理清思路一步一步来,否则一步错步步错。下面跟大家说一下搭建的顺序以及细节。 第一步:首先下载DBC2000进行安装,并按照里面的说明设置好。1、请把压缩包释放到D:\QMirServer目录下。2、在控制面板里找到BDC Administ…...

vue 生命周期
什么是生命周期,有什么作用 定义:vue 实例从创建到销毁的过程,在某个特定的位置会触发一个回调函数 作用:供开发者在生命周期的特定阶段执行相关的操作 生命周期分别有几个阶段 有四个阶段,每个阶段有两个钩子&…...

多开工具对应用程序性能的影响与优化
多开工具对应用程序性能的影响与优化 摘要: 随着计算机技术的不断发展,多开工具逐渐成为一种常见的软件应用。然而,使用多开工具可能会对应用程序的性能产生一定的影响。本文将探讨多开工具对应用程序性能的影响,并提供一些优化方…...

G1 GC基本逻辑
1 MixedGC基本过程 在G1GC中,有两种主要的垃圾回收过程:Young GC和Mixed GC。这两者都是为了回收堆内存中的垃圾对象,但是他们关注的区域和工作方式有所不同。 Young GC: Young GC主要负责回收Young Generation(包括…...

nvidia安装出现7-zip crc error解决办法
解决办法:下载network版本,重新安装。(选择自己需要的版本) 网址:CUDA Toolkit 12.3 Update 1 Downloads | NVIDIA Developer 分析原因:local版本的安装包可能在下载过程中出现损坏。 本人尝试过全网说的…...

Godot游戏自动化构建与发布:基于GitHub Actions与Docker的CI/CD实践
1. 项目概述:当Godot遇上CI/CD如果你是一名独立游戏开发者,或者在一个小团队里负责Godot引擎的项目,那么“构建”和“部署”这两个词,大概率是你开发流程里最头疼的环节之一。手动导出项目到不同平台(Windows、Linux、…...

AI模型部署实战:基于FastAPI与Tauri构建OpenClaw模型GUI应用
1. 项目概述与核心价值最近在AI应用开发圈里,一个名为“GrahamMiranda-AI/openclaw-model-gui”的项目引起了我的注意。乍一看这个标题,它融合了“openclaw-model”和“gui”两个关键部分,这让我立刻联想到一个典型的场景:一个已经…...
技术解析与应用前景)
量子私有信息检索(QPIR)技术解析与应用前景
1. 量子私有信息检索技术概述量子私有信息检索(Quantum Private Information Retrieval, QPIR)是密码学领域的一项突破性技术,它允许用户从数据库中检索特定条目而不泄露被查询的是哪个条目。这项技术的核心价值在于解决了隐私保护与数据获取…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...

开源AI图像生成工具Dream-Creator:本地部署与Stable Diffusion实战指南
1. 项目概述:一个开源的AI图像生成与创作工具 最近在GitHub上闲逛,发现了一个挺有意思的项目叫“Dream-Creator”。光看名字,你可能会联想到一些AI绘画或者创意生成工具。没错,这确实是一个围绕AI图像生成的开源项目。作为一个在…...

KIVI开源工具箱:模块化设计赋能开发者效率提升
1. 项目概述:一个面向开发者的开源工具箱最近在GitHub上闲逛,发现了一个挺有意思的项目,叫KIVI。第一眼看到这个名字,我以为是某种新的UI框架或者设计系统,毕竟“KIVI”听起来有点像是“Kiwi”的变体,容易联…...

All in Token, 移动,电信,联通,阿里,百度,华为,字节,Token石油战争,Token经济,百度要“重写”AI价值度量
AI Agent的价值,应该怎么被衡量? 2026年,AI行业的标志性拐点是Agent(智能体)快速普及。Agent作为核心生产力载体,将AI从Chatbot聊天模式带进主动执行的办事时代。 这个时候,如果我们还用旧尺子…...

Git Worktree CLI工具:告别分支切换焦虑,实现高效并行开发
1. 项目概述与核心价值如果你和我一样,长期在多个Git分支间穿梭,同时维护着几个不同的功能特性或修复补丁,那你一定对那种在分支间反复切换、代码状态混乱、甚至不小心提交到错误分支的“切分支焦虑症”深有体会。传统的git checkout或git sw…...

FPGA与GPU在OSOS-ELM算法中的性能对比与优化
1. 项目概述在边缘计算和实时信号处理领域,极端学习机(ELM)因其独特的训练机制和高效的计算性能而备受关注。OSOS-ELM作为ELM的一种变体,通过在线顺序学习机制进一步提升了算法的实用性。这项研究聚焦于FPGA和GPU两种硬件平台在执行OSOS-ELM算法时的性能…...

2026运营经理学习数据分析对职场能力提升的影响
一、数据分析在运营管理中的核心价值数据分析能力帮助运营经理优化决策流程,通过数据驱动的方法提升业务效率。掌握用户行为分析、市场趋势预测等技能,能够更精准地制定运营策略。数据可视化工具(如Tableau、Power BI)的应用&…...