力扣labuladong一刷day30天二叉树
力扣labuladong一刷day30天二叉树
文章目录
- 力扣labuladong一刷day30天二叉树
- 一、654. 最大二叉树
- 二、105. 从前序与中序遍历序列构造二叉树
- 三、106. 从中序与后序遍历序列构造二叉树
- 四、889. 根据前序和后序遍历构造二叉树
一、654. 最大二叉树
题目链接:https://leetcode.cn/problems/maximum-binary-tree/
思路:采用分解问题的方法,先构造父节点再构造左右子节点,每次都在指定区间内搜索,找到最大值后构造父节点,再划分左右区间递归。
class Solution {public TreeNode constructMaximumBinaryTree(int[] nums) {return traverse(nums, 0, nums.length - 1);}TreeNode traverse(int[] nums, int left ,int right) {if (left > right) return null;int max = -1, index = -1;for (int i = left; i <= right; i++) {if (nums[i] > max) {max = nums[i];index = i;}}TreeNode root = new TreeNode(max);root.left = traverse(nums, left, index-1);root.right = traverse(nums, index+1, right);return root;}
}
二、105. 从前序与中序遍历序列构造二叉树
题目链接:https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/
思路:通过前序和中序构造二叉树,要维护好前序的区间以及中序的区间,先构造父节点再构造左右子节点,父节点是前序区间的left,左右子节点由递归返回。 此外要注意速度,想节省遍历中序数组寻找父节点索引的时间的话,可以使用map预先存储下来。
class Solution {Map<Integer, Integer> map = new HashMap<>();public TreeNode buildTree(int[] preorder, int[] inorder) {for (int i = 0; i < inorder.length; i++) {map.put(inorder[i], i);}return create(preorder, inorder, 0, preorder.length-1,0, inorder.length-1);}TreeNode create(int[] preorder, int[] inorder, int left1, int right1, int left2, int right2) {if (left1 > right1 || left2 > right2) return null;int midV = preorder[left1];TreeNode node = new TreeNode(midV);int index = map.get(midV);node.left = create(preorder, inorder, left1+1, left1+index-left2, left2, index-1);node.right = create(preorder, inorder, left1+index-left2+1, right1, index+1, right2);return node;}
}
三、106. 从中序与后序遍历序列构造二叉树
题目链接:https://leetcode.cn/problems/construct-binary-tree-from-inorder-and-postorder-traversal/
思路:本题和上题类似,也是先构造父节点,然后再构造左右子节点,父节点由后续right构造,然后划分中序和后序的区间,递归构造左右子树。
class Solution {Map<Integer, Integer> map = new HashMap<>();public TreeNode buildTree(int[] inorder, int[] postorder) {for (int i = 0; i < inorder.length; i++) {map.put(inorder[i], i);}return create(inorder, postorder, 0, inorder.length-1, 0, postorder.length-1);}TreeNode create(int[] inorder, int[] postorder, int left1, int right1, int left2, int right2) {if (left1 > right1 || left2 > right2) return null;int midV = postorder[right2];int index = map.get(midV);TreeNode node = new TreeNode(midV);node.left = create(inorder, postorder, left1, index-1, left2, left2+index-left1-1);node.right = create(inorder, postorder, index+1, right1, left2+index-left1, right2-1);return node;}
}
四、889. 根据前序和后序遍历构造二叉树
题目链接:https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-postorder-traversal/
思路:通过前序和后序去构造二叉树,构造的结果不唯一,但方法是一样的,每次使用前序的left做为父节点,left+1做为左孩子的值,然后使用这个去后序中去划分区间,然后在划分前序遍历的区间,之后递归构造即可。
class Solution {Map<Integer, Integer> map = new HashMap<>();public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {for (int i = 0; i < postorder.length; i++) {map.put(postorder[i], i);}return create(preorder, postorder, 0, preorder.length-1, 0, postorder.length-1);}TreeNode create(int[] preorder, int[] postorder, int left1, int right1, int left2, int right2) {if (left1>right1 || left2>right2) return null;if (left1 == right1) return new TreeNode(preorder[left1]);int mid = preorder[left1];int index = map.get(preorder[left1+1]);TreeNode node = new TreeNode(mid);node.left = create(preorder, postorder, left1+1, left1 + index-left2+1, left2,index);node.right = create(preorder, postorder, left1 + index-left2+2, right1,index+1, right2-1);return node;}
}
相关文章:

力扣labuladong一刷day30天二叉树
力扣labuladong一刷day30天二叉树 文章目录 力扣labuladong一刷day30天二叉树一、654. 最大二叉树二、105. 从前序与中序遍历序列构造二叉树三、106. 从中序与后序遍历序列构造二叉树四、889. 根据前序和后序遍历构造二叉树 一、654. 最大二叉树 题目链接:https://…...

【云原生-K8s】检查yaml文件安全配置kubesec部署及使用
基础介绍基础描述特点 部署在线下载百度网盘下载安装 使用官网样例yamlHTTP远程调用安全建议 总结 基础介绍 基础描述 Kubesec 是一个开源项目,旨在为 Kubernetes 提供安全特性。它提供了一组工具和插件,用于保护和管理在 Kubernetes 集群中的工作负载和…...

LeetCode力扣每日一题(Java):20、有效的括号
一、题目 二、解题思路 1、我的思路 我看到题目之后,想着这可能是力扣里唯一一道我能秒杀的题目了 于是一波操作猛如虎写出了如下代码 public boolean isValid(String s) {char[] c s.toCharArray();for(int i0;i<c.length;i){switch (c[i]){case (:if(c[i]…...
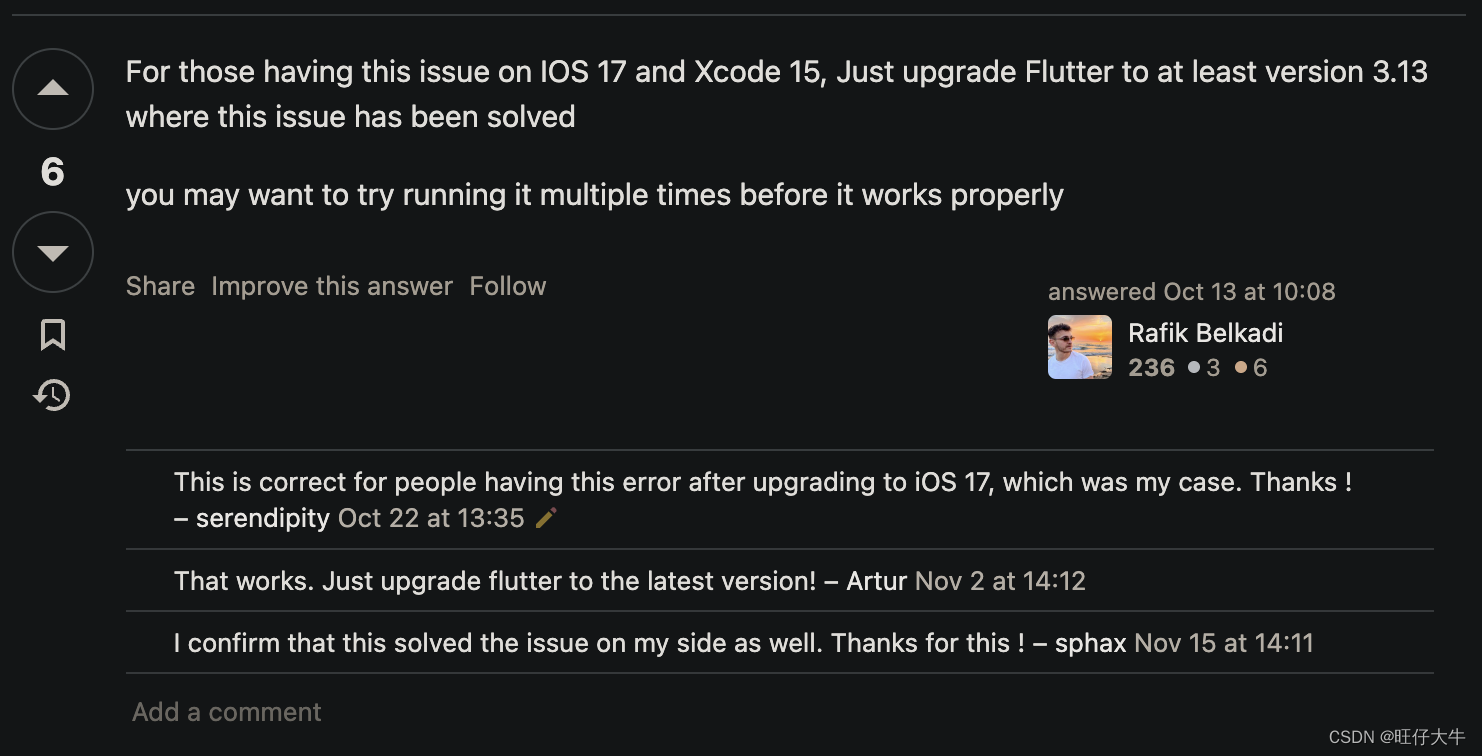
解决Flutter运行报错Could not run build/ios/iphoneos/Runner.app
错误场景 更新了IOS的系统版本为最新的17.0, 运行报以下错误 Launching lib/main.dart on iPhone in debug mode... Automatically signing iOS for device deployment using specified development team in Xcode project: GN3DCAF71C Running Xcode build... Xcode build d…...
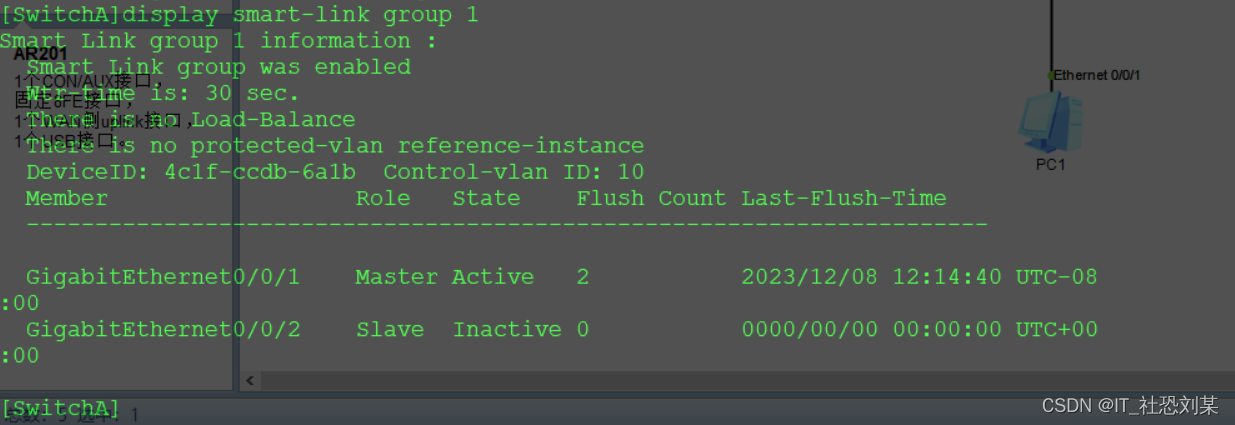
配置Smart Link主备备份示例
目录 实验拓扑 组网需求 配置思路 配置步骤 1.配置VLAN信息 2.在SwitchA上创建Smart Link备份组,并指定端口角色 3.使能回切功能并设置回切时间 4.使能发送Flush报文功能 5.使能接受Flush报文功能 验证配置结果 实验拓扑 组网需求 如上图所示,…...

03-微服务架构构建之微服务拆分
文章目录 前言一、微服务拆分的原则二、微服务拆分的时机三、微服务拆分的方法总结 前言 微服务架构是将一个单体应用程序拆分为一个个独立且保持松耦合的服务的一种架构方式,每个服务有着独立的数据库并且能独立运行部署。微服务架构的构建过程中,第一…...

Linus:我休假的时候也会带着电脑,否则会感觉很无聊
目录 Linux 内核最新版本动态 关于成为内核维护者 代码好写,人际关系难处理 内核维护者老龄化 内核中 Rust 的使用 关于 AI 的看法 参考 12.5-12.6 日,Linux 基金会组织的开源峰会(OSS,Open Source Summit)在日…...

快速排序的新用法
普通快排 简介 快速排序是一种高效的排序算法,利用分治的思想进行排序。它的基本原理是在待排序的n个数据中任取一个数据为分区标准,把所有小于该排序码的数据移到左边,把所有大于该排序码的数据移到右边,中间放所选记录&#x…...
利用乔拓云SAAS系统,快速、高效搭建小程序
a-service,软件即服务)系统来搭建他们的微信小程序。SAAS系统作为一种创新的软件应用模式,将软件作为一种服务提供给用户,为用户提供了更高效、更便捷的解决方案。本文将探讨为什么越来越多的商家选择使用乔拓云这种SAAS系统搭建小…...
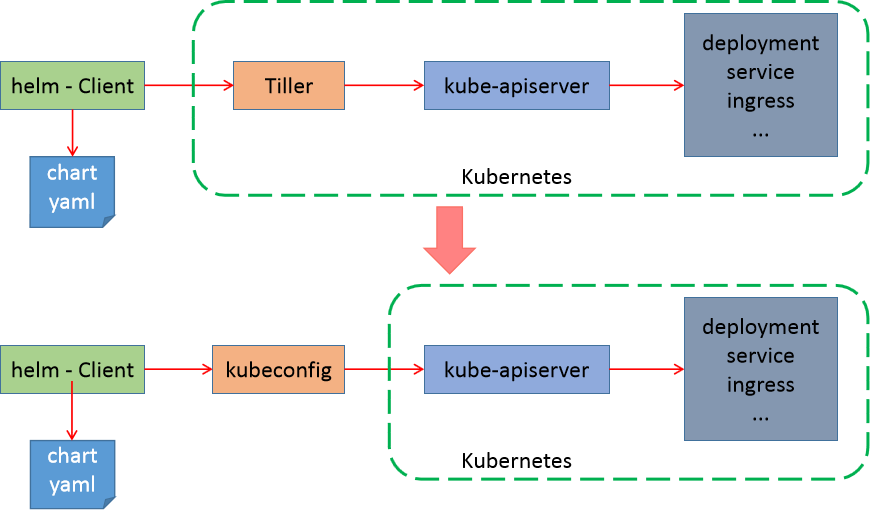
Kubernetes(K8s 1.27.x) 快速上手+实践,无废话纯享版
文章目录 1 基础知识1.1 K8s 有用么?1.2 K8s 是什么?1.3 k8s 部署方式1.4 k8s 环境解析 2 环境部署2.1 基础环境配置2.2 容器环境操作2.3 cri环境操作2.4 harbor仓库操作2.5 k8s集群初始化2.6 k8s环境收尾操作 3 应用部署3.1 应用管理解读3.2 应用部署实…...

非常抱歉的通知
非常感谢有这么多的同志向我提问一些问题,也非常感谢很多的同志可以看我的学习文章,这次大概有四五个月没有上csdn,看到了许多同志的疑问和慰问,我也很感动,但是由于我自己以及其他的原因,我现在打算以考编…...

rust 包模块组织结构
一个包(package)可以拥有多个二进制单元包及一个可选的库单元包。随着包内代码规模的增长,你还可以将代码拆分到独立的单元包(crate)中,并将它作为外部依赖进行引用。 RUST提供了一系列的功能来帮助我们管…...

深入浅出:HTTPS单向与双向认证及证书解析20231208
介绍: 网络安全的核心之一是了解和实施HTTPS认证。本文将探讨HTTPS单向认证和双向认证的区别,以及SSL证书和CA证书在这些过程中的作用,并通过Nginx配置实例具体说明。 第一部分:HTTPS单向认证 定义及工作原理:HTTPS单向认证是一…...
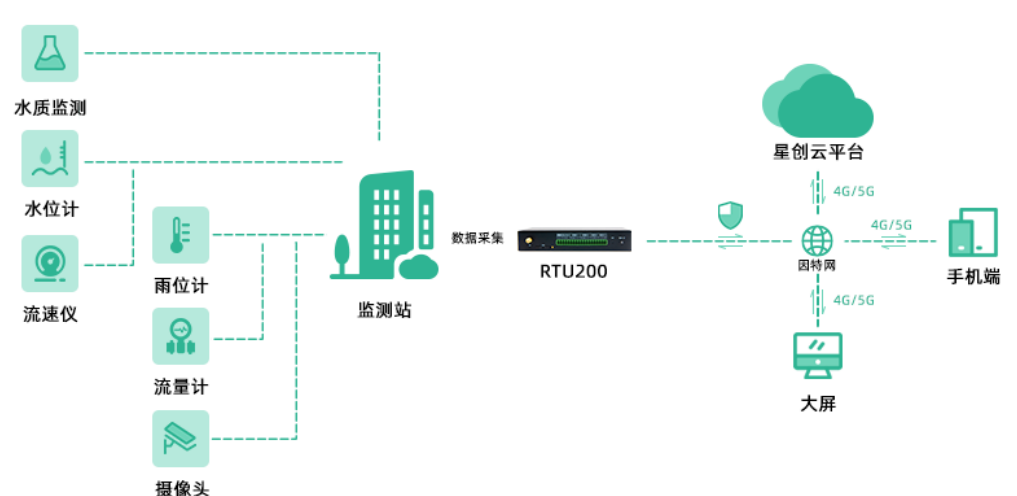
水利安全监测方案——基于RTU200的解决方案
引言: 水资源是人类赖以生存的重要基础,对于保障水利系统安全运行以及应对自然灾害起着关键作用。为了实现水利安全监测的目标,我们提出了基于RTU200的解决方案。本方案将结合RTU200的可靠性、灵活性和高效性,为您打造一个全面的…...

安卓开发学习---kotlin版---笔记(一)
Hello word 前言:上次学习安卓,学了Java开发,简单的搭了几个安卓界面。这次要学习Kotlin语言,然后开发安卓,趁着还年轻,学点新东西,坚持~ 未来的你会感谢现在努力的你~ 主要学习资料:…...

挑选在线客服系统的七大注意事项
越来越多的企业开始注重客户服务,所以在线客服系统也逐渐成为了电商企业不可或缺的一部分。然而在挑选在线客服系统的过程中,蛮多企业会遇到各种各样的问题,这就导致了最终选择的系统并不适合自己企业的需求。接下来我将提醒大家挑选在线客服…...
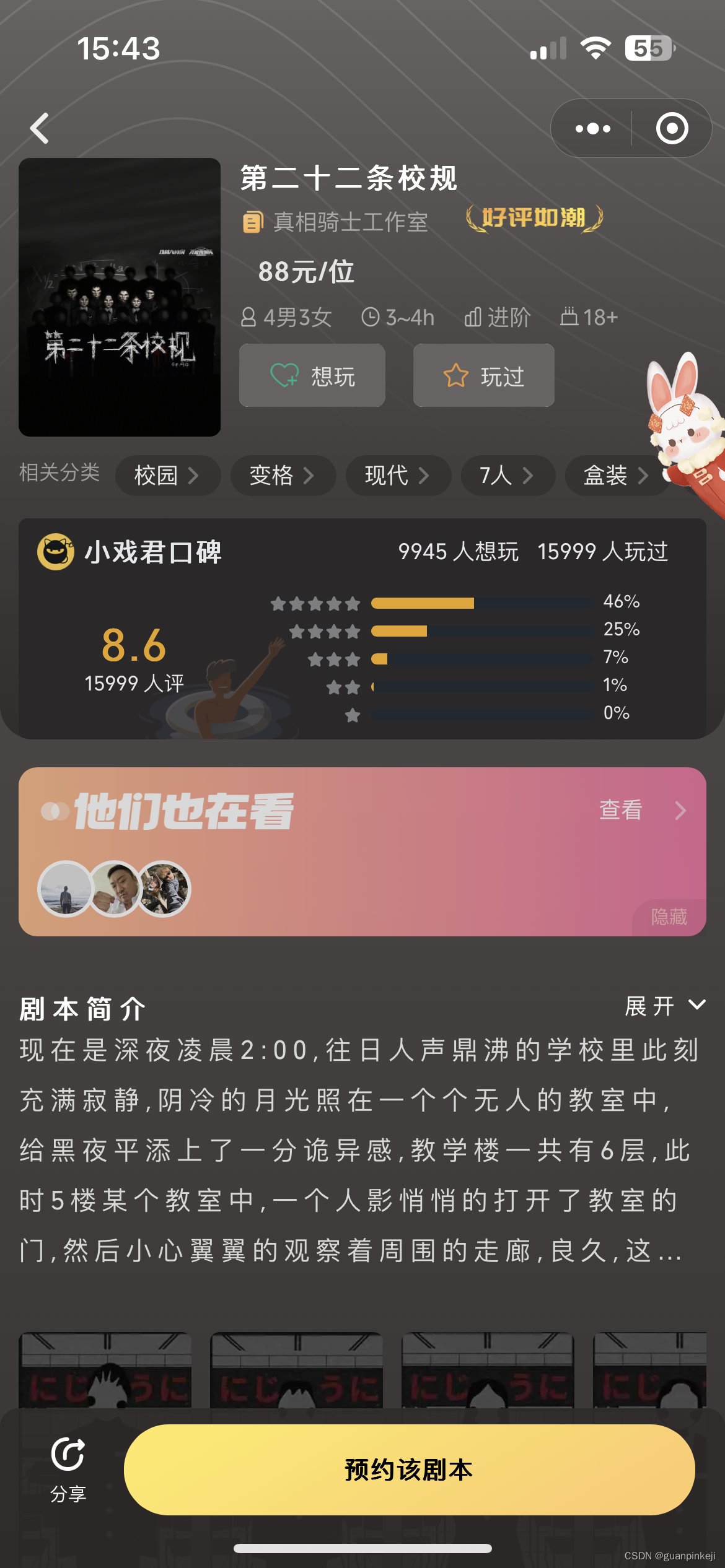
剧本杀小程序搭建:打造线上剧本杀新体验
剧本杀是一款以角色扮演为主的游戏,一度成为了年轻人的最喜爱的社交游戏。在剧本杀市场需求下,剧本杀规模也迅速上升。今年第一季度,剧本杀市场规模环比增长47%,市场整体消费水平逐渐呈上升趋势。 随着剧本杀的不断发展ÿ…...

机器学习实战:预测波士顿房价
前言: Hello大家好,我是Dream。 今天来学习一下机器学习中一个非常经典的案例:预测波士顿房价,在此过程中也会补充很多重要的知识点,欢迎大家一起前来探讨学习~ 一、导入数据 在这个项目中,我们利用马萨诸…...
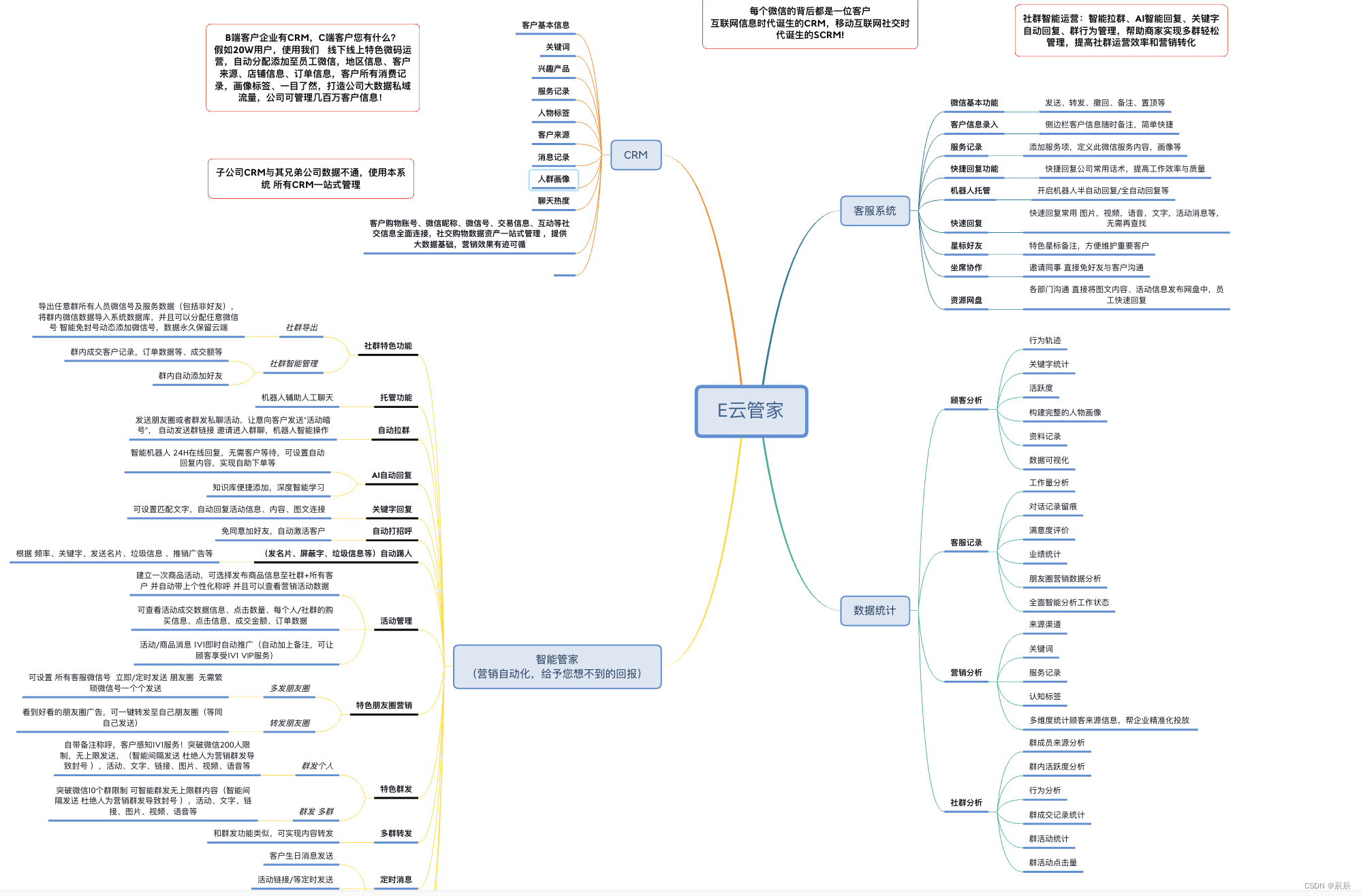
基于个微机器人的开发
简要描述: 下载消息中的动图 请求URL: http://域名/getMsgEmoji 请求方式: POST 请求头Headers: Content-Type:application/jsonAuthorization:login接口返回 参数: 参数名必选类型说明…...

程序员学习方法
https://www.zhihu.com/question/24187324 https://www.zhihu.com/question/505750740 windows系统: 如何业余开展 Windows 系统的学习? - 知乎 wifi工作原理: WiFi的工作原理是什么? - 知乎 发...

基于强化学习的机器人抓取:从PPO/SAC算法到仿真部署全解析
1. 项目概述:一个基于强化学习的机器人抓取开源项目最近在机器人控制领域,强化学习(Reinforcement Learning, RL)的应用越来越火,尤其是在需要高精度、高适应性的任务上,比如机器人抓取。传统的抓取规划方法…...

Verilog时钟分频实战:从偶数、奇数到小数分频的设计与实现
1. 项目概述:从零开始掌握Verilog时钟分频 在数字电路和FPGA设计中,时钟信号是驱动整个系统同步运行的“心跳”。然而,一个系统往往需要多种不同频率的时钟来驱动不同的模块,比如高速的处理器核心和低速的外设接口。直接使用多个外…...

终极虚拟显示器解决方案:ParsecVDisplay完全指南
终极虚拟显示器解决方案:ParsecVDisplay完全指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一款基于Parsec虚拟显示驱动(VDD&#x…...

AI智能体工具搜索系统:从MCP协议到语义检索的工程实践
1. 项目概述:从“工具搜索”到“智能体工具箱”的进化 最近在折腾AI智能体(Agent)开发的朋友,估计都绕不开一个核心问题:如何让智能体高效、准确地调用外部工具?无论是让它帮你查天气、发邮件,还…...

从刺绣到互动:用导电绣线与微控制器打造光控可穿戴艺术
1. 项目概述与核心价值最近在捣鼓一个特别有意思的玩意儿:把会发光的电子元件“绣”到衣服上,让它不仅能穿,还能跟你互动。这个光控发光琵琶鱼刺绣项目,就是一个绝佳的入门案例。它完美地融合了传统手工艺(刺绣&#x…...

PPO算法终极实战指南:基于PyTorch的强化学习完整解决方案
PPO算法终极实战指南:基于PyTorch的强化学习完整解决方案 【免费下载链接】PPO-PyTorch Minimal implementation of clipped objective Proximal Policy Optimization (PPO) in PyTorch 项目地址: https://gitcode.com/gh_mirrors/pp/PPO-PyTorch PPO-PyTorc…...

树莓派5本地大模型实时分析SEN6x环境传感器数据实战
1. 项目概述:当环境传感器遇上本地大模型在物联网和边缘计算领域,我们早已习惯了这样的工作流:传感器采集数据,微控制器或单板计算机(比如树莓派)负责收集和上传,最终的数据分析和洞察则交给云端…...

CCS8.0 TMS320F28335工程配置实战:从零搭建到Flash固件生成
1. CCS8.0开发环境与TMS320F28335基础认知 第一次接触TMS320F28335这款DSP芯片时,我完全被它复杂的开发环境吓到了。直到后来才发现,只要掌握CCS8.0这个开发工具的基本操作逻辑,整个开发过程就会变得异常清晰。这里先给大家科普几个关键概念&…...

ARM架构TLB机制与TLBI指令详解
1. ARM TLB机制与TLBI指令概述在ARM架构中,TLB(Translation Lookaside Buffer)是内存管理单元(MMU)的核心组件,负责缓存虚拟地址到物理地址的转换结果。当CPU访问内存时,首先查询TLB获取地址转换…...

Spoolman:终极3D打印线轴管理解决方案,让您的打印工作更高效 [特殊字符]
Spoolman:终极3D打印线轴管理解决方案,让您的打印工作更高效 🚀 【免费下载链接】Spoolman Keep track of your inventory of 3D-printer filament spools. 项目地址: https://gitcode.com/gh_mirrors/sp/Spoolman Spoolman是一个强大…...