02- 天池工业蒸汽量项目实战 (项目二)
- 忽略警告: warnings.filterwarnings("ignore")
import warnings
warnings.filterwarnings("ignore")- 读取文件格式: pd.read_csv(train_data_file, sep='\t') # 注意sep 是 ',' , 还是'\t'
- train_data.info() # 查看是否存在空数据及数据类型
- train_data.describe() # 查看数据分布
- 删除无关特征: train_data_drop = train_data.drop(['V5','V9','V11','V17','V22','V28'], axis=1)
- 获取特征相关性: train_corr = train_data_drop.corr()
- 同时删除训练数据和测试数据分布不均匀的特征:
- train_data.drop(drop_col_kde,axis = 1,inplace=True)
- all_data.to_csv('./processed_zhengqi_data.csv',index=False) # 保存数据
工业蒸汽量预测
项目描述
经脱敏后的锅炉传感器采集的数据(采集频率是分钟级别),根据锅炉的工况,预测产生的蒸汽量。
火力发电的基本原理是:燃料在燃烧时加热水生成蒸汽,蒸汽压力推动汽轮机旋转,然后汽轮机带动发电机旋转,产生电能。在这一系列的能量转化中,影响发电效率的核心是锅炉的燃烧效率,即燃料燃烧加热水产生高温高压蒸汽。锅炉的燃烧效率的影响因素很多,包括锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量;以及锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。
天池官网链接: 工业蒸汽量预测_学习赛_天池大赛-阿里云天池
第一部分 数据探索
1.1 导入数据探索工具包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
1.2 加载数据
- csv是 txt 格式 .
train_data_file = "./zhengqi_train.txt"
test_data_file = "./zhengqi_test.txt"train_data = pd.read_csv(train_data_file, sep='\t')
test_data = pd.read_csv(test_data_file, sep='\t')
train_data.head()1.3 查看数据集变量信息
1.3.1 查看数据集字段信息
test_data.head() # 查看开始部分的数据信息

1.3.2 查看详细数据信息
测试集数据共有1925个样本,数据中有V0-V37共计38个特征变量,变量类型都为数值类型。
train_data.info() # 查看数据详情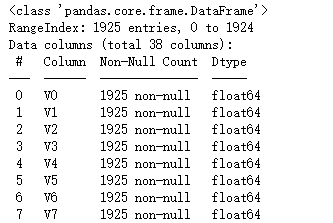
1.3.3 查看数据统计信息
train_data.describe() # 查看数据分布 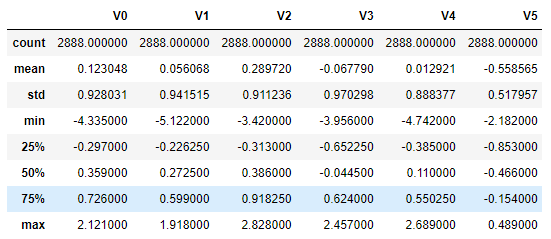
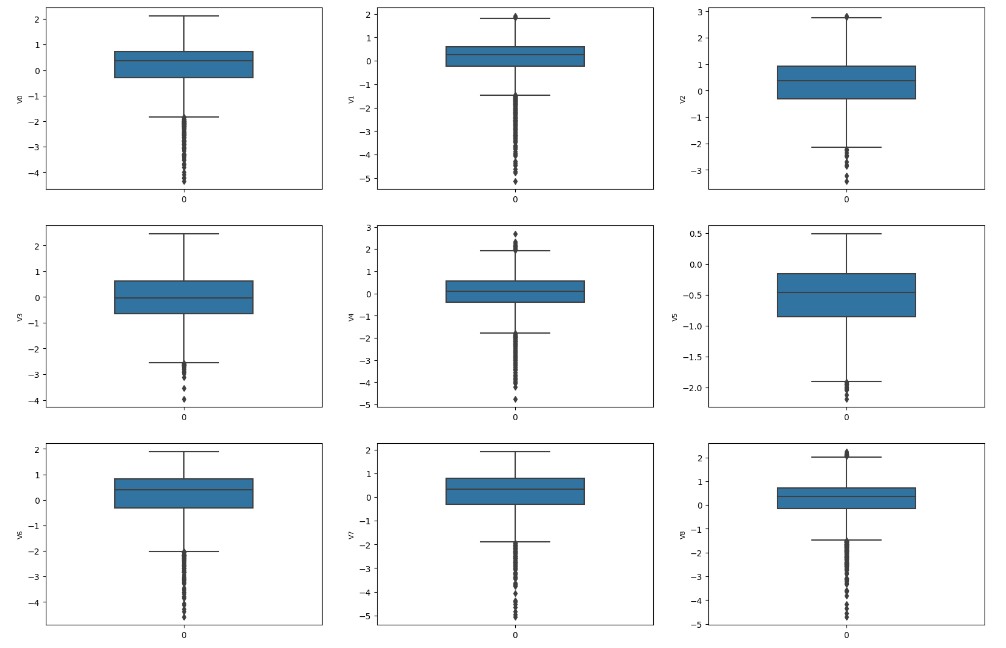
1.3.4 箱式图数据探索
fig = plt.figure(figsize=(6, 4)) # 指定绘图对象宽度和高度
sns.boxplot(train_data['V0'],width=0.5)
plt.savefig('./2-特征箱式图.jpg',dpi = 200)# 画箱式图
column = train_data.columns.tolist()[:39] # 列表头fig = plt.figure(figsize=(20, 60)) # 指定绘图对象宽度和高度
for i in range(38):plt.subplot(13, 3, i + 1) # 13行3列子图sns.boxplot(train_data[column[i]], width=0.5) # 箱式图plt.ylabel(column[i], fontsize=8)箱型图的作用:
- 直观明了地识别数据批中的异常值
- 利用箱线图判断数据批的偏态和尾重
1.4 数据分布查看
- sns.kdeplot() 查看训练数据和测试数据的对比, 是否分布一致 .
dist_cols = 6
dist_rows = len(test_data.columns)//6 + 1plt.figure(figsize=(4*dist_cols,4*dist_rows))i=1
for col in test_data.columns:ax=plt.subplot(dist_rows,dist_cols,i)ax = sns.kdeplot(train_data[col], color="Red", shade=True)ax = sns.kdeplot(test_data[col], color="Blue", shade=True)ax.set_xlabel(col)ax.set_ylabel("Frequency")ax = ax.legend(["train","test"])i+=1
查看指定特征(查看特征'V5', 'V17', 'V28', 'V22', 'V11', 'V9'数据的数据分布):
col = 3
row = 2
plt.figure(figsize=(5 * col,5 * row))
i=1
for c in ["V5","V9","V11","V17","V22","V28"]:ax = plt.subplot(row,col,i)ax = sns.kdeplot(train_data[c], color="Red", shade=True)ax = sns.kdeplot(test_data[c], color="Blue", shade=True)ax.set_xlabel(c)ax.set_ylabel("Frequency")ax = ax.legend(["train","test"])i+=1
plt.savefig('./4-数据分布.jpg',dpi = 200)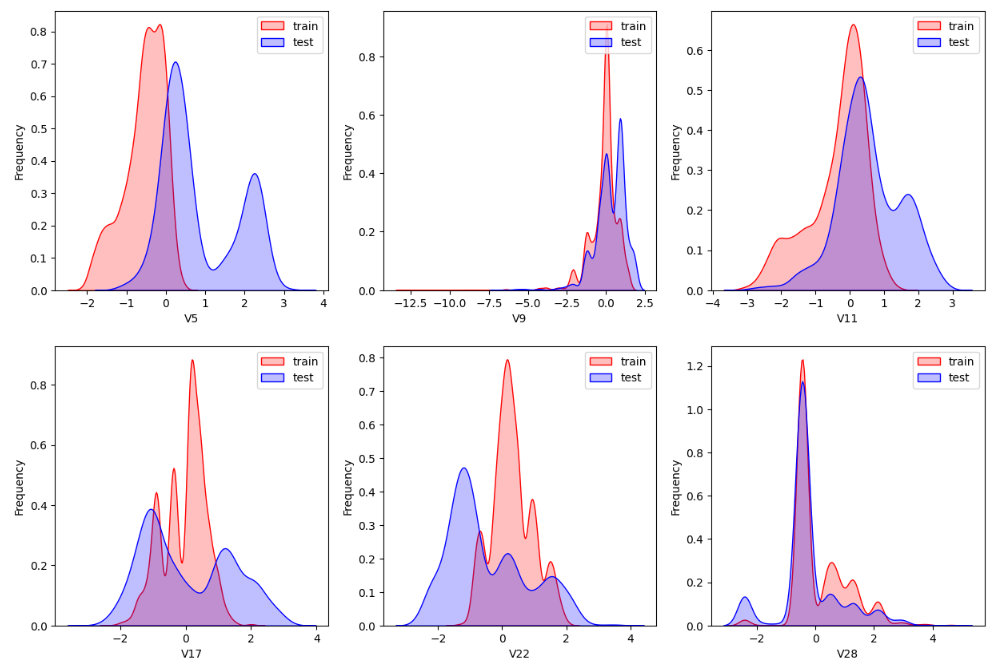
1.5 特征相关性
- train_corr = train_data_drop.corr() # 求取数据的相关性系数
drop_col_kde = ['V5','V9','V11','V17','V22','V28']
train_data_drop = train_data.drop(drop_col_kde, axis=1)
train_corr = train_data_drop.corr()
train_corr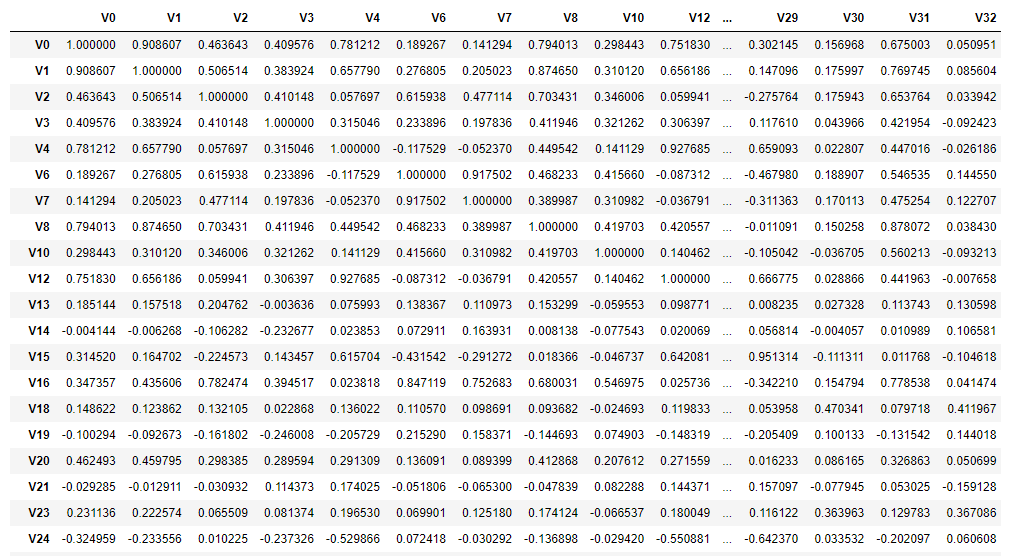
1.5.1 热力图 (相关性显示)
- ax = sns.heatmap(train_corr, vmax=.8, square=True, annot=True) # 根据相关系数画热力图
# 画出相关性热力图
ax = plt.subplots(figsize=(20, 16))#调整画布大小
# 画热力图 annot=True 显示系数
ax = sns.heatmap(train_corr, vmax=.8, square=True, annot=True)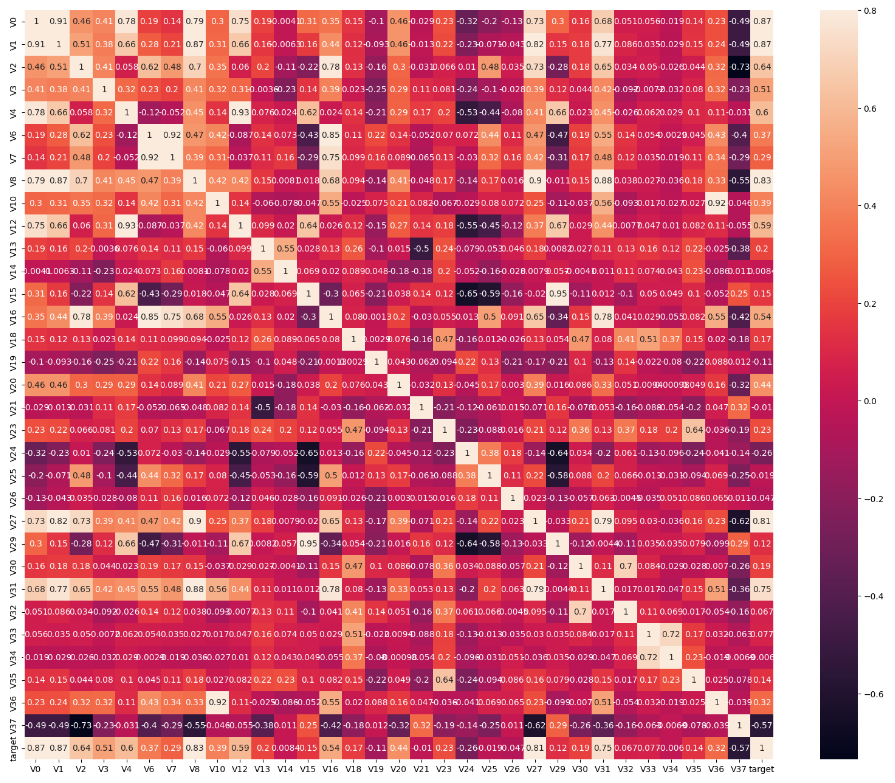
左下角热力图:
- mask = np.zeros_like(mcorr, dtype=np.bool) # 构造与mcorr同维数矩阵 为bool型
- mask[np.triu_indices_from(mask)] = True # 角分线右侧为True,右上角设置为True
- sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, fmt='0.2f') # 画热力图
plt.figure(figsize=(24, 20)) # 指定绘图对象宽度和高度
colnm = train_data_drop.columns.tolist() # 列表头
# 相关系数矩阵,即给出了任意两个变量之间的相关系数
mcorr = train_data_drop.corr()# 构造与mcorr同维数矩阵 为bool型
mask = np.zeros_like(mcorr, dtype=np.bool) # False# 角分线右侧为True,右上角设置为True(戴面具,看不见)
mask[np.triu_indices_from(mask)] = True# 设置colormap对象,表示颜色
cmap = sns.diverging_palette(220, 10, as_cmap=True)# 热力图(看两两相似度)
g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f')
plt.savefig('./5-特征相关性.jpg',dpi = 400)
1.6 特征筛选
1.6.1 根据数据分布进行特征删除
- 根据数据分布判定是否删除 , 根据前方的显示图对比
# 删除训练数据和预测数据 分布不均匀,不够正太分布的特征
train_data.drop(drop_col_kde,axis = 1,inplace=True)
test_data.drop(drop_col_kde,axis = 1,inplace= True)
train_data.head()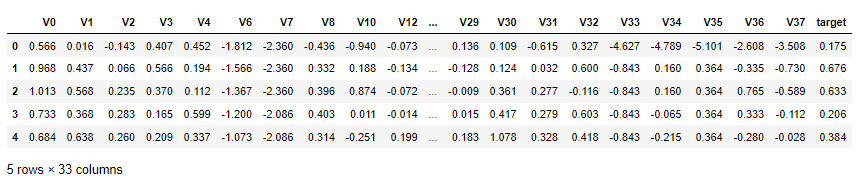
1.6.2 根据相关性系数进行特征筛选
- cond = mcorr[ 'target' ].abs() < 0.1 # 根据相关性判定
- drop_col_corr = mcorr.index[ cond ]
cond = mcorr['target'].abs() < 0.1
drop_col_corr = mcorr.index[cond]
display(drop_col_corr) # ['V14', 'V21', 'V25', 'V26', 'V32', 'V33', 'V34']# 删除
train_data.drop(drop_col_corr,axis = 1,inplace=True)
test_data.drop(drop_col_corr,axis = 1,inplace=True)display(train_data.head())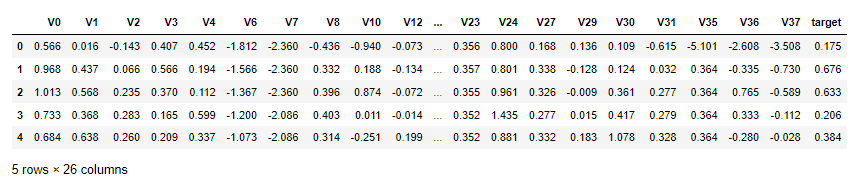
1.7 数据保存
- train_data[ 'label' ] = 'train' # 添加标签
- data.to_csv(./data.csv, index=False)
train_data['label'] = 'train'
test_data['label'] = 'test'all_data = pd.concat([train_data,test_data])
all_data.to_csv('./processed_zhengqi_data.csv',index=False)
all_data.head()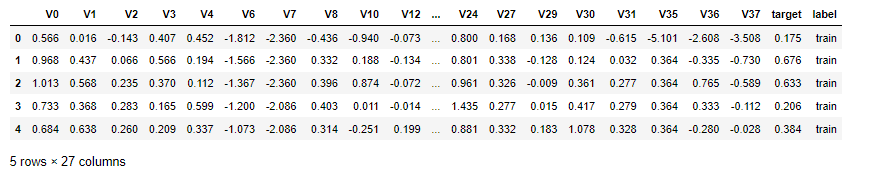
相关文章:
02- 天池工业蒸汽量项目实战 (项目二)
忽略警告: warnings.filterwarnings("ignore") import warnings warnings.filterwarnings("ignore") 读取文件格式: pd.read_csv(train_data_file, sep\t) # 注意sep 是 , , 还是\ttrain_data.info() # 查看是否存在空数据及数据类型train_data.desc…...

LeetCode-111. 二叉树的最小深度
目录题目分析递归法题目来源111. 二叉树的最小深度题目分析 这道题目容易联想到104题的最大深度,把代码搬过来 class Solution {public int minDepth(TreeNode root) {return dfs(root);}public static int dfs(TreeNode root){if(root null){return 0;}int left…...

git常用命令
(一)克隆代码(clone):将远程仓库代码克隆到本地仓库 克隆远程仓库某个分支 git clone -b 远程分支名称 https://github.com/master/master.git 本地文件名称 克隆远程仓库默认分支 git clone https://github.com/mas…...

2022年12月电子学会Python等级考试试卷(一级)答案解析
青少年软件编程(Python)等级考试试卷(一级) 一、单选题(共25题,共50分) 1. 关于Python语言的注释,以下选项中描述错误的是?( ) A. Python语言有两种注释方式&…...

大数据未来会如何发展
大数据应用的重要性,自全国提出“数据中国”的概念以来,我们周围默默地在发挥作用的大数据逐渐深入人们的心中,大数据的应用也越来越广泛,具体到金融、汽车、餐饮、电信、能源、体育和娱乐等领域 为什么大数据技术那么火…...

2022黑马Redis跟学笔记.基础篇(一)
2022黑马Redis跟学笔记.基础篇 一1.Redis入门1.1.认识NoSQL1.1.1.结构化与非结构化1.1.2.关联和非关联1.1.3.查询方式1.1.4.事务1.1.5.总结1.2.认识Redis1.3.安装Redis步骤一:安装Redis依赖步骤二:上传安装包并解压步骤三:启动(1).默认启动(2…...
【Spring(十一)】万字带你深入学习面向切面编程AOP
文章目录前言AOP简介AOP入门案例AOP工作流程AOP切入点表达式AOP通知类型AOP通知获取数据总结前言 今天我们来学习AOP,在最初我们学习Spring时说过Spring的两大特征,一个是IOC,一个是AOP,我们现在要学习的就是这个AOP。 AOP简介 AOP:面向切面编程,一种编程范式&#…...

基于Java+SpringBoot+Vue+uniapp前后端分离图书阅读系统设计与实现
博主介绍:✌全网粉丝3W,全栈开发工程师,从事多年软件开发,在大厂呆过。持有软件中级、六级等证书。可提供微服务项目搭建、毕业项目实战、项目定制✌ 博主作品:《微服务实战》专栏是本人的实战经验总结,《S…...

2021年新公开工业控制系统严重漏洞汇总
声明 本文是学习ITOT一体化工业信息安全态势报告(2019). 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 工业互联网安全威胁 2021年新公开工业控制系统严重漏洞 缓冲区溢出漏洞 缓冲区溢出(buffer overflow&…...
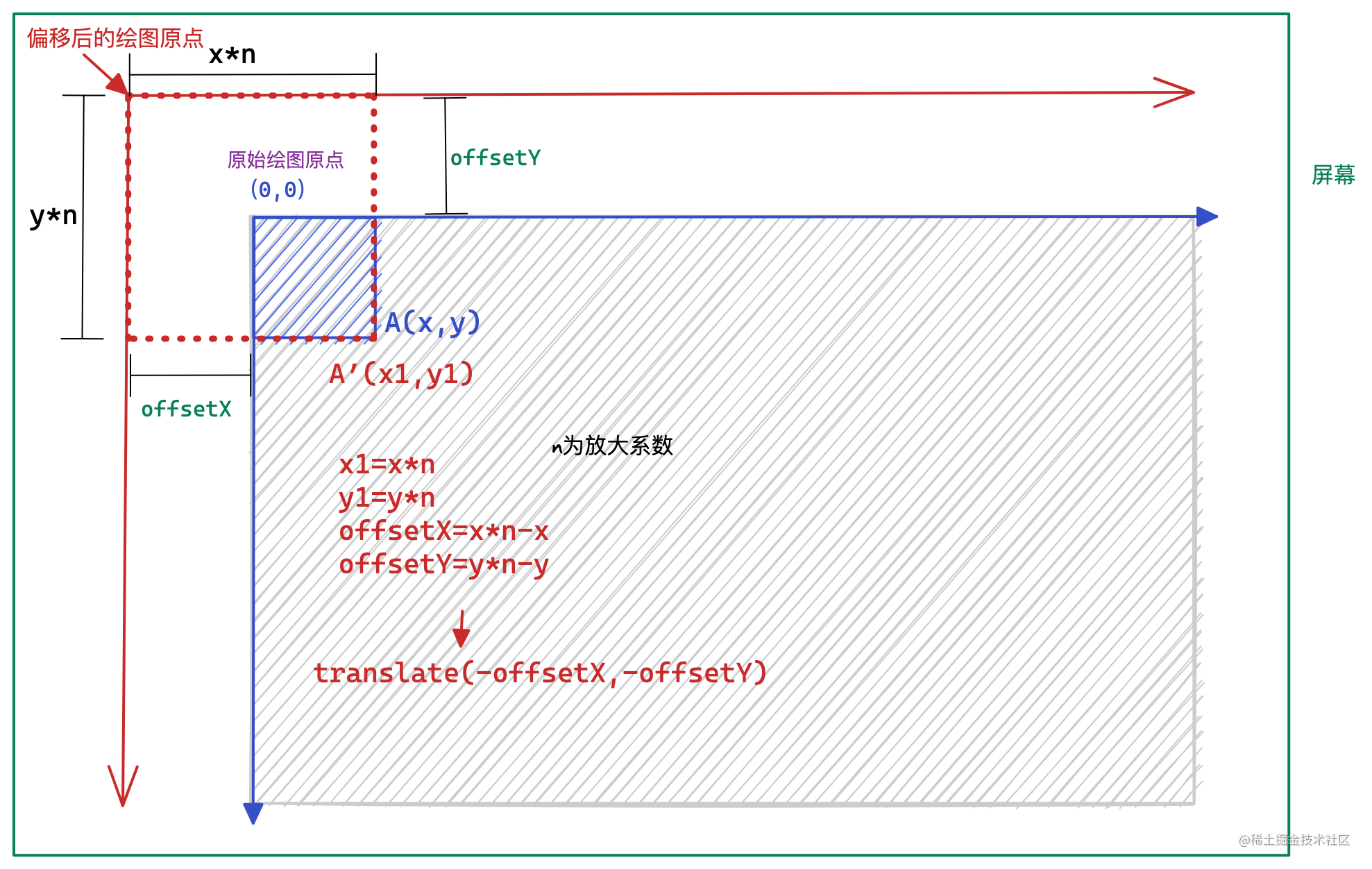
Canvas鼠标滚轮缩放以及画布拖动(图文并茂版)
Canvas鼠标滚轮缩放以及画布拖动 本文会带大家认识Canvas中常用的坐标变换方法 translate 和 scale,并结合这两个方法,实现鼠标滚轮缩放以及画布拖动功能。 Canvas的坐标变换 Canvas 绘图的缩放以及画布拖动主要通过 CanvasRenderingContext2D 提供的 …...

[ECCV 2020] FGVC via progressive multi-granularity training of jigsaw patches
Contents IntroductionProgressive Multi-Granularity (PMG) training frameworkExperimentsReferencesIntroduction 不同于显式地寻找特征显著区域并抽取其特征,作者充分利用了 CNN 不同 stage 输出的特征图的语义粒度信息,并使用 Jigsaw Puzzle Generator 进行数据增强来帮…...
Python推导式
列表(list)推导式 [remove for source in xx_list]或者[remove for source in xx_list if condition] 实例: names[Bob,Mark,Mausk,Johndan,Wendy] new_names[name.upper() for name in names if len(name)<5] print(new_names)即迭代列…...

Java列表List的定查改增删操作
Java列表List的定查改增删操作定义查找遍历元素与下标互查修改增加删除java.util中提供了三种常用的集合类,列表List、集合Map和字典Set。这些集合类相较于数组有更多功能,并且都可以通过Iterator(迭代器)来访问。 在这篇博客中&…...

day03java语言特性 JDK、JRE、JVM
1、Java语言的特性 1.1、简单性在Java语言当中真正操作内存的是:JVM(Java虚拟机)所有的java程序都是运行在Java虚拟机当中的。而Java虚拟机执行过程中再去操作内存。对于C或者C来说程序员都是可以直接通过指针操作内存的。C或者C更灵活&…...

HydroD 实用教程(二)有限元模型
目 录一、前言二、模型种类三、单元类型四、FEM文件五、参考文献一、前言 SESAM (Super Element Structure Analysis Module)是由挪威船级社(DNV-GL)开发的一款有限元分析(FEA)系统,它以 GeniE、…...

Java中的Set集合
Set不能存储重复元素,元素无序(指的是不按照添加的顺序,List集合是按照添加顺序存储的)hashSet注:源码底层是hashMap实现的,因为hashMap是双列的,其中键是不能重复的,而hashSet是单列…...
【RabbitMQ五】——RabbitMQ路由模式(Routing)
RabbitMQ路由模式前言RabbitMQ模式的基本概念为什么要使用Rabbitmq 路由模式RabbitMQ路由模式组成元素路由模式完整代码Pom文件引入RabbtiMQ依赖RabbitMQ工具类生产者消费者1消费者2运行结果截图前言 通过本篇博客能够简单使用RabbitMQ的路由模式。 本篇博客主要是博主通过官网…...

【C语言】宏定义 结构体 枚举变量的用法
目录 一、数据类型 二、C语言宏定义 三、C语言typedef重命名 四、 #define与typedef的区别 五、结构体 六、枚举变量 补充学习一点STM32的必备基础知识 一、数据类型 二、C语言宏定义 关键字:#define 用途:用一个字符串代替一个数字,…...

锁升级之Synchronized
Synchronized JVM系统锁一个对象里如果有多个synchronized方法,同一时刻,只要有一个线程去调用其中的一个synchronized方法,其他线程只能等待!锁的是当前对象,对象被锁定后,其他线程都不能访问当前对象的其…...
基于nodejs+vue疫情网课管理系统
疫情网课也都将通过计算机进行整体智能化操作,对于疫情网课管理系统所牵扯的管理及数据保存都是非常多的,例如管理员:首页、个人中心、学生管理、教师管理、班级管理、课程分类管理、课程表管理、课程信息管理、作业信息管理、请假信息管理、上课签到管理、论坛交流…...

Vivado里手把手配置MIPI CSI-2 RX Subsystem IP核:从D-PHY选IO到Video Format Bridge算位宽
Vivado中MIPI CSI-2 RX Subsystem IP核配置实战:从D-PHY选型到视频格式转换 在ZYNQ系列SoC的视觉处理系统中,MIPI CSI-2接口作为连接图像传感器的标准协议,其硬件实现往往成为项目成败的关键节点。本文将深入剖析Vivado工具中MIPI CSI-2 RX S…...

一文搞懂Agent Skill的原理与设计规范
最近 Skill 这个词在 AI 圈里出现的频率,越来越高。 你打开 Claude Code、Cursor、Codex,甚至 Gemini CLI,到处都在聊「Agent Skill」。 Agent Skill 刚出来,我以为这又是个新瓶装旧酒的概念。 Prompt 改个名字嘛,能…...

2026年株洲老人小孩都能用专业床垫有哪些?
引言随着生活水平的提高,人们对床垫的要求也越来越高。特别是对于老人和小孩这两类特殊人群,选择一款合适的床垫尤为重要。本文将介绍几款适合老人和小孩使用的专业床垫,其中包括德国美得丽(Musterring)床垫。德国美得…...

多智能体编排实战:从架构设计到生产部署的12周训练指南
1. 项目概述与核心价值最近在探索如何系统性地掌握多智能体编排技术时,我遇到了一个名为“Shadow Dojo”的开源项目。这个名字很有意思,“道场”一词本身就意味着一个需要持续练习、精进技艺的地方。这个项目将自己定位为“训练场”,目标非常…...

用CC2530 DIY一个无线串口透传模块:基于Zigbee的无线数据收发实践
基于CC2530的Zigbee无线串口透传模块实战指南 在物联网和智能硬件开发领域,无线数据传输一直是核心需求之一。CC2530作为一款集成了Zigbee射频前端的经典芯片,其成本效益和成熟生态使其成为众多开发者的首选。本文将带您深入探索如何利用两块CC2530开发板…...

Cursor Rules:为AI编程时代量身定制的代码规范集实战指南
1. 项目概述:Cursor Rules,一个为AI编程时代量身定制的代码规范集如果你和我一样,是Cursor编辑器的重度用户,那你一定体验过它那令人惊叹的AI辅助编程能力。它能帮你生成代码、重构函数、甚至解释复杂的逻辑。但不知道你有没有遇到…...

使用Hermes Agent框架时接入Taotoken自定义供应商的步骤详解
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Hermes Agent框架时接入Taotoken自定义供应商的步骤详解 对于使用Hermes Agent框架的开发者而言,将后端AI服务接入…...

AHB与APB总线桥接设计及SoC系统优化
1. AHB总线架构与APB桥接设计精要在复杂SoC设计中,AMBA总线作为ARM架构的核心互联标准,其AHB(Advanced High-performance Bus)与APB(Advanced Peripheral Bus)的协同工作直接影响系统性能。APB桥作为高低速…...

无线TDoA定位中的硬件偏差问题与DTB校准方法
1. 无线TDoA定位中的硬件偏差问题解析在无线定位领域,时间差到达(Time Difference of Arrival, TDoA)技术因其能够消除接收机时钟偏差而备受青睐。然而,这项技术在实际应用中面临一个关键挑战:节点硬件引入的系统性偏差…...

147.YOLOv8 vs YOLOv5 核心差异 + 缺陷检测完整代码,从原理到落地一步到位
摘要 YOLO(You Only Look Once)系列算法是目标检测领域最具影响力的单阶段检测模型。本文从零开始,系统讲解YOLOv8的核心原理与完整实践流程。通过一个工业级缺陷检测案例,覆盖从数据准备、模型训练、评估到部署的全链路。所有代码均基于Ultralytics官方库实现,确保可复现…...