ShardingSphere数据分片之分表操作

1、概述
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上层的标准和生态。 它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。 它站在数据库的上层视角,关注它们之间的协作多于数据库自身。
ShardingShpere的两个核心模块:
- ShardingSphere-JDBC:ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。
- ShardingSphere-Proxy:ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数据库二进制协议,对异构语言提供支持。
在开发中实现分库分表的操作,我们一般使用的ShardingSphere-JDBC这个模块。
具体详情请参考官网:https://shardingsphere.apache.org/document/current/cn/overview/
说实话,看这个官网需要一定的编码功底,懂的都懂。😄
ShardingSphere的分库分表操作的逻辑图:
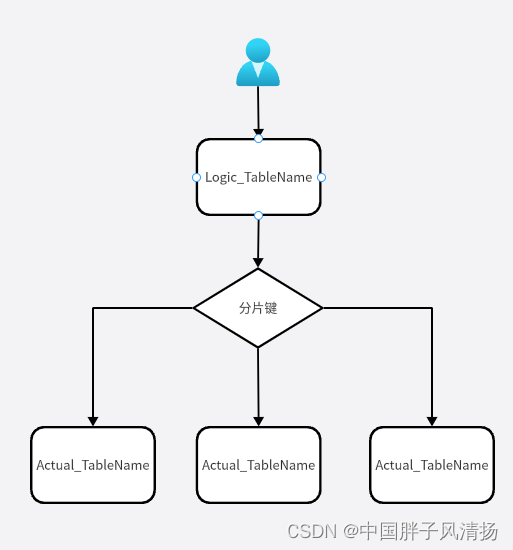
开发者配置了分库分表策略后,我们只需要操作逻辑表名就可以了。
2、数据分片带来的优缺点
数据分片主要是用来解决海量的数据访问的问题,将数据库采用垂直拆分或者水平拆分的方式将海量、复杂的数据分布到不同的数据库、数据表中,以此来实现专库专用、提高访问性能。
优点:
- 提高可扩展性:通过将数据拆分成多个小型数据库,每个数据库仅处理一部分数据,可以在数据增长时动态地添加新的分片,从而提高整个系统的可扩展性。
- 提升性能:分片后的每个小型数据库只处理部分数据,减轻了单个节点的压力,从而提升了整个系统的性能。
缺点:
- 复杂性增加:数据分片意味着需要更多的数据库来存储和管理数据,这增加了系统的复杂性。同时,对于每个查询,可能需要跨多个数据库进行查找,增加了查询的复杂性。
- 并发控制:在分布式系统中,并发控制是一个重要的问题。如果多个节点同时更新同一片数据,就可能导致数据不一致的问题。因此,需要采用并发控制技术来保证数据的正确性。
- 数据迁移和恢复:当新增或删除分片时,需要进行数据迁移和恢复。这个过程可能会导致数据的不一致或丢失。因此,需要设计合理的迁移和恢复策略来保证数据的正确性。
我们所使用ShardingSphere组件,通过配置Yaml文件来降低我们的编码复杂度。并发控制何数据迁移与恢复都是需要其他的方式来解决。
3、ShardingSphere分表操作
ShardingSphere的分库分表操作都是基于ShardingSphere-JDBC这个模块来实现。在当前开发中一般都需要和Springboot进行整合,而且只要是流行的框架、组件,SpringBoot一般都会有一个集成的依赖。
3.1、依赖
当前JDK已经到了21,当然我这里使用的还是JDK17,因为JDK21对于SpringBoot 3.1 以下的版本都不友好,会出现一个错误,所以今年刚出的JDK21可以作为爱好先了解,毕竟刚出来很多东西都还需要完善。
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId><version>5.1.1</version>
</dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.7.14</version>
</dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.4.1</version>
</dependency>
3.2、操作方式一:Yaml文件配置
在引入了ShardingSphere-JDBC模块后,可以通过YAML文件配置的方式轻松的配置分表操作。
spring:shardingsphere:props:sql-show: true # 是否展示ShardingSphere的SQL日志datasource: # 配置数据源ds0:username: rootpassword: 123456url: jdbc:mysql://127.0.0.1:3306/mysql_test?serverTimezone=Asia/Shanghaitype: com.zaxxer.hikari.HikariDataSource # 这个参数是必须要有的,否则会报错。driver-class-name: com.mysql.cj.jdbc.Drivernames: ds0 # 所有数据源的名称,用逗号隔开rules: # ShardingSphere规则sharding:sharding-algorithms: # 分片算法配置table-inline: # 分片算法名称,自定义的名称type: INLINE # 分片算法类型props: # 分片算法属性配置algorithm-expression: test_$->{id % 2} # 分片规则指定语句tables: # 分片表配置logic_table_name: # 自定义的逻辑表名称actual-data-nodes: ds0.test_0, ds0.test_1 # 真实的表名称,数据源.表名称,多个表之间用逗号隔开,也支持表达式:ds0.test_$->{0..1}table-strategy: # 表分片策略standard: # 标准分片策略sharding-column: id # 分片的列名sharding-algorithm-name: table-inline # 分片算法mode:type: Memory # 运行模式类型。可选配置:内存模式 Memory、单机模式 Standalone、集群模式 Clusterrepository:type: JDBC
在YAML文件中通过rules.sharding.sharding-algorithms属性来配置数据分片的分片方式,比如说test_$->{id % 2},这个就是按照奇偶的方式对数据进行划分数据。
在rules.sharding.sharding-algorithms.type参数主要用于指定分片算法的类型。以下是一些常见的 type 选项:
| 参数名称 | 参数描述 |
|---|---|
| inline | 行表达式分片算法。该算法允许你使用行表达式来定义分片规则,适用于简单的分片场景。 |
| hint | Hint 分片算法。该算法允许你使用 Hint 来指定分片规则,适用于一些特殊的分片场景。 |
| mod_sharding | 取模分片算法。根据指定的分片数量进行取模运算来进行分片,例如 user_id % 8 |
| range_sharding | 范围分片算法。允许你定义一个范围来进行分片,适用于范围查询等场景。 |
| hash_sharding | 哈希分片算法。根据指定的哈希算法进行分片,适用于一些需要一致性哈希的场景。 |
rules.sharding.tables.<logic_table_name>.table-strategy参数用来配置表分片的策略,可配置的属性如下:
1、standard:标准分片策略。
| 参数名称 | 参数描述 |
|---|---|
| sharding-column | 分片列名称 |
| precise-algorithm-class-name | 精确分片算法类名称,用于 = 和 IN 查询。 |
| range-algorithm-class-name | 范围分片算法类名称,用于 BETWEEN 查询。 |
2、complex:复合分片策略。
| 参数名称 | 参数描述 |
|---|---|
| sharding-columns | 分片列名称列表,多个列以逗号分隔。 |
| algorithm-class-name | 复合分片算法类名称。 |
3、inline:行表达式分片策略。
| 参数名称 | 参数描述 |
|---|---|
| sharding-column | 分片列名称。 |
| algorithm-expression | 分片算法行表达式,例如:${column} % 2。 |
4、hint:Hint 分片策略。
| 参数名称 | 参数描述 |
|---|---|
| algorithm-class-name | Hint分片算法类名称。 |
3.3、操作方式二:自定义分片算法
使用YAML文件的配置只能用于简单的分表配置,像test_0,test_1这种简单的,而像某些表名不同的复杂分表操作就不方便使用YAML的配置方式了,此时就需要使用自定义分片策略。
3.3.1、实现StandardShardingAlgorithm接口
自定义分表策略需要实现StandardShardingAlgorithm接口。通过doSharding方法来返回要操作的真实表名。
public class TestShardingAlgorithm implements StandardShardingAlgorithm<Integer> {private static Object[] TABLE_NAME_LIST = null;/*** 实现精确分片* @param collection yaml中定义的真实的表名列表* @param preciseShardingValue 分片的信息* 1、getColumnName(): 获取分片策略中的sharding-column参数的值* 2、getValue(): sharding-column参数所对应类的值* @return 真正需要执行的表名*/@Overridepublic String doSharding(Collection<String> collection, PreciseShardingValue<Integer> preciseShardingValue) {if(TABLE_NAME_LIST == null){TABLE_NAME_LIST = collection.toArray();}int index = preciseShardingValue.getValue() % TABLE_NAME_LIST.length;return (String) TABLE_NAME_LIST[index];}// 实现范围分片@Overridepublic Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Integer> rangeShardingValue) {return collection;}@Overridepublic void init() {// 进行初始化的配置}// 分片策略的 key@Overridepublic String getType() {return "TestShardingAlgorithm";}
}
在单体系统中,doSharding和getType两个方法是必须要编写的,ShardingSphere会根据这两个方法来调用分表策略。
我们也可以使用这种方式来实现动态分表策略,将需要分表的表名存放在一张表中,每次的操作都会进行数据库的访问来确定需要操作的表。存储媒介不光是数据库,还可以是Nacos、Zookeeper等。
3.3.2、配置Yaml文件
spring:shardingsphere:props:sql-show: truedatasource:ds0:username: rootpassword: 123456url: jdbc:mysql://127.0.0.1:3306/mysql_test?serverTimezone=Asia/Shanghaitype: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.cj.jdbc.Drivernames: ds0rules:sharding:sharding-algorithms:table-inline:type: TestShardingAlgorithmprops:algorithm-class-name: com.tt.shardingpheredemo.config.TestShardingAlgorithmtables:t_user:actual-data-nodes: ds0.test_0, ds0.test_1# 分表策略table-strategy:standard:sharding-column: idsharding-algorithm-name: table-inlinemode:type: Memoryrepository:type: JDBCmain:banner-mode: off
自定义分片策略的引入需要修改rules.sharding.sharding-algorithms参数中的type和props.algorithm-class-name两个参数。
type参数的值一定要是自定义策略类中的getType()返回值。
3.3.3、配置分片类载入文件
当我们完成上述的操作后,按照逻辑来说是没问题了的,但是,世事有例外😏,启动项目的时候直接报错:
No implementation class load from SPI `org.apache.shardingsphere.sharding.spi.ShardingAlgorithm` with type `TestShardingAlgorithm`.
如果type这个参数不是和getType()方法的值一致,也会报这个错误。
报这个错误的原因是TestShardingAlgorithm这个类没有被加载进程序,ShardingSphere的底层基于Java SPI机制。
我们不妨来看看StandardShardingAlgorithm其他的实现类是如何实现的。
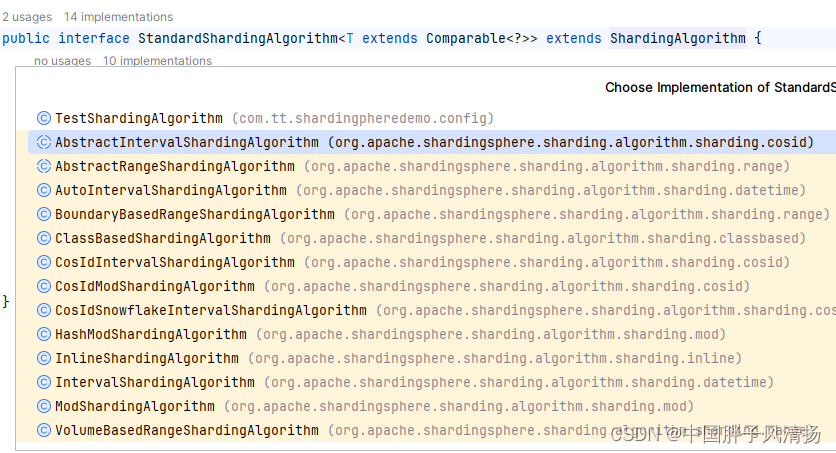
StandardShardingAlgorithm的实现类还是不少的,其中就有上面说的几种分片策略。
在ShardingSphere的源码中,我们看到这几种分片策略都不是通过SpringBoot的注入方式来加载入项目的,而是通过SPI机制来加载入项目,在源码中有一个org.apache.shardingsphere.sharding.spi.ShardingAlgorithm文件,这个文件存放着ShardingSphere所提供的分片策略方式。
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#org.apache.shardingsphere.sharding.algorithm.sharding.inline.InlineShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.mod.ModShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.mod.HashModShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.range.VolumeBasedRangeShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.range.BoundaryBasedRangeShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.datetime.AutoIntervalShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.datetime.IntervalShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.classbased.ClassBasedShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.complex.ComplexInlineShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.hint.HintInlineShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.cosid.CosIdModShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.cosid.CosIdIntervalShardingAlgorithm
org.apache.shardingsphere.sharding.algorithm.sharding.cosid.CosIdSnowflakeIntervalShardingAlgorithm
所以我们想要使用自定义的分片策略,那么就要使用源码中的方式将自定义的分片策略类加载入系统,使用Spring Boot的@Component方式是没有用的。
我们需要在项目的resources目录下创建一个同名的properties文件,来存放自定义的分片策略类的全限定名。
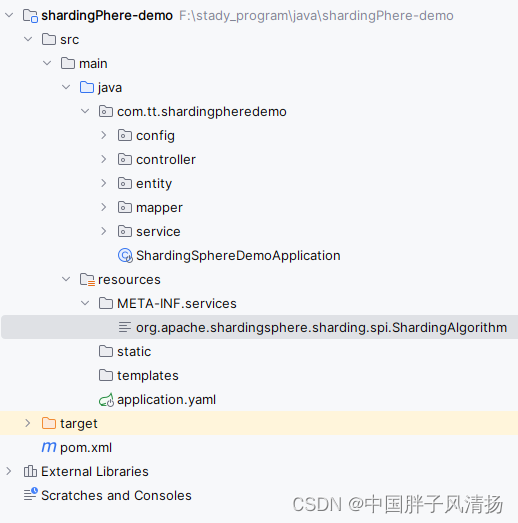
org.apache.shardingsphere.sharding.spi.ShardingAlgorithm文件一定要在META_INF.services目录下,因为源码中的文件就在这个目录下。
3.4、测试
3.4.1、实体类配置
因为系统中集成了Mybatis-plus这个组件,所以在编码上也会轻松很多,Dao层、Service层都和日常开发一样的,唯一不同的就是Entity上。
@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName(value = "logic_table_name")
public class Test{@TableId(type = IdType.AUTO)private int id;private String testName;private int abc;}
实体类的主要不同就在于@TableName的value值。
value值不再指向的是数据库中的真实表名,而是指向ShardingSphere配置中的逻辑表名。
3.4.2、数据库
两张表:test_1和test_1。
CREATE TABLE `test_0` (`id` int NOT NULL AUTO_INCREMENT,`test_name` varchar(255) NOT NULL,`abc` int NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;CREATE TABLE `test_1` (`id` int NOT NULL AUTO_INCREMENT,`test_name` varchar(255) NOT NULL,`abc` int NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
3.4.3、测试结果
本次测试采用奇偶分片策略,分片键为id。
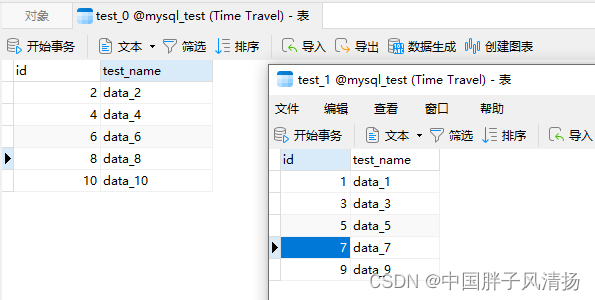
test_0表中存放了id为偶数的数据,test_1表中存放了id为奇数的数据。
4、总结
ShardingSphere虽然支持市面上大部分的分库分表方式,也是市面上当前最火的分库分表组件之一,但是:
- ShardingSphere的配置相对复杂,需要用户具备一定的数据库和中间件知识。配置过程中需要考虑分片键的选择、分片算法的设计、数据的迁移等因素,这些都需要用户进行深入的思考和规划。
- 学习成本高:由于ShardingSphere是一个相对复杂的系统,用户需要花费一定的时间和精力来学习它的原理、配置和使用方法。这对于一些新手来说可能是一个挑战。

相关文章:
ShardingSphere数据分片之分表操作
1、概述 Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。 Apache ShardingSphere 设计哲学为 Database Plus,旨在构建异构数据库上…...
基于ssm鲸落文化线上体验馆论文
摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存储,归纳,集中处理数据信息的管理方式。本鲸落文化线上体验馆就是在这样的大环境下诞生,其可以帮助管理者在短时间内处理完毕庞大的数据信…...

LeetCode Hot100 131.分割回文串
题目: 给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。 回文串 是正着读和反着读都一样的字符串。 方法:灵神-子集型回溯 假设每对相邻字符之间有个逗号,那么就看…...
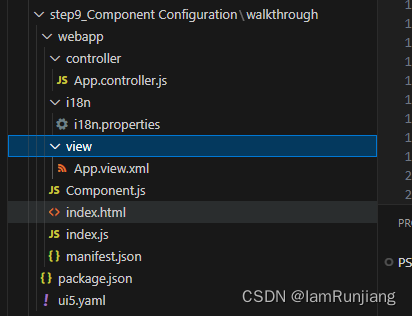
SAP UI5 walkthrough step9 Component Configuration
在之前的章节中,我们已经介绍完了MVC的架构和实现,现在我们来讲一下,SAPUI5的结构 这一步,我们将所有的UI资产从index.html里面独立封装在一个组件里面 这样组件就变得独立,可复用了。这样,无所什么时候我…...
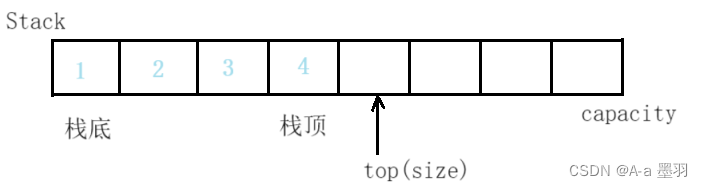
【数据结构和算法】--- 栈
目录 栈的概念及结构栈的实现初始化栈入栈出栈其他一些栈函数 小结栈相关的题目 栈的概念及结构 栈是一种特殊的线性表。相比于链表和顺序表,栈只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的…...

CentOS7.0 下rpm安装MySQL5.5.60
下载 下载路径: MySQL :: Download MySQL Community Server -->looking for the latest GA version-->5.5.60 此压缩包中有多个rpm包 有四个不是必须的,只需安装这三个 MySQL-server-5.5.60-1.el6.x86_64 MySQL-devel-5.5.60-1.el6.x86_64 MySQL-client-5.5.60-1.el6.x8…...

智慧能源:数字孪生压缩空气储能管控平台
压缩空气储能在解决可再生能源不稳定性和提供可靠能源供应方面具有重要的优势。压缩空气储能,是指在电网负荷低谷期将电能用于压缩空气,在电网负荷高峰期释放压缩空气推动汽轮机发电的储能方式。通过提高能量转换效率、增加储能密度、快速启动和调节能力…...

【链表OJ—反转链表】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 1、反转链表题目: 2、方法讲解: 解法一: 解法二: 总结 前言 世上有两种耀眼的光芒,一种是正在升起的太…...
TCP一对一聊天
客户端 import java.awt.BorderLayout; import java.awt.Color; import java.awt.Dimension; import java.awt.Font; import java.awt.event.ActionEvent; import java.awt.event.ActionListener; import java.io.BufferedReader; import java.io.IOException; import java.io…...
基于Java的招聘系统的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

spring boot整合mybatis进行部门管理管理的增删改查
部门列表查询: 功能实现: 需求:查询数据库表中的所有部门数据,展示在页面上。 准备工作: 准备数据库表dept(部门表),实体类Dept。在项目中引入mybatis的起步依赖,mysql的…...

微软 Power Platform 零基础 Power Pages 网页搭建高阶实际案例实践(四)
微软 Power Platform 零基础 Power Pages 网页搭建教程之高阶案例实践学习(四) Power Pages 实际案例学习进阶 微软 Power Platform 零基础 Power Pages 网页搭建教程之高阶案例实践学习(四)1、新增视图,添加List页面2…...
如何在任何STM32上面安装micro_ros
就我知道的:micro-ros只能在特定的昂贵的开发板上面运行,但是偶然发现了这个文章,似乎提供了一个全新的方式来在ros2和单片机之间通讯,如果能够这样肯定也能够提高效率,但即使不行,使用串口库也应该比较简单…...
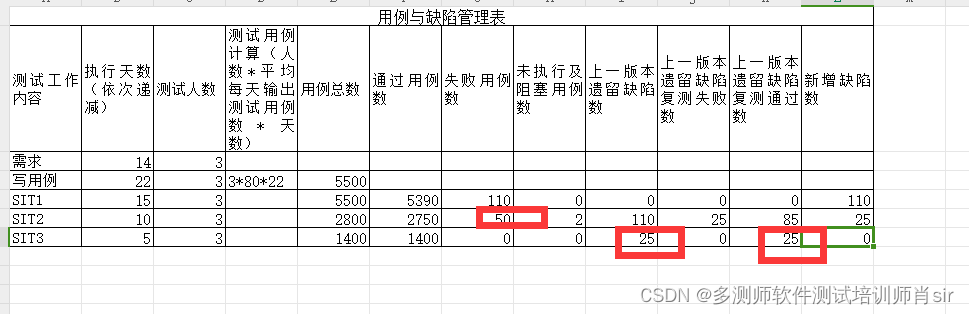
肖sir__ 项目讲解__项目数据
项目时间: 情况一:项目时间开始到上线的时间,这个时间一般比较长(一年,二年,三年) 情况二:项目的版本的时间或则是周期(1个月,2个月,3个月&…...

微服务实战系列之J2Cache
前言 经过近几天陆续发布Cache系列博文,博主已对业界主流的缓存工具进行了基本介绍,当然也提到了一些基本技巧。相信各位盆友看见这么多Cache工具后,在选型上一定存在某些偏爱: A同学说:不管业务千变万化,…...

12.ROS导航模块:gmapping、AMCL、map_server、move_base案例
目录 1 导航概述 2 导航简介 2.1 导航模块简介 1.全局地图 2.自身定位 3.路径规划 4.运动控制 5.环境感知 2.2 导航坐标系odom、map 1.简介 2.特点 3.坐标系变换 2.3 导航条件说明 1.硬件 2.软件 3 导航实现 3.1 创建本篇博客的功能包 3.2 建图--gmapping 3.…...
C++中string类的使用
一.string类 1.1为什么学习string类? C 语言中,字符串是以 \0 结尾的一些字符的集合,为了操作方便, C 标准库中提供了一些 str 系列的库函数,但是这些库函数与字符串是分离开的,不太符合OOP 的思想&#x…...

LeeCode每日刷题12.8
搜索插入位置 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 示例 1: 输入: nums [1,3,5,6], target 5 输出: …...

硕士毕业论文格式修改要点_word
目录 0、最开始要做的事情1、更改样式(先善器)2、多级标题(解决自动更新问题必要的基础设置)2、插入图片(1)设置一个图片样式——“无间隔”(2)插入题注(3)修…...

远红外温和护理,一贴缓解痛风不适
在冬天,很多人都会因为痛风等原因引起的关节炎症而感到不适,因为关节疼痛、肢体麻木等问题会对生活质量造成很大的影响。市场上缓解关节酸痛的护理品很多,常见的应该还是关节贴,我现在用的就是何浩明关节痛风贴。 相比于同类产品&…...

当“画笔”变成“画笔”,世界便不再扁平:上海科技大学师玉娇团队 BevSplat 论文深度解读
用高斯画笔为地面图像“补上高度”,让卫星图片与街景的配对不再尴尬 想象一下这幅情境:一辆自动驾驶汽车在密集的城市楼群中行驶。GPS 信号被摩天大楼遮挡得断断续续,车辆根本无法准确知道自己的位置。于是,它需要一种备用方案&am…...

长期使用Taotoken Token Plan套餐带来的成本节约感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐带来的成本节约感受 1. 项目背景与成本挑战 我们团队负责一个持续进行文本分析与内容生成的内部…...

QMCDecode:解锁你的QQ音乐收藏,让加密音频重获自由
QMCDecode:解锁你的QQ音乐收藏,让加密音频重获自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录ÿ…...

Beyond Compare 5完整激活教程:3种方法快速生成永久授权密钥
Beyond Compare 5完整激活教程:3种方法快速生成永久授权密钥 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 还在为Beyond Compare 5的30天试用期结束后无法继续使用而烦恼吗&#x…...

构建 AI Agent Harness Engineering 时常见的十个错误
构建 AI Agent Harness Engineering 时常见的十个错误 | 从翻车案例到生产级落地最佳实践 引入:85%的Agent上线失败,问题都出在「缰绳」上 2024年Q2,国内某股份制银行上线的智能理财顾问Agent,上线仅3天就触发了3起严重合规事故:风险承受能力等级为C1(最低风险等级)的用…...

如何3步实现视频字幕精准提取:video-subtitle-extractor终极指南
如何3步实现视频字幕精准提取:video-subtitle-extractor终极指南 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕区域检测…...

别光看教程!用mdadm管理软RAID时,这5个运维坑我帮你踩过了
别光看教程!用mdadm管理软RAID时,这5个运维坑我帮你踩过了在虚拟化环境和物理服务器中,软RAID因其成本效益和灵活性成为许多企业的首选方案。然而,从创建到长期运维,mdadm管理的软RAID阵列隐藏着诸多教科书上不会提及的…...

MAPED技术:电子衍射材料表征的创新方法
1. MAPED技术概述:电子衍射领域的革新方法多角度进动电子衍射(Multi-angle Precession Electron Diffraction, MAPED)是近年来在材料表征领域兴起的一项创新技术。这项技术通过采集不同入射角度的4D-STEM扫描数据,并在后期处理中进…...

全局退火算法:用神经网络驱动蒙特卡洛,突破组合优化瓶颈
1. 全局退火算法:为什么我们需要一种新的优化范式?在组合优化和统计物理领域,我们经常面对一个看似简单、实则令人头疼的核心问题:如何在一个由无数个可能状态构成的、崎岖不平的“能量景观”中找到那个最低的谷底——也就是全局最…...

AlphaEvolve:LLM与进化算法融合的自动代码优化系统
1. 项目概述:AlphaEvolve系统架构与核心思想AlphaEvolve代表了当前算法自动优化领域最前沿的技术突破。这个由Google DeepMind团队开发的系统,创造性地将大语言模型(LLM)的代码生成能力与进化算法的迭代优化机制相结合,形成了一个自主进化的编…...