C++ 关联容器
关联容器
关联容器支持高效的关键字查找和访问。
两个主要的关联容器(associative container)类型是 map 和 set。
map 中的元素是一些关键字——值对。
关键字起到索引的作用,值则表示与索引相关联的数据。
set 中的每个元素只包含一个关键字。
set 支持高效的关键字查询操作——检查一个给定关键字是否在 set 中。
标准库提供 8 个关联容器:
| 容器 | 功能 |
|---|---|
| map | 关联数组:保存关键字——值对 |
| set | 关键字即值,即只保存关键字的容器 |
| multimap | 关键字可重复出现的map |
| multiset | 关键字可重复出现的set |
| unordered_map | 用哈希函数组织的map |
| unordered_set | 用哈希函数组织的set |
| unordered_multimap | 哈希函数组织的map,关键字可重复出现 |
| unordered_multiset | 哈希函数组织的set,关键字可重复出现 |
允许重复关键字的容器的名字中包含 mutli;不保持关键字按顺序存储的容器的名字都以单词 unordered 开头。
map 和 mutlimap 定义在头文件 map 中;set 和 mutliset 定义在头文件 set 中;无序容器则定义在头文件 unordered_map 和 unordered_set 中。
关联容器概述
定义关联容器
默认初始化
map <int, string> M1;set <char> Set;
列表初始化
当初始化一个 map 时,必须提供关键字类型和值类型;每一个关键字—值对包围在花括号中‘{ key , value }’来指出它们一起构成了 map 中的一个元素。
map <int, string> M1 {{1,"C++"},{2,"Java"},{5,"Python"}};
当初始化一个 set 时,只需提供关键字类型,关键字类型就是元素类型。
set <char> Set1 { 'A','B','C' };
一个 map 或 set 中的关键字必须是唯一的;容器 mulitmap 和 mulitset 没有这个限制,它们都允许多个元素具有相同的关键字。
map <int, string> M1{{100,"C++"},{2,"Java"},{100,"Python"},{100,"C"}};cout <<M1.size() << endl; // 内含 2 个元素multimap <int, string> M2{{100,"C++"},{2,"Java"},{100,"Python"},{100,"C"}};cout << M2.size() << endl; // 内含 4 个元素set <char> Set1{ 'A','B','C','B','B' };cout << Set1.size() << endl; // 内含 3 个元素multiset <char> Set2{ 'A','B','C','B','B' };cout << Set2.size() << endl; // 内含 5 个元素
将一个新容器创建为另一个容器的拷贝
拷贝整个容器
map <int, string> M1 {{1,"C++"},{2,"Java"},{5,"Python"}};map <int, string> M2{ M1 };set <char> Set1 { 'A','B','C' };set <char> Set2 { Set1 };
拷贝迭代器指定范围中的元素
map <int, string> M1 {{1,"C++"},{2,"Java"},{5,"Python"}};map <int, string> M2{ M1.begin(),M2.end() };set <char> Set1 { 'A','B','C' };set <char> Set3{ Set1.begin(),Set1.end() };
有序容器的关键字类型的要求
对于有序容器,关键字类型必须定义元素比较的方法。
默认情况下,标准库使用关键字类型的<运算符来比较两个关键字。
向算法提供的自定义比较操作必须在关键字类型上定义一个严格偌序(strict weak ordering)。
自定义的比较操作必须具备如下基本性质:
- 两个关键字不能同时“小于等于”对方;如果 k1 “小于等于” k2,那么 k2 绝不能“小于等于” k1。
- 如果 k1 “小于等于” k2,且 k2 “小于等于” k3,那么 k1 必须“小于等于” k3。
- 如果存在两个关键字,任何一个都不“小于等于”另一个,那么我们称这两个关键字是“等价”的。
- 如果 k1 “等价于” k2,且 k2 “等价于” k3,那么 k1 必须“等价于” k3。
pair 类型
名为 pair 的标准库类型,定义在头文件 utility 中。
pair 是一个用来生成特定类型的模版。
一个 pair 保存两个数据成员。
当创建一个 pair 时,必须提供两个类型名,两个类型不要求一样。
pair <int, char> p; //未指定成员的初始值,则进行值初始化pair <int, char> p{ 10,'A' }; //指定成员的初始值auto p = make_pair(1,'A'); //返回一个指定了成员初始值的 pair
pair 的两个数据成员是 public 的,两个成员分别命名为 first 和 second,使用普通的成员访问符来访问它们。
pair <int, char> p{ 10,'A' };cout << p.first << endl; //输出 10cout << p.second << endl; //输出 A
关联容器迭代器
当解引用一个关联容器迭代器时,会得到一个类型为容器的 value_type 值的引用。
对于 map 而言,value_type 是一个 pair 类型,其 first 成员保存 const 的关键字,second 成员保存值。
map <int, string> M1{{1,"C++"},{2,"Java"},{100,"Python"},{100,"C"}};auto map_it = M1.begin(); //value_type 值的引用cout<< map_it->first <<endl; //输出 1,关键字值不允许修改cout << map_it->second << endl; //输出 C++
对于 set 而言,value_type 与 key_type 相同。
set <char> Set1 {'A', 'B', 'C'};auto set_it = Set1.begin();cout << *set_it << endl; //输出 A,关键字值不允许修改
遍历关联容器
当使用迭代器遍历有序容器时,迭代器按关键字升序遍历元素。
map
map <int, string> M1{{5,"C++"},{2,"Java"},{100,"Python"},{10,"C"}};auto map_it = M1.cbegin();while ( map_it != M1.cend() ){cout <<'{'<< map_it->first <<',' << map_it->second << '}'<<' ';map_it++;}/*输出:{2,"Java"} {5,"C++"} {10,"C"} {100,"Python"}*/
set
set <char> Set1 {'D', 'B', 'A','C'};auto set_it = Set1.cbegin();while ( set_it != Set1.cend() ){cout << *set_it++ << ' ';}/*输出:A B C D*/
map的下标操作
map 和 unordered_map 容器提供了下标运算符和一个对应的 at 函数。
不能对一个 mutlimap 或 unordered_mutlimap 进行下标操作,因为该容器中可能有多个值与一个关键字相关联。
set 容器不支持下标访问,因为 set 中没有与关键字相关的值。
map 下标运算符接收一个索引(即,关键字)获取与此索引相关联的值。
map <char, string> M1{{'A',"C++"},{'C',"Java"},{'D',"Python"},{'F',"C"}};cout << M1['A'] << endl; //输出 C++cout << M1.at('C') << endl; //输出 Java
如果索引(关键字)并不在 map 中,下标运算符会为它创建一个元素并插入到 map 中,关联值将进行值初始化。
map <int, char> M1{{1,'A'},{3,'B'},{5,'F'}};cout << (int)M1[2] << endl; //输出 0
如果索引(关键字)并不在 map 中,at 函数会抛出一个 out_of_range 异常。
当对一个 map 进行下标操作时,会获得一个 mapped_type 对象。
下标运算符和 at 函数只适用于非 const 的 map 和 unordered_mutlimap。
关联容器查找
对 map 使用 find 代替下标操作
成员函数 find 返回一个迭代器,指向第一个关键字为 k 的元素,若 k 不在容器中,则返回尾后迭代器
map <char, string> M1{{'A',"C++"},{'C',"Java"},{'D',"Python"},{'F',"C"}};auto map_it = M1.find('C');cout << map_it->second << endl; //输出 Java
lower_bound 和 upper_bound
成员函数 lower_bound 和 upper_bound 不适用于无序容器。
成员函数 lower_bound 返回一个迭代器,指向第一个关键字不小于 k 的元素。
map <char, string> M1{{'A',"C++"},{'C',"Java"},{'D',"Python"},{'F',"C"}};auto map_it = M1.lower_bound('C');cout << map_it->second << endl; //输出 Java
成员函数 upper_bound 返回一个迭代器,指向第一个关键字大于 k 的元素。
map <char, string> M1{{'A',"C++"},{'C',"Java"},{'D',"Python"},{'F',"C"}};auto map_it = M1.upper_bound('C');cout << map_it->second << endl; //输出Python
在 multimap 或 multiset 中查找元素
方法一:
成员函数 count 返回关键字等于 k 的元素的数量;对于不允许重复关键字的容器,返回值永远是 0 或 1.
multimap <char, string> M1{{'A',"C++"},{'B',"Java"},{'B',"Python"},{'B',"C"}};/*输出所有与关键字'B'相关联的值 */auto map_it = M1.find('B');for (int i = 0; i < M1.count('B'); ++i){cout << map_it->second << ' ';map_it++;}
方法二:
multimap <char, string> M1{{'A',"C++"},{'B',"Java"},{'B',"Python"},{'B',"C"}};/*输出所有与关键字'B'相关联的值 */auto map_it = M1.lower_bound('B');/*如果 lower_bound 和 upper_bound 返回相同的迭代器,则给定关键字不在容器中*/while ( map_it != M1.upper_bound('B') ){cout << map_it->second << endl;map_it++;}
方法三:
成员函数 equal_range 返回一个迭代器 pair,表示关键字等于 k 的元素的范围;若 k 不存在,pair 的两个成员均等于尾后迭代器。
multimap <char, string> M1{{'A',"C++"},{'B',"Java"},{'B',"Python"},{'B',"C"}};/*输出所有与关键字'B'相关联的值 */auto p = M1.equal_range('B');multimap <char, string>::iterator map_it = p.first;while ( map_it != p.second ){cout << map_it->second << endl;map_it++;}
向关联容器添加元素
向关联容器中插入一个元素。
map 的元素类型是 pair 类型。
map <char, string> M1;M1.insert( {'A',"C++"} );M1.insert( make_pair('B',"Java") );M1.insert( pair <char, string> {'C', "Python"} );M1.insert( map <char, string>::value_type{ 'D',"C" } );set <char> Set;Set.insert('B');Set.insert('A');
成员函数 insert 的返回值。
对于不包含重复关键字的容器,添加单一元素的 insert 的版本返回一个 pair 对象。
pair 的 first 成员是一个迭代器,指向具有给定关键字的元素;
pair 的 second 成员是一个 bool 值;
如果关键字已存在容器中,则 insert 什么都不做,bool 值为 false。
如果关键字不在容器中,则元素被插入到容器中,bool 值为 true。
map <char, string> M1;M1.insert( {'A',"C++"} );M1.insert( make_pair('B',"Java") );auto p = M1.insert( { 'A',"C++" } );cout << p.first->second << endl; // 输出 C++cout << p.second << endl; // 输出 0
向关联容器中插入一个花括号包围的元素值列表。
vector <int> V1{ 1,3,5,7,9 };set <int> Set;Set.insert({ 2,4,6,8,10 });
向关联容器中插入一对迭代器指定范围的所有元素;第一个迭代器指向要插入的第一个元素,第二个迭代器指向要插入的最后一个元素之后的位置。
vector <int> V1{ 1,3,5,7,9 };set <int> Set;Set.insert( V1.begin(), V1.end() );
删除元素
成员函数 erase 从容器中删除每个与关键字 k 相关联的元素;返回一个 size_type 值,指出删除的元素的数量。
map <char, string> M1{{'A',"C++"},{'C',"Java"},{'D',"Python"},{'F',"C"}};M1.erase('A'); //删除 {'A',"C++"}set <char> Set{ 'B','C','D','E','A' };Set.erase('B'); //删除 B
成员函数 erase 从容器中删除迭代器 p 指向的元素;p 必须指向容器中一个真实元素;返回一个指向 p 之后元素的迭代器。
map <char, string> M1{{'A',"C++"},{'C',"Java"},{'D',"Python"},{'F',"C"}};M1.erase( M1.begin(),M1.end() ); //删除所有元素set <char> Set{ 'B','C','D','E','A' };auto set_its = Set.end();--set_its;Set.erase( Set.begin(),set_its ); //删除 A B C D成员函数 erase 删除一对迭代器指定范围内的所有元素;返回指向被删除的元素之后位置的迭代器。
map <char, string> M1{{'A',"C++"},{'C',"Java"},{'D',"Python"},{'F',"C"}};auto map_its = M1.begin();++map_its;M1.erase(map_its); //删除 {'C',"Java"}set <char> Set{ 'B','C','D','E','A' };auto set_its = Set.end();--set_its;Set.erase( set_its ); //删除 E
删除容器内所有的元素
成员函数 clear 删除容器内所有元素。
set <char> Set{ 'B','C','D','E','A' };Set.clear();
无序容器
有序容器使用关键字类型的比较运算符来组织元素。
无序容器使用哈希函数和关键字类型的==运算符来组织元素。
管理桶
无序容器在存储上组织为一组桶,每个桶保存零个或多个元素。
无序容器使用一个哈希函数将元素映射到桶。
无序容器将具有一个特定哈希值的所有元素都保存在相同的桶中;如果容器允许重复关键字,所有具有相同关键字的元素也都会在同一个桶中。
为了访问容器中一个元素,容器首先计算元素的哈希值,它指出应该搜索哪个桶。
无序容器提供了一组管理桶的函数:
桶接口
| 成员函数 | 功能 |
|---|---|
| bucket_count () | 正在使用的桶的数目 |
| max_bucket_count () | 容器能容纳的最多的桶的数量 |
| bucket_size (n) | 第 n 个桶中有多少个元素 |
| bucket (k) | 关键字为 k 的元素在哪个桶中 |
桶迭代
| 成员 | 功能 |
|---|---|
| local_iterrator | 可以用来访问桶中元素的迭代器类型 |
| const_local_iterrator | 桶迭代器的 const 版本 |
| begin (n) | 桶 n 的首元素迭代器 |
| end (n) | 桶 n 的尾后迭代器 |
| cbegin (n) | 桶 n 的首元素迭代器,返回 const_local_iterrator |
| cend (n) | 桶 n 的尾后迭代器,返回 const_local_iterrator |
哈希策略
| 成员函数 | 功能 |
|---|---|
| load_factor () | 每个桶的平均元素数量,返回 float 值 |
| max_load_factor () | 容器试图维护的平均桶大小,返回 float 值;容器会在需要时添加新桶,使得 load_factor () <= max_load_factor () |
| rehash (n) | 重组存储,使得 bucket_count >= n 且 bucket_count >size/max_load_factor () |
| reserve (k) | 重组存储,使得容器可以保存 n 个元素且不必 rehash |
这些成员函数允许我们查询容器的状态以及在必要时强制容器进行重组。
相关文章:

C++ 关联容器
关联容器 关联容器支持高效的关键字查找和访问。 两个主要的关联容器(associative container)类型是 map 和 set。 map 中的元素是一些关键字——值对。 关键字起到索引的作用,值则表示与索引相关联的数据。 set 中的每个元素只包含一个关键…...

ES6之函数新增的扩展
参数 ES6允许为函数的参数设置默认值 function log(x, y World) {console.log(x, y); }console.log(Hello) // Hello World console.log(Hello, China) // Hello China console.log(Hello, ) // Hello函数的形参是默认声明的,不能使用let或const再次声明 functi…...

postgresql安装部署(docker版本)
1.在线部署 创建数据库存储目录 mkdir /home/pgdata创建容器 docker run --name postgresql --restartalways -d -p 5432:5432 -v /home/pgdata:/var/lib/postgresql/data --shm-size10g -e POSTGRES_PASSWORD密码 postgis/postgis:12-3.2-alpine–name为设置容器名称 -d表…...

【Python/Java/C++三种语言】20天拿下华为OD笔试之【位运算】2023B-出错的或电路【欧弟算法】全网注释最详细分类最全的华为OD真题
文章目录 题目描述与示例题目描述输入描述输出描述示例一输入输出说明 示例二输入输出说明 解题思路代码PythonJavaC时空复杂度 华为OD算法/大厂面试高频题算法练习冲刺训练 题目描述与示例 题目描述 某生产门电路的厂商发现某一批次的或门电路不稳定,具体现象为计…...
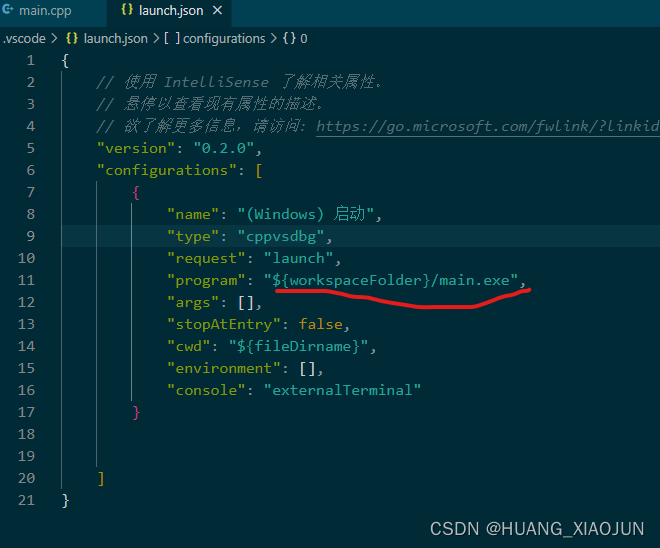
vscode 编译运行c++ 记录
一、打开文件夹,新建或打开一个cpp文件 二、ctrl shift p 进入 c/c配置 进行 IntelliSense 配置。主要是选择编译器、 c标准, 设置头文件路径等,配置好后会生成 c_cpp_properties.json; 二、编译运行: 1、选中ma…...

错题总结(四)
1.【一维数组】输入10个整数,求平均值 编写一个程序,从用户输入中读取10个整数并存储在一个数组中。然后,计算并输出这些整数的平均值。 int main() {int arr[10];int sum 0;for (int n 0; n < 10; n){scanf("%d", &arr…...
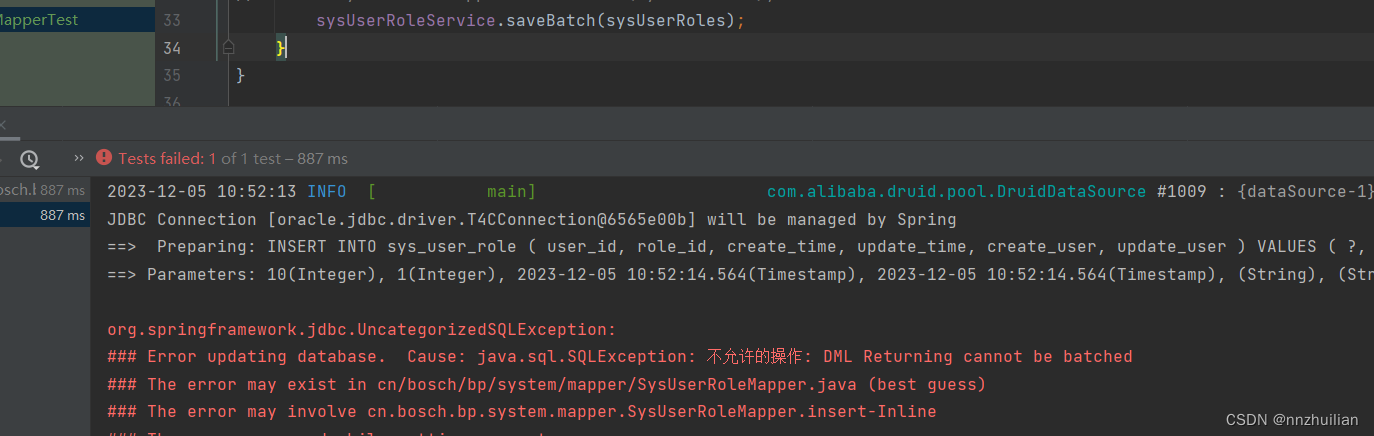
ORACLE使用Mybatis-plus批量插入
ORACLE使用mybatis-plus自带的iservice.saveBatch方法时,会报DML Returing cannot be batch错误: 推测原因是oracle不支持insert into table_name (,) values (,),()的写法。且oracle不会自动生…...

vue,uniapp的pdf等文件在线预览
vue,uniapp文件在线预览方案,用了个稍微偏门一点的方法实现了 通过后端生成文件查看页面,然后前端只要展示这个网页就行,uniapp就用web-view来展示,后台系统就直接window.open()打开就行 示例查看PDF文件,…...
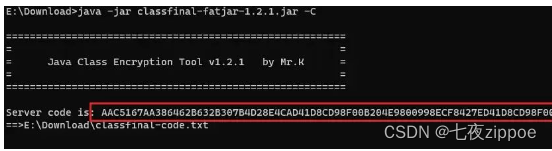
SpringBoot 项目 Jar 包加密,防止反编译
1场景 最近项目要求部署到其他公司的服务器上,但是又不想将源码泄露出去。要求对正式环境的启动包进行安全性处理,防止客户直接通过反编译工具将代码反编译出来。 2方案 第一种方案使用代码混淆 采用proguard-maven-plugin插件 在单模块中此方案还算简…...

DockerFile中途执行出错的解决办法
DockerFile中途执行出错的解决办法 你们是否也曾经因为DockerFile中途执行出错,而对其束手无策?总是对docker避之不及! 但是当下载的源码运用到了docker,dockerFile 执行到一半,报错了怎么办? 现状 那么当DockerFile执行一半出错后,会产生什么结果呢? 如图可知,生成…...

Word插件-好用的插件-一键设置字体--大珩助手
常用字体 整理了论文、公文常用字体 整理了常用的论文字体,可一键设置当前节或选择的文字的字体 字体设置 包含字体选择、字体颜色 特殊格式 包含首字下沉、段落分栏、统一宽度、双行合一、上标切换、下标切换、转为全角、转为半角、挖词填空、当前日期、大写金…...

【MODBUS】Modbus主站云端服务器和边缘设备部署区别
Modbus主站作为云端服务器: 云端服务器作为主站: 在这种部署方式中,云端服务器充当Modbus通信的主站,负责向不同的Modbus从站发起请求,并处理响应。云端服务器通常与其他云服务一起运行,可以在云平台上实现…...
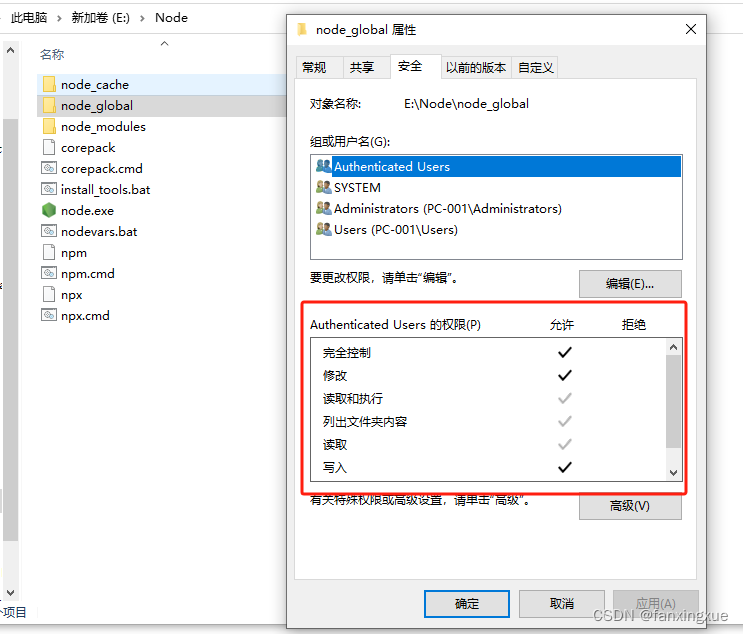
hbuiler中使用npm安装datav
注:datav边框样式目前使用时:适用于网页,不适用于app 1、先安装node 安装、配置Node路径 2、为Node配置环境变量 3、在hbuilder的设置中填写node的路径 配置 4、打开cmd输入npm install jiaminghi/data-view 安装dataV,&…...
贾佳亚团队新作LLaMA-VID,2token让大模型学会看好莱坞大片
家人们谁懂,连大模型都学会看好莱坞大片了,播放过亿的GTA6预告片大模型还看得津津有味,实在太卷了! 而让LLM卷出新境界的办法简单到只有2token——将每一帧编码成2个词即可搞定。等等!这种大道至简的方法有种莫名的熟…...

【数据结构】手撕排序
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《Linux》《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 文章目录 一、排序的概念及其运用1.1 排序的概念1.2 常见的算法排序 二、 冒泡排序三、直接插入排…...

运维05:自动化
人工运维时代 运维人员早期需要维护众多的机器,因此需要执行很多重复的劳动,很多机器需要同时部署相同的服务或者是执行相同的命令,还得反复地登录不同的机器,执行重复的动作 自动化运维时代 早期运维人员会结合ssh免密登录&…...
OpenCL学习笔记(一)开发环境搭建(win10+vs2019)
前言 异构编程开发,在高性能编程中有重要的,笔者本次只简单介绍下,如何搭建简单的开发环境,可以供有需要的小伙伴们开发测试使用 一、获取opencl的sdk库 1.使用cuda库 若本机有Nvidia的显卡,在安装cuda库后&#x…...

寻找两个正序数组的中位数
更好的阅读体验,请点击 YinKai s Blog。 题目:寻找两个正序数组的中位数 给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。 算法的时间复杂度应该为 O(log (mn)) 。 …...

探索低代码的潜力、挑战与未来展望
低代码开发作为一种新兴的开发方式,正在逐渐改变着传统的编程模式,低代码使得开发者无需编写大量的代码即可快速构建各种应用程序。然而,低代码也引发了一系列争议,有人称赞其为提升效率的利器,也有人担忧其可能带来的…...
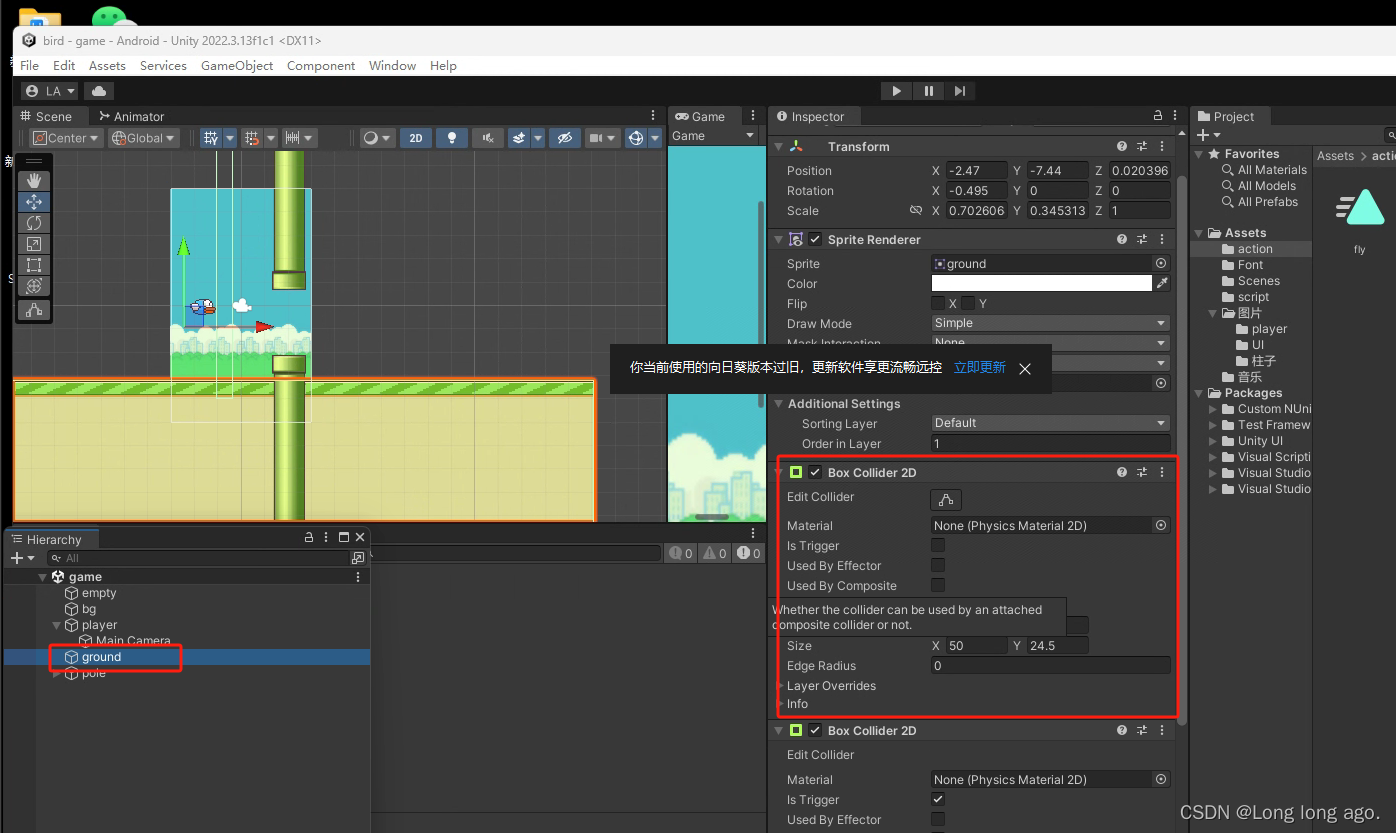
unity 2d 入门 飞翔小鸟 小鸟碰撞 及死亡(九)
1、给地面,柱体这种添加2d盒装碰撞器,小鸟移动碰到就不会动了 2、修改小鸟的脚本(脚本命名不规范,不要在意) using System.Collections; using System.Collections.Generic; using UnityEngine;public class Fly : Mo…...

3分钟快速上手Vin象棋:基于YOLOv5的智能中国象棋连线工具终极指南
3分钟快速上手Vin象棋:基于YOLOv5的智能中国象棋连线工具终极指南 【免费下载链接】VinXiangQi Xiangqi syncing tool based on Yolov5 / 基于Yolov5的中国象棋连线工具 项目地址: https://gitcode.com/gh_mirrors/vi/VinXiangQi 你是否厌倦了手动记录棋局的…...

如何快速掌握Vanna AI:新手完整指南从零构建智能数据库查询系统
如何快速掌握Vanna AI:新手完整指南从零构建智能数据库查询系统 【免费下载链接】vanna 🤖 Chat with your SQL database 📊. Accurate Text-to-SQL Generation via LLMs using Agentic Retrieval 🔄. 项目地址: https://gitcod…...

5大核心功能+3个实战技巧:ESP32原生USB开发的全面指南
5大核心功能3个实战技巧:ESP32原生USB开发的全面指南 【免费下载链接】EspTinyUSB ESP32S2 native USB library. Implemented few common classes, like MIDI, CDC, HID or DFU (update). 项目地址: https://gitcode.com/gh_mirrors/es/EspTinyUSB 想让你的E…...
)
AI Agent驱动的管理咨询实战手册(麦肯锡/BCG未公开方法论首次披露)
更多请点击: https://intelliparadigm.com 第一章:AI Agent驱动的管理咨询范式革命 传统管理咨询依赖专家经验、手工访谈与静态模型,响应周期长、知识复用率低、规模化交付困难。AI Agent 的崛起正从根本上重构这一价值链——它不再是辅助工…...

生产环境救急指南:当Navicat连不上时,用MongoDB Shell命令行搞定一切
生产环境救急指南:当Navicat连不上时,用MongoDB Shell命令行搞定一切 凌晨三点,服务器告警突然响起——某个关键服务因数据库查询超时而崩溃。你迅速打开Navicat准备排查,却发现生产环境的安全策略早已屏蔽了所有图形化工具的直接…...

Beam Search超参数调优指南:从原理到实践,如何为你的NLP任务选择最佳beam width?
Beam Search超参数调优实战:如何在生成质量与推理效率间找到平衡点 当GPT-3生成那段令人惊艳的诗歌时,背后其实经历了几百次候选序列的评估与筛选——这正是beam search算法的魔力所在。作为自然语言生成任务中最核心的解码策略之一,beam wid…...

大麦网自动抢票神器:5分钟配置,告别抢票焦虑的终极指南
大麦网自动抢票神器:5分钟配置,告别抢票焦虑的终极指南 【免费下载链接】ticket-purchase 大麦自动抢票,支持人员、城市、日期场次、价格选择 项目地址: https://gitcode.com/GitHub_Trending/ti/ticket-purchase 还在为心仪演唱会门票…...

Bebas Neue字体完全指南:免费商用的现代设计利器
Bebas Neue字体完全指南:免费商用的现代设计利器 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue 还在寻找一款能为你的设计项目增添专业感的免费字体吗?Bebas Neue字体库正是你需要的完美…...
)
第一次通过通讯节点连接实现无人机仿真模拟(ROS1 + C++ + PX4)
通过与chatGPT之间的交互,让其辅助我进行代码编写-------------------| C 控制节点 || (自主起飞/降落) |------------------|ROS Topic|------v------| MAVROS |------ -----|MAVLink|------v------| PX4 || 飞控 SITL |------------|仿真…...

windows下vs 2015 libtorrent库的配置,vs2015下-boost-openssl-libtorrent的配置
libtorrent依赖OpenSSL和boost库,首先要编译Openssl和boost库。 1、安装ActivePerl,下载地址:网上找。 安装完后配置环境变量(一般安装成功后,环境变量就已经配置好了,如果没有配置自己配置环境变量): …...