机器学习---Adaboost算法
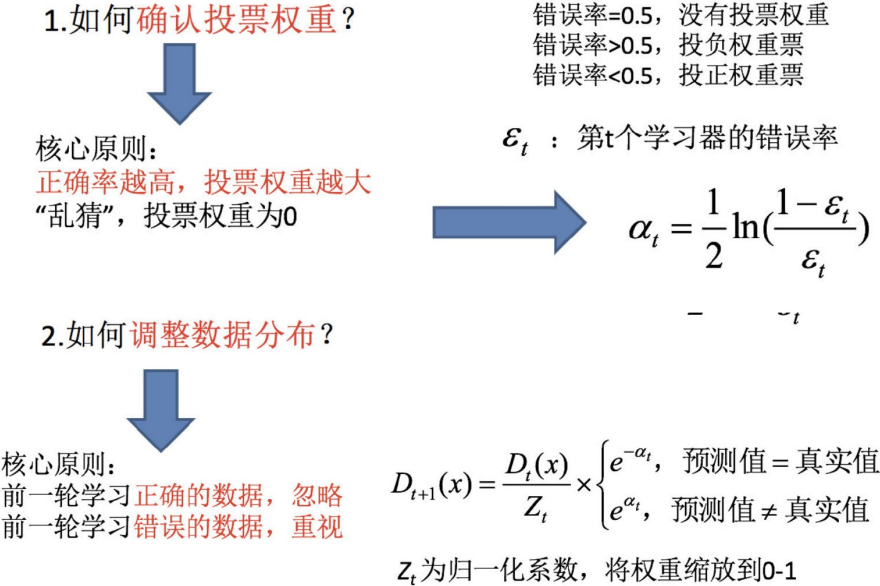
1. Adaboost算法介绍
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然
后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。Adaboost算法本身是通
过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类
的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每
次得到的分类器最后融合起来,作为最后的决策分类器。
目前,对Adaboost算法的研究以及应用大多集中于分类问题,同时近年也出现了一些在回归问题
上的应用。就其应用adaboost系列主要解决了:两类问题、多类单标签问题、多类多标签问题、大
类单标签问题,回归问题。它用全部的训练样本进行学习。使用adaboost分类器可以排除一些不必
要的训练数据特征,并将关键放在关键的训练数据上面。
该算法其实是一个简单的弱分类算法提升过程,这个过程通过不断的训练,可以提高对数据的分类
能力。
①先通过对N个训练样本的学习得到第一个弱分类器;
②将分错的样本和其他的新数据一起构成一个新的N个的训练样本,通过对这个样本的学习得到第
二个弱分类器;
③将1和2都分错了的样本加上其他的新样本构成另一个新的N个的训练样本,通过对这个样本的学
习得到第三个弱分类器
④最终经过提升的强分类器。即某个数据被分为哪一类要通过......的多数表决。
对于boosting算法,存在两个问题:
①如何调整训练集,使得在训练集上训练的弱分类器得以进行;
②如何将训练得到的各个弱分类器联合起来形成强分类器。
针对以上两个问题,AdaBoost算法进行了调整:
①使用加权后选取的训练数据代替随机选取的训练样本,这样将训练的焦点集中在比较难分的训练
数据样本上;
②将弱分类器联合起来,使用加权的投票机制代替平均投票机制。让分类效果好的弱分类器具有较
大的权重,而分类效果差的分类器具有较小的权重。
与Boosting算法不同的是,AdaBoost算法不需要预先知道弱学习算法学习正确率的下限即弱分类
器的误差,并且最后得到的强分类器的分类精度依赖于所有弱分类器的分类精度,这样可以深入挖
掘弱分类器算法的能力。
AdaBoost算法中不同的训练集是通过调整每个样本对应的权重来实现的。开始时,每个样本对应
的权重是相同的,即其中n为样本个数,在此样本分布下训练出一弱分类器。对于分类错误的样
本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被突显出来,从
而得到一个新的样本分布。在新的样本分布下,再次对样本进行训练,得到弱分类器。依次类推,
经过T次循环,得到T个弱分类器,把这T个弱分类器按一定的权重叠加(boost)起来,得到最终
想要的强分类器。
AdaBoost算法的具体步骤如下:
①给定训练样本集S,其中X和Y分别对应于正例样本和负例样本;T为训练的最大循环次数;
②初始化样本权重为1/n ,即为训练样本的初始概率分布;
③第一次迭代:(1)训练样本的概率分布相当,训练弱分类器;(2)计算弱分类器的错误率;(3)选取合
适阈值,使得误差最小;(4)更新样本权重;经T次循环后,得到T个弱分类器,按更新的权重叠
加,最终得到的强分类器。
Adaboost算法是经过调整的Boosting算法,其能够对弱学习得到的弱分类器的错误进行适应性
(Adaptive)调整。上述算法中迭代了T次的主循环,每一次循环根据当前的权重分布对样本x定一个
分布P,然后对这个分布下的样本使用弱学习算法得到一个弱分类器,对于这个算法定义的弱学习
算法,对所有的样本都有错误率,而这个错误率的上限并不需要事先知道,实际上。每一次迭代,
都要对权重进行更新。更新的规则是:减小弱分类器分类效果较好的数据的概率,增大弱分类器分
类效果较差的数据的概率。最终的分类器是个弱分类器的加权平均。
2. Adaboosting训练过程
基于AdaBoost算法的强分类器训练
输入:(1)训练样本集![]()
其中,y =-1,训练样本xi为负样本,y =+1,训练样本xi为正样本
(2)弱分类器的学习算法L
(3)弱分类器的数目M
输出:一个由M个弱分类器构成的强分类器
训练过程:
①初始化训练样本xi权重![]() 若正负样本数目一致,则
若正负样本数目一致,则![]()
若正负样本数目分别为N+,N-,则
②for m=1,...,M
训练弱分类器![]() 估计弱分类器fm(x)的分类错误率em,如:
估计弱分类器fm(x)的分类错误率em,如:
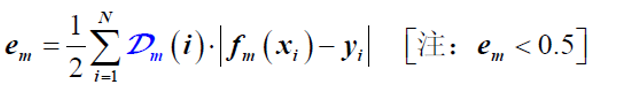
(3)估计弱分类器fm(x)的权重![]()
(4)基于弱分类器fm(x)调整各样本权重,并归一化调整:
归一化: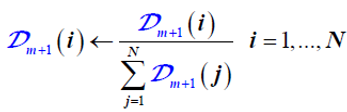 ,强分类器
,强分类器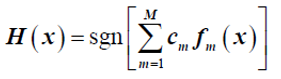 。
。
算法实现:

3. Adaboost算法例子
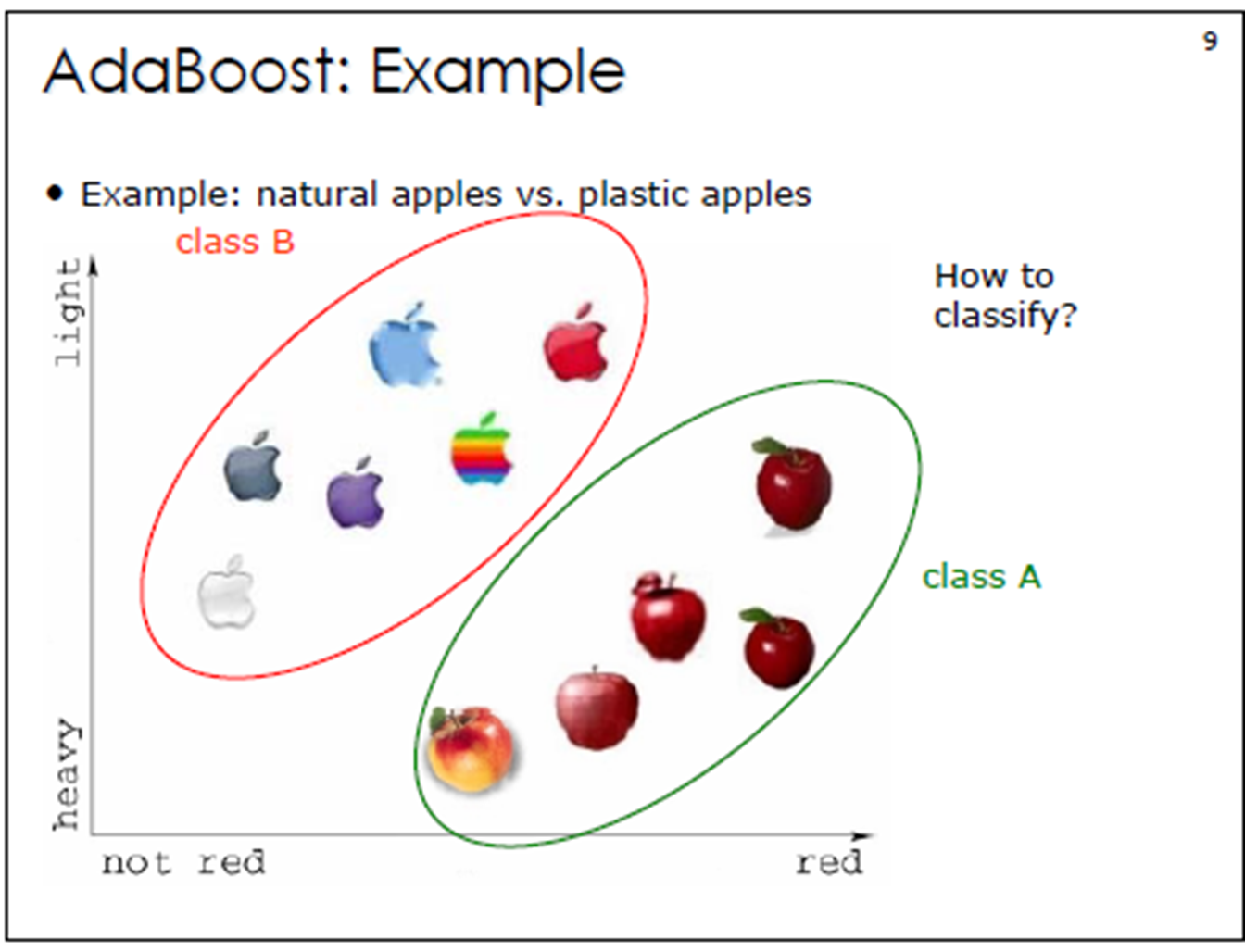






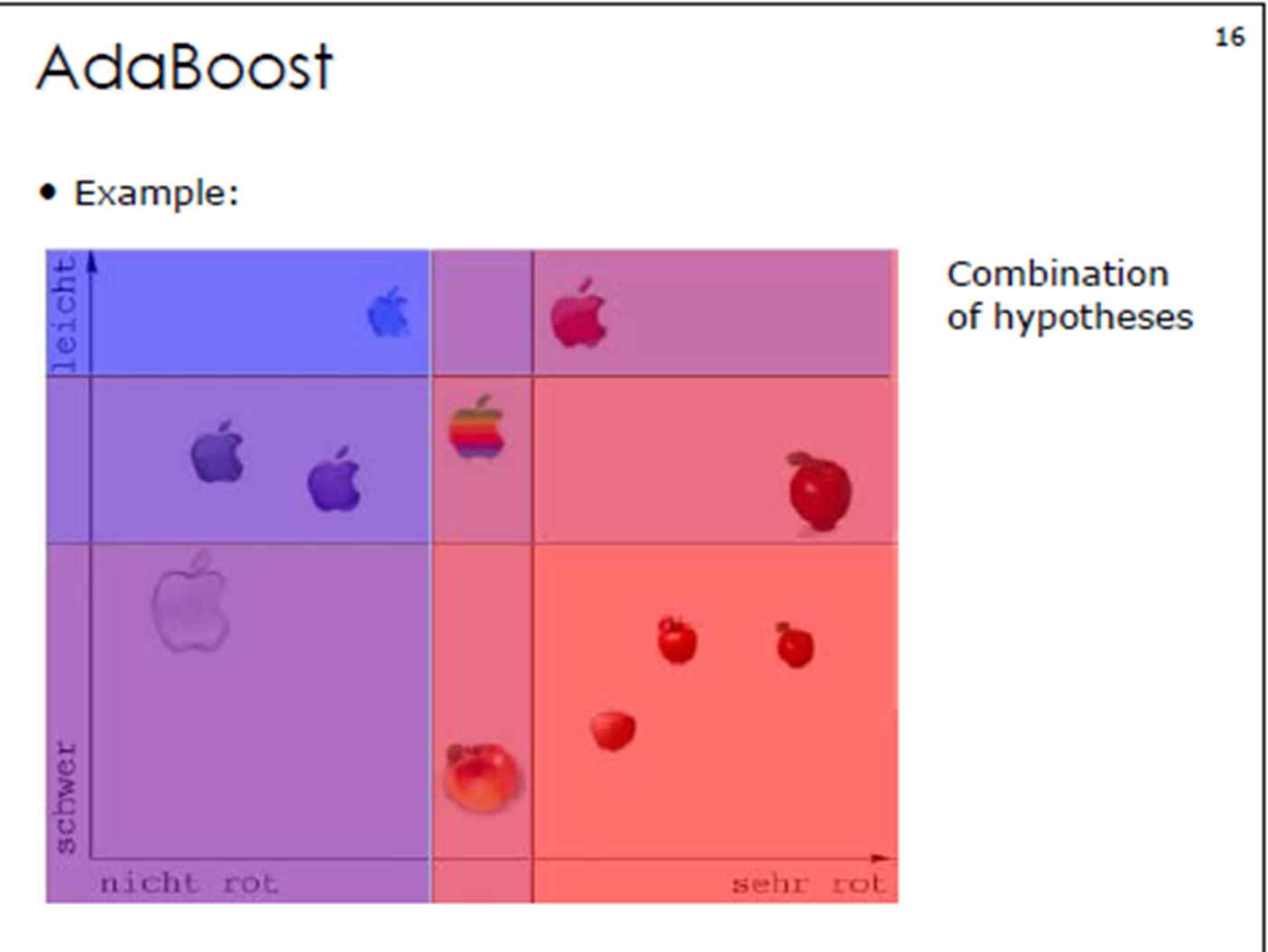
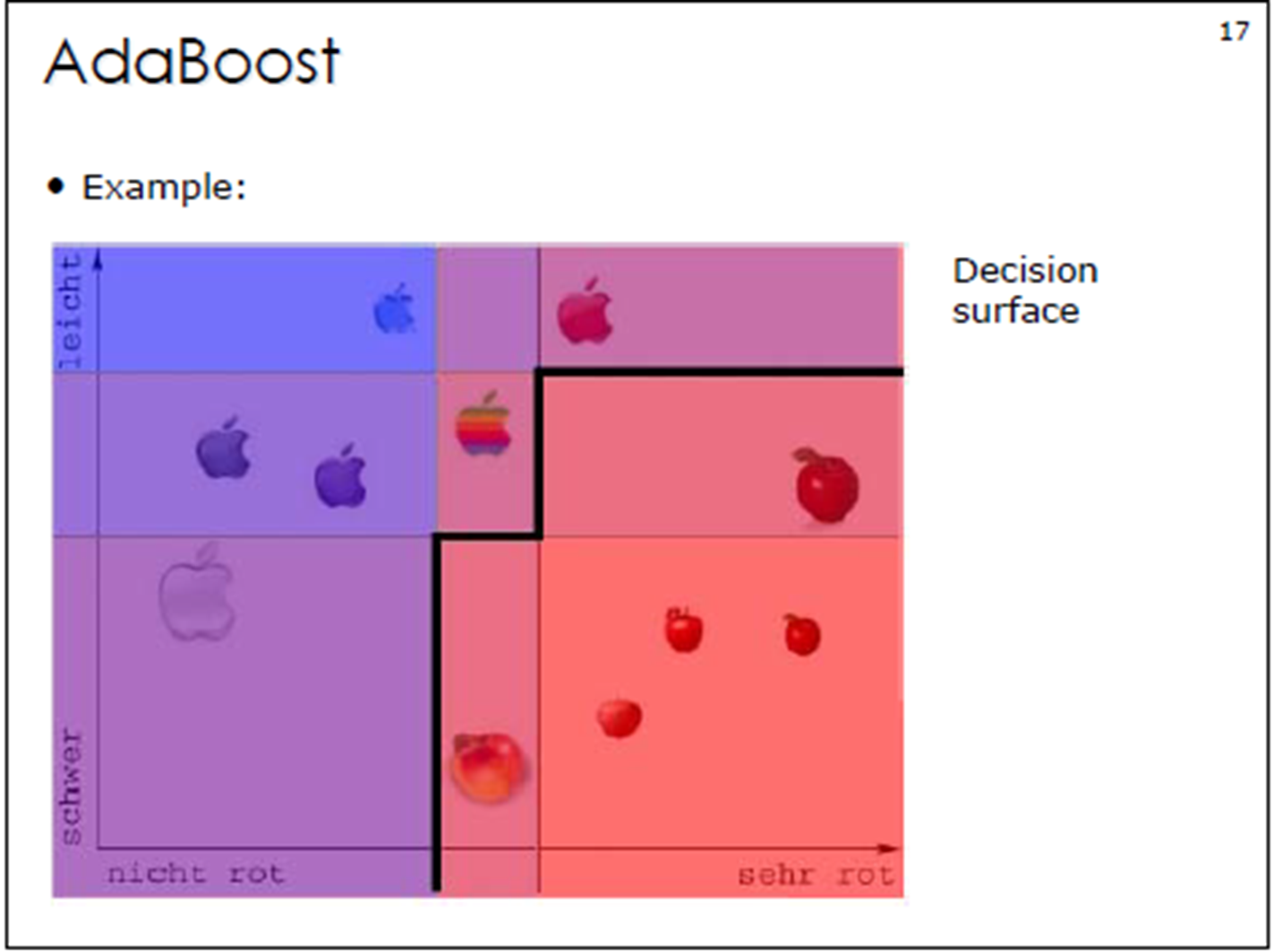
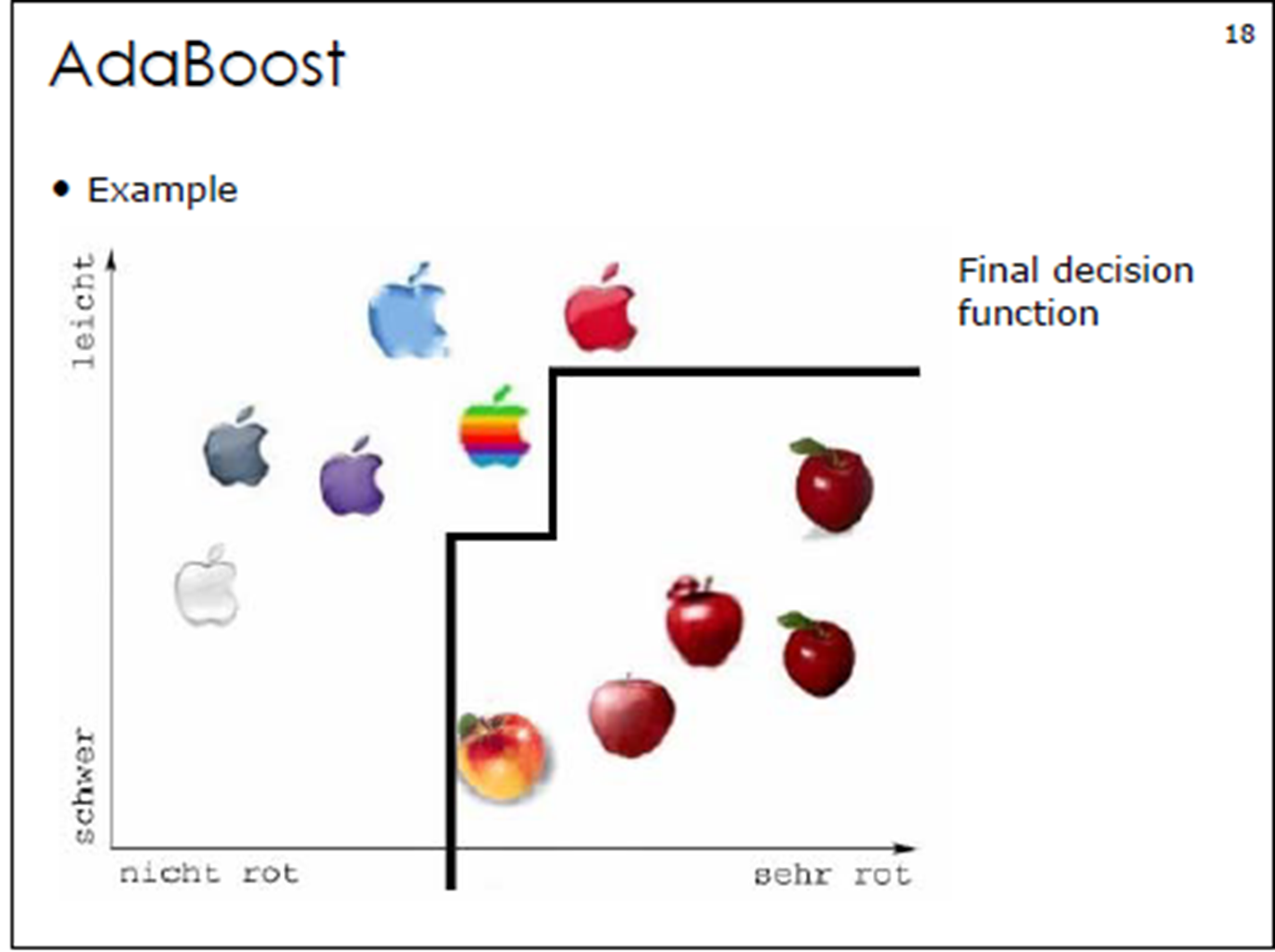
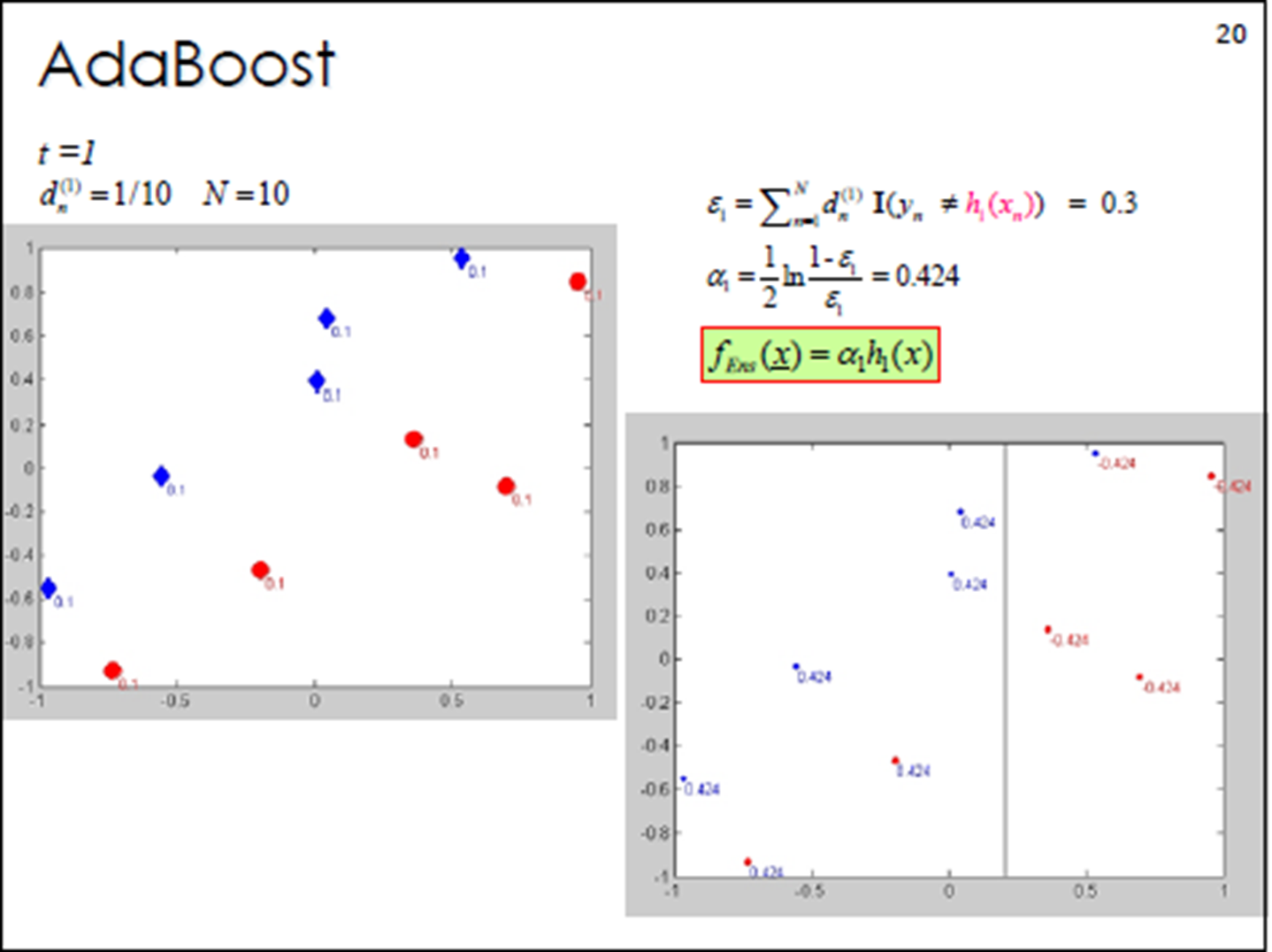
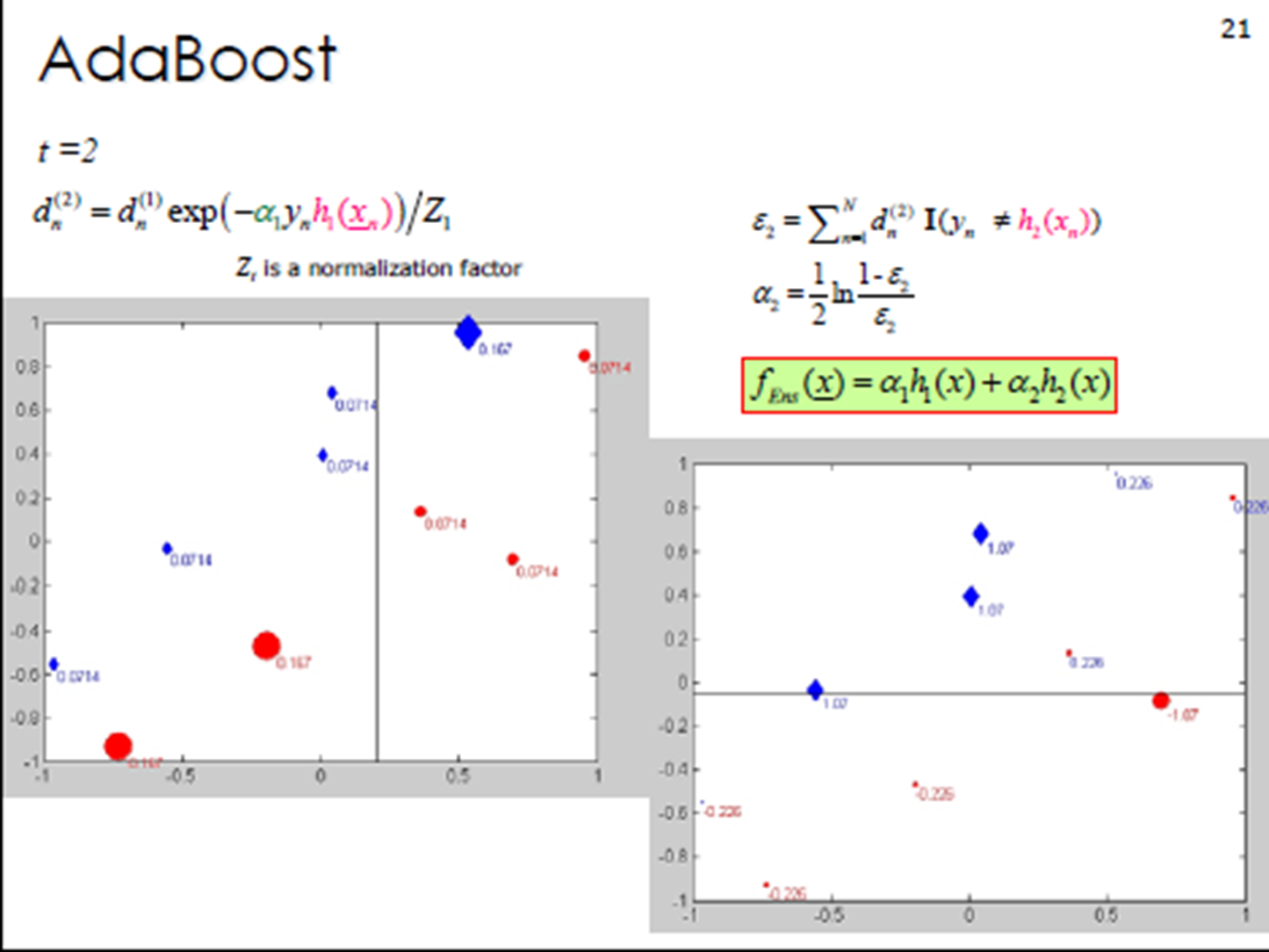
3. Adaboost算法计算案例
①初始化训练数据权重相等,训练第⼀个学习器。该假设每个训练样本在基分类器的学习中作用相
同,这⼀假设可以保证第⼀步能够在原始数据上学习基本分类器H1 (x)。
②AdaBoost反复学习基本分类器,在每⼀轮m = 1, 2, ..., M顺次的执⾏下列操作:
在权值分布为D的训练数据上,确定基分类器;
计算该学习器在训练数据中的错误率:![]()
计算该学习器的投票权重:![]()
根据投票权重,对训练数据重新赋权: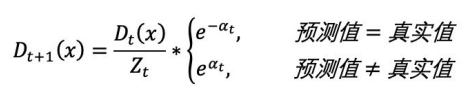
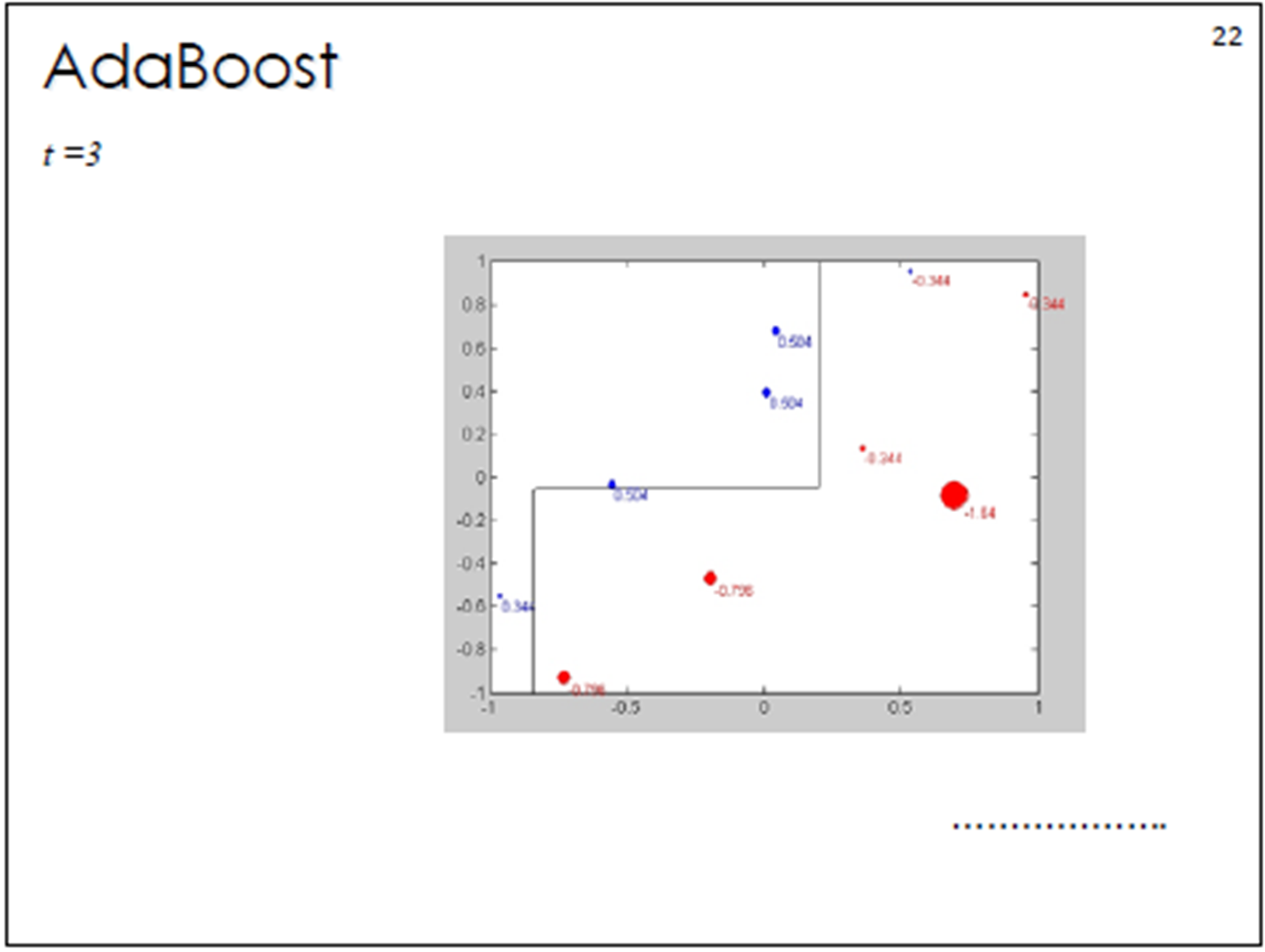
将下⼀轮学习器的注意⼒集中在错误数据上,重复执⾏上述计算步骤m次;
③对m个学习器进⾏加权投票: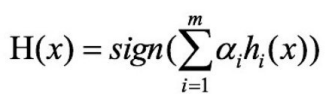
给定下⾯这张训练数据表所示的数据,假设弱分类器由xv产生,其阈值v使该分类器在训练数据集
上的分类误差率最低,试用Adaboost算法学习⼀个强分类器:

问题解答:
①初始化训练数据权重相等,训练第⼀个学习器:
![]()
![]()
②AdaBoost反复学习基本分类器,在每⼀轮m = 1, 2, ..., M顺次的执⾏下列操作:
当m=1的时候:在权值分布为D的训练数据上,阈值v取2.5时分类误差率最低,故基本分类器为:
![]() (6,7,8被分错)
(6,7,8被分错)
计算该学习器在训练数据中的错误率:![]()
计算该学习器的投票权重:![]()
根据投票权重,对训练数据重新赋权:![]()
根据下公式,计算各个权重值: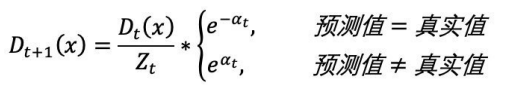
经计算得,D2的值为:![]()
计算过程: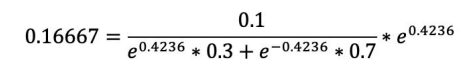
![]()
分类器H1(x)在训练数据集上有3个误分类点。
当m=2的时候:
在权值分布为D 的训练数据上,阈值v取8.5时分类误差率最低,故基本分类器为:
 (3,4,5被分错)
(3,4,5被分错)
计算该学习器在训练数据中的错误率:![]()
计算该学习器的投票权重:![]()
根据投票权重,对训练数据重新赋权:经计算得,D 的值为:

分类器H2(x)在训练数据集上有3个误分类点。
当m=3的时候:
在权值分布为D 的训练数据上,阈值v取5.5时分类误差率最低,故基本分类器为:
![]()
计算该学习器在训练数据中的错误率:![]()
计算该学习器的投票权重:![]()
根据投票权重,对训练数据重新赋权:经计算得,D4的值为:

分类器H3(x)在训练数据集上的误分类点个数为0。
③对m个学习器进行加权投票,获取最终分类器:
![]()
相关文章:
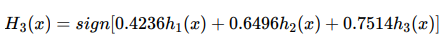
机器学习---Adaboost算法
1. Adaboost算法介绍 Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然 后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。Adaboost算法本身…...
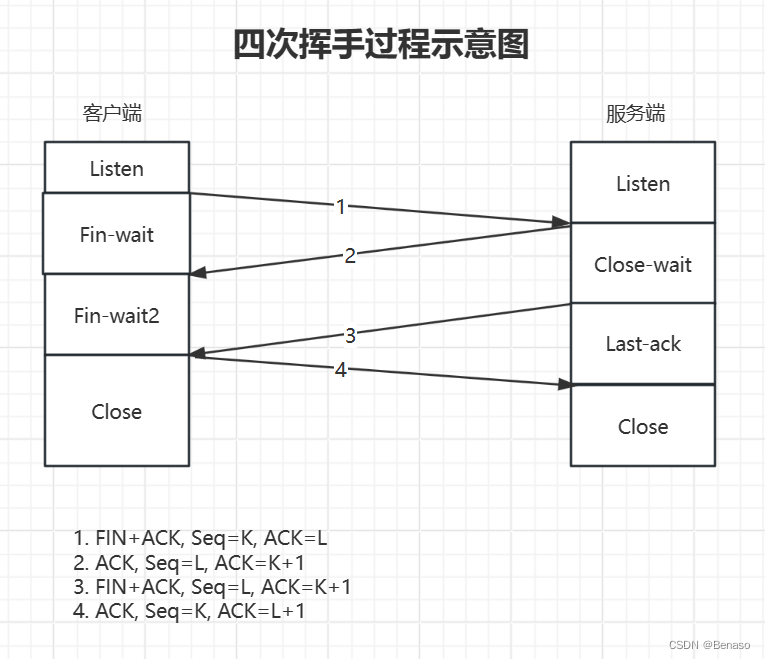
Java网络编程,使用UDP实现TCP(三), 基本实现四次挥手
简介 四次挥手示意图 在四次挥手过程中,第一次挥手中的Seq为本次挥手的ISN, ACK为 上一次挥手的 Seq1,即最后一次数据传输的Seq1。挥手信息由客户端首先发起。 实现步骤: 下面是TCP四次挥手的步骤: 第一次挥手&…...

“百里挑一”AI原生应用亮相,百度智能云千帆AI加速器首个Demo Day来了!
作者简介: 辭七七,目前大二,正在学习C/C,Java,Python等 作者主页: 七七的个人主页 文章收录专栏: 七七的闲谈 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖…...
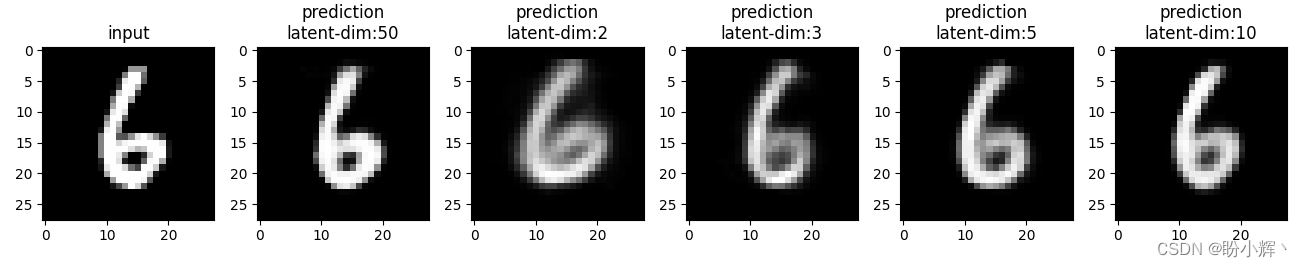
PyTorch深度学习实战(25)——自编码器
PyTorch深度学习实战(25)——自编码器 0. 前言1. 自编码器2. 使用 PyTorch 实现自编码器小结系列链接 0. 前言 自编码器 (Autoencoder) 是一种无监督学习的神经网络模型,用于数据的特征提取和降维,它由一个编码器 (Encoder) 和一…...

靠谱的车- 华为OD统一考试(C卷)
靠谱的车- 华为OD统一考试(C卷) OD统一考试(C卷) 分值: 100分 题解: Java / Python / C 题目描述 程序员小明打了一辆出租车去上班。出于职业敏感,他注意到这辆出租车的计费表有点问题…...

Apache Flink(十一):Flink集群部署-Standalone集群部署
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录 1. 节点划分...

vue的组件传值
Vue中组件之间的数据传递可以使用props和$emit来实现。 1.使用props传递数据:父组件可以通过子组件的props属性向子组件传递数据。 父组件中: <template><div><child-component :message"parentMessage"></child-comp…...
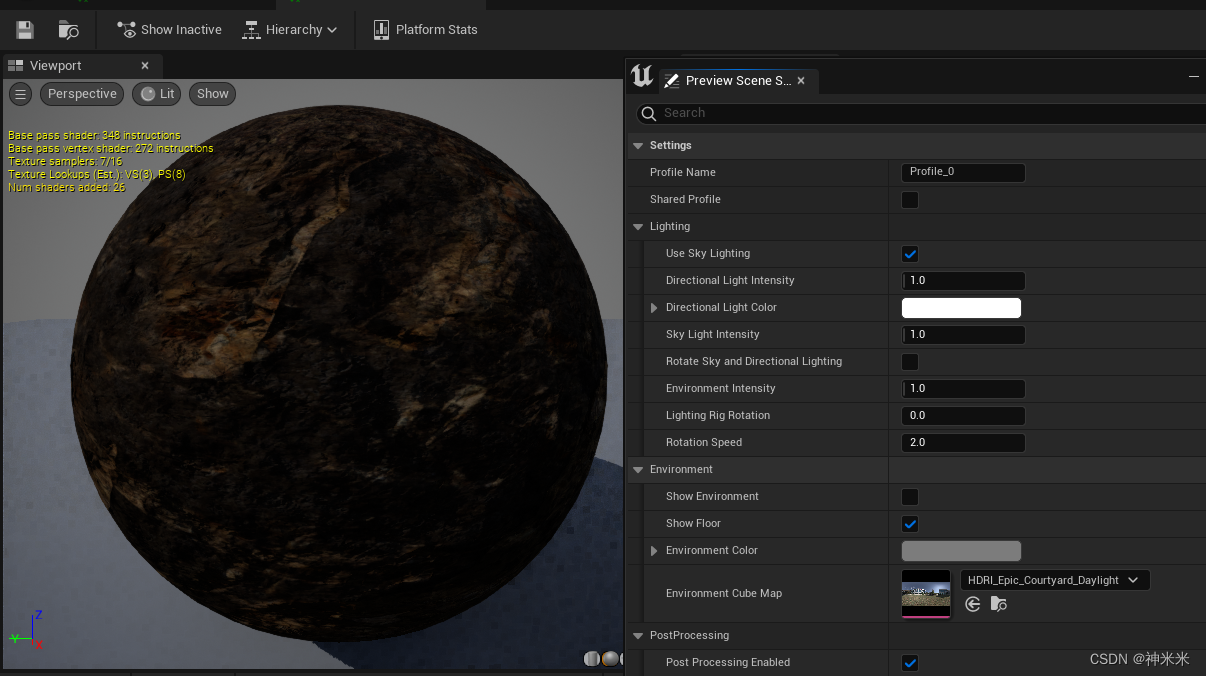
ue5材质预览界面ue 变黑
发现在5.2和5.1上都有这个bug 原因是开了ray tracing引起的,这个bug真是长时间存在,类似的bug还包括草地上奇怪的影子和地形上的影子等等 解决方法也很简单,就是关闭光追(不是…… 就是关闭预览,在材质界面preview sc…...

【SpringCloud篇】Eureka服务的基本配置和操作
文章目录 🌹简述Eureka🛸搭建Eureka服务⭐操作步骤⭐服务注册⭐服务发现 🌹简述Eureka Eureka是Netflix开源的一个基于REST的服务治理框架,主要用于实现微服务架构中的服务注册与发现。它由Eureka服务器和Eureka客户端组成&#…...

模拟目录管理 - 华为OD统一考试(C卷)
OD统一考试(C卷) 分值: 200分 题解: Java / Python / C++ 题目描述 实现一个模拟目录管理功能的软件,输入一个命令序列,输出最后一条命令运行结果。 支持命令: 1)创建目录命令: mkdir 目录名称,如mkdir abc为在当前目录创建abc目录,如果已存在同名目录则不执行任何操作…...

卷王开启验证码后无法登陆问题解决
问题描述 使用 docker 部署,后台设置开启验证,重启服务器之后,docker重启,再次访问系统,验证码获取失败,导致无法进行验证,也就无法登陆系统。 如果不了解卷王的,可以去官网看下。…...
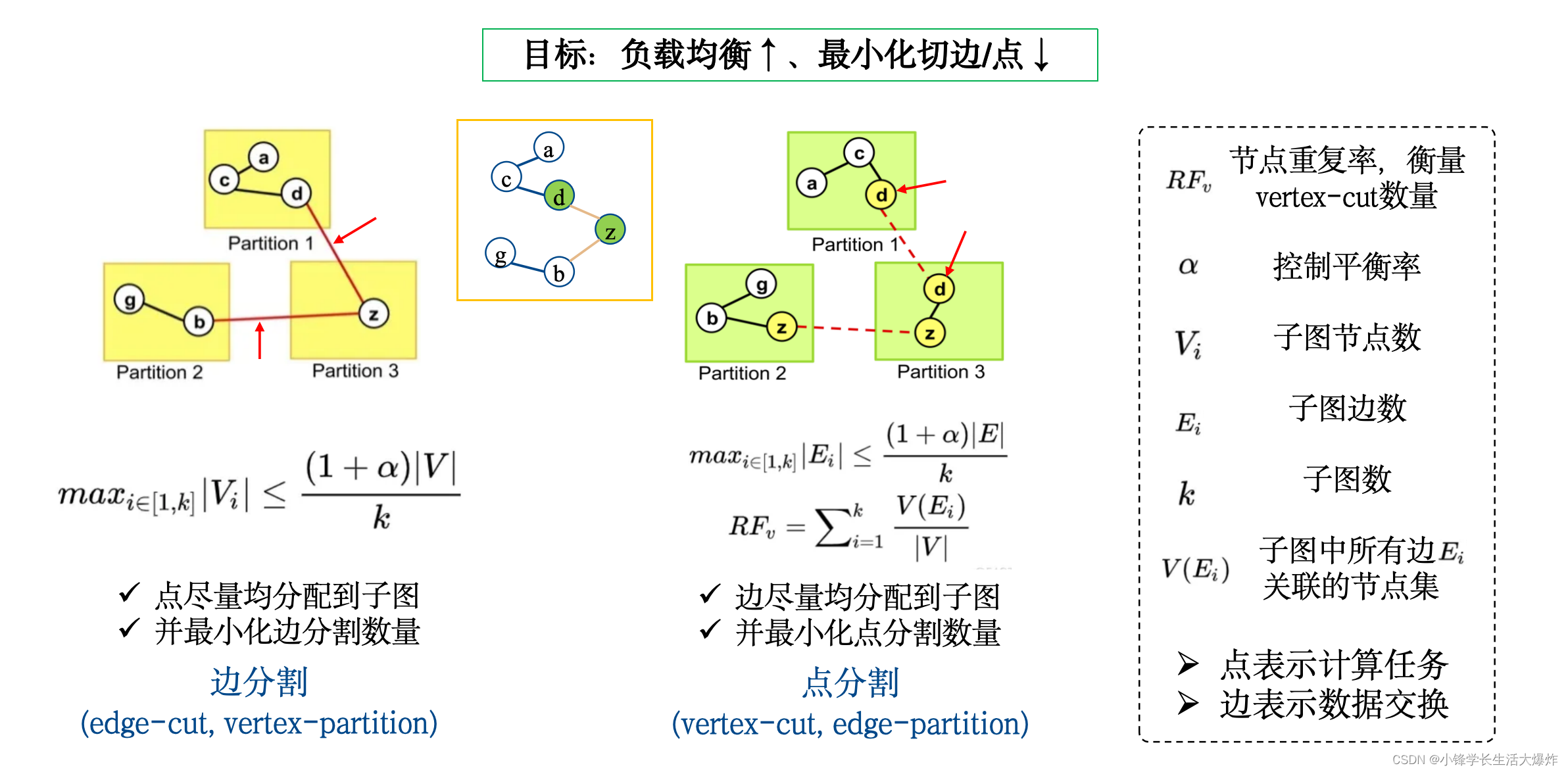
【知识】如何区分图论中的点分割和边分割
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 以下两个概念在现有中文博客下非常容易混淆: edge-cut(边切割) vertex-partition(点分割)vertex-cut(点切割) edge-partition(边分割) 实际上,初看中文时,真的会搞不清楚。但…...

【华为鸿蒙系统学习】- HarmonyOS4.0开发工具和环境配置问题总结|自学篇
🌈个人主页: Aileen_0v0 🔥热门专栏: 华为鸿蒙系统学习|计算机网络|数据结构与算法 💫个人格言:"没有罗马,那就自己创造罗马~" 目录 官方链接 HUAWEI DevEco Studio和SDK下载和升级 | HarmonyOS开发者 安装教程 (…...
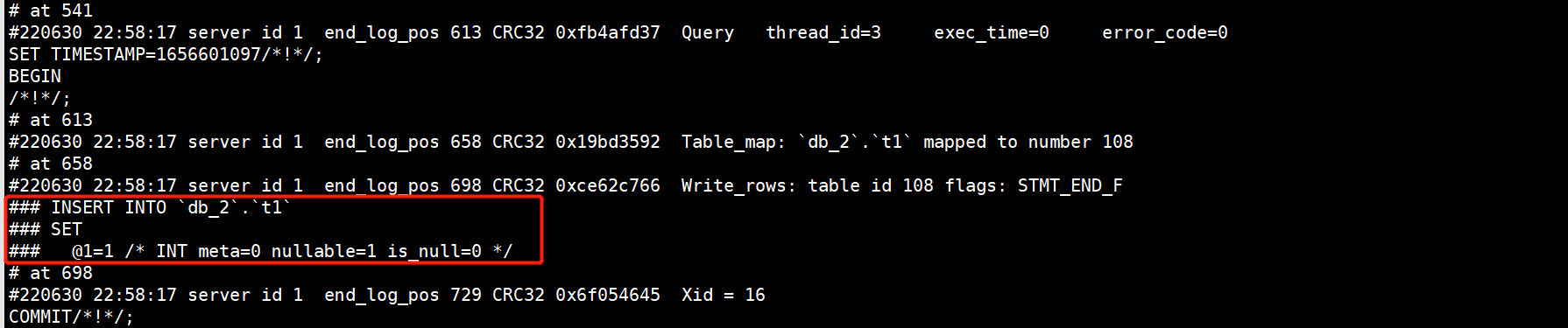
第78讲:MySQL数据库Binlog日志的核心概念与应用案例
文章目录 1.Binlog二进制日志的基本概念1.1.什么是Binlog二进制1.2.Binlog日志的三种记录格式1.3.Binlog日志中Event事件的概念 2.开启MySQL的Binlog二进制日志3.查看Binlog二进制日志中的Event事件信息3.1.查看当前数据库有那些Binlog日志3.2.产生一些DDL/DML语句3.3.观察Binl…...

MinGW编译Python至pyd踩坑整理
title: MinGW编译Python至pyd踩坑整理 tags: [Python,CC] categories: [开发记录,Python] date: 2023-12-12 13:48:20 description: sidebar: [‘toc’, ‘related’,‘recent’] 注意需要魔法 用scoop自动安装配置MinGw 需要魔法,不需要手动配置mingw scoop in…...

计算机毕业设计 基于SpringBoot的乡村政务办公系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
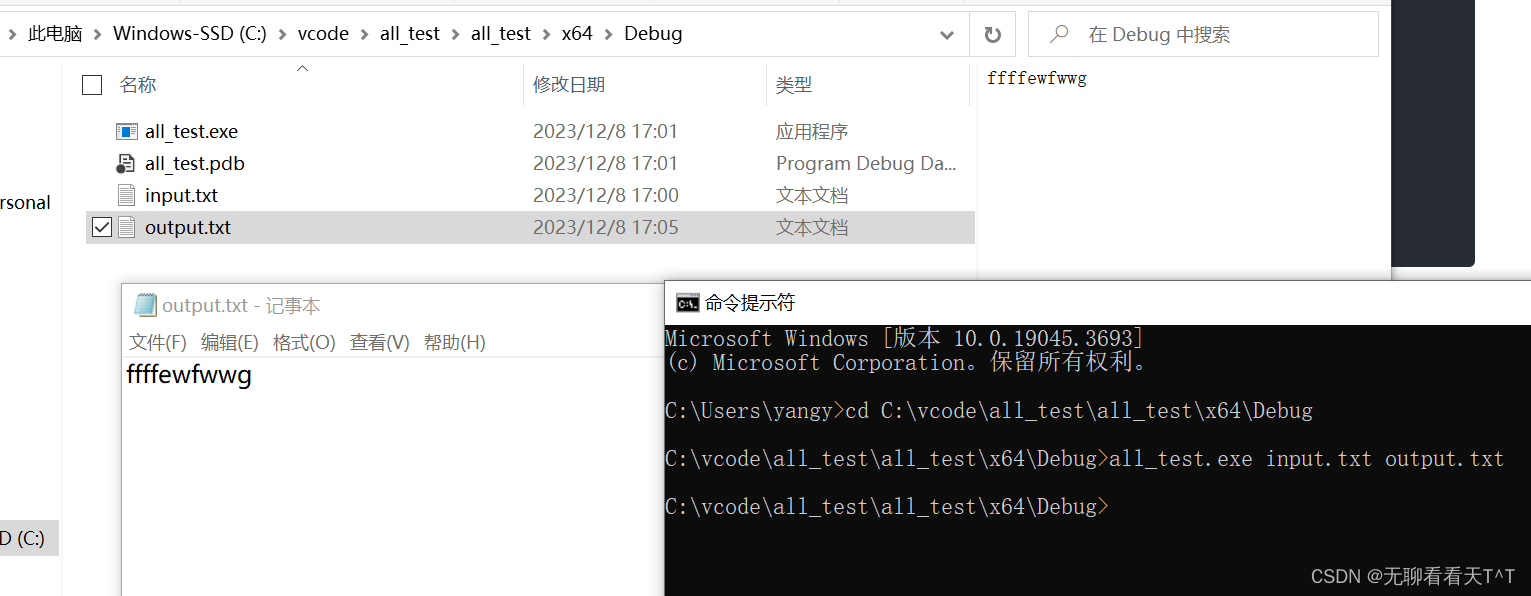
命令行参数(C语言)
目录 什么是命令行参数 main函数的可执行参数 不传参打印 传参打印 IDE传参 cmd传参 命令行参数的应用(文件拷贝) 什么是命令行参数 概念:命令行参数指的是在运行可执行文件时提供给程序的额外输入信息。它们通常以字符串形式出现&am…...

WT2003H4-16S语音芯片:扭蛋机新潮音乐,娱乐升级无限
在扭蛋机的乐趣世界里,唯创知音的WT2003H4-16S语音芯片,作为MP3音乐解码播放IC,为扭蛋机带来了更智能、更富有趣味的音乐体验,为玩家打开了娱乐升级的无限可能。 1. 机启音乐,欢迎扭蛋之旅 扭蛋机启动时,…...

Go 语言开发工具
Go 语言开发工具 VSCode VScode 安装教程参见:https://www.kxdang.com/topic//w3cnote/vscode-tutorial.html 然后我们打开 VSCode 的扩展(CtrlShiftP): 搜索 go: 点击安装,安装完成后我们就可以使用代码…...

神经网络是如何工作的? | 京东云技术团队
作为一名程序员,我们习惯于去了解所使用工具、中间件的底层原理,本文则旨在帮助大家了解AI模型的底层机制,让大家在学习或应用各种大模型时更加得心应手,更加适合没有AI基础的小伙伴们。 一、GPT与神经网络的关系 GPT想必大家已…...

UE5新手也能搞定的Niagara特效:用模板10分钟做出一个会动的烟雾
UE5 Niagara特效速成:10分钟打造动态烟雾的极简指南 第一次打开Unreal Engine的Niagara特效系统时,我被密密麻麻的节点和参数吓退了三次。直到发现模板库里的"Simple Sprite Burst",才意识到原来制作专业级特效可以如此简单——就像…...

Windows HEIC缩略图终极解决方案:3步解锁苹果照片完美预览
Windows HEIC缩略图终极解决方案:3步解锁苹果照片完美预览 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 还在为iPh…...

LeetCode 每日一题笔记 日期:2026.05.19 题目:2540. 最小公共值
LeetCode 每日一题笔记 0. 前言 日期:2026.05.19题目:2540. 最小公共值难度:简单标签:数组、双指针、哈希表 1. 题目理解 问题描述: 给定两个按非降序排序的整数数组 nums1 和 nums2,请返回它们的最小公共整…...
)
别再傻傻等下载了!QMT历史数据获取的3个高效技巧(含xtquant代码示例)
QMT历史数据获取效率优化实战:3个让回测提速200%的高级技巧 每次打开QMT准备回测策略时,最让人抓狂的莫过于漫长的历史数据等待时间。作为一名量化研究员,我曾在数据准备环节浪费了无数个下午——直到发现这几个能彻底改变工作流的技巧。本文…...

EC35编码器驱动踩坑实录:从波形分析到稳定读取,我的GD32调试笔记
EC35编码器驱动踩坑实录:从波形分析到稳定读取的GD32调试笔记 1. 问题初现:那些让人抓狂的"玄学"现象 第一次把EC35编码器接到GD32F303开发板上时,我天真地以为这不过是个简单的GPIO中断应用。按照常规思路配置了三个引脚的中断&am…...
)
Perplexity财经数据查询失效的4个致命信号,第3个95%用户仍在踩坑——附权威校验脚本(Python版)
更多请点击: https://kaifayun.com 第一章:Perplexity财经数据查询失效的4个致命信号,第3个95%用户仍在踩坑——附权威校验脚本(Python版) 信号一:HTTP状态码非200但响应体含“success”: true Perplexit…...

基于CW32F030的BLDC电机控制:从国产MCU到完整评估方案
1. 项目概述:从一颗国产MCU到一套完整的BLDC评估方案最近在做一个直流无刷电机(BLDC)的小项目,选型时发现了一款挺有意思的国产MCU——武汉芯源的CW32F030C8T6,以及围绕它打造的一套完整的评估套件CW32_BLCD_EVA。对于…...

Serverless冷启动优化全攻略:从原理到实战的性能提升方案
1. 项目概述:直面Serverless的“阿喀琉斯之踵”在Serverless架构的实践中,有一个问题几乎每个深度使用者都绕不开,那就是“冷启动”。想象一下,你精心设计的函数,在无人访问时安静地“休眠”以节省资源。当第一个请求突…...

格式改到心态崩?Paperxie 智能排版,一键把论文 “捏” 成学校模板
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/format/typesettinghttps://www.paperxie.cn/format/typesetting 改完论文正文、降完重复率,本以为终于能喘口气,结果被导师一句 “格式全错…...

自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现
自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现 【下载地址】自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现 本项目提供了一个完整的工程代码,用于实现自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现。自适应滤波器是一种能够根据环境变化自动调整滤波器参数…...