爬虫解析-BeautifulSoup-bs4(七)
目录
1.bs4的安装
2.bs4的语法
(1)查找节点
(2)查找结点信息
3.bs4的操作
(1)对本地文件进行操作
(2)对服务器响应文件进行操作
4.实战
beautifulsoup:和lxml一样,是一个html的解析器,主要功能也是解析和提取数据。
优缺点:
缺点:没有lxml效率高
优点:接口更加人性化,使用方便
1.bs4的安装
安装:pip install bs4
导入 from bs4 import BeautifulSoup
2.bs4的语法
(1)查找节点
1.根据标签名查找节点:
soup.a 【注】只能找到第一个
soup.a.name 标签a的名字,即“a”
soup.a.attrs 标签a 的属性,即“href=”..”
2.函数
(1).find(返回一个对象)
find(‘a’):只找到第一个 a 标签
find(‘a’, title=’属性值’)
find(‘a’, class=’属性值’)
(2).find_all (返回一个列表)
find_all('a’) 查找到所有的a
find_all(['a,'span']) 返回所有的a和span
find_all('a",limit=2) 只找前两个a
(3).select(根选择器得到节点对象)【推荐】
1. element
eg:p
2..class
eg: .firstname
3.#id
eg:#firstname
4.属性选择器
[attribute]
5.层级选择器
①后代选择器:element element
div p
②子代选择器:element>element
div>p
③多项选择器:element ,element
div,p
eg:soup = soup.select("a,span')
# 根据标签名查找节点
# 注意:找到的是第一个符合条件的数据
print(soup.a) # <a href="https://..." id="a1">BeautifulSoup</a>
# 获取标签名
print(soup.a.name) # a
# 获取标签的属性和属性值
print(soup.a.attrs) # {'href': 'https://...', 'id': 'a1'}# bs4 的一些函数
# (1)find 返回的是第一个符合条件的对象
print(soup.find('a')) # <a href="https://..." id="a1">BeautifulSoup</a>
# 根据属性值找到符合条件的标签对象
print(soup.find('a', id='a2')) #<a href="http://..." id="a2">lxml</a>
# 根据class查找标签对象,注意,class要加下划线'class_',因为这里的的class和定义类的class冲突了
print(soup.find('a',class_='link'))# (2)findAll 返回的是所有符合条件的对象的列表
# 找到所有符合条件的标签对象
print(soup.findAll('a')) # [<a class="link" href="https://..." id="a1">BeautifulSoup</a>, <a href="http://..." id="a2">lxml</a>]
# 获取多个标签,需要在 findAll中添加列表的数据
print(soup.findAll(['a','span'])) # [<a class="link" href="https://..." id="a1">BeautifulSoup</a>, <span>demo</span>, <a href="http://..." id="a2">lxml</a>]
# 找前几个符合条件的数据
print(soup.findAll('a',limit=1))# (3)select
# select 返回的是所有符合条件的对象列表
print(soup.select('a')) # [<a class="link" href="https://..." id="a1">BeautifulSoup</a>, <a href="http://..." id="a2">lxml</a>]
# 可以通过 '.' 代表 class,我们把这种操作叫做类选择器
print(soup.select('.link')) # [<a class="link" href="https://..." id="a1">BeautifulSoup</a>]
print(soup.select('#a1')) # [<a class="link" href="https://..." id="a1">BeautifulSoup</a>]# 属性选择器 通过属性来寻找对应的标签
# 查找<li>标签中有class的标签
print(soup.select('li[class]')) # [<li class="c1" id="l1">北京</li>, <li class="c2" id="l2">上海</li>]
# 查找<li>标签中 id 为 l2 的标签
print(soup.select('li[id="l2"]')) # [<li class="c2" id="l2">上海</li>]# 层级选择器
# 后代选择器
# 找到 div 下面的 li
print(soup.select('div li')) # [<li class="c1" id="l1">北京</li>, <li class="c2" id="l2">上海</li>, <li id="s1">广州</li>, <li id="s2">深圳</li>]
# 子代选择器
# 某标签的第一级子标签
print(soup.select('div > ul > li')) # [<li class="c1" id="l1">北京</li>, <li class="c2" id="l2">上海</li>, <li id="s1">广州</li>, <li id="s2">深圳</li>]
# 找到 a 标签 和 li 标签的所有对象
print(soup.select('a, li')) # [<li class="c1" id="l1">北京</li>, <li class="c2" id="l2">上海</li>, <li id="s1">广州</li>, <li id="s2">深圳</li>, <a class="link" href="https://..." id="a1">BeautifulSoup</a>, <a href="http://..." id="a2">lxml</a>]
(2)查找结点信息
1.获取节点内容: 适用于标签中嵌套标签的结构
obj.string
obj.get_text()[推荐]
2.节点的属性
tag.name 获取标签名
eg:tag=find("li)
print(tag.name)
tag.attrs将属性值作为一个字典返回
3.获取节点属性
obj.attrs.get('title')[常用]
obj.get('title')
obj['title"]
# 节点信息
# 获取节点内容
obj = soup.select('#d2')
# 如果 标签对象中只有内容,那string和get_text(),如果标签对象中,除了内容还有标签,那string就获取不到数据,而get_text()可以获取到数据
# 推荐使用 get_text()
print(obj[0].string)
print(obj[0].get_text())# 节点的属性
# 标签的名字
obj = soup.select('#p1')
print(obj[0].name) # p
# 将属性值作为一个字典返回
print(obj[0].attrs) # {'id': 'p1', 'class': ['p1']}# 获取节点的属性
obj = soup.select('#p1')[0]
print(obj.attrs.get('class')) # ['p1']
print(obj.get('class')) # ['p1']
print(obj['class']) # ['p1']HTML文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"/><title>Title</title>
</head>
<body><div><ul><li id='l1' class="c1">北京</li><li id="l2" class="c2">上海</li><li id="s1">广州</li><li id="s2">深圳</li><a href="https://..." id="a1" class="link">BeautifulSoup</a><span>demo</span></ul></div><a href="http://..." id="a2">lxml</a><div id = 'd2'><span>temp</span></div><p id="p1" class="p1">id和class都是p1怎么办</p>
</body>
</html>3.bs4的操作
bs4可以对服务器响应文件和本地文件进行操作
(1)服务器响应的文件生成对象
soup = BeautifulSoup(response.read().decode(),’lxml’)
(2)本地文件生成对象
soup = BeautifulSoup(open(‘1.html’),’lxml’
(1)对本地文件进行操作
from bs4 import BeautifulSoup# 通过解析本地文件讲解bs4 的基本语法
soup = BeautifulSoup(open('_075.html','r',encoding='utf-8'),'lxml')
(2)对服务器响应文件进行操作
import urllib.requesturl = 'https://www.starbucks.com.cn/menu/'request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')from bs4 import BeautifulSoup
# 通过解析本地文件讲解bs4 的基本语法
soup = BeautifulSoup(content,'lxml')4.实战
获取豆瓣评分的 Top250。
from bs4 import BeautifulSoup
import requests# 小demo
# content = requests.get("http://books.toscrape.com/").text
# # html.parser 指定解析器,说明我们正在解析html内容
# soup = BeautifulSoup(content,"html.parser")# # findAll返回一个可迭代对象
# # 通过特有class查找元素
# all_price = soup.findAll("p",attrs={"class": "price_color"})
# # print(all_price)
# for i in all_price:
# # 只想要数字,不想要标签,调用string属性
# print(i.string)# # 根据共有标签查找元素
# all_title = soup.findAll("h3")
# for i in all_title:
# all_a = soup.findAll("a")
# # # 如果该标签下只有一个<a>元素,那就直接用find提取这个元素就ok了,这样就能少写一个循环
# # a = soup.find("a")
# for link in all_a:
# print(link.string)headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.76"
}for start_num in range(0,250,25):response = requests.get(f'https://movie.douban.com/top250?start={start_num}', headers = headers)html = response.textsoup = BeautifulSoup(html,"html.parser")all_title = soup.findAll("span",attrs={"class":"title"})for title in all_title:title_string = title.stringif "/" not in title_string:print(title_string)参考
尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例)
相关文章:
)
爬虫解析-BeautifulSoup-bs4(七)
目录 1.bs4的安装 2.bs4的语法 (1)查找节点 (2)查找结点信息 3.bs4的操作 (1)对本地文件进行操作 (2)对服务器响应文件进行操作 4.实战 beautifulsoup:和lxml一样…...

分类预测 | Matlab实现OOA-SVM鱼鹰算法优化支持向量机的多变量输入数据分类预测
分类预测 | Matlab实现OOA-SVM鱼鹰算法优化支持向量机的多变量输入数据分类预测 目录 分类预测 | Matlab实现OOA-SVM鱼鹰算法优化支持向量机的多变量输入数据分类预测分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Matlab实现OOA-SVM鱼鹰算法优化支持向量机的多变量输…...
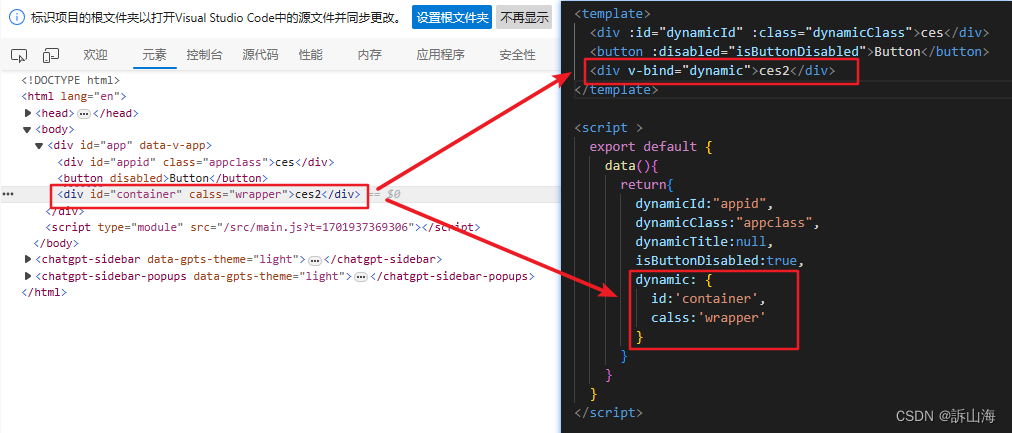
2.vue学习笔记(目录结构+模板语法+属性绑定)
文章目录 1.目录结构2.模板语法2.1.文本插值2.2.使用JavaScript表达式2.3.原始HTML 3.属性绑定3.1.简写3.2.布尔型Attribute3.3.动态绑定多个值 1.目录结构 1.vscode ——VSCode工具的配置文件夹 2.node_modules ——Vue项目的运行依赖文件夹 3.public ——资源文件夹&am…...

Python基本语法及高级特性总结
1. Python基本语法 1.1 变量和数据类型 在Python中,变量不需要预先声明,可以直接赋值。Python是一种动态类型语言,变量的类型会根据赋值的对象自动确定。例如: a 10 # a是整数类型变量 b 3.14 # b是浮点数类型变量 c …...

03-详解网关的过滤器工厂和常见的网关过滤器路由过滤器,默认过滤器,全局过滤器的执行顺序
过滤器工厂 过滤器种类 GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务响应的结果做加工处理 Spring提供了31中不同的路由过滤器工厂 AddResponseHeader表示给请求添加响应头 default-filters: # 默认过滤器 - AddResponseHeaderX-Response-Default-R…...
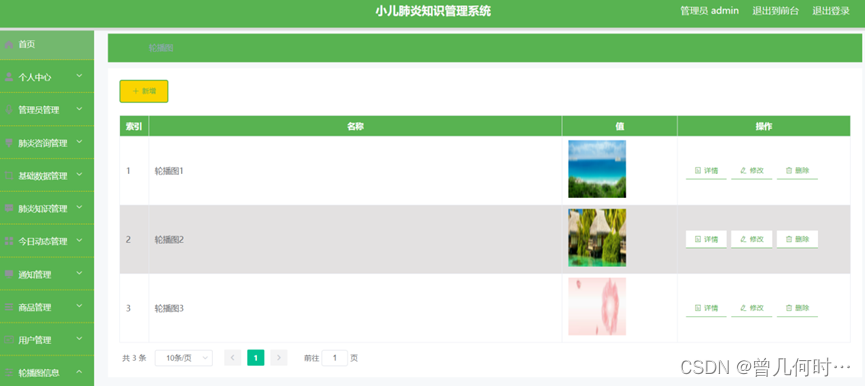
基于SSM的小儿肺炎知识管理系统设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

HuffMan tree
定义 给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。 基础知识 路…...
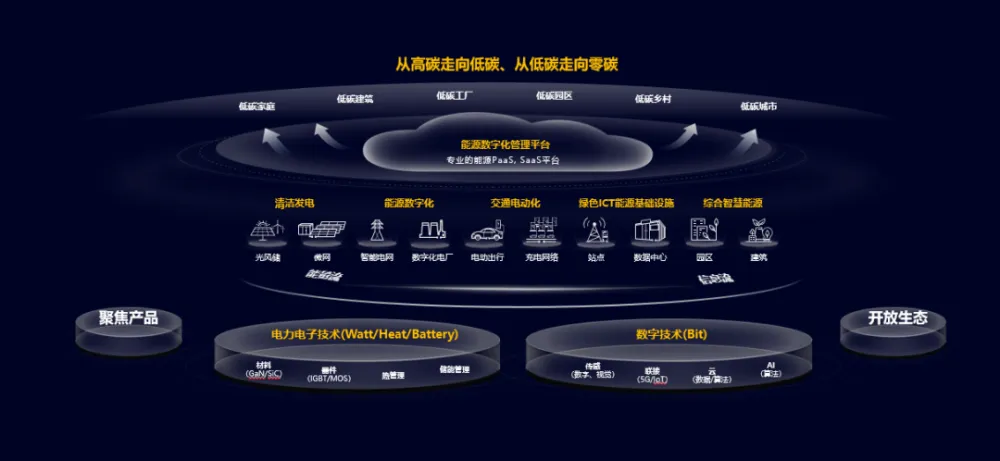
各地加速“双碳”落地,数字能源供应商怎么选?
作者 | 曾响铃 文 | 响铃说 随着我国力争2030年前实现“碳达峰”、2060年前实现“碳中和”的“双碳”目标提出,为各地区、各行业的低碳转型和绿色可持续发展制定“倒计时”时间表,一场围绕“数字能源”、“智慧能源”、“新能源”等关键词的创新探索进…...
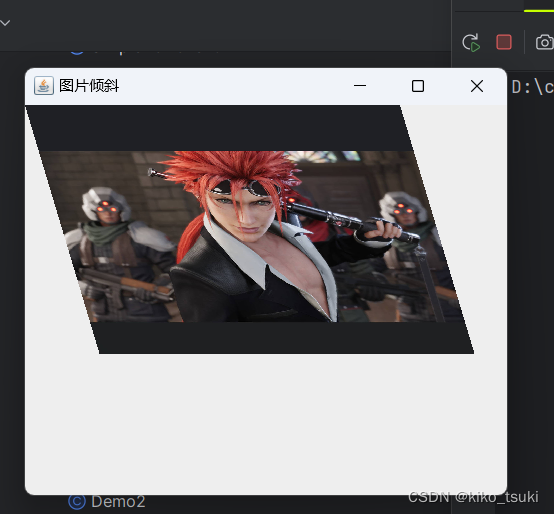
19.java绘图
A.Graphics类 Graphics类是java.awt包中的一个类,它用于在图形用户界面(GUI)或其他图形应用程序中进行绘制。该类通常与Component的paint方法一起使用,以在组件上进行绘制操作。 一些Graphics类的常见用法和方法: 在组…...

提升工作效率,尽在Microsoft Office LTSC 2021 for Mac!
在当今的办公环境中,高效率的工作是每个人都追求的目标。作为全球领先的办公软件套装,Microsoft Office LTSC 2021 for Mac将为您提供一站式的解决方案,帮助您轻松应对各种工作任务。 首先,Microsoft Office LTSC 2021 for Mac拥…...

day24_java的反射机制
反射 一、反射的概念 反射:加载类,反射出类的各个组成部分(类的成员:构造方法,属性,方法) java反射机制:在运行状态中,对于任何一个类都能够知道这个类的所有属性和方…...
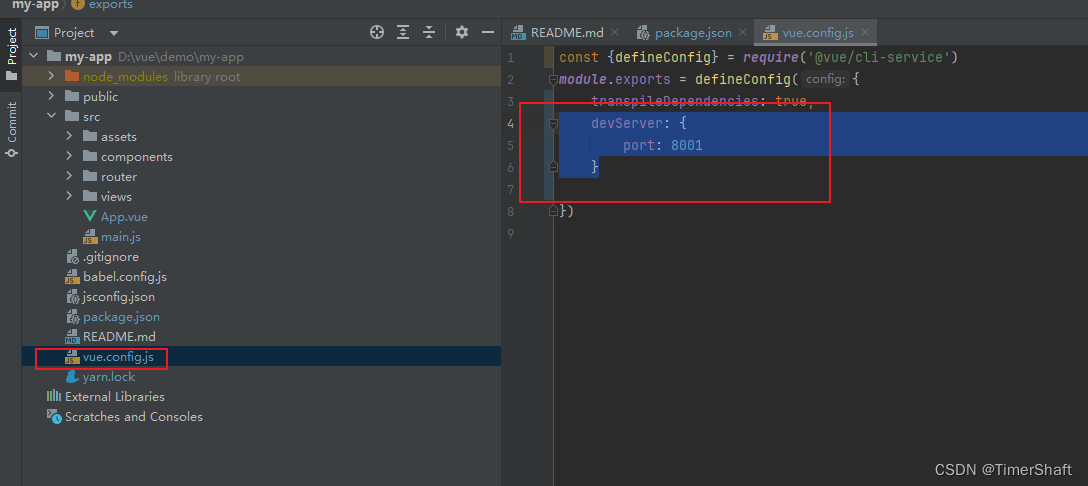
VUE学习二、创建一个前端项目
1.创建一个vue项目 使用命令 vue ui启动vue脚手架 vue ui 等待项目创建好 可以来任务栏启动项目 参数那里可以设置启动端口等参数 启动成功 成功访问 2. 用webstorm 打开项目 脚手架页面可安装基本依赖 比如路由 使用ws打开项目 启动项目 npm run serve 3.修改启动…...
「红队笔记」靶机精讲:Prime1 - 信息收集和分析能力的试炼
「红队笔记」靶机精讲:Prime1 - 信息收集和分析能力的试炼 本文是作者在观看 B 站《红队笔记》后做的一些笔记及相关知识的补充。学渗透特别推荐大家去看。如有侵权,请联系作者,作者看到后会第一时间删除。 靶机精讲之Prime1,vu…...
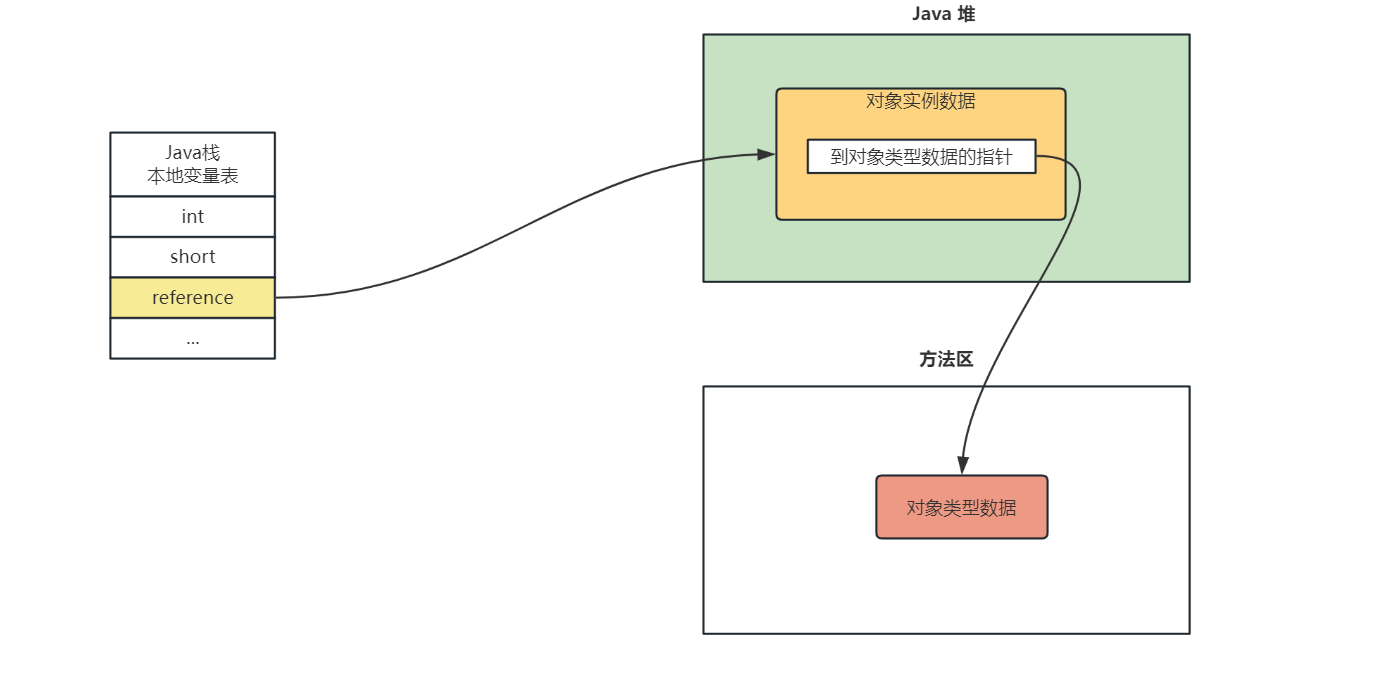
JVM虚拟机系统性学习-对象的创建流程及对象的访问定位
对象的创建流程与内存分配 对象创建流程如下: Java 中新创建的对象如何分配空间呢? new 的对象先放 Eden 区(如果是大对象,直接放入老年代)当 Eden 区满了之后,程序还需要创建对象,则垃圾回收…...

perf与火焰图-性能分析工具
参考链接 perf性能分析工具使用分享 如何读懂火焰图?-阮一峰 perf基本用法-record,report-知乎 火焰图抓取 准备: centos安装perf工具 dnf install perf下载火焰图解析代码 git clone https://github.com/brendangregg/FlameGraph.git抓取指定进程…...
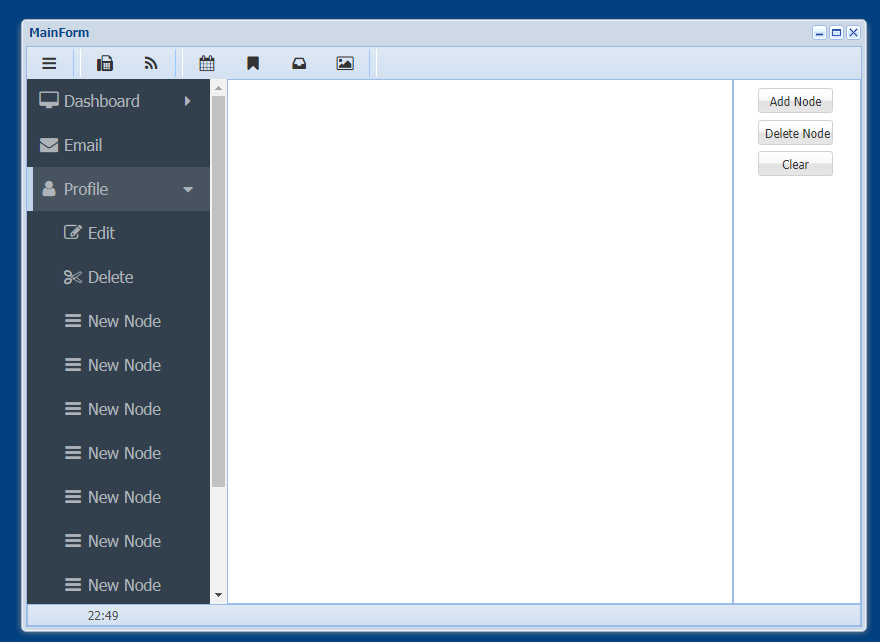
UniGui使用CSSUniTreeMenu滚动条
有些人反应UniTreeMenu当菜单项目比较多的时候会超出但是没有出滚动条,只需要添加如下CSS 老规矩,unitreemeu的layout的componentcls里添加bbtreemenu,然后在css里添加 .bbtreemenu .x-box-item{ overflow-y: auto; } 然后当内容超出后就会…...

Spring框架中的五种常用设计模式
1、单例模式 Spring 的 Bean 默认是单例模式,通过 Spring 容器管理 Bean 的⽣命周期,保证每个 Bean 只被 创建⼀次,并在整个应⽤程序中重用。 2.工厂模式 Spring 使⽤⼯⼚模式通过 BeanFactory 和 ApplicationContext 创建并管理 Bean 对象…...

华纳云:docker启动报错的原因和解决方法
Docker 启动报错可能由多种原因引起。以下是一些建议,可用于解决 Docker 启动问题: 查看 Docker 日志: 查看 Docker 的日志可以提供更多的详细信息,有助于定位问题。 sudo journalctl -xe | grep docker 或者查看 Docker 服务的详…...

代码规范及开发工具
代码规范及开发工具: 前端(vscode、idea): JavaScript规范: 1. 谷歌开源项目风格指南:JavaScript 、TypeScript篇 https://zh-google-styleguide.readthedocs.io/en/latest/google-typescript-…...
证件照制作小程序源代码
17638103951(同v)...

从EfficientNetV1到V2:我是如何用PyTorch复现Fused-MBConv模块并验证其速度优势的
从EfficientNetV1到V2:我是如何用PyTorch复现Fused-MBConv模块并验证其速度优势的 去年在优化移动端图像分类模型时,我偶然发现EfficientNetV2论文中提到的Fused-MBConv模块在浅层网络中的推理速度比传统MBConv快30%以上。这个数字让我既兴奋又怀疑——毕…...

Linux音频驱动开发实战:为TLV320ADC5120编写ALSA Codec驱动
1. 项目概述:从一块“哑巴”音频芯片到Linux系统的“耳朵”最近在折腾一块基于TI TLV320ADC5120的音频采集板,想把它接到我的RK3568开发板上用。芯片手册、硬件原理图都齐了,但一上电,系统里arecord -l根本找不到设备,…...
)
Gemini Nano离线推理部署手册(移动端LLM轻量化部署终极版)
更多请点击: https://codechina.net 第一章:Gemini Nano离线推理部署手册(移动端LLM轻量化部署终极版) Gemini Nano 是 Google 推出的首个专为端侧设备设计的轻量级大语言模型,支持在 Android 14 设备上本地运行&…...

从‘果冻屏’到‘瀑布屏’:OCA全贴合工艺如何悄悄改变了你的视觉体验?
从‘果冻屏’到‘瀑布屏’:OCA全贴合工艺如何悄悄改变了你的视觉体验? 还记得十年前那些让人抓狂的“果冻屏”吗?阳光下泛着彩虹纹,触控时总感觉隔着一层毛玻璃,甚至能清晰看到屏幕边缘积攒的灰尘。如今拿起任何一款旗…...

北京房山区浇筑阁楼测评:天顺诚达工艺佳但价格略高,适合这类
为了避免违反规则,以下内容去除了联系方式等违规信息。随着对居住空间利用需求的增加,在北京房山区浇筑阁楼成为不少人的选择。本次测评旨在为对北京房山区浇筑阁楼服务感兴趣的人群,客观呈现相关服务的情况。参与本次测评的是北京天顺诚达建…...

C 读取RAW文件程序
C# 读取RAW文件程序 【下载地址】C读取RAW文件程序 本仓库提供了一个简单的C#程序,用于读取RAW文件。该程序已经过调试,确保功能正常运行。需要注意的是,此程序仅提供基本的RAW文件读取功能,不包含任何图像处理或转换功能 项目地…...
)
数据结构第8章查找:单元测试15题全解析(顺序查找+折半查找+分块查找+哈希查找)
第8章 查找 单元测试1. 线性表只有以( A )方式存储,才能进行折半查找。A. 顺序B. 链接C. 二叉树D. 关键字有序的2. 有序表为{2,4,10,13,33,42,46,64&#x…...

如何快速掌握CircuitJS1:免费高效的浏览器电路仿真终极指南
如何快速掌握CircuitJS1:免费高效的浏览器电路仿真终极指南 【免费下载链接】circuitjs1 Electronic Circuit Simulator in the Browser 项目地址: https://gitcode.com/gh_mirrors/ci/circuitjs1 CircuitJS1是一款功能强大的电子电路仿真工具,它…...
)
VSCode里PlatformIO插件抽风?手把手教你彻底卸载重装PIO(解决创建工程失败)
VSCode PlatformIO插件异常终极解决手册:从崩溃到重生的全流程指南 当你在VSCode中满怀期待地点击"New Project"按钮,却看到那个刺眼的红色错误提示时,那种挫败感每个开发者都懂。PlatformIO作为物联网开发的瑞士军刀,一…...

算力基石:CPU、GPU与嵌入式AI的技术逻辑与融合发展
在人工智能全面普及的时代,算力已经成为数字产业发展的核心驱动力。从日常使用的智能手机、家用电脑,到云端大模型、智能汽车、工业传感设备,各类智能终端的运转都离不开处理器的算力支撑。其中,CPU作为通用计算核心、GPU作为并行…...