[GPT]Andrej Karpathy微软Build大会GPT演讲(下)--该如何使用GPT助手
该如何使用GPT助手--将GPT助手模型应用于问题

现在我要换个方向,让我们看看如何最好地将 GPT 助手模型应用于您的问题。
现在我想在一个具体示例的场景里展示。让我们在这里使用一个具体示例。
假设你正在写一篇文章或一篇博客文章,你打算在最后写这句话。
加州的人口是阿拉斯加的 53 倍。因此出于某种原因,您想比较这两个州的人口。
想想我们自己丰富的内心独白和工具的使用,以及在你的大脑中实际进行了多少计算工作来生成这最后一句话。
这可能是你大脑中的样子:
好的。对于下一步,让我写博客——在我的博客中,让我比较这两个人群。
好的。首先,我显然需要得到这两个人群。
现在我知道我可能根本不了解这些人群。
我有点,比如,意识到我知道或不知道我的自我知识;正确的?
我去了——我做了一些工具的使用,然后我去了维基百科,我查找了加利福尼亚的人口和阿拉斯加的人口。
现在我知道我应该把两者分开。
同样,我知道用 39.2 除以 0.74 不太可能成功。
那不是我脑子里能做的事情。
因此,我将依靠计算器。
我打算用一个计算器,把它打进去,看看输出大约是 53。
然后也许我会在我的大脑中做一些反思和理智检查。
那么53有意义吗?
好吧,这是相当大的一部分,但是加利福尼亚是人口最多的州,也许这看起来还可以。
这样我就有了我可能需要的所有信息,现在我开始写作的创造性部分了。
我可能会开始写类似,加利福尼亚有 53 倍之类的东西,然后我对自己说,这实际上是非常尴尬的措辞,让我删除它,然后再试一次。
在我写作的时候,我有一个独立的过程,几乎是在检查我正在写的东西,并判断它是否好看。
然后也许我删除了,也许我重新构造了它,然后也许我对结果感到满意。
基本上,长话短说,当你创造这样的句子时,你的内心独白会发生很多事情。
这里Andrej从一个具体的例子开始讲起,首先假设我们需要写一篇博客,在博客的最后希望写一句话“加州的人口是阿拉斯加的53倍”,为了能够给出这个结论,我们的大脑中需要进行很多前置工作,如下图所示,先想一下我得知道他们各自的人口是多少,但是这不在我的脑海中,因此我需要去检索。然后通过wiki我知道了加州有39.2M的人,阿拉斯加有0.74M的人,然后我需要计算一下两者的除法,但我没法心算,所以我用计算器算了一下,得到39.2/0.74=53. 快速的在脑海中确认一下,这个数值是否合理,加州人确实比阿拉斯加多很多,感觉应该合理,于是我确信加州的人是阿拉斯加的53倍,并写到我的博客中,在写的过程中可能还会觉得辞藻不够美妙,反复修改一下。 所以为了达成这个目标,我的脑海中需要经过很多很多的事项才可以。
但是,当我们在其上训练 GPT 时,这样的句子是什么样的?
从 GPT 的角度来看,这只是一个标记序列。因此,当 GPT 读取或生成这些标记时,它只会进行分块、分块、分块,每个块对每个标记的计算工作量大致相同。
这些 Transformer 都不是很浅的网络,它们有大约 80 层的推理,但 80 仍然不算太多。
这个Transformer将尽最大努力模仿...但是,当然,这里的过程看起来与你采用的过程非常非常不同。
特别是,在我们最终的人工制品中,在创建并最终提供给 LLM 的数据集中,所有内部对话都被完全剥离(只给出最后结果作为训练数据)。
并且与您不同的是,GPT 将查看每个标记并花费相同的算力去计算它们中的每一个,实际上,你不能指望它对每个标记做太多的工作。
基本上,这些Transformer就像标记模拟器。它们不知道自己不知道什么,它们只是模仿(预测)下一个标记;它们不知道自己擅长什么,不擅长什么,只是尽力模仿(预测)下一个标记。
它们不反映在循环中,它们不检查任何东西,它们在默认情况下不纠正它们的错误,它们只是对标记序列进行采样。
它们的头脑中没有单独的内心独白流,它们正在评估正在发生的事情。
现在它们确实有某种认知优势,我想说,那就是它们实际上拥有大量基于事实的知识,涵盖大量领域,因为它们有几百亿个参数,这是大量存储和大量事实。
而且我认为,它们也有相对大而完美的工作记忆。
因此,任何适合上下文窗口的内容都可以通过其内部自注意机制立即供Transformer使用,它有点像完美的记忆。它的大小是有限的,但Transformer可以非常直接地访问它,它可以无损地记住其上下文窗口内的任何内容。
这就是我比较这两者的方式。
我之提出所有这些,是因为我认为在很大程度上,提示只是弥补了这两种架构之间的这种认知差异。就像我们人类大脑和 LLM 大脑(的比较),你可以这么看。
这样的一个过程其实就是一连串的token序列。在GPT处理时,他只会一块一块又一块的逐个去处理这些token,花差不多的时间去计算下一个词是什么,他并不像我们人类一下具有丰富的心理活动。他不知道他知道什么,他只是去模拟下一个词。他不知道什么好什么坏,他只是去模拟下一个词。他不会反思,不会检查,不会修正自己的问题。他的优势在于具备大量的基础知识,涵盖了大量的领域,保存在他的几百亿的参数中,并且对于他们的context windows可以完美处理。
人们发现有一件事,在实践中效果很好。
特别是如果您的任务需要推理,您不能指望Transformer对每个标记进行太多推理,因此
相关文章:
[GPT]Andrej Karpathy微软Build大会GPT演讲(下)--该如何使用GPT助手
该如何使用GPT助手--将GPT助手模型应用于问题 现在我要换个方向,让我们看看如何最好地将 GPT 助手模型应用于您的问题。 现在我想在一个具体示例的场景里展示。让我们在这里使用一个具体示例。 假设你正在写一篇文章或一篇博客文章,你打算在最后写这句话。 加州的人口是阿拉…...

路由器静态路由的配置
路由器静态路由的配置步骤如下: 进入系统视图。输入命令sys进入系统视图。配置路由器的接口IP地址。命令格式为int g0/0/0,其中g0/0/0表示路由器的接口,可以根据实际情况进行修改。然后使用命令ip add配置接口的IP地址。配置下一跳地址。在静…...

[Firefly-Linux] RK3568在Ubuntu上安装内核头文件实现本地编译驱动程序
文章目录 一、介绍二、安装三、编译驱动四、自行编译debian包一、介绍 在 Linux 操作系统中,linux-headers.deb 和 linux-images.deb 分别用于安装内核头文件和内核二进制文件。 linux-headers.deb: 内核头文件包,通常以 linux-headers-x.x.x-x 的形式命名。包含编译内核模…...

RabbitMQ Streams 详解
RabbitMQ Streams是一种持久复制数据结构,可以完成与队列相同的任务:它们缓冲来自生产者的消息,这些消息由消费者读取。然而,流与队列的区别在于两个重要方面:消息的存储和消费方式。 Streams为仅追加的消息日志建模&a…...
跨境电商如何利用跨境客服软件提升销售额
随着全球化的推进,跨境电商成为了许多企业拓展市场的重要途径。然而,跨境电商面临着语言、文化、时差等多种挑战,为了提供更好的客户服务并提升销售额,跨境电商需要利用跨境客服软件。本文将探讨跨境电商如何利用跨境客服软件来提…...

css/less/scss代码注意事项
一.命名 1.类名使用小写字母,以中划线分割;id 使用 驼峰式命名; 2.less/scss中的函数、混合采用驼峰命名; 3. class 的命名不要使用 标签名,如.p .div .img; 二.选择器 尽量使用直接子选择器,否则,有时会造成性能损耗 .content .title { .…...
Git应用——代码提交规范 feat ,fix ,style
当前使用 feat 增加新功能fix 修复问题/BUGstyle 代码风格相关无影响运行结果的perf 优化/性能提升refactor 重构revert 撤销修改test 测试相关docs 文档/注释chore 依赖更新/脚手架配置修改等workflow 工作流改进ci 持续集成types 类型定义文件更改wip 开发中 别处看到 fea…...

TDengine Kafka Connector将 Kafka 中指定 topic 的数据(批量或实时)同步到 TDengine
教程放在这里:TDengine Java Connector,官方文档已经写的很清晰了,不再赘述。 这里记录一下踩坑: 1.报错 java.lang.UnsatisfiedLinkError: no taos in java.library.pathat java.lang.ClassLoader.loadLibrary(ClassLoader.j…...
单片机的低功耗模式介绍
文章目录 简介一、功耗来源说明1.1、芯片工作模式1.2、静态损耗1.3、I/O额外损耗1.4、动态损耗 二、功耗如何测量三、降低功耗有什么方法3.1、选取合适的芯片工作模式3.2、降低工作频率3.3、关闭不需要使用的外设3.4、 降低静态电流损耗3.5、 周期采集供电3.6、 设置IO口状态 四…...
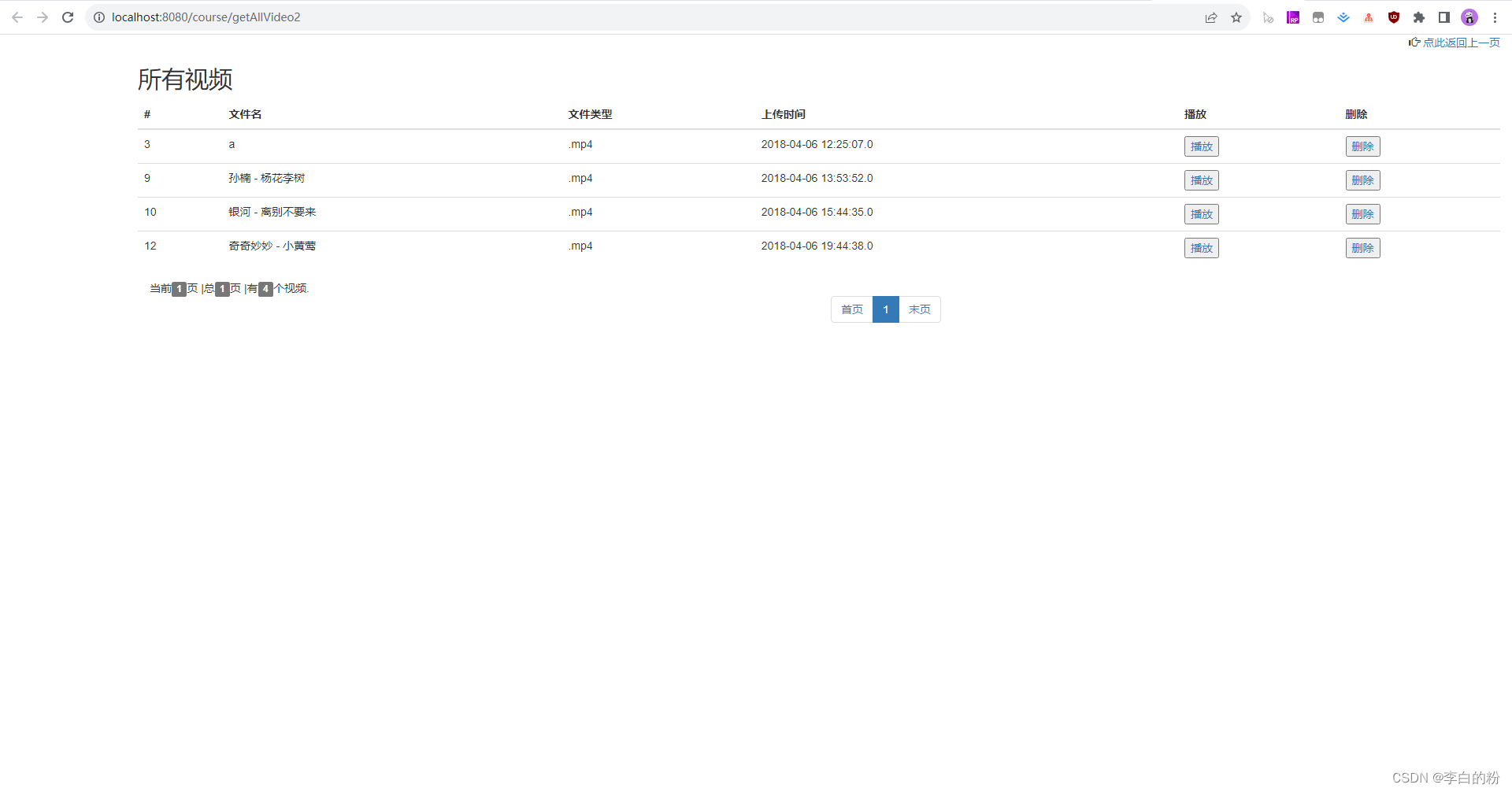
基于SSM实现的精品课程网站
一、系统架构 前端:jsp | js | css | jquery | bootstrap 后端:spring | springmvc | mybatis 环境:jdk1.7 | mysql | maven | tomcat 二、代码及数据库 三、功能介绍 01. 登录页 02. web端-首页 03. web端-视频教程 04. web端-资料…...

广州旅游攻略(略说一二)
广州是中国南方的一个重要城市,也是广东省的省会,拥有着悠久的历史和丰富的文化遗产。作为中国最繁华的城市之一,广州吸引了大量的游客前来探索其独特的魅力。今天我将为大家介绍一份广州旅游攻略,希望能帮助各位游客更好地了解这…...

C++STL的list模拟实现
文章目录 前言 list实现push_back迭代器(重点)普通迭代器const迭代器 inserterase析构函数构造函数拷贝构造赋值 vector和list的区别 前言 要实现STL的list, 首先我们还得看一下list的源码。 我们看到这么一个东西,我们知道C兼容C,可以用struct来创建一…...

django--分页功能
Django 提供了强大的分页功能,可以轻松地在视图中实现分页。 在视图中使用分页: # views.py from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger from django.shortcuts import render from .models import YourModeldef your…...
centOS安装bochsXshell连接centos启动可视化界面
centOS安装bochs 参考:https://blog.csdn.net/muzi_since/article/details/102559187 首先安装依赖环境: yum install gtk2 gtk2-devel yum install libXt libXt-devel yum install libXpm libXpm-devel yum install SDL SDL-devel yum install libXr…...

mac m2芯片 安装nginx + php + mysql
1.安装homebrew: 系统本身就有(命令brew -v查看下),如果没有安装一下 /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" 2.安装nginx brew install nginx 3.安装php bre…...

vue axios 使用
使用Vue中的Axios需要先安装axios库,可以通过yarn或npm安装: yarn add axios # 或者 npm install axios --save然后在Vue组件中导入axios并使用: import axios from axios;export default {data() {return {responseData: null,error: null…...

使用docker实现logstash同步mysql到es
准备工作: 1.有mysql的连接方式,并且可以连接成功 2.有es的连接方式,并且可以连接成功 3.安装了docker 环境是Ubuntu中安装了docker 一、创建配置文件,用于容器卷挂载 # 切换目录,可自定义 cd /home/test/ # 创建lo…...
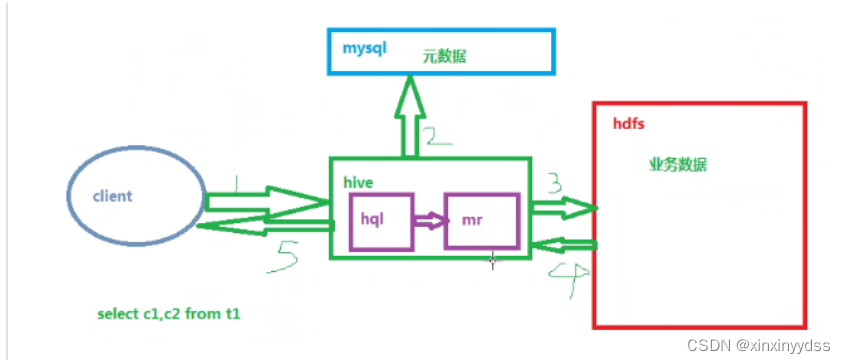
hive数据仓库工具
1、hive是一套操作数据仓库的应用工具,通过这个工具可实现mapreduce的功能 2、hive的语言是hql[hive query language] 3、官网hive.apache.org 下载hive软件包地址 Welcome! - The Apache Software Foundationhttps://archive.apache.org/ 4、hive在管理数据时分为元…...

C语言 联合体验证 主机字节序 +枚举
联合体应用:验证当前主机的大小端(字节序) //验证当前主机的大小端 #include <stdio.h>union MyData {unsigned int data;struct{unsigned char byte0;unsigned char byte1;unsigned char byte2;unsigned char byte3;}byte; };int main…...
python和pygame实现烟花特效
python和pygame实现烟花特效 新年来临之际,来一个欢庆新年烟花祝贺,需要安装使用第三方库pygame,关于Python中pygame游戏模块的安装使用可见 https://blog.csdn.net/cnds123/article/details/119514520 效果图及源码 先看效果图:…...

SillyTavern角色卡片系统:打造属于你的AI灵魂伴侣
SillyTavern角色卡片系统:打造属于你的AI灵魂伴侣 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否曾经幻想过,能有一个真正理解你、陪伴你的AI伙伴࿱…...
)
告别Vivado依赖!手把手教你用Modelsim独立仿真Vivado IP核(附PLL报错解决方案)
深度解析:如何高效利用Modelsim独立仿真Vivado IP核 在FPGA开发领域,仿真环节往往成为项目进度的瓶颈。许多工程师习惯性地依赖Vivado自带的仿真环境,却忽视了专业仿真工具Modelsim的强大性能。本文将带您突破这一局限,掌握脱离Vi…...

Sendwithus模板与现代邮件客户端兼容性测试:终极解决方案
Sendwithus模板与现代邮件客户端兼容性测试:终极解决方案 【免费下载链接】templates Sendwithus Open Source Email Templates 项目地址: https://gitcode.com/gh_mirrors/temp/templates Sendwithus Open Source Email Templates是一套强大的开源邮件模板集…...

3步快速安装Android应用的终极指南:告别模拟器时代
3步快速安装Android应用的终极指南:告别模拟器时代 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过在Windows电脑上直接运行Android应用&…...

38岁大厂P9被裁后卖保险:成年人的职场,没有铁饭碗
来自:推荐一个程序员编程资料站:http://cxyroad.com副业赚钱专栏:https://xbt100.top2024年IDEA最新激活方法后台回复:激活码CSDN免登录复制代码插件下载:CSDN复制插件以下是正文。01 | P9也不是免死金牌最近在网上看到…...

长期使用Taotoken的体验,账单清晰与模型切换便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的体验,账单清晰与模型切换便利性 作为长期将大模型能力集成到项目中的开发者,选择一个稳…...

Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型 对于需要在项目中集成大语言模型的 Python 开发者而言,逐…...

PPTist:5分钟创建专业演示文稿的免费开源在线PPT制作工具终极指南
PPTist:5分钟创建专业演示文稿的免费开源在线PPT制作工具终极指南 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, …...

如何彻底释放惠普OMEN游戏本性能:终极免费硬件控制工具指南
如何彻底释放惠普OMEN游戏本性能:终极免费硬件控制工具指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏本官方软件臃肿…...

GAD7980 ADC在振动数据采集中的实战应用与设计要点
1. 项目概述:为什么我们需要“快、精、高”的振动数据采集?在工业设备状态监测、精密仪器分析乃至消费电子性能评估领域,振动数据就像设备的“心电图”。它直接反映了机械结构的健康状况、运动部件的平衡性以及系统运行的稳定性。过去&#x…...