跟着我学Python基础篇:08.集合和字典
往期文章
跟着我学Python基础篇:01.初露端倪
跟着我学Python基础篇:02.数字与字符串编程
跟着我学Python基础篇:03.选择结构
跟着我学Python基础篇:04.循环
跟着我学Python基础篇:05.函数
跟着我学Python基础篇:06.列表
跟着我学Python基础篇:07.文本
目录
- 往期文章
- 1. 集合
- 1.1 创建和使用集合
- 1.2 增加和删除元素
- 1.3 子集,并集,交集和差集
- 2. 字典
- 2.1 创建字典
- 2.2 访问字典
- 2.3 修改字典中的值
- 2.4 添加新的键值对
- 2.5 删除
- 2.6 遍历
1. 集合
集合是包含一组唯一值的容器,和列表不一样,集合中的元素不以任何特定的顺序存储,不能通过位置进行访问。集合对象的可用操作和数学上的操作是一样的,因为集合不需要维护特定的顺序,集合操作和等价的列表操作相比要快地多。
1.1 创建和使用集合
为了创建带有初识元素的集合,可以指定包含在大括号中的元素。
cast={"lq","lxy","lx","mxm"}
或者,可以用set函数将任何序列转换为集合:
name=["tmo","jerry","tutu","shuazi"]
cast=set(name)python中不能通过{}来创建空集合,但是可以使用没有参数的set来创建。
cast=set()和其他容器一样,可以使用len函数来获取元素数量,使用in函数和not in函数来确定元素是否在集合中。
由于集合是无序的,不能像列表那样使用位置来访问集合中的元素,相反使用for循环迭代独立元素,但是注意,元素的访问顺序依赖于他们在内部是如何存储的,而非我们所看到的顺序。
name=["tmo","jerry","tutu","shuazi"]
cast=set(name)for characters in cast:print(characters)
我们可以看到,集合输出中的顺序和创建时候的顺序是不同的。这种不保持初始顺序使更多高效操作得到可能。
1.2 增加和删除元素
集合对象可以添加和删除元素,提供了一些常用的方法来操作集合。下面是集合增加和删除元素的方法:
- 增加元素:
- add(element):向集合中添加一个元素。
- update(iterable):将一个可迭代对象中的元素添加到集合中。
# 使用add()方法添加单个元素
my_set = {1, 2, 3}
my_set.add(4)
print(my_set) # 输出 {1, 2, 3, 4}# 使用update()方法添加多个元素
my_set = {1, 2, 3}
my_set.update([4, 5, 6])
print(my_set) # 输出 {1, 2, 3, 4, 5, 6}
- 删除元素:
- remove(element):从集合中移除指定的元素,如果元素不存在,则抛出KeyError异常。
- discard(element):从集合中移除指定的元素,如果元素不存在,则不抛出异常。
- pop():随机移除并返回集合中的一个元素。
- clear():清空集合中的所有元素。
my_set = {1, 2, 3, 4, 5}my_set.remove(3)
print(my_set) # 输出 {1, 2, 4, 5}my_set.discard(2)
print(my_set) # 输出 {1, 4, 5}element = my_set.pop()
print(element) # 随机输出集合中的一个元素my_set.clear()
print(my_set) # 输出 set()
需要注意的是,尝试从集合中删除不存在的元素时,remove()方法会引发KeyError异常,而discard()方法则不会。此外,由于集合是无序的,因此使用pop()方法随机移除并返回集合中的一个元素。
1.3 子集,并集,交集和差集
在Python中,集合(Set)对象支持多种集合操作,包括子集、并集、交集和差集:
- 子集(Subset):
- 如果集合A的所有元素都包含在集合B中,则集合A是集合B的子集。
- 使用issubset()方法来检查一个集合是否是另一个集合的子集。
A = {1, 2, 3}
B = {1, 2, 3, 4, 5}# 检查A是否是B的子集
result = A.issubset(B)
print(result) # 输出 True
- 并集(Union):
- 两个集合的并集包含了两个集合中的所有元素,且不重复。
- 使用union()方法或者
|运算符来获取两个集合的并集。
A = {1, 2, 3}
B = {3, 4, 5}# 获取A和B的并集
result = A.union(B) # 或者使用 result = A | B
print(result) # 输出 {1, 2, 3, 4, 5}
- 交集(Intersection):
- 两个集合的交集包含了同时存在于两个集合中的所有元素。
- 使用intersection()方法或者&运算符来获取两个集合的交集。
A = {1, 2, 3, 4}
B = {3, 4, 5}# 获取A和B的交集
result = A.intersection(B) # 或者使用 result = A & B
print(result) # 输出 {3, 4}
- 差集(Difference):
- 一个集合相对于另一个集合的差集包含了属于第一个集合但不属于第二个集合的所有元素。
- 使用difference()方法或者-运算符来获取两个集合的差集。
A = {1, 2, 3, 4}
B = {3, 4, 5}# 获取A相对于B的差集
result = A.difference(B) # 或者使用 result = A - B
print(result) # 输出 {1, 2}
2. 字典
字典是在键和值之间的容器。字典中的每个键有个关联的值,键是唯一的值,但一个值可能会被关联到多个键上。
字典是可变的,可以动态添加、修改和删除键值对。
2.1 创建字典
- 创建字典:
# 创建一个空字典
my_dict = {}# 创建带有初始键值对的字典
my_dict = {'name': 'John', 'age': 25, 'city': 'New York'}
2.2 访问字典
- 访问字典中的值:
my_dict = {'name': 'John', 'age': 25, 'city': 'New York'}# 通过键访问值
print(my_dict['name']) # 输出: John# 使用get()方法访问值(如果键不存在,返回指定的默认值)
print(my_dict.get('age')) # 输出: 25
print(my_dict.get('country', 'USA')) # 输出: USA(键'country'不存在,返回默认值'USA')
2.3 修改字典中的值
- 修改字典中的值:
my_dict = {'name': 'John', 'age': 25, 'city': 'New York'}# 修改键'name'对应的值
my_dict['name'] = 'Mike'
print(my_dict) # 输出: {'name': 'Mike', 'age': 25, 'city': 'New York'}
2.4 添加新的键值对
- 添加新的键值对:
my_dict = {'name': 'John', 'age': 25, 'city': 'New York'}# 添加新的键值对
my_dict['country'] = 'USA'
print(my_dict) # 输出: {'name': 'John', 'age': 25, 'city': 'New York', 'country': 'USA'}
2.5 删除
- 删除键值对:
my_dict = {'name': 'John', 'age': 25, 'city': 'New York'}# 删除键'age'对应的键值对
del my_dict['age']
print(my_dict) # 输出:{'name': 'John', 'city': 'New York'}# 清空字典
my_dict.clear()
print(my_dict) # 输出: {}
2.6 遍历
- 遍历字典:
my_dict = {'name': 'John', 'age': 25, 'city': 'New York'}# 遍历键
for key in my_dict:print(key) # 输出: name, age, city# 遍历值
for value in my_dict.values():print(value) # 输出: John, 25, New York# 遍历键值对
for key, value in my_dict.items():print(key, value) # 输出: name John, age 25, city New York
相关文章:
跟着我学Python基础篇:08.集合和字典
往期文章 跟着我学Python基础篇:01.初露端倪 跟着我学Python基础篇:02.数字与字符串编程 跟着我学Python基础篇:03.选择结构 跟着我学Python基础篇:04.循环 跟着我学Python基础篇:05.函数 跟着我学Python基础篇&#…...
Tomcat部署(图片和HTML等)静态资源时遇到的问题
文章目录 Tomcat部署静态资源问题图中HTML代码启动Tomcat后先确认Tomcat是否启动成功 Tomcat部署静态资源问题 今天,有人突然跟我提到,使用nginx部署静态资源,如图片。可以直接通过url地址访问,为什么他的Tomcat不能通过这样的方…...

在接触新的游戏引擎的时候,如何能快速地熟悉并开发出一款新游戏?
引言 大家好,今天分享点个人经验。 有一定编程经验或者游戏开发经验的小伙伴,在接触新的游戏引擎的时候,如何能快速地熟悉并开发出一款新游戏? 利用现成开发框架。 1.什么是开发框架? 开发框架,顾名思…...

计网 - TCP四次挥手原理全曝光:深度解析与实战演示
文章目录 Pre导图过程分析抓包实战第一次挥手 【FIN ACK】第二次挥手 【ACK】第三次挥手 【FINACK】第四次挥手 【ACK】 小结 Pre 计网 - 传输层协议 TCP:TCP 为什么握手是 3 次、挥手是 4 次? 计网 - TCP三次握手原理全曝光:深度解析与实战…...

个人养老金知多少?
个人养老金政策你了解吗?税优政策你知道吗?你会计算能退多少税吗?… 点这里看一看...
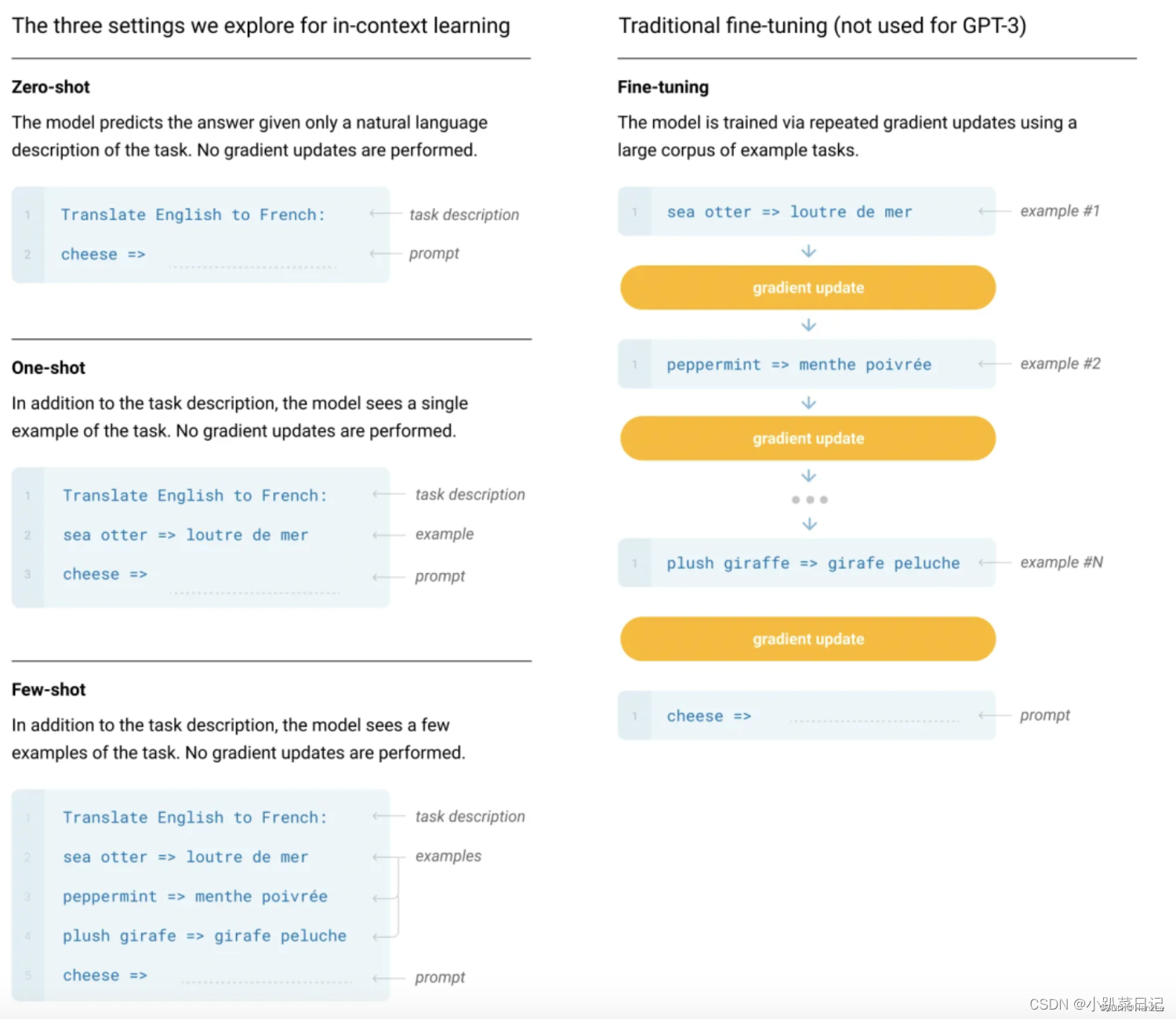
gpt3、gpt2与gpt1区别
参考:深度学习:GPT1、GPT2、GPT-3_HanZee的博客-CSDN博客 Zero-shot Learning / One-shot Learning-CSDN博客 Zero-shot(零次学习)简介-CSDN博客 GPT1、GPT2、GPT3、InstructGPT-CSDN博客 目录 gpt2与gpt1区别: gp…...
PyQt6 QDateEdit日期控件
锋哥原创的PyQt6视频教程: 2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~共计39条视频,包括:2024版 PyQt6 Python桌面开发 视频教程(无废话…...
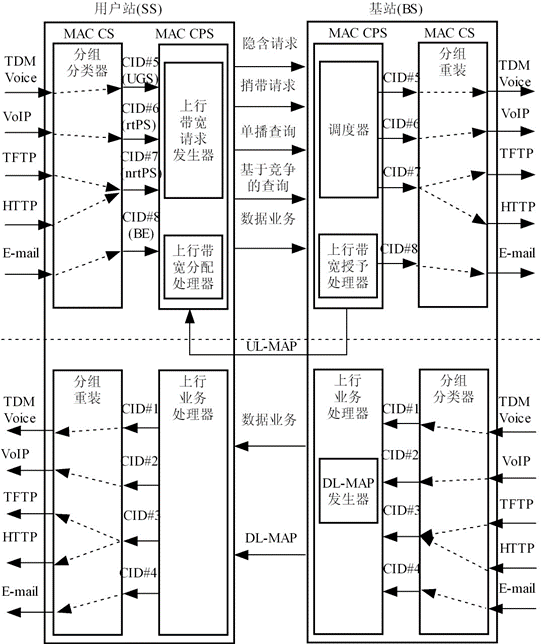
【无线网络技术】——无线城域网(学习笔记)
📖 前言:无线城域网(WMAN)是指在地域上覆盖城市及其郊区范围的分布节点之间传输信息的本地分配无线网络。能实现语音、数据、图像、多媒体、IP等多业务的接入服务。其覆盖范围的典型值为3~5km,点到点链路的覆盖可以高达…...
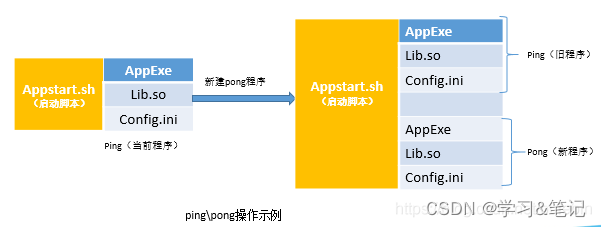
RK3568平台 OTA升级原理
一.前言 在迅速变化和发展的物联网市场,新的产品需求不断涌现,因此对于智能硬件设备的更新需求就变得空前高涨,设备不再像传统设备一样一经出售就不再变更。为了快速响应市场需求,一个技术变得极为重要,即OTA空中下载…...

mysql迁移步骤
MySQL迁移是指将MySQL数据库从一台服务器迁移到另一台服务器。这可能是因为您需要升级服务器、增加存储空间、提高性能或改变数据库架构。 以下是MySQL迁移的一般步骤: 以上是MySQL迁移的一般步骤,具体步骤可能因您的环境和需求而有所不同。在进行迁移之…...

计算机网络应用层(期末、考研)
计算机网络总复习链接🔗 目录 DNS域名服务器域名解析过程分类递归查询(给根域名服务器造成的负载过大,实际中几乎不用)迭代查询 域名缓存(了解即可)完整域名解析过程采用UDP服务 FTP控制连接与数据连接 电…...
Jenkins离线安装部署教程简记
前言 在上一篇文章基于Gitee实现Jenkins自动化部署SpringBoot项目中,我们了解了如何完成基于Jenkins实现自动化部署。 对于某些公司服务器来说,是不可以连接外网的,所以笔者专门整理了一篇文章总结一下,如何基于内网直接部署Jen…...

如果一个嵌套类需要在单个方法之外仍然是可见,或者它太长,不适合放在方法内部,就应该使用成员类。
当一个嵌套类需要在单个方法之外仍然是可见,或者它太长不适合放在方法内部时,可以考虑使用成员类(成员内部类)。成员类是声明在类的内部但不是在方法内部的类,可以访问外部类的实例成员。 以下是一个示例,…...

Vue3 中的 Proxy--读懂ES6中的Proxy
Proxy用于创建一个对象的代理,从而实现基本操作的拦截和自定义(如属性查找、赋值、枚举、函数调用等) 1.用法 Proxy为 构造函数,用来生成 Proxy实例 var proxy new Proxy(target, handler)参数 target表示所要拦截的目标对象…...
zk_dubbo
图灵面试笔记 zk dubbo spi dubbo 文章 dubbo与spring整合之Service、Reference注解处理过程 JAVA备忘录...
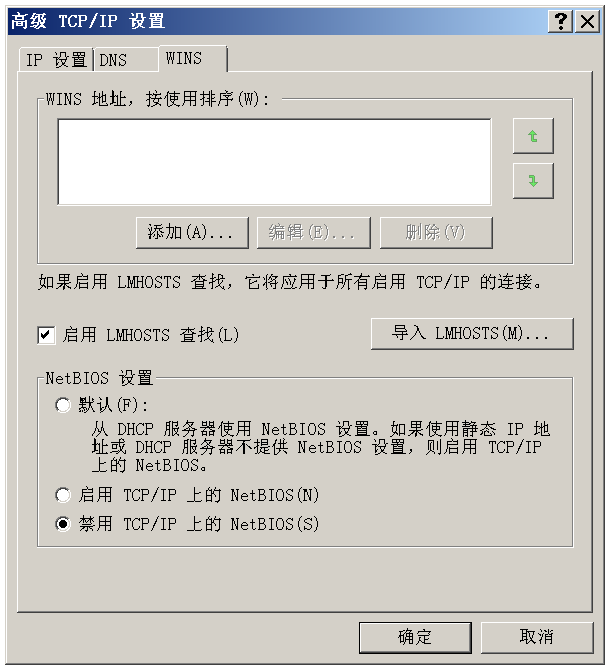
Windows 安全基础——NetBIOS篇
Windows 安全基础——NetBIOS篇 1. NetBIOS简介 NetBIOS(Network Basic Input/Output System, 网络基本输入输出系统)是一种接入服务网络的接口标准。主机系统通过WINS服务、广播及lmhosts文件多种模式,把NetBIOS名解析对应的IP地址…...

【基础知识】Hadoop生态系统
Hadoop是一个开源的分布式计算框架,主要用于大数据的存储和处理,即一个包含多种组件的综合分布式系统,组件相互协作完成从数据存储到计算分析的完整功能。 关键词——容灾 主从结构、多副本 主要特点 分布式存储 - Hadoop采用HDFS文件系统,可以将大数据分布式存…...
[Linux] LAMP架构
一、LAMP架构架构的概述 LAMP 架构是一种流行的 Web 应用程序架构,它的名称是由四个主要组件的首字母组成的: Linux(操作系统): 作为操作系统,Linux 提供了服务器的基础。它负责处理硬件资源、文件系统管理…...
HPM5300系列--第二篇 Visual Studio Code开发环境以及多种调试器调试模式
一、目的 在博文《HPM5300系列--第一篇 命令行开发调试环境搭建》、《HPM6750系列--第四篇 搭建Visual Studio Code开发调试环境》中我们介绍了命令行方式开发环境,也介绍了HPM6750evkmini开发板如何使用Visual Studio Code进行开发调试(其中调试方式使用…...

LeetCode2697. Lexicographically Smallest Palindrome
文章目录 一、题目二、题解 一、题目 You are given a string s consisting of lowercase English letters, and you are allowed to perform operations on it. In one operation, you can replace a character in s with another lowercase English letter. Your task is t…...

轻量级工作流编排引擎:从脚本管理到自动化流程的实践指南
1. 项目概述:从单体脚本到流程编排的进化 如果你和我一样,在数据工程、自动化运维或者机器学习模型训练这些领域摸爬滚打过几年,大概率会遇到一个相似的困境:手头的任务脚本越来越多,它们之间有的有依赖关系࿰…...

Ix开源平台:基于Kubernetes的私有云与家庭实验室一体化管理方案
1. 项目概述与核心价值最近在折腾一个叫Ix的开源项目,它来自ix-infrastructure这个组织。乍一看这个名字,你可能觉得有点抽象,但如果你对自托管、家庭实验室、私有云或者想找一个更现代、更易用的 TrueNAS 替代品感兴趣,那这个项目…...

Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南
Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirro…...
)
【稀缺首发】Midjourney达达主义风格提示工程白皮书:含89组对比实验数据+12个独家种子编号(限前500名下载)
更多请点击: https://intelliparadigm.com 第一章:达达主义在AI图像生成中的哲学解构 达达主义并非技术流派,而是一场对逻辑、秩序与意义权威的激进质疑——这一精神正悄然渗透至当代AI图像生成的核心机制中。当Stable Diffusion接收“一只会…...

OpenSpeedy终极指南:如何通过开源游戏加速工具突破帧率限制
OpenSpeedy终极指南:如何通过开源游戏加速工具突破帧率限制 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏中的卡顿和帧率限制?Open…...

阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程
阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本OAS是一款专门为《阴阳师》游戏设计的智能自动…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...

开源PCB自动布线神器FreeRouting:5分钟上手,效率提升300%
开源PCB自动布线神器FreeRouting:5分钟上手,效率提升300% 【免费下载链接】freerouting Advanced PCB auto-router 项目地址: https://gitcode.com/gh_mirrors/fr/freerouting FreeRouting是一款功能强大的开源PCB自动布线工具,它能帮…...

服务网格Istio实战
服务网格Istio实战 引言 服务网格(Service Mesh)作为微服务架构的基础设施层,提供了对服务间通信的精细控制能力。Istio是目前最流行的开源服务网格解决方案,它通过Sidecar代理拦截所有网络通信,提供流量管理、安全、可…...

Claude API封装项目深度解析:从安全评估到自主构建代码助手
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫 ashish200729/claude-code-source-code 。光看这个标题,很多开发者朋友可能会心头一热,以为这是某个AI模型的源代码被开源了。但作为一个在开源社区混迹多年的老码农&…...