深度学习 Day12——P1实现mnist手写数字识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
文章目录
- 前言
- 1 我的环境
- 2 代码实现与执行结果
- 2.1 前期准备
- 2.1.1 引入库
- 2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
- 2.1.3 导入数据
- 2.1.4 查看数据
- 2.1.5.数据可视化
- 2.2 构建CNN网络模型
- 2.3 训练模型
- 2.3.1 训练模型
- 2.3.2 编写训练函数
- 2.3.3 编写测试函数
- 2.3.4 正式训练
- 2.4 结果可视化
- 3 知识点详解
- 3.1 MNIST手写数字数据集介绍
- 3.2 Torch.NN简介
- 3.2.1nn.Module模块概述
- 3.2.2 Sequential类的概述
- 3.3【Pytorch】model.train() 和 model.eval() 原理与用法
- 3.3.1 两种模式
- 3.3.2功能
- 3.3.3 总结与对比
- 总结
前言
本文将采用pytorch框架创建CNN网络,实现简单实现mnist手写数字识别。讲述实现代码与执行结果,并浅谈涉及知识点。
关键字:MNIST手写数字数据集介绍,Torch.NN简介,Pytorch】model.train() 和 model.eval() 原理与用法。
1 我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm2020.2.3
- 深度学习环境:
torch == 1.9.1+cu111
torchvision == 0.10.1+cu111 - 显卡:NVIDIA GeForce RTX 4070
2 代码实现与执行结果
2.1 前期准备
2.1.1 引入库
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
import torchvision
import numpy as np
from torchinfo import summary
import torch.nn.functional as F
import warningswarnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
"""前期准备-设置GPU-"""
# 如果设备上支持GPU就使用GPU,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
输出
cuda
2.1.3 导入数据
'''前期工作-导入数据'''
train_ds = torchvision.datasets.MNIST('data', train=True, transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensordownload=True)test_ds = torchvision.datasets.MNIST('data', train=False, transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensordownload=True)
batch_size = 32train_dl = torch.utils.data.DataLoader(train_ds, batch_size=batch_size, shuffle=True)test_dl = torch.utils.data.DataLoader(test_ds, batch_size=batch_size)
2.1.4 查看数据
'''前期工作-查看数据'''
# 取一个批次查看数据格式
# 数据的shape为:[batch_size, channel, height, weight]
# 其中batch_size为自己设定,channel,height和weight分别是图片的通道数,高度和宽度。
imgs, labels = next(iter(train_dl)) # 通过 iter(train_dl) 创建一个数据迭代器,然后使用 next(train_dl) 从训练数据加载一个批次的图像和对应的标签。
# images包含了一批图像,labels 包含了这些图像的类别标签。
print(imgs.shape)
输出
torch.Size([32, 1, 28, 28])
2.1.5.数据可视化
'''前期工作-数据可视化'''
# 指定图片大小,图像大小为20宽、5高的绘图(单位为英寸inch)
plt.figure(figsize=(20, 5))
for i, img in enumerate(imgs[:20]):# 维度缩减,去除所有维度为1的维度npimg = np.squeeze(img.numpy())# 将整个figure分成2行10列,绘制第i+1个子图。plt.subplot(2, 10, i + 1)plt.imshow(npimg, cmap=plt.cm.binary) # 使用matlablib库cm子库中的binary颜色映射,讲图像渲染维黑白色plt.axis('off') # 取消坐标轴显示
plt.show() # 如果你使用的是Pycharm编译器,请加上这行代码
2.2 构建CNN网络模型
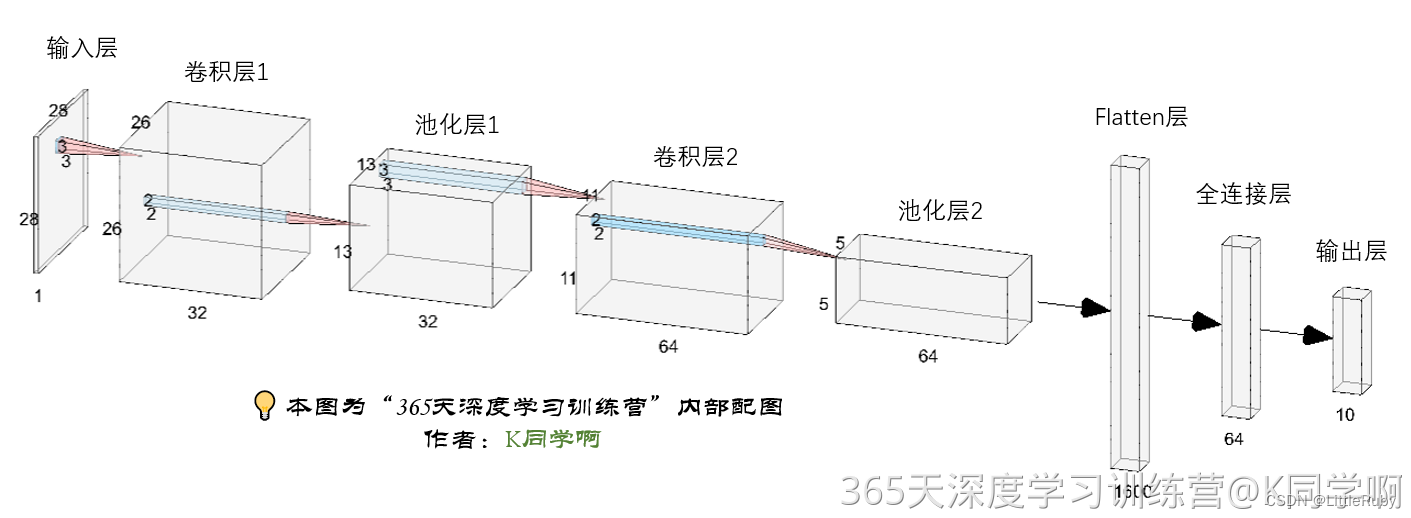
"""构建CNN网络"""
num_classes = 10 # 图片的类别数class Model(nn.Module):def __init__(self):super().__init__()# 特征提取网络self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 第一层卷积,卷积核大小为3*3self.pool1 = nn.MaxPool2d(2) # 设置池化层,池化核大小为2*2self.conv2 = nn.Conv2d(32, 64, kernel_size=3) # 第二层卷积,卷积核大小为3*3self.pool2 = nn.MaxPool2d(2)# 分类网络self.fc1 = nn.Linear(1600, 64)self.fc2 = nn.Linear(64, num_classes)# 前向传播def forward(self, x):x = self.pool1(F.relu(self.conv1(x)))x = self.pool2(F.relu(self.conv2(x)))x = torch.flatten(x, start_dim=1)x = F.relu(self.fc1(x))x = self.fc2(x)return x# 将模型转移到GPU中(我们模型运行均在GPU中进行)
model = Model().to(device)
summary(model)
输出
=================================================================
Layer (type:depth-idx) Param #
=================================================================
Model --
├─Conv2d: 1-1 320
├─MaxPool2d: 1-2 --
├─Conv2d: 1-3 18,496
├─MaxPool2d: 1-4 --
├─Linear: 1-5 102,464
├─Linear: 1-6 650
=================================================================
Total params: 121,930
Trainable params: 121,930
Non-trainable params: 0
=================================================================
2.3 训练模型
2.3.1 训练模型
"""训练模型--设置超参数"""
loss_fn = nn.CrossEntropyLoss() # 创建损失函数,计算实际输出和真实相差多少,交叉熵损失函数,事实上,它就是做图片分类任务时常用的损失函数
learn_rate = 1e-2 # 学习率
opt = torch.optim.SGD(model.parameters(), lr=learn_rate) # 作用是定义优化器,用来训练时候优化模型参数;其中,SGD表示随机梯度下降,用于控制实际输出y与真实y之间的相差有多大2.3.2 编写训练函数
"""训练模型--编写训练函数"""
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共60000张图片num_batches = len(dataloader) # 批次数目,1875(60000/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 加载数据加载器,得到里面的 X(图片数据)和 y(真实标签)X, y = X.to(device), y.to(device) # 用于将数据存到显卡# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # 清空过往梯度loss.backward() # 反向传播,计算当前梯度optimizer.step() # 根据梯度更新网络参数# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
2.3.3 编写测试函数
"""训练模型--编写测试函数"""
# 测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad(): # 测试时模型参数不用更新,所以 no_grad,整个模型参数正向推就ok,不反向更新参数for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()#统计预测正确的个数test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss2.3.4 正式训练
"""训练模型--正式训练"""
epochs = 5
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print('Done')
输出
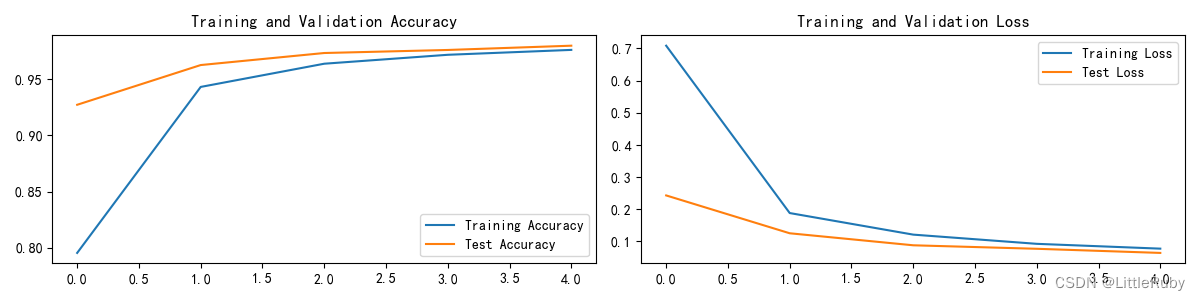
Epoch: 1, Train_acc:79.5%, Train_loss:0.709, Test_acc:92.7%,Test_loss:0.243
Epoch: 2, Train_acc:94.3%, Train_loss:0.188, Test_acc:96.2%,Test_loss:0.125
Epoch: 3, Train_acc:96.4%, Train_loss:0.121, Test_acc:97.3%,Test_loss:0.088
Epoch: 4, Train_acc:97.2%, Train_loss:0.093, Test_acc:97.6%,Test_loss:0.077
Epoch: 5, Train_acc:97.6%, Train_loss:0.078, Test_acc:98.0%,Test_loss:0.064
Done
2.4 结果可视化
"""训练模型--结果可视化"""
epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
3 知识点详解
3.1 MNIST手写数字数据集介绍
MNIST手写数字数据集来源于是美国国家标准与技术研究所,是著名的公开数据集之一。数据集中的数字图片是由250个不同职业的人纯手写绘制,数据集获取的网址为:http://yann.lecun.com/exdb/mnist/(下载后需解压)。我们一般会采用(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()这行代码直接调用,这样就比较简单MNIST手写数字数据集中包含了70000张图片,其中60000张为训练数据,10000为测试数据,70000张图片均是2828,如果我们把每一张图片中的像素转换为向量,则得到长度为2828=784的向量。因此我们可以把训练集看成是一个[60000,784]的张量,第一个维度表示图片的索引,第二个维度表示每张图片中的像素点。而图片里的每个像素点的值介于0-1之间。
在pytorch下可以直接调用torchvision.datasets里面的MNIST数据集(这是官方写好的数据集类)
train = torchvision.datasets.MNIST(root='./data/',train=True, transform= transforms.ToTensor())
作用
从 torchvision 中加载 MNIST 数据集的训练集
参数
- root=‘./data’: 数据集将被下载并保存在当前工作目录下的 ‘data’ 子目录中
- train=True: 加载训练集
- download=True: 如果数据集不存在,则下载数据集
- transform=transforms.ToTensor(): #接收PIL图片并返回转换后版本图片的转换函数,这里为将图像转换为 PyTorch 的 Tensor 格式
返回值为一个元组(train_data,train_target)(这个类使用的时候也有坑,必须用train[i]索引才能使用 transform功能),一般是与torch.utils.data.DataLoader配合使用
dataloader = DataLoader(train, batch_size=50,shuffle=True, num_workers=4)
for step, (x, y) in enumerate(dataloader):b_x = x.shapeb_y = y.shapeprint 'Step: ', step, '| train_data的维度' ,b_x,'| train_target的维度',b_y
作用
创建一个 DataLoader 对象,用于对数据进行批量加载和处理
参数
- trainset: 要加载的数据集
- batch_size=4: 每个批次包含的图像样本数量
- shuffle=True: 打乱数据,以便在每个 epoch 中随机访问样本
- num_workers=4:并行处理数
3.2 Torch.NN简介
torch.nn 是 PyTorch 中用于构建神经网络的模块。它提供了一组类和函数,用于定义、训练和评估神经网络模型。
torch.nn 模块的核心是 nn.Module 类,它是所有神经网络模型的基类。在Containers中通过继承 nn.Module 类,您可以创建自己的神经网络模型,并定义模型的结构和操作。
以下是 torch.nn 模块中常用的一些类和函数:
- nn.Linear: 线性层,用于定义全连接层,可以起到特征提取器的作用,最后一层的全连接层也可以认为是输出层,传入参数为输入特征数和输出特征数(输入特征数由特征提取网络计算得到,如果不会计算可以直接运行网络,报错中会提示输入特征数的大小,下方网络中第一个全连接层的输入特征数为1600。
- nn.Conv2d: 二维卷积层,用于处理图像数据。
- nn.ReLU: ReLU 激活函数。
- nn.Sigmoid: Sigmoid 激活函数。
- nn.Dropout: Dropout 层,用于正则化和防止过拟合。
- nn.CrossEntropyLoss: 交叉熵损失函数,通常用于多类别分类问题。
- nn.MSELoss: 均方误差损失函数,通常用于回归问题。
- nn.Sequential: 顺序容器,用于按顺序组合多个层,在初始化阶段就设定好网络结构,不需要在前向传播中重新写一遍。
使用 torch.nn 模块,您可以创建自定义的神经网络模型,并使用 PyTorch 提供的优化器(如 torch.optim)和损失函数来训练和优化模型。
3.2.1nn.Module模块概述
nn.Module类的基本定义
在定义自已的网络的时候,需要继承nn.Module类,并重新实现构造函数__init__()和forward这两个方法。在构造函数__init__()中使用super(Model, self).init()来调用父类的构造函数,forward方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心。
1.一般把网络中具有可学习参数的层(如全连接层、卷积层)放在构造函数__init__()中。
2.一般把不具有可学习参数的层(如ReLU、dropout)可放在构造函数中,也可不放在构造函数中(在forward中使用nn.functional来调用)。
示例1:将具有可学习参数层和不具有可学习参数层均放在构造函数中
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):def __init__(self):super(Model, self).__init__() # 调用父类的构造函数self.con2v = nn.Conv2d(1, 3, 3, 1)self.relu = nn.ReLU()self.max_pooling = nn.MaxPool2d(2, 1)def forward(self, x):x = self.con2v(x)x = self.relu(x)x = self.max_pooling(x)return x
model = Model()
print(model)
''' 可看到输出的模型结构
Model((con2v): Conv2d(1, 3, kernel_size=(3, 3), stride=(1, 1))(relu): ReLU()(max_pooling): MaxPool2d(kernel_size=2, stride=1, padding=0, dilation=1, ceil_mode=False)
)
'''示例2:把不具有可学习参数的层不放在构造函数中(在forward中使用nn.functional调用)
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):def __init__(self):super(Model, self).__init__() # 调用父类的构造函数self.con2v = nn.Conv2d(1, 3, 3, 1)self.max_pooling = nn.MaxPool2d(2, 1)def forward(self, x):x = self.con2v(x)x = F.relu(x)x = self.max_pooling(x)return x
model = Model()
print(model)
''' 可看到输出的模型结构
Model((con2v): Conv2d(1, 3, kernel_size=(3, 3), stride=(1, 1))(max_pooling): MaxPool2d(kernel_size=2, stride=1, padding=0, dilation=1, ceil_mode=False)
)
'''
由此可看出不具有可学习参数层没有放在构造函数里面,那么这些层就不会出现在model中。
也就是在构造函数__init__()中只是定义了模型的结构,而在forward方法中实现了模型中的所有层的连接。
3.只要在nn.Module中定义了forward函数,backward函数就会被自动实现(利用Autograd)。而且一般不是显式的调用forward(layer.forward), 而是layer(input), 会自执行forward()。
3.2.2 Sequential类的概述
nn.Sequential的定义:一个有顺序容器,神经网络模块将按照构造函数中传递的顺序添加到该容器中。此外,也可以传入一个有序的模块字典。
Sequenrial类实现了整数索引,每一个层是没有名称的,默认是以0、1、2…这样的index来命名,可以使用model[index]这样的方式获取一个层,并不能够通过名称(如model[“Conv2d”])来获取层。
示例如下:
import torch.nn as nn
class Model(nn.Module):def __init__(self):super(Model, self).__init__() # 调用父类的构造函数self.model1= nn.Sequential(nn.Conv2d(1, 3, 3, 1),nn.ReLU(),nn.Conv2d(3, 9, 3, 1),nn.MaxPool2d(2, 1))def forward(self, x):x = self.struct(x)return x
model = Model()
print(model)
print(model.model1[2]) # 通过索引获取第几个层''' 输出结果
Model((model1): Sequential((0): Conv2d(1, 3, kernel_size=(3, 3), stride=(1, 1))(1): ReLU()(2): Conv2d(3, 9, kernel_size=(3, 3), stride=(1, 1))(3): MaxPool2d(kernel_size=2, stride=1, padding=0, dilation=1, ceil_mode=False))
)
Conv2d(3, 9, kernel_size=(3, 3), stride=(1, 1))
'''
Sequential的三种包装方式
示例如下:
import torch.nn as nn
from collections import OrderedDict
class Model(nn.Module):def __init__(self):super(Model, self).__init__() # 调用父类的构造函数self.model1 = nn.Sequential( # 方式一nn.Conv2d(1, 3, 3, 1),nn.ReLU())self.model2 = nn.Sequential( # 方式二OrderedDict([('conv1', nn.Conv2d(1, 3, 3, 1)),('relu1', nn.ReLU())]))self.model3 = nn.Sequential() # 方式三self.model3.add_module('conv1', nn.Conv2d(1, 3, 3, 1)),self.model3.add_module('relu1', nn.ReLU())def forward(self, x):x = self.model1(x)x = self.model2(x)x = self.model3(x)return x
model = Model()
print(model)''' 输出结果
Model((model1): Sequential((0): Conv2d(1, 3, kernel_size=(3, 3), stride=(1, 1))(1): ReLU())(model2): Sequential((conv1): Conv2d(1, 3, kernel_size=(3, 3), stride=(1, 1))(relu1): ReLU())(model3): Sequential((conv1): Conv2d(1, 3, kernel_size=(3, 3), stride=(1, 1))(relu1): ReLU())
)
'''
参考链接:
nn.Module模块概述
神经网络的基本框架的搭建-nn.Module
3.3【Pytorch】model.train() 和 model.eval() 原理与用法
3.3.1 两种模式
pytorch可以给我们提供两种方式来切换训练和评估(推断)的模式,分别是:model.train() 和 model.eval()。
一般用法是:在训练开始之前写上 model.trian() ,在测试时写上 model.eval() 。
3.3.2功能
1. model.train()
在使用 pytorch 构建神经网络的时候,训练过程中会在程序上方添加一句model.train(),作用是 启用 batch normalization 和 dropout 。
如果模型中有BN层(Batch Normalization)和 Dropout ,需要在 训练时 添加 model.train()。
model.train() 是保证 BN 层能够用到 每一批数据 的均值和方差。对于 Dropout,model.train() 是 随机取一部分 网络连接来训练更新参数。
2. model.eval()
model.eval()的作用是 不启用 Batch Normalization 和 Dropout。
如果模型中有 BN 层(Batch Normalization)和 Dropout,在 测试时 添加 model.eval()。
model.eval() 是保证 BN 层能够用 全部训练数据 的均值和方差,即测试过程中要保证 BN 层的均值和方差不变。对于 Dropout,model.eval() 是利用到了 所有 网络连接,即不进行随机舍弃神经元。
为什么测试时要用 model.eval() ?
训练完 train 样本后,生成的模型 model 要用来测试样本了。在 model(test) 之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,它也会改变权值。这是 model 中含有 BN 层和 Dropout 所带来的的性质。
eval() 时,pytorch 会自动把 BN 和 DropOut 固定住,不会取平均,而是用训练好的值。
不然的话,一旦 test 的 batch_size 过小,很容易就会被 BN 层导致生成图片颜色失真极大。
eval() 在非训练的时候是需要加的,没有这句代码,一些网络层的值会发生变动,不会固定,你神经网络每一次生成的结果也是不固定的,生成质量可能好也可能不好。
也就是说,测试过程中使用model.eval(),这时神经网络会 沿用 batch normalization 的值,而并不使用 dropout。
3.3.3 总结与对比
如果模型中有 BN 层(Batch Normalization)和 Dropout,需要在训练时添加 model.train(),在测试时添加 model.eval()。
其中 model.train() 是保证 BN 层用每一批数据的均值和方差,而 model.eval() 是保证 BN 用全部训练数据的均值和方差;
而对于 Dropout,model.train() 是随机取一部分网络连接来训练更新参数,而 model.eval() 是利用到了所有网络连接。
参考链接:【Pytorch】model.train() 和 model.eval() 原理与用法
总结
通过本文的学习,了解了pytorch网络模型如何创建、训练与测试。
相关文章:
深度学习 Day12——P1实现mnist手写数字识别
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 文章目录 前言1 我的环境2 代码实现与执行结果2.1 前期准备2.1.1 引入库2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用C…...
【Docker实战】基于Dockerfile搭建LNMP+wordpress
一、项目背景和要求 公司在实际的生产环境中,需要使用Docker 技术在一台主机上创建LNMP服务并运行Wordpress网站平台。 然后对此服务进行相关的性能调优和管理工作 二、架构: nginx172.111.0.10docker-nginxmysql172.111.0.20docker-mysqlPHP172.111…...

【桌面应用开发】Tauri是什么?基于Rust的桌面应用
自我介绍 做一个简单介绍,酒架年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【…...

PHP的协程是什么?
PHP 的协程是一种轻量级的线程(或任务)实现,允许在一个进程中同时执行多个协程,但在任意时刻只有一个协程处于执行状态。协程可以看作是一种用户空间线程,由程序员显式地管理,而不是由操作系统内核进行调度…...

three.js 入门三:buffergeometry贴图属性(position、index和uvs)
环境: three.js 0.159.0 一、基础知识 geometry:决定物体的几何形状、轮廓;material:决定物体呈现的色彩、光影特性、贴图皮肤;mesh:场景中的物体,由geometry和materia组成;textu…...

Initial用法-FPGA入门3
Initial是什么 FPGA Initial是一种在FPGA中进行初始化的方法。在FPGA设备上,初始值决定了逻辑门的状态和寄存器的初始值。FPGA Initial可以通过设置初始值来控制电路在上电后的初始状态。 Initial的作用 2.1,控制电路启动时的初始状态 通过设置FPGA Ini…...

perl脚本中使用eval函数执行可能有异常的操作
perl脚本中有时候执行的操作可能会引发异常,为了直观的说明,这里举一个json反序列化的例子,脚本如下: #! /usr/bin/perl use v5.14; use JSON; use Data::Dumper;# 读取json字符串数据 my $json_str join(, <DATA>); # 反…...

『Redis』在Docker中快速部署Redis并进行数据持久化挂载
📣读完这篇文章里你能收获到 在Docke中快速部署Redis如何将Redis的数据进行持久化 文章目录 一、拉取镜像二、创建挂载目录1 宿主机与容器挂载映射2 挂载命令执行 三、创建容器—运行Redis四、查看运行情况 一、拉取镜像 版本号根据需要自己选择,这里以…...
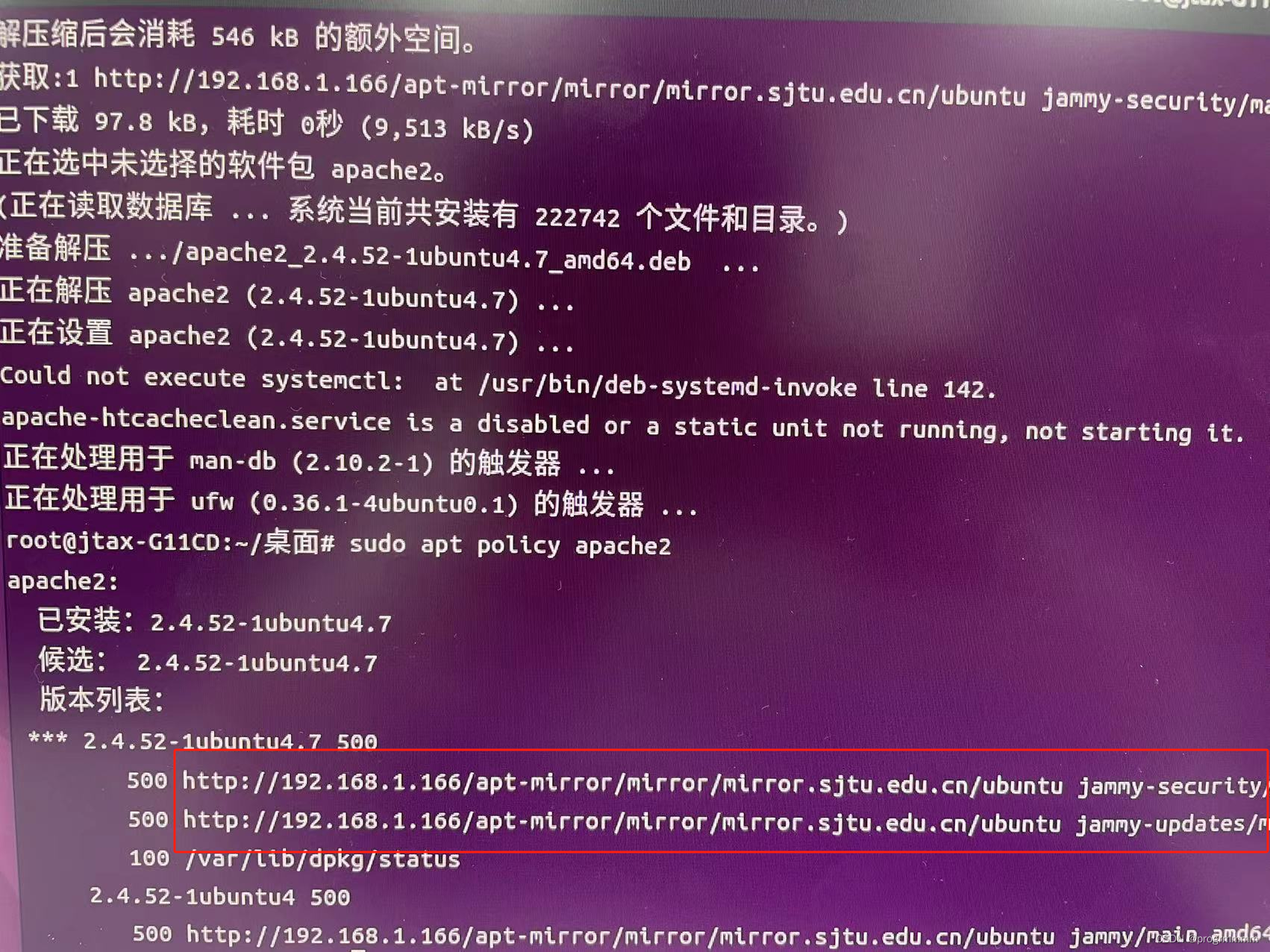
ubuntu创建apt-mirror本地仓库
首先创建apt-mirror的服务端,也就是存储所有apt-get下载的文件和依赖。大约需要300G,预留400G左右空间就可以开始了。 安装ubuntu省略,用的是ubuntu202204 ubuntu挂载硬盘(不需要的可以跳过): #下载挂载工具 sudo apt…...

计算机网络 internet应用 (水
ARPA net ---Internet 前身 发展史: ARPA net 第一个主干网..美国军方NSFnet 美国国家科学基金会NSFANSnet 美国全国 (internet 叫法开始出现) 第二代互联网(现在() IP地址 IP地址 最高管理机构 - InterNIC IPV4 32位 IPV6 128位 域名 起名 解析 domain name sys…...
【ChatGLM3】第三代大语言模型多GPU部署指南
关于ChatGLM3 ChatGLM3是智谱AI与清华大学KEG实验室联合发布的新一代对话预训练模型。在第二代ChatGLM的基础之上, 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、…...

云原生Kubernetes系列 | Docker/Kubernetes的卷管理
云原生Kubernetes系列 | Docker/Kubernetes的卷管理 1. Docker卷管理2. Kubernetes卷管理2.1. 本地存储2.1.1. emptyDir2.1.2. hostPath2.2. 网络存储2.2.1. 使用NFS2.2.2. 使用ISCSI2.3. 持久化存储2.3.1. PV和PVC2.3.2. 访问模式2.3.3. 回收策略1. Docker卷管理...
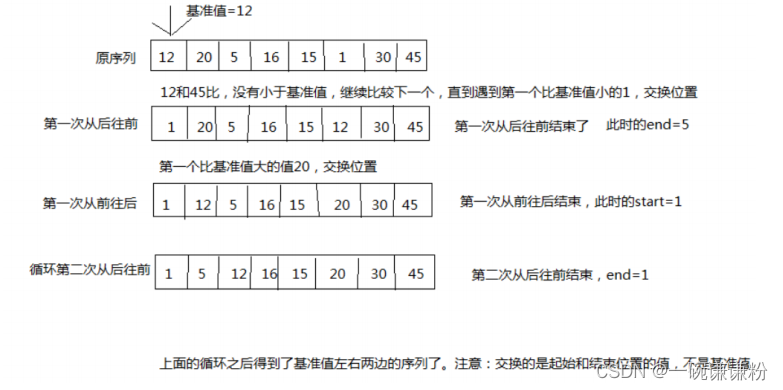
Java实现快速排序算法
快速排序算法 (1)概念:快速排序是指通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序。整个排序过程可以递归进行&…...
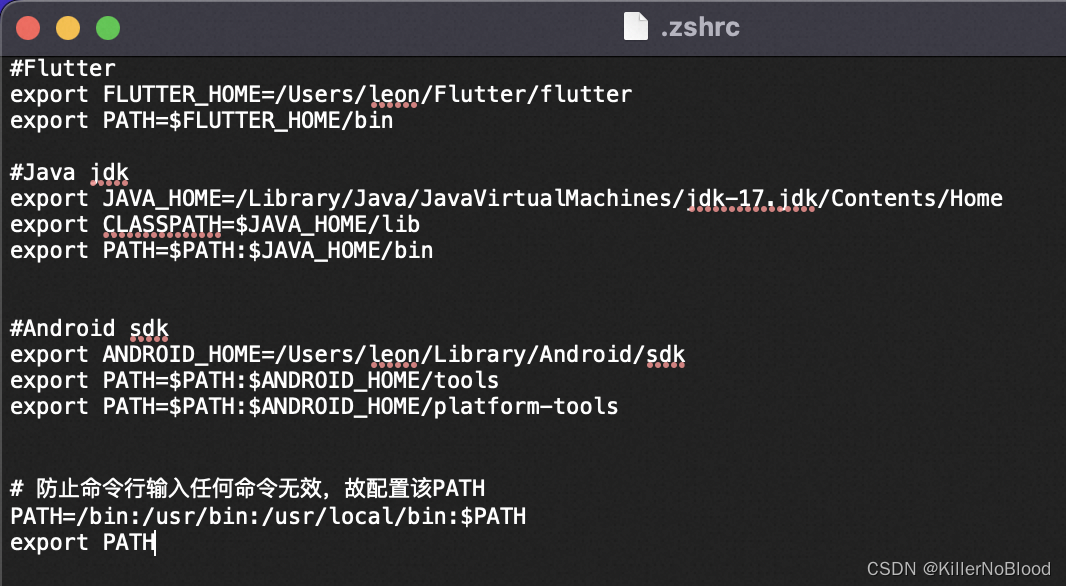
MAC配置环境变量
1、配置 JAVA JDK 1.1、查看 JDK 安装目录 (1)可以在Android Studio中查看,复制该路径 (2)也可以在官网下载 Java JDK下载地址 mac中的安装地址是"资源库->Java->JavaVirtualMachines"中 1.2、…...
系列五、DQL
一、DQL 1.1、概述 DQL的英文全称为:Data Query Language,中文意思为:数据查询语言,用大白话讲就是查询数据。对于大多数系统来说,查询操作的频次是要远高于增删改的,当我们去访问企业官网、电商网站&…...
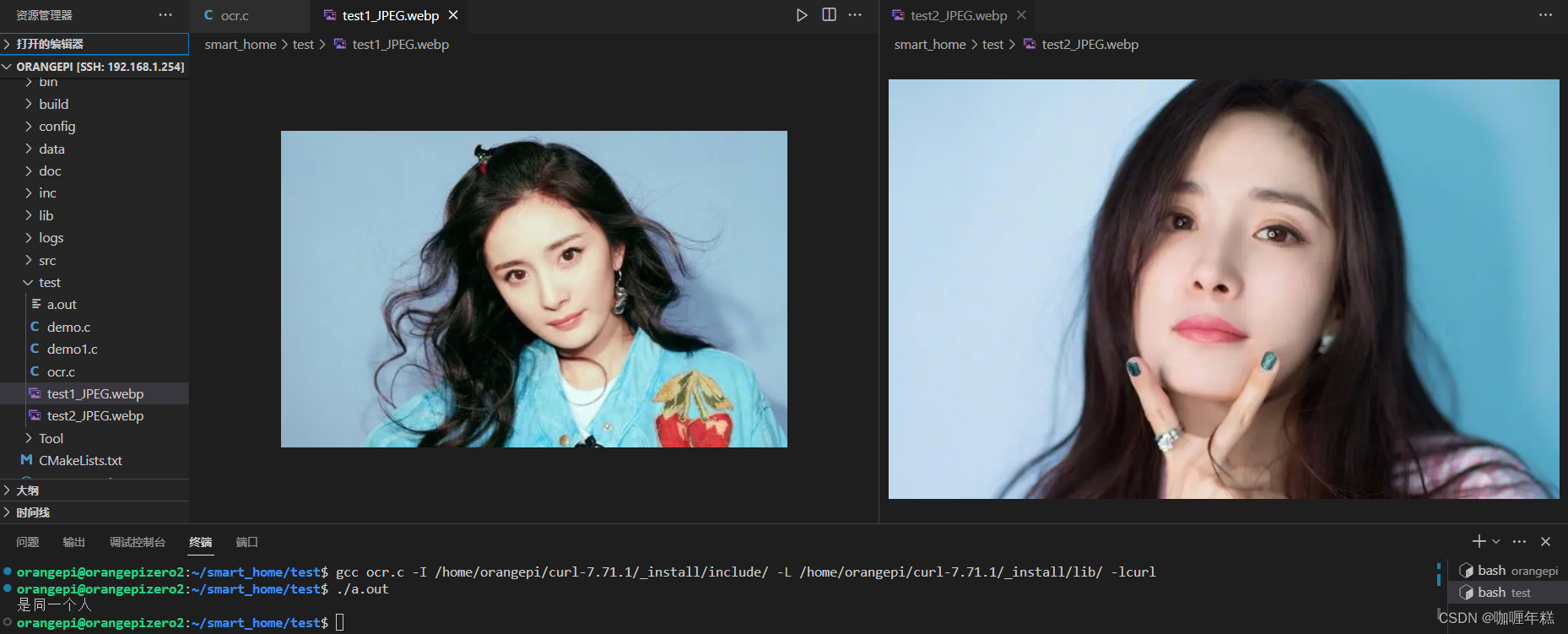
【智能家居】七、人脸识别 翔云平台编程使用(编译openSSL支持libcurl的https访问、安装SSL依赖库openSSL)
一、翔云 人工智能开放平台 API文档开发示例下载 二、编译openSSL支持libcurl的https访问 安装SSL依赖库openSSL(使用工具wget)libcurl库重新配置,编译,安装运行(运行需添加动态库为环境变量) 三、编程实现人脸识别 四、Base6…...
基于node 安装express后端脚手架
1.首先创建文件件 2.在文件夹内打开终端 npm init 3.安装express: npm install -g express-generator注意的地方:这个时候安装特别慢,最后导致不成功 解决方法:npm config set registry http://registry.npm.taobao.org/ 4.依次执行 npm install -g ex…...
Mrdoc知识文档
MrDoc知识文档平台是一款基于Python开发的在线文档系统,适合作为个人和中小型团队的私有云文档、云笔记和知识管理工具,致力于成为优秀的私有化在线文档部署方案。我现在主要把markdown笔记放在上面,因为平时老是需要查询一些知识点ÿ…...

C语言中getchar函数
在 C 语言中,getchar() 是一个标准库函数,用于从标准输入(通常是键盘)读取单个字符。它的函数原型如下: int getchar(void);getchar() 函数的工作原理如下: 当调用 getchar() 函数时,它会等待…...

全栈开发组合
SpringBoot是什么? SpringBoot是一个基于Spring框架的开源框架,由Pivotal团队开发。它的设计目的是用来简化Spring应用的初始搭建以及开发过程。SpringBoot提供了丰富的Spring模块化支持,可以帮助开发者更轻松快捷地构建出企业级应用 Sprin…...

从AwesomeCursorPrompt看提示工程:构建高效AI编程协作工作流
1. 项目概述:从“AwesomeCursorPrompt”看提示工程的演进最近在GitHub上看到一个挺有意思的项目,叫“AwesomeCursorPrompt”。光看名字,可能很多朋友会有点懵——“Cursor”是那个AI代码编辑器,“Prompt”是提示词,那这…...
CircuitPython实战:用传感器数据驱动NeoPixel灯光效果
1. 项目概述如果你刚拿到一块像Adafruit Circuit Playground Express这样的开发板,看着上面一圈彩色的NeoPixel LED和一堆传感器,可能会有点无从下手。别担心,这几乎是每个嵌入式开发者的必经之路。这块板子集成了光传感器、温度传感器、加速…...

3DMax对齐功能全解析:从基础操作到高阶建模实战
1. 3DMax对齐功能基础入门 刚接触3D建模的新手最常遇到的困扰就是:为什么我的模型总是对不齐?记得我第一次用3DMax做建筑模型时,花了两小时都没能把一扇窗户准确地装到墙面上。直到后来掌握了对齐工具,才发现原来这种问题5秒钟就能…...

不只是安装:在龙芯2k1000LA上为Loongnix配置WiFi、蓝牙与触摸屏驱动的完整流程
龙芯2k1000LA开发板外设驱动深度配置指南:从WiFi到触摸屏的全栈解决方案 在国产化硬件开发领域,龙芯2k1000LA开发板凭借其完全自主的LoongArch架构,正成为物联网和嵌入式设备开发者的重要选择平台。不同于x86架构的"开箱即用"体验&…...

去人类中心化研究引擎:AI如何突破学科壁垒驱动科研创新
1. 项目概述:一个“去人类中心化”的研究引擎最近在GitHub上看到一个挺有意思的项目,叫“De-Anthropocentric-Research-Engine”,直译过来就是“去人类中心化研究引擎”。第一眼看到这个标题,你可能和我一样,脑子里会冒…...

Linux进程诊断利器whatdiditdo:实时快照工具原理与实战
1. 项目概述:一个“透明”的进程监控器最近在折腾一个自动化脚本,它时不时会卡住,但日志里又看不出个所以然。排查这种问题,最直接的想法就是看看这个进程到底在“干什么”——它在读写哪些文件?调用了哪些系统调用&am…...

LLM应用开发框架llmflows:轻量级工作流编排实战指南
1. 项目概述:一个为LLM应用构建量身定制的轻量级框架最近在折腾大语言模型应用开发的朋友,估计都经历过类似的“甜蜜的烦恼”:想法很美好,但真要把想法变成可运行、可维护的代码,中间隔着无数个坑。从Prompt的反复调试…...

Allegro铺铜避坑指南:从十字花焊盘到孤铜删除,新手必知的10个实用技巧
Allegro铺铜避坑指南:从十字花焊盘到孤铜删除,新手必知的10个实用技巧 第一次在Allegro中铺铜时,那种手足无措的感觉我至今记忆犹新。面对密密麻麻的参数选项和看似简单的操作背后隐藏的各种"坑",即使是完成了布局布线的…...

长期使用Taotoken聚合API对项目运维复杂度的简化感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合API对项目运维复杂度的简化感受 作为项目维护者,我们团队在过去一段时间里,将多个大模…...

利用Taotoken多模型能力为AIGC应用构建智能降级链路
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken多模型能力为AIGC应用构建智能降级链路 在构建面向真实用户的AIGC应用时,服务的稳定性直接影响用户体验。…...