【项目实战】32G的电脑启动IDEA一个后端服务要2min,谁忍的了?
一、背景
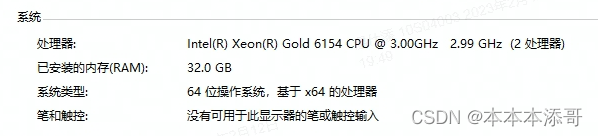
本人电脑性能一般,但是拥有着一台高性能的VDI(虚拟桌面基础架构),以下是具体的配置
二、问题描述
但是,即便是拥有这么高的性能,每次运行基于Dubbo微服务架构下的微服务都贼久,以下是启动一次所消耗的时长

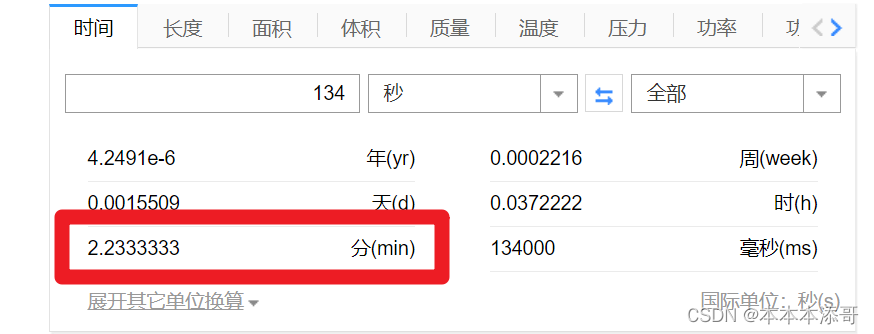
使用百度的时间转换的计算耗时,好家伙,启动一次竟然要耗时2.2min分钟
跟同事讨论了这个项目的启动时长,同事A说是我的IDEA的问题,同事B说是我电脑的问题。
本着一探究竟的精神,耗时了一个下午,我倒要看看究竟是那个应用在拖后腿!
三、问题跟踪与解决
3.1 重启IDEA和VDI
重新启动了IDEA。关闭了所有的IDEA中的进程,以确保不是IDEA在拖后腿。
重新启动了VDI,VDI如果在定期杀毒的话,也会拖后进程的。
3.2 关闭devtools模式
热部署一般是开发过程中使用:开发者不想因为修改内容后重启server浪费大量的时间,而是希望修改代码后能够快速加载自己修改的方法或者类。节省开发时间,为开发者提供改好的开发体验。使用热部署之后,它会监督spring项目修改点,把修改点的java文件编译成class文件,然后替换掉修改前的class文件,不用再去重新部署。
之前有尝试过,但是各种限制总是不顺利,尤其现在有了JRebel,这个基本上用不了,于是考虑不再使用。
找到POM文件,直接注释掉devtools的使用。
关闭devtools模式后的效果并不明显。
3.3 关闭项目启动时,初始化字典到缓存的打印
查看打印日志,发现总是会输出以下的脚本,什么鬼?启动一次就打印一次,这不是浪费时间吗?去掉!
JDBC Connection [org.apache.shardingsphere.driver.jdbc.core.connection.ShardingSphereConnection@537236d3] will not be managed by Spring
==> Preparing: select dict_id, dict_name, dict_type, status, create_by, create_time, remark from sys_dict_type
==> Parameters:
<== Columns: dict_id, dict_name, dict_type, status, create_by, create_time, remark
<== Row: 1, 系统开关, sys_normal_disable, 0, admin, 2018-03-16 11:33:00, 系统开关列表
<== Row: 123, 数据状态, ipds_data_status, 0, admin, 2020-08-11 16:38:25, null
<== Row: 125, 漏洞类型, idps_loophole_type, 0, admin, 2020-08-12 16:30:22, null
<== Row: 127, 严重等级, idps_loophole_grade, 0, admin, 2020-08-12 16:34:24, 漏洞严重等级
<== Total: 4
Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@636226a9]
Creating a new SqlSession
SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@1a9a2c28] was not registered for synchronization because synchronization is not active
JDBC Connection [org.apache.shardingsphere.driver.jdbc.core.connection.ShardingSphereConnection@1287e60e] will not be managed by Spring
==> Preparing: select dict_code, dict_sort, dict_label, dict_value, dict_type, css_class, list_class, is_default, status, create_by, create_time, remark from sys_dict_data where status = '0' and dict_type = ? order by dict_sort asc
==> Parameters: sys_normal_disable(String)
<== Columns: dict_code, dict_sort, dict_label, dict_value, dict_type, css_class, list_class, is_default, status, create_by, create_time, remark
<== Row: 6, 1, 正常, 0, sys_normal_disable, , primary, Y, 0, admin, 2018-03-16 11:33:00, 正常状态
<== Row: 7, 2, 停用, 1, sys_normal_disable, , danger, N, 0, admin, 2018-03-16 11:33:00, 停用状态
<== Total: 2
因为模块涉及到dict,所以很快定位到是数据字典模块的功能。
/**
* 项目启动时,初始化字典到缓存
*/
@PostConstruct
public void init() {List<SysDictType> dictTypeList = dictTypeMapper.selectDictTypeAll();for (SysDictType dictType : dictTypeList) {List<SysDictData> dictDataList = dictDataMapper.selectDictDataByType(dictType.getDictType());DictUtils.setDictCache(dictType.getDictType(), dictDataList);}
}
这一段代码中,使用了@PostConstruct,这个注解的介绍如下
从Java EE5规范开始,Servlet中增加了两个影响Servlet生命周期的注解,@PostConstruct和@PreDestroy,这两个注解被用来修饰一个非静态的void()方法。@PostConstruct是Java自带的注解,在方法上加该注解会在项目启动时执行该方法,也可以理解为在spring容器初始化的时候执行该方法。
注意:在方法上加@PostConstruct注解会在项目启动时执行该方法
因此解决方案也很简单,直接注释掉这个注解即可。
3.4 给XXL-job增加一个开关
看以下截图,发现每次都会进行XXL-job的init的动作。
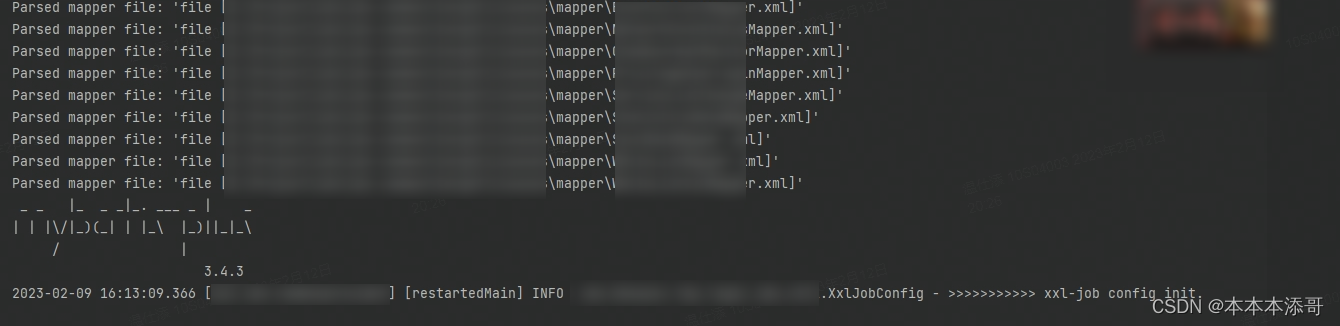
溯源这个的打印处,发现了如下代码
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {log.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;
}
难怪了,本机每次启动都会把自己注册到XXL-job的服务端。
因此,是否可以设计一个开关,让本机的服务不注册到XXL-job的服务端呢。于是有了以下的代码改善。
3.4.1 新增一个enabled字段,用于动态控制注册动作。
@Configuration
@Slf4j
public class XxlJobConfig {@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.address}")private String address;@Value("${xxl.job.executor.ip}")private String ip;@Value("${xxl.job.executor.port}")private int port;@Value("${xxl.job.executor.logpath}")private String logPath;@Value("${xxl.job.executor.logretentiondays}")private int logRetentionDays;/*** 开关,默认关闭*/@Value("${xxl.job.enabled}")private Boolean enabled;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {if (enabled) {log.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}return null;}
}
3.4.2 配置文件中新增开关的配置
xxl.job.enabled=true
3.5 关闭断点(最重要的点)
大家都知道在项目Debug过程中,使用Debug模式运行项目会太慢,往往会比正常直接运行要慢上将近三倍的时间
但是其中的原因却很少人说的清楚,其实是因为使用Debug模式运行时,我们会在某些方法上打了断点(像我,就往往会忘记关闭这些断点),而这种情况会出现Method breakpoints may dramatically slow down debugging的提示,这类提示有时会提示你,有时不会提示你。
解决方案:
3.5.1 返选取消所有断点
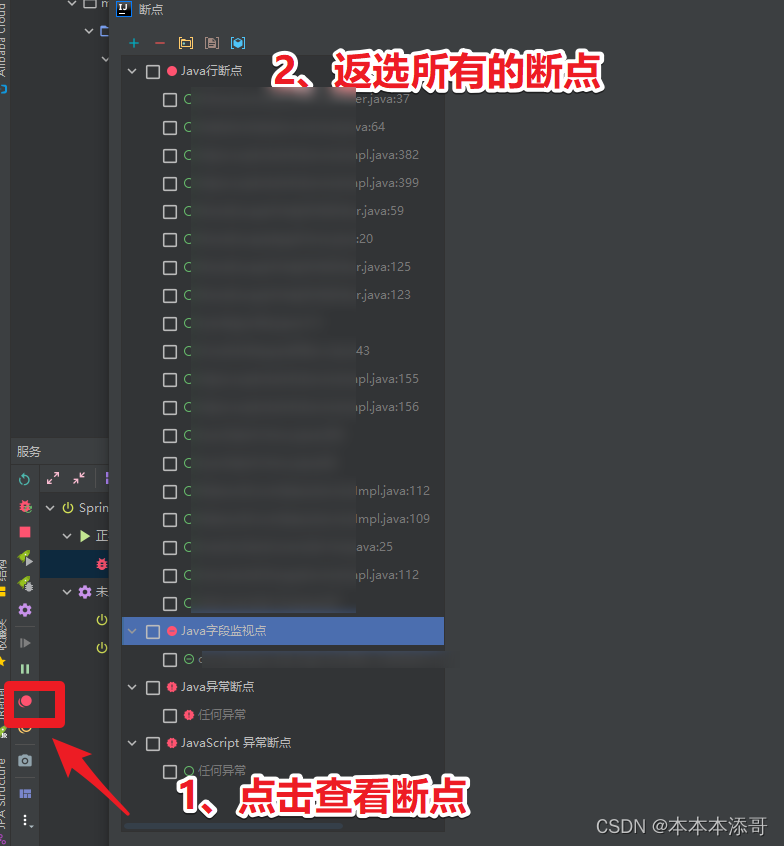
将Java Method Breakpoints下的选项的勾都去掉。
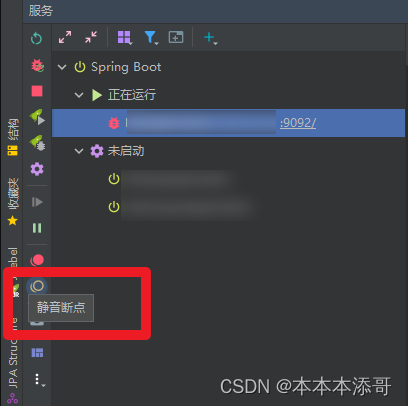
3.5.2 直接点击静音断点
四、问题验证
Started Application in 19.06 seconds
解决后,重新使用debug模式启动,发现启动时间直接降低下拉啦,撒花。
相关文章:
【项目实战】32G的电脑启动IDEA一个后端服务要2min,谁忍的了?
一、背景 本人电脑性能一般,但是拥有着一台高性能的VDI(虚拟桌面基础架构),以下是具体的配置 二、问题描述 但是,即便是拥有这么高的性能,每次运行基于Dubbo微服务架构下的微服务都贼久,以下…...
)
接口自动化面试题汇总(持续更新)
在自动化测试过程中,你如何处理测试数据?你会使用哪些方法来生成测试数据? 在自动化测试过程中,测试数据对于测试的准确性和覆盖率至关重要,常见方法有: 1、使用真实的生产数据:使用真实的生产…...
SpringBoot实现静态资源映射,登录功能以及访问拦截验证——以黑马瑞吉外卖为例
目录 一、项目简介 二、设置静态资源访问路径 三、实现登录功能 四、拦截访问请求 本篇文章以黑马瑞吉外卖为例 一、项目简介 瑞吉外卖项目分为后台和前台系统,后台提供给管理人员使用,前台则是用户订餐使用 资源我们放在resources下 二、设置静态…...

PythonWeb Django PostgreSQL创建Web项目(三)
了解Django框架下如何配置数据库链接与创建模型和应用 使用Django创建web项目,首先需要了解生成的项目文件结构,以及对应文件功能用途方可开始web项目页面创建,下方先介绍文件功能,之后再配置数据库连接以及管理创建模型与应用&a…...

【Visual Studio】git提交代码时使用GPG
前言 下载安装GPG的过程省略,直接开始进行配置 0.visual studio 版本说明 其余版本未测试,但是应该也是可以的 1 获取GPG的密钥ID 1.1 window下可以打开Kleopatra查看生成好的密钥的密钥ID 1.2 也可以从命令行中获取 gpg --list-keys 红框位置,后16位就是密钥ID 2 配置.git…...
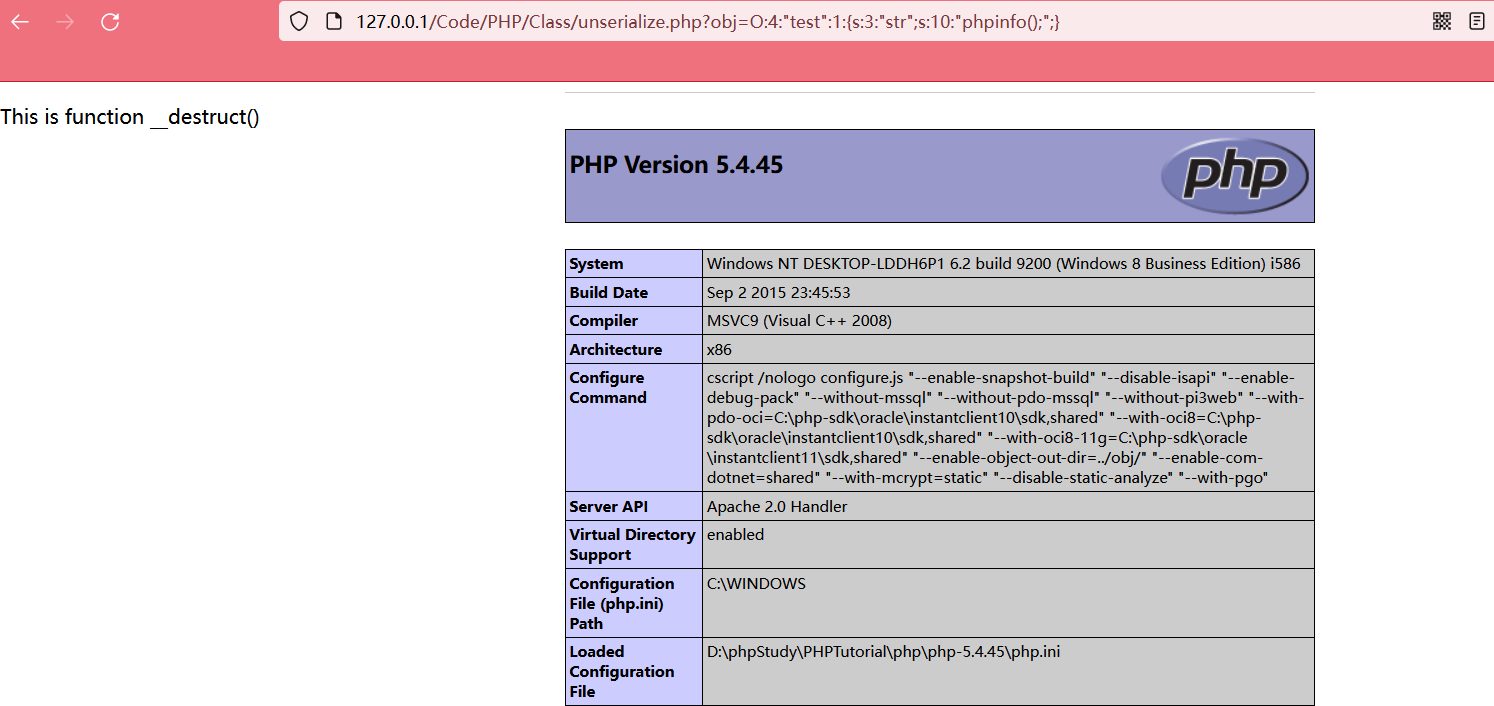
【反序列化漏洞-02】PHP反序列化漏洞实验详解
为什么要序列化百度百科上关于序列化的定义是,将对象的状态信息转换为可以存储或传输的形式(字符串)的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区(非关系型键值对形式的数据库Redis,与数组类似)。以后,可以通过…...

Gateway网关的使用
Gateway服务网关Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等响应式编程和事件流技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。1…...
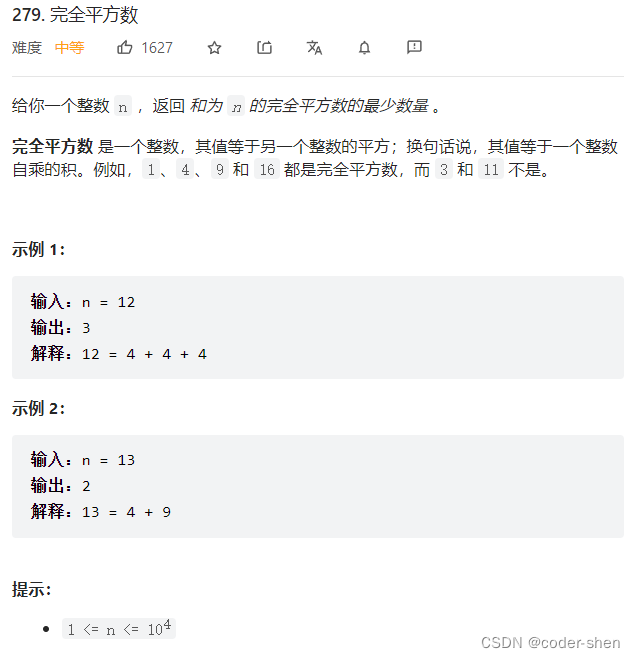
【LeetCode】背包问题总结
文章目录一、背包能否装满?416. 分割等和子集1049. 最后一块石头的重量 II二、装满背包有几种方法?494. 目标和518.零钱兑换II377. 组合总和 Ⅳ70. 爬楼梯三、背包装满的最大价值474.一和零四、装满背包最小物品数322. 零钱兑换279.完全平方数一、背包能…...

Java的开发工具有哪些?这十款工具大厂都在用!
工欲善其事必先利其器,各位同学大家好,我是小源~本期文章,给大家推荐十款Java的开发工具。一、 文本编辑器主要推荐三款:notepad、editplus、sublime text。这三款编辑工具,在我们的开发工作中几乎是相差无几ÿ…...

web学习-Node.js入门学习
web学习-Node.js入门学习1.回顾与思考2. 初识Node.js2.1 Node.js的简介2.2Node.js的环境安装2.3. fs文件系统模块2.3.1 fs.readFile()2.3.2 fs.writeFile()2.3.3 练习-整理考试成绩2.3.4 fs模块-路径动态拼接的问题2.4 path路径模块2.5 http模块2.5.1 服务器相关的概念2.5.2 创…...

100 eeeee
全部 答对 答错 敏捷综合训练3 1.看板中的精益生产概念是如何减少工作在瓶颈时期的影响? A它不会减少瓶颈,因为瓶颈是任何生产系统不可避免的副产品 B通过运用 5Y 分析根本原因 C通过成为一个及时的进度系统 D通过每周完善活动 答错了 收藏 学员得…...

物盾安全汤晓冬:工业互联网企业如何应对高发的供应链安全风险?
编者按:物盾安全是一家专注于物联网安全的产品厂商,其核心产品“物安盾”在能源、制造、交通等多个领域落地,为这些行业企业提供覆盖物联网云、管、边、端的安全整体解决方案。“物安盾”集成了腾讯安全制品扫描(BSCA)…...

微纳制造技术——基础知识
1.什么是直接带隙半导体和间接带隙半导体 导带底和价带顶处以同一K值,称为直接带隙半导体 导带底和价带顶不处在同一K值,称为间接带隙半导体 2.扩散和漂移的公式 3.三五族半导体的性质 1.high mobility 2.wide bandgap 3.direct bandgap 4.三五族…...

Makefile的使用
Makefile的使用 自动化编译脚本,这个东西就是,进行简单的设置,然后实现原码编成为相应程序,简单化自己进行相关操作的过程。不需要一个个自己进行全部进行输入。而且还有许多的简化书写方法。 这个Makefile的本质为一种脚本语言…...
RealBasicVSR模型转成ONNX以及用c++推理
文章目录安装RealBasicVSR的环境1. 新建一个conda环境2. 安装pytorch(官网上选择合适的版本)版本太低会有问题3. 安装 mim 和 mmcv-full4. 安装 mmedit下载RealBasicVSR源码下载模型文件写一个模型转换的脚步测试生成的模型安装RealBasicVSR的环境 1. 新建一个conda环境 cond…...
学习)
C语言作用域(变量生存的空间)学习
C 作用域规则 任何一种编程中,作用域是程序中定义的变量所存在的区域,超过该区域变量就不能被访问。C 语言中有三个地方可以声明变量: 在函数或块内部的局部变量 在所有函数外部的全局变量 在形式参数的函数参数定义中 让我们来看看什么是局…...
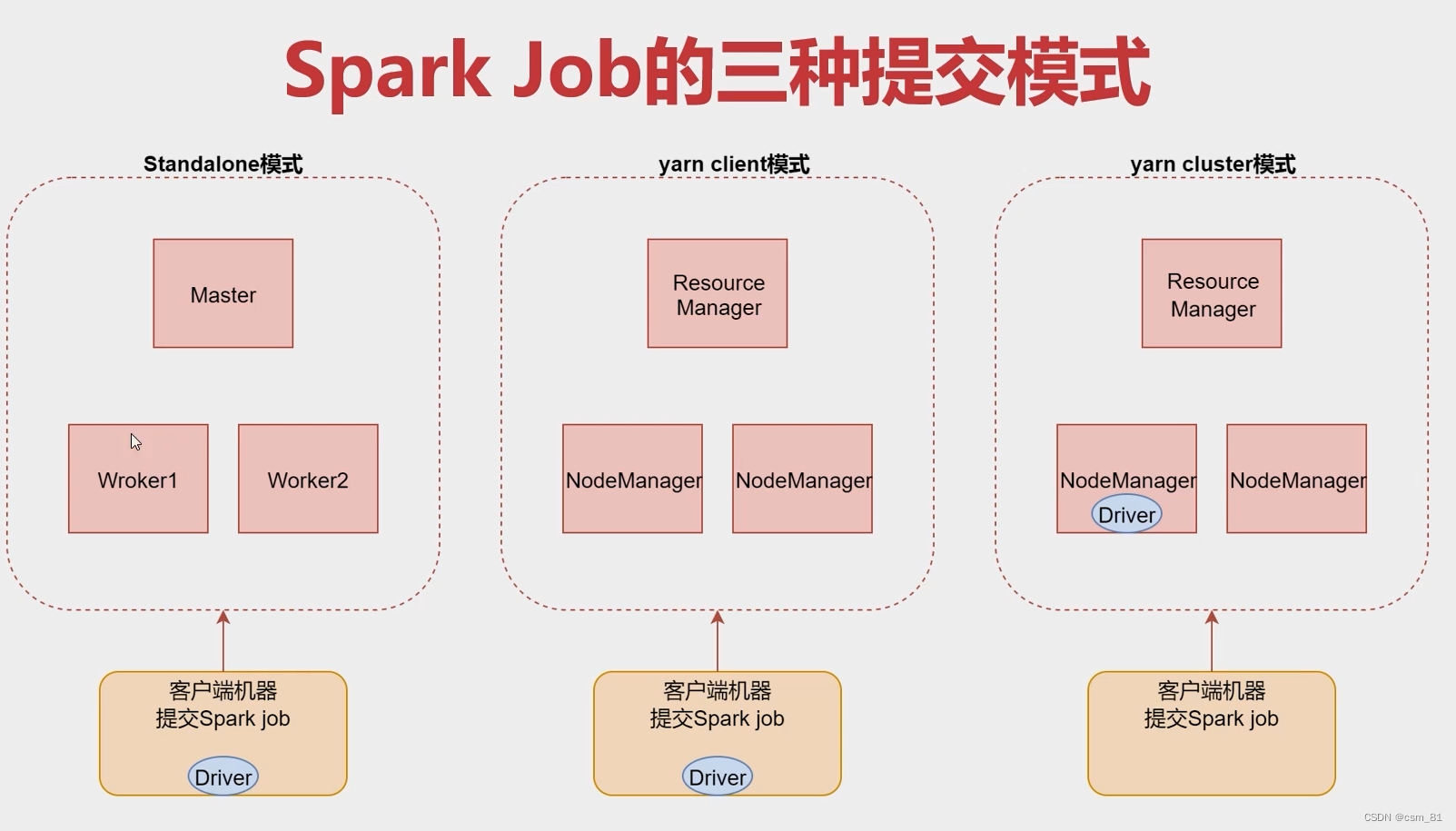
Spark性能优化一 概念篇
(一)宽依赖和窄依赖 窄依赖(Narrow Dependency):指父RDD的每个分区只被子RDD的一个分区所使用,例如map、filter等 这些算子一个RDD,对它的父RDD只有简单的一对一的关系,也就是说,RDD的每个part…...
[数据结构]:09-二分查找(顺序表指针实现形式)(C语言实现)
目录 前言 已完成内容 二分查找实现 01-开发环境 02-文件布局 03-代码 01-主函数 02-头文件 03-PSeqListFunction.cpp 04-SearchFunction.cpp 结语 前言 此专栏包含408考研数据结构全部内容,除其中使用到C引用外,全为C语言代码。使用C引用主要…...
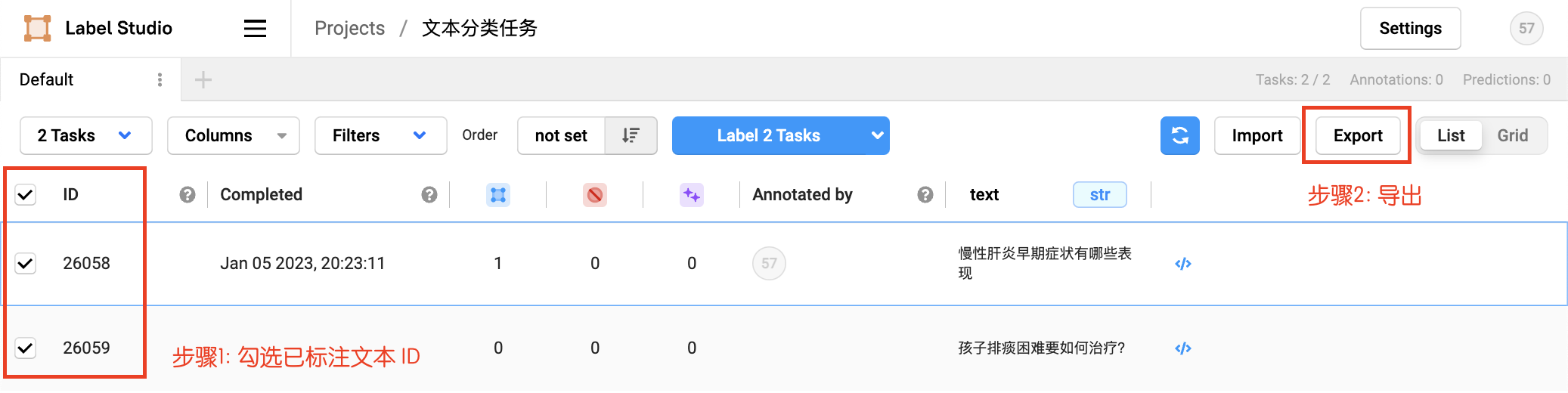
3.基于Label studio的训练数据标注指南:文本分类任务
文本分类任务Label Studio使用指南 1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等 2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等…...
)
Python进阶-----面向对象3.0(面对对象三大特征之---封装)
目录 前言: 什么是封装 Python私有化封装 习题 前言: 上一期是讲解Python中类的私有属性和方法,其实很好理解,我给一个类中的部分属性进行加密拒绝访问(上一期链接Python进阶-----面向对象2.0&#…...

ThunderAI:开箱即用的桌面AI助手,聚合Ollama与多模型应用实战
1. 项目概述:一个开箱即用的AI助手桌面应用最近在折腾本地AI应用的时候,发现了一个挺有意思的项目,叫ThunderAI。这名字听着就挺带劲,像一道闪电,主打的就是一个“快”和“直接”。简单来说,它就是一个基于…...

认知神经科学研究报告【20260055】
文章目录VAR 平稳向量自回归任务:L3 自适应涌现与 L4 经验迁移实验报告一、实验目标二、实验设计三、核心成果3.1 自主模型发现3.2 L4 跨任务经验迁移3.3 自主因果推断四、涌现层级评估六、结论VAR 平稳向量自回归任务:L3 自适应涌现与 L4 经验迁移实验报…...

实测Taotoken平台API调用稳定性与延迟体感观察记录
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测Taotoken平台API调用稳定性与延迟体感观察记录 在将大模型能力集成到生产应用时,服务的稳定性和响应延迟是开发者关…...

LabVIEW数字IO编程避坑指南:单点采样、连续采样到底怎么选?NI-MAX测试面板帮你验证
LabVIEW数字IO编程实战:采样模式选择与NI-MAX验证全攻略 在工业自动化测试领域,LabVIEW的数字IO模块是最基础也最常用的功能之一。许多工程师在初次接触数字IO编程时,往往会被各种采样模式搞得晕头转向——单点采样、N采样、连续采样…...

超越官方Demo:如何用COCO预训练权重快速微调Mask R-CNN处理你的自定义数据
超越官方Demo:如何用COCO预训练权重快速微调Mask R-CNN处理你的自定义数据 当你在工业质检、医疗影像分析或遥感图像处理中遇到需要精确目标分割的场景时,从头训练一个Mask R-CNN模型无疑是奢侈的。COCO数据集预训练权重就像一位经验丰富的"视觉专家…...

GKD第三方订阅管理解决方案:如何实现订阅标准化管理与90%可用性提升
GKD第三方订阅管理解决方案:如何实现订阅标准化管理与90%可用性提升 【免费下载链接】GKD_THS_List GKD第三方订阅收录名单 项目地址: https://gitcode.com/gh_mirrors/gk/GKD_THS_List 面对Android自动化工具GKD日益增长的第三方订阅管理需求,开…...

跨境社媒账号做不稳 很多时候不是内容不够好而是气质不够稳定
很多团队做跨境社媒时,最容易把注意力集中在“内容创意”上。 选题够不够新,切口够不够巧,视频开头能不能抓住人,标题会不会让人点开,这些当然都重要。但真正做久了之后会发现,一个账号能不能长期跑起来&am…...

如何快速解密QMC音频文件:qmc-decoder完整使用指南
如何快速解密QMC音频文件:qmc-decoder完整使用指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否遇到过从音乐平台下载的歌曲无法在其他播放器播放的情…...

个人健康助手为什么常常三天热度,留存问题到底出在哪
个人健康助手为什么常常三天热度,留存问题到底出在哪 个人健康助手类 App 很容易在冷启动阶段获得好奇心点击,但 3 天后打开率快速下降。本文不讨论诊断、治疗、分诊或用药建议,只从技术架构和工程流程角度分析:为什么回答质量不…...

别再只会scp了!Ansible copy和file模块的5个实战场景,从配置文件分发到权限管理
别再只会scp了!Ansible copy和file模块的5个实战场景,从配置文件分发到权限管理 如果你还在用scp或rsync手动同步服务器文件,每次修改权限都要逐台登录操作,那么这篇文章将彻底改变你的运维工作流。Ansible的copy和file模块不仅能…...