货物数据处理pandas版
1求和
from openpyxl import load_workbook
import pandas as pddef print_hi(name):# Use a breakpoint in the code line below to debug your script.print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.# Press the green button in the gutter to run the script.
if __name__ == '__main__':filePath1 = './src/原始数据精修.xlsx'df1 = pd.read_excel(filePath1, sheet_name='销售明细')index_list = ['部门名称', '年度名称', '季节名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']# 求和方法二,需将文本的列指定为索引df1 = df1.set_index(index_list)df1['合计'] = df1.apply(lambda x: x.sum(), axis=1)filePath2 = './src/处理结果精修.xlsx'#重置索引,防止单元格合并df1 = df1.reset_index()df1.to_excel(filePath2, sheet_name="new_sheet", index=False, na_rep=0, inf_rep=0)print(df1)
2.去除季节年度进行聚类
#去除年度和季节进行聚类df2 = pd.read_excel(filePath2, sheet_name='单款排名')df2.pop('年度名称')df2.pop('季节名称')index_list = ['部门名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']value_list = ['0M','1L','1XL','27','28','29','2XL','30','3XL','4XL','5XL','6XL','S','均','合计']#使用透视表聚合df2 = df2.pivot_table(index= index_list,values=value_list,aggfunc='sum')# 重置索引,防止单元格合并df2 = df2.reset_index()#将合计列放到最后面#dataframe中某一列放到最后,并改名为销售明细df2['销售明细'] = df2.pop('合计')df2.to_excel(filePath2, sheet_name="单款排名", index=False, na_rep=0, inf_rep=0)
3完整数据处理过程代码
from openpyxl import load_workbook
import pandas as pddef print_hi(name):# Use a breakpoint in the code line below to debug your script.print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.# Press the green button in the gutter to run the script.
if __name__ == '__main__':filePath1 = './src/原始数据精修.xlsx'# 加载工作簿wb = load_workbook(filePath1)# 获取sheet页,修改第一个sheet页面为name1 = wb.sheetnames[0]ws1 = wb[name1]ws1.title = "销售明细"wb.save(filePath1)#销售明细df1 = pd.read_excel(filePath1, sheet_name='销售明细')index_list = ['部门名称', '年度名称', '季节名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']# 求和方法二,需将文本的列指定为索引df1 = df1.set_index(index_list)df1['合计'] = df1.apply(lambda x: x.sum(), axis=1)filePath2 = './src/处理结果精修.xlsx'#重置索引,防止单元格合并df1 = df1.reset_index()df1.to_excel(filePath2, sheet_name="new_sheet", index=False, na_rep=0, inf_rep=0)#单款排名#去除年度和季节进行聚类df2 = df1.copy()df2.pop('年度名称')df2.pop('季节名称')index_list = ['部门名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']value_list = ['0M','1L','1XL','27','28','29','2XL','30','3XL','4XL','5XL','6XL','S','均','合计']#使用透视表聚合df2 = df2.pivot_table(index= index_list,values=value_list,aggfunc='sum')# 重置索引,防止单元格合并df2 = df2.reset_index()#将合计列放到最后面#dataframe中某一列放到最后,并改名为销售明细df2['销售明细'] = df2.pop('合计')df2.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)#品牌排名df3 = df1.copy()# 使用透视表聚合df3 = df3.pivot_table(index='品牌名称', values='合计', aggfunc='sum')# 重置索引,防止单元格合并df3 = df3.reset_index()# 将合计列放到最后面# dataframe中某一列放到最后,并改名为销售明细df3['销售明细'] = df3.pop('合计')df3.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)#年度销售df4 = df1.copy()# 使用透视表聚合print(df4)df4 = df4.pivot_table(index=['年度名称', '季节名称'], values='合计', aggfunc='sum')# 重置索引,防止单元格合并df4 = df4.reset_index()# 将合计列放到最后面# dataframe中某一列放到最后,并改名为销售明细df4['销售明细'] = df4.pop('合计')df4.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)#季节销售df5 = df1.copy()#使用透视表聚合df5 = df5.pivot_table(index=['季节名称'], values='合计', aggfunc='sum')# 重置索引,防止单元格合并df5 = df5.reset_index()df5['销售明细'] = df5.pop('合计')df5.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)#品类排名df6 = df1.copy()# 使用透视表聚合df6 = df6.pivot_table(index=['品类名称'], values='合计', aggfunc='sum')# 重置索引,防止单元格合并df6 = df6.reset_index()df6['销售明细'] = df6.pop('合计')df6.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)# print(df1)# 加载工作簿filePath2 = './src/处理结果精修.xlsx'wb = load_workbook(filePath2)#客户周销df7 = pd.DataFrame({'商店名称':[], '销售数量':[]})#创建表ws2 = wb.create_sheet("单款排名")ws3 = wb.create_sheet("品牌排名")ws4 = wb.create_sheet("年度销售")ws5 = wb.create_sheet("季节销售")ws6 = wb.create_sheet("品类排名")ws7 = wb.create_sheet("客户周销")wb.save(filePath2)#将生成的工作表导入到程序中result_sheet = pd.ExcelWriter(filePath2, engine='openpyxl') # 先定义要存入的文件名xxx,然后分别存入xxx下不同的sheetdf1.to_excel(result_sheet, "销售明细", index=False, na_rep=0, inf_rep=0)df2.to_excel(result_sheet, "单款排名", index=False, na_rep=0, inf_rep=0)df3.to_excel(result_sheet, "品牌排名", index=False, na_rep=0, inf_rep=0)df4.to_excel(result_sheet, "年度销售", index=False, na_rep=0, inf_rep=0)df5.to_excel(result_sheet, "季节销售", index=False, na_rep=0, inf_rep=0)df6.to_excel(result_sheet, "品类排名", index=False, na_rep=0, inf_rep=0)df7.to_excel(result_sheet, "客户周销", index=False, na_rep=0, inf_rep=0)# 这步不能省,否则不生成文件result_sheet._save()
初始文件格式

最终结果,处理完成

求行和和求列合
#销售明细df1 = pd.read_excel(filePath1, sheet_name='销售明细')index_list = ['部门名称', '年度名称', '季节名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']# 求和方法二,需将文本的列指定为索引df1 = df1.set_index(index_list)#df1.loc["按列求和"] = df1.apply(lambda x: x.sum())df1['合计'] = df1.apply(lambda x: x.sum(), axis=1)#求列合df1 = df1.reset_index()df1 = df1.set_index('部门名称')df1.loc['合计'] = df1.apply(lambda x: x.sum(), axis=0)#重置索引,防止单元格合并df1 = df1.reset_index()df1.to_excel("new_sheet1.xlsx", sheet_name="new_sheet", index=False, na_rep=0, inf_rep=0)
4格式处理
通过openpyxl进行格式处理
#销售明细
# 加载工作簿
wb1 = load_workbook('Mytest.xlsx')
# 获取sheet页
ws2 = wb1['销售明细']
#获取行
for cell in ws1['1']:#代码省略
#获取列
for cell in ws1['A']:#代码省略
字体示例
from openpyxl import Workbook
from openpyxl.styles import Font# 创建一个新的工作簿和工作表
workbook = Workbook()
sheet = workbook.active# 创建一个字体对象并设置属性
font = Font(name='Arial', # 字体名称size=12, # 字体大小bold=True, # 是否加粗italic=True, # 是否斜体underline='single', # 下划线类型:single、double、none等strike=True, # 是否有删除线color='FF0000' # 字体颜色,十六进制RGB值
)# 在单元格A1中应用字体样式
sheet['A1'].font = font
sheet['A1'].value = 'Hello, World!'# 保存工作簿
workbook.save('E:\\UserData\\Desktop\\font_example.xlsx')
背景边框示例
# 销售明细# 加载工作簿wb1 = load_workbook(filePath2)# 获取sheet页ws1 = wb1['销售明细']#设置字体# 创建一个字体对象并设置属性font = Font(name='微软雅黑', # 字体名称size=18, # 字体大小bold=True, # 是否加粗italic=False, # 是否斜体underline='none', # 下划线类型:single、double、none等strike=False, # 是否有删除线color='000000', # 字体颜色,十六进制RGB值vertAlign='baseline')dept_name = ws1['A2'].valuews1.insert_rows(0, 1) #插入一行min_row = ws1.min_rowmax_row = ws1.max_rowmin_col = ws1.min_columnmax_col = ws1.max_column#设置单元格格式# 调整行高ws1.row_dimensions[1].height = 24#合并单元格# 需要合并的左上方和右下方单元格坐标ws1.merge_cells(start_row=1, start_column=1, end_row=1, end_column=max_col)# 在单元格A1中应用字体样式ws1['A1'].font = fontws1['A1'].value = dept_name + '销售明细'#设置字体居中# 设置字体居中#要导入 from openpyxl import stylescell = ws1['A1']cell.alignment = styles.Alignment(horizontal='center', vertical='center')#首行设置底色# 设置第一行单元格的背景颜色为红色#from openpyxl.styles import PatternFillfor cell in ws[1]:cell.fill = PatternFill(start_color="FF0000", end_color="FF0000", fill_type="solid")# 保存工作簿wb1.save(filePath2)将数字转换为excel的列序号
import stringdef number_to_column(n):"""Convert a number to the corresponding column letter in Excel"""column = ""while n > 0:n -= 1column = string.ascii_uppercase[n % 26] + columnn //= 26return column# Example usage
print(number_to_column(1)) # Output: "A"
print(number_to_column(27)) # Output: "AA"
print(number_to_column(28)) # Output: "AB"
print(number_to_column(53)) # Output: "BA"
print(number_to_column(1000)) # Output: "ALL"
设置销售明细的代码
# 销售明细# 加载工作簿wb1 = load_workbook(filePath2)# 获取sheet页ws1 = wb1['销售明细']# 设置字体# 创建一个字体对象并设置属性font1 = Font(name='微软雅黑', # 字体名称size=18, # 字体大小bold=True, # 是否加粗italic=False, # 是否斜体underline='none', # 下划线类型:single、double、none等strike=False, # 是否有删除线color='000000', # 字体颜色,十六进制RGB值vertAlign='baseline')dept_name = ws1['A2'].valuews1.insert_rows(0, 1) # 插入一行min_row = ws1.min_rowmax_row = ws1.max_rowmin_col = ws1.min_columnmax_col = ws1.max_column# 设置单元格格式# 调整行高ws1.row_dimensions[1].height = 24# 合并单元格# 需要合并的左上方和右下方单元格坐标ws1.merge_cells(start_row=1, start_column=1, end_row=1, end_column=max_col)# 在单元格A1中应用字体样式ws1['A1'].font = font1ws1['A1'].value = dept_name + '销售明细'# 设置字体居中cell = ws1['A1']cell.alignment = styles.Alignment(horizontal='center', vertical='center')# 首行设置底色# 设置第一行单元格的背景颜色为黄色for cell in ws1[2]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")#列颜色填充for cell in ws1[number_to_column(max_col)]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")#设置边框cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'))#处理最后一行# 调整行高ws1.row_dimensions[max_row].height = 24# 设置末尾行单元格的背景颜色为黄色for cell in ws1[max_row]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")# 设置边框cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'),top=Side(style='thin'))# 合并单元格# 需要合并的左上方和右下方单元格坐标ws1.merge_cells(start_row=max_row, start_column=1, end_row=max_row, end_column=8)# 在单元格A1中应用字体样式cell = ws1.cell(column=1, row=max_row)cell.alignment = styles.Alignment(horizontal='center', vertical='center')cell.font = font1cell.value = '合计'
单款排名格式
#单款排名# 获取sheet页ws2 = wb1['单款排名']# 设置字体# 创建一个字体对象并设置属性dept_name = ws2['A2'].valuews2.insert_rows(0, 1) # 插入一行min_row = ws2.min_rowmax_row = ws2.max_rowmin_col = ws2.min_columnmax_col = ws2.max_column# 设置单元格格式# 调整行高ws2.row_dimensions[1].height = 24# 合并单元格# 需要合并的左上方和右下方单元格坐标ws2.merge_cells(start_row=1, start_column=1, end_row=1, end_column=max_col)# 在单元格A1中应用字体样式ws2['A1'].font = font1ws2['A1'].value = '单款排名'# 设置字体居中cell = ws2['A1']cell.alignment = styles.Alignment(horizontal='center', vertical='center')# 首行设置底色# 设置第一行单元格的背景颜色为黄色for cell in ws2[2]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")# 列颜色填充for cell in ws2[number_to_column(max_col)]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")# 设置边框cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'),top=Side(style='thin'))# 处理最后一行# 调整行高ws2.row_dimensions[max_row ].height = 24# 设置末尾行单元格的背景颜色为黄色for cell in ws2[max_row ]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")# 设置边框cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'),top=Side(style='thin'))# 合并单元格# 需要合并的左上方和右下方单元格坐标ws2.merge_cells(start_row=max_row, start_column=1, end_row=max_row , end_column=6)# 在单元格A1中应用字体样式cell = ws2.cell(column=1, row=max_row)cell.alignment = styles.Alignment(horizontal='center', vertical='center')cell.font = font1cell.value = '合计'
完整代码
from openpyxl import load_workbook
from openpyxl import styles
from openpyxl.styles import *import pandas as pd
from openpyxl.styles import Font
import stringdef print_hi(name):# Use a breakpoint in the code line below to debug your script.print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.def number_to_column(n):"""Convert a number to the corresponding column letter in Excel"""column = ""while n > 0:n -= 1column = string.ascii_uppercase[n % 26] + columnn //= 26return column# Press the green button in the gutter to run the script.
if __name__ == '__main__':filePath1 = './src/原始数据精修.xlsx'# 加载工作簿wb = load_workbook(filePath1)# 获取sheet页,修改第一个sheet页面为name1 = wb.sheetnames[0]ws1 = wb[name1]ws1.title = "销售明细"wb.save(filePath1)#销售明细df0 = pd.read_excel(filePath1, sheet_name='销售明细')index_list = ['部门名称', '年度名称', '季节名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']# 求和方法二,需将文本的列指定为索引df0 = df0.set_index(index_list)#df1.loc["按列求和"] = df1.apply(lambda x: x.sum())df0['合计'] = df0.apply(lambda x: x.sum(), axis=1)#df1=df1.sum()filePath2 = './src/处理结果精修.xlsx'#重置索引,防止单元格合并df0 = df0.reset_index()df1 = df0.copy()# 列求和df1 = df1.set_index('部门名称')df1.loc['合计'] = df1.apply(lambda x: x.sum(), axis=0)# df1=df1.sum()filePath2 = './src/处理结果精修.xlsx'# 重置索引,防止单元格合并df1 = df1.reset_index()df1.to_excel("new_sheet1.xlsx", sheet_name="new_sheet", index=False, na_rep=0, inf_rep=0)#单款排名#去除年度和季节进行聚类df2 = df0.copy()df2.pop('年度名称')df2.pop('季节名称')index_list = ['部门名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称']value_list = ['0M','1L','1XL','27','28','29','2XL','30','3XL','4XL','5XL','6XL','S','均','合计']#使用透视表聚合df2 = df2.pivot_table(index= index_list,values=value_list,aggfunc='sum')# 重置索引,防止单元格合并df2 = df2.reset_index()#将合计列放到最后面#dataframe中某一列放到最后,并改名为销售明细df2['销售明细'] = df2.pop('合计')df2.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)#列求和df2 = df2.set_index('部门名称')df2.loc['合计'] = df1.apply(lambda x: x.sum(), axis=0)# 重置索引,防止索引列消失df2 = df2.reset_index()#品牌排名df3 = df0.copy()# 使用透视表聚合df3 = df3.pivot_table(index='品牌名称', values='合计', aggfunc='sum')# 重置索引,防止单元格合并df3 = df3.reset_index()# 将合计列放到最后面# dataframe中某一列放到最后,并改名为销售明细df3['销售明细'] = df3.pop('合计')df3.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)df3 = df3.set_index('品牌名称')df3.loc['合计'] = df3.apply(lambda x: x.sum(), axis=0)# 重置索引,防止单元格合并df3 = df3.reset_index()#年度销售df4 = df0.copy()# 使用透视表聚合print(df4)df4 = df4.pivot_table(index=['年度名称', '季节名称'], values='合计', aggfunc='sum')# 重置索引,防止单元格合并df4 = df4.reset_index()# 将合计列放到最后面# dataframe中某一列放到最后,并改名为销售明细df4['销售明细'] = df4.pop('合计')df4.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)df4 = df4.set_index('年度名称')df4.loc['合计'] = df4.apply(lambda x: x.sum(), axis=0)# 重置索引,防止单元格合并df4 = df4.reset_index()#季节销售df5 = df0.copy()#使用透视表聚合df5 = df5.pivot_table(index=['季节名称'], values='合计', aggfunc='sum')# 重置索引,防止单元格合并df5 = df5.reset_index()df5['销售明细'] = df5.pop('合计')df5.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)df5 = df5.set_index('季节名称')df5.loc['合计'] = df5.apply(lambda x: x.sum(), axis=0)# 重置索引,防止单元格合并df5 = df5.reset_index()#品类排名df6 = df0.copy()# 使用透视表聚合df6 = df6.pivot_table(index=['品类名称'], values='合计', aggfunc='sum')# 重置索引,防止单元格合并df6 = df6.reset_index()df6['销售明细'] = df6.pop('合计')df6.sort_values(by="销售明细", axis=0, ascending=False, inplace=True)df6 = df6.set_index('品类名称')df6.loc['合计'] = df6.apply(lambda x: x.sum(), axis=0)# 重置索引,防止单元格合并df6 = df6.reset_index()# print(df1)# 加载工作簿filePath2 = './src/处理结果精修.xlsx'wb = load_workbook(filePath2)#客户周销df7 = pd.DataFrame({'商店名称':[], '销售数量':[]})#创建表ws2 = wb.create_sheet("单款排名")ws3 = wb.create_sheet("品牌排名")ws4 = wb.create_sheet("年度销售")ws5 = wb.create_sheet("季节销售")ws6 = wb.create_sheet("品类排名")ws7 = wb.create_sheet("客户周销")wb.save(filePath2)#将生成的工作表导入到程序中result_sheet = pd.ExcelWriter(filePath2, engine='openpyxl') # 先定义要存入的文件名xxx,然后分别存入xxx下不同的sheetdf1.to_excel(result_sheet, "销售明细", index=False, na_rep=0, inf_rep=0)df2.to_excel(result_sheet, "单款排名", index=False, na_rep=0, inf_rep=0)df3.to_excel(result_sheet, "品牌排名", index=False, na_rep=0, inf_rep=0)df4.to_excel(result_sheet, "年度销售", index=False, na_rep=0, inf_rep=0)df5.to_excel(result_sheet, "季节销售", index=False, na_rep=0, inf_rep=0)df6.to_excel(result_sheet, "品类排名", index=False, na_rep=0, inf_rep=0)df7.to_excel(result_sheet, "客户周销", index=False, na_rep=0, inf_rep=0)# 这步不能省,否则不生成文件result_sheet._save()# 销售明细# 加载工作簿wb1 = load_workbook(filePath2)# 获取sheet页ws1 = wb1['销售明细']# 设置字体# 创建一个字体对象并设置属性font1 = Font(name='微软雅黑', # 字体名称size=18, # 字体大小bold=True, # 是否加粗italic=False, # 是否斜体underline='none', # 下划线类型:single、double、none等strike=False, # 是否有删除线color='000000', # 字体颜色,十六进制RGB值vertAlign='baseline')dept_name = ws1['A2'].valuews1.insert_rows(0, 1) # 插入一行min_row = ws1.min_rowmax_row = ws1.max_rowmin_col = ws1.min_columnmax_col = ws1.max_column# 设置单元格格式# 调整行高ws1.row_dimensions[1].height = 24# 合并单元格# 需要合并的左上方和右下方单元格坐标ws1.merge_cells(start_row=1, start_column=1, end_row=1, end_column=max_col)# 在单元格A1中应用字体样式ws1['A1'].font = font1ws1['A1'].value = dept_name + '销售明细'# 设置字体居中cell = ws1['A1']cell.alignment = styles.Alignment(horizontal='center', vertical='center')# 首行设置底色# 设置第一行单元格的背景颜色为黄色for cell in ws1[2]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")#列颜色填充for cell in ws1[number_to_column(max_col)]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")#设置边框cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'))#处理最后一行# 调整行高ws1.row_dimensions[max_row].height = 24# 设置末尾行单元格的背景颜色为黄色for cell in ws1[max_row]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")# 设置边框cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'),top=Side(style='thin'))# 合并单元格# 需要合并的左上方和右下方单元格坐标ws1.merge_cells(start_row=max_row, start_column=1, end_row=max_row, end_column=8)# 在单元格A1中应用字体样式cell = ws1.cell(column=1, row=max_row)cell.alignment = styles.Alignment(horizontal='center', vertical='center')cell.font = font1cell.value = '合计'#单款排名# 获取sheet页ws2 = wb1['单款排名']# 设置字体# 创建一个字体对象并设置属性dept_name = ws2['A2'].valuews2.insert_rows(0, 1) # 插入一行min_row = ws2.min_rowmax_row = ws2.max_rowmin_col = ws2.min_columnmax_col = ws2.max_column# 设置单元格格式# 调整行高ws2.row_dimensions[1].height = 24# 合并单元格# 需要合并的左上方和右下方单元格坐标ws2.merge_cells(start_row=1, start_column=1, end_row=1, end_column=max_col)# 在单元格A1中应用字体样式ws2['A1'].font = font1ws2['A1'].value = '单款排名'# 设置字体居中cell = ws2['A1']cell.alignment = styles.Alignment(horizontal='center', vertical='center')# 首行设置底色# 设置第一行单元格的背景颜色为黄色for cell in ws2[2]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")# 列颜色填充for cell in ws2[number_to_column(max_col)]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")# 设置边框cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'),top=Side(style='thin'))# 处理最后一行# 调整行高ws2.row_dimensions[max_row ].height = 24# 设置末尾行单元格的背景颜色为黄色for cell in ws2[max_row ]:cell.fill = PatternFill(start_color="FFFF00", end_color="FF0000", fill_type="solid")# 设置边框cell.border = Border(left=Side(style='thin'), bottom=Side(style='thin'), right=Side(style='thin'),top=Side(style='thin'))# 合并单元格# 需要合并的左上方和右下方单元格坐标ws2.merge_cells(start_row=max_row, start_column=1, end_row=max_row , end_column=6)# 在单元格A1中应用字体样式cell = ws2.cell(column=1, row=max_row)cell.alignment = styles.Alignment(horizontal='center', vertical='center')cell.font = font1cell.value = '合计'# 保存工作簿wb1.save(filePath2)相关文章:
货物数据处理pandas版
1求和 from openpyxl import load_workbook import pandas as pddef print_hi(name):# Use a breakpoint in the code line below to debug your script.print(fHi, {name}) # Press CtrlF8 to toggle the breakpoint.# Press the green button in the gutter to run the scr…...
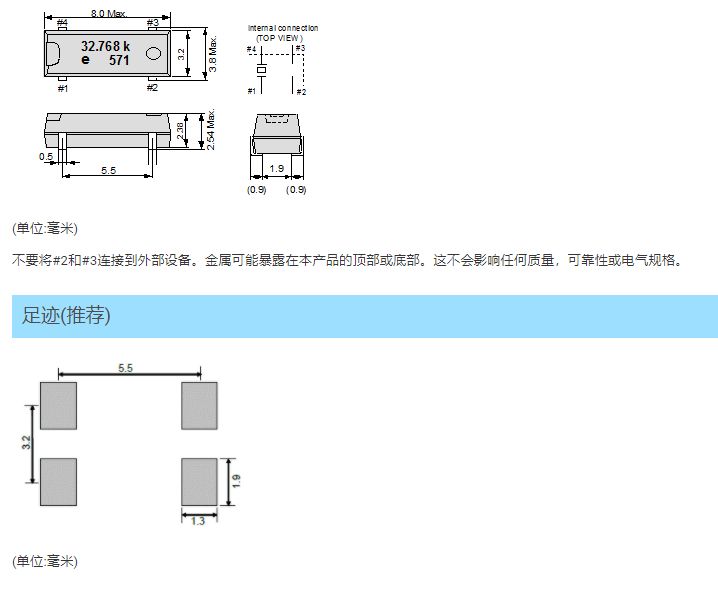
MC-30A (32.768 kHz用于汽车应用的晶体单元)
MC-30A 32.768 kHz用于汽车应用的晶体,车规晶振中的热销型号之一。该款石英晶体谐振器,可以在-40 to 85 C的温度内稳定工作,能满足起动振动的要求。同时满足AEC-Q200无源元件质量标准认证,满足汽车仪表系统的所有要求。 频率范围…...
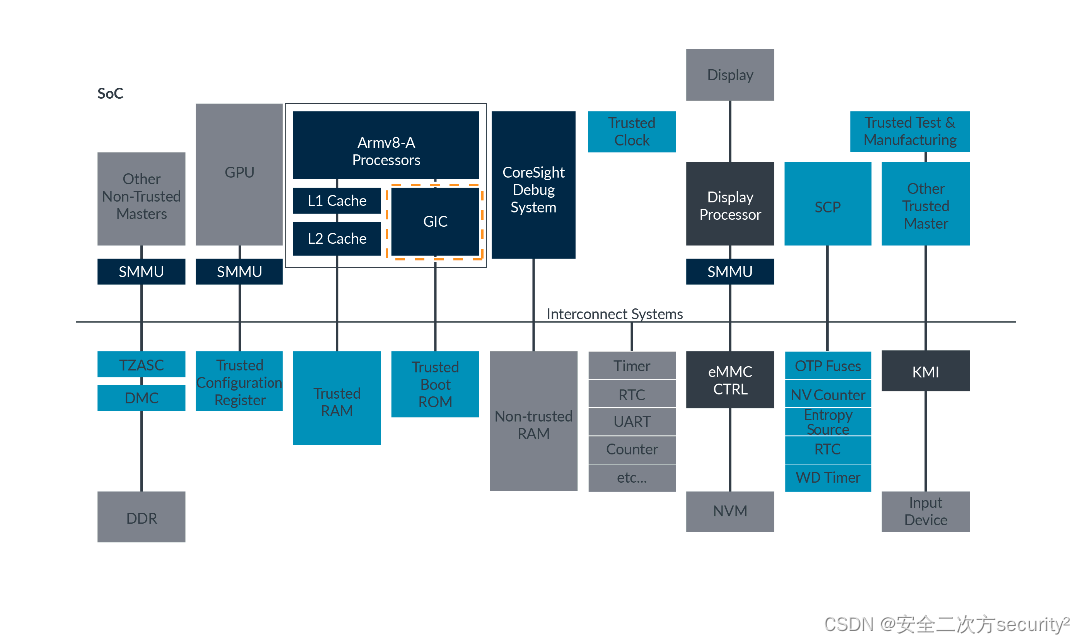
TrustZone之其他设备及可信基础系统架构
一、其他设备 最后,我们将查看系统中的其他设备,如下图所示: 我们的示例TrustZone启用的系统包括一些尚未涵盖的设备,但我们需要这些设备来构建一个实际的系统。 • 一次性可编程存储器(OTP)或保险丝 这些是一旦写入就无法更改的存储器。与每个芯片上都包含相同…...
自由编程学习资源:free-programming-books
最近,我发现了一个在GitHub上备受欢迎的项目,它为程序员和编程爱好者提供了丰富、免费且高质量的学习资料,这就是"free-programming-books"。目前,这个项目在GitHub上已经有305k的star,显示出它在开发者社区…...

饥荒Mod 开发(十三):木牌传送
饥荒Mod 开发(十二):一键制作 饥荒Mod 开发(十四):制作屏幕弹窗 一键传送源码 饥荒的地图很大,跑地图太耗费时间和饥饿值,如果大部分时间都在跑图真的是很无聊,所以需要有一个能够传送的功能,不仅可以快速…...
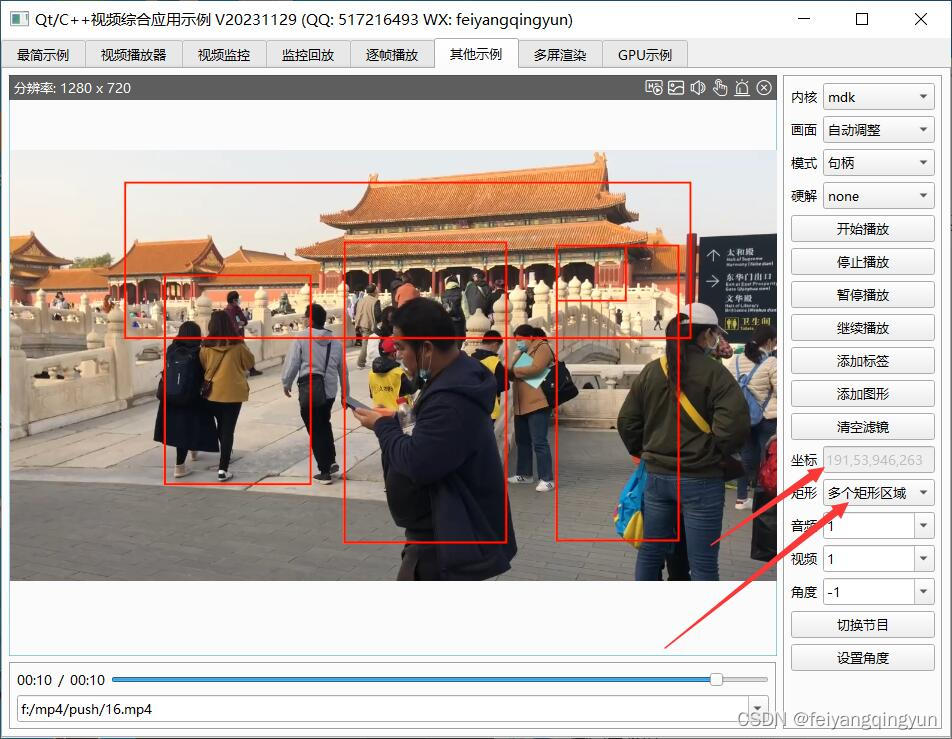
Qt/C++音视频开发60-坐标拾取/按下鼠标获取矩形区域/转换到视频源真实坐标
一、前言 通过在通道画面上拾取鼠标按下的坐标,然后鼠标移动,直到松开,根据松开的坐标和按下的坐标,绘制一个矩形区域,作为热点或者需要电子放大的区域,拿到这个坐标区域,用途非常多࿰…...

Java实现订单超时未支付自动取消的8种方法总结
Java实现订单超时未支付自动取消的8种方法总结 定时轮询 数据库定时轮询方式,实现思路比较简单。启动一个定时任务,每隔一定时间扫描订单表,查询到超时订单就取消。优点:实现简单。缺点:轮询时间间隔不好确定&#x…...

android动态权限申请并展示权限使用说明
# ExplainPermissions 动态权限申请并展示权限使用说明 随着工信部对APP的一系列整治,现在用户对于APP在使用时动态申请的权限是比较敏感的,为了更好的用户体验,我们可以在权限动态申请的时候一并向用户展示所需要申请权限的使用说明。这样用…...
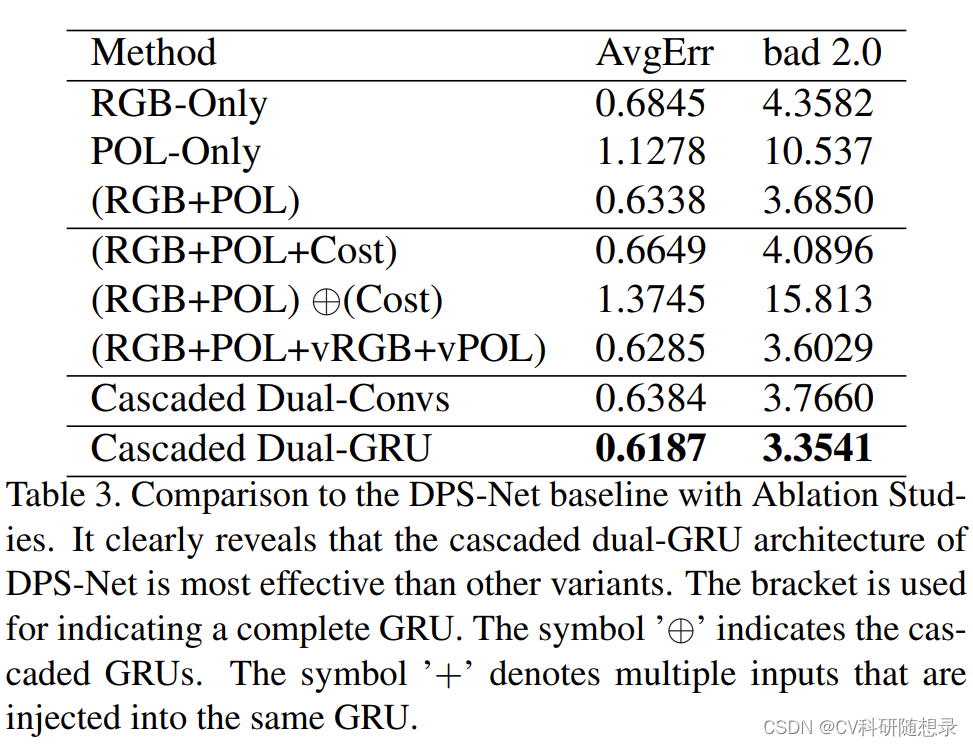
论文阅读《DPS-Net: Deep Polarimetric Stereo Depth Estimation》
论文地址:https://openaccess.thecvf.com/content/ICCV2023/html/Tian_DPS-Net_Deep_Polarimetric_Stereo_Depth_Estimation_ICCV_2023_paper.html 概述 立体匹配模型难以处理无纹理场景的匹配,现有的方法通常假设物体表面是光滑的,或者光照是…...
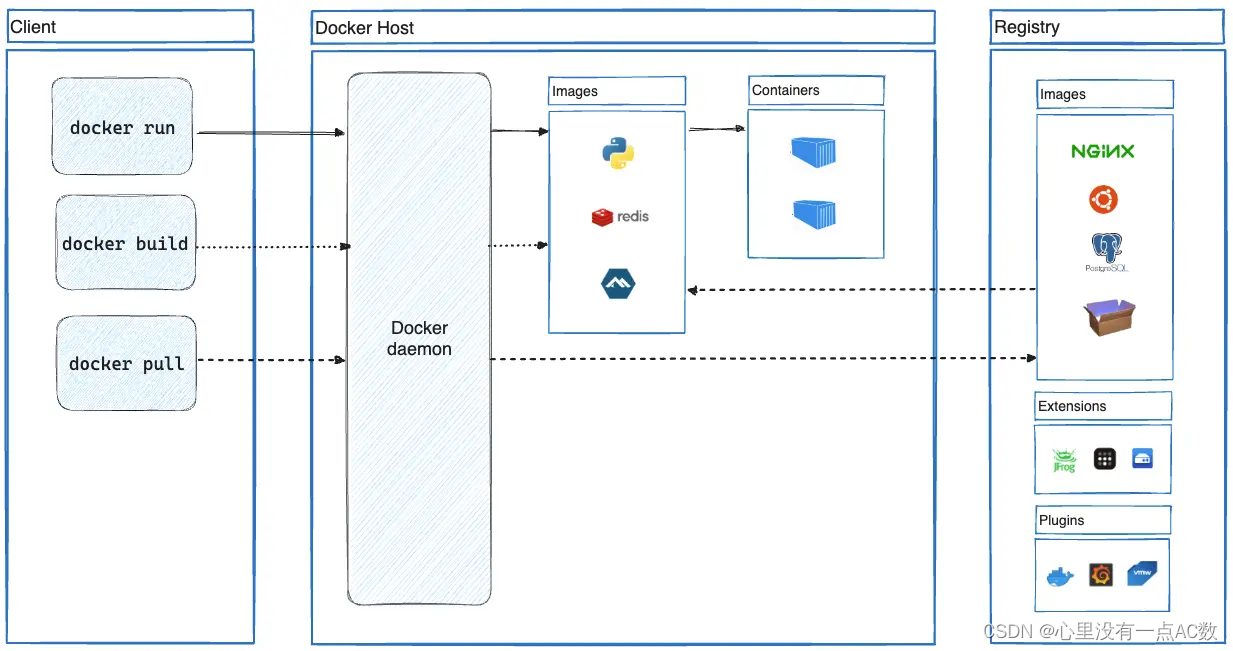
docker文档转译1
写在最前面 本文主要是转译docker官方文档。主题是Docker overview,这里是链接 Docker概述 Docker是一个用于开发、发布和运行应用程序的开放平台。Docker使你能够将应用程序与基础设施分离,从而可以快速交付软件。你可以使用相同的方法像管理应用程序…...
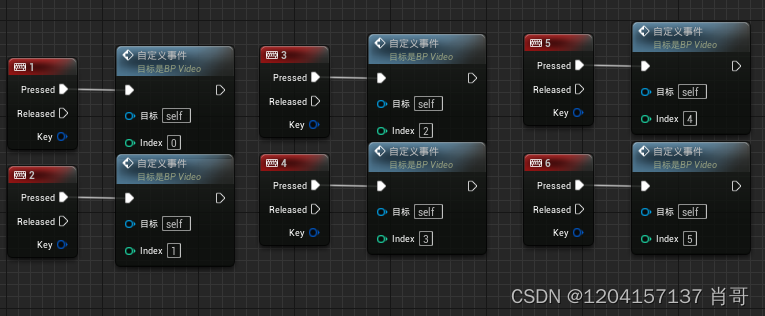
UE4 图片环形轮播 蓝图
【需求】 图片环形轮播 任意图片之间相互切换 切换图片所需时间均为1s 两个图片之间切换使用就近原则 播放丝滑无闪跳 【Actor的组成】 每个图片的轴心都在原点 【蓝图节点】...
饥荒Mod 开发(十):制作一把AOE武器
饥荒Mod 开发(九):物品栏排列 饥荒Mod 开发(十一):修改物品堆叠 前面的文章介绍了很多基础知识以及如何制作一个物品,这次制作一把武器,装备之后可以用来攻击怪物。 制作武器贴图和动画 1.1 制作贴图。 先准备一张武器的贴图&a…...

微服务实战系列之ZooKeeper(下)
前言 通过前序两篇关于ZooKeeper的介绍和总结,我们可以大致理解了它是什么,它有哪些重要组成部分。 今天,博主特别介绍一下ZooKeeper的一个核心应用场景:分布式锁。 应用ZooKeeper Q:什么是分布式锁 首先了解一下&…...

FFmpeg项目的组成
主要由三个部分组成: 工具 ffmpeg:用于音视频转码、转换ffplay:音视频播放器ffserver:流媒体服务器ffprobe:多媒体码流分析器 SDK 这个部分是供开发者使用的SDK,SDK是编译好的库。基本上每个平台都有对…...
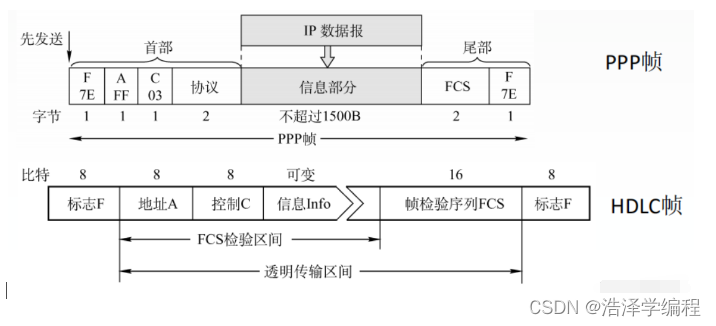
计算机网络:数据链路层(广域网、PPP协议、HDLC协议)
今天又学会了一个知识,加油! 目录 一、广域网 二、PPP协议 1、PPP协议应满足的要求 2、PPP协议无需满足的要求 3、PPP协议的三个组成部分 4、PPP协议的状态图 5、PPP协议的帧格式 三、HDLC协议 1、HDLC的站(主站、从站、复合站&…...

Spring Boot i18n中文文档
本文为官方文档直译版本。原文链接 Spring Boot 支持本地化消息,因此您的应用程序可以满足不同语言偏好的用户。默认情况下,Spring Boot 会在类路径的根目录下查找是否存在消息资源包。 自动配置适用于已配置资源包的默认属性文件(默认为 mes…...

持久化存储 StorageClass
kubernetes从v1.4版本开始引入了一个新的资源对象StorageClass,用于标记存储资源的特性和性能。到v1.6版本时,StorageClass和动态资源供应的机制得到了完善,实现了存储卷的按需创建,在共享存储的自动化管理进程中能够实现了重要的…...

uni-app点击预览图片
<image :src"info.shopLogoUrl" tap"_previewImage(info.shopLogoUrl)" mode"widthFix" >_previewImage(image) {var imgArr [];imgArr.push(image);//预览图片uni.previewImage({urls: imgArr,current: imgArr[0]});},大佬地址...
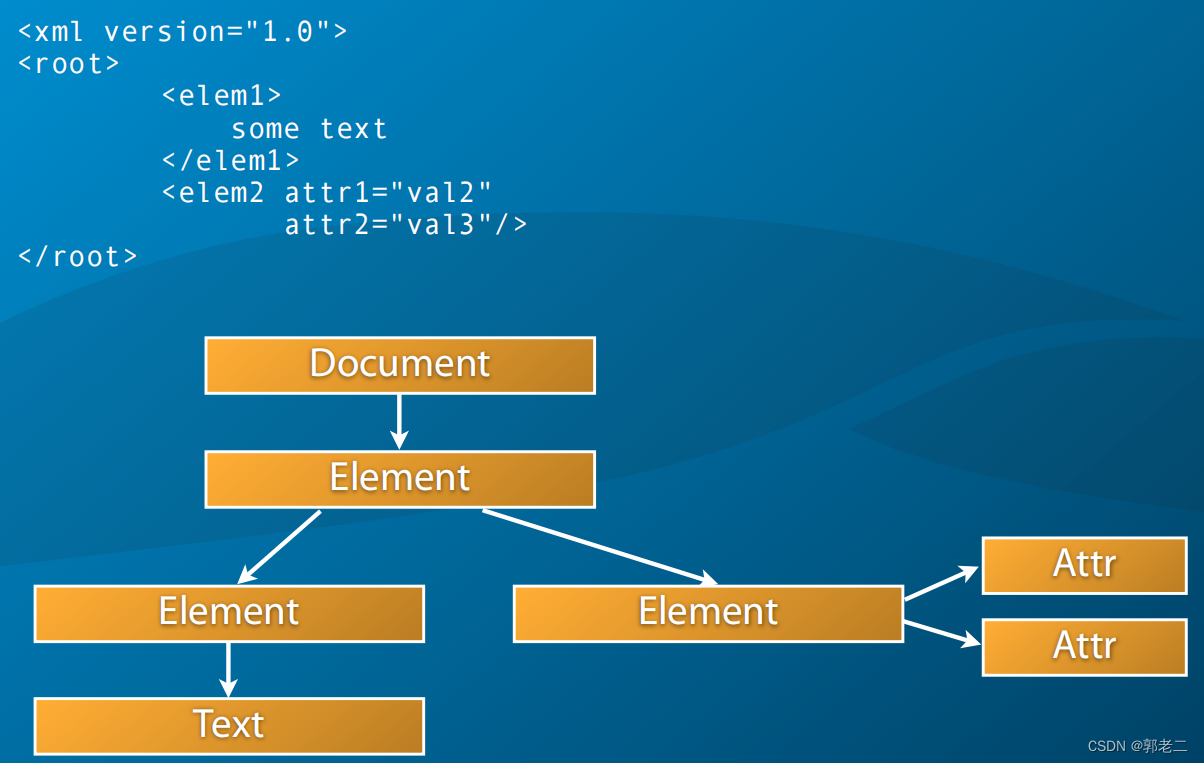
【C++】POCO学习总结(十八):XML
【C】郭老二博文之:C目录 1、XML文件格式简介 1)XML文件的开头一般都有个声明,声明是可选 <?xml version"1.0" encoding"UTF-8"?>2)根元素:XML文件最外层的元素 3ÿ…...
京东体育用品销售数据分析与可视化系统
京东体育用品销售数据分析与可视化系统 前言数据爬取模块1. 数据爬取2. 数据处理3. 数据存储 数据可视化模块1. 数据查看2. 店铺商品数量排行3. 整体好评率4. 不同品牌市场占比5. 品牌差评率排名6. 品牌价格排名7. 品牌评论数量分布 创新点 前言 在体育用品行业,了…...

如何快速实现语音转文字:AsrTools 零配置音频转字幕工具指南
如何快速实现语音转文字:AsrTools 零配置音频转字幕工具指南 【免费下载链接】AsrTools ✨ AsrTools: Smart Voice-to-Text Tool | Efficient Batch Processing | User-Friendly Interface | No GPU Required | Supports SRT/TXT Output | Turn your audio into acc…...

Git冲突解决终极指南:5步掌握hello-git实战视频中的冲突处理技巧
Git冲突解决终极指南:5步掌握hello-git实战视频中的冲突处理技巧 【免费下载链接】hello-git Curso para aprender a trabajar con el sistema de control de versiones Git y la plataforma GitHub desde cero y para principiantes. 项目地址: https://gitcode.…...

如何用MIKE IO快速上手水文数据分析:Python数据处理终极指南
如何用MIKE IO快速上手水文数据分析:Python数据处理终极指南 【免费下载链接】mikeio Read, write and manipulate dfs0, dfs1, dfs2, dfs3, dfsu and mesh files. 项目地址: https://gitcode.com/gh_mirrors/mi/mikeio MIKE IO是一个功能强大的Python开源库…...

Taotoken控制台的用量看板如何帮助团队管理API成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken控制台的用量看板如何帮助团队管理API成本 对于项目负责人或技术管理者而言,透明可控的支出至关重要。在集成多…...

Decepticon:基于AI的自主红队平台架构与实战解析
1. 项目概述:Decepticon,一个为专业红队而生的自主黑客智能体在网络安全领域,尤其是红队测试中,我们常常面临一个困境:攻击面在指数级增长,而人的精力和时间却是线性的。传统的渗透测试工具链虽然强大&…...

Xilinx 7系列FPGA目标设计平台:从芯片到生态的系统开发革命
1. 项目概述:Xilinx 7系列FPGA设计平台的划时代意义作为一名在数字系统设计领域摸爬滚打了十几年的工程师,我至今还记得2012年初听到Xilinx发布其28nm 7系列FPGA首批“目标设计平台”时的兴奋感。那感觉就像是,一直需要自己从零开始搭积木、焊…...

从车窗升降到自动驾驶:用5个真实故事看懂汽车总线LIN、CAN、CAN-FD、FlexRay和以太网的进化史
从车窗升降到自动驾驶:用5个真实故事看懂汽车总线技术的进化史 清晨七点,当上班族按下车钥匙解锁按钮时,车门锁、后视镜展开、仪表盘亮起的动作几乎同步完成——这背后是汽车电子系统数十年的进化缩影。从最初控制车窗升降的简单信号传输&…...

告别RAM焦虑:手把手教你用MicroBlaze BootLoader把大程序塞进QSPI Flash和DDR3
突破FPGA内存瓶颈:MicroBlaze大型程序加载实战指南 当你的MicroBlaze项目从简单的控制逻辑升级到需要文件系统、网络协议栈甚至实时操作系统时,代码体积的膨胀速度往往超出预期。那些曾经足够用的BRAM资源突然变得捉襟见肘——这就像试图在智能手机上运行…...

解决每次打开JFlash就提示:Device: TLE9863QXW20: Flash bank 0x11000000: No loader specified的问题
问题现象:每次打开JFlash就提示: Device: TLE9863QXW20: Flash bank 0x11000000: No loader specified解决方法:1.WinR 输入以下 打开目录:%APPDATA%\SEGGER\JLinkDevices2.文本打开xml文件:我是打开华大(HDCS)芯片的时…...

Windows 11本地部署最新大模型深度方案
一、方案概述 随着大语言模型的快速发展,本地部署已成为保护数据隐私、降低API成本的重要选择。本方案将详细介绍在Windows 11系统上部署最新大模型的完整流程,包括硬件配置、环境搭建、模型选择和性能优化。 二、硬件配置要求 2.1 最低配置 GPU: NVIDIA…...