kafka学习笔记--节点的服役与退役
本文内容来自尚硅谷B站公开教学视频,仅做个人总结、学习、复习使用,任何对此文章的引用,应当说明源出处为尚硅谷,不得用于商业用途。
如有侵权、联系速删
视频教程链接:【尚硅谷】Kafka3.x教程(从入门到调优,深入全面)
文章目录
- 服役新节点
- 新节点准备
- 执行负载均衡操作
- 退役旧节点
- 执行负载均衡操作
- 执行停止命令
服役新节点
依旧使用前面文章创建的三个hadoop102、103、104三个节点,模拟节点的服役与退役
新节点准备
(1)关闭 hadoop104,并右键执行克隆操作。
(2)开启 hadoop105,并修改 IP 地址。
[root@hadoop104 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.10.105
PREFIX=24
GATEWAY=192.168.10.2
DNS1=192.168.10.2(3)在 hadoop105 上,修改主机名称为 hadoop105。
[root@hadoop104 ~]# vim /etc/hostname
hadoop105
(4)重新启动 hadoop104、hadoop105。
(5)修改 haodoop105 中 kafka 的 broker.id 为 3。
(6)删除 hadoop105 中 kafka 下的 datas 和 logs。
[atguigu@hadoop105 kafka]$ rm -rf datas/* logs/*
(7)启动 hadoop102、hadoop103、hadoop104 上的 kafka 集群。
[atguigu@hadoop102 ~]$ zk.sh start
[atguigu@hadoop102 ~]$ kf.sh start
(8)单独启动 hadoop105 中的 kafka。
[atguigu@hadoop105 kafka]$ bin/kafka-server-start.sh -daemon ./config/server.properties
执行负载均衡操作
(1)创建一个要均衡的主题。
[atguigu@hadoop102 kafka]$ vim topics-to-move.json
{"topics": [{"topic": "first"}],"version": 1
}
(2)生成一个负载均衡的计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[0,2,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[1,0,2],"log_dirs":["any","any","any"]}]}Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","any","any"]}]}
(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json
输入如下内容:
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","any","any"]}]}
(4)执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
(5)验证副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verifyStatus of partition reassignment:
Reassignment of partition first-0 is complete.
Reassignment of partition first-1 is complete.
Reassignment of partition first-2 is complete.Clearing broker-level throttles on brokers 0,1,2,3
Clearing topic-level throttles on topic first
退役旧节点
执行负载均衡操作
先退役一台节点,生成执行计划,然后按照服役时操作流程执行负载均衡。
(1)创建一个要均衡的主题。
[atguigu@hadoop102 kafka]$ vim topics-to-move.json
{"topics": [{"topic": "first"}],"version": 1
}
(2)创建执行计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generateCurrent partition replica assignment
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[3,1,2],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[0,2,3],"log_dirs":["any","any","any"]}]}Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[1,2,0],"log_dirs":["any","any","any"]}]}(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2 中)。
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[1,2,0],"log_dirs":["any","any","any"]}]}
(4)执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
(5)验证副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verifyStatus of partition reassignment:
Reassignment of partition first-0 is complete.
Reassignment of partition first-1 is complete.
Reassignment of partition first-2 is complete.Clearing broker-level throttles on brokers 0,1,2,3
Clearing topic-level throttles on topic first
执行停止命令
在 hadoop105 上执行停止命令即可。
[atguigu@hadoop105 kafka]$ bin/kafka-server-stop.sh
相关文章:

kafka学习笔记--节点的服役与退役
本文内容来自尚硅谷B站公开教学视频,仅做个人总结、学习、复习使用,任何对此文章的引用,应当说明源出处为尚硅谷,不得用于商业用途。 如有侵权、联系速删 视频教程链接:【尚硅谷】Kafka3.x教程(从入门到调优…...
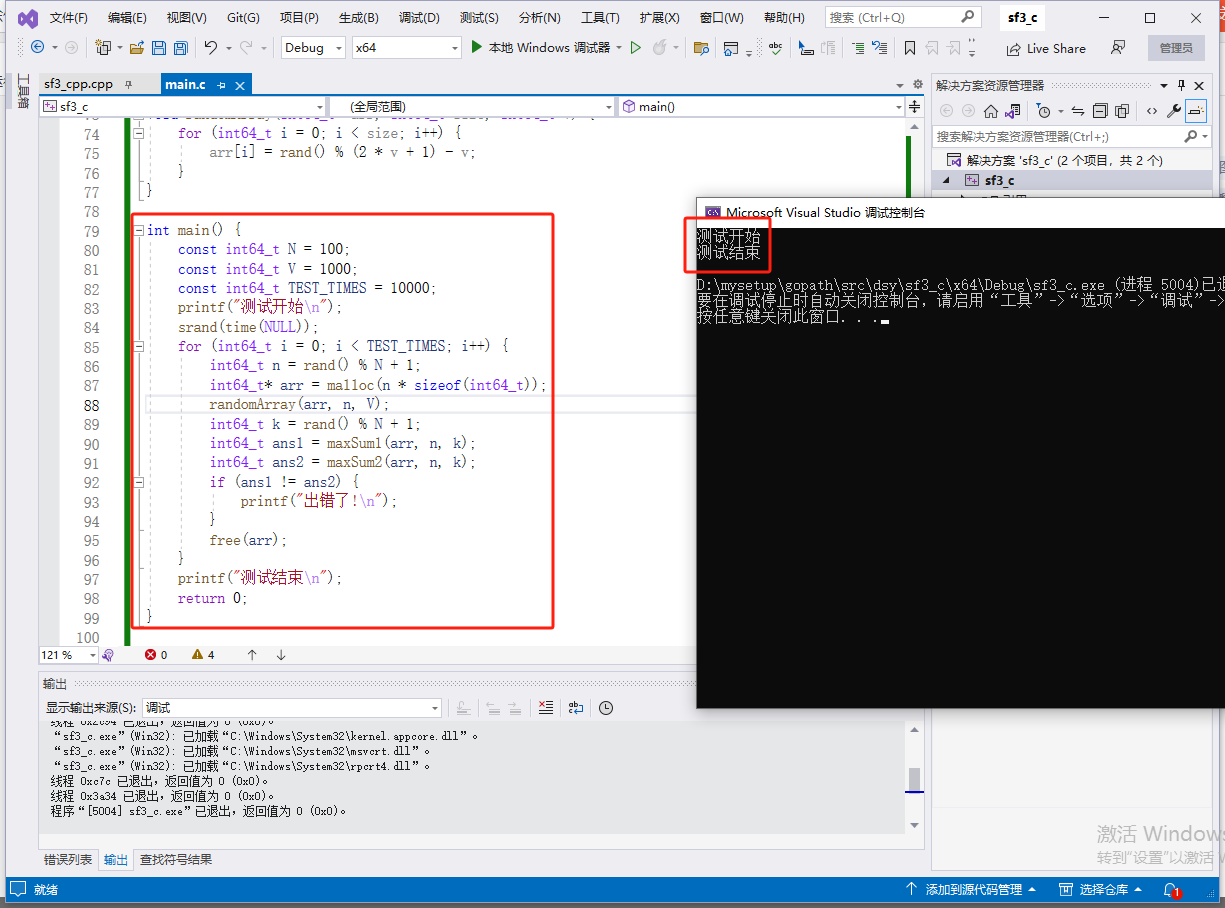
2023-12-16:用go语言,给定整数数组arr,求删除任一元素后, 新数组中长度为k的子数组累加和的最大值。 来自字节。
2023-12-16:用go语言,给定整数数组arr,求删除任一元素后, 新数组中长度为k的子数组累加和的最大值。 来自字节。 答案2023-12-16: 来自左程云。 灵捷3.5 大体步骤如下: 算法 maxSum1 分析࿱…...
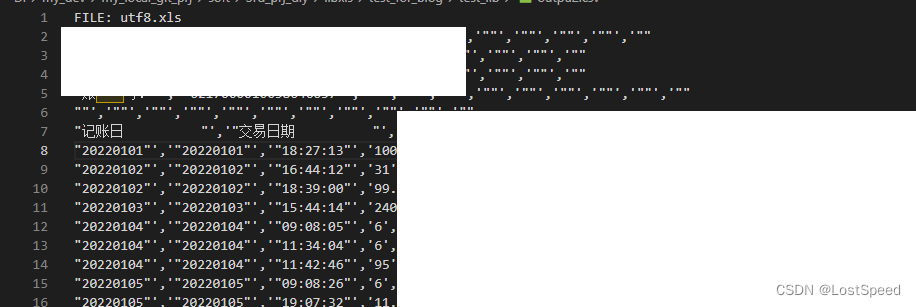
libxls - 编译
文章目录 libxls - 编译概述笔记静态库工程测试控制台exe工程测试备注备注END libxls - 编译 概述 想处理.xls格式的excel文件. 查了一下libxls库可以干这个事. 库地址 https://github.com/libxls/libxls.git 但是这个库的makefile写的有问题, 在mingw和WSL下都编译不了. 好在…...

自建私有git进行项目发布
自建私有git进行博客项目发布 之前尝试过通过建立私有git仓库,来发布自己的hexo静态博客,但是失败了,今天尝试了一下午,算是有了结果。下面记录我的过程。 我的需求: 我有一个服务器,希望在服务器端建一…...

华为HCIP认证H12-821题库上
1、2.OSPF核心知识 (单选题)下面关于0SPF的特殊区域,描述错误的是: A、Totally Stub Area允许ABR发布缺省的三类LSA,不接受五类LSA和细化三类LSA B、NSSA Area和Stub区域的不同在于该区域允许自治系统外部路由的引入,由ABR发布…...
Web安全漏洞分析—文件包含
在当今数字化时代,随着Web应用程序的广泛应用,网络安全问题愈加凸显。其中,文件包含漏洞作为一种常见但危险的安全隐患,为恶意攻击者提供了可乘之机。在这篇博客中,我们将深入探讨文件包含漏洞的本质、攻击手法以及应对…...
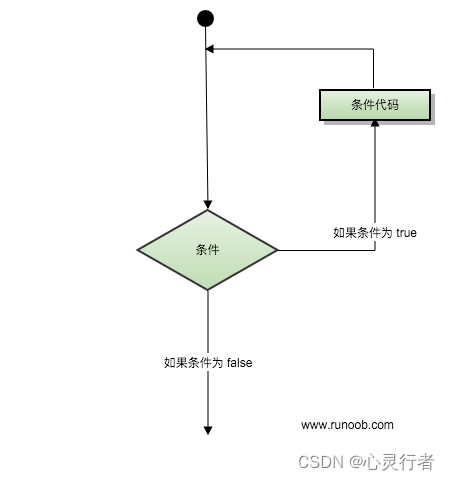
C++入门【9-C++循环】
C 循环 有的时候,可能需要多次执行同一块代码。一般情况下,语句是顺序执行的:函数中的第一个语句先执行,接着是第二个语句,依此类推。 编程语言提供了允许更为复杂的执行路径的多种控制结构。 循环语句允许我们多次…...
 ----20231215)
Python3 数字(Number) ----20231215
Python3 数字(Number) # Python3 数字(Number)# Python 数字数据类型用于存储数值。 # 数据类型是不允许改变的,这就意味着如果改变数字数据类型的值,将重新分配内存空间。# 以下实例在变量赋值时 Number 对象将被创建: var1 = 1 var2 = 10# 您也可以使用del语句删除一些数…...
PyQt6 QToolBar工具栏控件
锋哥原创的PyQt6视频教程: 2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~共计44条视频,包括:2024版 PyQt6 Python桌面开发 视频教程(无废话版…...
nodejs+vue+微信小程序+python+PHP基于大数据的银行信用卡用户的数仓系统的设计与实现-计算机毕业设计推荐
银行信用卡用户的数仓系统综合网络空间开发设计要求。目的是将银行信用卡用户的数仓系统从传统管理方式转换为在网上管理,完成银行信用卡用户的数仓管理的方便快捷、安全性高、交易规范做了保障,目标明确。银行信用卡用户的数仓系统可以将功能划分为管理…...

EMC RI/CI测试方案助您对抗电磁设备干扰!
方案背景 电磁或射频干扰的敏感性,会给工程师带来重大的风险和安全隐患。尤其是在工业、船用和医疗设备环境。这些环境系统中的控制、导航、监控、通信和警报等关键零部件必须具备电磁抗扰水平,以确保系统始终正常运行。 抗扰系统测试方案一般分为传导…...

【机器学习】数据降维
非负矩阵分解(NMF) sklearn.decomposition.NMF找出两个非负矩阵,即包含所有非负元素(W,H)的矩阵,其乘积近似于非负矩阵x。这种因式分解可用于例如降维、源分离或主题提取。 主成分分析(PCA) sklearn.decomposition.PCA使用数据的奇异值分解…...

vue3路由跳转及传参
1.创建项目及路由 1.1 创建文件时记得勾选上vue-router,没有勾选也没有关系 // vue3安装命令 npm create vuelatest // 以下选项可根据自己所需,进行选择,不懂就翻译 ✔ Project name: … <your-project-name> ✔ Add TypeScript? …...
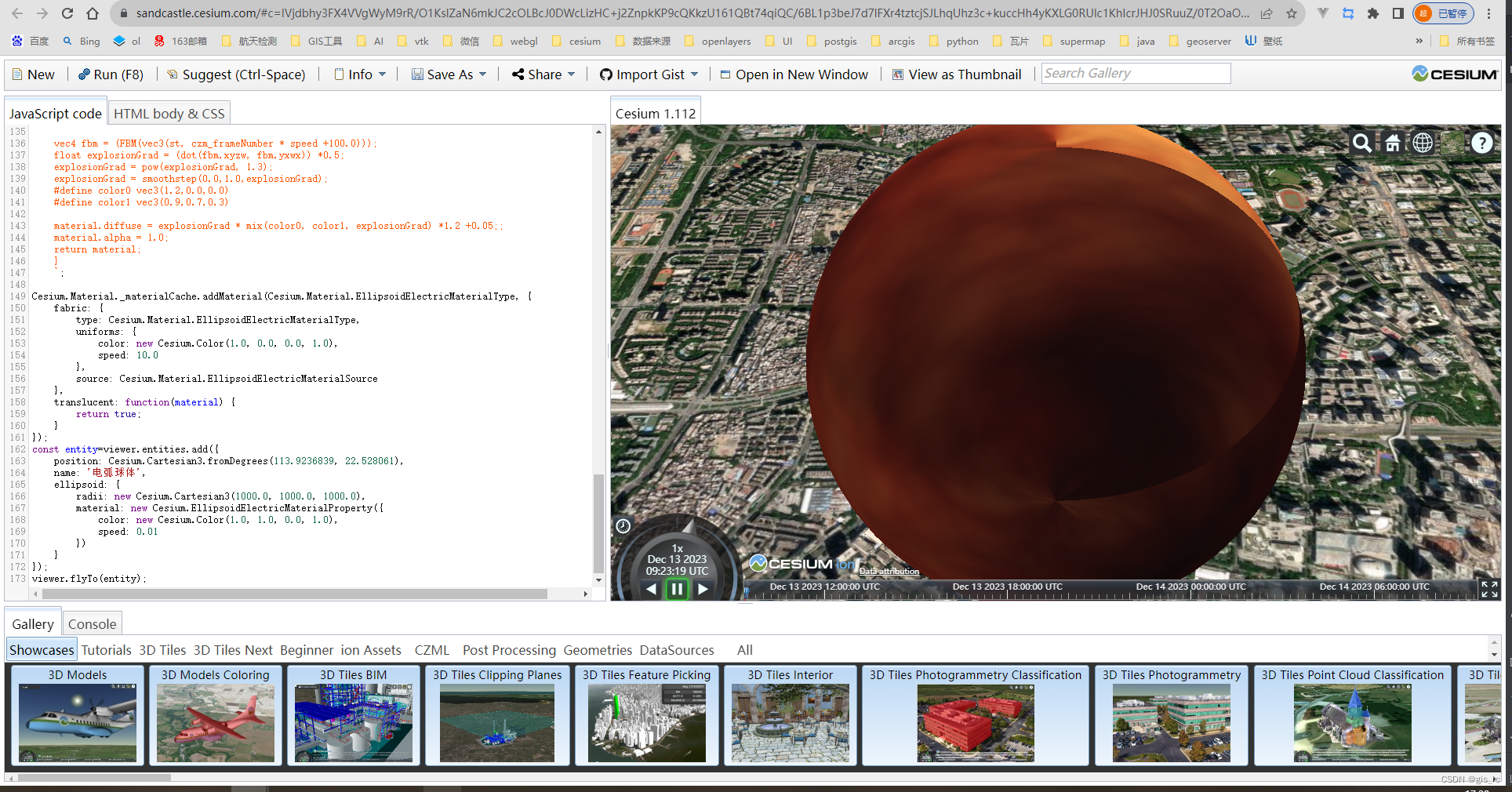
cesium 自定义贴图,shadertoy移植教程。
1.前言 cesium中提供了一些高级的api,可以自己写一些shader来制作炫酷的效果。 ShaderToy 是一个可以在线编写、测试和分享图形渲染着色器的网站。它提供了一个图形化的编辑器,可以让用户编写基于 WebGL 的 GLSL 着色器代码,并实时预览渲染结…...

引用阿里图标库,不知道对应的图标是什么,可在本地显示图标ui,再也不要担心刚来不知道公司图标对应的是什么了
项目中使用了阿里的图标库,但是无法看到对应显示什么,每次都要去阿里图标库里面找 在下载下来的文件中会发现有两个文件一个是iconfont.css和iconfont.json, 这两个文件的数据可以拿到然后显示在页面上 有两个问题: 1:…...

HandlerMethodArgumentResolver用于统一获取当前登录用户
这里记录回顾一些知识,不然就快忘记啦。 环境:SpringBoot 2.0.4.RELEASE需求:很多Controller方法,刚进来要先获取当前登录用户的信息,以便做后续的用户相关操作。准备工作:前端每次请求都传token࿰…...
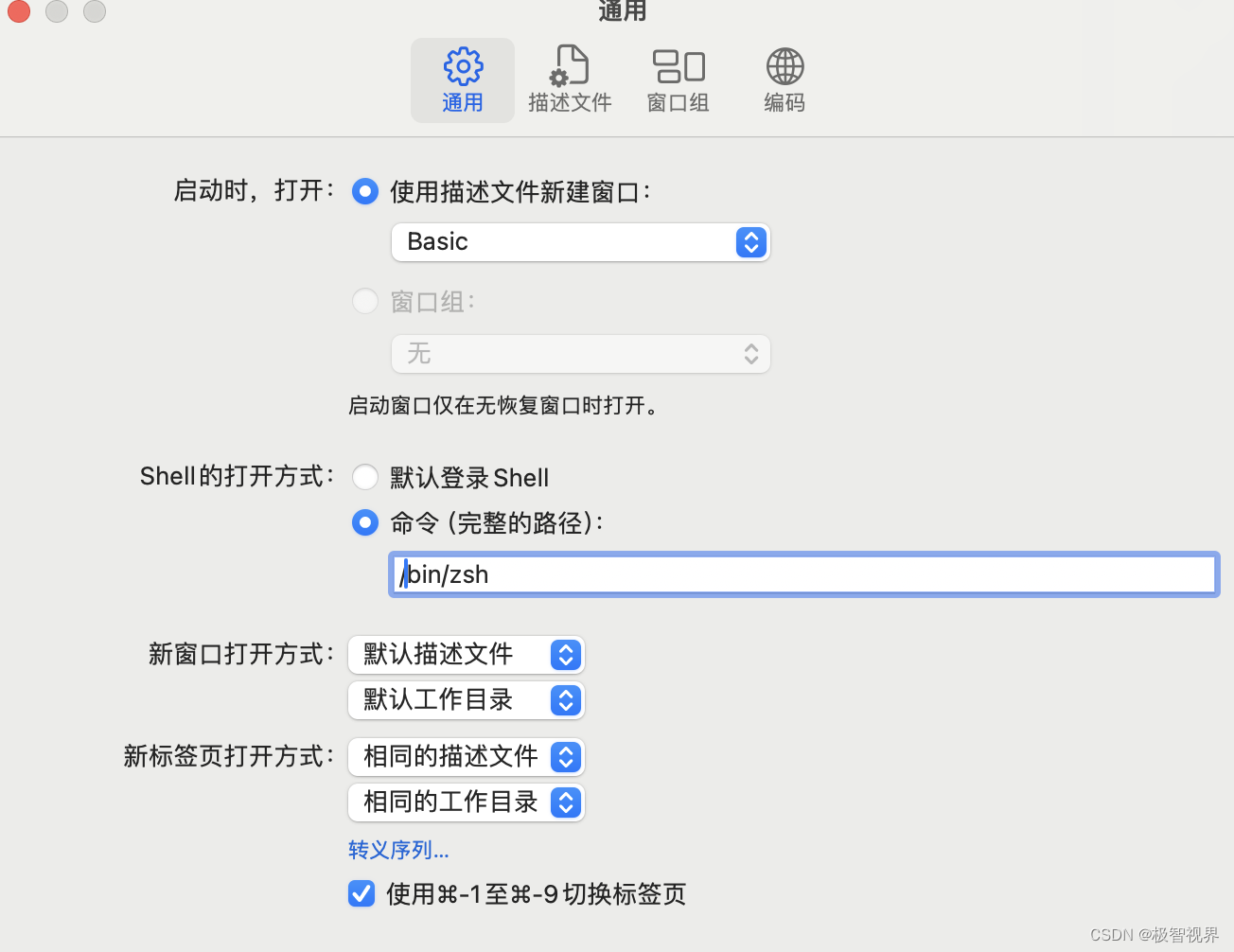
记录 | mac打开终端时报错:login: /opt/homebrew/bin/zsh: No such file or directory [进程已完成]
mac打开终端时报错:login: /opt/homebrew/bin/zsh: No such file or directory [进程已完成],导致终端没有办法使用的情况 说明 zsh 没有安装或者是安装路径不对 可以看看 /bin 下有没有 zsh,若没有,肯定是有 bash 那就把终端默…...
anolisos8.8安装显卡+CUDA工具+容器运行时支持(containerd/docker)+k8s部署GPU插件
anolisos8.8安装显卡及cuda工具 一、目录 1、测试环境 2、安装显卡驱动 3、安装cuda工具 4、配置容器运行时 5、K8S集群安装nvidia插件 二、测试环境 操作系统:Anolis OS 8.8 内核版本:5.10.134-13.an8.x86_64 显卡安装版本:525.147.05 c…...

Golang 链表的创建和读取 小记
文章目录 链表的相关知识链表的创建:模拟方式建立链表的**递归创建** 链表的读取遍历读取递归读取 完整代码 链表的相关知识 链表有时会具有头节点,头节点的指针指向第一个节点的地址,其本身的数据域可以根据自己的选择进行赋值 接下来我将以将int转…...
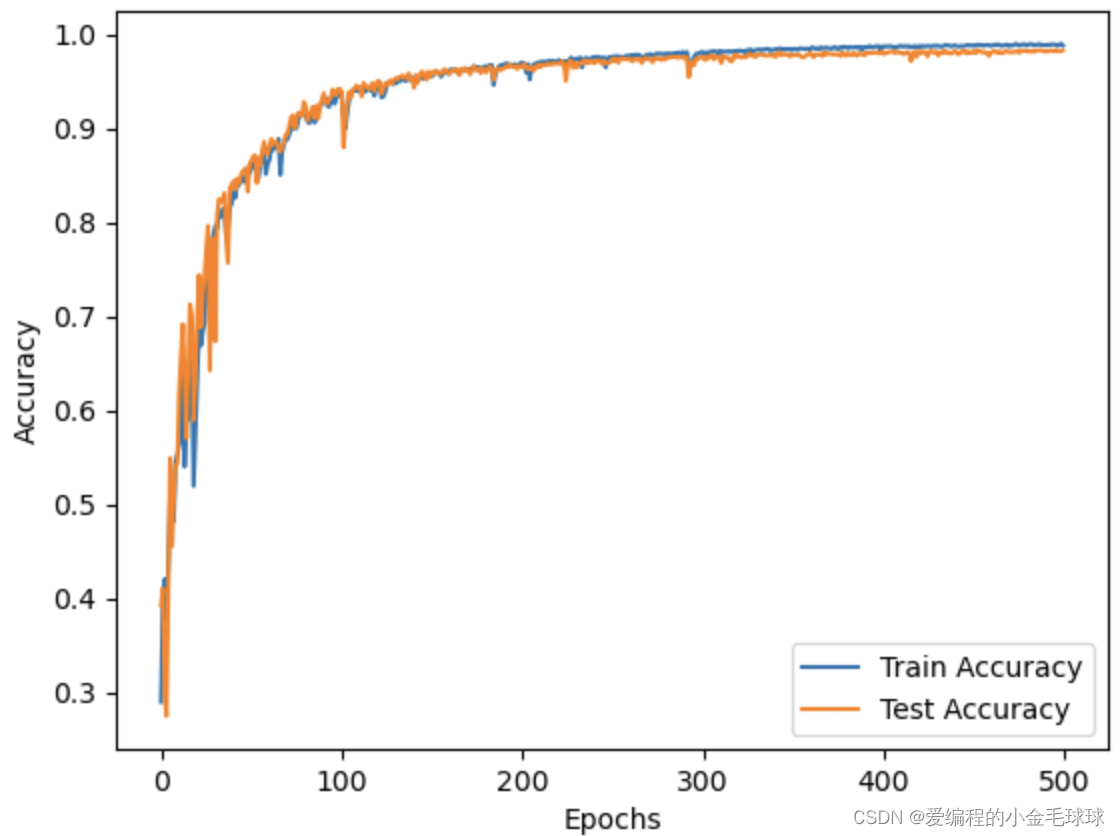
实验记录:深度学习模型收敛速度慢有哪些原因
深度学习模型收敛速度慢有哪些原因? 学习率设置不当: 学习率是算法中一个重要的超参数,它控制模型参数在每次迭代中的更新幅度。如果学习率过大,可能会导致模型在训练过程中的振荡,进而影响到收敛速度;如果…...

9.5%复合增长率强势领航!2025年全球甲酸真空回流焊炉市场规模1.2亿美元,2032年剑指2.24亿,高增长动能全面释放
QYResearch调研显示,2025年全球甲酸真空回流焊炉市场规模大约为1.2亿美元,预计2032年将达到2.24亿美元,2026-2032期间年复合增长率(CAGR)为9.5%。结合QYResearch数据及行业深耕经验,当前甲酸真空回流焊炉行…...

Postman数据迁移实战:如何用导入导出功能,在团队间高效同步你的接口集合和环境变量
Postman团队协作指南:接口资产迁移与标准化管理实践 在分布式团队和敏捷开发成为主流的今天,API开发工具的高效使用直接影响着协作效率。作为被全球超过2000万开发者使用的API工具,Postman的集合与环境变量功能已经成为团队间接口定义传递的事…...

抖音视频批量下载难题如何解决?douyin-downloader开源工具完整指南
抖音视频批量下载难题如何解决?douyin-downloader开源工具完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fa…...

从点灯到项目:手把手教你为TMS320F28335创建可复用的工程模板
从点灯到项目:手把手教你为TMS320F28335创建可复用的工程模板 当你第一次点亮TMS320F28335开发板上的LED时,那种成就感无与伦比。但很快你会发现,随着项目复杂度提升,代码开始变得混乱不堪——头文件散落各处、函数命名随意、每次…...

LuckyLilliaBot终极指南:一站式构建跨协议QQ机器人的完整解决方案
LuckyLilliaBot终极指南:一站式构建跨协议QQ机器人的完整解决方案 【免费下载链接】LuckyLilliaBot 支持 OneBot 11、Satori 和 Milky 协议 项目地址: https://gitcode.com/gh_mirrors/li/LuckyLilliaBot 还在为QQ机器人开发中协议不兼容、功能单一而烦恼吗&…...
:基于CLIP-ViT-L/14特征空间逆向推演的6维可控性建模)
Midjourney提示词黑箱破解(仅限本期开放):基于CLIP-ViT-L/14特征空间逆向推演的6维可控性建模
更多请点击: https://intelliparadigm.com 第一章:Midjourney提示词黑箱破解的底层逻辑与认知跃迁 Midjourney 的提示词(Prompt)并非自然语言自由表达,而是一套隐式编码的**语义协议栈**——它在扩散模型隐空间中触发…...

OpenMC多群截面计算深度解析:传输修正合并的3种解决方案与性能优化实战
OpenMC多群截面计算深度解析:传输修正合并的3种解决方案与性能优化实战 【免费下载链接】openmc OpenMC Monte Carlo Code 项目地址: https://gitcode.com/gh_mirrors/op/openmc 你是否在使用OpenMC进行多群蒙特卡洛计算时,遇到模拟结果与参考值偏…...

物联网服务选型指南:从核心模块解析到实战避坑
1. 物联网服务选型:从数据孤岛到智能系统的桥梁在物联网项目里摸爬滚打了十几年,我见过太多项目卡在“服务选型”这个环节。很多工程师朋友,硬件玩得转,代码写得溜,但一到要把设备连上网,让数据跑起来&…...

NoSleep:告别Windows意外休眠的终极解决方案,让你的电脑始终保持清醒状态
NoSleep:告别Windows意外休眠的终极解决方案,让你的电脑始终保持清醒状态 【免费下载链接】NoSleep Lightweight Windows utility to prevent screen locking 项目地址: https://gitcode.com/gh_mirrors/nos/NoSleep 你是否经历过视频会议演示到一…...

BilibiliDown:三步搞定B站无损音频提取,构建你的专属音乐库
BilibiliDown:三步搞定B站无损音频提取,构建你的专属音乐库 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.…...