国产ToolLLM的课代表---OpenBMB机构(清华NLP)旗下ToolBench的安装部署与运行(附各种填坑说明)
ToolBench项目可以理解为一个能直接提供训练ToolLLM的平台,该平台同时构建了ToolLLM的一个开源训练指令集。,该项目是OpenBMB机构(面壁智能与清华NLP联合成立)旗下的一款产品,OpenBMB机构名下还同时拥有另外一款明星产品–XAgent。
ToolBench的简介
该项目旨在构建开源、大规模、高质量的指令调整 SFT 数据,以促进构建具有通用工具使用能力的强大LLMs。其目标是赋予开源 LLMs 掌握成千上万多样的真实世界API能力。项目通过收集高质量的指令调整数据集来实现这一目标。该数据集使用最新的ChatGPT(gpt-3.5-turbo-16k)自动构建,该版本升级了增强的函数调用功能。
与此同时,通过项目提供的数据集、相应的训练和评估脚本,可以得到ToolBench上经过微调的一个强大的工具调用模型ToolLLaMA。
项目数据集的构建
以下是数据集构建方法、模型训练、推理模式的整体概览
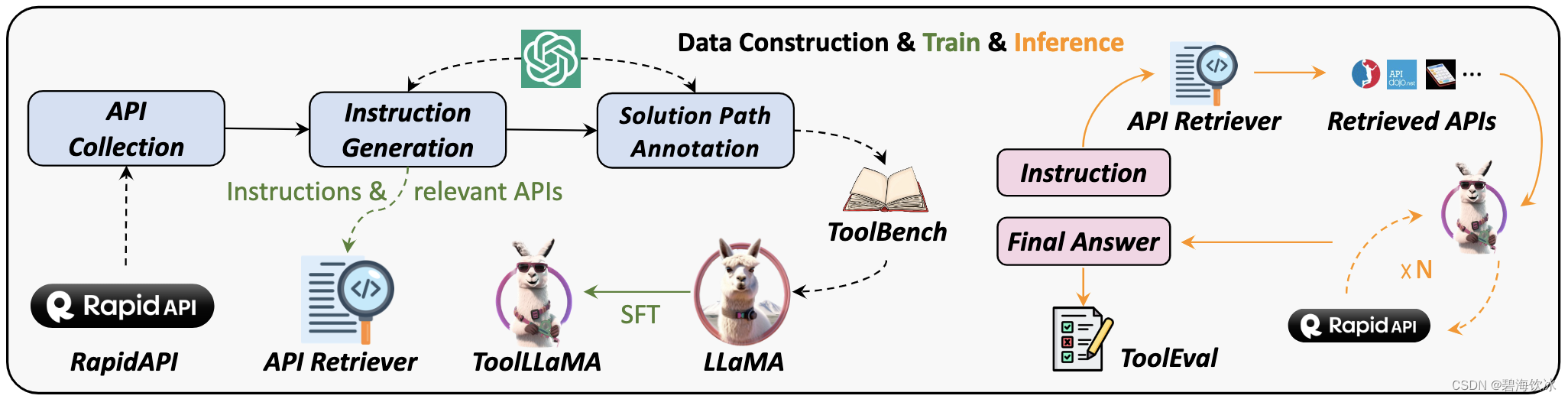
产品自身特点
API收集: 项目从 RapidAPI 收集了 16464 个API。RapidAPI 是一个托管开发者提供的大规模真实世界API的平台。
指令生成: 项目生成了涉及单工具和多工具场景的指令。
回答标注: 项目设计了一种新颖的深度优先搜索决策树方法(DFSDT),以增强LLMs的规划和推理能力。这显著提高了标注效率,并成功地对那些不能用CoT或ReACT回答的复杂指令进行了标注。项目提供的回答不仅包括最终答案,还包括模型的推理过程、工具执行和工具执行结果。
API Retriever: 项目整合了API检索模块,为ToolLLaMA提供了开放域的工具使用能力。
数据生成:所有数据均由OpenAI API自动生成并由项目组筛选,整个数据创建过程易于扩展。
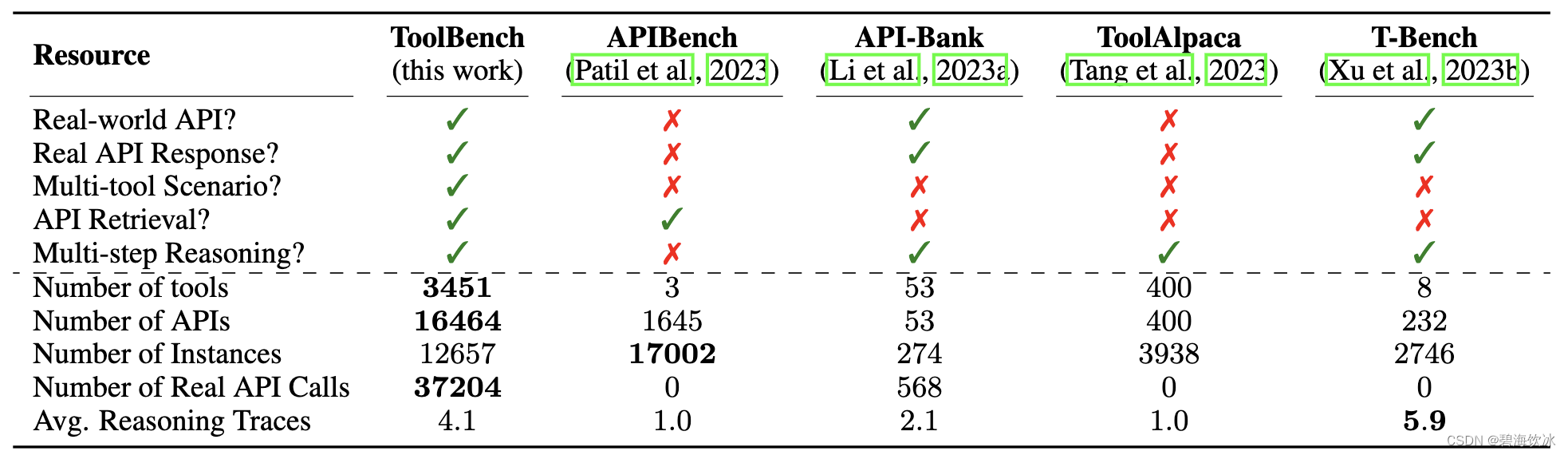
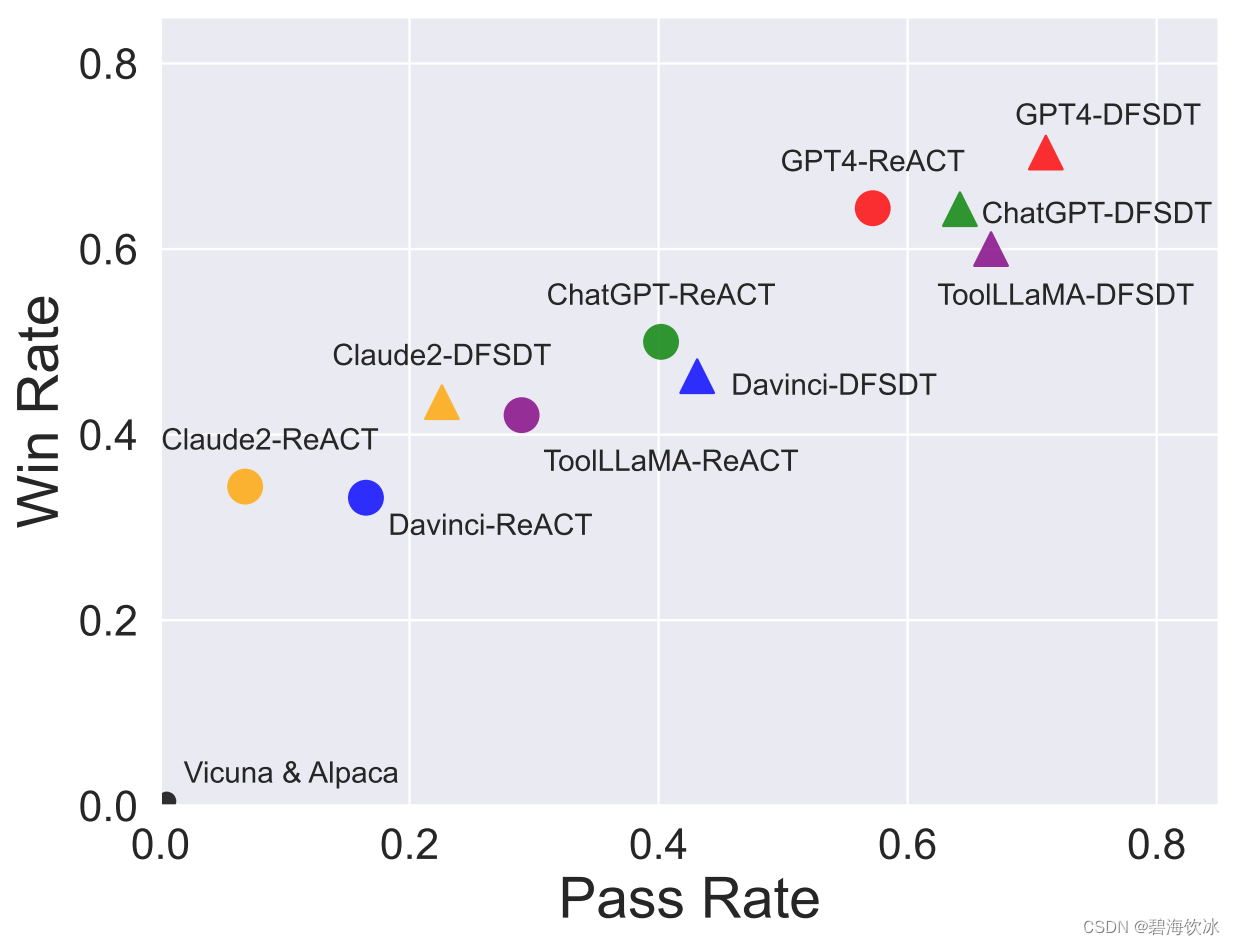
ToolLLaMA已经达到了和ChatGPT(turbo-16k)接近的工具使用能力,未来我们将不断进行数据的后处理与清洗,以提高数据质量并增加真实世界工具的覆盖范围。
产品的FT(FineTuning)
该项目提供了ToolLLaMA的FT方法,本篇不做更多介绍,又兴趣的同学可以到这里查看其具体流程
ToolBench的安装
Clone项目
克隆这个仓库并进入ToolBench文件夹。
git clone git@github.com:OpenBMB/ToolBench.git
cd ToolBench
申请项目方的ToolbenchKey
因为项目方自建了RapidAPI的服务,可以向项目方申请使用该RapidAPI服务进行推理。
请点击这里填写问卷,大概2个工作日内,工作人员会给你ToolBench项目方给您发送toolbench key。然后初始化您的toolbench key:
export TOOLBENCH_KEY="your_toolbench_key"
当然,您也可以使用自己私有的RapidAPI Account进行推理,具体操作可以看这里
ToolBench 的设置与启动
ToolBench运行环境是要求Python>=3.9,此处我们用了Python3.10,为防止环境间的干扰,使用了Conda,Conda的安装配置可以自行百度解决,要注意下载2023年的版本,能够支持到3.10才可以
# 新创建toolbench_env环境,使用python3.10
conda create -n toolbench_env python=3.10 -y# 查看已建立的所有的虚拟环境
conda env list
# conda environments:
#
# base * /root/anaconda3
# py310 /root/anaconda3/envs/py310
# toolbench_env /root/anaconda3/envs/toolbench_env# 切换到toolbench_env
conda active toolbench_env# 在Toolbench的根目录下执行以下命令安装依赖包
pip install -r requirements.txt
DataSet的下载
推理时会需要一些预设的数据(其实,大部分数据时训练ToolLLaMA模型所使用的),可以到 Tsinghua Cloud.这个地方去下载
下载的数据解压后,就在项目目录的data文件夹下,400M大小,其数据的目录格式如下
├── /data/
│ ├── /instruction/
│ ├── /answer/
│ ├── /toolenv/
│ ├── /retrieval/
│ ├── /test_instruction/
│ ├── /test_query_ids/
│ ├── /retrieval_test_query_ids/
│ ├── toolllama_G123_dfs_train.json
│ └── toolllama_G123_dfs_eval.json
├── /reproduction_data/
│ ├── /chatgpt_cot/
│ ├── /chatgpt_dfs/
│ ├── ...
│ └── /toolllama_dfs/
ToolBench的python应用推理
运行推理时,可以使用项目方已经训练完毕的ToolLLaMA版本,也可以使用OpenAI的key来调用GPT3.5或GPT4.0服务。
使用项目方的ToolLLaMA
项目方已经训练的ToolLLaMA版本已升级到ToolLLaMA-2-7b-v2,其模型利用了Toolbench项目的数据集,经由LLaMA-2-7b微调而来, 可免费下载使用。
抱抱脸那边时常连接不太稳定,而且,当前的ToolLLaMA-2-7b-v2模型文件的总和已经到达20G+,连接外网不方便或机器资源不那么充裕的,大概率会被劝退,这时可以使用OpenAI的Key来试试效果~~
使用OpenAI的key
- 用rapidAPI作答
将您的OPENAI_KEY设定后,使用以下代码运行(官方的指引直接跑不起来,请使用我的这个命令)
export TOOLBENCH_KEY=""
export OPENAI_KEY=""
export PYTHONPATH=./
python toolbench/inference/qa_pipeline.py \--tool_root_dir data/toolenv/tools/ \--backbone_model chatgpt_function \--openai_key $OPENAI_KEY \--max_observation_length 1024 \--method DFS_woFilter_w2 \--input_query_file data/test_instruction/G1_instruction.json \--output_answer_file chatgpt_dfs_inference_result/qa_answer \--toolbench_key $TOOLBENCH_KEY
注意的坑:如果代码提示有说OpenAI版本过高的问题,可以直接运行以下命令,将openai包还原到1.00以下
pip install openai==0.28.0
执行以上的命令时,会解析ata/test_instruction/G1_instruction.json文件的请求,然后进行响应,这个文件如果不做任何编辑,猜想应该会把里面的所有Task都跑一遍,我还是很心疼自己的美刀,于是只留出一个看看效果就行了,G1_instruction.json文件裁剪后的内容如下:
[{"api_list": [{"category_name": "Food","tool_name": "Nutrition by API-Ninjas","api_name": "/v1/nutrition","api_description": "API Ninjas Nutrition API endpoint.","required_parameters": [{"name": "query","type": "STRING","description": "Query text to extract nutrition information (e.g. **bacon and 3 eggs**).","default": "1lb brisket with fries"}],"optional_parameters": [],"method": "GET","template_response": {"name": "str","calories": "float","serving_size_g": "float","fat_total_g": "float","fat_saturated_g": "float","protein_g": "float","sodium_mg": "int","potassium_mg": "int","cholesterol_mg": "int","carbohydrates_total_g": "float","fiber_g": "float","sugar_g": "float"}}],"query": "I'm planning a family dinner and I need to know the nutrition information for a recipe. Can you extract the nutrition data for a dish that includes 2 pounds of chicken, 1 cup of rice, and 3 tablespoons of olive oil?","relevant APIs": [["Nutrition by API-Ninjas","/v1/nutrition"]],"query_id": 88193}
]
上面那个文件的示例,其实也就是要问这句话:
I’m planning a family dinner and I need to know the nutrition information for a recipe.
Can you extract the nutrition data for a dish that includes 2 pounds of chicken, 1 cup of rice, and 3 tablespoons of olive oil?
如果运行成功,可以看到输出的内容如下:
[process(0)]now playing I'm planning a family dinner and I need to know the nutrition information for a recipe. Can you extract the nutrition data for a dish that includes 2 pounds of chicken, 1 cup of rice, and 3 tablespoons of olive oil?, with 2 APIs
[process(0)]total tokens: 698
Action: v1_nutrition_for_nutrition_by_api_ninjas
query to Food-->nutrition_by_api_ninjas-->v1_nutrition_for_nutrition_by_api_ninjas
Action Input: {"query": "2 pounds of chicken, 1 cup of rice, and 3 tablespoons of olive oil"
}
Observation: {"error": "", "response": "[{'name': 'chicken', 'calories': 2019.8, 'serving_size_g': 907.184, 'fat_total_g': 117.0, 'fat_saturated_g': 33.2, 'protein_g': 215.3, 'sodium_mg': 655, 'potassium_mg': 1625, 'cholesterol_mg': 835, 'carbohydrates_total_g': 0.4, 'fiber_g': 0.0, 'sugar_g': 0.0}, {'name': 'rice', 'calories': 201.3, 'serving_size_g': 158.0, 'fat_total_g': 0.4, 'fat_saturated_g': 0.1, 'protein_g': 4.2, 'sodium_mg': 1, 'potassium_mg': 67, 'cholesterol_mg': 0, 'carbohydrates_total_g': 44.9, 'fiber_g': 0.6, 'sugar_g': 0.1}, {'name': 'olive oil', 'calories': 352.0, 'serving_size_g': 40.5, 'fat_total_g': 41.0, 'fat_saturated_g': 5.6, 'protein_g': 0.0, 'sodium_mg': 0, 'potassium_mg': 0, 'cholesterol_mg': 0, 'carbohydrates_total_g': 0.0, 'fiber_g': 0.0, 'sugar_g': 0.0}]"}
[process(0)]total tokens: 1405
Action: Finish
Action Input: {"return_type": "give_answer","final_answer": "The nutrition information for the dish is as follows:\n- Chicken:\n - Calories: 2019.8\n - Fat: 117g\n - Saturated Fat: 33.2g\n - Protein: 215.3g\n - Sodium: 655mg\n - Potassium: 1625mg\n - Cholesterol: 835mg\n - Carbohydrates: 0.4g\n - Fiber: 0g\n - Sugar: 0g\n- Rice:\n - Calories: 201.3\n - Fat: 0.4g\n - Saturated Fat: 0.1g\n - Protein: 4.2g\n - Sodium: 1mg\n - Potassium: 67mg\n - Cholesterol: 0mg\n - Carbohydrates: 44.9g\n - Fiber: 0.6g\n - Sugar: 0.1g\n- Olive Oil:\n - Calories: 352\n - Fat: 41g\n - Saturated Fat: 5.6g\n - Protein: 0g\n - Sodium: 0mg\n - Potassium: 0mg\n - Cholesterol: 0mg\n - Carbohydrates: 0g\n - Fiber: 0g\n - Sugar: 0g"
}
Observation: {"response":"successfully giving the final answer."}
[process(0)]valid=True另外,以上命令成功运行后,就会在chatgpt_dfs_inference_result/qa_answer文件夹中生成回复文件,再次运行同样的命令不会再重新生成gpt请求,除非将应答文件手动删除。
- 用customAPI作答
这种方式,其开源项目地址已有描述,可以参照这里
需要注意的坑:
第一, API描述的json文件中,tool_name字段名要和文件名保持一致,是不是一定英文没有验证过
第二,json描述文件的位置要在data/toolenv/tools/目录下面,且要新建文件夹,文件夹的名字不一定非要是’Customized’,但位置不能变,因为所有tools的白名单都是从data/toolenv/tools/目录获取的
后端:server启动
正常提供服务时,我们还是需要把各个可执行命令转化为server服务,方便进行连续测试,以下则是server启动的操作方法(此处用的还是openai key,如果你想使用ToolLLaMA来启动,请参照github上的说明):
export TOOLBENCH_KEY="your toolbench key is applied from ToolBench platform"
export OPENAI_KEY="your OpenAI key"
export PYTHONPATH=./# 该条命令能够启动Toolbenchserver,不过目前官方的server启动模式还尚未能完全兼容gpt的指令,
# 在前端发出指令后,其响应的代码逻辑仍存在问题.
# 查看了一下源码,应该是toolbench_server.py代码中定义data_dict = { "query": user_input},这个对象的包装缺少api_tools的相关定义,
# 其缺失的代码逻辑需要补足后才能正常工作(本来是打算server启动后再来hack代码尝试的,发现可能需要不少变动甚至重构,还没有成型的解决方案)
python toolbench/inference/toolbench_server.py \--corpus_tsv_path data/retrieval/G1/corpus.tsv \--retrieved_api_nums 5 \--tool_root_dir data/toolenv/tools/ \--backbone_model chatgpt_function \--openai_key $OPENAI_KEY \--max_observation_length 1024 \--method DFS_woFilter_w2 \--input_query_file data/test_instruction/G1_instruction.json \--output_answer_file chatgpt_dfs_inference_result/server_answer \--toolbench_key $TOOLBENCH_KEY
注意的坑:以上使用openai key的方式启动,如果有关于model path的错误爆出时,可以将toolbench\inference\toolbench_server.py的部分代码进行变动以绕过。
# 在class Model初始化的那部分代码中变动以下内容:
print("Loading retriever...")# 注释下面这句,然后将retriever赋None值,因为使用chatgpt_function时,不会使用retriever相关代码
# self.retriever = self.pipeline.get_retriever() self.retriever = None
正常启动后,可以看到以下提示:
Server ready* Serving Flask app 'toolbench_server'* Debug mode: on
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.* Running on all addresses (0.0.0.0)* Running on http://127.0.0.1:5000* Running on http://10.0.0.11:5000
Press CTRL+C to quit
前端:chatbot-ui-toolllama
ToolBench 项目和一个基于ChatBotUi的Web UI项目可以搭配使用, 以用于后端的Tools调用。
# 本地运行chatbot-ui-toolllama的步骤
git clone https://github.com/lilbillybiscuit/chatbot-ui-toolllama
cd chatbot-ui-toolllama
# 此处运行前请先通过nvm来快速安装node v18版本
npm install
npm run dev
运行之后,你能看到以下提示:
> ai-chatbot-starter@0.1.0 dev
> next devready - started server on 0.0.0.0:3000, url: http://localhost:3000
Attention: Next.js now collects completely anonymous telemetry regarding usage.
This information is used to shape Next.js' roadmap and prioritize features.
You can learn more, including how to opt-out if you'd not like to participate in this anonymous program, by visiting the following URL:
https://nextjs.org/telemetryevent - compiled client and server successfully in 4.3s (273 modules)
wait - compiling...
event - compiled successfully in 302 ms (233 modules)
*注意的坑:*如果碰到以下错误信息:
showAll: args["--show-all"] ?? false,
syntaxError: Unexpected token '?'
上面的错误提示,意味着你的node环境是不是 v18版本,可以用nvm install v18来安装该环境
nvm install v18
# 根据nvm所安装的版本,把node版本切换到v18
nvm use v18.19.0
# 将v18更改为默认node版本
nvm alias default v18.19.0
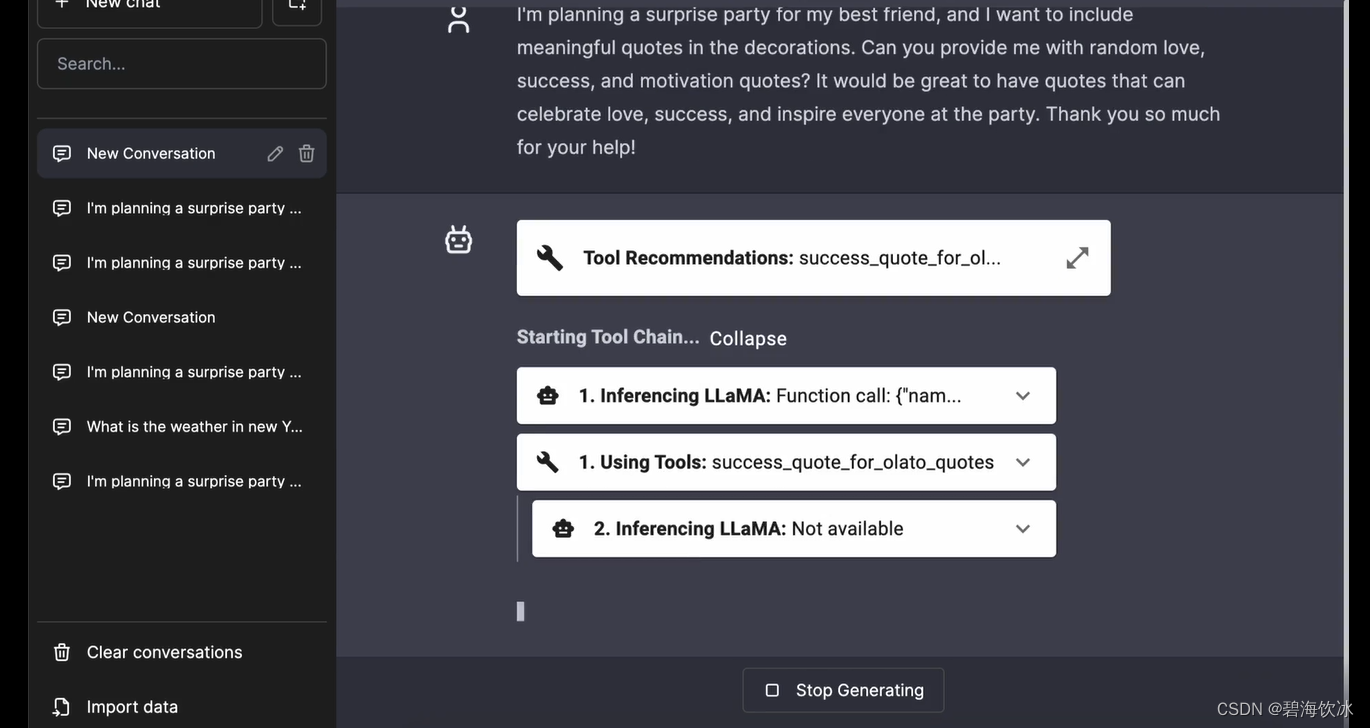
启动后,访问http://localhost:3000就能打开一个类似chatgpt的聊天页面,和下面这个应该相似(借官网的一用)。这是部署了ToolbenchLLaMA的应答效果,但那个model实在是大,暂时手上没有闲置的GPU机器,自己改造了后台GPT直连,只是将python单应用跑通,了解下这个项目的应用潜力和设计思路,本人尚未将server的gpt模式和前台的联动代码调通,有兴趣的同学可以继续尝试哈。
相关文章:
国产ToolLLM的课代表---OpenBMB机构(清华NLP)旗下ToolBench的安装部署与运行(附各种填坑说明)
ToolBench项目可以理解为一个能直接提供训练ToolLLM的平台,该平台同时构建了ToolLLM的一个开源训练指令集。,该项目是OpenBMB机构(面壁智能与清华NLP联合成立)旗下的一款产品,OpenBMB机构名下还同时拥有另外一款明星产…...
-C#串口通信数据接收不完整解决方案)
串口通信(5)-C#串口通信数据接收不完整解决方案
本文讲解C#串口通信数据接收不完整解决方案。 目录 一、概述 二、Modbus RTU介绍 三、解决思路 四、实例 一、概述 串口处理接收数据是串口程序编写的关键...

大数据分析岗是干什么的?
大数据分析岗主要负责从大规模数据集中提取、整理、分析和解释有关业务、市场或其他相关领域的信息的职位。 主要的职责和工作内容如下: 1. 数据收集和整理 收集各种数据源(包括结构化、非结构化和半结构化数据),并将其整理成可…...

hadoop运行jar遇到的一个报错
报错信息: 2023-12-19 14:28:25,893 INFO mapreduce.Job: Job job_1702967272525_0001 failed with state FAILED due to: Application application_1702967272525_0001 failed 2 times due to AM Container for appattempt_1702967272525_0001_000002 exited with…...
长短期记忆(LSTM)神经网络-多输入分类
目录 一、程序及算法内容介绍: 基本内容: 亮点与优势: 二、实际运行效果: 三、部分程序: 四、完整程序下载: 一、程序及算法内容介绍: 基本内容: 本代码基于Matlab平台编译&am…...

开启创意之旅:免费、开源的噪波贴图(noise texture)生成网站——noisecreater.com详细介绍
在当今数字创意领域,噪波贴图(Noise Texture)是游戏渲染、游戏开发、美术设计以及影视制作等行业不可或缺的艺术素材之一。为了满足广大创作者的需求,noisecreater.com应运而生,成为一款免费、开源的噪波贴图生成工具。…...
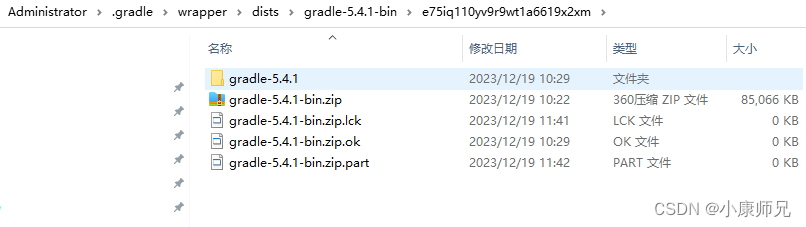
Android Studio问题解决:Gradle Download 下载超时 Connect reset
文章目录 一、遇到问题二、解决办法 一、遇到问题 Gradle Download下载超时Sync了很多次,一直失败 二、解决办法 手动通过gradle网站下载 https://gradle.org/releases/可能也会出现超时,最好开个VPN软件会比较快。 下载好的软件,放到本机的…...

【Python百宝箱】云上翱翔:Python编程者的AWS奇妙之旅
雲端箴言:用Python主持AWS管理交響樂 前言 随着云计算的普及,AWS(Amazon Web Services)成为了许多组织和开发者首选的云服务提供商。作为Python工程师,深入了解AWS管理工具和库对于高效利用云资源至关重要。本文将引…...
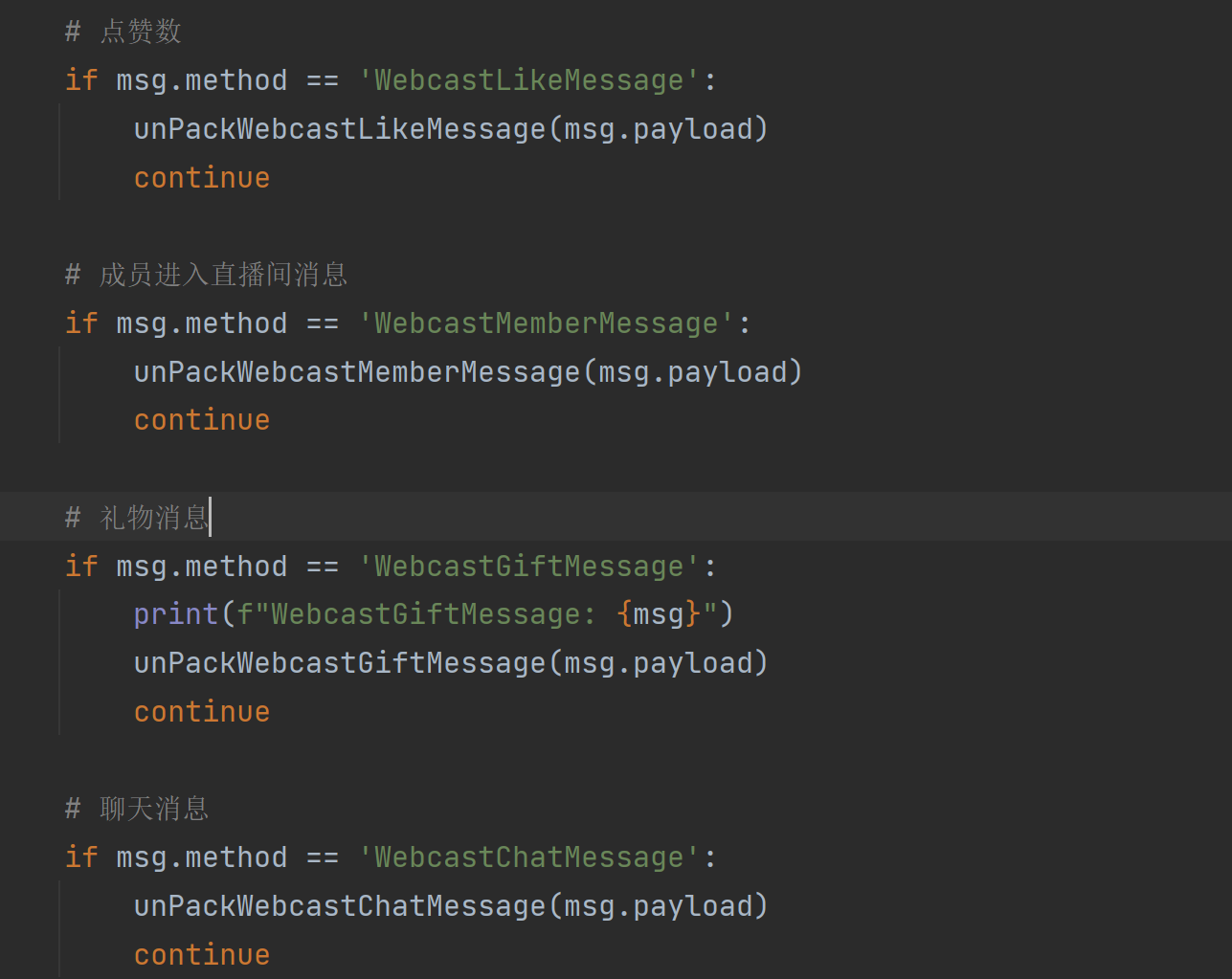
抖音直播间websocket礼物和弹幕消息推送可能出现重复的情况,解决办法
在抖音直播间里,通过websocket收到的礼物消息数据格式如下: {common: {method: WebcastGiftMessage,msgId: 7283420150152942632,roomId: 7283413007005207308,createTime: 1695803662805,isShowMsg: True,describe: 莎***:送给主播 1个入团卡,priority…...

【设计模式--行为型--访问者模式】
设计模式--行为型--访问者模式 访问者模式定义结构案例优缺点使用场景扩展分派动态分派静态分派双分派 访问者模式 定义 封装一些作用于某种数据结构中的各元素的操作,它可以在不改变这个数据结构的前提下定义作用于这些元素的新操作。 结构 抽象访问者角色&…...
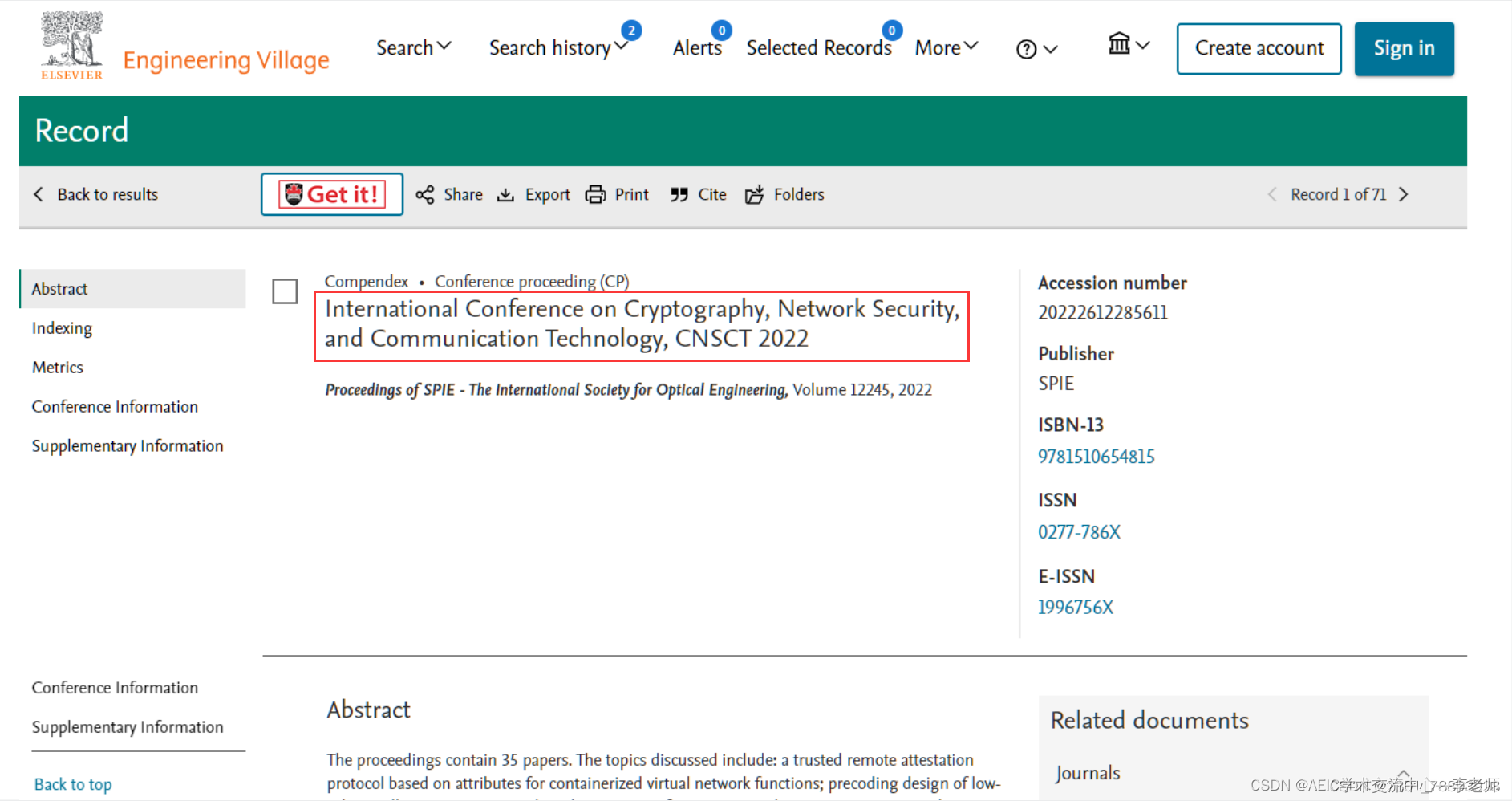
[最后一个月征稿、ACM独立出版】第三届密码学、网络安全和通信技术国际会议(CNSCT 2024)
第三届密码学、网络安全和通信技术国际会议(CNSCT 2024) 2024 3rd International Conference on Cryptography, Network Security and Communication Technology 一、大会简介 随着互联网和网络应用的不断发展,网络安全在计算机科学中的地…...

android —— PopupWindow
一、常用方法: 1、设置显示的位置 // 一个参数 popupWindow.showAsDropDown(v); //参数1: popupWindow关联的view // 参数2和3:相对于关联控件的偏移量popupWindow.showAsDropDown(View anchor, int xoff, int yoff)2、是否会获取焦点 popupWindow.se…...
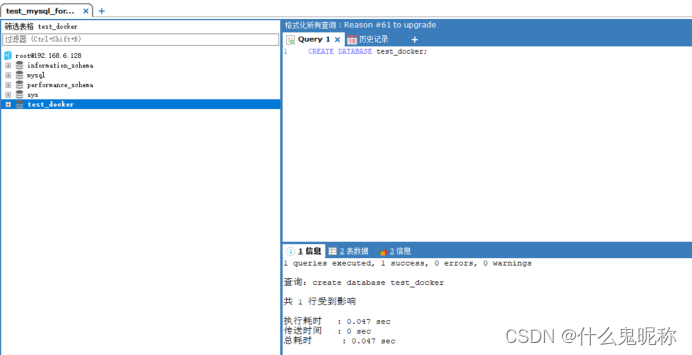
mysql部署 --(docker)
先查找MySQL 镜像 Docker search mysql ; 拉取mysql镜像,默认拉取最新的; 创建mysql容器,-p 代表端口映射,格式为 宿主机端口:容器运行端口 -e 代表添加环境变量,MYSQL_ROOT_PASSWORD是root用户…...

基于多智能体系统一致性算法的电力系统分布式经济调度策略MATLAB程序
微❤关注“电气仔推送”获得资料(专享优惠) 参考文献: 主要内容: 应用多智能体系统中的一致性算法,以发电机组的增量成本和柔性负荷的增量效益作为一致性变量,设计一种用于电力系统经济调度的算法&#x…...
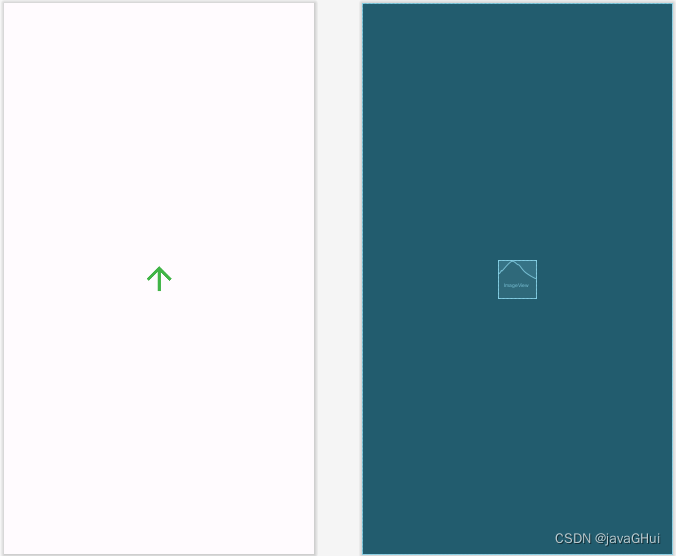
Android : SensorManager 传感器入门 简单应用
功能介绍:转动手机 图片跟着旋转 界面: activity_main.xml <?xml version"1.0" encoding"utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android"http://schemas.android.com/apk/res/andr…...

《点云处理》 点云去噪
前言 通常从传感器(3D相机、雷达)中获取到的点云存在噪点(杂点、离群点、孤岛点等各种叫法)。噪点产生的原因有不同,可能是扫描到了不想要扫描的物体,可能是待测工件表面反光形成的,也可能是相…...
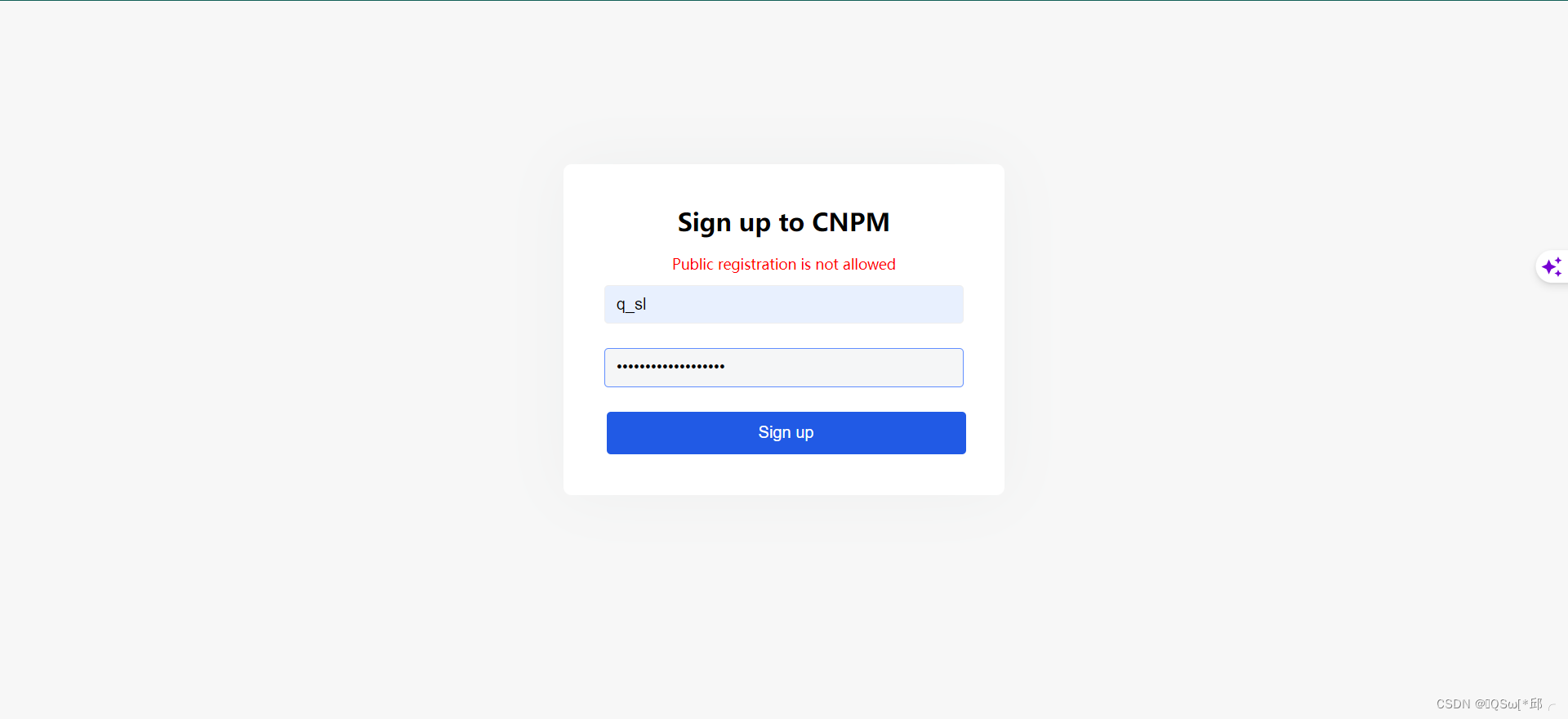
npm login报错:Public registration is not allowed
npm login报错:Public registration is not allowed 1.出现场景2.解决 1.出现场景 npm login登录时,出现 2.解决 将自己的npm镜像源改为npm的https://registry.npmjs.org/这个,解决!...

OpenHarmony 启动流程优化
目前rk3568的开机时间有21s,统计的是关机后从按下 power 按键到显示锁屏的时间,当对openharmony的系统进行了裁剪子系统,系统app,禁用部分服务后发现开机时间仅仅提高到了20.94s 优化微乎其微。在对init进程的log进行分析并解决其…...

解决腾讯云CentOS 6硬盘空间不足问题:从快照到数据迁移
引言: 随着数据的不断增加,服务器硬盘空间不足变成了许多运维人员必须面对的问题。此主机运行了httpd(apache服务),提供对外web访问服务,web资源挂载在**/data/wwwroot目录下,http日志存放在/data/wwwlogs目录下&…...

org.slf4j日志组件实现日志功能
slf4j 全称是Simple Logging Facade for Java。facade是一种设计模式。 slf4j 是一个抽象程度更高的日志组件,本身并不提供实际的日志功能。实际的日志功能是通过log4j等日志组件实现,而使用者只需要关心 slf4j 给出的API。 slf4j 仅仅是一个为Java程序提…...
)
保姆级教程:用COMSOL 5.6搞定房间声学模态分析(附网格划分避坑指南)
保姆级教程:用COMSOL 5.6实现高精度房间声学模态分析 当你第一次尝试用COMSOL分析房间的声学特性时,是否曾被复杂的参数设置和网格划分搞得晕头转向?本文将带你一步步攻克声学模态分析中最关键的环节——特征频率求解与网格优化。不同于泛泛而…...

深入GORM源码:手把手教你为自定义字段打造专属‘Clause钩子’
深入GORM源码:手把手教你为自定义字段打造专属‘Clause钩子’ 在当今快速迭代的业务场景中,数据库操作早已不再是简单的CRUD。当我们面对复杂的状态流转、多租户隔离或敏感数据加密时,往往需要在数据持久化层植入特定的业务逻辑。GORM作为Go生…...

2026最权威的六大AI写作工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术研究链路里,DeepSeek能够为论文撰写给予全流程辅助支持,从梳理…...

Gemini应用商店曝光量暴跌?3步诊断+5个隐藏算法漏洞修复指南
更多请点击: https://intelliparadigm.com 第一章:Gemini应用商店曝光量暴跌?3步诊断5个隐藏算法漏洞修复指南 近期大量开发者反馈 Gemini 应用商店自然曝光量断崖式下跌,部分应用 7 日内曝光下降超 68%,但后台数据未…...
原理与应用全解析)
时序电路的心脏:钟控触发器(RS/D/JK/T)原理与应用全解析
1. 时序电路的心脏:为什么需要钟控触发器? 第一次接触数字电路时,我被各种触发器绕得头晕。直到老师用"心脏"来比喻钟控触发器,才恍然大悟——就像心脏通过规律跳动为全身供血一样,钟控触发器通过时钟脉冲协…...

3步解锁网易云音乐NCM加密文件:ncmdumpGUI图形化工具完全指南
3步解锁网易云音乐NCM加密文件:ncmdumpGUI图形化工具完全指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲…...

苹果为何拒绝TD-SCDMA特供版iPhone?复盘技术标准与市场时机的战略博弈
1. 项目概述:一场关于苹果与中国移动的世纪猜想2012年的科技圈,空气中弥漫着一股躁动与期待。几乎所有的行业分析师和手机发烧友都在讨论同一个话题:苹果公司是否会为了全球最大的移动运营商——中国移动,专门推出一款支持TD-SCDM…...

Windows上快速安装APK的终极指南:APK Installer完整使用教程
Windows上快速安装APK的终极指南:APK Installer完整使用教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经需要在Windows电脑上运行Android应用…...

AI智能体安全策略引擎:AgentEnforcer框架设计与实战应用
1. 项目概述:一个为AI智能体量身定制的“行为守门员” 最近在折腾AI智能体(Agent)的开发,尤其是在构建那些需要自主执行任务、与外部API交互的复杂系统时,一个核心痛点总是挥之不去: 如何确保智能体的行为…...
)
手把手教你:在RT-Thread上用STM32驱动0.96寸OLED显示动态二维码(附完整源码)
基于RT-Thread的STM32动态二维码显示系统开发实战 在智能门锁、工业设备配网等物联网场景中,二维码作为信息载体正发挥着越来越重要的作用。本文将完整呈现如何在RT-Thread操作系统上,通过STM32驱动0.96寸OLED实现动态二维码显示功能。不同于简单的功能演…...