hive企业级调优策略之分组聚合优化
测试用表准备
hive企业级调优策略测试数据
(阿里网盘下载链接):https://www.alipan.com/s/xsqK6971Mrs
订单表(2000w条数据)
表结构
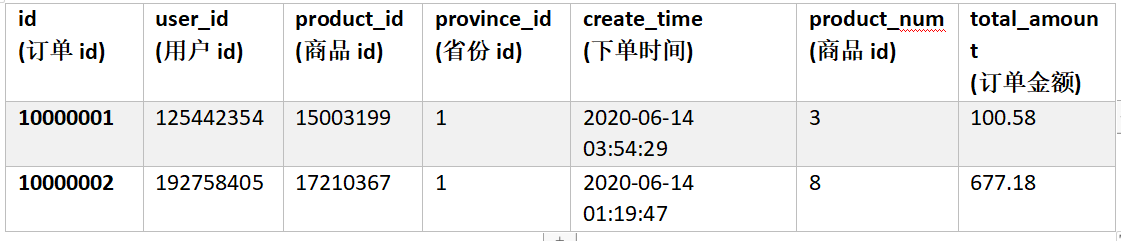
建表语句
drop table if exists order_detail;
create table order_detail(id string comment '订单id',user_id string comment '用户id',product_id string comment '商品id',province_id string comment '省份id',create_time string comment '下单时间',product_num int comment '商品件数',total_amount decimal(16, 2) comment '下单金额'
)comment '订单表'partitioned by (dt string)row format delimited fields terminated by '\t'
数据装载
将order_detail.txt文件上传到HDFS,并执行以下导入语句。
注:文件较大,请耐心等待。
load data inpath 'hdfs://flinkv1:8020/input/order_detail.txt' overwrite into table order_detail partition(dt='2020-06-14');
支付表(600w条数据)
表结构

建表语句
drop table if exists payment_detail;
create table payment_detail(id string comment '支付id',order_detail_id string comment '订单明细id',user_id string comment '用户id',payment_time string comment '支付时间',total_amount decimal(16, 2) comment '支付金额'
)
partitioned by (dt string)
row format delimited fields terminated by '\t';
数据装载
将payment_detail.txt文件上传HDFS,并执行以下导入语句。
注:文件较大,请耐心等待。
load data inpath 'hdfs://flinkv1:8020/input/payment_detail.txt' overwrite into table payment_detail partition(dt='2020-06-14');商品信息表(100w条数据)
表结构

建表语句
drop table if exists product_info;
create table product_info(id string comment '商品id',product_name string comment '商品名称',price decimal(16, 2) comment '价格',category_id string comment '分类id'
)
row format delimited fields terminated by '\t';
数据装载
将product_info.txt文件上传到HDFS,并执行以下导入语句。
load data local inpath '/opt/module/hive/datas/product_info.txt' overwrite into table product_info;
省份信息表(34条数据)
表结构

建表语句
drop table if exists province_info;
create table province_info(id string comment '省份id',province_name string comment '省份名称'
)
row format delimited fields terminated by '\t';
数据装载
将province_info.txt文件上传到HDFS,并执行以下导入语句。
load data inpath 'hdfs://flinkv1:8020/input/province_info.txt' overwrite into table province_info;
优化说明
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
Hive对分组聚合的优化主要围绕着减少Shuffle数据量进行,具体做法是map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
map-side 聚合相关的参数如下:
启用map-side聚合
set hive.map.aggr=true;
用于检测源表数据是否适合进行map-side聚合,根据设置的比例系数进行检测,如果设置为1将不在进行检测,所有数据都进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,例如根据主键ID进行分组,那么map端即时聚合也没有作用,反而多此一举浪费资源,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
–用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
如果统计数据远大于分组值(例如100000条数据,计算每个省份的条数,省份可以确认34个,那么统计条数远大于分组值)我们可以直接把检测比例系数设置为1,检测源表数据设置为0;免去检测直接进行map-side聚合。
set hive.map.aggr.hash.min.reduction=1;
set hive.groupby.mapaggr.checkinterval=1;
map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。(默认不需要调整,出现问题在进行调整)
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
优化案例
(1)示例SQL
selectprovince_id,count(*)
from order_detail
group by province_id;
关闭map-side优化:
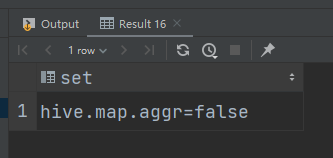

(2)优化前
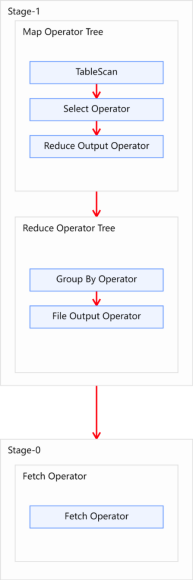
未经优化的分组聚合,执行计划如下图所示:
(3)优化思路
可以考虑开启map-side聚合,配置以下参数:
–启用map-side聚合,默认是true
set hive.map.aggr=true;
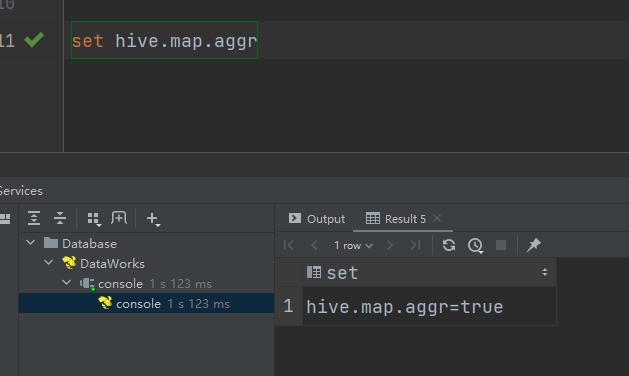
用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=1;
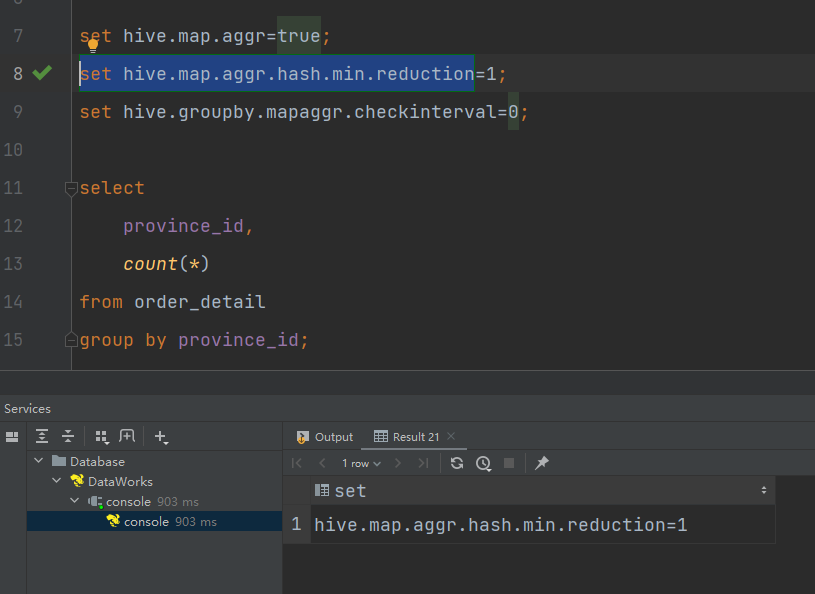
–用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=0;
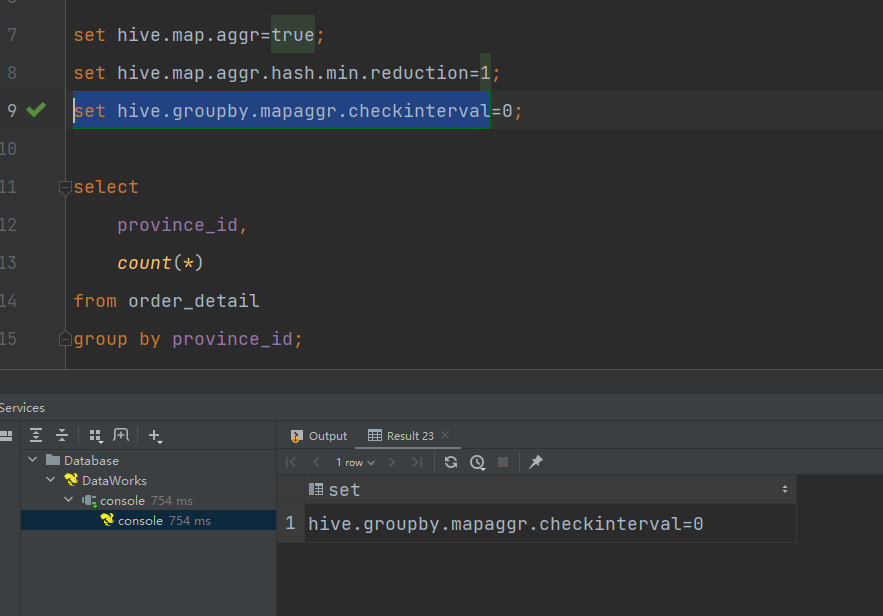
–map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
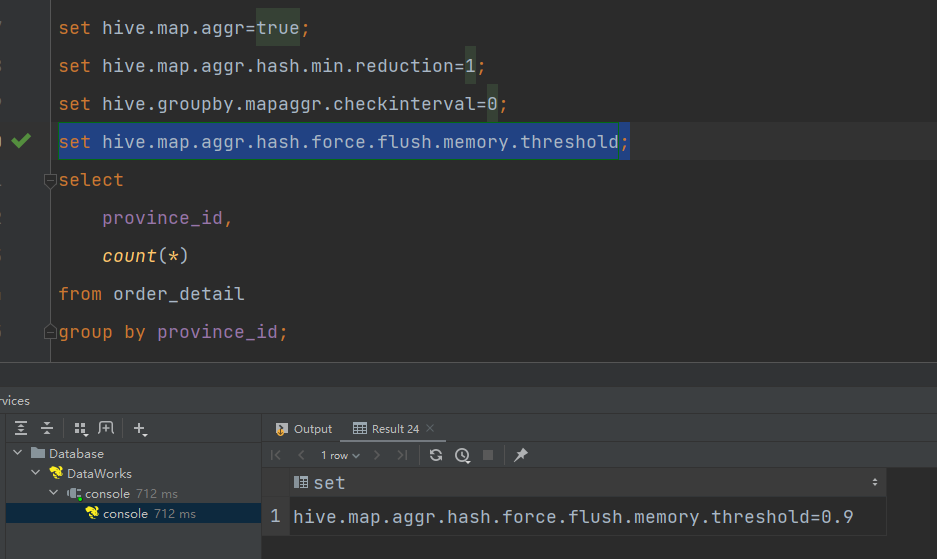
再次执行,耗时显而易见减少。

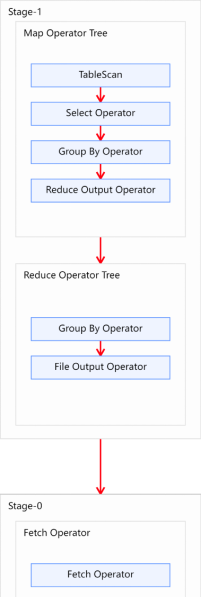
优化后的执行计划如图所示:
相关文章:
hive企业级调优策略之分组聚合优化
测试用表准备 hive企业级调优策略测试数据 (阿里网盘下载链接):https://www.alipan.com/s/xsqK6971Mrs 订单表(2000w条数据) 表结构 建表语句 drop table if exists order_detail; create table order_detail(id string comment 订单id,user_id …...

英码科技受邀参加2023计算产业生态大会,分享智慧轨道交通创新解决方案
12月13-14日,“凝心聚力,共赢计算新时代”——2023计算产业生态大会在北京香格里拉饭店成功举办。英码科技受邀参加行业数字化分论坛活动,市场总监李甘来先生现场发表了题为《AI哨兵,为铁路安全运营站好第一道岗》的精彩主题演讲&…...

【openssl】Linux升级openssl-1.0.1到1.1.1
文章目录 前言一、openssl是什么?二、使用步骤1.下载2.编译安装3.一些问题 总结 前言 记录一次openssl的升级,1.0.1升级到1.1.1 一、openssl是什么? OpenSSL是一个开源的加密工具包,广泛用于安全套接层(SSLÿ…...

美国联邦机动车安全标准-FMVSS
FMVSS标准介绍: FMVSS是美国《联邦机动车安全标准》,由美国运输部下属的国家公路交通安全管理局(简称NHTSA)具体负责制定并实施。是美国联邦政府针对机动车制定的安全标准,旨在提高机动车的安全性能,减少交通事故中的人员伤亡。F…...
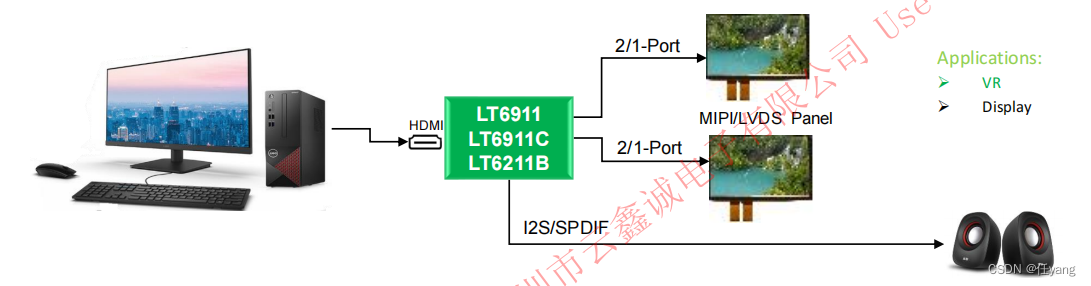
龙迅LT6211B,HDMI1.4转LVDS,应用于AR/VR市场
产品描述 LT6211B 是一款用于 VR/ 显示应用的高性能 HDMI1.4 至 LVDS 芯片。 对于 LVDS 输出,LT6211B 可配置为单端口、双端口或四端口。对于2D视频流,同一视频流可以映射到两个单独的面板,对于3D视频格式,左侧数据可以发送到一个…...

解决docker拉取镜像错误 missing signature key 问题
核心原因:本地docker版本过低,需要: 1. 彻底卸载本地docker文件 2. 配置yum 镜像文件, 重新安装最新版本 相信教程可参考: CentOS安装Docker(超详细)_centos 安装docker-CSDN博客...

倒计数器:CountDownLatch
CountDownLatch 是 Java 中用于多线程编程的一个同步工具。 它允许一个或多个线程等待其他线程执行完特定操作后再继续执行。 CountDownLatch 通过一个计数器来实现, 该计数器初始化为一个正整数,每当一个线程完成了指定操作,计数器就会减一。…...
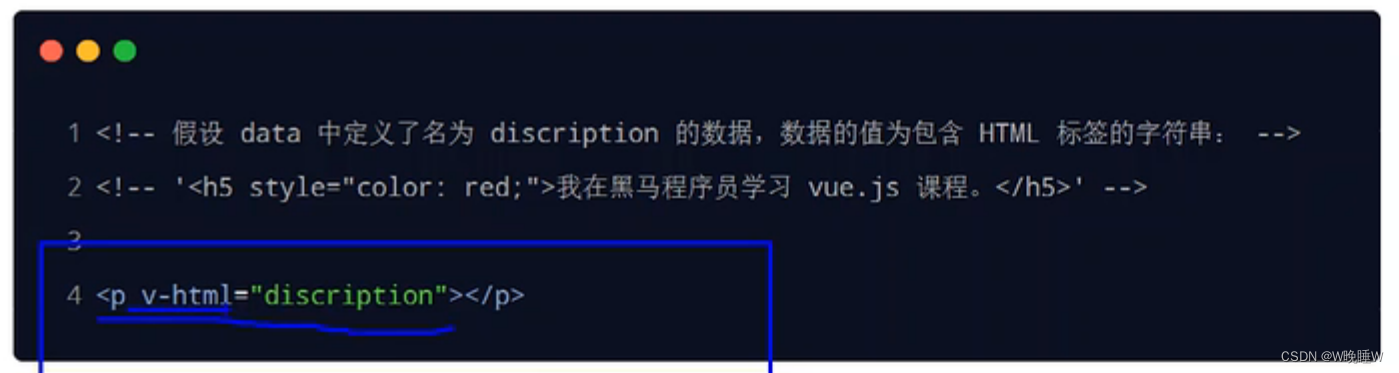
vue内容渲染
内容渲染指令用来辅助开发者渲染DOM元素的文本内容。常用的内容渲染指令有3个 1.v-text 缺点:会覆盖元素内部原有的内容 2.{{}}:插值表达式在实际开发中用的最多,只是内容的占位符,不会覆盖内容 3.v-html:可以把带有标…...
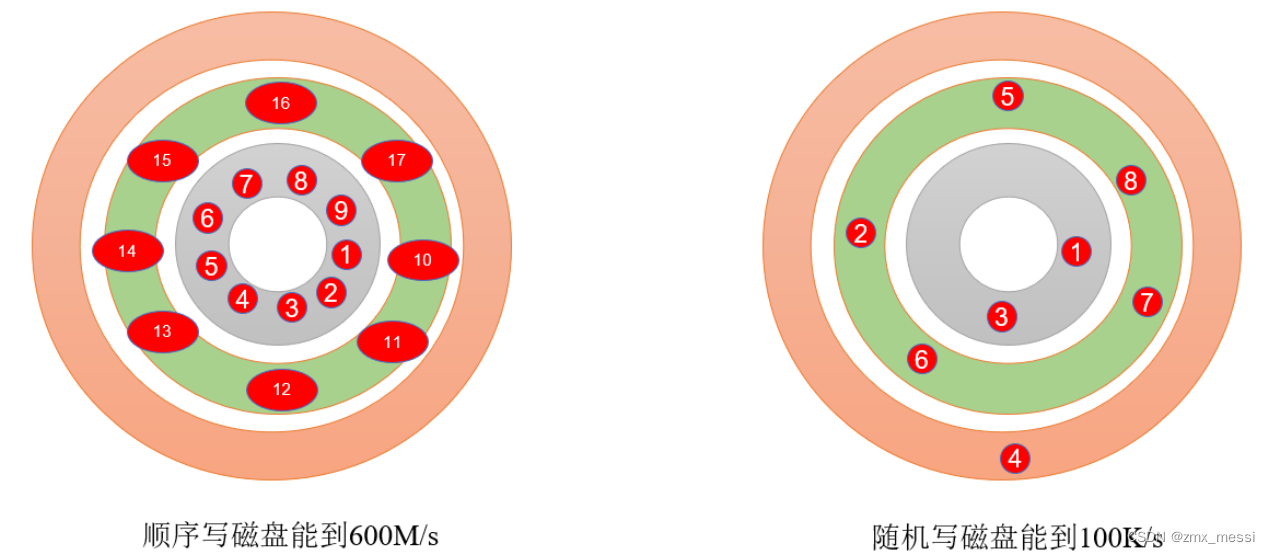
Kafka为什么能高效读写数据
1)Kafka 本身是分布式集群,可以采用分区技术,并行度高(生产消费方并行度高); 2)读数据采用稀疏索引,可以快速定位要消费的数据; 3)顺序写磁盘; …...

Flink系列之:Table API Connectors之Debezium
Flink系列之:Table API Connectors之Debezium 一、Debezium二、依赖三、使用Debezium Format四、可用元数据五、Format参数六、重复的变更事件七、消费 Debezium Postgres Connector 产生的数据八、数据类型映射 一、Debezium Debezium 是一个 CDC(Chan…...

【Python基础】文件读写
文章目录 [toc]打开文件open()函数参数解析示例 文件路径绝对路径示例 相对路径示例 打开文件的模式常用模式 读文件示例 写文件示例 按行读写文件readline()示例 readlines()示例 writelines()示例 关闭文件示例finally语句示例 上下文管理器示例 自定义读写类示例 打开文件 …...
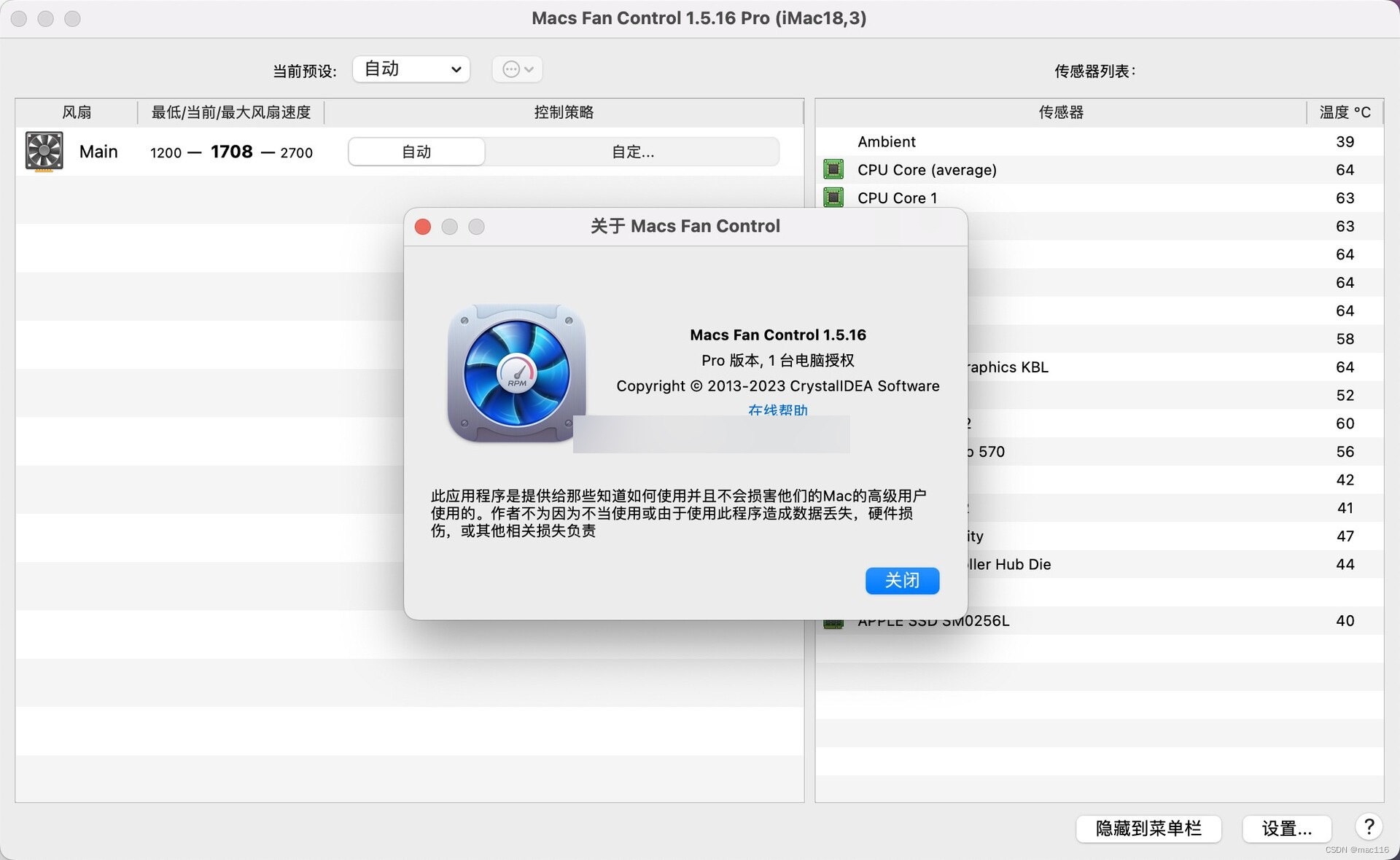
电脑风扇控制软件Macs Fan Control mac支持多个型号
Macs Fan Control mac是一款专门为 Mac 用户设计的软件,它可以帮助用户控制和监控 Mac 设备的风扇速度和温度。这款软件允许用户手动调整风扇速度,以提高设备的散热效果,减少过热造成的风险。 Macs Fan Control 可以在菜单栏上显示当前系统温…...
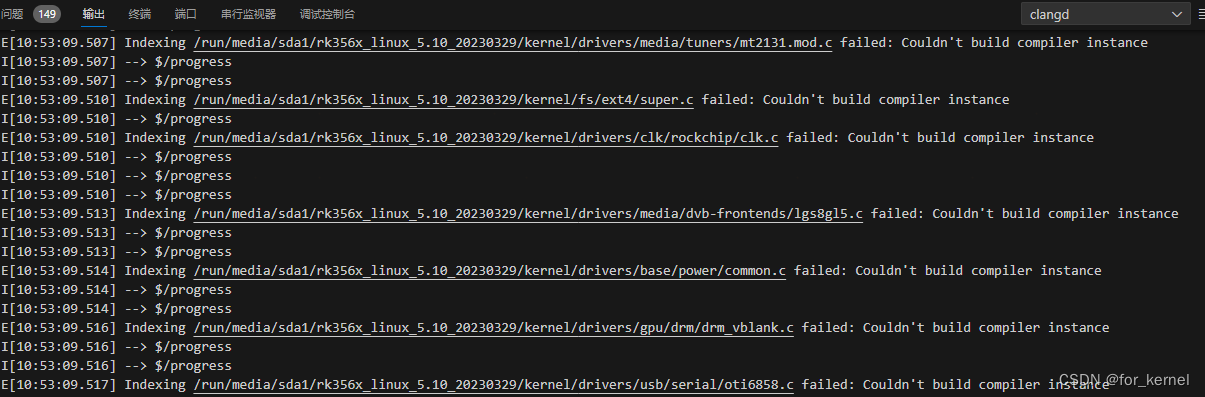
clangd:Couldn‘t build compiler instance
在使用vscode clangd 搭建RK3588 5.10版本linux内核代码开发环境时,使用bear生成 compile_commands.json时,clangd生成标签失败代码无法跳转,查看clangd日志,发现标签生成失败,失败原因:Couldnt build comp…...

Springboot启动出现Error to process server push response的解决方法
目录 前言1. 问题所示2. 原理分析3. 解决方法前言 注意,此篇博客只提供一种bug排查思路,毕竟每个项目引起的依赖包冲突都不一致! 1. 问题所示 启动Springboot的时候,5秒刷一次这个,大致如下: 2023-12-17 13:02:01.166 WARN 20196 --- [ main] o.s.boot.ac…...
P2P网络下分布式文件共享场景的测试
P2P网络介绍 P2P是Peer-to-Peer的缩写,“Peer”在英语里有“对等者、伙伴、对端”的意义。因此,从字面意思来看,P2P可以理解为对等网络。国内一些媒体将P2P翻译成“点对点”或者“端对端”,学术界则统一称为对等网络(Peer-to-Pee…...

计算机组成原理综合1
1、完整的计算机系统应包括______。D A. 运算器、存储器和控制器 B. 外部设备和主机 C. 主机和实用程序 D. 配套的硬件设备和软件系统 2、计算机系统中的存储器系统是指______。D A. RAM存储器 B. ROM存储器 C. 主存储器 …...

探秘 AJAX:让网页变得更智能的异步技术(下)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
CentOs7.x安装部署SeaTunnelWeb遇到的坑
CentOs7.x安装部署SeaTunnelWeb遇到的坑 文章目录 1. 环境2. SeaTunnel安装部署2.1下载安装包2.2 设置环境变量2.3 安装连接器插件2.4 拷贝jar包到lib下2.5 启动命令2.6 执行官方client提交任务demo 3. SeaTunnel-Web安装部署3.1 下载安装包3.2 初始化数据库脚本或修改配置appl…...

Netlink通信
前言 Netlink 是 Linux 内核与用户空间进程之间进行通信的机制之一,一种特殊的进程间通信(IPC) 。它是一种全双工、异步的通信机制,允许内核与用户空间之间传递消息。Netlink 主要用于内核模块与用户空间程序之间进行通信,也被一些用户空间工具用于与内…...

Python打造简单而强大的聊天机器人:详解与实例代码
更多资料获取 📚 个人网站:ipengtao.com 聊天机器人在现代应用中扮演着重要的角色,能够与用户进行自然语言交互。本篇博客将带领读者通过Python,使用自然语言处理库构建一个简单而强大的聊天机器人。我们将深入讨论处理用户输入、…...

Perplexity搜索响应延迟超800ms?揭秘底层向量重排序瓶颈及4种实时优化方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity搜索响应延迟超800ms?揭秘底层向量重排序瓶颈及4种实时优化方案 当Perplexity类RAG系统在高并发场景下出现端到端响应延迟突破800ms时,性能剖析常指向一个被低估的环节…...

Claude规格说明书生成器:提升大模型任务执行效率的工程化方法
1. 项目概述:一个为Claude模型定制的“规格说明书”生成器如果你和我一样,经常与Anthropic的Claude系列大语言模型打交道,无论是Claude 3 Opus、Sonnet还是Haiku,那你肯定遇到过这样的场景:你有一个复杂的任务…...

昇思大模型垂域模型
昇思 MindSpore 垂域模型是基于通用大模型基座 行业数据微调 领域技术增强构建的行业专用 AI 模型,依托 MindSpore Transformers 套件与昇腾硬件,在医疗、金融、电力、法律、工业等领域实现深度落地,兼顾通用能力与行业专业性,训…...

NAS如何变身创作利器?基于绿联DX4600 Pro自建图床与Typora无缝协作
1. 为什么选择NAS自建图床? 作为一名长期使用Markdown写作的内容创作者,我深知图片管理的重要性。过去三年我先后尝试过七牛云、又拍云等第三方图床服务,虽然费用不高(每月约5-10元),但经常遇到两个致命问题…...

VBS转VBE不只是加密:聊聊Scripting.Encoder的‘黑历史’与现代替代方案
VBS转VBE:从Scripting.Encoder的兴衰到现代脚本保护方案 在Windows脚本技术的发展长河中,VBScript(VBS)曾经是自动化任务和系统管理的重要工具。而与之相伴的VBE(VBScript Encoded)格式,则承载着…...

深入解析OpenWrt启动流程:从Bootloader到procd的完整指南
1. 项目概述与核心价值搞OpenWrt开发,尤其是涉及到系统定制、驱动适配或者故障排查,你迟早会碰到一个绕不开的核心问题:这玩意儿到底是怎么启动的?很多人可能觉得,启动流程嘛,不就是上电、加载内核、跑起来…...

实用指南:5分钟搞定Minecraft MASA模组中文汉化
实用指南:5分钟搞定Minecraft MASA模组中文汉化 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese MASA全家桶汉化包是专为Minecraft 1.21版本设计的专业本地化解决方案&#x…...

解决企业IT服务管理复杂性的iTop开源CMDB架构实践
解决企业IT服务管理复杂性的iTop开源CMDB架构实践 【免费下载链接】iTop A simple, web based CMDB & IT Service Management tool 项目地址: https://gitcode.com/gh_mirrors/it/iTop 在数字化转型时代,企业面临IT配置信息分散、工单流转低效、资产跟踪…...

2025最权威的十大AI科研工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 学术研讨范畴正在历经深度的变动,人工智能论文工具现身,极大地提高了…...

从CLIP到多模态:对比学习驱动的视觉-语言模型演进与实战
1. 对比学习:CLIP的基石与多模态革命 我第一次接触CLIP模型是在2021年初,当时OpenAI发布的这篇论文彻底颠覆了我对视觉模型训练方式的认知。传统计算机视觉任务总是离不开人工标注的海量数据,而CLIP却另辟蹊径,用自然语言作为监督…...