scrapy快加构造并发送请求
scrapy数据建模与请求
学习目标:
- 应用 在scrapy项目中进行建模
- 应用 构造Request对象,并发送请求
- 应用 利用meta参数在不同的解析函数中传递数据
1. 数据建模
通常在做项目的过程中,在items.py中进行数据建模
1.1 为什么建模
- 定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查
- 配合注释一起可以清晰的知道要抓取哪些字段,没有定义的字段不能抓取,在目标字段少的时候可以使用字典代替
- 使用scrapy的一些特定组件需要Item做支持,如scrapy的ImagesPipeline管道类,百度搜索了解更多
1.2 如何建模
在items.py文件中定义要提取的字段:
# Define here the models for your scraped items
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy
class DoubanItem(scrapy.Item):# define the fields for your item here like:name = scrapy.Field() # 名字content = scrapy.Field() # 内容link = scrapy.Field() # 链接txt = scrapy.Field() #详情介绍
1.3 如何使用模板类
模板类定义以后需要在爬虫中导入并且实例化,之后的使用方法和使用字典相同
job.py:
from myspider.items import MyspiderItem # 导入Item,注意路径
...def parse(self, response)item = MyspiderItem() # 实例化后可直接使用item['name'] = node.xpath('./h3/text()').extract_first()item['title'] = node.xpath('./h4/text()').extract_first()item['desc'] = node.xpath('./p/text()').extract_first()print(item)
注意:
- from myspider.items import MyspiderItem这一行代码中 注意item的正确导入路径,忽略pycharm标记的错误
- python中的导入路径要诀:从哪里开始运行,就从哪里开始导入
1.4 开发流程总结
- 创建项目
scrapy startproject 项目名 - 明确目标
在items.py文件中进行建模 - 创建爬虫
3.1 创建爬虫
scrapy genspider 爬虫名 允许的域
3.2 完成爬虫
修改start_urls
检查修改allowed_domains
编写解析方法 - 保存数据
在pipelines.py文件中定义对数据处理的管道
在settings.py文件中注册启用管道
2. 翻页请求的思路
对于要提取如下图中所有页面上的数据该怎么办?

回顾requests模块是如何实现翻页请求的:
- 找到下一页的URL地址
- 调用requests.get(url)
scrapy实现翻页的思路:
- 找到下一页的url地址
- 构造url地址的请求对象,传递给引擎
3. 构造Request对象,并发送请求
3.1 实现方法
- 确定url地址
- 构造请求,scrapy.Request(url,callback)
- callback:指定解析函数名称,表示该请求返回的响应使用哪一个函数进行解析
- 把请求交给引擎:yield scrapy.Request(url,callback)
3.2 网易招聘爬虫
通过爬取豆瓣新书速递的页面信息,学习如何实现翻页请求
地址: https://book.douban.com/latest?icn=index-latestbook-all
思路分析:
- 获取首页的数据
- 寻找下一页的地址,进行翻页,获取数据
注意:
- 可以在settings中设置ROBOTS协议
# False表示忽略网站的robots.txt协议,默认为True
ROBOTSTXT_OBEY = False
- 可以在settings中设置User-Agent:
# scrapy发送的每一个请求的默认UA都是设置的这个User-Agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
scrapy.Request的更多参数
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False])
参数解释
- 中括号里的参数为可选参数
- callback:表示当前的url的响应交给哪个函数去处理
- meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
- dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
- method:指定POST或GET请求
- headers:接收一个字典,其中不包括cookies
- cookies:接收一个字典,专门放置cookies
- body:接收json字符串,为POST的数据,发送payload_post请求时使用(在下一章节中会介绍post请求)
4. meta参数的使用
meta的作用:meta可以实现数据在不同的解析函数中的传递
在爬虫文件的parse方法中,提取详情页增加之前callback指定的parse_detail函数:
def parse(self,response):...yield scrapy.Request(detail_url, callback=self.parse_detail,meta={"item":item})
...def parse_detail(self,response):#获取之前传入的itemitem = resposne.meta["item"]
特别注意
- meta参数是一个字典
- meta字典中有一个固定的键
proxy,表示代理ip,关于代理ip的使用我们将在scrapy的下载中间件的学习中进行介绍
小结
- 完善并使用Item数据类:
- 在items.py中完善要爬取的字段
- 在爬虫文件中先导入Item
- 实力化Item对象后,像字典一样直接使用
- 构造Request对象,并发送请求:
- 导入scrapy.Request类
- 在解析函数中提取url
- yield scrapy.Request(url, callback=self.parse_detail, meta={})
- 利用meta参数在不同的解析函数中传递数据:
- 通过前一个解析函数 yield scrapy.Request(url, callback=self.xxx, meta={}) 来传递meta
- 在self.xxx函数中 response.meta.get(‘key’, ‘’) 或 response.meta[‘key’] 的方式取出传递的数据
相关文章:
scrapy快加构造并发送请求
scrapy数据建模与请求 学习目标: 应用 在scrapy项目中进行建模应用 构造Request对象,并发送请求应用 利用meta参数在不同的解析函数中传递数据 1. 数据建模 通常在做项目的过程中,在items.py中进行数据建模 1.1 为什么建模 定义item即提前…...

【C++】谈谈深拷贝与浅拷贝
目录 一、浅拷贝 1.定义 2.示例 3.问题 二、深拷贝 1.定义 2.示例 3.优点 三、考虑场景 浅拷贝的考虑 1.性能要求 2.简单地数据结构 3.资源管理 深拷贝的考虑 1.动态内存分配 2.复杂数据结构 3.资源管理 总结 一、浅拷贝 1.定义 浅拷贝是指对对象进行复制时…...

电商API接口如何驱动业务:代码演示与解析
随着电子商务的飞速发展,电商平台的业务逻辑日益复杂,涉及的模块和功能也越来越多。在这个过程中,电商API接口扮演着至关重要的角色。通过API接口,不同的业务模块可以相互通信,实现数据和服务的共享,提高业…...

秋招总结_就业
2020秋招总结 【前言】 以下内容是写给研二学弟学妹们的秋招总结,研一的师弟师妹们如有需要,也可看看。先说一下我为什么要写这个总结: 1、时代在变化,社会在发展,一届有必要给下一届讲一些经验。 2、我平时和你们…...

基于查表法的水流量算法设计与实现
写在前面 本文分享的是一种基于查表法的水流量的算法方案设计与实现,算法简单易懂,主要面向初学者,有两个目的:一是给初学者一些算法设计的思路引导;二是引导初学者学习怎样用C语言编程实现。 一、设计需求 基于“19…...

Python:复制、移动文件到指定文件夹
需要考虑的问题: 指定文件夹是否存在,不存在则创建在指定文件夹中是否存在同名文件,是覆盖还是另存为 import os import shutil import tracebackdef copyfile(srcfile, dstpath, replaceFalse):"""复制文件到指定文件夹par…...
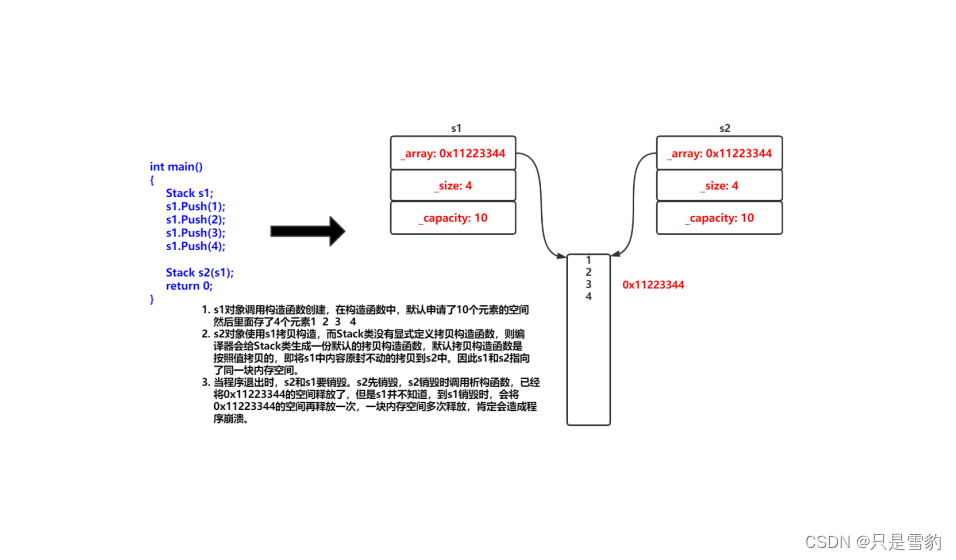
类和对象(中篇)
类的六个默认成员函数 如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数。 默认成员函数: 用户没有显式实现,编译器会…...
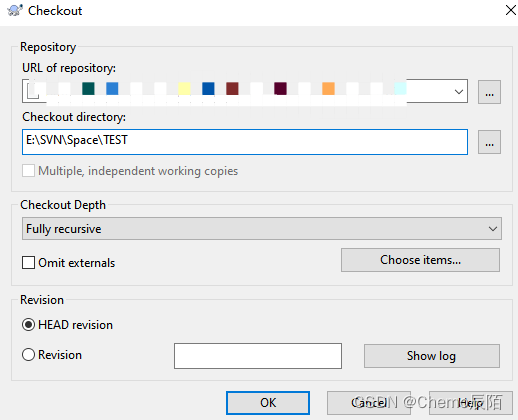
简单几步完成SVN的安装
介绍以及特点 SVN:Subversion,即版本控制系统。 1.代码版本管理工具 2.查看所有的修改记录 3.恢复到任何历史版本和已经删除的文件 4.使用简单上手快,企业安全必备 下载安装 SVN的安装分为两部分,第一部分是服务端安装&…...
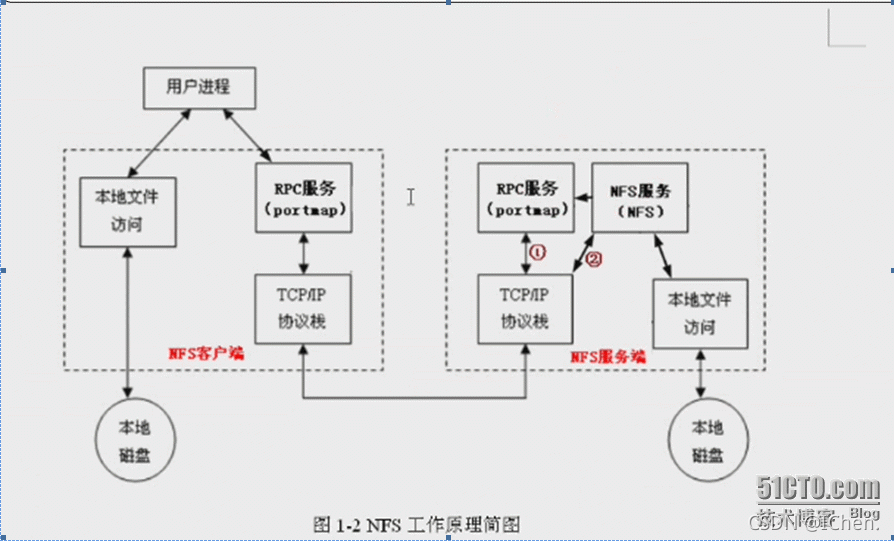
NFS原理详解
一、NFS介绍 1)什么是NFS 它的主要功能是通过网络让不同的机器系统之间可以彼此共享文件和目录。 NFS服务器可以允许NFS客户端将远端NFS服务器端的共享目录挂载到本地的NFS客户端中。 在本地的NFS客户端的机器看来,NFS服务器端共享的目录就好像自己的磁…...
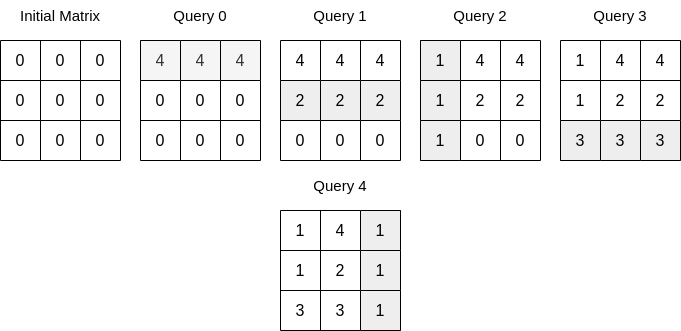
查询后矩阵的和
说在前面 🎈不知道大家对于算法的学习是一个怎样的心态呢?为了面试还是因为兴趣?不管是出于什么原因,算法学习需要持续保持。 问题描述 给你一个整数 n 和一个下标从 0 开始的 二维数组 queries ,其中 queries[i] [t…...

Flutter实现丝滑的滑动删除、移动排序等-Dismissible控件详解
文章目录 Dismissible 简介使用场景常用属性基本用法举例注意事项 Dismissible 简介 Dismissible 是 Flutter 中用于实现可滑动删除或拖拽操作的一个有用的小部件。主要用于在用户对列表项或任何其他可滑动的元素执行删除或拖动操作时,提供一种简便的实现方式。 使…...
JDK bug:ciObjectFactory::create_new_metadata:原因完全解析
文章目录 1、问题2.详细日志2.关键日志3.结论4.JDK:bug最终bug链接: 京东遇到过类似bug各位大佬如果有更详细的解答可以留言。 1、问题 服务不通,接口404,查看日志有一下截图,还有一个更详细的日志 2.详细日志 # #…...
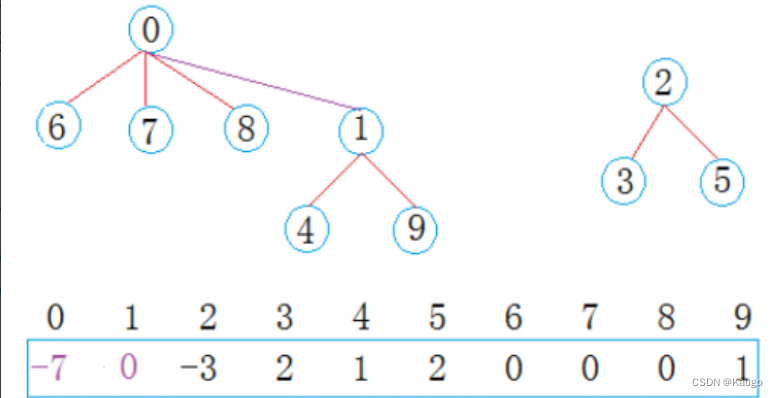
【数据结构】并查集的简单实现,合并,查找(C++)
文章目录 前言举例: 一、1.构造函数2.查找元素属于哪个集合FindRoot3.将两个集合归并成一个集合Union4.查找集合数量SetCount 二、源码 前言 需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规…...
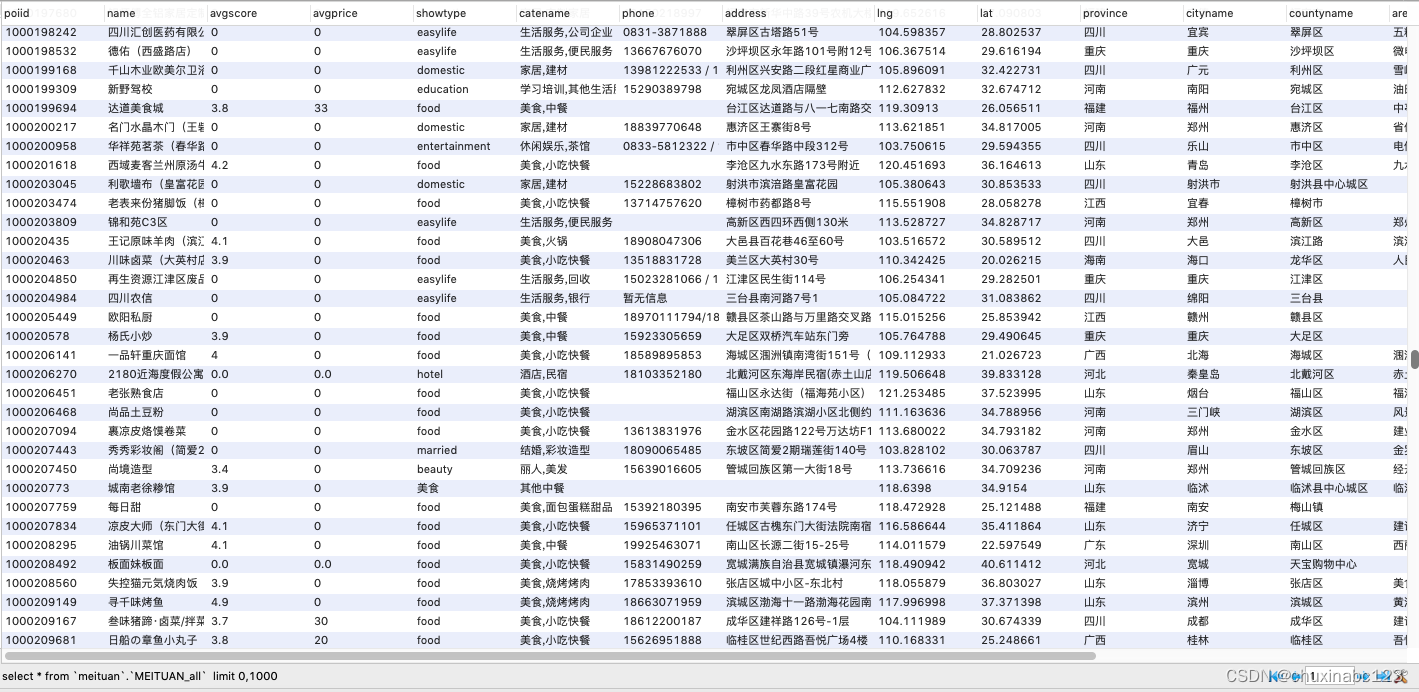
2023美团商家信息
2023美团商家电话、地址、经纬度、评分、均价、执照......

0155 - Java 数组
1 数组介绍 数组可以存放多个同一类型的数据。数组也是一种数据类型,是引用类型。 即:数(数据)组(一组)就是一组数据 2 数组的使用 2.1 使用方式一 2.2 使用方式二 3 数组使用注意事项和细节 数组是多个相同类型数据的组合,实现对这些数据…...

Java 语言有哪些特点
Java语言具有以下特点: 简单易学:Java语法相对简单,与C相比更容易上手。 面向对象:Java是一门纯粹的面向对象编程语言,支持封装、继承和多态等面向对象的特性。 平台无关性:Java程序可以在不同的操作系统…...

SAP 特殊采购类50简介----虚拟件
今天我们测试一下特殊类50,也就是我们常说的虚拟件。 虚拟物料是库存中实际不存在的物料清单(BOM)的子装配件,它用于简化物料清单。尽管虚拟物料出现在物料清单中,但生产订单显示制造虚拟物料所需的组件,而不是虚拟物料本身。 我们举个列子,生产的手机是有包装的,有盒子…...

C语言——内存函数的使用与模拟实现
大家好,我是残念,希望在你看完之后,能对你有所帮助,有什么不足请指正!共同学习交流 本文由:残念ing 原创CSDN首发,如需要转载请通知 个人主页:残念ing-CSDN博客,欢迎各位…...
)
Mysql索引事务(面试高频)
文章目录 目录 文章目录 前言 一 . 索引 1.1 概念 1.2 作用 1.3 使用场景 1.4 存储引擎 二 . 事务 2.1 事务的概念 2.2 事务四大特性 前言 大家好,今天给大家绍一下mysql索引和事务 一 . 索引 1.1 概念 索引是一种特殊的文件,包含着对数据表中的所有记录的引用指针…...

SpringCloudGateway 3.1.4版本 Netty内存泄漏问题解决
一、 产生的异常 当时是服务器访问不到服务了,上去一看,无法申请资源OutOfDirectMemoryError了,内存级别的东西让人一阵头大,赶紧在线下模拟, 1. 减少分配的堆外内存,打开Netty的监测工具等有助于复现的…...

告别拓展坞!实测Spacedesk无线投屏:Win10/Win11到iPad的延迟、画质与触控体验全解析
Spacedesk无线投屏实战评测:Win11与iPad Pro的协作新范式 当iPad Pro的Liquid视网膜显示屏遇上Windows系统的生产力工具,能否摆脱线材束缚实现无缝协作?Spacedesk这款免费无线投屏软件正在重新定义多屏工作场景。作为深度体验过各类投屏方案的…...

VSCode Mermaid Preview:面向技术团队的实时图表协作解决方案
VSCode Mermaid Preview:面向技术团队的实时图表协作解决方案 【免费下载链接】vscode-mermaid-preview Previews Mermaid diagrams 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-mermaid-preview 在技术文档编写、系统架构设计和项目规划过程中&…...

别让中文路径坑了你!FaceFusion在Windows和Mac上的完整环境配置与文件规范指南
别让中文路径坑了你!FaceFusion在Windows和Mac上的完整环境配置与文件规范指南 在数字创意领域,FaceFusion作为一款强大的AI换脸工具,正受到越来越多内容创作者的青睐。然而,许多用户在初次接触时往往会被一系列看似莫名其妙的错误…...

告别if/else地狱:从表驱动到设计模式的代码重构实战
1. 项目概述:从“屎山”到“优雅”的代码重构之旅“优雅地优化掉这些多余的if/else”,这几乎是每个有一定经验的开发者,在接手或维护一个项目时,内心最常响起的呐喊。我见过太多代码,它们最初可能只是几个简单的条件判…...
)
告别MainTest!用XML+CAPL在CANoe里做可视化勾选测试(附.can文件避坑指南)
告别MainTest!用XMLCAPL在CANoe里构建可视化勾选测试系统 在车载电子测试领域,CAPL脚本一直是工程师们的得力工具,但传统基于MainTest的测试架构存在明显局限——每次修改测试用例组合都需要重新编译脚本,这在快速迭代的开发环境中…...

为你的企业构建第一个 AI Agent Harness Engineering 的步骤
为你的企业构建第一个 AI Agent Harness Engineering 的步骤 1. 引入与连接:为什么你的Agent上线就“闯祸”? 1.1 真实场景:一个价值12万的Agent事故 2024年3月,国内某SaaS创业公司的客户成功团队上线了第一款AI Agent:原本的目标是让Agent自动回答80%的客户常见问题,自…...

2026年六大GEO公司排名竞争力横评及企业选型实操指南针
根据易观发布的《中国 GEO 行业发展报告 2026》显示,2026年国内 GEO 市场规模已达 30 亿元,在短短 3 年内实现了 35 倍的爆发式增长,超过 68% 的中大型企业已将生成式引擎优化正式纳入年度预算。在当前由大模型驱动的信息分发范式下ÿ…...

无参考视频质量评估:AI如何在没有标准答案时评判视频画质
1. 项目概述:当AI成为视频的“质检员”在视频内容爆炸式增长的今天,我们每天都会接触到海量的视频流——从手机随手拍的短视频,到专业制作的影视剧,再到监控摄像头24小时不间断的记录。你有没有想过,这些视频的“画质”…...

联网搜索会污染大模型判断吗?——面向日常开发场景的工程化分析
文章目录联网搜索会污染大模型判断吗?——面向日常开发场景的工程化分析结论1. 先区分三种“污染”1.1 不是权重污染,而是上下文污染1.2 检索污染:搜索结果不等于可信依据1.3 指令污染:外部内容可能改变模型行为2. 为什么日常开发…...

从账单明细看 Taotoken 按 Token 计费模式带来的成本控制优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单明细看 Taotoken 按 Token 计费模式带来的成本控制优势 1. 成本感知的起点:账单明细结构 对于使用大模型 API 的…...