在国产GPU寒武纪MLU上快速上手Pytorch使用指南
本文旨在帮助Pytorch使用者快速上手使用寒武纪MLU。以代码块为主,文字尽可能简洁,许多部分对标NVIDIA CUDA。不正确的地方请留言更正。本文不定期更新。
文章目录
- 前言
- Cambricon PyTorch的Python包torch_mlu导入
- 将模型加载到MLU上model.to('mlu')
- 定义损失函数,然后将其拷贝至MLU
- 将数据从CPU拷贝到MLU设备
- 以mnist.py为例的训练代码demo
- 参考引用
前言
大背景:信创改造、信创国产化、GPU国产化。
为使PyTorch支持寒武纪MLU,寒武纪对机器学习框架PyTorch进行了部分定制。若要在寒武纪MLU上运行PyTorch,需要安装并使用寒武纪定制的 Cambricon PyTorch。
Cambricon PyTorch的Python包torch_mlu导入
Cambricon CATCH是寒武纪发布的一款Python包(包名torch_mlu),提供了在MLU设备上进行张量计算的能力。安装好Cambricon CATCH后,便可使用torch_mlu模块:
import torch # 需安装Cambricon PyTorch
import torch_mlu # 动态扩展MLU后端
附 Cambricon PyTorch源码编译安装
导入 torch 和 torch_mlu 后可以测试在MLU上完成加法运算:
t0 = torch.randn(2, 2, device='mlu') # 在MLU设备上生成Tensor
t1 = torch.randn(2, 2, device='mlu')
result = t0 + t1 # 在MLU设备上完成加法运算
将模型加载到MLU上model.to(‘mlu’)
以ResNet18为例,将模型加载到MLU上用 model.to('mlu'),对标cuda的 model.to(device) :
# 定义模型
model = models.__dict__["resnet50"]()
# 将模型加载到MLU上。
mlu_model = model.to('mlu')
定义损失函数,然后将其拷贝至MLU
# 构造损失函数
criterion = nn.CrossEntropyLoss()
# 将损失函数拷贝到MLU上
criterion.to('mlu')
将数据从CPU拷贝到MLU设备
x = torch.randn(1000000, dtype=torch.float)
x_mlu = x.to(torch.device('mlu'), non_blocking=True)
以mnist.py为例的训练代码demo
import torch # 导入原生 PyTorch
import torch_mlu # 导入 Cambricon PyTorch
from torch.utils.data import DataLoader
from torchvision.datasets import mnist
from torch import nn
from torch import optim
from torchvision import transforms
from torch.optim.lr_scheduler import StepLR
import torch.nn.functional as F# 定义模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 32, 3, 1)self.conv2 = nn.Conv2d(32, 64, 3, 1)self.dropout1 = nn.Dropout2d(0.25)self.dropout2 = nn.Dropout2d(0.5)self.fc1 = nn.Linear(9216, 128)self.fc2 = nn.Linear(128, 10)# 定义前向计算def forward(self, x):x = self.conv1(x)x = F.relu(x)x = self.conv2(x)x = F.relu(x)x = F.max_pool2d(x, 2)x = self.dropout1(x)x = torch.flatten(x, 1)x = self.fc1(x)x = F.relu(x)x = self.dropout2(x)x = self.fc2(x)output = F.log_softmax(x, dim=1)return output# 模型训练
def train(model, train_data, optimizer, epoch):model = model.train()for batch_idx, (img, label) in enumerate(train_data):img = img.mlu()label = label.mlu()optimizer.zero_grad()out = model(img)loss = F.nll_loss(out, label)# 反向计算loss.backward()# 梯度更新optimizer.step()if batch_idx % 100 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(img), len(train_data.dataset),100. * batch_idx / len(train_data), loss.item()))# 模型推理
def validate(val_loader, model):test_loss = 0correct = 0model.eval()with torch.no_grad():for images, target in val_loader:images = images.mlu()target = target.mlu()output = model(images)test_loss += F.nll_loss(output, target, reduction='sum').item()pred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(val_loader.dataset)# 打印精度结果print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(val_loader.dataset),100. * correct / len(val_loader.dataset)))# 主函数
def main():# 定义预处理函数data_tf = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.1307],[0.3081])])# 获取 MNIST 数据集train_set = mnist.MNIST('./data', train=True, transform=data_tf, download=True)test_set = mnist.MNIST('./data', train=False, transform=data_tf, download=True)train_data = DataLoader(train_set, batch_size=64, shuffle=True)test_data = DataLoader(test_set, batch_size=1000, shuffle=False)net_orig = Net()# 模型拷贝到MLU设备net = net_orig.mlu()optimizer = optim.Adadelta(net.parameters(), 1)# 训练10个epochnums_epoch = 10# 训练完成后保存模型save_model = True# 学习率调整策略scheduler = StepLR(optimizer, step_size=1, gamma=0.7)for epoch in range(nums_epoch):train(net, train_data, optimizer, epoch)validate(test_data, net)scheduler.step()if save_model: # 将训练好的模型保存为model.pthif epoch == nums_epoch-1:checkpoint = {"state_dict":net.state_dict(), "optimizer":optimizer.state_dict(), "epoch": epoch}torch.save(checkpoint, 'model.pth')if __name__ == '__main__':main()
参考引用
寒武纪PyTorch v1.13.1用户手册
相关文章:

在国产GPU寒武纪MLU上快速上手Pytorch使用指南
本文旨在帮助Pytorch使用者快速上手使用寒武纪MLU。以代码块为主,文字尽可能简洁,许多部分对标NVIDIA CUDA。不正确的地方请留言更正。本文不定期更新。 文章目录 前言Cambricon PyTorch的Python包torch_mlu导入将模型加载到MLU上model.to(mlu)定义损失函…...

重生奇迹MU觉醒战士攻略
剑士连招技巧:生命之光:PK前起手式,增加血上限。 雷霆裂闪:眩晕住对手,剑士PK战士第一技能,雷霆裂闪是否使用好关系到胜负。 霹雳回旋斩:雷霆裂闪后可以选择用霹雳回旋斩跑出一定范围(因为对手…...

美颜技术详解:深入了解视频美颜SDK的工作机制
本文将深入探讨视频美颜SDK的工作机制,揭示其背后的科技奥秘和算法原理。 1.引言 视频美颜SDK作为一种集成到应用程序中的技术工具,通过先进的算法和图像处理技术,为用户提供令人印象深刻的实时美颜效果。 2.视频美颜SDK的基本工作原理 首…...
3D模型格式转换工具如何实现高性能数据转换?请看CAE系统开发实例!
客户背景 DP Technology是全球知名的CAM的供应商,在全球8个国家设有18个办事处。DP Technology提供的CAMESPRIT系统是一个用于数控编程,优化和仿真全方面的CAM系统。CAMESPRIT的客户来自多个行业,因此支持多种CAD工具和文件格式显得格外重…...
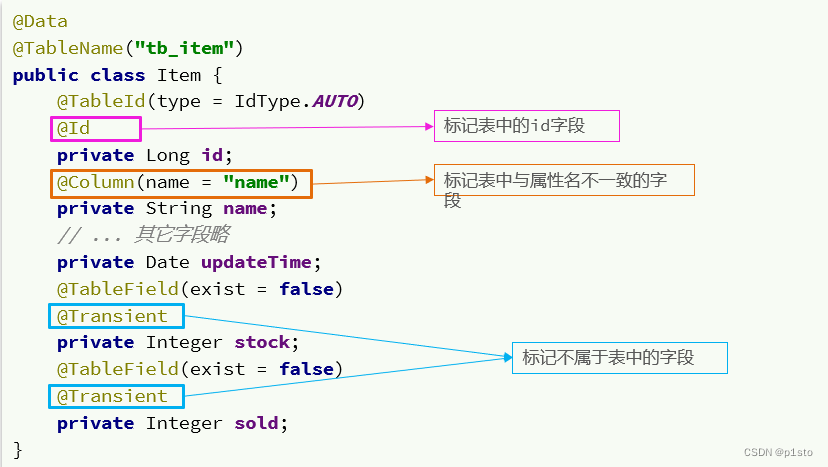
多级缓存:亿级流量的缓存方案
文章目录 一.多级缓存的引入二.JVM进程缓存三.Lua语法入门四.多级缓存1.OpenResty2.查询Tomcat3.Redis缓存预热4.查询Redis缓存5.Nginx本地缓存6.缓存同步 一.多级缓存的引入 传统缓存的问题 传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未…...
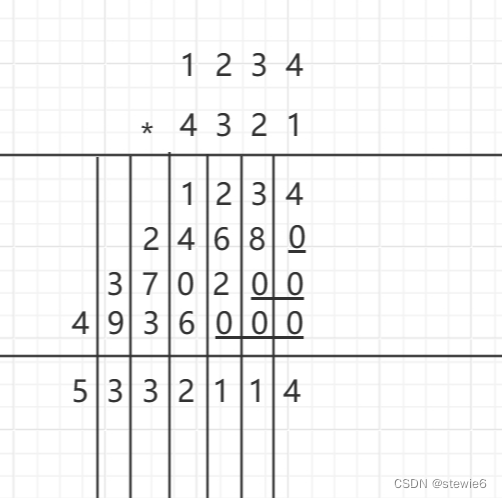
C语言——高精度乘法
一、引子 高精度乘法相较于高精度加法和减法有更多的不同,加法和减法是一位对应一位进行操作的,而乘法是一个数的每一位对另一个数的每一位进行操作,需要的计算步骤更多。 二、核心算法 void Calculate(int num1[], int num2[], int numres…...
为什么C语言没有被C++所取代呢?
今日话题,为什么C语言没有被C所取代呢?虽然C是一个功能更强大的语言,但C语言在嵌入式领域仍然广泛使用,因为它更轻量级、更具可移植性,并且更适合在资源受限的环境中工作。这就是为什么C语言没有被C所取代的原因。如果…...
)
基于Spring的枚举类+策略模式设计(以实现多种第三方支付功能为例)
摘要 最近阅读《贯彻设计模式》这本书,里面使用一个更真实的项目来介绍设计模式的使用,相较于其它那些只会以披萨、厨师为例的设计模式书籍是有些进步。但这书有时候为了使用设计模式而强行朝着对应的 UML 图来设计类结构,并且对设计理念缺少…...

基于Linphone android sdk开发Android软话机
1.Linphone简介 1.1 简介 LinPhone是一个遵循GPL协议的开源网络电话或者IP语音电话(VOIP)系统,其主要如下。使用linphone,开发者可以在互联网上随意的通信,包括语音、视频、即时文本消息。linphone使用SIP协议&#…...
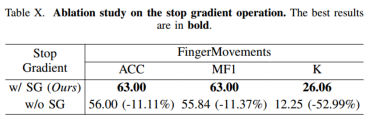
[论文分享]TimeDRL:多元时间序列的解纠缠表示学习
论文题目:TimeDRL: Disentangled Representation Learning for Multivariate Time-Series 论文地址:https://arxiv.org/abs/2312.04142 代码地址:暂无 关键要点:多元时间序列,自监督表征学习,分类和预测 摘…...
分享一个好看的vs主题
最近发现了一个很好看的vs主题(个人认为挺好看的),想要分享给大家。 主题的名字叫NightOwl,和vscode的主题颜色挺像的。操作方法也十分简单,首先我们先在最上面哪一行找到扩展。 然后点击管理扩展,再搜索栏…...

什么是云呼叫中心?
云呼叫中心作为一种高效的企业呼叫管理方案,越来越受到企业的青睐,常被用于管理客服和销售业务。那么,云呼叫中心到底是什么? 什么是云呼叫中心? 云呼叫中心是一种基于互联网的呼叫管理系统,与传统的呼叫…...
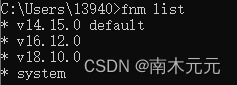
还在用nvm?来试试更快的node版本管理工具——fnm
前言 📫 大家好,我是南木元元,热衷分享有趣实用的文章,希望大家多多支持,一起进步! 🍅 个人主页:南木元元 目录 什么是node版本管理 常见的node版本管理工具 fnm是什么 安装fnm …...
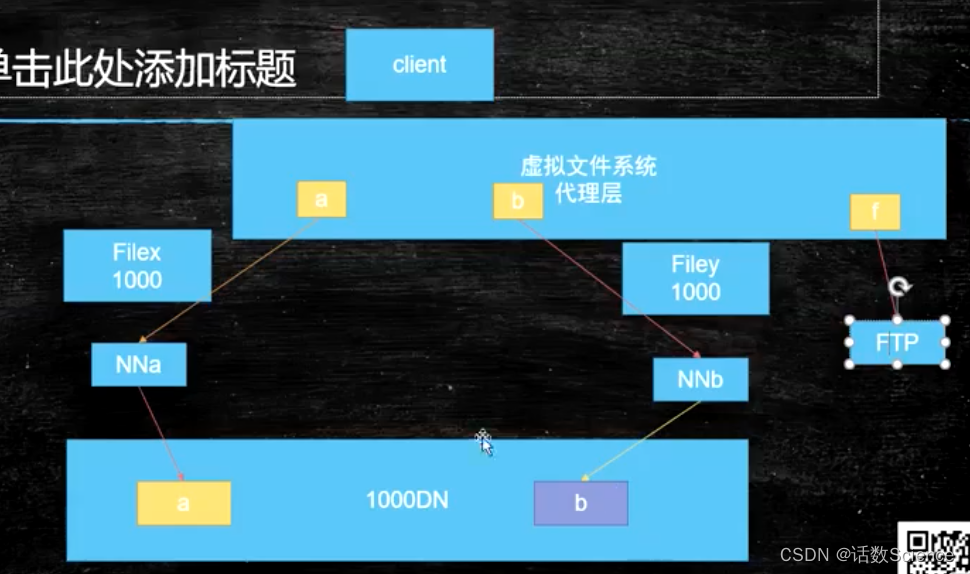
【Hadoop精讲】HDFS详解
目录 理论知识点 角色功能 元数据持久化 安全模式 SecondaryNameNode(SNN) 副本放置策略 HDFS写流程 HDFS读流程 HA高可用 CPA原则 Paxos算法 HA解决方案 HDFS-Fedration解决方案(联邦机制) 理论知识点 角色功能 元数据持久化 另一台机器就…...
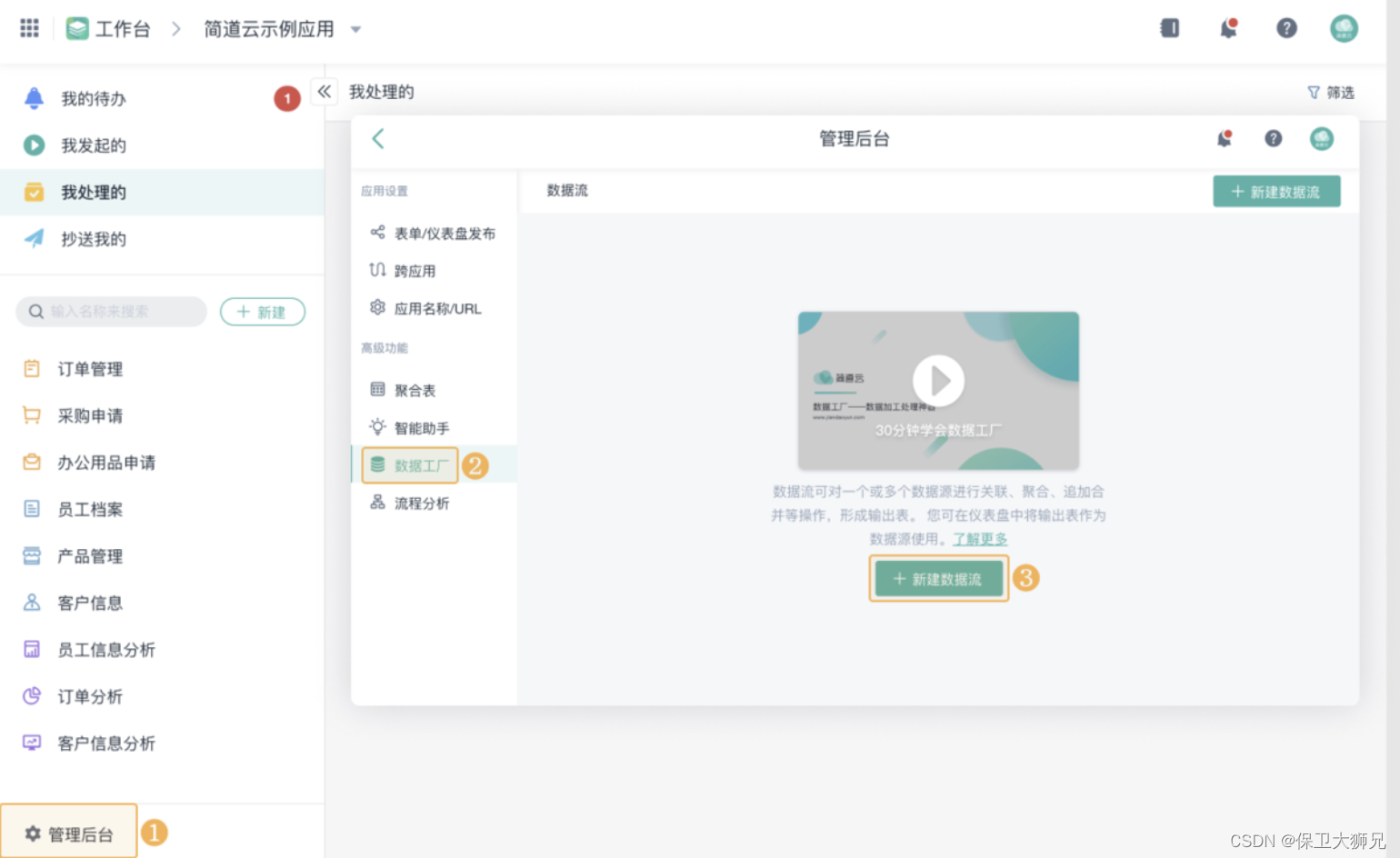
企业需要哪些数字化管理系统?
企业需要哪些数字化管理系统? ✅企业引进管理系统肯定是为了帮助整合和管理大量的数据,从而优化业务流程,提高工作效率和生产力。 ❌但是,如果各个系统之间不互通、无法互相关联数据的话,反而会增加工作量和时间成本…...
【vue】开发常见问题及解决方案
有一些问题不限于 Vue,还适应于其他类型的 SPA 项目。 1. 页面权限控制和登陆验证页面权限控制 页面权限控制是什么意思呢? 就是一个网站有不同的角色,比如管理员和普通用户,要求不同的角色能访问的页面是不一样的。如果一个页…...

飞天使-k8s知识点3-卸载yum 安装的k8s
要彻底卸载使用yum安装的 Kubernetes 集群,您可以按照以下步骤进行操作: 停止 Kubernetes 服务: sudo systemctl stop kubelet sudo systemctl stop docker 卸载 Kubernetes 组件: sudo yum remove -y kubelet kubeadm kubectl…...

ZooKeeper 集群搭建
文章目录 ZooKeeper 概述选举机制搭建前准备分布式配置分布式安装解压缩并重命名配置环境配置服务器编号配置文件 操作集群编写脚本运行脚本搭建过程中常见错误 ZooKeeper 概述 Zookeeper 是一个开源的分布式服务协调框架,由Apache软件基金会开发和维护。以下是对Z…...

Meson:现代的构建系统
Meson是一款现代化、高性能的开源构建系统,旨在提供简单、快速和可读性强的构建脚本。Meson被设计为跨平台的,支持多种编程语言,包括C、C、Fortran、Python等。其目标是替代传统的构建工具,如Autotools和CMake,提供更简…...
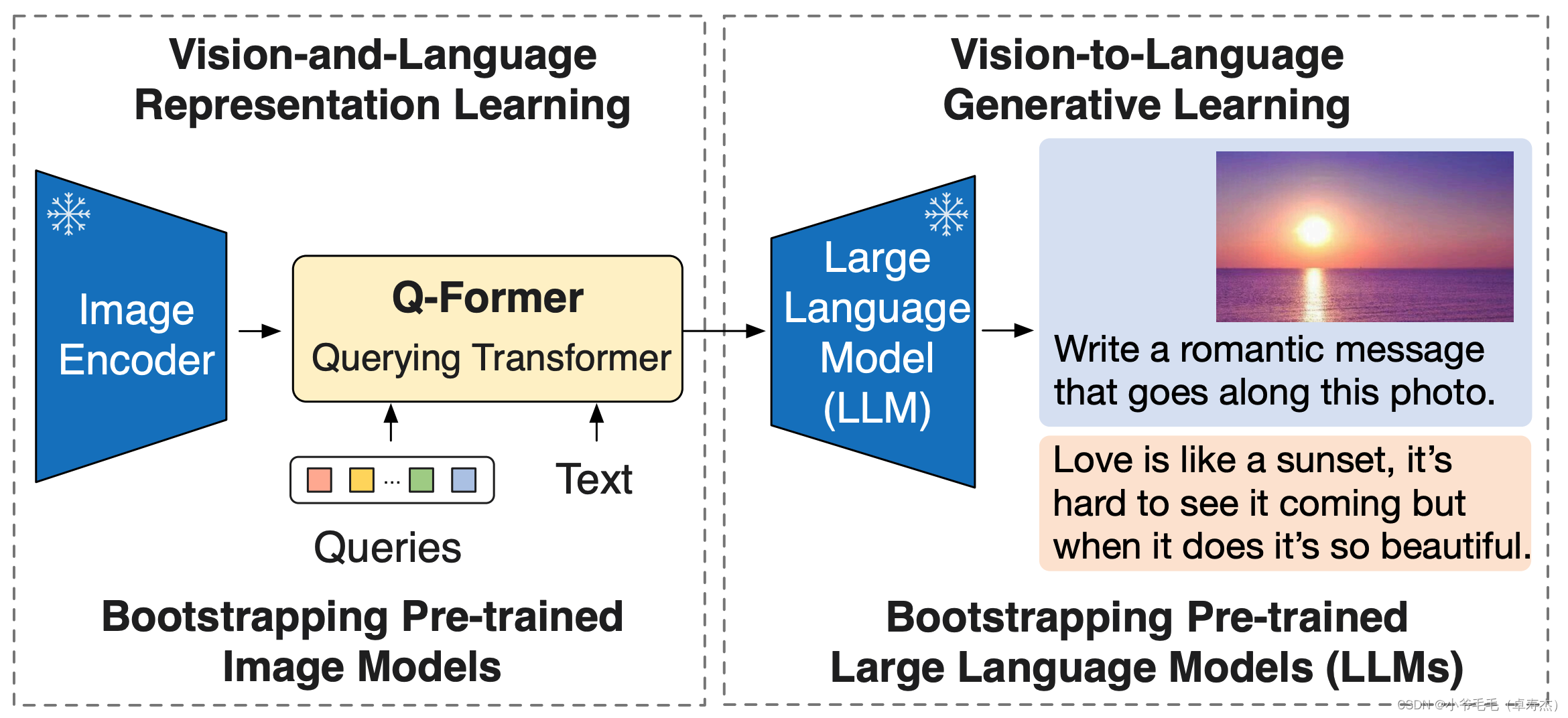
【大模型AIGC系列课程 5-2】视觉-语言大模型原理
重磅推荐专栏: 《大模型AIGC》;《课程大纲》 本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在…...

初创公司如何借助Taotoken控制大模型API试用与正式成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何借助Taotoken控制大模型API试用与正式成本 对于初创公司而言,在产品从原型验证到正式上线的过程中&#x…...
— 硬件I2C驱动AT24C02 EEPROM从零到一)
小熊派gd32f303实战指南(9)— 硬件I2C驱动AT24C02 EEPROM从零到一
1. 硬件I2C与AT24C02基础认知 第一次接触硬件I2C时,我也被那些专业术语搞得一头雾水。简单来说,I2C就像两个人用摩斯密码交流——只需要两根线(SDA数据线和SCL时钟线),就能让主设备(GD32F303)和…...

如何快速掌握Unitree Go2机器人ROS2开发:面向初学者的完整教程
如何快速掌握Unitree Go2机器人ROS2开发:面向初学者的完整教程 【免费下载链接】go2_ros2_sdk Unofficial ROS2 SDK support for Unitree GO2 AIR/PRO/EDU 项目地址: https://gitcode.com/gh_mirrors/go/go2_ros2_sdk Unitree Go2 ROS2 SDK是一个强大的开源项…...

别再只用轮盘赌了!遗传算法选择算子实战对比:Python代码实现与性能调优心得
遗传算法选择算子深度实战:从轮盘赌到锦标赛的Python优化指南 在解决复杂优化问题时,遗传算法展现出了惊人的适应能力。但许多开发者止步于基础的轮盘赌选择(Roulette Wheel Selection),却不知不同选择策略对算法性能的…...

RAD-NeRF:面向实时人像合成的神经辐射场高效架构
1. 项目概述:当NeRF遇上实时人像,RAD-NeRF到底在解决什么问题?我第一次看到“Efficient NeRFs for Real-Time Portrait Synthesis (RAD-NeRF)”这个标题时,手边正调试一个跑在RTX 4090上的标准NeRF模型——单帧渲染耗时23秒&#…...

农业大宗商品与气候数据融合:MCP架构下的数据工程实践
1. 项目概述:当农业大宗商品遇上气候数据最近在做一个挺有意思的项目,核心是把农业大宗商品的数据和气候数据给打通了。听起来好像是个挺宏大的概念,对吧?其实说白了,就是想把“地里长的”和“天上变的”这两件事&…...

Flair NLP框架:从入门到精通的7步完整学习指南 [特殊字符]
Flair NLP框架:从入门到精通的7步完整学习指南 🚀 【免费下载链接】flair A very simple framework for state-of-the-art Natural Language Processing (NLP) 项目地址: https://gitcode.com/gh_mirrors/fl/flair Flair是一个简单而强大的自然语…...

使用Taotoken后如何清晰观测API用量与成本变化
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后如何清晰观测API用量与成本变化 对于团队管理者或开发者而言,将大模型能力集成到产品中后,资…...
)
华为eNSP模拟器实战:用VRRP+MSTP给公司网络做个高可用冗余(附完整配置命令)
华为eNSP企业级网络高可用架构实战:VRRP与MSTP深度协同设计 当一家中型企业的终端规模突破500台时,网络架构的脆弱性往往会突然暴露——某个交换机的意外宕机可能导致整个部门断网,核心链路的拥塞会让关键业务卡顿不已。这时仅靠基础的STP和…...

PrismLauncher-Cracked:彻底解除Minecraft离线账号限制的终极指南
PrismLauncher-Cracked:彻底解除Minecraft离线账号限制的终极指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional Onl…...