MySQL是如何保证数据不丢失的?
文章目录
- 前言
- Buffer Pool 和 DML 的关系
- DML操作流程
- 加载数据页
- 更新记录
- 数据持久化方案
- 合适的时机刷盘
- 双写机制
- 日志先行机制
- 日志刷盘机制
- Redo Log 恢复数据
- 总结
前言
上篇文章《InnoDB在SQL查询中的关键功能和优化策略》对InnoDB的查询操作和优化事项进行了说明。但是,MySQL作为一个存储数据的产品,怎么确保数据的持久性和不丢失才是最重要的,感兴趣的可以跟随本文一探究竟。
Buffer Pool 和 DML 的关系
InnoDB中的「Buffer Pool」除了在查询时起到提高效率作用,同样,在insert、update、delete这些DML操作时为了减少和磁盘的频繁交互,也会将这些更新先在Buffer Pool中缓存的数据页进行操作,随后将这些有更新的「脏页」刷到磁盘中。
这个时候就涉及到一个问题:如果MySQL服务宕机了,这些在内存中更新的数据会不会丢失?
答案是一定会存在丢失现象的,只不过MySQL做到了尽量不让数据丢失。接下来来看一下MySQL是怎么做的。
这里还是把结构图贴一下,方便下面介绍时看图理解。
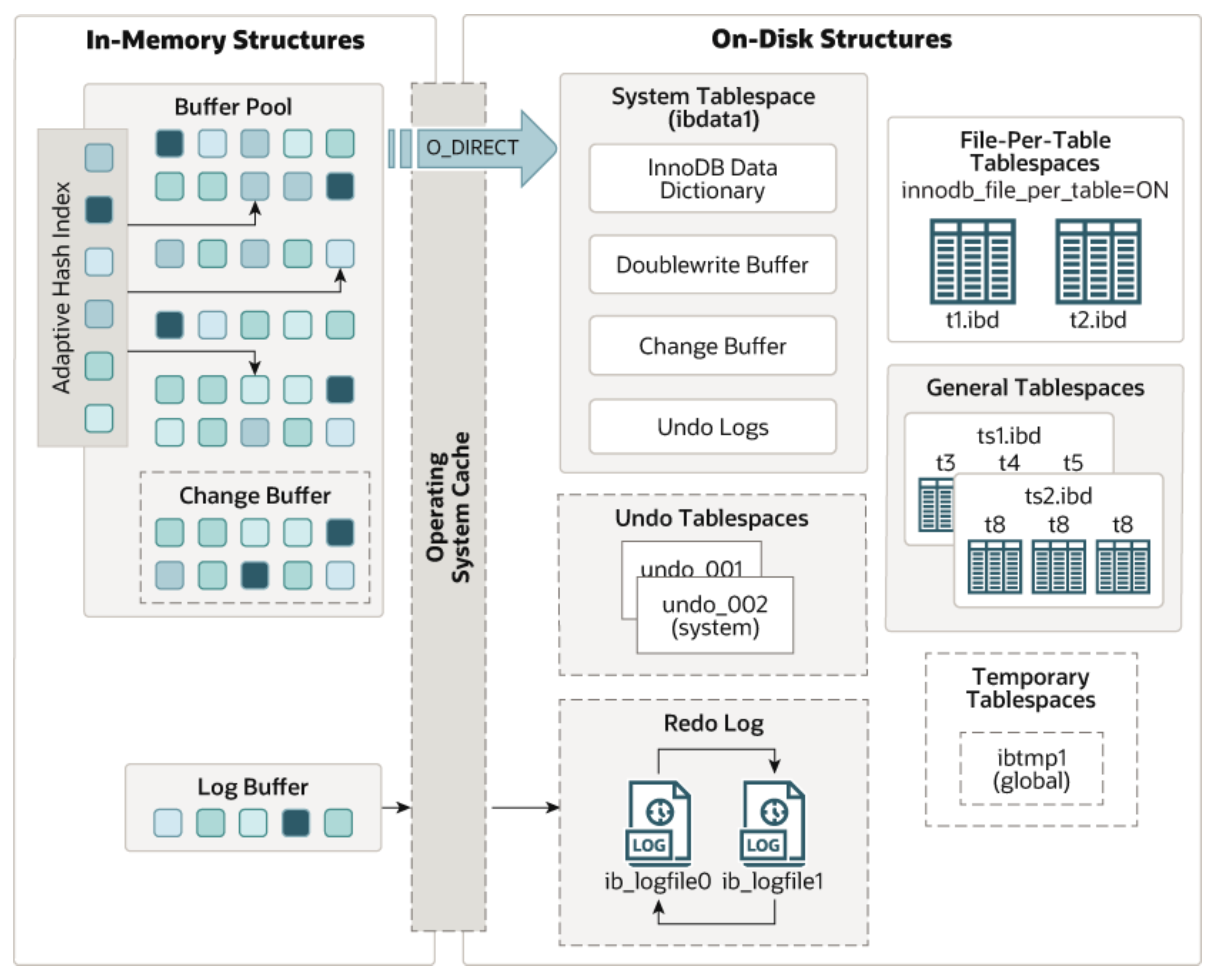
DML操作流程
加载数据页
通过上文可以知道,行记录是在数据页中,所以,当InnoDB接收到DML操作请求后,还是会去找「数据页」,查找的过程跟上文查询行记录流程是一样。这里说一下,insert的请求会根据主键索引去找数据页,update、delete根据查询条件去找数据页,总之「数据页」要加载到「Buffer Pool」之后才会进行下一步操作。
更新记录
定位到数据页后,insert操作就是往数据页中添加一行记录,delete是标记一下行记录的‘删除标记’,而update则是先删除再添加,这是因为存在可变长的字段类型,比如varchar,每次更新时,这种类型的数据占用内存是不固定的,所以先删除再添加。
这里的删除标记是行记录的字段,也就是除了业务字段数据,InnoDB默认为每行记录添加的字段,所以一个行记录大概如下图,这也是之前提到过的「行格式」。

找到数据页并且更新记录之后DML操作就算完成了,但是还没有落地到磁盘。
这个时候直接刷新到磁盘视为完成不可以吗?
数据持久化方案
可以是可以,但是如果每次的DML操作都要将一个16KB的数据页刷到磁盘,其效率是极低的,估计也就没有人用MySQL了。但是如果不刷新到磁盘,就会发生MySQL服务宕机数据会丢失现象。MySQL在这里的处理方案是:
- 等待合适的时机将批量的「脏页」异步刷新到磁盘。
- 先快速将更新的记录以日志的形式刷新到磁盘。
先看第一点,什么时候是合适的时机?
合适的时机刷盘
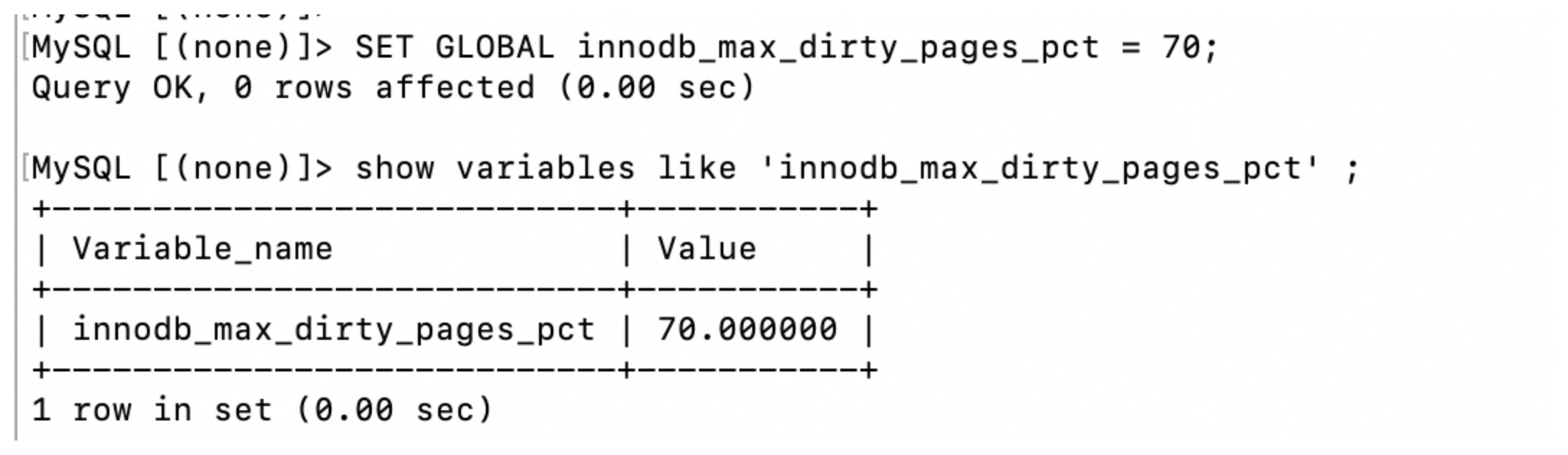
当「脏页」在「Buffer Pool」中达到某个阈值的时候,InnoDB会将这些脏页刷新到磁盘中。这个阈值可以通过 innodb_max_dirty_pages_pct 这个参数查看或设置,相关命令如下:
-- 查看脏页刷新阈值
show variables like 'innodb_max_dirty_pages_pct'
-- 在线设置脏页刷新阈值,当脏页在Buffer Pool占用70%的时候刷新
SET GLOBAL innodb_max_dirty_pages_pct = 70
当然,这个合适的时机只是为了减少与磁盘的交互,用来提高性能的,并不能确保数据不丢失。
双写机制
在刷新「脏页」这里还有一个非常重要的注意事项就是:因为InnoDB的页大小为16KB,而一般操作系统的页大小为4KB。意味着InnoDB将这些「脏页」向磁盘刷新时,在操作系统层面会被分成4个4KB的页,这样的话,如果其中有一页因为MySQL宕机或者其他异常导致没有成功刷新到磁盘,就会出现「页损坏现象」,数据也就不完整了。
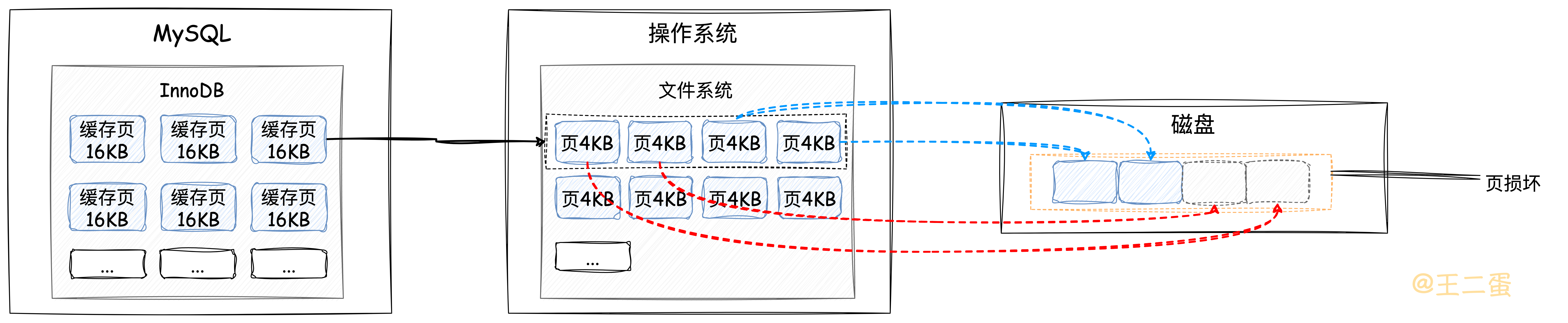
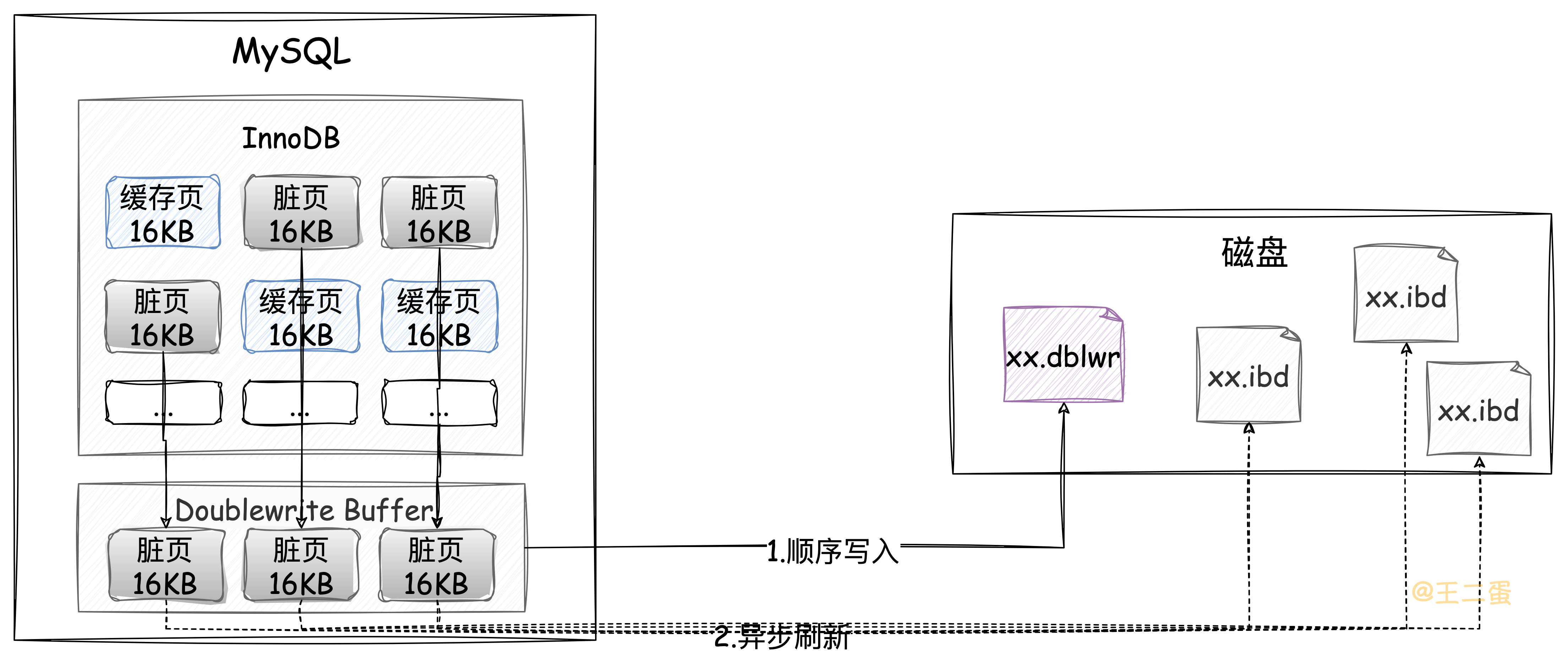
所以InnoDB在这里采用的双写机制,在将这些「脏页」刷新到磁盘之前先会往结构图中的「Doublewrite Buffer」中写入,随后再刷新到对应的表空间中,当出现故障时就可以通过双写缓冲区进行恢复。
向「Doublewrite Buffer」就不会发生「页损坏现象」?
「Doublewrite Buffer」的大小是独立且固定的,不是基于页的大小来划分的。所以不受操作系统中的页大小限制,也不会发生「页损坏现象」。并且先以顺序IO的方式向「Doublewrite Buffer」写入数据页,再以随机IO异步刷新到表空间这种方式还可以提高写入性能。
再看第二点,为什么以日志的形式先刷新到磁盘?
日志先行机制
在「Buffer Pool」中更新完数据页后,由于不会及时将这些「脏页」刷新到磁盘,为了避免数据丢失,会将本次的DML操作向「Log Buffer」中写一份并且刷新到磁盘中,相比16KB的数据页来说,这个数据量会小很多,而且写入日志文件时是追加操作,属于顺序IO,效率较高。如下图,哪种方式写入效率更高是显而易见的。
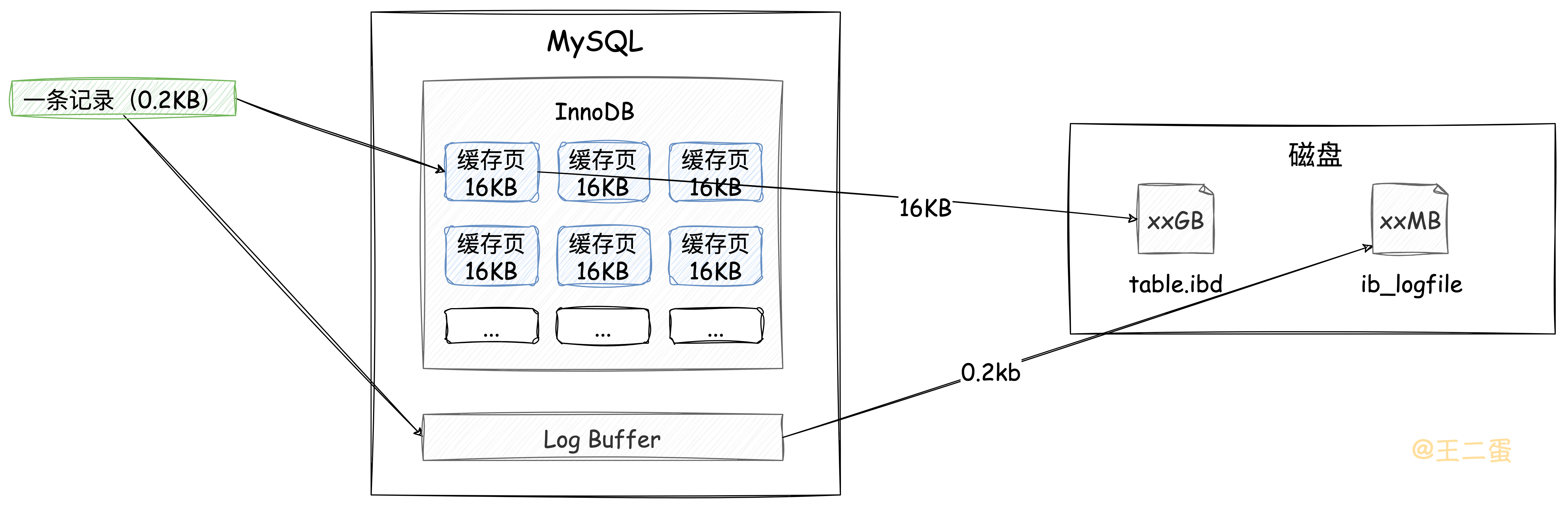
这里说的日志文件就是经常会听到的「Redo Log」,即使MySQL宕机了,通过磁盘的redolog,也可以在MySQL启动时尽可能的将数据恢复到宕机之前样子。当然,还有「Undo Log」,因为对本文重点没有直接影响,所以不对此展开说明。
这种日志先行(WAL)的机制也是MySQL用于提高效率和保障数据可靠的一种方式。
为什么是尽可能的恢复?
日志刷盘机制
因为「Log Buffer」中的日志数据什么时候向磁盘刷新则是由 innodb_flush_log_at_trx_commit 和 innodb_flush_log_at_timeout 这两个参数决定的。
innodb_flush_log_at_trx_commit默认为1,也就是每次事务提交后就会刷新到磁盘。- 当
innodb_flush_log_at_trx_commit设置为0时,则不会根据事务提交来刷新,而是根据innodb_flush_log_at_timeout设置的时间定时刷新,这个时间默认为1秒。 - 当
innodb_flush_log_at_trx_commit设置为2时,仅将日志写入操作系统中的缓存中,随后跟随根据innodb_flush_log_at_timeout定时刷新。
如果在MySQL服务宕机的时候,「Log Buffer」中的日志没有刷新到磁盘,这部分数据也是会丢失的,在重启后也不会恢复。所以如果不想丢失数据,在性能还可以的情况下,尽量将innodb_flush_log_at_trx_commit设置为1。
「redo log」是怎么恢复数据的?
Redo Log 恢复数据
首先,redo log会记录DML的操作类型、数据的表空间、数据页以及具体操作内容,以 insert into t1(1,'hi')为例,对应的redo log内容大概这样的

假如 innodb_flush_log_at_trx_commit 的值为1,那么当该DML操作事务提交后,就会将 redo log 刷新到磁盘。成功刷新到磁盘后,就可以视为数据被写入成功。
此时如果「脏页」还没刷新到磁盘便宕机,那么在下次MySQL启动时便去加载redo log,如果redo log存在数据则意味着需要恢复数据。这个时候就可以通过redo log中的内容重新构建「脏页」,从而恢复到宕机之前的状态。
怎么构建「脏页」呢?
其实在每次的redo log写入时都会记录一个「LSN(log sequence number)」,同时这个值在「数据页」中记录最后一次被修改的日志序列位置。MySQL在启动时通过LSN来对比 redo log 和数据页,如果数据页中的LSN小于 redo log 的LSN,则会将该数据页加载到「Buffer Pool」,然后根据 redo log 的内容构建出「脏页」,等待下次刷新到磁盘,数据也就恢复了。如下图
注意:这个恢复的过程重点在redo上,实际上还涉及到「Change Buffer」、「Undo Log」等操作,这里没有展开说明。
「Doublewrite Buffer」和「redo log」都是恢复数据的,不冲突吗?
不冲突,「Doublewrite Buffer」是对「页损坏现象」的整个数据页进行恢复,Redo Log只能对某次的DML操作进行恢复。
总结
InnoDB通过以上的操作可以尽可能的保证MySQL不丢失数据,最后再总结一下MySQL是如何保障数据不丢失的:
- 为了避免频繁与磁盘交互,每次DML操作先在「Buffer Pool」中的缓存页中执行,缓存页有更新之后便成为「脏页」,随后根据
innodb_max_dirty_pages_pct这个参数将「脏页」刷新到磁盘。 - 因为「脏页」在刷新到磁盘之前可能会存在MySQL宕机等异常行为导致数据丢失,所以MySQL采用日志先行(WAL)机制,将DML操作以日志的形式进行记录到「Redo Log」中,随后根据
innodb_flush_log_at_trx_commit和innodb_flush_log_at_timeout这两个参数将「Redo Log」刷新到磁盘,以便恢复。 - 在向磁盘刷新「脏页」时,为了避免发生「页损坏」现象,InnoDB采用双写机制,先将这些脏页顺序写入「Doublewrite Buffer」中,随后再将数据页异步刷新到各个表空间中,这种方式既能提高写入效率,又可以保障数据的完整性。
- 如果在「脏页」刷新到磁盘之前,MySQL宕机了,那么会在下次启动时通过 redo log 将脏页构建出来,做到数据恢复。
- 通过以上步骤,MySQL做到了尽可能的不丢失数据。
相关文章:
MySQL是如何保证数据不丢失的?
文章目录 前言Buffer Pool 和 DML 的关系DML操作流程加载数据页更新记录 数据持久化方案合适的时机刷盘双写机制日志先行机制日志刷盘机制Redo Log 恢复数据 总结 前言 上篇文章《InnoDB在SQL查询中的关键功能和优化策略》对InnoDB的查询操作和优化事项进行了说明。但是&#…...

CUMT--Java复习--泛型与集合
目录 一、泛型 1、概述 2、通配符 3、有界类型 二、集合 1、概述 2、迭代器接口 三、集合类 1、Collection接口 2、List接口 3、Set接口 4、Queue接口 5、Map接口 四、集合转换 五、集合工具类 一、泛型 1、概述 从JDK5.0开始,Java引入泛型类型&…...
Android 权限申请
在Android中,从Android 6.0(API级别23)开始,应用在运行时需要动态申请权限。以下是一些步骤来动态申请权限: 在应用的清单文件(AndroidManifest.xml)中声明需要的权限。例如,如果应…...
不可见副本)
R语言【base】——invisible将控制台的输出模式调整为隐藏,只允许赋值后输出,返回对象的(临时)不可见副本
Package base version 4.3.2 invisible(x NULL) 参数【x】:一个任意的 R 对象,默认为 NULL。 如果希望函数返回的值可以赋值,但在未赋值时不打印,则可以使用该函数。 f <- function(x){if (x){return (x)} else {return (in…...

LA@线性代数学习总结@主要对象和问题@思想方法
文章目录 线性代数研究对象主要问题联系核心概念核心定理 核心操作和运算基础高级小结 性质和推导方法问题转换为线性方程组求解问题验证和推导性质定理 线性代数研究对象 线性代数的研究对象主要是行列式和矩阵(向量)矩阵这种对象可以做的操作和运算很多,特别是方阵,它们的计…...
VMware克隆虚拟机
要求:利用模板虚拟机hadoop100,克隆出hadoop101虚拟机。 1、鼠标右键点击已存在的模板虚拟机hadoop100 --> 管理 --> 克隆 2、选择克隆自虚拟机中的当前状态 3、创建完整克隆 4、修改虚拟机名称、位置 5、等待克隆完成后,则成功克隆出…...

C语言中常见的关键字
一、数据类型关键字(20个) 基本数据类型(5个) void:声明函数无返回值或无参数,声明无类型指针,显式丢弃运算结果 char:字符型类型数据,属于整型数据的一种 intÿ…...
新型智慧视频监控系统:基于TSINGSEE青犀边缘计算AI视频识别技术的应用
边缘计算AI智能识别技术在视频监控领域的应用有很多。这项技术结合了边缘计算和人工智能技术,通过在摄像头或网关设备上运行AI算法,可以在现场实时处理和分析视频数据,从而实现智能识别和分析。目前来说,边缘计算AI视频智能技术可…...

智能优化算法应用:基于梯度算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于梯度算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于梯度算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.梯度算法4.实验参数设定5.算法结果6.参考文献7.MA…...
如何使用Docker搭建青龙面板并结合内网穿透工具发布至公网可访问
文章目录 一、前期准备本教程环境为:Centos7,可以跑Docker的系统都可以使用。本教程使用Docker部署青龙,如何安装Docker详见: 二、安装青龙面板三、映射本地部署的青龙面板至公网四、使用固定公网地址访问本地部署的青龙面板 正文…...
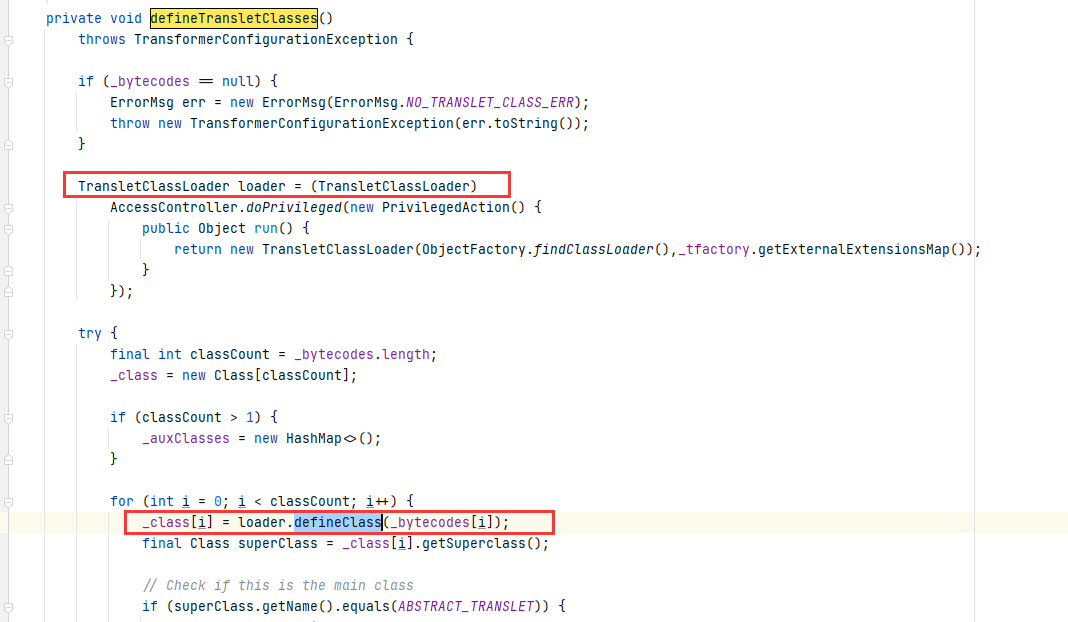
fastjson1.2.24 反序列化漏洞(CVE-2017-18349)分析
FastJson在< 1.2.24 版本中存在反序列化漏洞,主要原因FastJson支持的两个特性: fastjson反序列化时,JSON字符串中的type字段,用来表明指定反序列化的目标恶意对象类。fastjson反序列化时,字符串时会自动调用恶意对…...

Linux中history使用(过滤,显示时间,查找)
显示历史命令 history 显示最后几条执行命令 history 5 显示history记录中命令执行时间 export HISTTIMEFORMAT"%F %T " 显示命令中有某些内容的最后几条执行命令 history | grep key | tail -n 2...
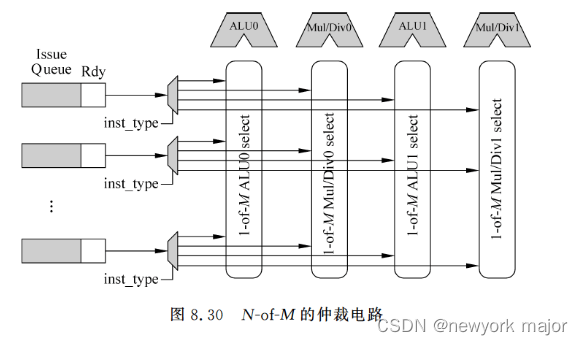
issue阶段的选择电路的实现
1-of-M的仲裁电路 为什么要实现oldest-first 功能的仲裁呢? 这是考虑到越是旧的指令,和它存在相关性的指令也就越多,因此优先执行最旧的指令,则可以唤醒更多的指令,能够有效地提高处理器执行指令的并行度,而且最旧的指…...
BearPi Std 板从入门到放弃 - 后天篇(3)(ESP8266透传点灯)
简介 电脑搭建一个TCP Server, ESP8266 串口设置好透传模式, 再由TCP Server发送指令控制灯的亮灭; 开灯指令: led_on回车 ; 关灯指令: led_off回车 主芯片: STM32L431RCT6 LED : PC13 \ 推挽输出即可 \ 高电平点亮 串口: Usart1 / LPUART E…...

【Linux】macOS下使用scp命令编写脚本上传文件至服务器
使用时需要输入服务器密码 #!/bin/bash# 检查传递给脚本的参数数量 if [ "$#" -ne 2 ]; thenecho "Usage: $0 <本地文件路径> <服务器文件夹路径>"exit 1 fi# 接收命令行参数 local_file"$1" remote_path"$2"# 定义远程服…...

难以置信:WINDOWS11真的取消了助记符
助记符是个好东西,记住了非常的方便。这几天升级到WINDOWS11之后,发现助记符被全面取消!真是难以置信! 现在WIN11越来越象MAC,MAC好用吗?当然不好用。 其实WIN11完全可以开发两套界面,各取所需。…...
使用VSC从零开始Vue.js——备赛笔记——2024全国职业院校技能大赛“大数据应用开发”赛项——任务3:数据可视化
使用Visual Studio Code(VSC)进行Vue开发非常方便,下面是一些基本步骤: 一、下载和安装Vue 官网下载地址Download | Node.js Vue.js是基于Node.js的,所以首先需要安装Node.js,官网下载地址:No…...

企业直聘招聘人才求职系统招聘会小程序系统源码
技术栈: 端 原生小程序开发 后端php7.2 数据库mysql5.6 主要功能: 企业入住 ,企业直聘 个人实名认证,人才求职 发布线上招聘会 企业招聘邀请 个人简历置顶 刷新 浏览足迹浏览 附近 招聘信息查看...
大型语言模型:SBERT — Sentence-BERT
slavahead 一、介绍 Transformer 在 NLP 方面取得了进化进步,这已经不是什么秘密了。基于转换器,许多其他机器学习模型已经发展起来。其中之一是BERT,它主要由几个堆叠的变压器编码器组成。除了用于情感分析或问答等一系列不同的问题外&#…...

高效编写软件测试报告的关键技巧
引言: 软件测试报告是测试团队与开发团队之间沟通的重要工具,它记录了测试过程中的发现、问题和建议。一个清晰、准确、高效的软件测试报告可以帮助开发团队更好地理解测试结果,并及时修复问题。本文将介绍一些高效编写软件测试报告的关键技巧…...

基于树莓派与开源硬件的虾类养殖水质监控系统设计与实践
1. 项目概述:一个开源的虾类养殖监控系统最近在翻看GitHub上的开源项目,偶然发现了一个挺有意思的仓库,叫“openshrimp”。光看名字,你可能会觉得这是个跟海鲜或者生物相关的项目,但实际上,它是一个面向水产…...

抖音内容采集技术方案深度解析:架构设计与企业级应用实战指南
抖音内容采集技术方案深度解析:架构设计与企业级应用实战指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallbac…...

NoFences完整指南:免费开源工具彻底解决Windows桌面杂乱问题
NoFences完整指南:免费开源工具彻底解决Windows桌面杂乱问题 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为杂乱的Windows桌面图标而烦恼吗?No…...

基于MCP协议构建安全可控的AI智能体数据接入层
1. 项目概述:一个为智能体打造的“安全印章”与“情报中枢”最近在折腾AI智能体(Agent)的开发与集成,发现一个挺有意思的现象:大家把模型能力、工具调用这些“上层建筑”都玩得很溜,但一涉及到让智能体安全…...
)
别再搞混了!设备上那个RJ45口是Console调试口,不是网口(附UART转RS-232电路详解)
网络设备调试入门:解密Console口的真实身份与电路原理 刚拿到一台崭新的交换机或路由器时,许多新手会对着设备后面板上那个看似普通的RJ45接口发愣——它长得和网口几乎一模一样,但旁边却标注着"Console"。这个看似简单的接口背后&…...

别盲目学AI!先搞懂人工智能的3大核心分支,选对方向少走3年弯路
文章目录前言第一大分支:大模型与生成式AI——AI行业的"水电煤"什么是大模型与生成式AI?大模型技术在2026年的发展现状大模型方向的主要岗位和薪资大模型方向的学习路线第二大分支:智能体与多智能体系统——2026年AI行业最大的风口…...
)
Angular+Claude协同开发全栈实践(企业级项目落地手册)
更多请点击: https://intelliparadigm.com 第一章:AngularClaude协同开发全栈实践(企业级项目落地手册) 在现代企业级应用开发中,前端框架与AI辅助编程的深度集成正成为提效关键。Angular 提供结构化、可扩展的单页应…...

物理神经计算:突破冯·诺依曼瓶颈的新范式
1. 物理神经计算:突破冯诺依曼瓶颈的新范式在传统计算架构面临能效瓶颈的今天,物理神经计算(Physical Neural Computing)正在掀起一场硬件革命。这种新型计算范式不再依赖传统的数字逻辑门和冯诺依曼架构,而是直接利用…...

ZYNQ实战:从零构建uCOSIII最小系统与BSP配置详解
1. 环境准备与硬件设计 第一次在ZYNQ上跑uCOSIII时,我踩了不少坑。记得当时为了找个靠谱的参考文档,翻遍了国内外论坛。现在回头看,其实只要硬件配置对了,软件移植就是水到渠成的事。咱们先从最基础的Vivado工程搭建说起。 我用的…...

AI工作流编排利器:OpenClaw Workflow Kit 模块化设计与实战
1. 项目概述:一个为AI工作流打造的“瑞士军刀”最近在GitHub上看到一个挺有意思的项目,叫leilong611-ai/openclaw-workflow-kit。光看这个名字,你可能会有点懵:“OpenClaw”是啥?“Workflow Kit”又是干嘛的࿱…...