听GPT 讲Rust源代码--src/tools(18)

File: rust/src/tools/rust-analyzer/crates/ide-ssr/src/from_comment.rs
在Rust源代码中的from_comment.rs文件位于Rust分析器(rust-analyzer)工具的ide-ssr库中,它的作用是将注释转换为Rust代码。
具体来说,该文件实现了从注释中提取出Rust代码的功能。在使用Rust编写代码时,注释通常是用来提供代码文档、示例或者注解的。但是,有时候注释中也会包含一些可执行的Rust代码片段,这些代码片段可以被提取并转换为可执行的Rust代码。
该文件中的代码通过解析注释中的特定语法来提取Rust代码。它搜索包含特定标记的注释行,并从中提取出Rust代码。例如,一个常用的标记是// ssr:code,注释中包含该标记的行将被解析为Rust代码。
一旦提取出Rust代码,该文件会将其转换为Rust AST(抽象语法树)的表示形式。这意味着将注释中的代码转换为Rust编程语言理解的内部数据结构。通过转换为AST,Rust编译器可以更好地理解这些代码,并进行语义分析、语法检查、类型推导等操作。
从注释中提取Rust代码可以帮助开发人员编写清晰的示例代码、测试代码或者快速的原型代码。这在代码文档、教程和演示中非常有用。
总结而言,from_comment.rs文件实现了一个功能,将注释中的Rust代码提取并转换为可执行的Rust代码,以便在Rust分析器中使用。这提供了一种快速编写、测试和展示Rust代码的便捷方式。
File: rust/src/tools/rust-analyzer/crates/ide-ssr/src/lib.rs
文件rust-analyzer/crates/ide-ssr/src/lib.rs是Rust语言的语法重写(syntax rewriting)功能的实现。这个功能可以用于在代码中进行模式匹配和替换。该文件包含了几个重要的数据结构和算法,用于在给定的代码中查找并替换匹配的模式。
首先,SsrRule是语法重写规则的表示。它包含一个输入模式(input pattern)和一个输出模式(output pattern),用于描述要匹配和替换的代码模式。
接下来,SsrPattern是一个抽象的代码模式,它可以表示表达式、语句、模式或任何其他代码片段。它可以是具体的,包含实际的代码,也可以是通配符,表示任何代码。SsrPattern提供了一些方法,以便在模式匹配和替换的过程中使用。
然后是SsrMatches,它表示匹配到一个模式的具体代码片段。SsrMatches记录了匹配的模式的位置和子模式的匹配。
MatchFinder<'db>是主要的匹配查找器,它负责根据给定的规则在代码中查找匹配。它使用数据库(数据库类型是’db)来对代码进行索引和导航,以支持高效的匹配操作。
最后,MatchDebugInfo是一个用于调试目的的结构体,记录了匹配过程中的一些信息。它可以用于收集和显示匹配的详细信息,帮助开发人员理解匹配过程。
这些结构体的组合和使用形成了语法重写功能的核心部分,这个功能可以用于编写自定义的代码重写规则,以提高代码的可读性和维护性。在Rust源代码中,该文件是Rust语言分析器(Analyzer)的一部分,用于支持编写和应用语法重写规则,从而实现代码重构和改进。
File: rust/src/tools/rust-analyzer/crates/ide-ssr/src/resolving.rs
在Rust源代码中,rust-analyzer/crates/ide-ssr/src/resolving.rs文件的作用是实现了语法结构(SSR)中的解决器(resolver)。解决器是用于解析和推断语法结构的各个部分的工具。该文件中定义了一些结构体和函数,用于处理解析和推断的逻辑。
以下是对每个结构体的详细介绍:
-
ResolutionScope<'db>: 这个结构体代表了一个解析作用域。它包含了解析某个节点时所需的上下文信息,比如在哪个模块内、哪些变量是可见的等。 -
ResolvedRule: 这个结构体表示一个解析过的规则。它包含了规则的名称和解析后的模式。 -
ResolvedPattern: 这个结构体表示一个解析过的模式。它包含了模式的名称和类型。 -
ResolvedPath: 这个结构体表示一个解析过的路径。它包含了路径的具体信息,比如模块、方法等。 -
UfcsCallInfo: 这个结构体表示一个解析过的统一函数调用语法结构。它包含了调用的方法名称、参数等信息。 -
Resolver<'a, 'db>: 这个结构体是一个解析器的实例。它持有一个数据库('db)和一个作用域('a),用于解析和推断语法结构。
以上结构体共同协作,用于解析和推断SSR中的各个语法结构。解析器使用ResolutionScope来跟踪语法结构的作用域,使用ResolvedRule和ResolvedPattern来表示解析过的规则和模式,使用ResolvedPath来表示解析过的路径,使用UfcsCallInfo来表示解析过的统一函数调用语法结构。
解析器的主要作用是根据给定的代码片段,确定语法结构在编译时的具体含义。这对于编辑器扩展和代码静态分析工具等工具非常重要,因为它可以帮助开发者在编码时进行错误检查和自动补全等功能。
File: rust/src/tools/rust-analyzer/crates/ide-ssr/src/matching.rs
在Rust源代码中,rust/src/tools/rust-analyzer/crates/ide-ssr/src/matching.rs文件是用于实现在代码中执行结构化搜索和替换操作的功能。它提供了一组用于匹配和替换模式的结构体和枚举。
-
Match struct:表示一个匹配结果,包含有关匹配项的详细信息,如匹配位置、匹配内容等。
-
PlaceholderMatch struct:表示一个匹配项中的占位符的匹配结果。占位符可以是用于替换的模式中的一部分,用于标识需要被替换的内容。
-
MatchFailureReason enum:表示匹配失败的原因。它包含一系列可能的失败原因,如匹配模式结构不匹配、类型不匹配等。
-
MatchFailed struct:表示匹配失败的结果。它包含了失败的原因和相关的匹配项。
-
Matcher struct:用于执行匹配操作的结构体。它接受一个模式,并在给定的源代码中进行匹配,返回匹配结果。
-
PatternIterator struct:用于迭代模式中的各个部分。它是用于模式匹配过程的辅助类型。
-
Phase enum:表示结构化搜索和替换的不同阶段。它包含了
PatternSearch和PlaceholderReplace两个枚举成员,分别表示搜索和替换的阶段。
这些结构体和枚举共同协作,实现了在给定代码中寻找匹配模式并替换的功能。matcher结构体会解析给定的模式,并使用PatternIterator按照指定的阶段进行匹配操作。匹配成功后,会返回Match结构体,并根据需要进行替换操作。而如果匹配失败,则会返回MatchFailed结构体,其中包含失败的原因和相关的匹配项。通过这些功能,matching.rs文件提供了执行结构化搜索和替换操作的能力。
File: rust/src/tools/rust-analyzer/crates/tt/src/buffer.rs
在Rust的源代码中,rust/src/tools/rust-analyzer/crates/tt/src/buffer.rs 文件的作用是提供了与文本缓冲区相关的数据结构和功能。
EntryId(usize) 是一个简单的标识符,用于唯一标识缓冲区中的每个条目,并提供对条目的索引引用。
EntryPtr 是一个指向缓冲区条目的指针,它具体包含了 TokenBuffer<'t, Cursor<'a>> 的引用。
TokenBuffer<'t, Cursor<'a>> 是一个用于存储待解析的文本缓冲区的结构体。其中 't 是一个生命周期参数,'a 则是另一个生命周期参数,用于指示 TokenBuffer 借用的时间范围。通过 Cursor 可以遍历 TokenBuffer 中的条目。
TokenList<'a 是一个 trait,定义了访问 TokenBuffer 中条目列表的方法。
Entry<'t, TokenTreeRef<'a>> 是一个 EntryPtr 的具体实现,它存储了待解析的标记树。
TokenTreeRef<'a> 是一个对标记树的引用。
这些枚举类型:Punct, Literal, Ident, Group,是 TokenTreeRef 的具体实现,用于区分 TokenTreeRef 是标点符号、字面量、标识符还是组。
总之,这个文件提供了一套用于处理待解析文本缓冲区的数据结构和功能,包括缓冲区的条目索引和指针、遍历缓冲区、访问条目列表以及对标记树的处理。
File: rust/src/tools/rust-analyzer/crates/tt/src/lib.rs
在Rust源代码中,rust/src/tools/rust-analyzer/crates/tt/src/lib.rs文件是tt crate(也称为TokenTree crate)的入口文件,用于提供对Rust代码中的标记树(TokenTree)进行解析、操作和生成的工具。
该文件实现了一系列的结构体和枚举类型来表示Rust代码中的不同标记和标记树的不同部分。下面是对这些类型的详细介绍:
-
TokenId(pub, ...):表示标记的唯一标识符,用于在标记树中引用特定标记。它是公共(pub)的结构体,但省略了其余的定义,因此无法提供更多详细信息。 -
SyntaxContext(pub, ...):表示语法上下文,用于确定标记树中标记的语法作用域。它是一个带有子树、分隔符、字面量、标点和标识符的结构体,它们通过Span类型进行参数化,用于跟踪标记的位置和范围。 -
Subtree<Span>:表示标记树中的子树部分,可以包含其他标记和分隔符。该结构体含有一个Span类型的参数,用于跟踪子树的位置和范围。 -
Delimiter<Span>:表示标记树中的分隔符,如括号、花括号或方括号。它也有一个Span类型的参数,用于跟踪分隔符的位置和范围。 -
Literal<Span>:表示标记树中的字面量,如字符串、数字等。同样,它也有一个Span类型的参数,用于跟踪字面量的位置和范围。 -
Punct<Span>:表示标记树中的标点符号,如逗号、点号等。同样,它也有一个Span类型的参数,用于跟踪标点符号的位置和范围。 -
Ident<Span>:表示标记树中的标识符,如变量名、函数名等。同样,它也有一个Span类型的参数,用于跟踪标识符的位置和范围。 -
TokenTree<Span>:表示整个标记树。可以是子树、叶子(即单个标记)或一对分隔符(左右分界符)。 -
Leaf<Span>:表示标记树中的叶子部分,即单个标记。 -
DelimiterKind:表示分隔符的种类,可以是括号、花括号或方括号之一。 -
Spacing:表示标记前后的间距,可以是紧凑(Spacing::Joint)或空白(Spacing::Alone)之一。
这些结构体和枚举类型的定义和实现,提供了一个表达和操作Rust代码中标记树的框架,方便进行各种源代码分析和生成的任务。
File: rust/src/tools/rust-analyzer/crates/text-edit/src/lib.rs
在Rust源代码中,rust/src/tools/rust-analyzer/crates/text-edit/src/lib.rs文件是rust-analyzer工具中用于实现文本编辑的部分。
Indel是一个表示插入(insert)或删除(delete)操作的结构体。它包含了一段文本以及对应的偏移量(offset),用于标识插入或删除的位置。
TextEdit是一个表示文本编辑的结构体。它由在文本中进行插入和删除操作的Indel结构体组成。一个TextEdit可以应用于一个字符串,将其中的特定位置的文本替换为指定的文本(插入或删除)。
TextEditBuilder是一个用于构建TextEdit对象的结构体。它提供了一系列方法来添加插入或删除操作(使用Indel对象)到编辑中,并最终构建出一个完整的TextEdit对象。
通过使用这些结构体,rust-analyzer可以方便地进行文本的插入和删除操作,并将这些操作重新应用于其他字符串上。这在编程语言工具中非常常见,因为源代码的分析和变换通常需要进行文本处理。
File: rust/src/tools/rust-analyzer/crates/load-cargo/src/lib.rs
在Rust的源代码中,rust/src/tools/rust-analyzer/crates/load-cargo/src/lib.rs文件的作用是实现了一个库,用于加载和解析Cargo项目的配置和元数据。
LoadCargoConfig是一个配置结构体,用于指定如何加载和处理Cargo项目。它包含了各种设置,比如项目文件夹、工作目录、环境变量等。
ProjectFolders是一个结构体,用于表示Cargo项目的文件夹结构。它包含了项目根目录、源代码目录等信息。
SourceRootConfig是一个结构体,用于表示源代码根目录的配置。它包含了源代码目录、是否解析测试目录、是否解析外部包等信息。
Expander是一个trait,定义了宏扩展器的接口。proc_macro_api::ProcMacro是实现了Expander trait 的宏扩展器。
IdentityExpander是一个结构体,实现了Expander trait,并提供了一个简单的宏扩展器,它仅返回输入的代码,不做任何处理。
EmptyExpander是一个结构体,实现了Expander trait,并提供了一个空的宏扩展器,它不做任何处理,始终返回空的代码。
ProcMacroServerChoice是一个枚举类型,用于表示宏扩展服务器的选择。它包含了两个选项:Custom表示用户指定的宏扩展服务器,Start表示自动启动的宏扩展服务器。
以上是对rust/src/tools/rust-analyzer/crates/load-cargo/src/lib.rs文件中的几个结构体和枚举类型的简要介绍,它们在加载和解析Cargo项目时起到了不同的作用。
File: rust/src/tools/rust-analyzer/crates/sourcegen/src/lib.rs
rust/src/tools/rust-analyzer/crates/sourcegen/src/lib.rs文件是Rust分析器工具(rust-analyzer)中的一个源代码生成器模块,用于生成Rust源代码的辅助工具。
该文件中定义了一些用于生成源代码的数据结构和函数。其中,CommentBlock struct代表一个注释块,用于在生成的代码中插入注释。它包含了注释的内容和注释的位置信息。CommentBlock struct有以下字段:
content: 字符串,表示注释的内容。location: Location struct,表示注释所在的位置。
Location struct代表源代码中的一个位置,它包含了文件路径、行号和列号等信息。Location struct有以下字段:
file: 字符串,表示文件的路径。line: 无符号整数,表示所在行的行号。col: 无符号整数,表示所在列的列号。
这些数据结构和函数的目的是为了方便在生成Rust源代码时插入注释和定位注释的位置。通过使用这些结构和函数,开发者可以在生成的源代码中灵活地插入注释,提高代码的可读性和可维护性。
总之,该文件中的数据结构和函数是rust-analyzer工具中用于生成Rust源代码的辅助工具,提供了注释块和位置信息的定义和操作,可以方便地插入和定位注释。
File: rust/src/tools/rust-analyzer/crates/toolchain/src/lib.rs
文件 lib.rs 是 toolchain crate 的入口文件,它定义了 toolchain crate 的主要功能和结构。
首先,lib.rs 文件中包含了一些必要的引用,这些引用是为了与其他 crate 进行交互和使用,如 std::path 和 std::fs 等。然后,文件中定义了 crate 的核心结构体 Toolchain,用于表示一个 Rust 工具链。
Toolchain 结构体具有以下字段:
path:表示工具链的路径。这个字段是一个PathBuf类型,用于指定工具链所在的路径。rustc:表示rustc的路径。这个字段是一个PathBuf类型,用于指定 Rust 编译器rustc的路径。cargo:表示cargo的路径。这个字段是一个PathBuf类型,用于指定 Rust 构建系统cargo的路径。
接下来,Toolchain 结构体还定义了一些方法,用于对工具链进行操作和查询。其中的一些重要方法包括:
discover:用于从指定的路径中发现 Rust 工具链。它会检查路径中是否存在rustup、rustc和cargo,并将其作为工具链的路径和二进制文件路径存储起来。parse:用于解析工具链路径以获取工具链信息,并存储到Toolchain结构体中的相应字段中。to_string:将整个工具链路径转换为一个字符串。is_custom_toolchain:检查工具链是否是自定义工具链。set_as_global:将工具链设置为全局工具链。override_platform:在给定工具链上覆盖目标平台。
此外,文件中还包含了一些其他辅助函数,用于从字符串中解析版本号、检查文件是否存在等操作。
总体来说,rust-analyzer/crates/toolchain/src/lib.rs 文件定义了 toolchain crate 的数据结构和方法,通过这些方法可以对 Rust 工具链进行自动发现、解析、操作和查询。
File: rust/src/tools/rust-analyzer/lib/la-arena/src/map.rs
在Rust源代码中,rust/src/tools/rust-analyzer/lib/la-arena/src/map.rs 是一个用于实现基于 Arena 数据结构的 Map(映射)的文件。
首先,ArenaMap 结构是 Arena Map 的主要实现。它使用 Idx 作为键(key)类型,T 作为值(value)类型。ArenaMap 使用 Arena 数据结构来存储键值对。Arena 是一种高效的内存分配方式,它可以在一个连续的内存块上分配新的结构体实例,并保证这些实例之间的内存布局是连续的。因此,ArenaMap 可以提供更好的性能,因为它们的数据可以在内存中紧凑地存储,减少了内存碎片和指针跳转。
然后,ArenaMapIter 结构是用于迭代 ArenaMap 中所有键值对的迭代器。它使用 Idx 作为键类型,(&'a T, &U)(其中 T、U 是值类型)作为迭代器的元素类型。它通过在 Arena 中依次访问存储的键值对来实现迭代。
接下来,VacantEntry 和 OccupiedEntry 结构分别表示 ArenaMap 中一个插槽(slot)为空的情况和被占用的情况。它们用于在 ArenaMap 中插入、删除和查找键值对。VacantEntry 允许在该插槽中插入新的键对应的值,并返回一个引用来操作这个新的值。OccupiedEntry 允许访问和修改一个已经存在的键对应的值。
最后,Entry 枚举用于表示一个键在 ArenaMap 中的状态。它有两个变体:Vacant 和 Occupied。Vacant 变体表示键不存在于 ArenaMap 中,而 Occupied 变体表示键已经存在于 ArenaMap 中。
综上所述,rust/src/tools/rust-analyzer/lib/la-arena/src/map.rs 文件中的结构体和枚举用于实现基于 Arena 数据结构的 Map,提供高效的插入、删除和查找操作,并提供了相应的迭代器以及操作 Map 中各个键值对的方法。
File: rust/src/tools/rust-analyzer/lib/la-arena/src/lib.rs
在Rust源代码中,rust/src/tools/rust-analyzer/lib/la-arena/src/lib.rs文件主要定义了一些用于管理内存分配和索引的数据结构和算法。下面对于文件中的几个重要结构进行详细介绍:
-
RawIdx(u32):这是一个简单的包装类型,用于表示无类型的索引。在
Arena<T>结构中,使用RawIdx作为内部索引的类型,可以减少内存占用和提高性能。 -
Idx:这是一个泛型结构,它用于表示
Arena<T>中存储的元素的索引。该结构包含一个RawIdx类型字段,并提供了一些方便的方法来操作索引值,如比较、转换、增减等。 -
IdxRange:这是一个范围结构,用于表示
Idx<T>类型的连续范围。它包含一个起始索引和一个结束索引,用于表示Arena<T>中一段连续的元素。 -
Arena:这是一个泛型结构,用于管理元素类型为T的动态数组。它使用
RawIdx作为内部索引的类型,并使用连续的内存块来存储元素。Arena<T>提供了一系列方法来操作元素,例如插入、删除、获取、迭代等。它还提供了内存池的功能,可以高效地重用已删除元素的内存空间。 -
IntoIter(Enumerate<Vec>):这是一个迭代器结构,用于在
Arena<T>上进行迭代。它采用惰性求值的方式,通过内部的Enumerate<Vec<T>>迭代器来遍历Arena<T>中的元素。迭代器返回的是一个元组(Idx<T>, &T),其中包含了元素的索引和引用。
综上所述,rust/src/tools/rust-analyzer/lib/la-arena/src/lib.rs文件定义了一些基本的数据结构和算法,用于管理内存分配和索引。Arena<T>和Idx<T>主要用于实现高效的内存管理和索引访问,而IdxRange<T>和IntoIter<T>则提供了更方便的范围和迭代操作。这些结构使得在Rust代码中可以更便捷地进行内存管理和元素访问。
File: rust/src/tools/rust-analyzer/lib/line-index/src/lib.rs
文件rust/src/tools/rust-analyzer/lib/line-index/src/lib.rs是Rust语言的语法分析器rust-analyzer的一个核心组件,用于处理代码的行列信息。它提供了用于处理和查询代码行列信息的数据结构和算法。
以下是对每个结构体的详细介绍:
-
LineCol:
LineCol结构体表示单个字符的行列位置。它具有两个字段:line和col,分别表示代码中的行号和列号。此结构体用于定位代码中的特定位置。 -
WideLineCol:
WideLineCol结构体表示Unicode字符的行和列位置。与LineCol相比,WideLineCol结构体能够正确处理宽字符(Unicode字符宽度大于1)。它同样具有line和col字段,也用于定位特定字符位置。 -
WideChar:
WideChar结构体表示Unicode字符的宽度和字节索引。它具有width和byte_index字段,用于指示Unicode字符的宽度和在原始字节序列中的索引。 -
LineIndex:
LineIndex结构体是对代码的快速行索引的表示。它是通过将源代码拆分为行,并存储每一行的起始字节索引,来支持快速行查询的结构。LineIndex还提供了一些方法,可以通过字符位置(LineCol或WideLineCol)查找行,并计算行号和列号。
对于WideEncoding枚举,它提供了与字符编码相关的宽字符处理功能。该枚举包含以下几个变体:
-
Utf16:
Utf16变体表示UTF-16编码的字符。 -
Utf8:
Utf8变体表示UTF-8编码的字符。 -
Utf8Lossy:
Utf8Lossy变体表示在出现无效的UTF-8字节序列时,通过替代字符(�)进行宽字符处理。
这些WideEncoding变体用于处理不同类型的字符编码,并提供了间接的方法来计算字符的宽度和字节索引。
总之,rust/src/tools/rust-analyzer/lib/line-index/src/lib.rs文件中的LineCol、WideLineCol、WideChar、LineIndex结构体和WideEncoding枚举提供了rust-analyzer语法分析器中处理代码行列信息的重要组件。它们用于定位代码中的特定位置,支持宽字符的处理,并提供行索引和字符编码相关的功能。
lib
Crates in this directory are published to crates.io and obey semver.
They could live in a separate repo, but we want to experiment with a monorepo setup.
We use these crates from crates.io, not the local copies because we want to ensure that
rust-analyzer works with the versions that are published. This means if you add a new API to these
crates, you need to release a new version to crates.io before you can use that API in rust-analyzer.
To release new versions of these packages, change their version in Cargo.toml. Once your PR is merged into master a workflow will automatically publish the new version to crates.io.
While prototyping, the local versions can be used by uncommenting the relevant lines in the
[patch.'crates-io'] section in Cargo.toml
File: rust/src/tools/rust-analyzer/lib/lsp-server/examples/goto_def.rs
在Rust源代码中,rust/src/tools/rust-analyzer/lib/lsp-server/examples/goto_def.rs文件的作用是实现了一个用于处理LSP(Language Server Protocol)命令的示例程序,该命令用于查找给定符号的定义位置,并将光标移动到该定义位置。
具体来说,该文件中包含一个名为goto_def的函数,该函数是处理gotoDefinition请求的入口点。当语言服务器接收到gotoDefinition请求时,会调用该函数来处理请求。
在函数内部,首先会获取请求中指定的文件路径和光标位置信息。然后,使用Rust分析器(rust-analyzer)提供的功能,对指定的符号调用goto_definition函数,以找到该符号的定义位置。
goto_definition函数使用语言服务器自动创建的Rust抽象语法树(AST)来分析Rust源代码,并查找给定符号的定义位置。一旦找到定义位置,函数会将其格式化为LSP规定的位置(行号和列号)格式,并作为响应返回给客户端。
此示例程序的目的是展示如何使用Rust分析器和LSP来实现基本的“跳转到定义”功能。它可以为开发者提供一个参考,用于了解如何在自己的LSP服务器中实现类似的功能。
需要注意的是,该示例程序只是演示了一种可能的实现方式,实际的语言服务器中可能会根据具体需求进行不同的实现。
File: rust/src/tools/rust-analyzer/lib/lsp-server/src/stdio.rs
在Rust源代码中,rust-analyzer/lib/lsp-server/src/stdio.rs 文件的作用是实现了与标准输入输出(STDIO)进行通信的LSP(Language Server Protocol)服务器。LSP服务器是一种用于提供代码编辑器功能的服务器,它接收来自客户端的请求,并返回相应的响应。
该文件中定义了一个名为 StdioServer 的结构体,它实现了 lsp_server::Server trait,并通过 STDIO 进行与客户端的通信。该结构体主要完成以下任务:
-
实现与客户端的通信:通过读取标准输入流(STDIN)来接收来自客户端的请求,分析请求的类型,并触发相应的方法来处理请求。然后通过将响应写入标准输出流(STDOUT)将结果发送回客户端。
-
处理请求和响应:通过调用
initialize、shutdown、completion等方法,处理不同类型的请求,例如初始化服务器、关闭服务器和提供代码自动补全等功能。 -
管理请求和响应的状态:确保响应按照请求的顺序返回给客户端,并记录请求的状态,以便在需要时检查和处理。
此外,StdioServer 还依赖于 lsp_server::Message 和 lsp_server::Connection 结构体,它们分别用于解析和处理来自客户端的消息,并与客户端建立连接。
关于 IoThreads 结构体,它定义了用于处理 STDIN 和 STDOUT 的 I/O 线程池。它包含两个字段:
-
next_io_thread:一个AtomicUsize类型的原子计数器,用于轮询选择下一个可用的 I/O 线程。 -
io_threads:一个Vec类型的线程池,用于处理 STDIN 和 STDOUT 的 I/O 操作。
这些结构体的作用是通过多线程处理 STDIO 的输入和输出,以提高性能并确保流畅的消息传递。在 STDIO 进行通信时,多个线程可以同时处理输入和输出,从而减少了阻塞和等待的时间,提高了处理速度和效率。
File: rust/src/tools/rust-analyzer/lib/lsp-server/src/socket.rs
文件rust/src/tools/rust-analyzer/lib/lsp-server/src/socket.rs是Rust语言的一个源代码文件,它在Rust语言的语言服务器工具rust-analyzer中实现了与客户端之间的通信。
在LSP(Language Server Protocol)中,客户端和语言服务器通过一个socket(套接字)进行通信。socket.rs文件定义了一种Socket类型,该类型封装了与客户端建立连接、读取和写入数据等操作。
具体来说,socket.rs文件中定义了以下结构和函数:
-
Socket类型:Socket类型封装了与客户端的连接。它具有一个内部的
TcpStream字段,通过这个字段可以进行读取和写入。Socket类型提供了一系列方法,如new用于新建Socket对象,connect用于与客户端建立连接,read_message用于读取客户端发送的消息,write_message用于向客户端发送消息等。 -
read_message函数:read_message函数通过调用Socket的read方法,从客户端读取字节流并将其解析为一个LSP请求或响应。它能够处理读取时的各种异常情况,并返回相应的结果。
-
write_message函数:write_message函数通过调用Socket的write方法,将一个LSP请求或响应转换成字节流并写入到Socket中,发送给客户端。它能够处理写入时的各种异常情况,并返回相应的结果。
上述的Socket类型、read_message函数和write_message函数是整个LSP服务器与客户端通信的核心部分,通过实现这些功能,可以实现与客户端的双向通信,接收和处理客户端发送的请求,以及向客户端发送响应。
总的来说,socket.rs文件是Rust语言的LSP服务器工具rust-analyzer中用于实现与客户端之间通信的关键部分。它定义了Socket类型和相关的读写函数,通过与客户端建立连接并读取、写入消息,实现了LSP协议规定的通信机制。通过socket.rs文件,rust-analyzer可以与各种支持LSP的编辑器进行通信,提供代码分析、补全、重构等功能。
File: rust/src/tools/rust-analyzer/lib/lsp-server/src/error.rs
在Rust源代码中,rust-analyzer是一个用于提供Rust语言服务器功能的工具,负责处理LSP(Language Server Protocol)的请求和响应。其中,rust/src/tools/rust-analyzer/lib/lsp-server/src/error.rs文件定义了一些与错误处理相关的结构体和枚举。
在该文件中,ProtocolError是一个公共的结构体,使用pub(crate)修饰,表示只在当前crate内可见。它用于表示与LSP协议相关的错误。 这个结构体有以下几个字段:
code: 表示错误代码。message: 表示错误信息。data: 表示一些与错误相关的附加数据。
ExtractError是一个枚举类型,表示从请求或响应中解析出错的错误。这个枚举有以下几个变体:
MissingField: 表示缺少字段错误。InvalidField: 表示字段无效错误。InvalidType: 表示类型无效错误。Custom: 表示自定义的解析错误。
这些错误类型用于帮助解析LSP请求和响应时出现的错误,以便进行适当的错误处理。
这些结构体和枚举的定义主要用于在rust-analyzer中的LSP服务器中对错误进行建模和处理。通过定义适当的错误类型,可以更好地理解和处理来自客户端的LSP请求和响应中可能出现的错误,以提供更好的错误信息和处理方式。
File: rust/src/tools/rust-analyzer/lib/lsp-server/src/lib.rs
在Rust源代码中,rust/src/tools/rust-analyzer/lib/lsp-server/src/lib.rs这个文件是实现Rust-Analyzer的Language Server Protocol(LSP)服务器的主要代码文件。
LSP是一种标准化的协议,用于在开发工具和编辑器之间进行通信,以提供代码补全、代码导航、重构等功能。Rust-Analyzer是Rust语言的一个可扩展的分析器,它通过实现LSP服务器,为支持LSP的编辑器提供了强大的代码分析功能。
lib.rs中的代码实现了LSP服务器的核心逻辑,包括与客户端的通信、处理LSP请求、解析和处理LSP协议消息等。
其中,Connection结构体表示与客户端的连接,并提供与客户端进行通信的方法。它包含输入输出流(input/output stream),用于在服务器和客户端之间传输LSP消息。Connection还提供了解析JSON格式的LSP消息和序列化LSP响应的功能。
TestCase结构体用于定义单元测试用例。Rust-Analyzer的LSP服务器需要经过测试以确保其正确性和稳定性。TestCase结构体中定义了测试数据和期望的输出,用于执行对LSP服务器的功能进行自动化测试。这些测试用例可以验证LSP请求的处理逻辑是否按预期工作。
总的来说,rust/src/tools/rust-analyzer/lib/lsp-server/src/lib.rs文件实现了Rust-Analyzer的LSP服务器的核心逻辑,并提供与客户端通信的功能。Connection结构体用于管理与客户端的连接,而TestCase结构体用于定义LSP服务器的单元测试用例。
File: rust/src/tools/rust-analyzer/lib/lsp-server/src/req_queue.rs
文件req_queue.rs中定义了ReqQueue结构体,用于处理LSP请求的队列。
ReqQueue:
该结构体使用双向链表表示的一个请求队列,其中I是请求的类型参数。它包含以下字段和方法:
- requests:用于存储请求的双向链表。
- pending_id:用于为新的请求生成唯一的标识符。
- next_id:指示下一个请求的唯一标识符。
- task_slots:最大并发任务数。
- task_pool:一个任务池,用于处理请求的回调函数。
- task_queue:一个任务队列,存储等待处理的请求。
Incoming:
该结构体是对输入请求的封装,其中I是请求的类型参数。它包含以下字段:
- id:请求的唯一标识符。
- request:实际的请求。
Outgoing:
该结构体是对输出请求的封装,其中O是响应的类型参数。它包含以下字段:
- id:请求的唯一标识符。
- response:实际的响应。
ReqQueue结构体的主要作用是处理输入的LSP请求。当收到一个新的请求时,它会生成一个唯一的标识符作为请求的id,并将其封装成Incoming结构体的形式,然后将其添加到请求队列中。
ReqQueue结构体提供了一些方法来处理和管理请求队列:
- submit:将一个请求添加到队列中。
- finish_with:标记特定请求已完成并填充响应。
- handle_shutdown:处理服务器关闭请求。
- start_next_task:开始处理下一个请求任务。
- tick:任务的调度函数,用于执行请求队列中的任务。
整个流程如下:
- 当收到一个新的请求时,将其封装成Incoming结构体的形式,并通过submit方法添加到请求队列中。
- start_next_task方法会检查当前任务数是否小于最大并发任务数,并开始处理下一个请求任务。
- 当任务完成后,会通过finish_with方法对请求进行标记,并将响应存储在请求队列中的对应Outgoing结构体中。
- 在tick方法中,会检查是否有未处理的请求任务,如果有,则通过task_pool和task_queue来处理请求并获取响应。
通过以上的结构和流程,ReqQueue结构体实现了请求队列的管理,能够处理并发请求并返回响应,从而使Rust源代码能够有效地处理LSP请求。
File: rust/src/tools/rust-analyzer/lib/lsp-server/src/msg.rs
在Rust的源代码中,rust/src/tools/rust-analyzer/lib/lsp-server/src/msg.rs 这个文件定义了与 Language Server Protocol (LSP) 相关的消息类型和处理逻辑。
以下是相关结构和枚举类型的详细介绍:
-
RequestId(IdRepr):这是一个包装了请求的唯一标识符的结构体。IdRepr是一个表示请求标识符的具体类型,可以是数字、字符串或其他合法类型。 -
Request:表示一个发出的请求消息,包含了请求的方法名称和参数。 -
Response:表示对一个请求的响应消息,包含了响应的结果或错误信息。 -
ResponseError:表示一个请求的错误信息,包含了错误码和错误消息。 -
Notification:表示一条通知消息,不需要请求响应。 -
JsonRpc:是一个涵盖了所有 LSP 消息类型的枚举。它包含了Request、Response和Notification这三种消息类型,以及对应的字段。 -
Message:代表了 LSP 客户端和服务器之间通信的消息类型。它是一个包含了 LSP 消息内容的枚举,可以是请求、响应或通知消息。 -
IdRepr:是请求的唯一标识符的内部表示。它可以是数字、字符串或其他合法类型,用于唯一地标识每个请求。 -
ErrorCode:定义了 LSP 错误码的枚举。当处理请求时发生错误,可以使用这些错误码来返回适当的错误信息。
这些结构体和枚举类型在 LSP 通信协议中起到了关键的作用,用于表示不同类型的消息、请求、响应和通知,以及处理错误信息。
# File: rust/src/tools/rust-analyzer/xtask/src/release.rs在Rust源代码中,rust/src/tools/rust-analyzer/xtask/src/release.rs文件是一个用于构建和发布Rust分析器(Rust Analyzer)的脚本。Rust Analyzer是一个Rust语言的LSP(Language Server Protocol)工具,用于提供代码编辑功能,如代码自动完成、语法检查、重构等。release.rs文件定义了一系列任务和功能,主要用于构建、测试和发布Rust Analyzer。它使用了一些外部工具和库,例如CMake、cargo、gzip和tar等。以下是release.rs文件的一些关键功能和任务:1. 设置构建环境:脚本首先会检查相关依赖工具和库是否已安装,并设置构建环境的路径和变量,以确保编译和构建过程的顺利进行。2. 编译和构建:脚本会自动执行编译和构建Rust Analyzer的过程。它会使用CMake来生成构建系统,并调用cargo进行实际的编译和构建操作。脚本可以根据需要选择不同的构建选项,如开启或关闭某些特性或插件。3. 运行测试:脚本包含一系列测试任务,用于验证Rust Analyzer的正确性和性能。这些测试任务可以包括单元测试、集成测试和基准测试等。脚本会自动运行这些测试,并输出测试结果。4. 打包发布:脚本包含了发布Rust Analyzer的任务。它会创建一个发布版本的压缩包,并将构建好的可执行文件、依赖库和配置文件等打包到该压缩包中。脚本还可以生成不同平台和操作系统的发布版本,以满足用户的不同需求。5. 发布到Crates.io:脚本提供了一个任务,用于将Rust Analyzer发布到Crates.io,这是Rust语言的包管理平台。这样可以方便其他开发者使用和安装Rust Analyzer。总体来说,rust/src/tools/rust-analyzer/xtask/src/release.rs文件是一个重要的脚本,用于简化和自动化Rust Analyzer的构建、测试和发布过程。它提供了一系列任务和功能,以方便开发者进行开发和使用Rust Analyzer,并确保其质量和稳定性。# File: rust/src/tools/rust-analyzer/xtask/src/main.rsrust/src/tools/rust-analyzer/xtask/src/main.rs是Rust源代码中的一个文件,它在rust-analyzer工具的xtask模块中扮演着重要的角色。首先,rust-analyzer是一个Rust语言的语法分析器和代码编辑器插件,用于提供代码自动补全、跳转定义、查找引用等功能。而xtask模块是该工具的辅助工具,用于编写和管理Rust源代码的构建脚本和任务。它提供了一系列的命令行工具和测试,用于开发和维护Rust源代码。在rust-analyzer的xtask中,main.rs文件定义了主要的入口函数,负责处理命令行参数和调度任务。它启动并管理各个子任务,包括编译、运行测试、格式化代码等。main.rs文件使用了Rust语言的标准库中的相关功能,如argparse库用于解析命令行参数,walkdir库用于遍历目录,proc-macro2库用于处理Rust的过程宏等。除了任务的调度,main.rs文件还负责加载并执行各个子任务的代码。每个子任务对应一个单独的Rust源代码文件,如compile.rs、fmt.rs和test.rs等,这些文件实现了具体的功能逻辑。main.rs文件负责根据用户的命令行参数调用相应的子任务,并根据任务的执行结果输出相应的日志和错误信息。总而言之,rust-analyzer/xtask/src/main.rs文件是rust-analyzer工具的核心文件,负责调度和管理各个子任务,并提供了命令行接口供用户使用。通过这个文件,开发者可以方便地使用和扩展rust-analyzer工具,进行Rust源代码的开发和维护。# File: rust/src/tools/rust-analyzer/xtask/src/metrics.rs在Rust源代码中,`rust/src/tools/rust-analyzer/xtask/src/metrics.rs`文件是用于定义度量指标(metrics)和主机(host)的工具。该工具在执行编译和其他任务时用于统计和收集有关Rust项目的信息。该文件中包含了两个结构体:`Metrics`和`Host`。`Metrics`结构体用于存储度量指标的信息,主要用于记录各种操作的计数和耗时。它包含了各种度量指标的字段,例如编译时间、内存使用量等。通过记录这些指标,开发人员可以更好地了解项目的性能和效率,并进行优化。`Metrics`结构体还提供了方法用于更新和打印度量指标的信息。`Host`结构体是用于主机相关的操作的工具。这些操作包括创建和销毁临时目录、运行命令、监控进程等。`Host`结构体封装了许多系统级的功能,使得代码可以更方便地执行这些操作。通过使用`Host`结构体,`metrics.rs`文件可以在度量指标的收集过程中扮演指导者的角色,并与底层系统进行交互。总的来说,`metrics.rs`文件在Rust源代码中的`rust-analyzer`工具中起到了收集和统计度量指标的作用,用于帮助开发人员分析项目的性能,并提供了与主机系统交互的功能。# File: rust/src/tools/rust-analyzer/xtask/src/release/changelog.rsrust/src/tools/rust-analyzer/xtask/src/release/changelog.rs是Rust编程语言的Rust Analyzer工具的一个文件,其作用是生成发布日志。在这个文件中,定义了一些结构体(struct)和枚举(enum)来帮助生成发布日志。其中,PrInfo结构体表示一个Pull Request(PR)的信息,包含PR的标题、作者和链接等。PrKind枚举表示PR的类型,包括Bug修复、新功能、性能改进等。具体来说,PrInfo结构体有以下字段:
- title: PR的标题
- author: PR的作者的GitHub用户名
- pr: PR的链接
- kind: PR的类型(PrKind枚举)
- breaking_change_description: 如果PR有破坏性改变的描述,比如API的变动等
- nodejs_version: PR对应的Node.js版本(如果适用)
- motivation: PR的动机和背景
- backport_requests: 如果PR需要进行回溯(backport)到之前的版本,记录这些版本号而PrKind枚举有以下成员:
- Unknown: 未知类型
- BugFix: Bug修复
- Feature: 新功能
- PerformanceImprovement: 性能改进
- Refactoring: 重构
- Lint: Lint改进
- Tooling: 工具改进
- Documentation: 文档改进
- Internal: 内部改进
- Dependency: 依赖项改进
- Maintenance: 维护这些结构体和枚举用于在生成发布日志时提供相关的信息,包括PR的类型、作者、标题等,以及是否有破坏性改变。这样可以帮助开发人员更好地了解每个版本的变动,并将这些信息整理成易于阅读的发布日志。# File: rust/src/tools/rust-analyzer/xtask/src/dist.rsrust/src/tools/rust-analyzer/xtask/src/dist.rs文件的作用是为Rust分发工具提供一些辅助函数和数据结构。它定义了Target和Patch这两个结构体,用于描述不同目标操作系统上的分发目录,并且提供了一些功能函数来处理这些目标。Target结构体用于描述不同操作系统上的分发目录。它包含了目标操作系统的名称、目标目录的路径、目标的元数据(如配置文件等)等信息。通过Target结构体,可以确定特定操作系统上适用的分发目录。Patch结构体用于描述要应用的补丁。补丁是针对某个目标操作系统上的特定分发目录的修改。Patch结构体包含了补丁的来源、补丁的路径、补丁的目标文件路径等信息。通过Patch结构体,可以实现在特定操作系统上对分发目录进行定制化修改。dist.rs文件还提供了一些功能函数来处理目标和补丁。例如,`find_target()`函数可以根据给定的目标系统名称查找对应的Target结构体。`find_patch()`函数可以根据给定的目标系统名称和要修改的分发目录路径,查找对应的Patch结构体。其他辅助函数还包括对目标和补丁进行解析、验证等操作。总而言之,dist.rs文件在Rust源代码中提供了一些辅助函数和数据结构,用于处理Rust分发工具的目标操作系统和定制化修改。通过这些函数和数据结构,可以方便地对不同操作系统上的分发目录进行管理和定制化操作。# File: rust/src/tools/rust-analyzer/xtask/src/publish/notes.rs在Rust源代码中,`rust-analyzer`是一个开源的Rust语言服务器,负责提供代码分析和编辑功能。在该代码库中的`xtask/src/publish/notes.rs`文件是`rust-analyzer`中的一个工具模块,它负责将文本文件转换为带有标注的文档。具体来说,`notes.rs`文件中包含了几个重要的结构体和枚举类型,如下所示:1. `Converter<'a>`:这是一个泛型结构体,用于将文本文件转换为带有标注的文档。它接收一个字符串的切片作为输入,并生成一个表示带有标注的文档的数据结构。2. `ListNesting(Vec<ListMarker>)`:这是一个带有列表标记的向量结构体,用于表示嵌套的列表结构。它包含了一个`ListMarker`枚举的向量,用于表示每个列表项的标记类型。3. `Macro`:这是一个枚举类型,用于表示宏的类型。它包含了不同类型的宏,如`Include`、`Define`等。4. `ListMarker`:这是一个枚举类型,用于表示列表项的标记类型。它包含了不同类型的列表标记,如`Bullet`、`Number`、`Line`等。5. `Component`:这是一个枚举类型,用于表示文档的组件类型。它包含了不同类型的组件,如`List`、`Paragraph`、`Heading`、`CodeBlock`等。通过这些结构体和枚举类型,`notes.rs`文件提供了对文本文件中的各种元素(如列表、宏、段落等)进行解析和转换的功能。它能够将输入的文本文件转换为具有结构化标注的文档,方便后续进行语法分析和代码编辑等操作。# File: rust/src/tools/rust-analyzer/xtask/src/install.rs在Rust源代码中,`rust/src/tools/rust-analyzer/xtask/src/install.rs`文件的作用是安装`rust-analyzer`工具。`rust-analyzer`是Rust语言的语法分析器和IDE支持工具。该文件定义了一些结构体和枚举,用于配置和安装`rust-analyzer`。`ClientOpt`是结构体,用于配置`rust-analyzer`客户端的行为。它具有以下字段:
- `root`:用于指定工作区的根目录。
- `client`:指定客户端要使用的端口号。
- `log_file`:指定日志输出文件的路径。`ServerOpt`是结构体,用于配置`rust-analyzer`服务器的行为。它具有以下字段:
- `version`:指定要安装的`rust-analyzer`版本。
- `watch`:一个布尔值,指定在文件更改时是否重新启动服务器。
- `no_output`:一个布尔值,指定是否禁止输出。`Malloc`是枚举,用于指定用于分配内存的方式,具有以下选项:
- `system`: 使用系统分配器。
- `mimalloc`: 使用`mimalloc`分配器。
- `jemalloc`: 使用`jemalloc`分配器。这些枚举选项可以用于配置`rust-analyzer`的内存分配行为。通过这些结构体和枚举,`install.rs`文件提供了一种自定义和配置`rust-analyzer`工具的方式,以适应不同的使用场景和需求。# File: rust/src/tools/rust-analyzer/xtask/src/publish.rs`publish.rs` 文件是 Rust 编程语言的代码仓库中 `rust-analyzer` 工具的 `xtask` 构建工具的一部分,它负责实现发布 `rust-analyzer` 的构建和分发功能。以下是详细的介绍。`rust-analyzer` 是一个用于提供前端开发支持的 IDE 插件,针对 Rust 编程语言。`rust-analyzer` 提供了诸如代码补全、代码导航、语法高亮、错误提示等功能,以便开发人员更高效地编写 Rust 代码。为了将 `rust-analyzer` 分发给用户和集成到不同的开发环境中,需要使用 `publish.rs` 文件来构建和分发。首先,`publish.rs` 文件定义了一个名为 `publish_cli` 的函数,该函数接收一组命令行参数并解析它们。这些参数包括目标平台、发布版本号和 GitHub API 密钥等信息,这些信息用于构建和发布 `rust-analyzer`。接下来,`publish_cli` 函数会检查 Rust 编译器版本是否符合要求,并在版本不正确时输出错误信息。然后,`publish_cli` 函数会构建 `rust-analyzer` 的二进制文件。它会调用 `cargo` 命令进行编译,并使用 `--release` 参数指定构建发布版本的二进制文件。完成构建后,`publish_cli` 函数会检查是否设置了 GitHub API 密钥,并将其用于构建和发布操作。它使用 Rust 中的 `reqwest` 包向 GitHub API 发送请求,执行与版本发布相关的操作,例如创建发布标签、上传二进制文件、发布预览版本等。它还会将构建过程的输出信息打印到控制台。最后,`publish_cli` 函数会在构建和发布操作完成后输出成功或失败的信息,并返回适当的退出状态码。`publish.rs` 文件的核心功能是通过调用编译器和 GitHub API,实现构建和发布 `rust-analyzer`。它简化了构建和分发过程,并提供了命令行界面以便于使用。# File: rust/src/tools/rust-analyzer/xtask/src/flags.rs在Rust源代码中,rust/src/tools/rust-analyzer/xtask/src/flags.rs文件的作用是定义了一系列的命令行选项和相关的数据结构,用于配置和控制xtask工具的行为。具体来说,该文件中定义了以下几个主要数据结构和枚举:1. Xtask: 这是一个struct,表示xtask工具的配置选项。它包含了一系列可选的标志和参数,用于控制xtask的行为。比如,可以设置是否启用某个功能、指定某个目录的路径等。2. Install: 这是一个struct,表示xtask的Install命令的配置选项。它包含了一系列标志和参数,用于指定安装的选项,如安装路径、是否开启某个功能等。3. FuzzTests: 这是一个struct,表示xtask的FuzzTests命令的配置选项。它包含了一系列标志和参数,用于指定进行模糊测试的选项,如测试样本的数量、测试时间限制等。4. Release: 这是一个struct,表示xtask的Release命令的配置选项。它包含了一系列标志和参数,用于指定发布的选项,如发布的版本号、发布的目标平台等。5. Promote: 这是一个struct,表示xtask的Promote命令的配置选项。它包含了一系列标志和参数,用于指定推广的选项,如推广的目标平台、是否发布等。6. Dist: 这是一个struct,表示xtask的Dist命令的配置选项。它包含了一系列标志和参数,用于指定构建分发版本的选项,如构建的类型、构建的目标平台等。7. PublishReleaseNotes: 这是一个struct,表示xtask的PublishReleaseNotes命令的配置选项。它包含了一系列标志和参数,用于指定发布发布说明的选项,如发布的版本号、发布的目标平台等。8. Metrics: 这是一个struct,表示xtask的Metrics命令的配置选项。它包含了一系列标志和参数,用于指定统计指标的选项,如统计的时间范围、统计的维度等。9. Bb: 这是一个struct,表示xtask的Bb命令的配置选项。它包含了一系列标志和参数,用于指定构建位板的选项,如构建的类型、构建的目标平台等。10. XtaskCmd: 这是一个enum,用于表示xtask的命令类型。它包含了Xtask工具支持的各种命令,如安装、构建、发布等。通过此枚举可以选择不同的命令类型,并传递给xtask进行相应的操作。11. MeasurementType: 这是一个enum,用于表示统计指标的类型。它包含了不同的统计指标类型,如编译时间、构建大小等。通过此枚举可以选择不同的统计指标类型,并进行相应的操作。总体而言,flags.rs文件定义了一系列的结构体和枚举,用于配置和控制xtask工具的行为,在命令行中传递不同的选项和参数,以完成不同的任务。# File: rust/src/tools/rustdoc-themes/main.rs在Rust源代码中,`rust/src/tools/rustdoc-themes/main.rs`文件的作用是创建和管理`rustdoc`文档生成工具所使用的主题。`rustdoc`是Rust的文档生成工具,允许开发者为他们的Rust程序自动生成文档。这些文档可以以HTML格式输出,并使用适当的样式和主题来提供更好的可读性和用户体验。`rustdoc-themes`工具用于管理这些主题。具体地说,`main.rs`文件实现了一个命令行工具,它提供了以下一些功能:1. 显示当前安装的主题列表:工具可以列出当前可用的主题,以供用户选择。2. 安装主题:用户可以从远程仓库或本地文件系统安装主题。工具会处理下载、解压和安装主题的过程。3. 删除主题:用户可以删除已安装的主题。4. 更新主题:用户可以更新已安装的主题到最新版本。5. 切换主题:用户可以选择将当前主题切换为其他可用主题。以上功能通过解析命令行参数来实现,用户可以通过命令行输入指定的命令和参数来执行相应的操作。`main.rs`文件使用Rust的标准库中的命令行解析库`clap`来处理命令行参数的解析。此文件还会调用其他辅助函数和模块来完成其任务,例如用于下载和解压主题包的模块、用于获取可用主题列表的模块等。总之,`rust/src/tools/rustdoc-themes/main.rs`文件实现了一个命令行工具,用于管理`rustdoc`文档生成工具所使用的主题,包括安装、删除、更新和切换主题等功能。# File: rust/src/tools/tier-check/src/main.rs在Rust源代码的rust/src/tools/tier-check/src/main.rs文件中,主要实现了一个名为"tier-check"的工具。该工具旨在帮助开发者检查Rust编译器的"编译层级",并生成有关Rust构建系统编译层级的信息。下面将对该文件的主要功能进行详细介绍:1. 导入依赖:首先,在文件的开头,会导入一些必要的依赖项,比如用于命令行解析和处理的依赖项。2. 定义结构体和常量:在文件中,定义了一些结构体和常量。其中最重要的是"Tier"结构体,它用于表示Rust编译层级的信息,包括层级的名称、编译测试的状态、编译测试的说明等。3. 定义函数:在文件中,定义了一些用于处理编译层级的函数。其中最重要的是:- `fn parse_args(args: &[String]) -> Res<Vec<Tier>>`:该函数用于解析命令行参数,并返回一个Result类型的值,其中包含了一个Tier类型的Vector,表示所有编译层级的信息。- `fn run_for_tier(tier: &Tier) -> Res<()>`:该函数用于为指定的编译层级执行编译测试,并返回一个Result类型的值,其中包含了成功或失败的信息。- `fn main()`:这是整个文件的主函数。它首先调用`parse_args`函数解析命令行参数,然后逐个调用`run_for_tier`函数来执行指定编译层级的编译测试。在函数的结尾,会输出层级检查结果的总结信息。4. 其他辅助函数:文件中还定义了一些辅助函数,用于输出帮助信息、错误信息等。综上所述,rust/src/tools/tier-check/src/main.rs这个文件的主要作用是实现"tier-check"工具,用于检查Rust编译器的编译层级,并提供有关Rust构建系统编译层级的信息。通过运行该工具,开发者可以了解Rust编译器不同层级的编译测试状态和说明。# File: rust/src/tools/lint-docs/src/groups.rs在Rust源代码中,`rust/src/tools/lint-docs/src/groups.rs` 文件的作用是定义和组织代码中的不同 lint 类型和其对应的组。 Lint 是一种用于静态代码分析的工具,它可以帮助开发者发现代码中的潜在问题和不良实践。该文件中的代码主要有以下几个部分:1. 导入依赖项: 该部分包含了一些 Rust 核心库和其他依赖项的导入语句,用于在代码中使用相应的结构和函数。2. Lint 组定义: 在该文件中,可以找到一系列的 Lint 组的定义。其中每个 Lint 组都由一个结构体表示,结构体中包含了组的名称、描述、以及组内所包含的具体 Lint 类型等信息。通过定义不同的 Lint 组,可以对不同类型的 Lint 进行分类和管理。3. Lint 类型定义: 除了 Lint 组的定义之外,该文件还包含了多个 Lint 类型的定义。每个 Lint 类型都由一个结构体表示,结构体中包含了 Lint 类型的名称、描述、以及与 Lint 类型相关的配置信息等。通过定义不同的 Lint 类型,可以对代码中的各种问题进行分类和标记。4. Lint 组和 Lint 类型的映射关系: 在 Rust 的代码中,一个 Lint 组可能包含多个 Lint 类型。在该文件中,通过使用 `LintGroups` 结构体和相关的宏定义,将不同的 Lint 类型与对应的 Lint 组进行映射和关联。总结来说,`rust/src/tools/lint-docs/src/groups.rs` 文件用于定义和组织 Rust 代码中的 Lint 组和 Lint 类型,帮助开发者进行静态代码分析和潜在问题的检测。它提供了一种结构化的方式来管理和分类不同类型的 Lint,并为开发者提供了一个工具去查找和解决代码中的潜在问题。# File: rust/src/tools/lint-docs/src/main.rs`rust/src/tools/lint-docs/src/main.rs` 是 Rust 编译器源代码中 `lint-docs` 工具的入口点文件。`lint-docs` 是一个用于生成 Rust lint 文档的工具。在 Rust 编译器中,lint 是一种静态代码分析工具,它用于检查代码中潜在的问题或不规范的用法,并给出相关的警告或建议。Rust 标准库和第三方库都可以定义自己的 lint,并通过编译器进行管理和应用。`lint-docs` 工具的目的是生成关于所有可用 lint 的文档,以供开发者参考。这些文档可以帮助开发者了解每个 lint 的目的、使用方法以及相关的配置选项。这对于初学者来说是一个很好的资源,可以帮助他们遵循规范编写代码,并充分利用 Rust 提供的静态分析功能。`lint-docs` 工具的主要功能如下:1. 解析编译器源代码中的 lint 定义和配置:通过分析 Rust 编译器源代码中的相关文件,`lint-docs` 工具可以获取所有现有的 lint 的定义和配置信息。2. 生成 lint 文档:根据解析的 lint 信息,`lint-docs` 工具可以生成包含所有 lint 的文档。这些文档通常会提供 lint 的名称、描述、用法示例、配置选项等信息。文档的格式可以是 HTML、Markdown 等,以方便浏览和查阅。3. 更新 lint 文档:当 Rust 编译器的 lint 集合发生变化时,`lint-docs` 工具可以自动更新生成的文档,以确保开发者可以获得最新的 lint 信息。总之,`lint-docs` 工具是一个用于生成 Rust lint 文档的工具,它通过解析编译器源代码中的 lint 定义和配置,可以帮助开发者了解每个 lint 的目的、使用方法以及相关的配置选项。这个工具对于开发者来说是一个很有用的资源,可以帮助他们更好地理解和使用 Rust 的静态分析功能。# File: rust/src/tools/lint-docs/src/lib.rs在Rust的源代码中,rust/src/tools/lint-docs/src/lib.rs文件的作用是提取Rust编译器中的lint规则,并生成为可供文档化的格式。该工具的主要目的是帮助开发者了解Rust中各种静态检查的规则及其相应的说明,并提供示例代码以帮助开发者理解和使用。主要的结构体和枚举类型有:1. LintExtractor<'a>:该结构体实现了对Rust编译器lint规则信息的提取。它包含了一些方法,用于从rustc中提取lint规则的详细信息,并将其转化为可供文档化的形式。2. Lint:Lint结构体代表一个lint规则,包含了lint规则的名称、描述、建议的修复方法等信息。LintExtractor使用Lint结构体来表示每个具体的lint规则。3. Level:Level是一个枚举类型,表示lint规则的严重程度。它包括以下几个成员:- Allow:表示在编译器中关闭该lint规则。- Warn:表示在编译器中以警告的形式启用该lint规则。- Deny:表示在编译器中以错误的形式启用该lint规则。编译器将不允许通过编译。- Forbid:表示在编译器中禁止使用该lint规则。编译器将报告一个错误,并中断编译过程。通过将lint规则的信息提取为可供文档化的格式,开发者可以很方便地查看和理解Rust编译器中各种lint规则的作用和适用情况,并根据需要选择性地启用、关闭或修改这些规则,以改进代码质量和可维护性。# File: rust/src/tools/jsondoclint/src/main.rs在Rust源代码中,rust/src/tools/jsondoclint/src/main.rs这个文件是JSON文档验证工具的源代码入口文件。主要功能是解析Rust源代码中的文档注释,并检查是否符合指定的JSON格式要求。具体而言,该文件中包含了三个主要的struct:Error、JsonOutput和Cli。1. Error:这个struct用于表示错误的信息。它包含了错误的种类(ErrorKind)和错误的消息(message)。2. JsonOutput:这个struct用于表示可输出的JSON文档的结构。它包含了源文件路径(source_file)、错误行号(line)和错误信息的字符串(errors)。3. Cli:这个struct是命令行界面的接口,包含了解析命令行参数、执行验证操作和输出结果的功能。在该文件中,还定义了一些用于错误处理的enum,即ErrorKind。1. ErrorKind:这个enum定义了错误的种类,包含了以下几个变体:- ParseError:解析错误,表示解析注释失败。- IoError:IO错误,表示读取源文件失败。- Utf8Error:UTF-8错误,表示解析文档注释时出现了UTF-8编码问题。- JsonError:JSON错误,表示文档注释中的JSON格式不符合要求。每个变体都包含了相应的错误信息,以便在出现错误时进行诊断和报告。通过这些结构体和枚举,jsondoclint工具能够解析Rust源代码中的文档注释,并验证是否符合指定的JSON格式要求。它可以帮助开发人员在编写文档时提供实时的错误检查和提示,提高文档的质量和准确性。# File: rust/src/tools/jsondoclint/src/item_kind.rs在Rust源代码中,rust/src/tools/jsondoclint/src/item_kind.rs文件的作用是定义了用于解析Rust代码中的项(item)的相关结构体和枚举类型。它是用于Rust语言的JSON文档工具链中的一部分。JSON Doc Lint是Rust的一个工具,用于生成Rust代码的文档,并将其输出为JSON格式。 item_kind.rs 定义了用于解析Rust代码中的不同项类型(例如结构体、枚举、函数等)的数据结构。该文件中的主要结构是 `Kind` 这个枚举类型。Kind枚举定义了不同的Rust代码项类型,包括:1. Struct(结构体) – 代表Rust代码中的结构体。
2. Enum(枚举)– 代表Rust代码中的枚举类型。
3. Union(联合)– 代表Rust代码中的联合类型。
4. Trait(特质)– 代表Rust代码中的特质(Trait)。
5. Function(函数)– 代表Rust代码中的函数。
6. Method(方法)– 代表Rust代码中的方法(Method)。
7. Macro(宏)– 代表Rust代码中的宏。
8. MacroRules(宏规则)– 代表Rust代码中的宏规则(Macro Rules)。
9. Other(其他)– 代表Rust代码中的其他项类型。这些不同的项类型在JSON Doc Lint工具链中起着不同的作用。它们用于解析Rust代码,提取出相应的项信息,并将其转换为JSON格式的文档。这些项类型使得工具可以准确地识别和处理不同的Rust代码结构。通过定义不同的Kind枚举项,可以根据源代码中的不同项类型执行特定的处理逻辑。例如,可以针对不同的项类型生成不同的文档部分,或对特定类型的项进行特殊的处理。因此,item_kind.rs文件的作用是为JSON Doc Lint工具链提供了项类型的定义和相关功能,以便从源代码中提取并处理不同类型的Rust项。相关文章:
听GPT 讲Rust源代码--src/tools(18)
File: rust/src/tools/rust-analyzer/crates/ide-ssr/src/from_comment.rs 在Rust源代码中的from_comment.rs文件位于Rust分析器(rust-analyzer)工具的ide-ssr库中,它的作用是将注释转换为Rust代码。 具体来说,该文件实现了从注…...

如何实现设备远程控制?
在工业自动化领域,设备远程控制是一项非常重要的技术。它使得设备可以在远离现场的情况下进行远程操作和维护,大大提高了设备的可用性和效率。 设备远程控制的应用场景有哪些? 远程故障排除:当设备出现故障时,工程师…...

百度侯震宇详解:大模型将如何重构云计算?
12月20日,在2023百度云智大会智算大会上,百度集团副总裁侯震宇以“大模型重构云计算”为主题发表演讲。他强调,AI原生时代,面向大模型的基础设施体系需要全面重构,为构建繁荣的AI原生生态筑牢底座。 侯震宇表示&…...

[Java]FileOutputStream的换行/续写/一次性写出一个字符串的方法
1.续写:FileOutputStream这个io流中的write方法默认情况下是覆盖写入的,如果需要追加写入,需要添加一个参数true 2.虽然write只能一个字符一个字符写入 但是我们可以把想输入的字符串放在str 再将str转化成byte数组 import java.io.FileOutp…...

VM进行TCP/IP通信
OK就变成这样 vm充当服务端的话也是差不多的操作 点击连接 这里我把端口号换掉了因为可能被占用报错了,如果有报错可以尝试尝试换个端口号 注: 还有一个点在工作中要是充当服务器,要去网络这边看下他的ip地址 拉到最后面...

剑指Offer 队列栈题目集合
目录 用两个栈实现队列 用两个栈实现队列 刷题链接: https://www.nowcoder.com/practice/54275ddae22f475981afa2244dd448c6 题目描述 思路一: 使用两个栈来实现队列的功能。栈 1 用于存储入队的元素,而栈 2 用于存储出队的元素。 1.push…...

grafana基本使用
一、安装grafana 1.下载 官网下载地址: https://grafana.com/grafana/download官网包的下载地址: yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.2.2-1.x86_64.rpm官网下载速度非常慢,这里选择清华大…...
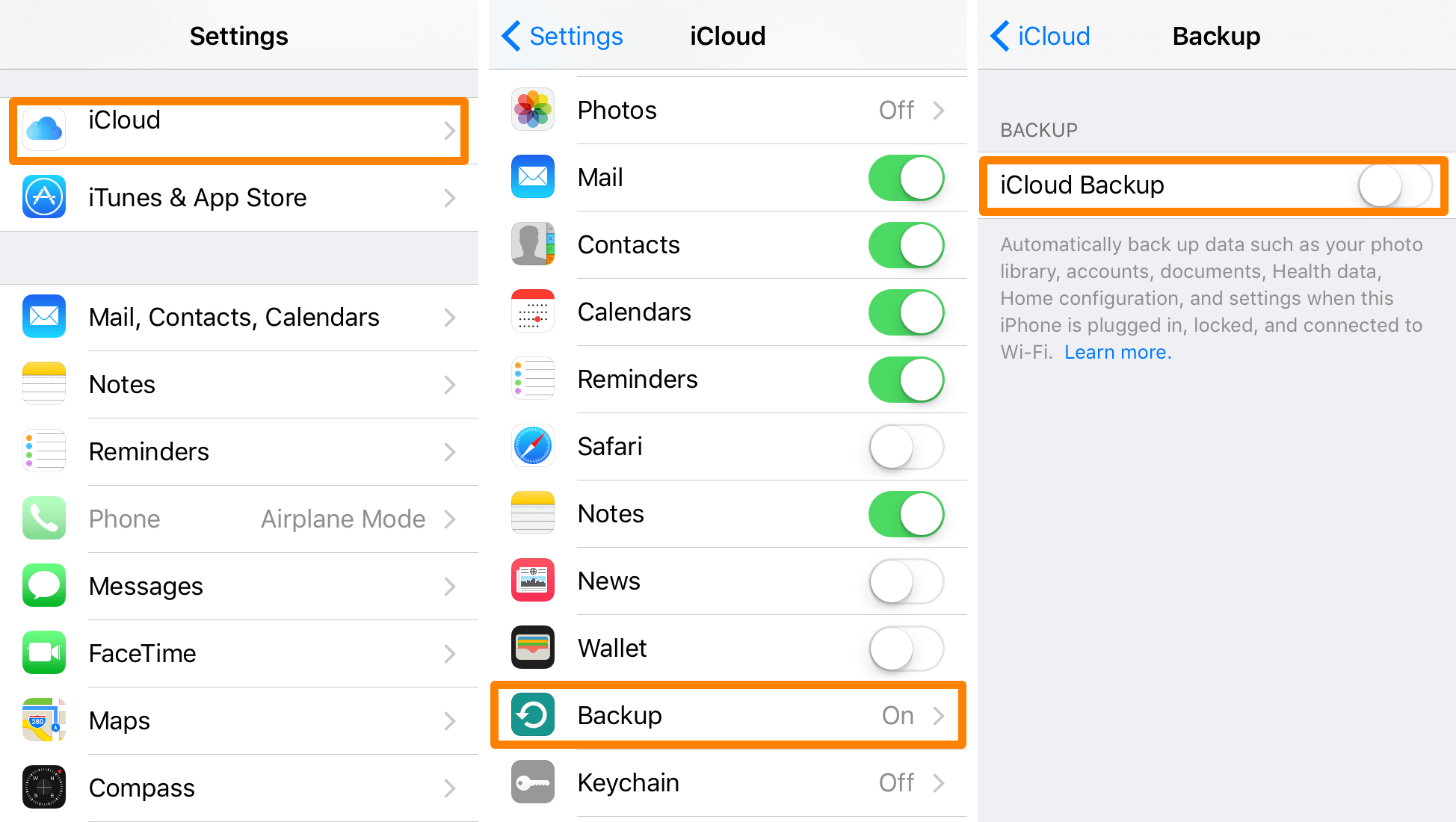
备份至关重要!如何解决iCloud的上次备份无法完成的问题
将iPhone和iPad备份到iCloud对于在设备发生故障或丢失时确保数据安全至关重要。但iOS用户有时会收到一条令人不安的消息,“上次备份无法完成。”下面我们来看看可能导致此问题的原因,如何解决此问题,并使你的iCloud备份再次顺利运行。 这些故…...

【项目问题解决】% sql注入问题
目录 【项目问题解决】% sql注入问题 1.问题描述2.问题原因3.解决思路4.解决方案1.前端限制传入特殊字符2.后端拦截特殊字符-正则表达式3.后端拦截特殊字符-拦截器 5.总结6.参考 文章所属专区 项目问题解决 1.问题描述 在处理接口入参的一些sql注入问题,虽然通过M…...
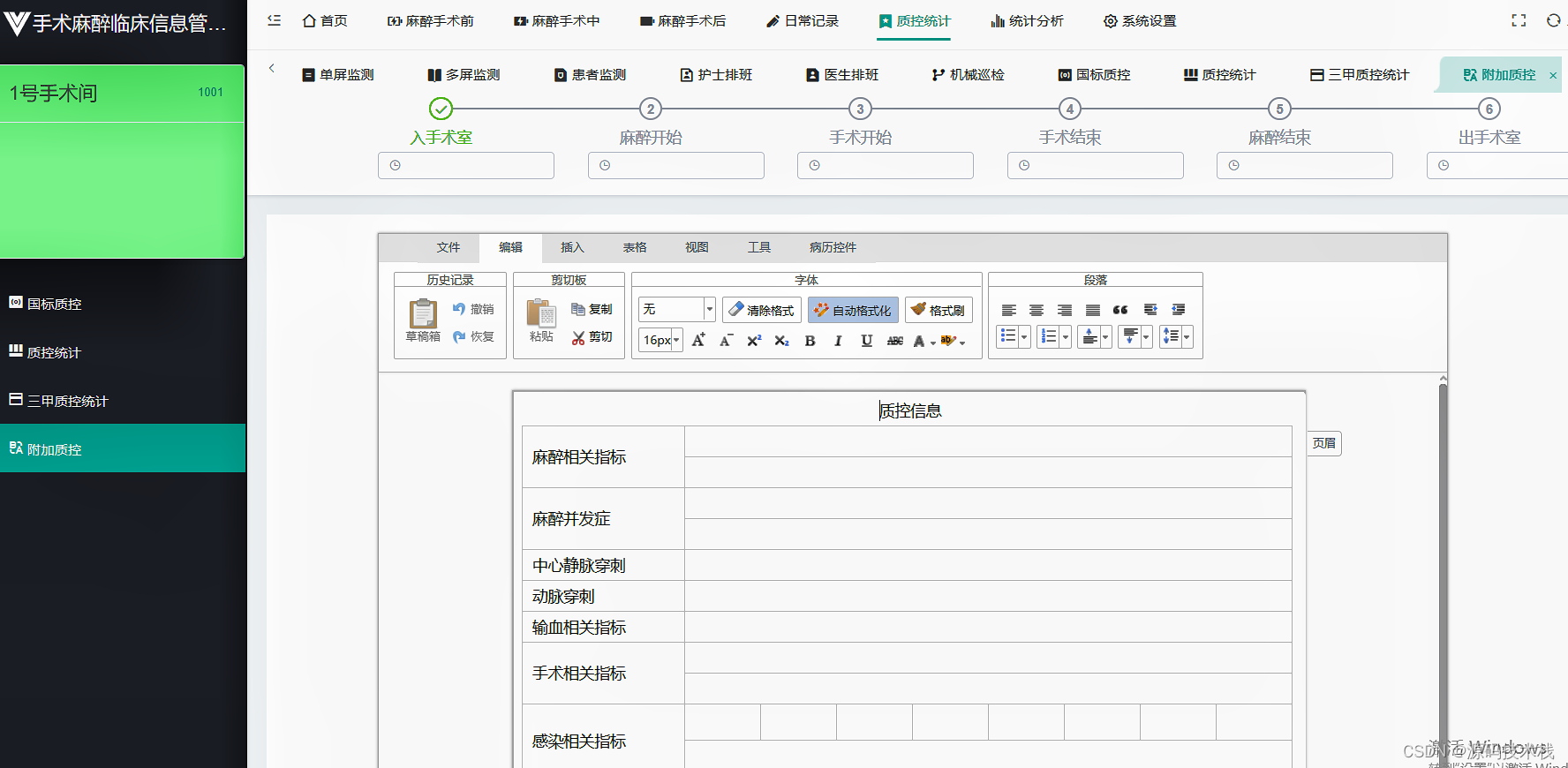
B/S医院手术麻醉临床管理系统源码 手术申请、手术安排
手术麻醉系统概述 手术室是医院各个科室工作交叉汇集的一个重要中心,在时间、空间、设备、药物、材料、人员调配的科学管理、高效运作、安全质控、绩效考核,都十分重要。手术麻醉管理系统(Operation Anesthesia Management System࿰…...

解锁高效工作!5款优秀工时管理软件推荐
工时管理,一直是让许多企业和团队头疼的问题。传统的纸质工时表、复杂的电子表格,不仅操作繁琐,还容易出错。幸好,随着科技的进步,我们迎来了工时管理软件的春天。今天,就让我们一起走进这个新时代…...

ICLR 2024 高分论文 | Step-Back Prompting 使大语言模型通过抽象进行推理
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2024 高分论文:《Step-Back Prompting Enables Reasoning Via Abstraction in Large Language Models》 论文地址:https://openreview.net/forum?id=3bq3jsvcQ1 …...
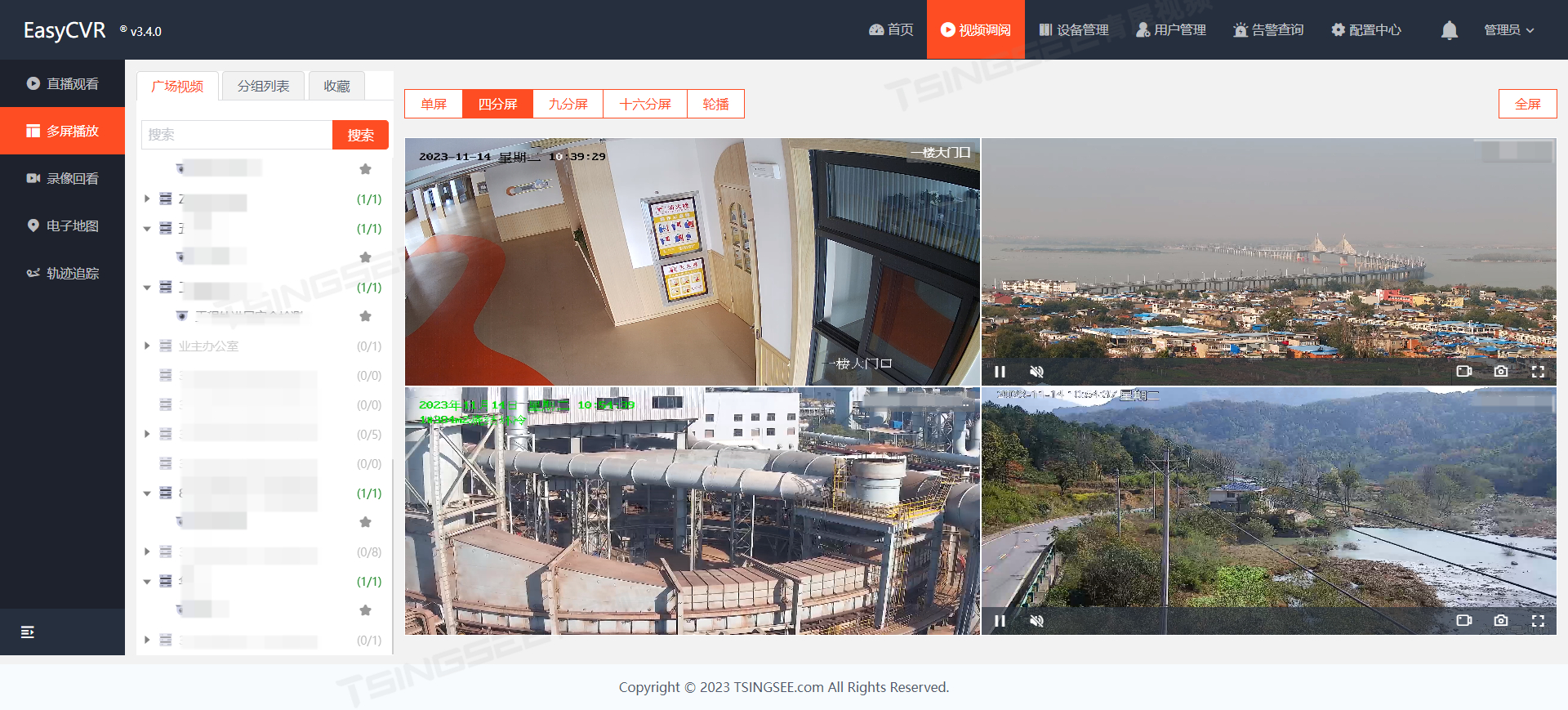
边缘计算有哪些常用场景?TSINGSEE边缘AI视频分析技术行业解决方案
随着ChatGPT生成式人工智能的爆发,AI技术在业界又掀起一波新浪潮。值得关注的是,边缘AI智能也在AI人工智能技术进步的基础上得到了快速发展。IDC跟踪报告数据显示,2021年我国的边缘计算服务器整体市场规模达到33.1亿美元,预计2020…...

配置BGP的基本示例
目录 BGP简介 BGP定义 配置BGP目的 受益 实验 实验拓扑 编辑 组网需求 配置思路 配置步骤 配置各接口所属的VLAN 配置各Vlanif的ip地址 配置IBGP连接 配置EBGP 查看BGP对等体的连接状态 配置SwitchA发布路由10.1.0.0/16 配置BGP引入直连路由 BGP简介 BGP定义 …...
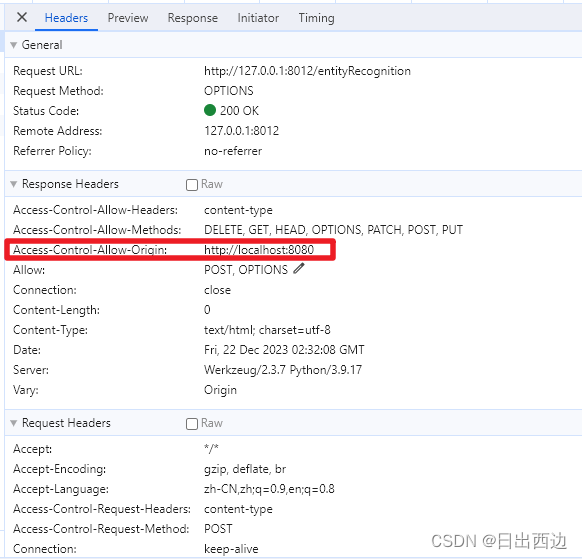
Flask解决接口跨域问题
1、什么是跨域CROS CORS(Cross-Origin Resource Sharing,跨域资源共享)是一种浏览器安全策略,用于控制在一个网页应用中如何让一个域的Web页面能够请求另一个域的资源。在Web开发中,由于同源策略(Same-Ori…...
数据恢复工具推荐!这3款堪称删除文件恢复大师!
“快看看我!经常都会莫名奇妙丢失各种电脑文件,但是又无法通过简单的方法找回重要的数据,有没有什么简单的操作可以帮助我快速恢复数据的呀?非常感谢!” 在我们的日常生活中,无论是工作还是学习,…...

论文笔记 | ICLR 2023 ReAct:通过整合推理和行动来增强语言模型
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2023 | Accept: notable-top-5%:《ReAct: Synergizing Reasoning and Acting in Language Models》 一句话总结:ReAct 方法在问答任务中通过提示大语言模型生成与任…...
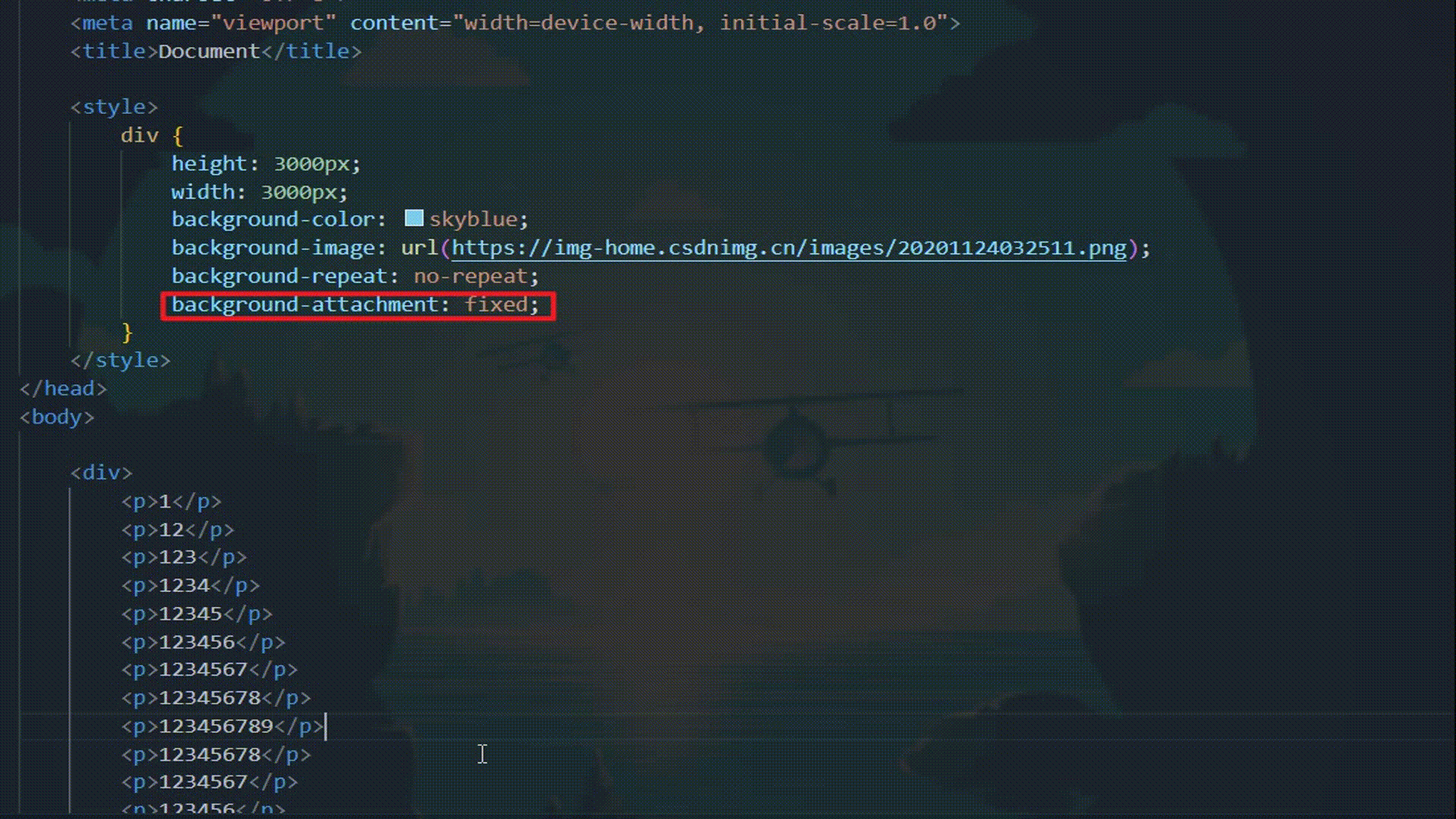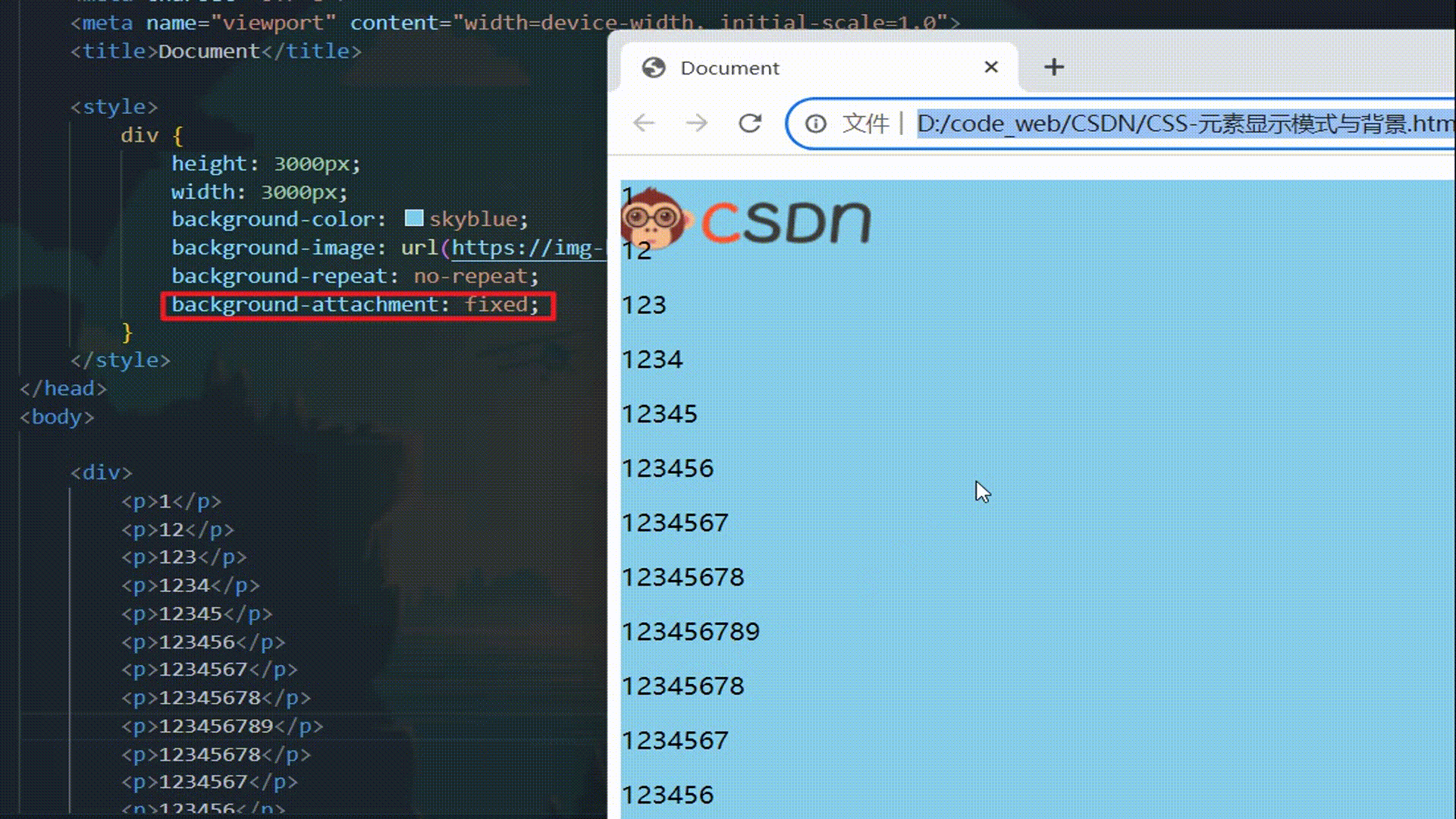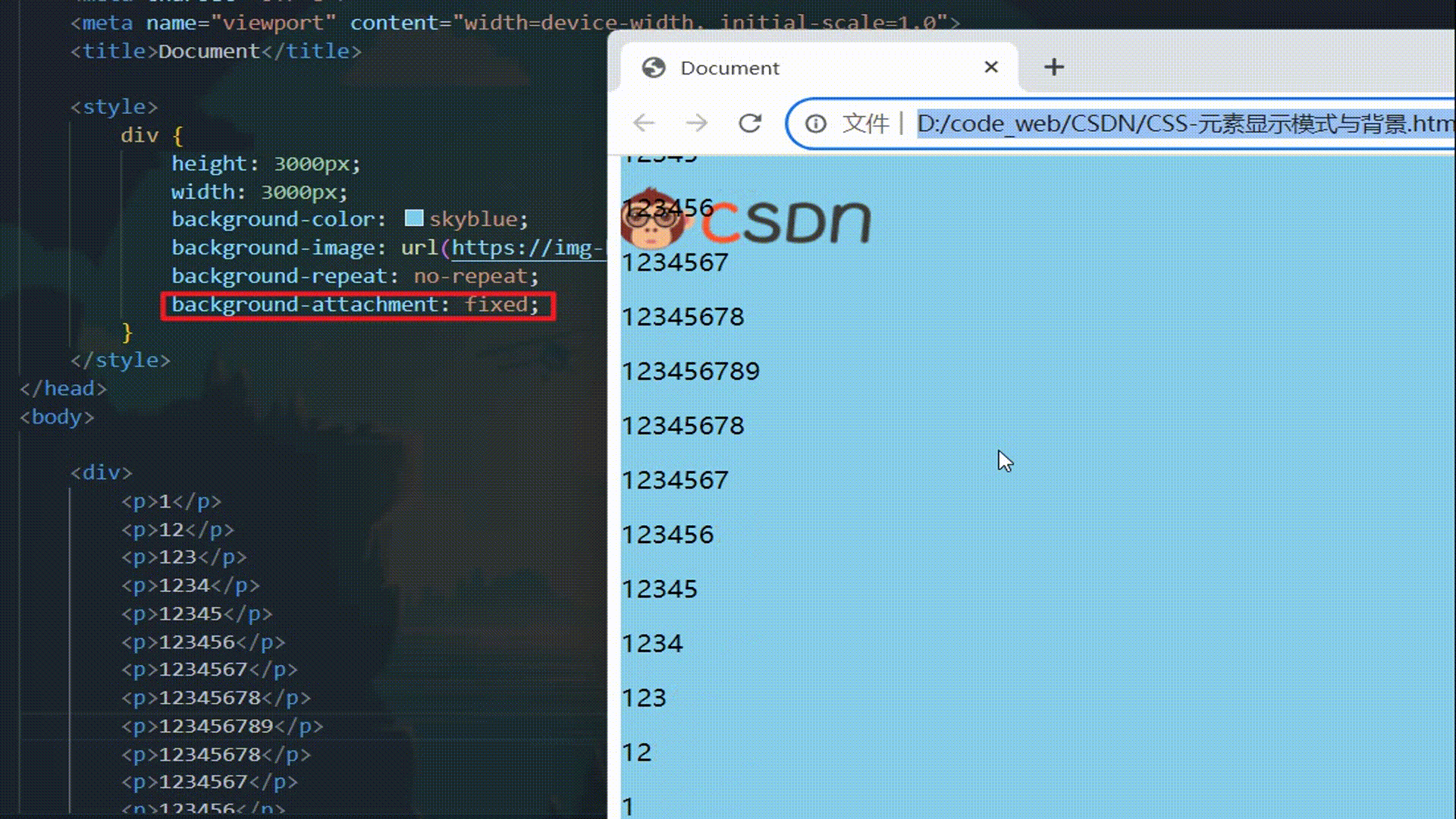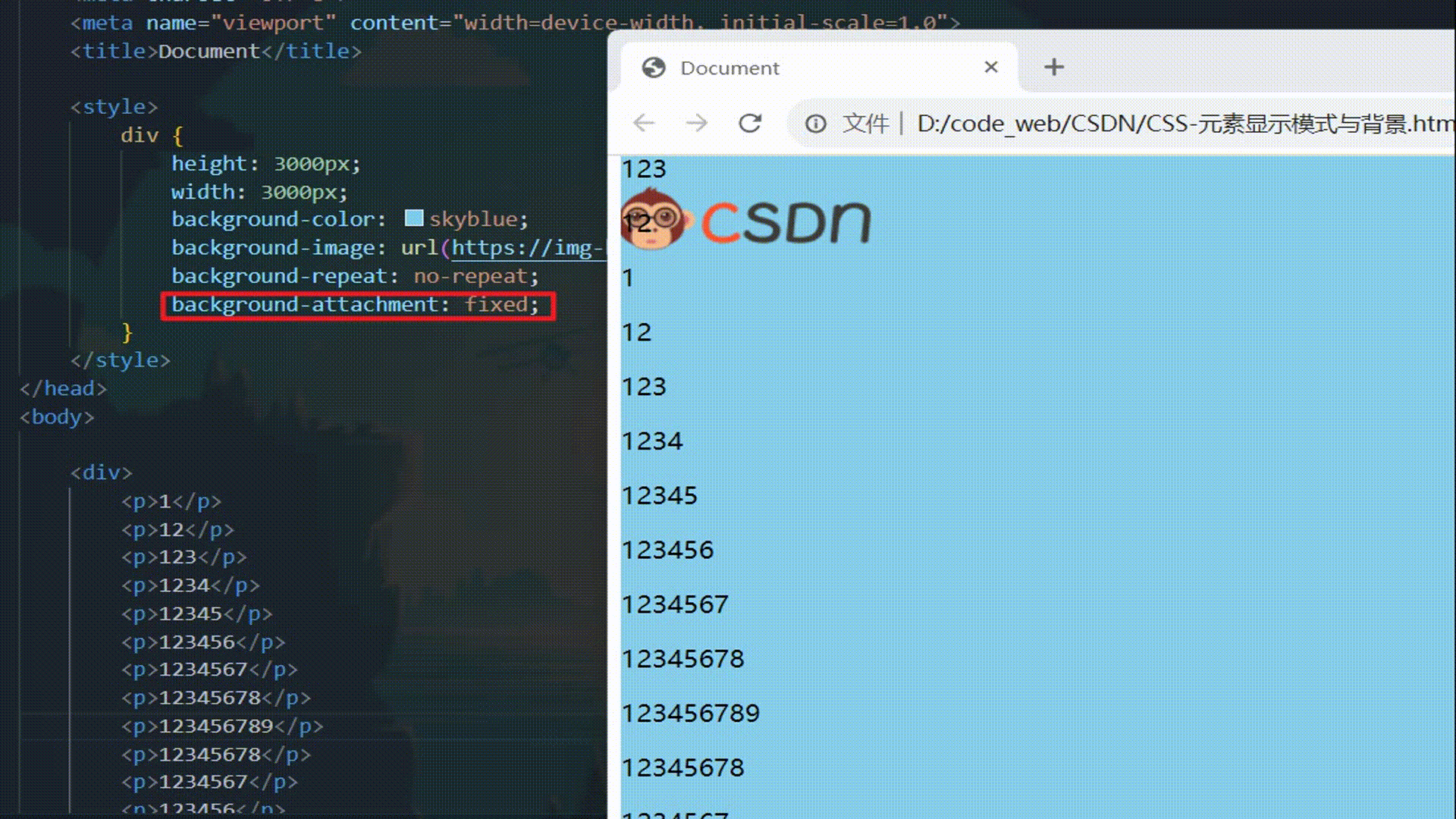
CSS:元素显示模式与背景
CSS:元素显示模式与背景 元素显示模式什么是元素显示模式块级元素 block行内元素 inline行内块元素 inline-block元素显示模式对比元素显示模式转换 display 背景背景颜色 background-color背景图片 background-image背景平铺 background-repeat背景图片位置 backgr…...

K8S 为什么关闭 SELinux 和交换内存
在学习搭建 K8S 环境和使用 K8S 时,所有教程必然会提到的事情就是关闭节点的 SELinux 和交换内存,如同自然规律一样。 那么为什么会有这样的要求呢? 交换内存 计算机的物理内存是有限的,而进程对内存的使用是不确定的ÿ…...

7. ASP.NET Core Blazor 官网文档
官方文档地址:https://learn.microsoft.com/zh-cn/aspnet/core/blazor/?viewaspnetcore-8.0 Blazor 是一种 .NET 前端 Web 框架,在单个编程模型中同时支持服务器端呈现和客户端交互性: 使用 C# 创建丰富的交互式 UI。共享使用 .NET 编写的…...

为什么需要做GEO优化?AI新时代的商业规则探索
2026年,一个加速蔓延的商业现象正在发生:消费者不再打开搜索引擎、翻阅列表、逐条点击蓝色链接——他们直接打开DeepSeek、豆包、Kimi等AI助手,用一句完整的话发起提问:“这个价位哪个品牌最值得买?”“敏感肌用什么护…...

Python使用Matplotlib绘制基础可视化图表
在Python中进行数据可视化,最常用且功能强大的库是 Matplotlib。它可以帮助你轻松绘制出柱状图、折线图、饼图、散点图、直方图、箱线图、热力图、雷达图等。在开始之前,请确保你已经安装了Matplotlib库。如果没有,可以在终端或命令行中运行以…...

大恒相机USB3驱动冲突排查:设备管理器可见但软件无法识别的深度解析
1. 问题现象与初步排查 最近在调试大恒USB3相机时遇到了一个典型问题:设备管理器里能正常识别相机设备,但打开配套软件GalaxyView却死活找不到相机。这种"看得见摸不着"的情况在工业视觉开发中特别常见,尤其是当你同时安装了多个视…...
)
基于BS模式的小型房屋租赁系统(10016)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

诺云定制APP:赋能社区团购商家私域长效盈利
如今社区团购行业早已告别野蛮烧钱补贴的粗放发展阶段,迈入精细化私域运营、低成本稳复购的深耕时代。不管是深耕社区多年的本地团购实体店家、社区团长创业者,还是手握生鲜、日用刚需货源的供应链商家,都面临着共同经营难题:依赖…...

在线教程丨单卡即可爆改,面壁智能等开源MiniCPM-V-4.6,1.3B端侧模型支持图像理解/视频理解/OCR/多轮多模态对话
过去几年,整个 AI 行业几乎都笼罩在 Scaling Law 的叙事之下。参数越大、训练数据越多,模型似乎就越接近「通用智能」。从千亿到万亿参数,大模型不断刷新人们对推理能力与世界知识的想象,也让「堆算力、卷规模」成为行业默认的发展…...

IJTAG标准解析:片上仪器统一管理与SoC调试自动化实践
1. 项目概述:当芯片内部“仪器”需要统一调度最近在整理一些老资料时,翻到了2012年EE Times上的一篇旧闻,讲的是ASSET公司发布了一份关于IEEE P1687 IJTAG标准的入门教程。虽然时间过去十多年,但文中提到的“片上仪器”标准化管理…...

面向少儿的 AI 背单词 APP开发
开发一款面向少儿的 AI 背单词 APP,核心在于将“机械记忆”转化为“交互式探索”。结合 2026 年主流的 AI 智能体技术,其主要功能可以归纳为以下几个维度。1. 沉浸式动态语境生成不同于传统的静态例句,AI 会根据孩子的兴趣(如恐龙…...

如何用LDBlockShow高效绘制连锁不平衡热图:从入门到精通的完整指南
如何用LDBlockShow高效绘制连锁不平衡热图:从入门到精通的完整指南 【免费下载链接】LDBlockShow LDBlockShow: a fast and convenient tool for visualizing linkage disequilibrium and haplotype blocks based on VCF files 项目地址: https://gitcode.com/gh_…...
)
告别手写代码!用Simulink+STM32CubeMX给F103点个灯(保姆级图文教程)
零代码玩转STM32:Simulink与CubeMX联动的LED控制实战指南 在嵌入式开发领域,传统的手写代码方式正逐渐被模型化设计工具所革新。想象一下,只需拖拽几个功能模块,设置几个参数,就能让STM32微控制器按照你的想法工作——…...