四. 基于环视Camera的BEV感知算法-BEVDepth
目录
- 前言
- 0. 简述
- 1. 算法动机&开创性思路
- 2. 主体结构
- 3. 损失函数
- 4. 性能对比
- 总结
- 下载链接
- 参考
前言
自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考
本次课程我们来学习下课程第四章——基于环视Camera的BEV感知算法,一起去学习下 BEVDepth 感知算法
课程大纲可以看下面的思维导图

0. 简述
本节内容和大家一起学习一个非常好的工作叫 BEVDepth 是旷世研究院的工作
我们还是从以下四个方面展开,算法动机&开创性思路、主体结构、损失函数和性能对比
1. 算法动机&开创性思路
其实 BEV 感知算法我们讲了这么多,核心内容我们也强调了很多次是怎么去构建这个 BEV 空间的表征,我们怎么得到 BEV 呢,输入图像通过图像处理可以得到 BEV,输入点云通过点云处理可以得到 BEV,核心内容是我们怎么把图像特征,怎么把点云特征转换到 BEV 空间当中

那这个表征我们也讲过有很多方式,我们把它分为两类,一类是从 2D 到 3D 的方式,也有从 3D 到 2D 的方式,BEVDepth 是属于从 2D 到 3D 的方式,我们来复习一下,从 2D 到 3D 的映射离不开图像生成原理,如果我们已知相机的内参和外参矩阵且已知 2D 图像像素点 p p p,我们将 2D 点 p p p 投影到 3D 空间是什么呢,是一条射线,如果我们想要做到 2D 点 p p p 和 3D 点 P P P 唯一确定关系的话怎么做呢,需要深度值
2D 像素坐标加深度加转换矩阵我们就可以计算得到 3D 世界坐标 P P P,所以深度值非常重要,那深度信息要怎么得到呢,现有方法主要可以分为两类,有一类是离散深度分布(例如 LSS),我们将这条射线划分成很多个深度网格,我们去判断我们要映射的像素点 p p p 落在哪个深度段上的概率最大,是一种概率分布的概念;另外一种叫连续深度估计(例如伪点云),网络会预测我们当前像素点的深度值,是一个确定值,那比如 p p p 它有一个唯一确定深度 D D D,是一个确定的深度估计值
所以按照离散深度分布我们最后做出的映射是什么呢,是从点到线的映射;按照连续深度分布我们做的是什么呢,是从点和点的映射关系,2D 和 3D 空间唯一确定的点与点的关系
OK,那我们想一下上面说的 2D 到 3D 无论是离散分布也好还是连续深度估计也好有没有什么问题呢,是有的,它其实主要问题是深度的不可靠,那也就是说我们这个 D D D 无论是离散深度分布也好还是连续深度估计也好,我们的 D D D 值很容易算错,那一旦深度算错了我们的映射其实也就错了,那我们最终构造的 BEV 空间是不是也就错了,我们检测呢也自然不可能对
那这种深度不可靠的原因是什么呢,作者认为呢主要缺少的是没有一个合适的监督信息,我们可以先不讨论伪点云的方式,我们主要还是针对离散深度分布的方法,那也就是说没有真值去告诉网络我们对应的 pixel 应该落在哪个深度。所以第一点那作者认为由于缺乏明确的深度监督很难做出很准确的深度感知结果,那第二点是什么呢,是网络不能充分利用相机的内外参数所以没有办法有效推断像素深度,我们输入深度预测网络的是什么,是图像特征,通过网络我们可以估计深度分布 D D D,我们输入的是特征我们没有告诉网络我们当前的相机型号是什么,相机和激光雷达相对应的关系是什么,是没有告诉这个信息的,所以网络仅仅依靠特征去进行深度推断而没有充分利用相机的内外参数,作者认为它也是导致没有办法准确推断像素深度的原因之一,那我们所说的第三点还有一个什么原因呢,效率问题,那比如像基于伪点云的思路需要引入额外的深度估计网络,这个网络其实一般而言比较庞大也比较耗时
因此我们简单总结下现有 2D 到 3D 方式的缺点:
- 没有明确的深度监督,很难输入准确的深度感知
- 深度子网络不能充分利用相机的内外参数,无法有效推断像素深度
- 相同的分辨率输入,相同的主干网络,基于深度的目标检测器速度较慢
所以说 BEVDepth 作者尝试能否使用一种轻量化的结构提供准确的监督,一个是监督另外一个是内外参数从而实现深度准确的预测
所以从动机出发我们也能想到 BEVDepth 关注的核心问题是什么呢,其实是深度估计,那我们怎么将深度估计去做得更准确呢,引入深度监督信息,引入相机内外参矩阵

那 OK 我们再来看看 BEVDepth 的预测和之前讲的 LSS 的结构有什么不同呢,首先从上面的示意图我们能看出来,我们说的 LSS 结构是一种离散深度估计结构,所以呢我们看到的深度图呈现的是网格的模式,都是一小块一小块的网格;而 BEVDepth 看起来是更连续的也更丰富一点
此外 BEVDepth 一个很显著的好处是对于前景位置很明显,那比如从上面的 LSS 图上很难分辨出行人轮廓和车辆轮廓,但相反我们在 BEVDepth 上能够明显的看出车在那哪在哪,那说完动机之后我们再来看一看 BEVDepth 主体结构是怎么做的,是具体怎么设计这个网络的
2. 主体结构
BEVDepth 主体结构如下图所示:


我们看网络还是老套路从输入输出看起,输入是 Multi-view Images 多视角图像,输出预测结果也就是我们要的检测结果,那我们再来看一下具体流程,输入的如果是图像,那么编码网络是什么,是图像编码器,输入图像通过图像编码器我们可以得到图像特征,图像特征怎么用呢,那当然是将图像特征转换到 BEV 空间当中得到 BEV Feature,所以我们中间看到的流程全都是用来做图像到 BEV 空间对应视角转换的
那么图像怎么转换到 BEV 的呢,有了图像特征通过深度估计网络可以得到深度值,然后利用深度值将图像特征对应的映射到 BEV 空间组成 BEV 特征,那么这个深度值预测模块其实是 BEVDepth 的核心内容了

我们先不着急,我们从头开始一个一个看,那首先第一个模块是图像编码器,图像的 Backbone,如上图所示,我们说输入图像通过图像编码器可以得到图像特征,图像编码网络有很多也就是 2D Backbone 有很多,包括 ResNet、ViT、Swin Transformer 等等,也可以使用一些多尺度的策略比如特定金字塔等等,最后我们得到什么,得到的是图像特征,那这就是图像编码模块的功能,非常简单

有了图像特征我们就考虑图像特征要怎么得到 BEV 特征呢,我们说这个过程呢其实离不开视角转换设计,有了图像特征我们可以通过深度估计,离散的也好连续的也好得到深度概率分布值或者具体的深度值,有了深度我们才可以做特征映射,才能转换到 BEV 空间
所以视角转换模块其实包含两个内容,一个是深度估计,一个是特征映射,那我们一个一个看,如上图所示,深度估计网络 Depth Net 其实包含两个输入,一个输入是图像特征,我们得到的图像特征,另一个输入是相机参数 Camera Parameters,内参外参矩阵它都属于相机参数,同时输入到 Depth Net 一个深度估计网络中去预测深度分布,我们得到的是一个深度分布结果。输入图像特征输入相机参数通过深度网络得到深度分布,我们刚才讲解的流程其实就是深度估计这个模块一个主要的流程

那大家可能有个疑问就是我们 Depth Net 应该怎么做,我们接下来看一下详细的 Depth Net 是怎么做的,如上图所示,我们刚刚讲了我们 Depth Net 网络包含两个输入,一个是图像特征 Image Features,一个是参数输入内参输入,输出其实也是两个,一个是经过卷积的特征我们叫 Context,图像通过卷积网络可以得到 Context,图像呢同时经过下面的支路可以得到 Depth
上面支路的图像特征处理很简单直接通过卷积输出 Context,那下面的支路也是通过卷积,只不过多了一个相机参数输入,相机内参要怎么处理,首先相机内参数本身参数维度很小,所以说要通过一个扩维的操作,扩维其实也很简单,一个 MLP 就能搞定的事情,扩到多少维呢,其实是和输入的图像通道有关系的,相机扩展的维度和图像通道维度数量是一样的
为什么这么做呢那也涉及到动机的问题,那像作者这里引入的相机内参矩阵其实更偏向一种权重参数,也就是说相机内参矩阵映射成了一种权重去乘上原始的 Feature,对原始图像特征的通道维度进行加权,那我们说这是什么呢,是通道注意力机制,权重高的通道我们需要重点关注,权重低的通道呢我们可以选择性忽略,完事之后得到了加权特征然后再通过一系列的残差网络,DCN 网络得到最终的深度预测结果
所以这个 Depth 网络它叫 Depth Net,相比而言还是比较轻量的,输入图像特征输入相机内参矩阵,输出深度预测结果和图像 Context 特征

那得到的输出我们来看看是怎么用的呢,在上图中也能看到我们刚才讲 Depth Net 的两个输出,一个是输出图像 Context 另一个是输出我们预测好的深度分布。另外我们一直强调什么,强调 BEVDepth 设计的动机是作者认为以前方法不好的主要原因是缺乏监督信息,那显然 BEVDepth 是包含监督网络的,它的监督是从哪来的呢,从点云过来的,场景的点云信息为深度估计模块提供了深度监督也就是上图中的 Depth Supervision
点云投影到图像上对应的位置,那么这个像素位置就有了点云的深度值作为显式的监督,我们讲显式那就是明确的告诉网络什么是对的什么是错的,我这个 pixel 应该映射到哪,我这个 pixel 不应该映射到哪,而不是让网络去猜我这个映射到底对不对,通过这样一个监督信息其实是辅助了深度预测模块的训练的,让网络可以预测得更准
有了深度有了图像特征可以做什么,可以做转换,那在做转换之前我们还要考虑一个事情,我们得到的这个深度结果一定是好的吗,深度结果是受深度信息监督的,我们这个深度信息监督一定是对的吗,那为什么这么问呢,其实是因为 BEVDepth 作者认为深度监督来源于点云的投影,点云投影到图像依赖什么呢,依赖相机的内参外参转换矩阵,内参我们讲过出厂后基本是固定的,然而外参是会变的,会由于车的抖动产生一定的偏差,那如果外参的转换矩阵存在偏差,点云通过内参外参矩阵投影到的图像像素是不是也就存在偏差了

因此在这种情况下 BEVDepth 作者认为深度监督是存在偏差的而且这个偏差不可避免很难估量,偏差既然不可避免既然很难估量我们就不再在 Depth Net 中处理了,也没有办法去处理,我们通过深度值预测出来之后,引入深度校正网络,如上图所示,额外的 Refinement 去修正外参扰动带来的偏差
通过这个网络之后,我们认为这个网络现在输出的深度已经很准了我们可以做映射了,所以这里就引入了一个映射模块叫 Efficient Voxel Pooling 体素的高效池化。那我们说这个模块其实包含两个概念,一个概念是体素池化,体素池化很好理解无非是和我们讲的 2D 图像上的网格池化类似,使用了一个最大值或者平均值等等的处理方式,那这里体素池化是用在体素上面。另外提出的一个词叫 Efficient 高效,什么叫高效呢,这个词怎么理解
我们一起来看一下体素高效池化这个模块详细的结构,如下图所示:

上面的右图是作者提出的体素高效池化,左图是我们本次课程当中提到过很多次的离散深度分布估计,将 2D 像素特征映射到 3D 空间特征的一种方式,图像上的每一个像素点映射到 3D 空间是一条射线。那从 BEVDepth 的框图也能看到一个相机对应的像素点到空间位置是一条射线,那这个射线通过离散化的网格在不同位置有着不同概率的深度分布,那比如图中高一点的地方可能概率就偏大一点,矮一点的颜色浅一点的地方可能概率就偏小一点
那体素的高效池化网络的高效体现在速度快,那怎么加速呢,其实是为每一个网格分配了一个 CUDA 线程,一个 CUDA 线程的作用是处理一个网格的特征,我们叫一个视锥空间的特征,BEV 空间下所有的视锥空间是一个并行化处理的,所有网格是一起做的,我们所有视锥空间是一起做的,那所以自然速度就会加快
那在这里一旦 BEV 空间构造好了,我们自然会进行下一步那就是基于 BEV 特征去做预测,有了 BEV Feature 我们自然可以做预测,那这就是 BEVDepth 完整的结构
3. 损失函数
那 OK,我们再理一下 BEVDepth 整体网络,其框图如下所示

输入的是 Multi-view 图像一个多视角的图像,通过图像编码器可以得到图像特征,通过 Depth Net 预测深度分布,然后通过深度校正 BEV 空间的特征生成可以得到 BEV Feature,核心内容其实是深度预测模块,与之前的深度分布估计不同 BEVDepth 引入的是有监督信息的深度估计,那这些监督信息哪来呢,点云投影出来的监督值,那既然是有监督信息的,损失函数也是有的,深度估计损失,还有一个是 3D 预测损失,那它们俩就是完整的 BEVDepth 的损失函数
4. 性能对比
OK,我们再看下性能,如下表所示:

nuScenes 测试集下 BEVDepth 整体性能还是可以的 mAP 是 0.52

我们是重点关注消融实验,那首先在表 1 中作者做了一个很有意思的实验,我们看下第一行 learned 它表示的其实就是我们 LSS 网络,它作为一个 Baseline 其 mAP 是 28.2,OK,那现在作者怎么做,把 LSS 网络学习到的离散深度分布结果替换成一些随机量,随机量分为两种有一种是 soft 的一种是 hard 的,我们翻译过来叫软随机和硬随机,软随机那就不是非 0 即 1 的结果,存在 0.5、0.6、0.8 等等,random hard 叫硬随机比如 one-hot 编码就是一个硬随机
那作者发现了一个什么特别有意思的事情呢,我们把 LSS 学习到的离散深度分布值替换成一些随机量之后,性能没有下降得很明显没有崩盘,它只是稍许下降,尤其是替换成 random soft 之后性能也仅仅从 28.2 下降了 3.7 个点到 24.5,这是不是挺神奇的,有一点超出我们常识认知。另外作者其实也用 GT 进行替换,这个性能提高非常明显,从 28.2 提高到了 47.0,有将近 20 个点的提升,那足以证明深度监督信息是很有效的

那在表 4 当中是对文中涉及的一些模块进行了一个验证,前面 DL 模块是深度监督模块,后面第二个 CA 模块是深度监督当中引入了相机参数,后面的 DR 模块是校正模块是 refinement,我们有了深度估计之后对深度值去进行一个校正,MF 是多帧的网络把时序信息引入进去之后性能有了进一步的提升

表 6 讨论了深度校正模块的一些详细的内容,把里面的一些卷积操作进行了对比,用了 1x1 的卷积,3x1 的卷积,3x3 的卷积,那性能最好的是 3x3 的卷积

另外由于引入了深度损失,有了深度监督有了深度预测结果所以引入了深度损失,那作者对深度损失函数也进行了讨论,如表 5 所示,采用了两种损失函数一个是 BCE,一个是 L1 以及合在一起的方式

我们再来看一个很有意思的东西,图像的训练尺寸和测试的尺寸对性能的鲁棒性是不是有影响,如上图所示,训练的时候采用的是 256x704 的尺寸,测试是在不同尺寸下去做的测试,那绿色的部分是 Base Detector,蓝色的是 BEVDepth 的方式也就是本文的方式
作者发现一个什么事情,我们训练尺寸比如 256x704 的训练尺寸如果放在同等尺寸下去进行测试的时候性能差不多,用 BEVDepth 是 30.4 用 base detector 是 28.2,大家性能差不多,如果说训练尺寸和测试尺寸差距很大,比如说我们训练的是 256x704 的尺寸推理的时候采用 192x640 的尺寸,那这个 Base Detector 性能下降得非常明显,从 28.2 直接下降到了 18.9,BEVDepth 性能下降得不是太明显
那为什么 Base Detector 鲁棒性这么差呢,它为什么对图像尺寸性能这么不好呢,其实也比较好理解,缺少了深度监督嘛,因为很多像素是没有学习到一个比较好的深度分布的,那么一旦测试环境发生变化性能波动就会非常大。同时也得益于比较好的深度分布预测,我们能看到 BEVDepth 的方式在不同尺寸下相比而言还是比较鲁棒的

另外作者还给出了上图的可视化结果,我们能看到像作者的方式投影的位置其实非常好的,绿色部分是 BEVDepth 的投影位置,旁边绿色加红色是传统方法的投影点,它只有很小一部分绿色的点是投影在正确的位置上,而很大一部分红色区域的点是投影在外面也就是错误位置上,它其实就是投影位置飘了
OK,我们 BEVDepth 的核心内容就到此为止,BEVDepth 主要思路其实就是通过深度监督信息的引入让深度估计得更准,那至于其他模块其实都是偏工程性质的模块
总结
BEVDepth 的作者围绕 Depth 深度估计展开,他认为现有的方法由于缺乏明确的深度监督很难做出准确的深度感知结果,此外深度估计子网络不能充分利用相机的内外参数导致无法有效推断像素深度,基于此 BEVDepth 作者提出了一个深度预测模块,与之前的深度分布估计方法不同的是 BEVDepth 引入的是有监督信息的深度估计,这些监督信息来自于点云的投影,这就是 BEVDepth 的核心内容了,通过点云投影到图像这个深度监督信息的引入让深度估计得更准
OK,以上就是 BEVDepth 的全部内容了,下节我们学习一篇想法独特的环视 BEV 感知算法 BEVDistill,敬请期待😄
下载链接
- 论文下载链接【提取码:6463】
- 数据集下载链接【提取码:data】
参考
- [1] Li et al. Bevdepth: Acquisition of reliable depth for multi-view 3d object detection
相关文章:
四. 基于环视Camera的BEV感知算法-BEVDepth
目录 前言0. 简述1. 算法动机&开创性思路2. 主体结构3. 损失函数4. 性能对比总结下载链接参考 前言 自动驾驶之心推出的《国内首个BVE感知全栈系列学习教程》,链接。记录下个人学习笔记,仅供自己参考 本次课程我们来学习下课程第四章——基于环视Cam…...
——使用docker compose安装mysql)
CentOS系统环境搭建(二十五)——使用docker compose安装mysql
centos系统环境搭建专栏🔗点击跳转 文章目录 使用docker compose安装mysqlMySQL81.新建文件夹2.创建docker-compose.yaml3.创建my.cnf4.mysql容器的启动和关闭 MySQL5.71.新建文件夹2.创建docker-compose.yaml3.创建my.cnf4.mysql容器的启动和关闭 使用docker comp…...
协作机器人(Collaborative-Robot)安全碰撞的速度与接触力
协作机器人(Collaborative-Robot)的安全碰撞速度和接触力是一个非常重要的安全指标。在设计和使用协作机器人时,必须确保其与人类或其他物体的碰撞不会对人员造成伤害。 对于协作机器人的安全碰撞速度,一般会设定一个上限值&…...

第11章 GUI Page400~402 步骤二 画直线
运行效果: 源代码: /**************************************************************** Name: wxMyPainterApp.h* Purpose: Defines Application Class* Author: yanzhenxi (3065598272qq.com)* Created: 2023-12-21* Copyright: yanzhen…...
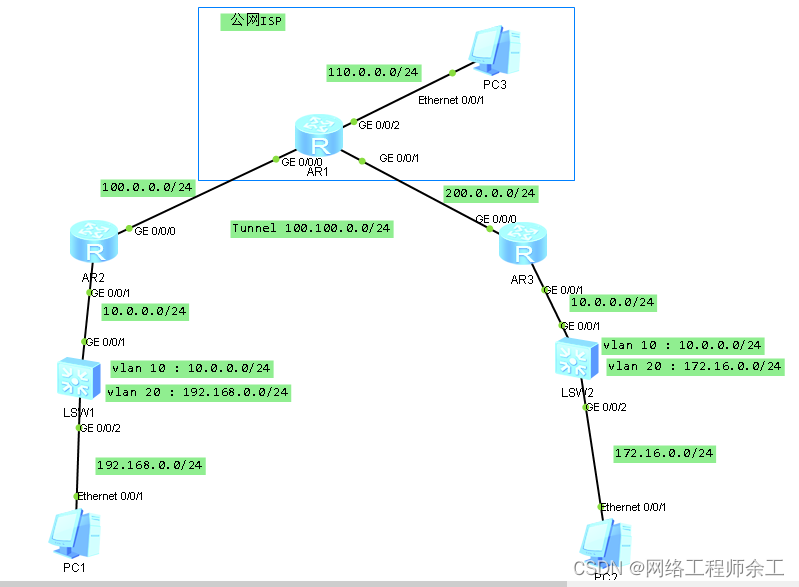
华为gre隧道全部跑静态路由
最终实现: 1、pc1能用nat上网ping能pc3 2、pc1能通过gre访问pc2 3、全部用静态路由做,没有用ospf,如果要用ospf,那么两边除了路由器上跑ospf,核心交换机也得用ospf r2配置: acl number 3000 rule 5 deny…...

【c++】入门1
c关键字 命名空间 在C/C中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染ÿ…...
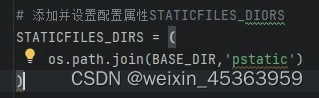
Python之Django项目的功能配置
1.创建Django项目 进入项目管理目录,比如:D盘 执行命令:diango-admin startproject demo1 创建项目 如果提示diango命令不存在,搜索diango-admin程序的位置,然后加入到环境变量path中。 进入项目,cd demo…...
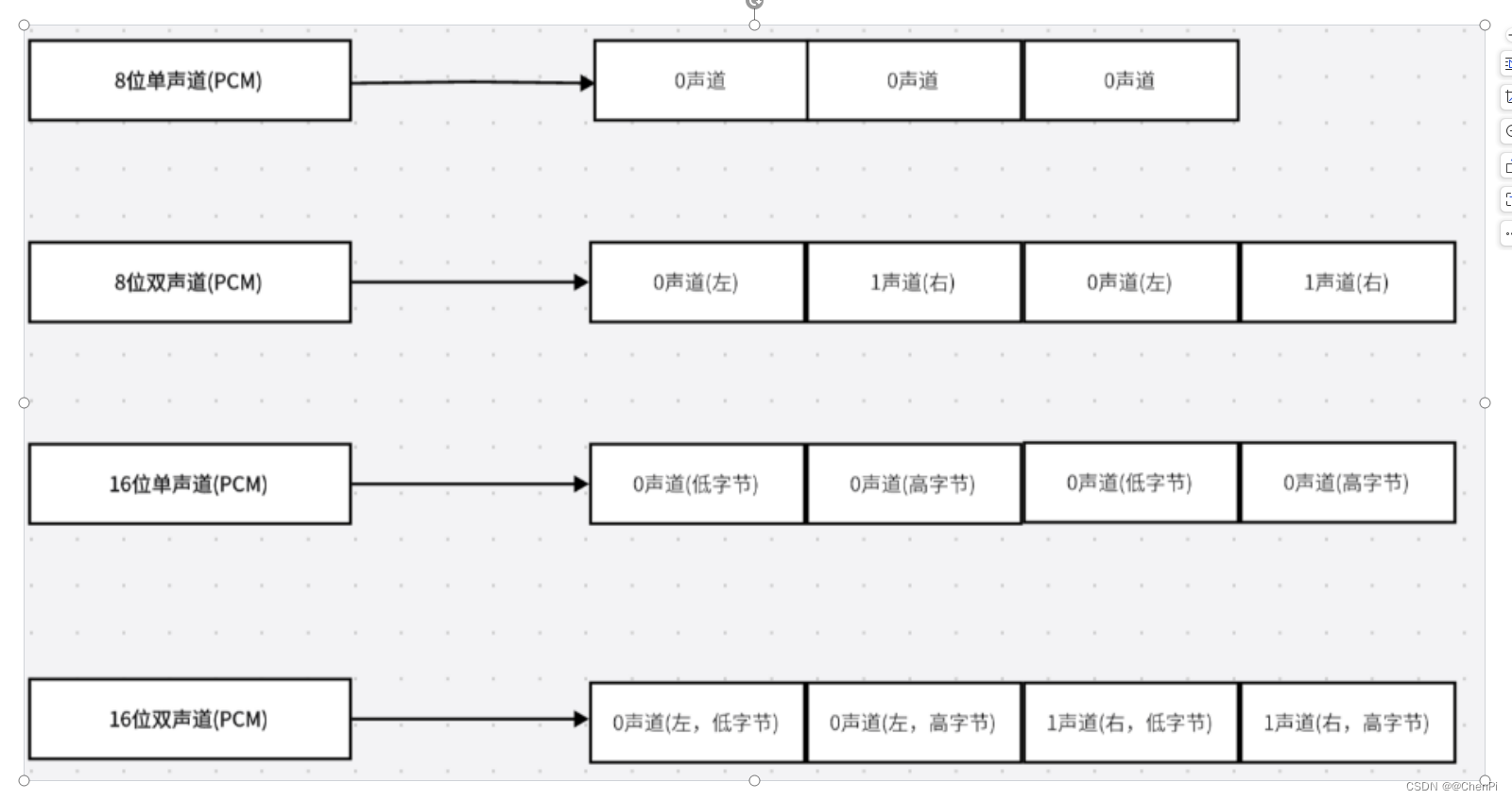
P4 音频知识点——PCM音频原始数据
目录 前言 01 PCM音频原始数据 1.1 频率 1.2 振幅: 1.3 比特率 1.4 采样 1.5 量化 1.6 编码 02. PCM数据有以下重要的参数: 采样率: 采集深度 通道数 PCM比特率 PCM文件大小计算: …...

解决Electron中WebView加载部分HTTPS页面白屏的方法
Electron是一个开源的桌面应用程序框架,它允许使用Web技术构建跨平台的桌面应用。在Electron应用中,WebView 是一个常用的组件,用于嵌套加载Web内容。然而,有时候在加载使用 HTTPS 协议的页面时,可能会因为证书问题导致…...

【Java中创建对象的方式有哪些?】
✅Java中创建对象的方式有哪些? ✅使用New关键字✅使用反射机制✅使用clone方法✅使用反序列化✅使用方法句柄✅ 使用Unsafe分配内存 ✅使用New关键字 这是我们最常见的也是最简单的创建对象的方式,通过这种方式我们还可以调用任意的构造函数 (无参的和有…...
)
npm使用详解(好吧好吧是粗解)
目录 npm是什么? npm有什么用? npm安装 在 Windows 上 在 macOS 上 在 Linux 上(使用 apt 包管理器为例) 验证 npm 安装成功: npm使用 1. 初始化项目: 2. 安装和管理依赖: 3. 查看和…...
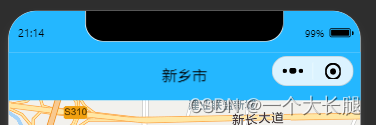
uniapp自定义头部导航怎么实现?
一、在pages.json文件里边写上自定义属性 "navigationStyle": "custom" 二、在对应的index页面写上以下: <view :style"{ height: headheight px, backgroundColor: #24B7FF, zIndex: 99, position: fixed, top: 0px, width: 100% …...
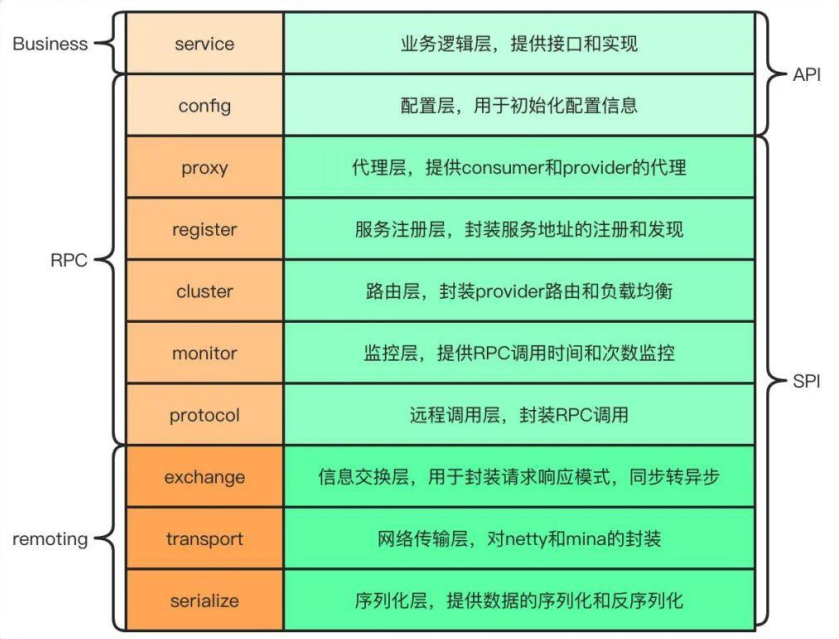
什么是 Dubbo?它有哪些核心功能?
文章目录 什么是 Dubbo?它有哪些核心功能? 什么是 Dubbo?它有哪些核心功能? Dubbo 是一款高性能、轻量级的开源 RPC 框架。由 10 层模式构成,整个分层依赖由上至下。 通过这张图我们也可以将 Dubbo 理解为三层模式&…...
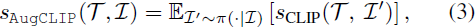
(2021|CoRR,AugCLIP,优化)FuseDream:通过改进的 CLIP+GAN 空间优化实现免训练文本到图像生成
FuseDream: Training-Free Text-to-Image Generation with Improved CLIPGAN Space Optimization 公众:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料) 目录 0. 摘要 1. 简介 2. CLIPGAN 文本到图…...

python pip安装依赖的常用软件源
目录 引言 一、什么是镜像源? 二、清华源 三、阿里源 四、中科大源 五、豆瓣源 六、更多资源 引言 在软件开发和使用过程中,我们经常需要下载和更新各种软件包和库文件。然而,由于网络环境的限制或者服务器的负载&#…...

避免大M取值过大引起的数值问题
在数学建模当中,常常会见到大M法,它之所以叫大M法,是因为它涉及到一个(绝对值)较大的系数M,这个大M的值应大于约束中的连续变量或者约束表达式可能取到的任何合理值,M值取过大往往会造成优化问题…...

史密斯圆图的使用
史密斯圆图的使用 简介识别史密斯圆图等反射系数圆归一化阻抗圆导纳圆图史密斯圆图的使用单支匹配双支匹配简介 史密斯图Smith Chart是电气工程,无线电,射频工程,微波工程和通信等领域常用的一种图示工具,用于分析和设计传输线和阻抗匹配网络,它由美国工程师Phillip H.Sm…...

可重复读解决了哪些问题? 对 SQL 慢查询会考虑哪些优化 ?
文章目录 可重复读解决了哪些问题?对 SQL 慢查询会考虑哪些优化 ? 可重复读解决了哪些问题? (1)可重复读的核心就是一致性读(consistent read);保证多次读取同一个数据时,其值都和事务开始时候的内容是一致…...
从0开始python学习-35.allure报告企业定制
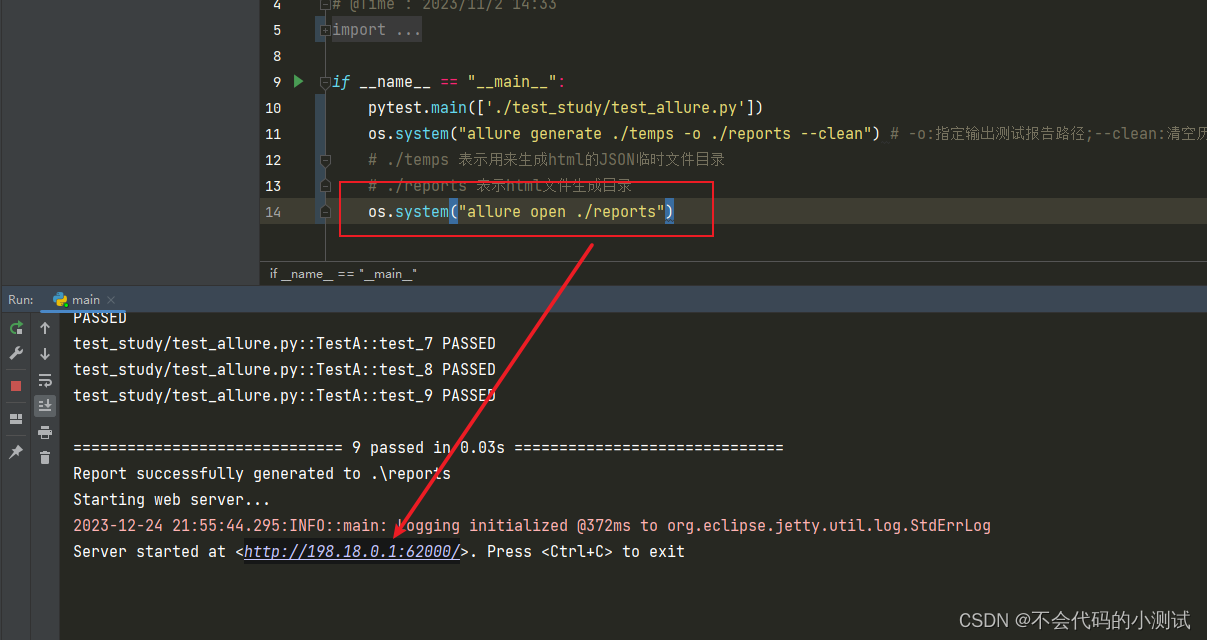
目录 1. 搭建allure环境 2. 生成报告 3. logo定制 4. 企业级报告内容或层级定制 5. allure局域网查看 1. 搭建allure环境 1.1 JDK,使用PyCharm 找到pycharm安装目录找到java.exe记下jbr目录的完整路径,eg: C:\Program Files\JetBrains\PyCharm Com…...

蓝桥杯2020年10月青少组Python程序设计省赛真题
1、设计一个猜字母的程序,程序随机给出26个小写字母中的一个,答题者输入猜测的字母,若输入的不是26个小写字母之一,让用户重新输入,若字母在答案之前或之后,程序给出相应正确提示,如答错5次,则答题失败并退出游戏,若回答正确,程序输出回答次数并退出游戏。 2、试编一个“口…...

Arm Iris组件参数化建模与调试实践
1. Arm Iris组件概述与核心价值Arm Iris组件是Fast Models仿真平台中的关键模块,它为芯片设计验证和软件开发提供了高度参数化的虚拟原型环境。作为一名长期从事Arm架构开发的工程师,我发现Iris组件的设计理念完美体现了"配置即硬件"的思想——…...

Arm Cortex-A35 Cycle Model技术解析与SoC集成实战
1. Arm Cortex-A35 Cycle Model技术解析在SoC设计领域,虚拟平台验证已成为不可或缺的关键环节。作为Armv8-A架构中的能效比优化核心,Cortex-A35处理器通过Cycle Model提供了RTL级精度的硬件行为模拟能力。我在多个车载SoC项目中验证发现,其Cy…...

如何让Photoshop图层批量导出速度提升3倍?这个开源脚本做到了!
如何让Photoshop图层批量导出速度提升3倍?这个开源脚本做到了! 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Ado…...

基于强化学习的机器人抓取:从PPO/SAC算法到仿真部署全解析
1. 项目概述:一个基于强化学习的机器人抓取开源项目最近在机器人控制领域,强化学习(Reinforcement Learning, RL)的应用越来越火,尤其是在需要高精度、高适应性的任务上,比如机器人抓取。传统的抓取规划方法…...

GitHub自动化运维:构建模块化Operator集提升开发效率
1. 项目概述:一个为GitHub开发者量身定制的“操作集”如果你是一个重度GitHub用户,无论是维护个人项目、参与开源贡献,还是管理团队仓库,大概率都经历过这样的场景:每天要重复执行一堆琐碎但必要的操作。比如ÿ…...

基于vLLM与OpenAI API的LLM生产部署框架实战指南
1. 项目概述:一个面向生产环境的LLM部署框架最近在折腾大语言模型(LLM)的部署,发现了一个挺有意思的项目:run-llama/llama_deploy。这名字乍一看,可能会让人以为它只是用来部署Meta的Llama系列模型的&#…...

ubantu安装vscode
在火狐浏览器中搜索vscode官网,找到.deb文件下载,下载完成后文件所在的位置为 主文件夹/下载 文件夹内。...

Linux系统信息查询全攻略:从内核到发行版的深度解析与脚本实践
1. 项目概述:一个看似简单却暗藏玄机的基础操作“查看Linux系统版本”,这几乎是每个运维工程师、开发人员乃至普通用户在接触Linux系统时,第一个需要掌握的命令。它简单到常常被新手教程一笔带过,却又复杂到足以让老手在排查问题时…...

【PCL中Ptr释放问题 aligned_free 的2种解决方法】
PCL中Ptr释放问题 aligned_free解决方法1解决方法2解决方法1 添加avx指令,参考这篇博客https://blog.csdn.net/qq_60609496/article/details/123900817 解决方法2 我按照方法1尝试添加了avx或者sse等,都不行,我是要做一个静态库的时候链接…...

Filecoin挖矿硬件怎么选?用Lotus-bench实测RTX 2080 Ti到GTX 1060的密封性能
Filecoin挖矿硬件实战指南:从GPU选型到Lotus-bench深度优化 在Filecoin挖矿生态中,GPU性能直接决定了密封效率和区块奖励获取能力。面对市场上从高端RTX 2080 Ti到入门级GTX 1060的各类显卡,矿工往往陷入选择困境——官方推荐列表中的参数是否…...