pytorch常用的几个函数详解
文章目录
- view
- 基本用法
- 自动计算维度
- 保持原始数据不变
- t函数
- 功能
- 语法
- 返回值
- 示例
- 注意事项
- permute() 函数
- 基本概念
- permute() 函数的使用
- unsqueeze() 函数
- 基本概念
- unsqueeze() 函数的使用
- squeeze() 函数
- 基本概念
- squeeze() 函数的使用
- transpose() 函数
- 基本概念
- transpose() 函数的使用
- cat() 函数
- 语法
- 参数
- 返回值
- 示例
- 示例 1:连接两个向量
- 示例 2:连接两个矩阵
- 示例 3:连接多个张量
- stack() 函数
- 语法
- 参数
- 返回值
- 示例
- 示例 1:基本用法
- 示例 2:指定堆叠维度
- 示例 3:堆叠不同形状的张量
- chunk函数
- 语法
- 参数
- 返回值
- 示例和解释
- flip函数
- 语法
- 参数
- 返回值
- 示例
- 示例 1:翻转一维张量
- 示例 2:翻转二维张量的行和列
- 示例 3:只翻转二维张量的列
- ReLU函数
- Dropout函数
- sigmoid函数
- interpolate函数
- 基本语法
- 参数说明
- 返回值
- 示例
- Softmax函数
- 为什么使用 Softmax?
- 在 PyTorch 中如何使用 Softmax?
view
view() 是 PyTorch 中的一个常用函数,用于改变张量(tensor)的形状。在深度学习中,我们经常需要调整数据的形状以适应不同的网络结构或计算需求,view() 函数就是用来完成这个任务的。
基本用法
view() 函数接受一个形状参数,返回一个具有新形状的张量。例如:
import torchx = torch.randn(4, 4) # 创建一个 4x4 的随机张量
print(x.shape) # 输出原始形状:torch.Size([4, 4])y = x.view(2, 8) # 改变形状为 2x8
print(y.shape) # 输出新形状:torch.Size([2, 8])
这里,x 是一个形状为 (4, 4) 的张量,通过 view() 函数,我们将其形状改变为 (2, 8)。
自动计算维度
有时候,我们可能只知道部分维度的大小,其他维度的大小希望由 PyTorch 自动计算。这可以通过在 view() 函数中使用 -1 来实现。例如:
import torchx = torch.randn(4, 4) # 创建一个 4x4 的随机张量
print(x.shape) # 输出原始形状:torch.Size([4, 4])y = x.view(-1) # 将张量展平为一维
print(y.shape) # 输出新形状:torch.Size([16])
这里,-1 表示让 PyTorch 自动计算该维度的大小。因此,y 的形状会被自动计算为 (16,)。
保持原始数据不变
view() 函数返回的是一个新的张量,原始张量的数据并不会被改变。新的张量和原始张量共享相同的数据,但形状不同。这意味着对新张量的修改也会影响原始张量。例如:
import torchx = torch.randn(4, 4) # 创建一个 4x4 的随机张量
y = x.view(2, 8) # 改变形状为 2x8y += 1.0 # 对新张量进行修改
print(x) # 输出原始张量,可以看到其值也被改变了
在这个例子中,我们对 y(新形状的张量)进行了加法操作,结果 x(原始形状的张量)的值也被相应地改变了。这是因为 x 和 y 共享相同的数据。
view() 函数是 PyTorch 中非常实用的一个函数,它允许我们灵活地改变张量的形状以适应不同的计算需求。在使用 view() 时,需要注意新张量和原始张量共享数据的特点,以避免不必要的错误。
t函数
在PyTorch中,t() 函数用于对张量进行转置操作。下面我将对 t() 函数进行更详细的解释。
功能
t() 函数用于计算一个张量的转置。对于2D张量(即矩阵),它计算矩阵的转置,将行和列进行交换。对于更高维度的张量,t() 函数会对其最后两个维度进行转置。
语法
torch.t(input)
- input:要转置的输入张量。
返回值
- 返回一个新的张量,其中包含输入张量的转置。原始张量的数据不会被修改。
示例
下面是一个使用 t() 函数的示例:
import torch# 创建一个2D张量(矩阵)
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
print("原始张量 x:")
print(x)# 计算张量的转置
y = x.t()
print("转置后的张量 y:")
print(y)
输出:
原始张量 x:
tensor([[1, 2, 3],[4, 5, 6]])
转置后的张量 y:
tensor([[1, 4],[2, 5],[3, 6]])
在这个示例中,我们创建了一个2D张量 x,并使用 t() 函数计算其转置。结果是一个新的2D张量 y,其中行和列已经交换。注意,原始张量 x 的数据保持不变,而 y 是一个新的张量对象。
注意事项
- 对于2D张量(矩阵),
t()函数与transpose(0, 1)是等价的。但对于更高维度的张量,它们的行为是不同的。t()只对最后两个维度进行转置,而transpose()可以指定要转置的两个维度。 t()函数不会修改原始张量的数据,而是返回一个新的转置后的张量。
permute() 函数
permute() 是 PyTorch 中的一个非常有用的函数,用于重新排列张量的维度。在多维数据处理中,我们经常需要调整数据的维度顺序以适应不同的操作或模型需求,permute() 函数正是为此目的而设计的。
基本概念
首先,了解张量的维度是非常重要的。一个张量可以有多个维度,例如:一个1D张量(向量)有一个维度,一个2D张量(矩阵)有两个维度,以此类推。
当我们谈论重新排列张量的维度时,我们实际上是指改变这些维度的顺序。
permute() 函数的使用
permute() 函数接受一个参数,该参数是一个表示新维度顺序的元组。元组中的每个元素都是原始张量维度的索引。
示例 1:2D 张量(矩阵)的转置
假设我们有一个2D张量(即矩阵),并且我们想要转置它(即交换行和列)。这可以通过使用 permute() 函数轻松实现。
import torch# 创建一个2D张量
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
print("原始张量:")
print(x)# 使用permute进行转置
y = x.permute(1, 0)
print("转置后的张量:")
print(y)
输出:
原始张量:
tensor([[1, 2, 3],[4, 5, 6]])
转置后的张量:
tensor([[1, 4],[2, 5],[3, 6]])
在这个例子中,原始张量的维度是 (2, 3)。通过 permute(1, 0),我们交换了维度的位置,得到了一个新的形状为 (3, 2) 的张量。
示例 2:更高维度张量的排列
permute() 同样可以用于更高维度的张量。例如,假设我们有一个形状为 (batch_size, channels, height, width) 的4D张量,并且我们想要将其转换为 (channels, batch_size, height, width)。
import torch# 创建一个4D张量
x = torch.rand((2, 3, 4, 5)) # Shape: [batch_size, channels, height, width]
print("原始张量的形状:", x.shape)# 重新排列维度
y = x.permute(1, 0, 2, 3) # New shape: [channels, batch_size, height, width]
print("重新排列后张量的形状:", y.shape)
输出:
原始张量的形状: torch.Size([2, 3, 4, 5])
重新排列后张量的形状: torch.Size([3, 2, 4, 5])
permute() 函数提供了一种灵活的方式来重新排列张量的维度。通过指定一个新的维度顺序,我们可以轻松地适应不同的数据处理和模型训练需求。
unsqueeze() 函数
unsqueeze 是 PyTorch 中的一个非常有用的函数,用于增加张量的维度。在处理多维数据时,我们经常需要改变数据的形状以适应不同的操作或模型需求,unsqueeze 正是为此目的而设计的。
基本概念
在理解 unsqueeze 之前,首先要知道张量的维度。一个张量可以有多个维度,例如:一个1D张量(向量)有一个维度,一个2D张量(矩阵)有两个维度,以此类推。
当我们谈论增加张量的维度时,我们实际上是在指定位置插入一个新的维度,这个新的维度的大小是1。
unsqueeze() 函数的使用
unsqueeze 函数接受一个参数,该参数表示要插入新维度的位置。位置是从0开始计数的。
语法:
torch.unsqueeze(input, dim)
input:输入张量。dim:插入新维度的位置。
示例:
假设我们有一个1D张量(向量)[1, 2, 3, 4],并且我们想要在第0维(最外层维度)之前增加一个维度,使其变为2D张量。
import torch# 创建一个1D张量
x = torch.tensor([1, 2, 3, 4])
print("原始张量:")
print(x)
print("原始张量的形状:", x.shape)# 使用unsqueeze增加维度
y = torch.unsqueeze(x, 0)
print("\n增加维度后的张量:")
print(y)
print("增加维度后的张量的形状:", y.shape)
输出:
原始张量:
tensor([1, 2, 3, 4])
原始张量的形状: torch.Size([4])增加维度后的张量:
tensor([[1, 2, 3, 4]])
增加维度后的张量的形状: torch.Size([1, 4])
可以看到,通过在第0维之前插入一个新的维度,我们成功地将1D张量转换为2D张量。新维度的大小是1。
squeeze() 函数
unsqueeze 函数提供了一种简单的方式来增加张量的维度。通过指定要插入新维度的位置,我们可以轻松地改变张量的形状,以适应不同的数据处理和模型训练需求。
squeeze 是 PyTorch 中的一个非常有用的函数,用于减少张量的维度。在处理多维数据时,我们经常需要改变数据的形状以适应不同的操作或模型需求,squeeze 正是为此目的而设计的。
基本概念
在理解 squeeze 之前,首先要知道张量的维度。一个张量可以有多个维度,例如:一个1D张量(向量)有一个维度,一个2D张量(矩阵)有两个维度,以此类推。
当我们谈论减少张量的维度时,我们实际上是指删除那些大小为1的维度。
squeeze() 函数的使用
squeeze 函数可以接受一个参数,该参数表示要删除的维度的索引。如果不提供参数,则默认删除所有大小为1的维度。
语法:
torch.squeeze(input, dim=None)
input:输入张量。dim:要删除的维度的索引。如果不提供,则删除所有大小为1的维度。
示例:
- 删除特定维度的示例:
假设我们有一个形状为 (10, 1, 10) 的3D张量,并且我们想要删除第1维(索引为1的维度)。
import torch# 创建一个3D张量
x = torch.rand((10, 1, 10))
print("原始张量的形状:", x.shape)# 使用squeeze删除第1维
y = torch.squeeze(x, 1)
print("删除维度后的张量的形状:", y.shape)
输出:
原始张量的形状: torch.Size([10, 1, 10])
删除维度后的张量的形状: torch.Size([10, 10])
- 删除所有大小为1的维度的示例:
假设我们有一个形状为 (10, 1, 10, 1) 的4D张量,并且我们想要删除所有大小为1的维度。
import torch# 创建一个4D张量
x = torch.rand((10, 1, 10, 1))
print("原始张量的形状:", x.shape)# 使用squeeze删除所有大小为1的维度
y = torch.squeeze(x)
print("删除维度后的张量的形状:", y.shape)
输出:
原始张量的形状: torch.Size([10, 1, 10, 1])
删除维度后的张量的形状: torch.Size([10, 10])
squeeze 函数提供了一种简单的方式来减少张量的维度。通过指定要删除的维度的索引或删除所有大小为1的维度,我们可以轻松地改变张量的形状,以适应不同的数据处理和模型训练需求。
transpose() 函数
transpose 是 PyTorch 中的一个函数,用于交换张量的两个维度。这个函数与 permute 不同,因为 transpose 只是交换两个特定的维度,而 permute 是重新排列所有维度。
基本概念
在理解 transpose 之前,首先要知道张量的维度。一个张量可以有多个维度,例如:一个1D张量(向量)有一个维度,一个2D张量(矩阵)有两个维度,以此类推。
当我们谈论交换张量的两个维度时,我们实际上是指交换这两个维度的位置。
transpose() 函数的使用
transpose 函数接受两个参数:要交换的第一个维度的索引和要交换的第二个维度的索引。
语法:
torch.transpose(input, dim0, dim1)
input:输入张量。dim0:要交换的第一个维度的索引。dim1:要交换的第二个维度的索引。
示例:
假设我们有一个形状为 (3, 4) 的2D张量,我们想要交换第0维和第1维的位置。
import torch# 创建一个2D张量
x = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
print("原始张量:")
print(x)
print("原始张量的形状:", x.shape)# 使用transpose交换维度
y = torch.transpose(x, 0, 1)
print("\n交换维度后的张量:")
print(y)
print("交换维度后的张量的形状:", y.shape)
输出:
原始张量:
tensor([[ 1, 2, 3, 4],[ 5, 6, 7, 8],[ 9, 10, 11, 12]])
原始张量的形状: torch.Size([3, 4])交换维度后的张量:
tensor([[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11],[ 4, 8, 12]])
交换维度后的张量的形状: torch.Size([4, 3])
可以看到,通过交换第0维和第1维的位置,我们成功地得到了一个新的2D张量。
cat() 函数
torch.cat 是 PyTorch 中用于将多个张量(tensors)连接在一起的函数。下面是对 torch.cat 函数的详细解释:
语法
torch.cat(tensors, dim=0, *, out=None) → Tensor
参数
tensors(sequence of Tensors):要连接的张量序列。所有张量必须具有相同的形状,除了在连接的维度上。dim(int, optional):要连接的维度。默认值是 0。out(Tensor, optional):输出张量。
返回值
返回一个包含输入张量数据的新张量,这些张量在指定的维度上被连接在一起。
示例
下面是一些使用 torch.cat 的示例:
示例 1:连接两个向量
import torchx = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])
z = torch.cat((x, y))
print(z) # 输出: tensor([1, 2, 3, 4, 5, 6])
在这个示例中,我们有两个形状相同的向量 x 和 y,我们使用 torch.cat 将它们连接在一起,结果是一个包含两个向量所有元素的新向量。
示例 2:连接两个矩阵
import torchx = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[5, 6]])
z = torch.cat((x, y), dim=0)
print(z) # 输出: tensor([[1, 2], [3, 4], [5, 6]])
在这个示例中,我们有两个形状不同的矩阵 x 和 y。我们通过在 dim=0(即行)上连接它们来创建一个新矩阵,该矩阵包含两个输入矩阵的所有行。
示例 3:连接多个张量
import torchx = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[5, 6], [7, 8]])
z = torch.tensor([[9, 10], [11, 12]])
w = torch.cat((x, y, z), dim=1)
print(w) # 输出: tensor([[ 1, 2, 5, 6, 9, 10], [ 3, 4, 7, 8, 11, 12]])
在这个示例中,我们有三个形状相同的矩阵 x、y 和 z。我们通过在 dim=1(即列)上连接它们来创建一个新矩阵,该矩阵包含所有输入矩阵的所有列。
stack() 函数
torch.stack 是 PyTorch 中的一个函数,用于将一系列张量按新的维度堆叠起来。
语法
torch.stack(tensors, dim=0, *, out=None) → Tensor
参数
tensors(sequence of Tensors) – 需要堆叠的张量序列。dim(int) – 插入新维度的索引。必须在 0 和 len(tensors[0].shape) + 1 (包含) 之间。out(Tensor, optional) – 输出张量。
返回值
返回一个张量,该张量是通过在指定维度上堆叠输入张量而构建的。
示例
下面是一些使用 torch.stack 的示例:
示例 1:基本用法
import torchx = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])
z = torch.stack((x, y))
print(z) # 输出: tensor([[1, 2, 3], [4, 5, 6]])
在这个例子中,我们有两个形状相同的1D张量 x 和 y。使用 torch.stack 将它们堆叠在一起,结果是一个2D张量,其中 x 和 y 成为新张量的行。
示例 2:指定堆叠维度
import torchx = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[5, 6], [7, 8]])
z = torch.stack((x, y), dim=2)
print(z) # 输出: tensor([[[1, 5], [2, 6]], [[3, 7], [4, 8]]])
在这个例子中,我们有两个形状相同的2D张量 x 和 y。通过在 dim=2(即第三个维度,因为索引是从0开始的)上堆叠它们,我们创建了一个新的3D张量。
示例 3:堆叠不同形状的张量
如果你尝试堆叠形状不匹配的张量,将会得到一个错误。例如:
import torchx = torch.tensor([1, 2, 3])
y = torch.tensor([[4, 5, 6], [7, 8, 9]])
# 下面的代码将会抛出一个错误,因为 x 和 y 的形状不匹配。
# z = torch.stack((x, y)) # 这行代码会引发错误。
在这个例子中,由于 x 和 y 的形状不匹配,因此无法将它们堆叠在一起。你需要确保要堆叠的所有张量都具有相同的形状。
chunk函数
torch.chunk 是 PyTorch 中的一个非常有用的函数,用于将张量(Tensor)沿特定维度拆分为多个较小的张量。下面是这个函数的详细解释。
语法
torch.chunk(input, chunks, dim=0)
参数
- input (Tensor): 输入的张量,即你想要拆分的张量。
- chunks (int): 你想要将输入张量拆分成的块数。
- dim (int, optional): 沿着哪个维度进行拆分。默认值是 0,即第一个维度。
返回值
该函数返回一个元组,其中包含拆分后的张量块。
示例和解释
- 基本用法:
假设我们有一个形状为 (6,) 的一维张量,并且我们想要将其拆分为3个部分。
import torchx = torch.tensor([1, 2, 3, 4, 5, 6])
chunks = torch.chunk(x, 3)
for i, chunk in enumerate(chunks):print(f"Chunk {i+1}: {chunk}")
输出:
Chunk 1: tensor([1, 2])
Chunk 2: tensor([3, 4])
Chunk 3: tensor([5, 6])
注意,由于我们的输入张量有6个元素,并且我们想要将其拆分为3个块,所以每个块有2个元素。
2. 指定拆分维度:
假设我们有一个形状为 (2, 3) 的二维张量,并且我们想要沿着第二个维度(列)进行拆分。
import torchx = torch.tensor([[1, 2, 3], [4, 5, 6]])
chunks = torch.chunk(x, 2, dim=1) # 沿着列(第二个维度)拆分
for i, chunk in enumerate(chunks):print(f"Chunk {i+1}:\n{chunk}\n")
输出:
Chunk 1:
tensor([[1, 2],[4, 5]])Chunk 2:
tensor([[3],[6]])
这里,由于我们的输入张量的形状是 (2, 3),并且我们沿着第二个维度拆分成2个块,所以第一个块包含前两列,第二个块包含最后一列。
3. 错误示例:
如果你尝试将一个形状为 (6,) 的张量拆分为4个块,你会得到一个错误,因为6不能被4整除。确保你的张量大小可以被 chunks 参数整除是很重要的。
4. 注意: 如果你的 dim 参数超出了张量的维度范围,你也会得到一个错误。例如,对于一个形状为 (3, 3) 的二维张量,有效的 dim 值是0和1。任何其他的值都会导致错误。
flip函数
torch.flip 是 PyTorch 中的一个函数,用于翻转张量(Tensor)中的数据。
语法
torch.flip(input, dims)
参数
- input (Tensor): 输入张量。
- dims (int or tuple of ints): 要翻转的维度。可以是单个维度或维度的元组。
返回值
返回一个与输入张量形状相同的新张量,但在指定的维度上进行了翻转。
示例
下面是一些使用 torch.flip 的示例:
示例 1:翻转一维张量
import torchx = torch.tensor([1, 2, 3, 4])
y = torch.flip(x, [0])
print(y) # 输出: tensor([4, 3, 2, 1])
在这个例子中,我们有一个一维张量 x,我们使用 torch.flip 并指定 dims=[0] 来翻转整个张量。结果是一个新的张量 y,其中元素的顺序被翻转。
示例 2:翻转二维张量的行和列
import torchx = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
y = torch.flip(x, [0, 1])
print(y) # 输出: tensor([[9, 8, 7], [6, 5, 4], [3, 2, 1]])
在这个例子中,我们有一个二维张量 x,我们使用 torch.flip 并指定 dims=[0, 1] 来分别翻转行和列。结果是一个新的张量 y,其中行和列的顺序都被翻转。
示例 3:只翻转二维张量的列
import torchx = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
y = torch.flip(x, [1])
print(y) # 输出: tensor([[3, 2, 1], [6, 5, 4], [9, 8, 7]])
在这个例子中,我们有一个二维张量 x,我们使用 torch.flip 并指定 dims=[1] 来只翻转列。结果是一个新的张量 y,其中列的顺序被翻转,但行的顺序保持不变。
ReLU函数
ReLU(Rectified Linear Unit)函数是深度学习中常用的一种激活函数,它在神经网络中引入了非线性特性。在PyTorch中,可以使用torch.relu()函数或nn.ReLU()层来应用ReLU激活。
ReLU函数的数学表达式为:
f(x) = max(0, x)
其中,x是输入张量(tensor)。ReLU函数将负数值映射为0,将正数值映射为它们本身。这种操作称为“整流”(rectification),因此得名ReLU。
ReLU函数具有以下特点:
- 计算简单:ReLU函数的计算非常简单,只需要比较输入值和0的大小即可。这使得它在前向传播和反向传播过程中都具有高效性。
- 稀疏性:由于ReLU函数将负数值映射为0,因此在神经网络中引入了一定的稀疏性。这种稀疏性有助于提取输入数据的特征,并提高模型的泛化能力。
- 缓解梯度消失问题:在深度神经网络中,当使用Sigmoid或Tanh等饱和激活函数时,梯度在反向传播过程中可能会逐渐消失。而ReLU函数的梯度要么是0(对于负输入),要么是1(对于正输入),因此在一定程度上缓解了梯度消失问题。
在PyTorch中,你可以使用以下两种方式应用ReLU激活函数:
- 使用
torch.relu()函数:
import torchx = torch.tensor([-1.0, 0.0, 1.0, 2.0])
y = torch.relu(x)
print(y) # 输出: tensor([0., 0., 1., 2.])
- 使用
nn.ReLU()层:
import torch.nn as nnrelu_layer = nn.ReLU()
x = torch.tensor([-1.0, 0.0, 1.0, 2.0])
y = relu_layer(x)
print(y) # 输出: tensor([0., 0., 1., 2.])
这两种方式都可以实现ReLU激活函数的功能。使用torch.relu()函数是一种简单的、直接的方法;而使用nn.ReLU()层则更为灵活,可以将ReLU层嵌入到神经网络模型中。
Dropout函数
Dropout是一种正则化技术,用于防止神经网络过拟合。它在训练过程中随机地将神经网络的某些节点设置为0,这意味着在前向传播过程中,这些节点不会有任何贡献。由于每个迭代过程中都随机“关闭”了一部分节点,实际上神经网络的结构在每次迭代时都略有不同。这样做可以使得模型不太可能过度依赖于某些特定的节点,从而提高模型的泛化能力。
在PyTorch中,torch.nn.Dropout是一个实现Dropout的模块。其语法如下:
torch.nn.Dropout(p=0.5, inplace=False)
参数:
p:在训练过程中,每一层后面,将随机失活的概率。默认值为0.5。inplace:如果设置为True,将在输入上进行操作并返回,而不是返回新的Tensor。默认值为False。
下面是一个简单的例子,说明如何在神经网络中使用Dropout:
import torch
import torch.nn as nnclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5输入图像,16个通道self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)self.dropout = nn.Dropout(p=0.2) # Dropout layer with dropout probability of 0.2def forward(self, x):x = self.fc1(x)x = self.dropout(x) # Apply dropout after the first fully connected layerx = self.fc2(x)x = self.dropout(x) # Apply dropout after the second fully connected layerx = self.fc3(x)return x
在这个例子中,我们在两个全连接层之后使用了Dropout。在训练过程中,每次前向传播时,都有20%的节点会被随机地设置为0。这有助于防止模型过拟合训练数据。
需要注意的是,Dropout只在训练过程中使用。在评估或测试模型时,通常会关闭Dropout(即将p设置为0),以确保输出的稳定性。
sigmoid函数
sigmoid函数在深度学习和神经网络中扮演着非常重要的角色。它被广泛用作激活函数,帮助神经网络学习和模拟复杂的模式。
函数形式:
sigmoid(x)=11+e−x\text{sigmoid}(x) = \frac{1}{1 + e^{-x}}sigmoid(x)=1+e−x1
其中 xxx 是输入。
主要特性:
- 输出范围:sigmoid函数的输出范围总是在(0, 1)之间,这使得它在某些场景下(例如:二分类问题的输出层)特别有用。
- 非线性:sigmoid函数是非线性的,这意味着它可以帮助神经网络捕捉和学习输入数据中的非线性关系。
- 可微性:sigmoid函数在其整个定义域上都是可微的,这意味着我们可以使用基于梯度的方法(如梯度下降)来优化神经网络的参数。
- 饱和性:当 xxx 很大或很小时,sigmoid函数的梯度接近于0。这可能导致所谓的“梯度消失”问题,使得神经网络在训练过程中的参数更新变得非常缓慢。
在PyTorch中的使用:
在PyTorch中,你可以很容易地使用torch.sigmoid()函数来计算sigmoid激活。例如:
import torch# 创建一个张量
x = torch.tensor([-1.0, 0.0, 1.0])# 使用sigmoid函数
y = torch.sigmoid(x)
print(y) # 输出: tensor([0.2689, 0.5000, 0.7311])
应用:
虽然sigmoid函数在过去被广泛用作神经网络的隐藏层激活函数,但现在更常见的选择是ReLU(Rectified Linear Unit)及其变体,因为它们可以缓解梯度消失问题并加速训练。然而,在二分类问题的输出层中,sigmoid激活仍然是一个流行的选择。
interpolate函数
interpolate()函数是PyTorch中用于对多维数据进行插值的一个非常有用的函数。它可以对输入张量进行上采样或下采样,以改变其尺寸。这个函数特别在处理图像、时间序列数据或其他需要调整尺寸的多维数据时非常有用。
基本语法
torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None)
参数说明
input:输入张量,可以是任意维度的。size:输出张量的大小,可以是一个整数或整数的元组。如果指定了size,则忽略scale_factor。scale_factor:相对于输入大小的放大或缩小因子。可以是一个浮点数或浮点数的元组。如果指定了size,则忽略此参数。mode:插值模式,可以是'nearest'、'linear'、'bilinear'、'bicubic'、'trilinear'、'area'等。不同的模式适用于不同维度和类型的数据。align_corners:如果为True,则输入和输出张量的角落像素将对齐,从而保留这些像素的值。这只在mode为'linear'、'bilinear'或'trilinear'时有效。默认为False。recompute_scale_factor:如果为True,则在执行插值之前会重新计算scale_factor,以确保输出大小与指定的size匹配。默认为False。
返回值
返回一个与输入张量形状相同,但大小调整为指定size或scale_factor的新张量。
示例
下面是一个使用PyTorch interpolate()函数进行图像上采样的简单示例:
import torch
import torch.nn.functional as F# 假设我们有一个1x1的输入图像
input_image = torch.tensor([[[[1.0]]]], dtype=torch.float32)# 使用bilinear插值进行上采样到3x3大小
output_image = F.interpolate(input_image, size=(3, 3), mode='bilinear', align_corners=True)print(output_image)
输出:
tensor([[[[1.0000, 1.0000, 1.0000],[1.0000, 1.0000, 1.0000],[1.0000, 1.0000, 1.0000]]]])
在这个例子中,我们使用interpolate()函数将一个1x1的图像上采样到一个3x3的图像,使用了双线性插值(bilinear)。注意,因为输入图像只有一个像素,并且该像素的值为1.0,所以上采样后的输出图像所有像素值也都是1.0。
masked_select函数
torch.masked_select() 是 PyTorch 中的一个函数,它用于从输入张量中选择满足特定条件的元素。该函数的主要参数有两个:输入张量和一个布尔掩码。掩码的形状必须与输入张量的形状相同,掩码中的每个元素对应于输入张量中的相应元素。当掩码中的元素为 True 时,相应的输入元素会被选中。
函数的定义如下:
torch.masked_select(input, mask, out=None)
参数:
input(Tensor) – 输入张量。mask(BoolTensor) – 布尔掩码,形状与input相同。out(Tensor, optional) – 输出张量。
返回值:
一个一维张量,包含所有被选中的元素。返回的张量不会保留原始张量的形状信息。
示例:
假设我们有一个形状为 [3, 3] 的张量 x 和一个相应的布尔掩码 mask:
import torchx = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
mask = torch.tensor([[True, False, True], [False, True, False], [True, True, True]], dtype=torch.bool)
我们可以使用 torch.masked_select() 来选择满足条件的元素:
selected_elements = torch.masked_select(x, mask)
print(selected_elements)
输出:
tensor([1, 3, 5, 7, 8, 9])
在这个例子中,掩码中的 True 值对应于输入张量 x 中的元素 [1, 3, 5, 7, 8, 9],因此这些元素被选中并返回为一个一维张量。
Softmax函数
Softmax 是一个在机器学习和深度学习中常见的函数,主要用于将一个实数向量映射到概率分布上。具体来说,给定一个向量 z \mathbf{z} z,Softmax 函数将其转换为概率分布 p \mathbf{p} p,其中 p i p_i pi 是 z \mathbf{z} z 的第 i 个元素的指数除以所有元素的指数和。
数学上,Softmax 函数可以表示为:
p i = e z i ∑ j = 1 n e z j p_i = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}} pi=∑j=1nezjezi
其中 n n n 是输入向量的维度。
为什么使用 Softmax?
- 概率分布: Softmax 函数可以将任何实数向量转换为概率分布,使得所有输出概率之和为 1。这使得它非常适合用于多分类问题中,特别是当输出有多个类别时。
- 梯度平滑: 在反向传播中,Softmax 的梯度是平滑的,这有助于优化算法(如梯度下降)更稳定地工作。
- 计算方便: 由于 Softmax 是基于指数函数的,它通常可以通过查表来高效计算,这有助于加速训练过程。
在 PyTorch 中如何使用 Softmax?
在 PyTorch 中,你可以使用 torch.nn.Softmax 类或 torch.nn.functional.softmax 函数来应用 Softmax。
例如:
import torch
import torch.nn as nn
import torch.nn.functional as F# 定义一个张量
tensor = torch.tensor([1.0, 2.0, 3.0])# 使用 PyTorch 的 Softmax 类
softmax = nn.Softmax(dim=0)
result = softmax(tensor)
print(result) # 输出: tensor([0.0900, 0.2777, 0.6323])# 或者使用 PyTorch 的 functional 模块
result = F.softmax(tensor, dim=0)
print(result) # 输出: tensor([0.0900, 0.2777, 0.6323])
在上面的例子中,我们定义了一个一维张量并应用了 Softmax。dim=0 表示沿着第一个维度(通常是行)进行 Softmax。如果你希望沿着列(第二个维度)进行 Softmax,可以将 dim 设置为 1。
相关文章:

pytorch常用的几个函数详解
文章目录 view基本用法自动计算维度保持原始数据不变 t函数功能语法返回值示例注意事项 permute() 函数基本概念permute() 函数的使用 unsqueeze() 函数基本概念unsqueeze() 函数的使用 squeeze() 函数基本概念squeeze() 函数的使用 transpose() 函数基本概念transpose() 函数的…...

Linux下安装Flume
1 下载Flume Welcome to Apache Flume — Apache Flume 下载1.9.0版本 2 上传服务器并解压安装 3 删除lib目录下的guava-11.0.2.jar (如同服务器安装了hadoop,则删除,如没有安装hadoop则保留这个文件,否则无法启动flume&#…...

20231225使用BLE-AnalyzerPro WCH升级版BLE-PRO蓝牙分析仪抓取BLE广播数据
20231225使用BLE-AnalyzerPro WCH升级版BLE-PRO蓝牙分析仪抓取BLE广播数据 2023/12/25 20:05 结论:硬件蓝牙分析仪 不一定比 手机端的APK的效果好! 亿佰特E104-2G4U04A需要3片【单通道】,电脑端的UI为全英文的。 BLE-AnalyzerPro WCH升级版B…...
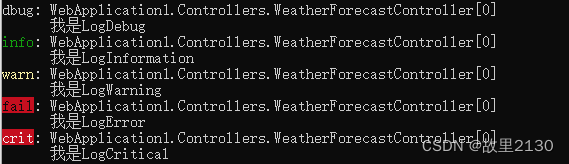
.net6使用Sejil可视化日志
(关注博主后,在“粉丝专栏”,可免费阅读此文) 之前介绍了这篇.net 5使用LogDashboard_.net 5logdashboard rootpath-CSDN博客 这篇文章将会更加的简单,最终的效果都是可视化日志。 在程序非常庞大的时候&…...
 : 大数据导出为insert)
mysql(51) : 大数据导出为insert
代码 import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; import java.math.BigDecimal; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Objects;public class 大数据导出为insert {public …...

MFC查找错误的方法
在visual studio2005上Debug总是会出现各种问题,比如指针错误,乱码等,无法正确查看变量的值,这时候可以使用AfxMessageBox()方法对数据进行弹窗输出,但AfxMessageBox()函数只支持CString数据输出,我们就需要…...
Jave EE 网络原理之网络层与数据链路层
文章目录 1. 网络层1.1 IP 协议1.1.1 协议头格式1.1.2 地址管理1.1.2.1 认识 IP 地址 1.1.3 路由选择 2. 数据链路层2.1 认识以太网2.1.1 以太网帧格式2.1.2 DNS 应用层协议 1. 网络层 网络层要做的事情,主要是两个方面 地址管理 (制定一系列的规则&am…...

ElasticSearch 使用映射定义索引结构
动态映射 dynamic 可选值解释true默认值,启用动态映射,新增的字段会添加到映射中runtime查询时动态添加到映射中false禁用动态映射,忽略未知字段strict发现未知字段,抛出异常 显示映射 创建映射 PUT user {"mappings&qu…...

HTML---网页布局
目录 文章目录 一.常见的网页布局 二.标准文档流 标准文档流常见标签 三.display属性 四.float属性 总结 一.常见网页布局 二.标准文档流 标准文档流常见标签 标准文档流的组成 块级元素<div>、<p>、<h1>-<h6>、<ul>、<ol>等内联元素<…...
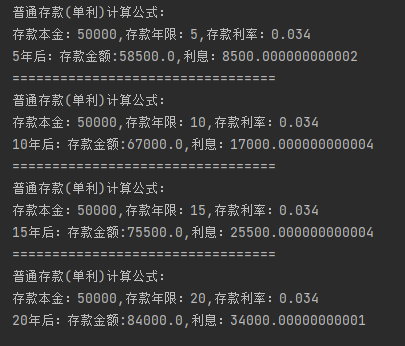
python 普通存款(单利)计算公式:
python 普通存款(单利)计算公式: 代码如下: #普通存款 单利计算公式:a:原值,n:计算年限,li:利率(小数), def danli(a,n,li):print("普通存款(单利)计…...

什么是 PHP 内存溢出 ?遇到了要如何解决呢 ?
PHP内存溢出指的是在PHP应用程序中,分配给脚本执行的内存超出了PHP配置文件中设置的限制。当脚本尝试使用比可用内存更多的内存时,就会发生内存溢出错误。 一、内存溢出可能由以下几个原因引起: 循环引用:如果存在循环引用&#…...
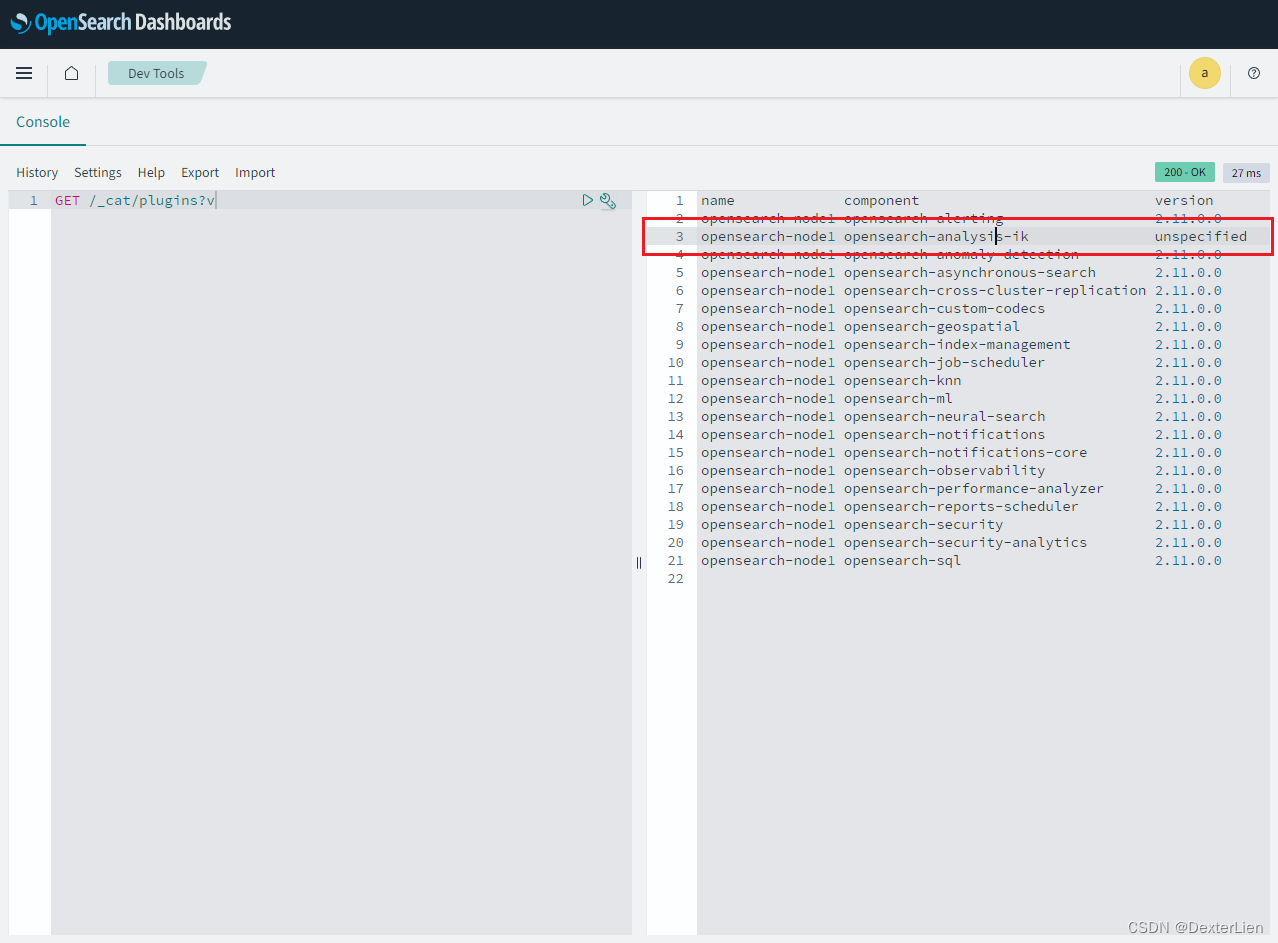
本地使用 docker 运行OpenSearch + Dashboard + IK 分词插件
准备基础镜像 注意一定要拉取和当前 IK 分词插件版本一致的 OpenSearch 镜像: https://github.com/aparo/opensearch-analysis-ik/releases 写这篇文章的时候 IK 最新版本 2.11.0, 而 dockerhub 上 OpenSearch 最新版是 2.11.1 如果版本不匹配的话是不能用的, 小版本号对不上…...
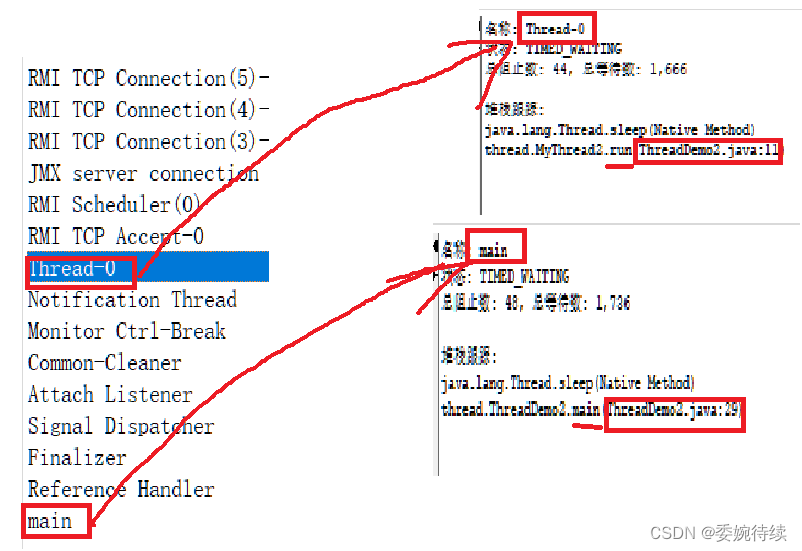
【JavaEE初阶一】线程的概念与简单创建
1. 认识线程(Thread) 1.1 关于线程 1.1.1 线程是什么 由前一节的内容可知,进程在进行频繁的创建和销毁的时候,开销比较大(主要体现在资源的申请和释放上),线程就是为了解决上述产生的问题而提…...
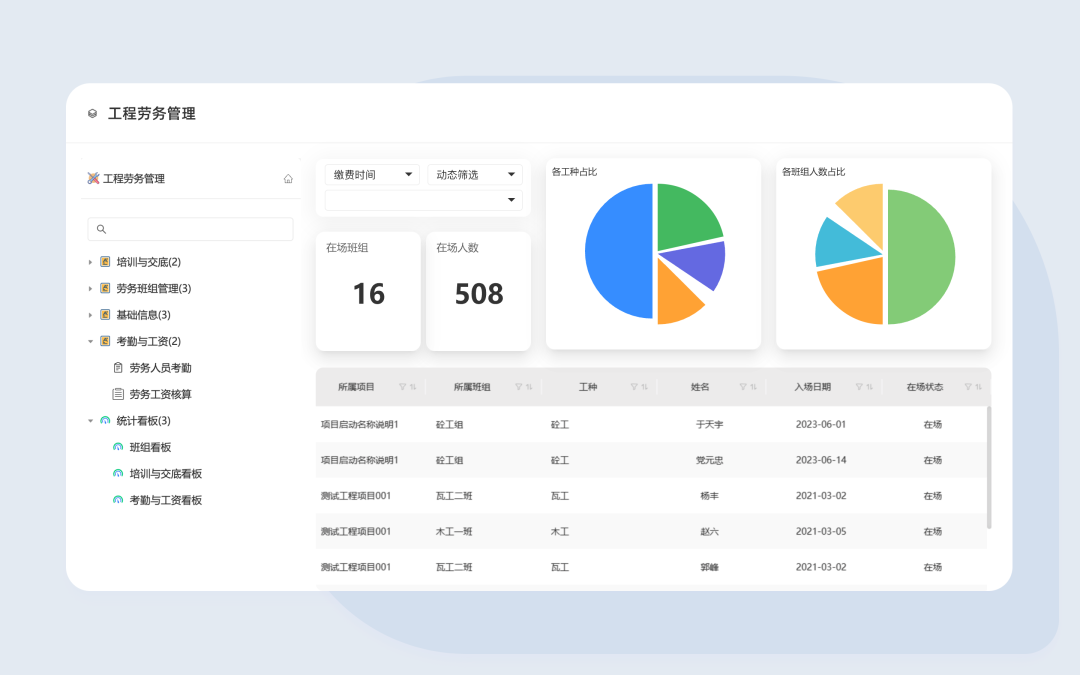
三叠云工程劳务管理,优化建筑施工管理,提升效率与质量
随着建筑行业的蓬勃发展,工程施工现场管理变得愈发复杂。传统的人员管理方式已经无法满足企业快速发展的需求。如何提高施工效率、优化人力资源管理成为了建筑企业亟待解决的问题。逐渐走向数字化的工程建设行业,急需一种足以匹配这一时代变革、高效管理…...

RocketMQ连接报错RemotingConnectException: connect to <192.168.57.129:9876>解决
文章目录 前言一、RocketMQ 连接报错处理1.1 报错信息1.2 修改 broker.conf 文件1.3 Linux 开放端口1.4 项目启动成功 前言 上一篇文章:基于SpringBoot整合RocketMQ异步发送短信功能在项目启动的过程中报了 RocketMQ 连接错误。针对这个问题,本文给予记…...

设计模式--桥接模式
实验9:桥接模式 本次实验属于模仿型实验,通过本次实验学生将掌握以下内容: 1、理解桥接模式的动机,掌握该模式的结构; 2、能够利用桥接模式解决实际问题。 [实验任务]:两个维度的桥接模式 用桥接模式…...

redis基本用法学习(C#调用StackExchange.Redis操作redis)
StackExchange.Redis是基于C#的高性能通用redis操作客户端,也属于常用的redis客户端之一,本文学习其基本用法。 新建Winform项目,在Nuget包管理器中搜索并安装StackExchange.Redis,如下图所示: StackExchange.…...
SQL题:1308. 不同性别每日分数总计)
单挑力扣(LeetCode)SQL题:1308. 不同性别每日分数总计
相信很多学习SQL的小伙伴都面临这样的困境,学习完书本上的SQL基础知识后,一方面想测试下自己的水平;另一方面想进一步提升,却不知道方法。 其实,对于技能型知识,我的观点一贯都是:多练习、多实…...

Vue3组合式-依赖注入provideinject
一、注意点 专门强调了是3.0且是组合式,不是2.0不支持也不是选项式不支持provide&&inject,是支持但是有很明显的弊端,不建议使用 二、场景 官方的解释: 通常情况下,当我们需要从父组件向子组件传递数据时,会…...

SRE 与 DevOps 的不同之处
尽管网站可靠性工程 (SRE) 理念早在 2003 年就由 Google 的 Ben Treynor Sloss 提出,但其近年来却一直受到追捧。随着 DevOps 实践已经在许多组织中牢固确立,两者之间的冲突是否已经显现?SRE 只不过是一种过时的趋势吗?是 SRE 补充…...

在 Taotoken 上观测多模型 API 调用用量与成本明细
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Taotoken 上观测多模型 API 调用用量与成本明细 对于使用多个大模型 API 的开发者而言,清晰、透明地掌握调用情况和…...

终端工作空间新选择:从 tmux 到 Zellij 的迁移与实战
1. 为什么需要从 tmux 迁移到 Zellij 作为一个用了五年 tmux 的老用户,我最初对 Zellij 这个"新玩具"是持怀疑态度的。直到有一次在远程服务器上调试时,tmux 的窗格突然卡死,所有工作进度瞬间归零,我才开始认真寻找替代…...

品牌如何通过AI搜索优化构建长期影响力?GEO战略资产打造可持续竞争壁垒
摘要品牌通过AI搜索优化(GEO)构建长期影响力与权威认知,关键在于将其从短期获客技术升级为沉淀知识、构建AI信任机制的战略资产。核心路径是持续向AI模型提供高质量、结构化的品牌知识,使其成为AI的“可信信源”,并主动…...

BilibiliDown:专业级B站视频下载工具,高效构建个人媒体库
BilibiliDown:专业级B站视频下载工具,高效构建个人媒体库 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.co…...

在vscode中快速配置taotoken的claude code插件实现稳定编程助手
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在VSCode中快速配置Taotoken的Claude Code插件实现稳定编程助手 对于使用VSCode的开发者而言,Claude Code插件是一个强…...

终极Cybersources渗透测试工具大全:从Web应用到网络安全的全面覆盖指南
终极Cybersources渗透测试工具大全:从Web应用到网络安全的全面覆盖指南 【免费下载链接】cybersources A curated list of cybersecurity tools and resources. 项目地址: https://gitcode.com/gh_mirrors/cy/cybersources Cybersources是一个精心策划的网络…...

【模块化设计-10】UART1 驱动 + 环形 FIFO 实现高效串口数据收发
在嵌入式开发中,串口(UART)是最常用的通信接口之一,而直接采用中断 缓冲区的方式处理串口数据,能有效避免数据丢失、提升收发效率。本文将基于实际项目代码,详解UART1 驱动与环形 FIFO(ring_fi…...

Wwise音频工具完全指南:3步轻松解包和修改游戏音频文件
Wwise音频工具完全指南:3步轻松解包和修改游戏音频文件 【免费下载链接】wwiseutil Tools for unpacking and modifying Wwise SoundBank and File Package files. 项目地址: https://gitcode.com/gh_mirrors/ww/wwiseutil 还在为无法编辑游戏音频文件而烦恼…...

5分钟实现PNG/JPG到SVG的终极转换:vectorizer矢量化工具完全指南
5分钟实现PNG/JPG到SVG的终极转换:vectorizer矢量化工具完全指南 【免费下载链接】vectorizer Potrace based multi-colored raster to vector tracer. Inputs PNG/JPG returns SVG 项目地址: https://gitcode.com/gh_mirrors/ve/vectorizer vectorizer是一个…...

Linux SSH身份验证全解析:从密码到证书的六种方法与实践指南
1. SSH身份验证:守护远程访问的第一道门在Linux世界里,SSH(Secure Shell)就是那把打开远程服务器大门的钥匙。无论是管理云服务器、部署应用,还是进行日常运维,我们几乎每天都在和它打交道。但很多人可能没…...