CNN实现对手写字体的迭代
导入库
import torchvision
import torch
from torchvision.transforms import ToTensor
from torch import nn
import matplotlib.pyplot as plt导入手写字体数据
train_ds=torchvision.datasets.MNIST('data/',train=True,transform=ToTensor(),download=True)
test_ds=torchvision.datasets.MNIST('data/',train=False,transform=ToTensor(),download=True)
train_dl=torch.utils.data.DataLoader(train_ds,batch_size=64,shuffle=True)
test_dl=torch.utils.data.DataLoader(test_ds,batch_size=46)
imgs,labels=next(iter(train_dl))
print(imgs.shape)
print(labels.shape)
从上述代码中可以看到,train_dl返回的图片数据是四维的,4个维度分别代表批次、通道数、高度和宽度(batch,channel,height,width),这正是PyTorch下卷积模型所需要的图片输入格式
创建卷积模型并训练
下面创建卷积模型来识别MNIST手写数据集。我们所创建的卷积模型先试用两个卷积层和两个池化层,然后将最后一个池化的输出展平为二维数据形式连接到全连接层,最后是输出层,中间的每一层都是用ReLU函数激活,输出层的输出张量长度为10,与类别数一致。代码如下
class Model(nn.Module):def __init__(self):super().__init__()self.conv1=nn.Conv2d(1,6,5) #初始化第一个卷积层self.conv2=nn.Conv2d(6,16,5) #初始化第二个卷积层self.liner_1=nn.Linear(16*4*4,256) #初始化全连接层16*4*4为输入的特征,256为输出的特征#就是将一个大小为16×4×4的输入特征映射到一个大小为256的输出特征空间中self.liner_2=nn.Linear(256,10) #初始化输出层def forward(self,input):#调用第一个卷积层和池化层x=torch.max_pool2d(torch.relu(self.conv1(input)),2)#调用第二个卷积层和池化层x=torch.max_pool2d(torch.relu(self.conv2(x)),2)# view()方法将数据展平为二维形式# torch.Size([64,16,4,4])->torch.Size([64,16*4*4])x=x.view(-1,16*4*4)x=torch.relu(self.liner_1(x)) # 全连接层x=self.liner_2(x) #输出层return x#判断当前可用的device,如果显卡可用,就设置为cuda,否则设置为cpu
device="cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))#初始化模型,并使用.to()方法将其上传到device
#如果GPU可以用,会上传到显存,如果device是CPU,依保留在内存
model=Model().to(device) # 初始化模型并设置设备
print(model)loss_fn=nn.CrossEntropyLoss() # 初始化交叉熵损失函数optimizer=torch.optim.SGD(model.parameters(),lr=0.001) # 初始化优化器def train(dataloader,model,loss_fn,optimizer):size=len(dataloader.dataset) # 获取当前数据集样本总数量num_batches=len(dataloader) #获得当前dataloader总批次数# train_loss用于累计所有批次的损失之和,correct用于累计预测正确的样本总数train_loss,correct=0,0for X,y in dataloader: #对dataloader进行迭代X,y=X.to(device),y.to(device) #每一批次的数据设置为使用当前device进行预测,并计算一个批次的损失pred=model(X)loss=loss_fn(pred,y) # 返回的是平均损失#使用反向传播算法,根据损失优化模型参数optimizer.zero_grad() #将模型参数的梯度全部归零loss.backward() # 损失反向传播,计算模型参数梯度optimizer.step() # 根据梯度优化参数with torch.no_grad():# correct 用于累计预测正确的样本总数correct+=(pred.argmax(1)==y).type(torch.float).sum().item()#train_loss用于累计所有批次的损失之和train_loss+=loss.item()#train_loss是所有批次的损失之和,所以计算全部样本的平均损失时需要处于总批次数train_loss/=num_batches#correct是预测正确的样本总是,若计算整个epoch总体正确率,需除以样本总数量correct/=sizereturn train_loss,correctdef test(dataloader,model):size=len(dataloader.dataset)num_batches=len(dataloader)test_loss,correct=0,0with torch.no_grad():for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model(X)test_loss+=loss_fn(pred,y).item()correct+=(pred.argmax(1)==y).type(torch.float).sum().item()test_loss/=num_batchescorrect/=sizereturn test_loss,correctepochs=50 #一个epoch代表对全部数据训练一遍train_loss=[] #每个epoch训练中训练数据集的平均损失被添加到此列表
train_acc=[] #每个epoch训练中训练数据集的平均正确率被添加到此列表
test_loss=[] #每个epoch训练中测试数据集的平均损失被添加到此列表
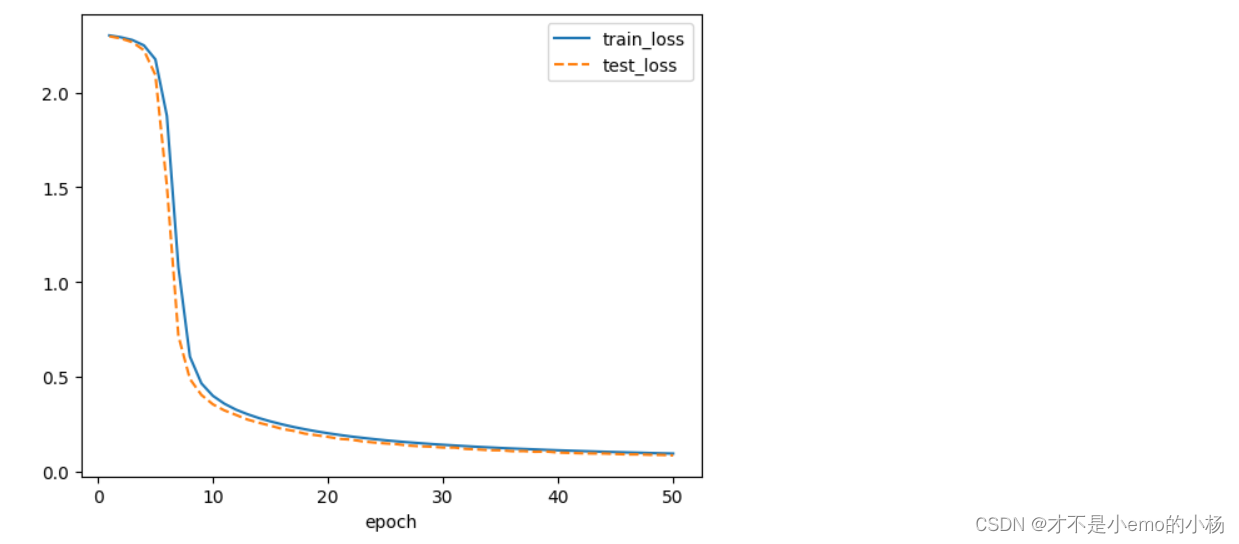
test_acc=[] #每个epoch训练中测试数据集的平均正确率被添加到此列表for epoch in range(epochs):#调用train()函数训练epoch_loss,epoch_acc=train(train_dl,model,loss_fn,optimizer)#调用test()函数测试epoch_test_loss,epoch_test_acc=test(test_dl,model)train_loss.append(epoch_loss)train_acc.append(epoch_acc)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)#定义一个打印模版template=("epoch:{:2d},train_loss:{:.5f},train_acc:{:.1f}%,test_loss:{:.5f},test_acc:{:.1f}%")#输出当前的epoch的训练集损失、训练集正确率、测试集损失、测试集正确率print(template.format(epoch,epoch_loss,epoch_acc*100,epoch_test_loss,epoch_test_acc*100))print("Done!")plt.plot(range(1,epochs+1),train_loss,label="train_loss")
plt.plot(range(1,epochs+1),test_loss,label='test_loss',ls="--")
plt.xlabel('epoch')
plt.legend()
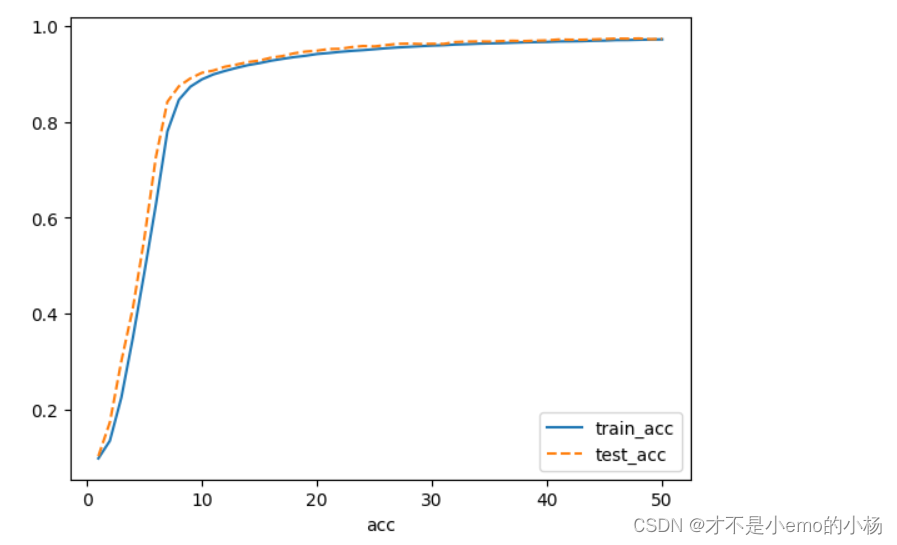
plt.show()plt.plot(range(1, epochs + 1), train_acc, label="train_acc")
plt.plot(range(1, epochs + 1), test_acc, label='test_acc', ls="--")
plt.xlabel('acc')
plt.legend()
plt.show()
函数式API
import torch.nn.functional as Fclass Model(nn.Module):def __init__(self):super().__init__()self.conv1=nn.Conv2d(1,6,5) #初始化第一个卷积层self.conv2=nn.Conv2d(6,16,5) #初始化第二个卷积层self.liner_1=nn.Linear(16*4*4,256) #初始化全连接层16*4*4为输入的特征,256为输出的特征#就是将一个大小为16×4×4的输入特征映射到一个大小为256的输出特征空间中self.liner_2=nn.Linear(256,10) #初始化输出层def forward(self,input):#调用第一个卷积层和池化层x=F.max_pool2d(F.relu(self.conv1(input)),2)#调用第二个卷积层和池化层x=F.max_pool2d(F.relu(self.conv2(x)),2)# view()方法将数据展平为二维形式# torch.Size([64,16,4,4])->torch.Size([64,16*4*4])x=x.view(-1,16*4*4)x=F.relu(self.liner_1(x)) # 全连接层x=self.liner_2(x) #输出层return x相关文章:
CNN实现对手写字体的迭代
导入库 import torchvision import torch from torchvision.transforms import ToTensor from torch import nn import matplotlib.pyplot as plt 导入手写字体数据 train_dstorchvision.datasets.MNIST(data/,trainTrue,transformToTensor(),downloadTrue) test_dstorchvis…...
docker学习笔记01-安装docker
1.Docker的概述 用Go语言实现的开源应用项目(container);克服操作系统的笨重;快速部署;只隔离应用程序的运行时环境但容器之间可以共享同一个操作系统;Docker通过隔离机制,每个容器间是互相隔离…...

【《设计模式之美》】如何取舍继承与组合
文章目录 什么情况下不推荐使用继承?组合相比继承有哪些优势?使用组合、继承的时机 本文主要想了解: 为什么组合优于继承,多用组合少用继承。如何使用组合来替代继承哪些情况适用继承、组合。有哪些设计模式使用到了继承、组合。 …...

一步到位:用Python实现PC屏幕截图并自动发送邮件,实现屏幕监控
在当前的数字化世界中,自动化已经成为我们日常生活和工作中的关键部分。它不仅提高了效率,还节省了大量的时间和精力。在这篇文章中,我们将探讨如何使用Python来实现一个特定的自动化任务 - PC屏幕截图自动发送到指定的邮箱。 这个任务可能看…...
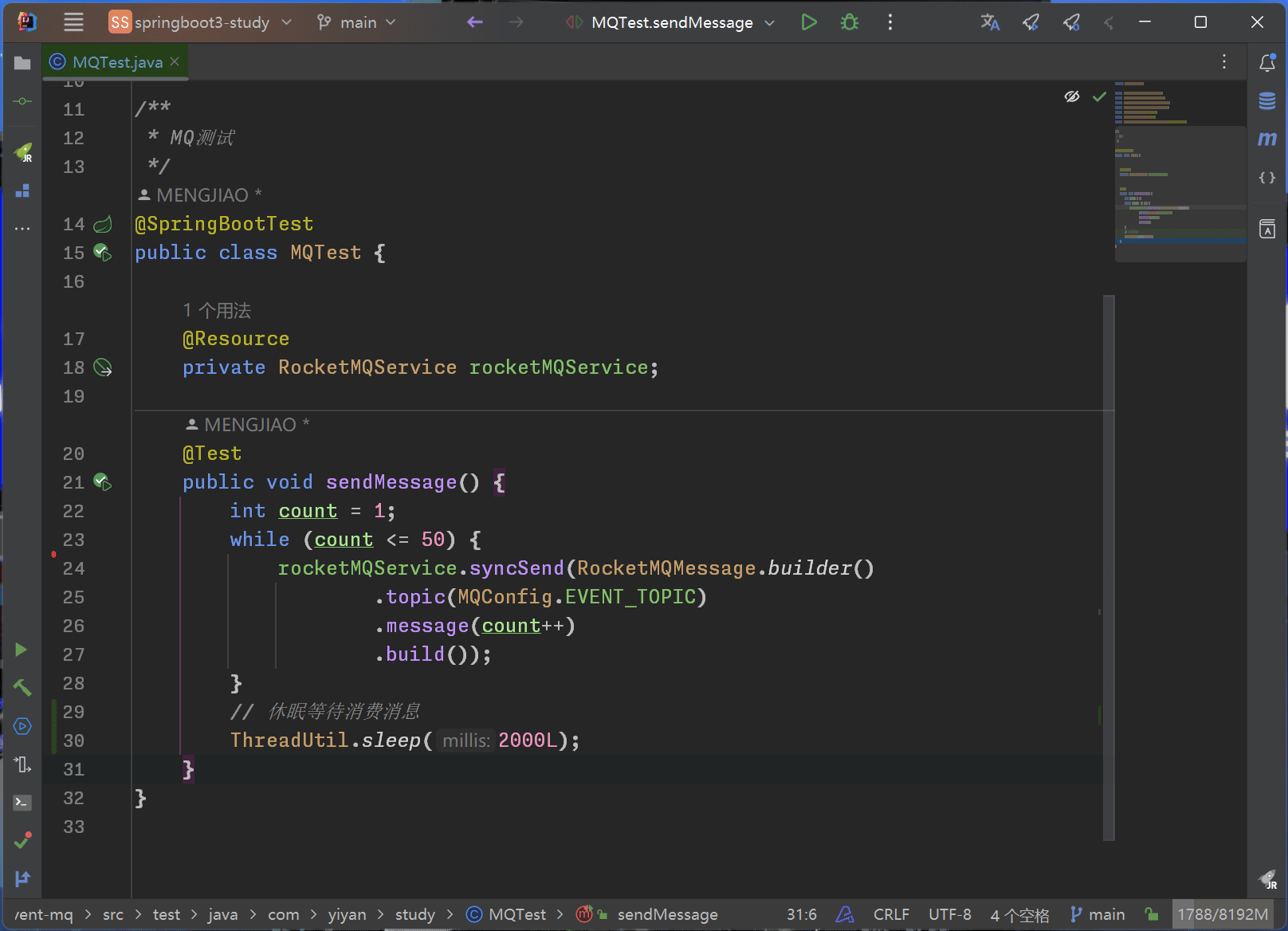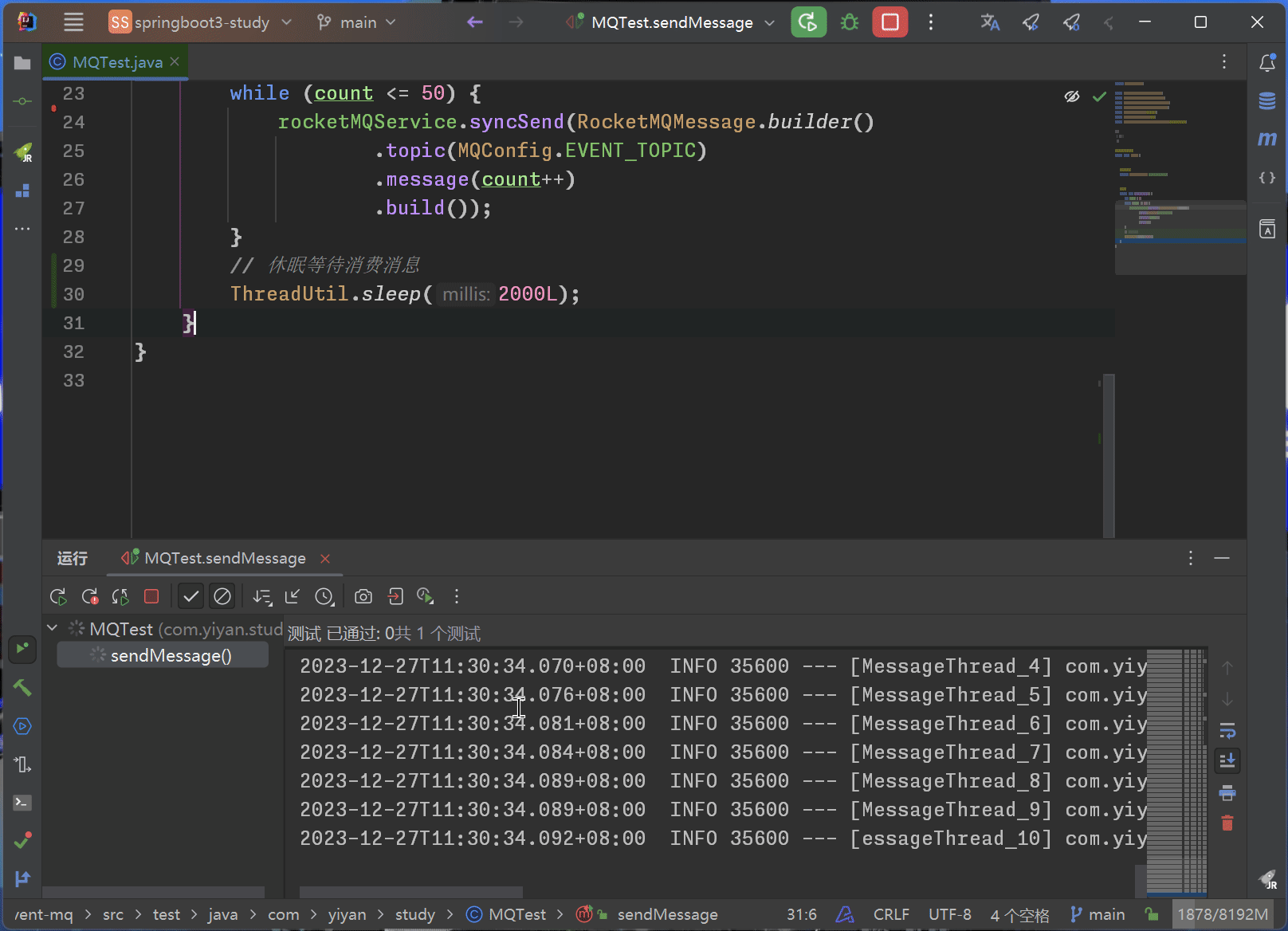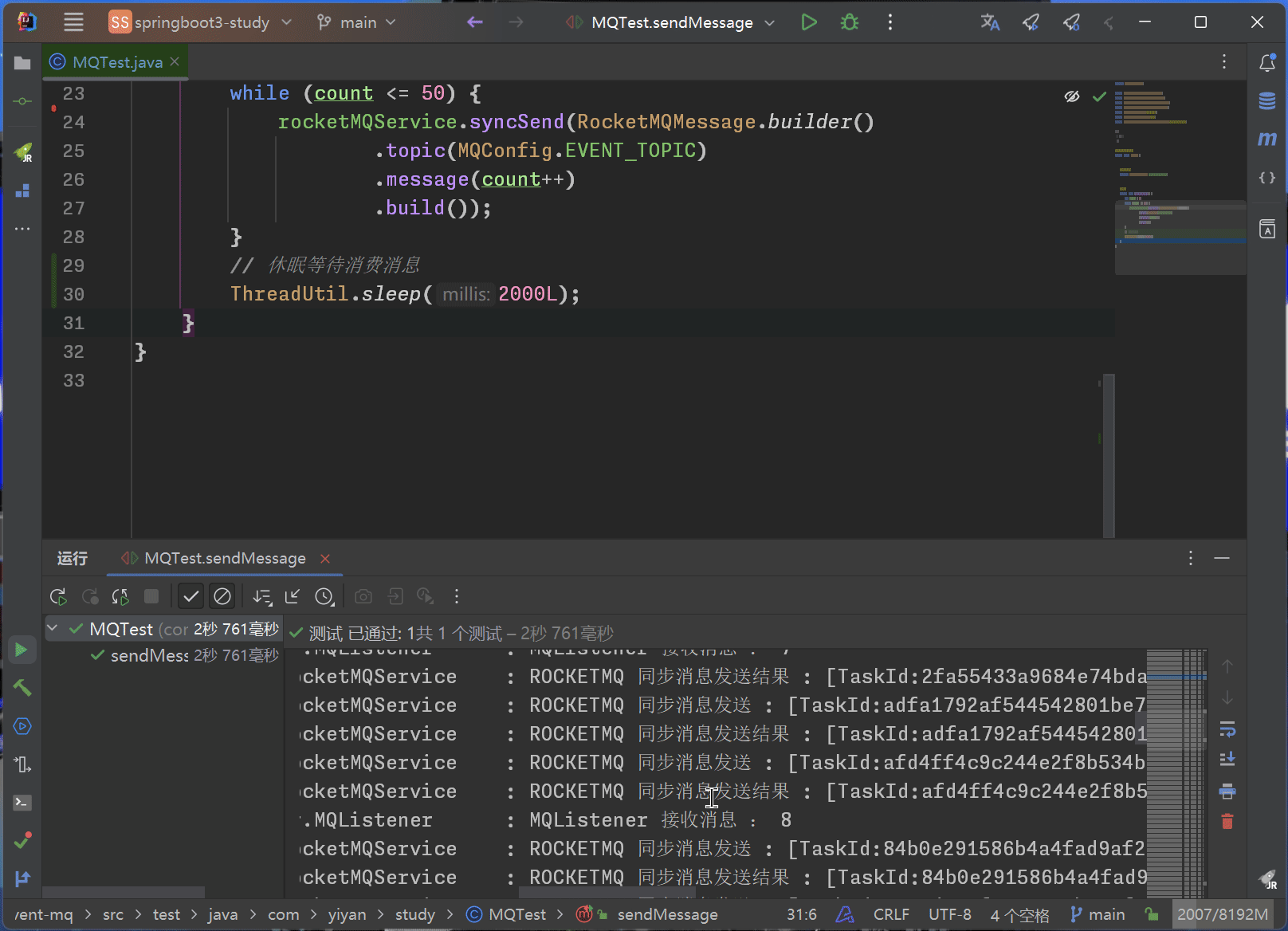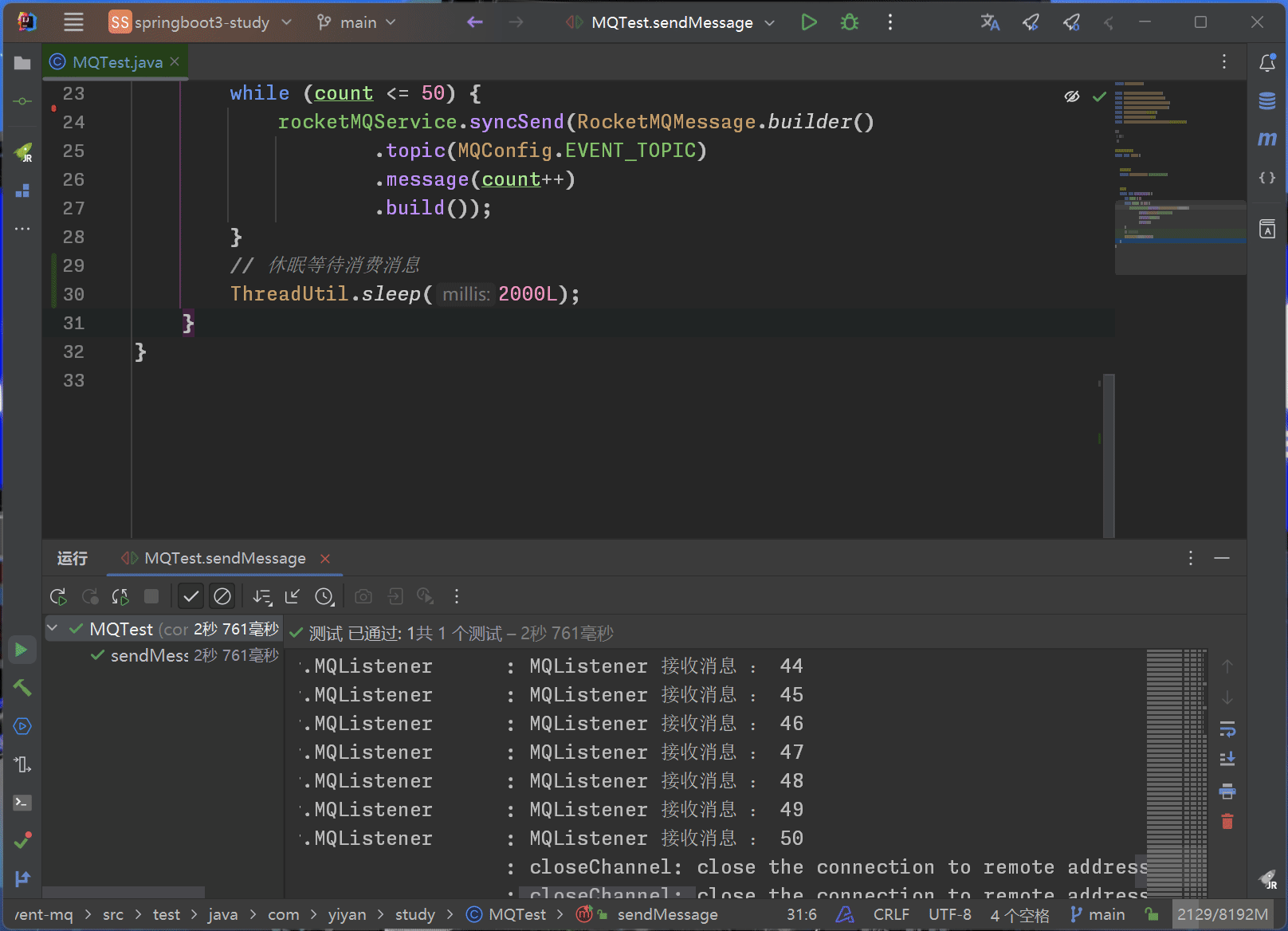
Spring Boot+RocketMQ 实现多实例分布式环境下的事件驱动
为什么要使用MQ? 在Spring Boot Event这篇文章中已经通过Guava或者SpringBoot自身的Listener实现了事件驱动,已经做到了对业务的解耦。为什么还要用到MQ来进行业务解耦呢? 首先无论是通过Guava还是Spring Boot自身提供的监听注解来实现的事…...

oracle ORA-01704: string literal too long ORACLE数据库clob类型
当oracle数据表中有clob类型字段时候,insert或update的sql语句中,超过长度就会报错 ORA-01704: string literal too long update xxx set xxx <div><h1>123</h1></div> where id 100;可以修改为 DECLAREstr varchar2(10000…...
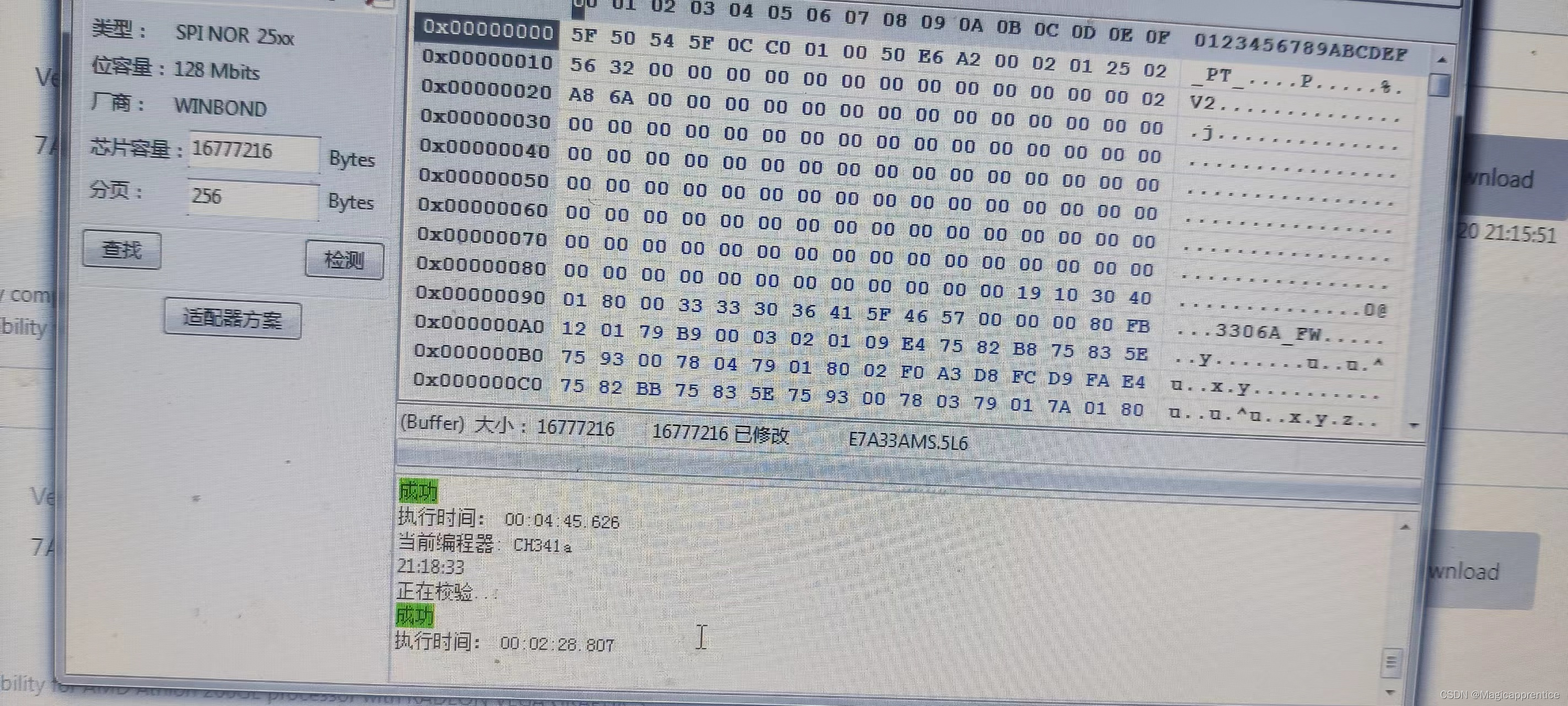
微星主板强刷BIOS(以微星X370gaming plus 为例)
(前两天手欠,用U盘通过微星的M-flash升级BIOS 升级过程中老没动静就强制关机了 然后电脑就打不开了) 几种强刷主板BIOS的方式 在网上看到有三种强刷BIOS的方式分别是: 使用夹子编程器 (听说不太好夹)使用微星转接线编程器(只能用于微星主板࿰…...

matlab 图像上生成指定中心,指定大小的矩形窗
用matlab实现在图像上生成指定中心,指定大小的矩形窗(奇数*奇数) function PlaneWin PlaneWindow(CentreCoorX,CentreCoorY,RadiusX,RadiusY,SizeImRow,SizeImColumn) % 在图像上生成指定中心,指定大小的矩形窗(奇数*奇数) % % Input: % CentreCoorX(1*1) % CentreCoorY(1*1)…...
❀My学习小记录之算法❀
目录 算法:) 一、定义 二、特征 三、基本要素 常用设计模式 常用实现方法 四、形式化算法 五、复杂度 时间复杂度 空间复杂度 六、非确定性多项式时间(NP) 七、实现 八、示例 求最大值算法 求最大公约数算法 九、分类 算法:) 一、定义 …...

Hive-high Avaliabl
hive—high Avaliable hive的搭建方式有三种,分别是 1、Local/Embedded Metastore Database (Derby) 2、Remote Metastore Database 3、Remote Metastore Server 一般情况下,我们在学习的时候直接使用hive –service metastore的方式…...
码住!8个小众宝藏的开发者学习类网站
1、simplilearn simplilearn是全球排名第一的在线学习网站,它的课程由世界知名大学、顶级企业和领先的行业机构通过实时在线课程设计和提供,其中包括顶级行业从业者、广受欢迎的培训师和全球领导者。 2、VisuAlgo VisuAlgo是一个免费的在线学习算法和数…...
Postman常见问题及解决方法
1、网络连接问题 如果Postman无法发送请求或接收响应,可以尝试以下操作: 检查网络连接是否正常,包括检查网络设置、代理设置等。 确认请求的URL是否正确,并检查是否使用了正确的HTTP方法(例如GET、POST、PUT等&#…...

ubuntu图形化登录默认只有guest session账号解决方法
新安装的ubuntu16.x 图形化界面登录默认只有guest账号,只有进入guest账号之后再去手动切换root账号很麻烦,但是这样确实很安全。为了方便希望能够在登录图形化界面的时候以root身份/或者自定义其他身份登录。做一下简单的记录。 使用终端命令行编辑文件…...
)
全国计算机等级考试| 二级Python | 真题及解析(1)
一、选择题 1. 按照“后进先出”原则组织数据的数据结构是____ A栈 B双向链表 C二叉树 D队列 正确答案: A 2. 以下选项的叙述中,正确的是 A在循环队列中,只需要队头指针就能反映队列中元素的动态变化情况 B在循环队列中,只需要队尾指针就能反映队列中元素的动态变…...
)
Java开发框架和中间件面试题(9)
目录 102.你了解秒杀吗?怎么设计? 103.什么是缓存穿透?怎么解决? 102.你了解秒杀吗?怎么设计? 1.设计难点:并发量大,应用,数据库都承受不了。另外难控制超卖。 2.设计…...

【ARMv8M Cortex-M33 系列 2 -- Cortex-M33 JLink 连接 及 JFlash 烧写介绍】
文章目录 Jlink 工具JLink 命令行示例JFlash 烧写问题Jlink 工具 J-Link 是 SEGGER 提供的一款流行的 JTAG 调试器,它支持多个平台和处理器。JLink.exe 是 J-Link 调试器的命令行接口,它允许用户通过命令行执行一系列操作,例如编程、擦除、调试等。 工具链接: https://ww…...

react pwa应用示例
创建一个基于React的PWA应用,你可以使用create-react-app,它自带PWA支持,但默认是关闭的。以下是创建React PWA应用的步骤: 安装create-react-app 如果你还没有安装,你可以通过npm来安装: npm install -…...

python如何通过日志分析加入黑名单
python通过日志分析加入黑名单 监控nginx日志,若有人攻击,则加入黑名单,操作步骤如下: 1.读取日志文件 2.分隔文件,取出ip 3.将取出的ip放入list,然后判读ip的次数 4.若超过设定的次数,则加…...
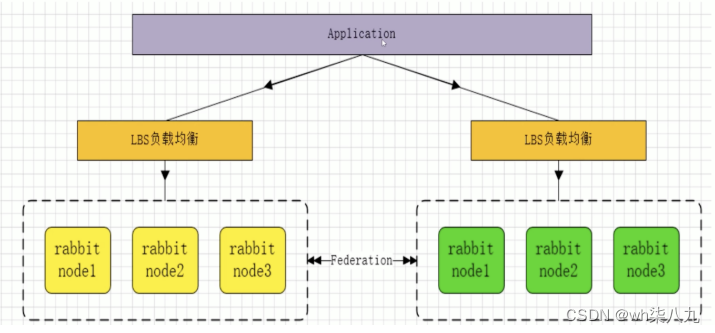
RabbitMq知识概述
本文来说下RabbitMq相关的知识与概念 文章目录 概述AMQP协议Exchange 消息如何保证100%投递什么是生产端的可靠性投递可靠性投递保障方案 消息幂等性高并发的情况下如何避免消息重复消费confirm 确认消息、Return返回消息如何实现confirm确认消息return消息机制 消费…...

专业级A链接测试特有
A链接普通 A链接添加链接描述带有blank...

量子同态加密:理论与实践的突破
1. 量子同态加密:理论与实践的桥梁量子同态加密(Quantum Homomorphic Encryption, QHE)是密码学领域的一项突破性技术,它允许在加密的量子数据上直接执行任意量子计算,而无需事先解密。这项技术对于构建真正隐私保护的…...
)
仅限内部团队使用的Perplexity行业扫描协议(附可复用Prompt模板库+信源可信度评分表v2.3)
更多请点击: https://codechina.net 第一章:Perplexity行业扫描协议的定位与适用边界 Perplexity行业扫描协议(Perplexity Industry Scanning Protocol,简称PISP)并非通用型AI评估框架,而是一套面向垂直领…...

水培种菜翻车了?可能是水质问题!用NodeMCU和TDS传感器给你的营养液做个“体检”
水培种菜翻车了?可能是水质问题!用NodeMCU和TDS传感器给你的营养液做个“体检” 看着阳台上蔫头耷脑的生菜叶子,你开始怀疑人生——明明按照教程配了营养液,定时补光通风,为什么植物就是长不好?别急着怪自己…...
【量化】IPTQ-ViT: Post-Training Quantization of Non-linear Functions for Integer-only Vision Transformer
【PTQ】PTQViT/IPTQ-ViT (arXiv 2022) 问题: ViT 中的非线性函数(GELU、Softmax)在纯整数推理中存在计算障碍。 核心创新: 模块方法作用多项式近似 GELU用低阶多项式逼近 GELU将非线性运算转化为整数可执行的乘加Bit-shifting Softmax用位移操作近似 …...

别再被html2canvas生成的图片糊一脸了!试试这个新版1.4.1的清晰度优化方案
深度解析html2canvas 1.4.1:告别图片模糊的现代解决方案 当我们需要将网页内容转换为图片时,html2canvas无疑是最常用的工具之一。然而,许多开发者在使用过程中都遭遇过生成的图片模糊不清的问题,尤其是在移动设备上表现更为明显。…...

用$monitor给Verilog模块装个‘实时仪表盘’:以UART回环测试为例的调试实战
用$monitor给Verilog模块装个‘实时仪表盘’:以UART回环测试为例的调试实战 在数字电路验证的浩瀚海洋中,调试就像是在黑暗中寻找灯塔的过程。传统波形调试如同手持火炬前行,而$monitor系统任务则为我们装上了全景雷达——它能自动捕捉信号变…...
)
树莓派当机载电脑:搭建Pixhawk无人机与动捕系统的ROS通信桥梁(VRPN/MOCAP_NOKOV双方案)
树莓派作为机载计算机:构建Pixhawk无人机与动作捕捉系统的ROS通信框架 在无人机自主飞行和机器人协同控制领域,高精度的位置反馈是实现稳定控制的基础。传统GPS定位在室内环境中完全失效,而基于光学动作捕捉系统的定位方案能够提供毫米级的精…...

AIGC 检测‘句长标准差‘到底是什么?嘎嘎降 AI 帮你 AI 率从 70% 降到 7%
AIGC 检测"句长标准差"到底是什么?嘎嘎降 AI 帮你 AI 率从 70% 降到 7% AIGC 检测算法 4.0 版本看的 5 项底层指标里——句长标准差权重最高(约 35%)。理解了这一项你就知道为什么手改一周降不下 AI 率。这篇文章把"句长标准差…...
)
一线大厂AI开发笔记本清单(万元内)
人机协作,AI模型:Deepseek仅供参考一线大厂AI开发笔记本清单(万元内)机型CPUGPU(显存)内存SSD散热Linux兼容性风险等级性能星级参考价华硕 天选7 Pro 酷睿版Ultra 9 290HX Plus (24核)RTX 5070 (8GB)32GB1T…...
)
Oracle 19c单实例安装后,别忘了做这5个安全与性能基础配置(CentOS 7版)
Oracle 19c单实例安装后的5个关键安全与性能配置指南(CentOS 7环境) 刚完成Oracle 19c的安装只是数据库管理的第一步。许多初级DBA常犯的错误是认为安装成功就意味着工作结束,实际上默认配置往往存在严重的安全漏洞和性能隐患。本文将带您完成…...