掌握ElasticSearch(一):Elasticsearch安装与配置、Kibana安装
文章目录
- 〇、简介
- 1.Elasticsearch简介
- 2.典型业务场景
- 3.数据采集工具
- 4.名词解释
- 一、安装
- 1.使用docker
- (1)创建虚拟网络
- (2)Elasticsearch安装步骤
- 2.使用压缩包
- 二、配置
- 1.目录介绍
- 2.配置文件介绍
- 3.elasticsearch.yml节点配置
- 4.jvm.options堆配置
- 二、可视化工具Kibana
- 1.介绍
- 2.安装(Docker)
- 参考
Elasticsearch版本:7.12.1
Kibana版本:7.12.1
操作系统:centos7
〇、简介
1.Elasticsearch简介
- 什么是Elasticsearch:
Elasticsearch是一个提供可扩展的企业级搜索服务的工具。它主要提供了大数据搜索和分析服务。相较于传统的关系数据库,Elasticsearch具有更高的性能、易扩展性和良好的容错性。
- 传统数据库的局限性:
传统的关系数据库在处理大数据时存在明显的短板,主要表现在性能差和扩展难的问题上。即使采用一定的方法去优化SQL,查询速度依然可能很慢,而关系数据库的集群搭建也不太容易,查询性能在很多业务场景中依然没有保障。
- Elasticsearch的优势:
相较于关系数据库,Elasticsearch存在几个明显的优点:高性能、易扩展和良好的容错性。它使用倒排索引作为存储结构并大量使用缓存机制,能够非常快速地从海量的数据中查询出需要的结果。搭建多个Elasticsearch节点组成一个集群对外提供分布式的搜索服务也非常简单,而且每个索引可以配置副本机制,即使Elasticsearch有部分服务器宕机也不用担心数据丢失。
2.典型业务场景
Elasticsearch在以下几个典型的业务场景中有着广泛的应用:
- 在线实时日志分析:
使用Elasticsearch分析线上日志是十分常见的操作,从最初的ELK(Elasticsearch、Logstash、Kibana)平台到如今的Elastic Stack都包含开箱即用的在线日志采集、存储、分析的功能,使用起来快捷、方便。
- 物联网数据监控:
对于各种传感器设备、可穿戴设备实时产生的各种需要监控和分析的数据,由于数据量很大且实时性要求较高,很适合用Elasticsearch来进行技术选型,Elasticsearch在智慧交通、智能家居、公共安全、运维监控等领域有着广泛的应用。
- 文献检索和文献计量:
Elasticsearch是一种出色的搜索引擎,很适合用于电子图书馆、论文检索系统所需的多样化信息检索服务,同时Elasticsearch强大的数据分析能力为文献计量提供了便利的统计接口。
- 商务智能大屏展示:
Elasticsearch通过有效的大数据分析和研判,使用多维度的钻取分析为用户提供决策支持和趋势预测,其在智慧公安、智慧交通、智慧水利等领域的大屏展示系统中应用尤其普遍。
- 数据分析型应用程序中的应用:
Elasticsearch很适合读多写少的数据分析型应用程序,特别适用于OLAP数据分析相关的项目。在这种情况下,考虑到Elasticsearch本身具备数据存储的能力,可以作为数据源。
3.数据采集工具
除了使用应用程序写入Elasticsearch,你还可以使用官方提供的数据采集工具Logstash或者第三方的ETL工具把数据写入Elasticsearch。这些工具功能十分丰富,包括:
- Logstash:早期的数据采集、转换工具,可以很方便地把各种数据写入Elasticsearch。
- Beats家族:一系列命名包含beat的轻量级数据采集器,包括Filebeat、Metricbeat、Packetbeat、Winlogbeat、Heartbeat和Auditbeat等,功能各异,但都能用来采集各种数据并写入Elasticsearch。
4.名词解释
-
集群(cluster):多个安装了Elasticsearch的服务器如果拥有相同的集群名称,则它们属于同一个集群,对外提供统一的服务。在一个集群中,只有一个主节点,当主节点宕机时需要重新“选举”出新的主节点来维持集群正常运转。
-
节点(node):一个节点就是一台安装了Elasticsearch的服务器,它是组成集群的基本单元。
-
索引(index):索引是存储数据的基本单元,在大多数情况下,可以把它理解为关系数据库中的表。
-
文档(document):文档是写入索引的基本单元,一个文档就是索引中的一条数据。写入索引的文档是JSON格式的文本字符串,里面包含各个字段的信息,保存在索引的_source元数据中。
-
分片(shard):分片分为主分片和副本分片,每个索引拥有至少一个主分片和零个或多个副本分片,一个分片本质上是一个Lucene索引。当整个集群的节点数量增加或减少时,为了让分片在每个节点上分布得比较均匀,通常会使分片在集群中移动,这个过程也就是分片的分配。在任何时候,索引的主分片和它对应的副本分片不能位于同一个节点上,这是为了保证节点宕机时,主分片和副本分片不会同时丢失。
-
主分片(primary shard):当文档数据写入索引时,会首先选择一个主分片进行写入,再把数据同步到副本分片。主分片的数目在建立索引时就已经固定,无法修改。如果一个索引拥有的主分片越多,那么它能存储的数据越多,主分片的个数通常跟索引的数据量成正相关。
-
副本分片(replica shard):副本分片是主分片的一个副本,它能够分担一些数据搜索的请求,从而提高搜索的吞吐量。同时,副本分片还具备容灾备份的能力,当主分片所在的节点宕机时,副本分片可以被选举为主分片来保持数据的完整性。另外,索引的副本分片数目可以随时修改。
-
分片恢复(shard recovery):分片恢复指的是把一个分片的数据完全同步到另一个分片的过程。这个过程伴随有分片的创建和分配,在集群启动时或者节点数目改变时自发完成。只有分片恢复完全结束,副本分片才能对外提供搜索服务。
-
索引缓冲区(index buffer):索引缓冲区用于在内存中存储最新写入索引的数据,只有在索引缓冲区写满的时候,这些新的数据才会被一次性写入磁盘。
-
传输模块(transport module):当节点接收请求后不能处理或无法单独处理时,节点需要把请求转发给其他节点,这是同一个集群中不同节点之间互相通信的手段,这个过程由传输模块来完成。
-
网关模块(gateway module):网关模块存储着集群的信息和每个索引分片的持久化数据。默认使用的是本地网关,它会把数据存储在本地文件系统中,你还可以配置网关模块使用HDFS或其他存储手段来持久化Elasticsearch的数据。
-
节点发现模块(node discovery module):节点发现模块用于节点之间的互相识别,可把新节点加入集群。这个过程需要使用传输模块来完成节点之间的通信。
-
线程池(thread pool):Elasticsearch内置了多个线程池用于处理不同的操作请求。例如,analyze线程池用于处理文本分析的请求,write线程池用于处理索引数据的写入请求,search线程池用于处理搜索请求。你可以配置线程池的大小以改变其对这些请求的处理能力。
一、安装
1.使用docker
首先,你需要安装一个docker,关于Docker的使用我在《玩转Docker》系列博客中已经介绍过了。
(1)创建虚拟网络
因为需要使用 Docker 部署 ElasticSearch 和 Kibana ,并且它们相互之间需要进行网络通信,所有首先创建一个虚拟网络,然后在运行容器的时候,加入这个网络即可。
docker network create es-net
(2)Elasticsearch安装步骤
以下是使用Docker安装Elasticsearch的步骤:
- 拉取Elasticsearch镜像:打开终端或命令行界面,运行以下命令来拉取Elasticsearch的官方镜像:
docker pull elasticsearch/elasticsearch:7.12.1
这将会从Docker Hub上拉取Elasticsearch 7.12.1版本的镜像到本地环境。
- 创建并运行Elasticsearch容器:运行以下命令来创建并运行Elasticsearch容器
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1
这个命令中,-d参数表示以后台模式运行容器,–name elasticsearch指定容器的名称,-p 9200:9200 -p 9300:9300指定端口映射,-e "discovery.type=single-node"设置Elasticsearch的单节点模式。--network es-net指定加入虚拟网络。
- 验证Elasticsearch是否运行:在浏览器中访问
localhost:9200
如果一切正常,将会看到Elasticsearch的信息返回,表明Elasticsearch已经成功运行。
注意:
这里使用的是单节点模式的Elasticsearch,如果你需要搭建多节点集群,还需要进行额外的配置。
docker安装的Elasticsearch的目录文件默认是在容器中的/usr/share/elasticsearch目录下。
2.使用压缩包
注意,这一节我安装示范版本为7.2.0,操作系统为centos。
安装Elasticsearch 7.2.0 在 CentOS 上的完整步骤如下:
- 更新系统:首先,确保你的 CentOS 系统是最新的。可以通过以下命令更新系统:
sudo yum update
- 安装 Java:Elasticsearch 运行需要 Java 环境,确保你的系统已经安装了 Java。你可以通过以下命令检查是否已经安装了 Java:
java -version
如果没有安装 Java,你可以通过以下命令安装 OpenJDK:
sudo yum install java-1.8.0-openjdk
- 下载并安装 Elasticsearch:使用 wget 命令下载 Elasticsearch 7.2.0 的安装包,并解压安装:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.2.0-linux-x86_64.tar.gz
tar -xzf elasticsearch-7.2.0-linux-x86_64.tar.gz
- 配置 Elasticsearch:进入解压后的 Elasticsearch 目录,编辑配置文件 elasticsearch.yml:
cd elasticsearch-7.2.0/config
vi elasticsearch.yml
在配置文件中,你可以设置集群名称、节点名称、监听地址等参数。
- 创建非root用户
useradd es
passwd es #输入密码
6.启动 Elasticsearch 服务:
su es # 切换到非root用户
./安装目录/elasticsearch-7.2.0/bin/elasticsearch
- 验证 Elasticsearch:使用 curl 命令验证 Elasticsearch 是否正常运行:
curl -X GET "你的电脑ip:9200/"
如果一切顺利,你应该能够看到 Elasticsearch 的信息返回。
通过以上步骤,你应该能够在 CentOS 上成功安装 Elasticsearch 7.2.0,并启动 Elasticsearch 服务。记得根据实际情况修改配置文件和路径,以确保一切正常运行。
二、配置
1.目录介绍
在容器外,进入正在运行的Elasticsearch容器的命令行界面:
docker exec -it es /bin/bash
进入安装目录:
cd /usr/share/elasticsearch
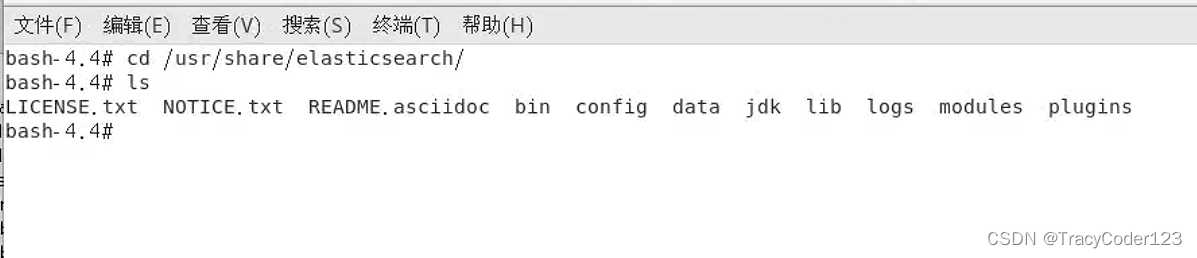
- 安装目录介绍:
● bin:包含与Elasticsearch有关的各种可执行脚本,很多都是批处理文件。
● config:包含各种节点的配置文件,elasticsearch.yml文件也在这个目录下,可以用于配置许多重要的参数。
● data:默认的数据存放目录,包含写入Elasticsearch的数据文件。
● jdk:包含一个自带的JDK,如果你不用自己计算机中的JDK,那么这个JDK就会派上用场。
● lib:包含Elasticsearch运行时需要用到的JAR包。
● logs:默认的日志存放目录,包含Elasticsearch运行时产生的各种日志文件。
● modules:包含Elasticsearch内置的各种模块,每个模块都是一个插件。
● plugins:包含用户添加的第三方插件,例如IK分词器插件就需要安装到这个目录下。
2.配置文件介绍
查看配置文件:
cd /usr/share/elasticsearch/config
ls

在Elasticsearch的config文件夹下,一共有3个重要的配置文件,其中elasticsearch.yml用于配置节点的参数,jvm.options用来配置Elasticsearch运行时占用的堆内存大小,log4j2.properties用来配置Elasticsearch运行时的日志参数。
那些可以通过调用REST接口,在节点运行时动态修改的配置叫作动态配置;配置在elasticsearch.yml文件中,只能在集群重启后才能生效的配置叫作静态配置。
- 配置优先级:
当你需要修改集群节点的配置信息时,通常有以下3种方法。
(1)调用集群节点配置的REST接口并设置配置项临时生效,该配置项在集群重启后失效。
(2)调用集群节点配置的REST接口并设置配置项持久生效,该配置项在集群重启后依然有效。
(3)直接把集群节点配置项写在elasticsearch.yml文件中。
如果一个配置项没有采用以上3种方法进行配置,则会采用集群节点默认的配置。如果同一个配置项在多个地方都配置过,而且配置得不一样,则第一种临时配置的优先级最高,第二种持久生效的配置次之,写在elasticsearch.yml文件中的配置优先级最低。
通常比较好的做法是,对于整个集群范围内生效的动态配置直接使用REST接口进行控制,对于每个节点各自不同的配置(例如IP地址)直接在节点的elasticsearch.yml中配置,这样做可以避免遗漏某个节点的配置而引起错误。
为了方便,我们在容器外面把elasticsearch的config目录复制出来查看:
语法为:docker cp 容器id:容器中的目录 主机上的目录
docker cp 1536112ad6f4:/usr/share/elasticsearch/config ./
然后就可以在容器外面查看各个配置文件了。
3.elasticsearch.yml节点配置
这是elasticsearch.yml最初的配置,指定了集群名和节点host:
cluster.name: "docker-cluster"
network.host: 0.0.0.0
下面我介绍一下其他比较重要的配置。
- path.data和path.logs
这两个配置项用于配置数据目录和日志目录,在生产环境中,由于文件较大,应尽量配置存储容量大的目录,可以配置多个目录。
path:data:- /esdata1- /esdata2logs:- /var/log/eslog1- /var/log/eslog2
- bootstrap.memory_lock
这是用于操作系统内存锁的配置项,开启内存锁可以防止操作系统中的缓存数据被交换到外存而导致查询性能大幅下降,在生产环境中,这个配置项一定要设置为true。
bootstrap.memory_lock: true
注意:在CentOS中,直接设置bootstrap.memory_lock为true可能会因为缺少权限并不能立即开启内存锁,还需要一些额外的配置,我将会在后续博客中介绍这个问题。
- network.host和http.port
network.host: 192.168.9.105
http.port: 9201
- discovery.seed_hosts和cluster.initial_master_nodes
这两个配置项在单节点环境下保持默认设置即可,当需要搭建集群时,这两个配置项对于节点的发现和主节点的选举至关重要。discovery.seed_hosts用于配置一组IP地址或主机名,这组地址的列表是集群中的主候选节点的列表,当一个节点启动时会尝试与该列表中的各个主候选节点建立连接,如果连接成功并找到主节点就把该节点加入集群。
discovery.seed_hosts:- 192.168.9.10- 192.168.9.11- host3.com
cluster.initial_master_nodes用于明确地指定一组节点名称的列表,这个列表也是主候选节点的列表,Elasticsearch集群在第一次启动时会读取该列表初始化投票配置,该配置将用于主节点的选举。在这个列表中,配置的每个节点的名称要与该节点的node.name配置的名称保持一致。
cluster.initial_master_nodes: ["node-1", "node-2"]
4.jvm.options堆配置
Elasticsearch的堆内存配置在性能调优中非常重要。以下是一些关于Elasticsearch堆内存配置的要点:
分配合适的堆内存大小:
Elasticsearch的堆内存大小直接影响其性能。如果设置得太小,可能查询时内存不够而导致服务宕机;如果设置得太大,又会超过JVM用于压缩对象指针的阈值而导致内存浪费。通常建议将堆内存设置为物理内存的一半,但不要超过30GB(压缩对象指针的阈值)。过小的堆内存会导致频繁的垃圾回收,而过大的堆内存可能会导致长时间的垃圾回收暂停,影响性能。
-Xms4g
-Xmx4g
Xms代表最小的堆内存大小,Xmx代表最大的堆内存大小,这两个值必须设置成一样的。
二、可视化工具Kibana
1.介绍
Kibana是一个开源的数据分析和可视化平台,它是Elastic Stack(之前称为ELK Stack)的一部分,用于搜索、查看、分析和交互式地操作存储在Elasticsearch索引中的数据。Kibana提供了丰富的图表、表格、地图等可视化组件,用户可以通过Kibana轻松地创建各种数据可视化和仪表盘,以便更好地理解和分析数据。
使用Kibana有以下好处:
-
数据可视化:Kibana提供了丰富的可视化组件,用户可以通过简单的拖拽和配置操作,创建各种图表、表格、地图等数据可视化,帮助用户更直观地理解数据。
-
仪表盘:Kibana允许用户将多个可视化组件组合成仪表盘,从而可以在一个页面上综合展示多个数据可视化,帮助用户全面地监控和分析数据。
-
数据查询:Kibana提供了强大的查询功能,用户可以通过Kibana界面轻松地构建和执行复杂的数据查询,以便快速地找到所需的数据。
-
开放性和扩展性:Kibana是一个开源的项目,用户可以根据自己的需求进行定制和扩展,满足不同的数据分析和可视化需求。
总的来说,Kibana作为Elastic Stack的一部分,为用户提供了强大的数据分析和可视化能力,帮助用户更好地理解和利用存储在Elasticsearch中的数据。
2.安装(Docker)
下面开始使用docker安装kibana:
- 拉取Kibana镜像:在终端中执行以下命令来拉取Kibana的官方镜像:
docker pull kibana:7.12.1
- 运行Kibana容器:执行以下命令来运行Kibana容器:
docker run -d --name kibana -e ELASTICSEARCH_HOSTS=http://es:9200 --network=es-net -p 5601:5601 kibana:7.12.1
-e ELASTICSEARCH_HOSTS=http://es:9200: 设置 Kibana 运行时连接的 Elasticsearch 节点的地址,这里指定了 Elasticsearch 服务的地址为 http://es:9200,其中 “es” 是 Elasticsearch 服务的容器名,而不是具体的 IP 地址。这是因为在 --network=es-net 中指定了容器连接到 “es-net” 网络,容器名会被解析为相应的 IP 地址。
- 访问Kibana:在浏览器中输入
http://localhost:5601,如果一切正常,你将会看到Kibana的页面,表明Kibana已经成功运行。
参考
https://blog.csdn.net/qq_61635026/article/details/133645483
相关文章:
掌握ElasticSearch(一):Elasticsearch安装与配置、Kibana安装
文章目录 〇、简介1.Elasticsearch简介2.典型业务场景3.数据采集工具4.名词解释 一、安装1.使用docker(1)创建虚拟网络(2)Elasticsearch安装步骤 2.使用压缩包 二、配置1.目录介绍2.配置文件介绍3.elasticsearch.yml节点配置4.jvm.options堆配置 二、可视化工具Kibana1.介绍2.安…...
)
《剑指offer》Java版--13.机器人的运动范围(BFS)
剑指offer原题13:机器人的运动范围 地上有一个m行n列的方格。一个机器人从坐标(0,0)的格子开始移动,它每次可以向左、右、上、下移动一格,但不能进入行坐标和列坐标的数位之和大于k的格子。例如,当k为18时,机器人能够进入方格(35,37),因为353…...
基于流程挖掘的保险理赔优化策略实践
引言 在当今日益竞争的商业环境中,保险公司面临着日益增长的业务量和客户期望的挑战。特别是在理赔领域,理赔是保险行业的重要环节,也是保险公司和客户之间最直接的联系点。然而,长周期和繁琐的理赔流程常常给保险公司和投保人带来困扰。因此,如何提供准确且高效的理赔处…...

Docker五 | DockerFile
目录 DockerFile 常用保留字 FROM MAINTAINER RUN EXPOSE WORKDIR USER ENV VOLUME ADD COPY CMD ENTRYPOINT DockerFile案例 前期准备 编写DockerFile文件 运行DockerFile 运行镜像 DockerFile是用来构建Docker镜像的文本文件,是由一条条构建…...

2023年度总结:技术旅程的杨帆远航⛵
文章目录 职业规划与心灵成长 ❤️🔥我的最大收获与成长 💪新年Flag 🚩我的技术发展规划 ⌛对技术行业的深度思考 🤔祝愿 🌇 2023 年对我来说是一个充实而令人难以忘怀的一年。这一年,我在CSDN上发表了 1…...
SpringBoot+AOP+Redis 防止重复请求提交
本文项目基于以下教程的代码版本: https://javaxbfs.blog.csdn.net/article/details/135224261 代码仓库: springboot一些案例的整合_1: springboot一些案例的整合 1、实现步骤 2.引入依赖 我们需要redis、aop的依赖。 <dependency><groupId>org.spr…...

偷流量、端口占用、网络负载高、socket创建释放异常等Android高阶TCP/IP网络问题定位思路
一,背景 通常一些偷流量、端口占用、网络负载高、socket创建释放异常等Android网络相关问题,可以通过使用tcpdump抓tcp/ip报文,来定位。但是tcpdump无进程信息,也没有APK包名信息,无法确认异常的报文来自哪些Apk或者n…...

《人人都能用英语》学习笔记
https://github.com/xiaolai/everyone-can-use-english 核心: 用 What──它究竟是什么?Why──为什么它是那个样子?How──要掌握它、应用它,必须得遵循什么样的步骤? 在运行程序之前,要反复浏览代码&a…...

NFC与ZigBee技术在智慧农业物联网监测系统中的应用
近年来,我国农业物联网技术飞速发展,基于物联网技术的智能农业监测系统有望得到较大规模的推广应用。但传统的物联网农业监测系统其网络结构层次单一,多采用基于有线或无线结构的节点-上位机数据采集模式,节点数据访问模式缺乏灵活…...
k8s-cni网络 10
Flannel vxlan模式跨主机通信原理 在同一个节点上的pod 流量通过cni网桥可以直接进行转发; 在需要跨主机访问时,数据包通过flannel(隧道) 知道另一边的mac地址,就可以拿到另一边的ip地址,然后构建常规的以太网数据包,…...

听GPT 讲Rust源代码--src/tools(27)
File: rust/src/tools/clippy/clippy_lints/src/methods/suspicious_to_owned.rs 文件rust/src/tools/clippy/clippy_lints/src/methods/suspicious_to_owned.rs的作用是实施Clippy lint规则,检测产生潜在性能问题的字符转换代码,并给出相关建议。 在Rus…...

经济危机下,我们普通人如何翻身?2024创业新风口,适合普通人的创业项目
明年的商业环境会比今年更残酷,不是贩卖危机。旅游行业还在刺激性消费,再过几个月大家就没钱了,估计慢慢也消停。中小微企业资金链断裂,大部分公司倒闭,大批人失业,所以经济恢复需要一个周期。 30年河东&am…...

深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第五节 引用类型复制问题及用克隆接口ICloneable修复
深入浅出图解C#堆与栈 C# Heaping VS Stacking 第五节 引用类型复制问题及用克隆接口ICloneable修复 [深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第一节 理解堆与栈](https://mp.csdn.net/mdeditor/101021023)[深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第二节…...

python中基本元素的pop函数
python中基本元素的pop函数 一、列表List二、元组Tuple三、字典dict四、集合set 一、列表List pop() 根据索引删除并返回被删除的元素,索引默认为-1 a [1, 2, 3, 2, 5] b a.pop() # b5,默认返回最后一个值 print(b) b a.pop(2) # b3,返回a[2] pri…...
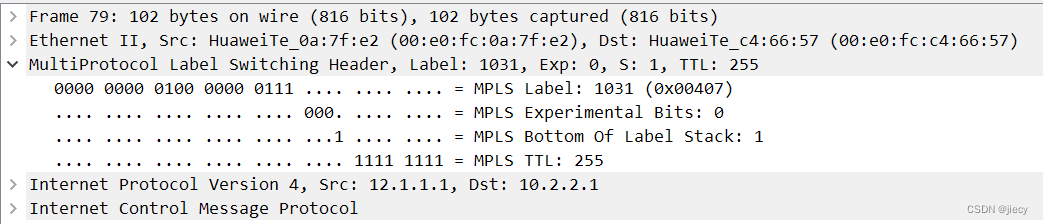
MPLS动态协议LDP配置示例
一、预习: MPLS是一种根据报文中携带的标签来转发数据的技术,两台LSR必须在它们之间转的数据 的标签使用上“达成共识”。LSR之间可以运行LDP来告知其他LSR本设备上的标签绑定信息,从而实现标签报文的正确转发。 LSR:Label Switch…...
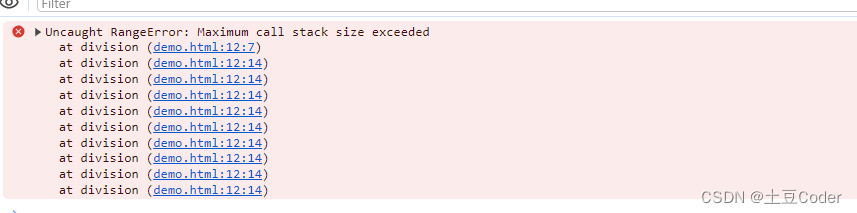
JS调用栈:为何会栈溢出
JS调用栈:为何会栈溢出 JS调用栈什么是函数调用什么是栈在开发中利用调用栈栈溢出 JS调用栈 JavaScript 经常会出现一个函数中调用另外一个函数的情况,调用栈就是用来管理函数调用关系的一种数据结构,首先你要先弄明白函数调用和栈结构 什么…...

代码随想Day52 | 300.最长递增子序列、674. 最长连续递增序列、718. 最长重复子数组
300.最长递增子序列 这道题目的重点在于动态数组的定义 dp[i]:以nums[i]为结尾的最长递增子序列,因为这样定义可以进行递推; 递推:j从0-i进行对比,如果nums[i]大于nums[j],dp[i]dp[j]1; 初始化…...
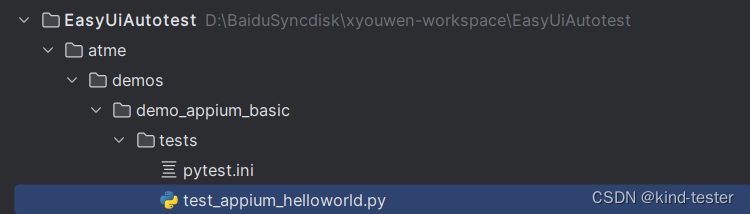
使用 pytest 相关特性重构 appium_helloworld
一、前置说明 在 pytest 基础讲解 章节,介绍了 pytest 的特性和基本用法,现在我们可以使用 pytest 的一些机制,来重构 appium_helloworld 。 appium_helloworld 链接: 编写第一个APP自动化脚本 appium_helloworld ,将脚本跑起来 代码目录结构: pytest.ini 设置: [pyt…...
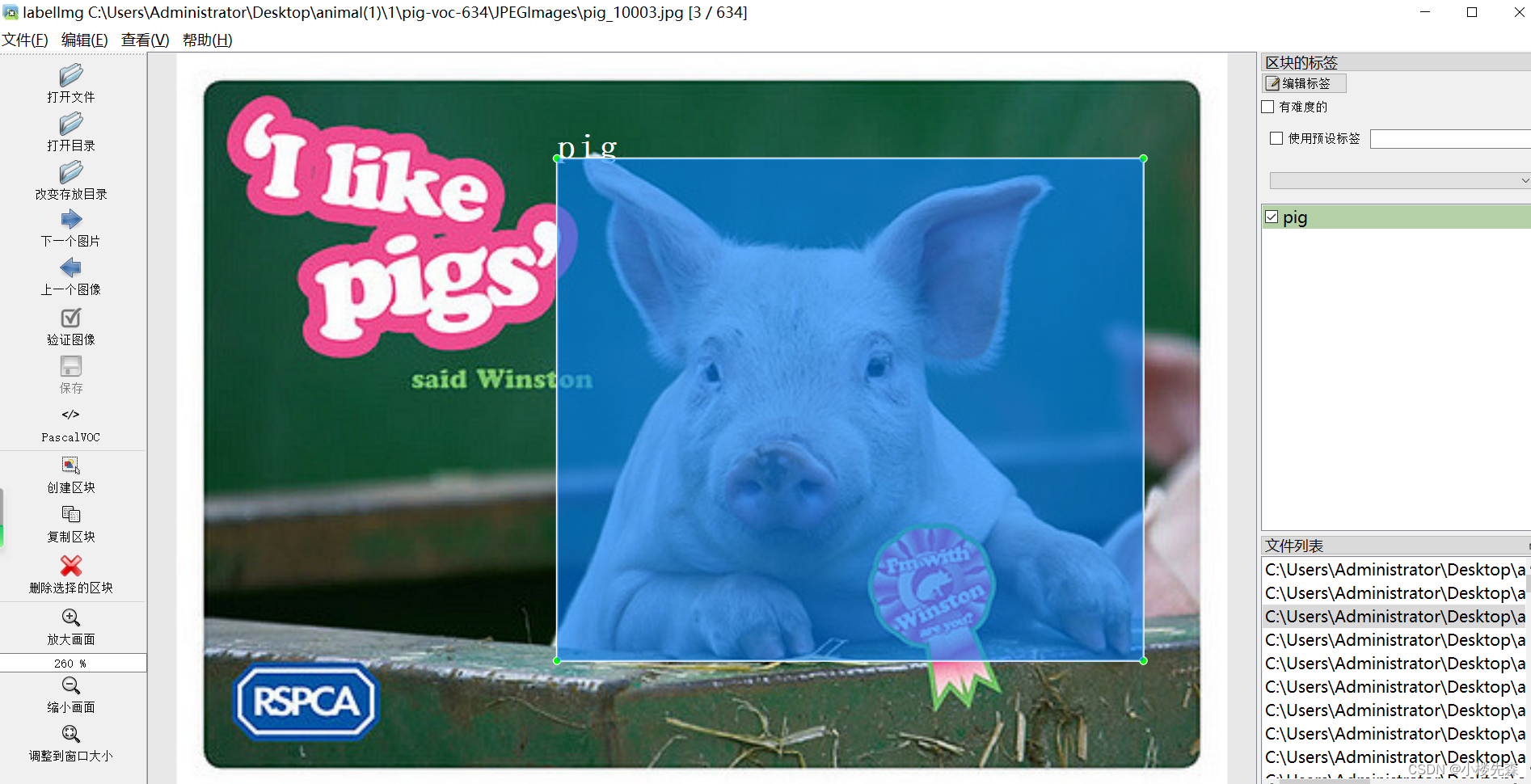
猪目标检测数据集VOC格式600张
猪是一种常见的哺乳动物,通常被人们认为是肉食动物,但实际上猪是杂食性动物,以植物性食物为主,也有偶尔食肉的习性。猪的体型较大,圆胖的体型和圆润的脸庞使其显得憨态可掬。它们主要通过嗅觉来感知周围环境࿰…...
Pandas中concat的用法
Pandas中concat的用法 pd.concat 是 pandas 库中的一个函数,用于将多个 pandas 对象(如 Series、DataFrame)沿指定轴进行合并连接。 pd.concat(objs, axis0, joinouter, ignore_indexFalse, keysNone, levelsNone, namesNone, verify_in…...

终极指南:3分钟学会用Onekey下载Steam游戏清单,告别手动烦恼
终极指南:3分钟学会用Onekey下载Steam游戏清单,告别手动烦恼 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 想要快速获取Steam游戏清单却苦于复杂操作?Oneke…...

凌壹科技ZO-3965U-6C2L嵌入式主板深度拆解:硬件解析与工业应用实战
1. 项目概述:一块嵌入式主板的深度拆解最近在整理手头的工控项目资料,翻出了一块来自凌壹科技的ZO-3965U-6C2L嵌入式主板。这块板子之前在一个边缘计算网关项目里服役了两年多,一直稳定可靠。趁着这个机会,我决定把它从机箱里拆出…...

Photoshop图层批量导出神器:快速高效导出PSD图层为独立文件的最佳解决方案
Photoshop图层批量导出神器:快速高效导出PSD图层为独立文件的最佳解决方案 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Ado…...

Coolapk-UWP 深度解析:基于MVVM架构的Windows桌面酷安客户端开发实战指南
Coolapk-UWP 深度解析:基于MVVM架构的Windows桌面酷安客户端开发实战指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 在移动应用生态日益丰富的今天,将移动端优…...

基于MCP协议的AI工具调用服务器:omega-point-convergence-mcp实战指南
1. 项目概述与核心价值最近在折腾AI智能体开发,特别是想让它们能更“主动”地去获取和处理外部信息时,一个绕不开的话题就是工具调用。传统的API集成方式,每个新工具都得写一遍对接代码,调试起来繁琐不说,维护成本也高…...

CST实战指南 | 场路协同仿真中的元器件模型导入与验证
1. 场路协同仿真中的元器件模型导入基础 我第一次接触CST场路协同仿真时,最头疼的就是如何把各种元器件模型正确导入到仿真环境中。经过多次项目实践,我发现这其实是个系统性工程,需要根据不同的仿真场景和元器件类型采取不同的处理策略。 在…...

普通人如何构建AI智能体?一篇文章搞定——快速搭建属于自己的智能体
构建一个属于自己的智能体,其核心流程围绕一个通用架构展开,该架构定义了智能体如何感知、决策和行动。 对于普通人(非专业开发者)而言,关键在于利用现有的、低代码或无代码的框架和平台,将复杂的架构组件…...

Perplexity最新v2.4文档重大更新预警:3个已删除接口、2个强制迁移路径、1个即将下线的Auth Flow——错过今晚将无法兼容生产环境
更多请点击: https://intelliparadigm.com 第一章:Perplexity最新v2.4文档重大更新预警总览 Perplexity v2.4 文档体系迎来结构性升级,核心聚焦于开发者体验一致性、API 响应语义增强及本地化支持扩展。本次更新不再仅限于补丁式修订&#x…...

提示工程:从AI调教到结构化沟通的系统方法论
1. 项目概述:从“咒语”到“工程”的思维跃迁最近在GitHub上看到一个挺有意思的项目,叫“Hazrat-Ali9/Prompt-Engineering”。乍一看,这名字有点神秘,但点进去你会发现,它其实是一个关于“提示工程”的资源集合。这让我…...

CM201-1-CH刷机避坑指南:S905L3B+UWE5621DS芯片组合刷机时,为什么必须取消‘擦除flash’?
CM201-1-CH刷机避坑指南:S905L3BUWE5621DS芯片组合的特殊性解析 每次刷机操作都像一场精密手术,而CM201-1-CH这款搭载S905L3B主控与UWE5621DS无线芯片组合的机顶盒,则像一位"特殊体质"的患者——常规操作可能导致不可逆的"医疗…...