【数据结构】详细剖析线性表
顺序表与链表的比较
- 导言
- 一、线性表
- 二、线性表的存储结构
- 三、顺序表和链表的相同点
- 四、顺序表与链表之间的差异
- 五、存储结构的选择
- 六、静态顺序表的基本操作
- 七、无头结点单链表的基本操作
- 结语

导言
大家好,很高兴又和大家见面啦!!!
经过这段时间的学习与分享,想必大家跟我一样都已经对线性表的相关内容比较熟悉了。为了更好的巩固线性表相关的知识点,下面我们一起将线性表这个章节的内容梳理一遍吧。
一、线性表
线性表的相关概念
线性表时具有相同数据类型的 n ( n > = 0 ) n(n>=0) n(n>=0)个数据元素的有限序列,其中 n n n为表长,当 n = 0 n=0 n=0时线性表是一个空表。
如果我们以 a i ( 1 < = i < = n ) a_i(1<=i<=n) ai(1<=i<=n)作为线性表的各个元素时,元素 a 1 a_1 a1为线性表唯一的第一个元素,称为表头元素;元素 a n a_n an为线性表唯一的最后一个元素,称为表尾元素。
线性表的逻辑特性是:
- 除了表头元素外,每个元素有且仅有一个直接前驱;
- 除了表尾元素外,每个元素有且仅有一个直接后继。
线性表的特点是:
- 表中元素的个数是有限的;
- 表中元素具有逻辑上的顺序性,表中元素有其先后次序;
- 表中元素都是数据元素,每个元素都是单个元素;
- 表中元素的数据类型都相同,这意味着每个元素所占空间大小相同;
- 表中元素具有抽象性,即仅讨论元素间的逻辑关系,而不考虑元素的内容;
线性表的基本操作:
- 创建与销毁
InitList(&L):初始化表。构造一个空的线性表;DestroyList(&L):销毁操作。销毁线性表,并释放线性表L所占用的内存空间。
- 插入与删除
ListInSERT(&L,i,e):插入操作。在表L中第i个位置插入指定元素e;ListDelete(&L,i,&e):删除操作。删除表L中第i个位置的元素,并用e返回删除元素的值;
- 查找
LocateElem(L,e):按值查找操作。在表L中查找具有给定关键字值的元素;GetElem(L,i):按位查找操作。获取表L中第i个位置的元素的值;
- 其它操作
Length(L):求表长。返回线性表L的长度,即L中数据元素的个数;PrintList(L):输出操作。按前后顺序输出线性表L的所有元素值;Empty(L):判空操作。若L为空表,则返回true,否则返回false;
复习完了线性表的相关知识点,下面我们来看一下线性表的两种存储结构;
二、线性表的存储结构
线性表的各元素在内存中存储时满足在逻辑上相邻,也在物理位置上相邻,这样的存储结构称为顺序存储,又称为顺序表。通常用高级程序设计语言中的数组来表示顺序存储结构。
线性表中的各个元素在内存中存储时满足在逻辑上相邻,在物理位置上不一定相邻,元素与元素之间通过“链”建立起来的逻辑关系,这样的存储结构称为链式存储,又称为链表。
对于顺序表和链表它们又有哪些异同点呢?
三、顺序表和链表的相同点
顺序表和链表的相同点都是建立在它们的本质上面的,下面我们就来看看它们具有哪些相同点:
- 顺序表和链表的元素个数都是有限的;
- 顺序表和链表的元素类型都是相同的;
- 顺序表和链表的元素都满足在逻辑上相邻;
- 顺序表和链表的元素都是数据元素,且每个元素都是单一元素;
- 顺序表和链表的元素都满足只有一个唯一的表头元素和一个唯一的表尾元素;
- 顺序表和链表的逻辑特性都是:
- 除了表头元素外,每个元素都有且仅有一个直接前驱;
- 除了表尾元素外,每个元素都有且仅有一个直接后继;
- 循序表和链表都能进行创建、销毁、增删改查等基本操作;
- 顺序表和链表在金泰
因此,我们可以得到结论:
- 顺序表和链表的本质都是线性表,只不过线性表强调的数据元素在内存上的逻辑结构,而顺序表与链表强调的是数据元素在内存上的存储结构;
介绍完了顺序表与链表的相同点,接下来我们继续来看一看它们的不同点;
四、顺序表与链表之间的差异
- 存取方式不同
- 顺序表是顺序存取结构,同时也是随机存取结构;
- 链表是链式存取结构,同时也是非随机存取结构;
因此,我们想要访问顺序表的各个元素时,只需要知道元素的下标就可以直接查找到,此时的时间复杂度是O(1);而链表想要访问第i个元素时,需要从表头开始进行遍历,此时的时间复杂度是O(n);
- 物理结构不同
- 顺序表的各个元素在物理位置上也是相邻的;
- 链表的各个元素在物理位置上不一定相邻;
因此顺序表在存储时可以做到密集存储,但是需要在内存中消耗一块连续的存储空间;而链表在存储时是离散存储的,但是需要消耗额外的空间来存放指向下一个结点的指针;
- 创建方式不同
- 顺序表在创建时需要明确最大表长、当前表长、数据存放的空间;
- 链表在创建时需要明确数据域和指针域;
- 顺序表在初始化时可以只初始化当前表长;
- 链表在初始化时需要对头结点进行初始化,链表的表长需要通过额外的计数器来确定;
因此顺序表在创建后表的大小是固定的,虽然可以通过malloc、calloc和realloc来申请新的空间达到修改表长的目的,但是在申请完新的空间后还伴随着大量的复制操作,此时的时间复杂度是O(n);而链表在创建时链表的大小是可以随时进行修改的,只需要在插入新结点时修改对应结点的指针域就行,此时的时间复杂度是O(1);
- 查找方式不同
- 顺序表在进行按位查找时,可以直接通过位序查找到对应的元素;
- 链表在进行按位查找时,需要通过从头结点往后进行遍历才能找到对应的元素;
- 顺序表在进行按值查找时,可以通过不同的查找方式进行快速查找;
- 链表在进行按值查找时,需要从头结点开始往后进行顺序查找;
因此顺序表在进行按位查找时的时间复杂度是O(1),在进行按值查找时的最坏时间复杂度为O(n);而链表在进行按位查找与按值查找的时间复杂度都是O(n);
- 插入与删除方式不同
- 顺序表在进行插入与删除时需要移动大量的元素;
- 链表在进行插入与删除时只需要修改对应的指针域;
因此顺序表的插入与删除操作的时间复杂度为O(n);而链表的插入与删除的时间复杂度为O(1);
- 空间分配不同
- 顺序表在进行动态分配时,需要申请一块连续的空间,且空间大小不能修改;
- 链表在进行动态分配时,需要申请对应的结点的空间,空间大小可以随时修改;
- 顺序表在修改表长时,需要移动大量的元素;
- 链表在修改表长时,只需要修改对应结点的指针域;
因此,顺序表在修改表长时对应的时间复杂度为O(n);而链表在修改表长时对应的时间复杂度为O(1);
在了解了顺序表与链表的异同点后,我们又应该如何进行选择呢?
五、存储结构的选择
我们在实际运用中要选择对应的存储结构,就需要结合具体的情况进行分析。从前面的介绍中我们可以看到,顺序表的优势是在查找元素的上面,而链表的优势是在增加、删除上面。因此我们在选择时需要考虑以下几点:
- 存储的考虑
在不确定线性表的长度与存储规模时,宜采用链表;
在确定线性表的表长,且需要密集存储时,宜采用顺序表;
- 运算的考虑
在表长固定的情况下需要经常对表中元素进行按序号访问时,宜采用顺序表;
在表长需要进行增加、删除的操作时,宜采用链表;
- 环境的考虑
在不支持指针的计算机语言中,虽然可以通过静态链表来实现链表,但是顺序表会更加简单一点;
在支持指针的计算机语言中,就需要从存储与运算这两个方面的角度去考虑了。
总之,两种存储结构各有长短,选择哪一种还是得由实际情况来决定。通常较稳定的线性表选择顺从存储;需要平方进行插入、删除操作的线性表选择链式存储。要想更加深刻的理解顺序存储与链式存储之间的优缺点,还是需要熟练的掌握它们才行。
六、静态顺序表的基本操作
在前面我们只介绍了动态顺序表的基本操作,今天我将补上静态顺序表基本操作,其对应的的基本格式如下所示:
//顺序表的静态创建
#define MaxSize 10//定义最大表长
typedef struct Sqlist {ElemType data[MaxSize];//存储数据元素的数组int length;//当前表长
}Sqlist;//重命名后的静态顺序表类型名
//顺序表的初始化
bool InitList(Sqlist* L){if (!L)return false;//指针L为空指针时返回falseL->length = 0;//初始化当前表长return true;
}
//顺序表的按位查找
ElemType GetElem(Sqlist L, int i){if (i<1 || i>L.length)//位序小于1,或者位序大于当前表长时表示位序不合理return -1;//位序不合理,返回-1return L.data[i - 1];//位序合理,返回下标为i-1的元素的值
}
//顺序表的按值查找
int LocateElem(Sqlist L, ElemType e) {for (int i = 0; i < L.length; i++){if (L.data[i] == e)return i + 1;//找到对应的值返回位序i+1}return -1;//没有对应的值返回-1
}
//顺序表的插入
bool ListInsert(Sqlist* L, int i, ElemType e) {if (i<1 || i>L->length + 1)//位序小于1,或者位序大于当前表长+1时表示位序不合理return false;//位序不合理返回falseif (L->length >= MaxSize)return false;//当前线性表已存满,返回falsefor (int j = L->length; j >= i; j--) {L->data[j] = L->data[j - 1];//元素往后移动}L->data[i - 1] = e;//将元素e插入位序i的位置L->length++;//当前表长+1return true;//插入成功返回true
}
//顺序表的删除
bool ListDelete(Sqlist* L, int i, ElemType e) {if (i<1 || i>L->length)//位序小于1,或者位序大于当前表长时位序不合理return false;//位序不合理返回falsee = L->data[i - 1];for (int j = i - 1; j < L->length; j++) {L->data[j] = L->data[j + 1];//元素往前移}L->length--;//当前表长-1return true;//删除成功返回true
}
七、无头结点单链表的基本操作
前面的介绍中,我只介绍了有头结点的单链表与双链表的基本操作,这里给大家补上无头结点的单链表的基本操作,其对应的格式如下所示:
//无头结点单链表的基本操作
//单链表类型的声明
typedef struct LNode {ElemType data;//数据域struct LNode* next;//指针域
}LNode, * LinkList;//重命名后的结点类型与单链表类型名
//单链表的初始化
bool InistList(LinkList* L) {if (!L)return false;//L为空指针时返回falseL= NULL;//头指针初始化为空指针return true;//初始化完返回true
}
//单链表的创建——头插法
LinkList List_HeadInsert(LinkList* L){if (!L)return NULL;//当L为空指针时返回NULLLNode* s = NULL;//指向表头结点的指针ElemType x = 0;//存放数据元素的变量……;//获取数据元素while (x != EOF)//为创建过程设置一个终点{//头插操作if (!(*L))//单链表为空表时{*L = (LNode*)calloc(1, sizeof(LNode));//创建表头结点assert(*L);//创建失败报错(*L)->data = x;//将数据元素放入数据域中(*L)->next = NULL;//表头结点指针域指向空指针}else {s = (LNode*)calloc(1, sizeof(LNode));//创建新结点assert(s);//创建失败报错s->data = x;//数据元素存放进数据域中s->next = (*L)->next;//新结点指针域指向表头结点(*L)->next = s;//头指针指向新结点}……;//获取新的数据元素}return *L;//返回创建好的单链表
}
//单链表的创建——尾插法
LinkList List_TailInsert(LinkList* L) {if (!L)return NULL;//当L为空指针时返回NULLLNode* r = NULL;//指向表尾结点的指针LNode* s = NULL;//指向新结点的指针ElemType x = 0;//存放数据元素的变量……;//获取数据元素while (x != EOF)//为创建过程设置一个终点{//尾插操作if (!(*L))//单链表为空表时{*L = (LNode*)calloc(1, sizeof(LNode));//创建表头结点assert(*L);//创建失败报错(*L)->data = x;//将数据元素放入数据域中(*L)->next = NULL;//表头结点指针域指向空指针r = (*L);//表尾指针指向表头结点,此时的表头结点也是表尾结点}else {s = (LNode*)calloc(1, sizeof(LNode));//创建新结点assert(s);//创建失败报错s->data = x;//数据元素存放进数据域中s->next = r->next;//新结点指针域指向表尾结点r->next = s;//表尾结点的指针域指向新结点r = s;//表尾指针指向新结点}……;//获取新的数据元素}return *L;//返回创建好的单链表
}
//单链表的按位查找
LNode* GetElem(LinkList L, int i) {if (!L)return NULL;//单链表为空表时返回NULLif (i < 1)return NULL;//位序不合理时返回NULLint j = 1;//单链表结点的位序LNode* s = L->next;//指向查找结点的指针while (j < i && s)//当位序相等时,结束查找;当s为空指针时,结束查找{s = s->next;//向后遍历}return s;//查找结束,返回当前结点
}
//单链表的按值查找
LNode* LocateElem(LinkList L, ElemType e) {if (!L)return NULL;//当表为空表时返回NULLLNode* s = L->next;//指向查找结点的指针while (s->data == e && s)//当元素相等时,结束查找,当s为空指针时,结束查找{s = s->next;//向后遍历}return s;//查找结束,返回当前结点
}
//单链表的前插操作——指定结点
bool InsertPriorNode(LNode* p, ElemType e) {if (!p)return false;//p为空指针,返回falseLNode* s = (LNode*)calloc(1, sizeof(LNode));//创建新结点assert(s);//创建失败,报错s->data = p->data;//p结点的数据元素放入新结点的数据域中p->data = e;//插入的数据元素放入p结点的数据域中s->next = p->next;//新结点的指针域指向p结点的后继结点p->next = s;//p结点的指针域指向新结点,完成插入操作return true;//插入成功,返回true
}
//单链表的前插操作——指定位序
bool InsertPriorNode(LinkList* L, int i, ElemType e) {if (!L)return false;//L为空指针时返回falseif (!(*L))return false;//单链表为空表时返回falseif (i < 1)return false;//位序不合理时,返回falseLNode* p = GetElem(*L, i - 1);//指向前驱结点的指针LNode* s = (LNode*)calloc(1, sizeof(LNode));//创建新结点assert(s);//创建失败,报错s->data = e;//数据元素放入新结点的数据域中s->next = p->next;//新结点的指针域指向p结点的后继结点p->next = s;//p结点的指针域指向新结点,完成插入操作return true;//插入成功,返回true
}
//单链表的后插操作——指定结点
bool InsertNextNode(LNode* p, ElemType e) {if (!p)return false;//p为空指针,返回falseLNode* s = (LNode*)calloc(1, sizeof(LNode));//创建新结点assert(s);//创建失败,报错s->data = e;//数据元素放入新结点的数据域中s->next = p->next;//新结点的指针域指向p结点的后继结点p->next = s;//p结点的指针域指向新结点,完成插入操作return true;//插入成功,返回true
}
//单链表的后插操作——指点位序
bool InsertNextNode(LinkList* L, int i, ElemType e) {if (!L)return false;//L为空指针时返回falseif (!(*L))return false;//单链表为空表时返回falseif (i < 1)return false;//位序不合理时,返回falseLNode* p = GetElem(*L, i);//指向位序i结点的指针if (!p)return false;//结点p为空指针时,返回falseLNode* s = (LNode*)calloc(1, sizeof(LNode));//创建新结点assert(s);//创建失败,报错s->data = e;//数据元素放入新结点的数据域中s->next = p->next;//新结点的指针域指向p结点的后继结点p->next = s;//p结点的指针域指向新结点,完成插入操作return true;//插入成功,返回true
}
//单链表的删除操作——指定位序
bool ListDelete(LinkList* L, int i, ElemType e) {if (!L)return false;//L为空指针时返回falseif (!(*L))return false;//单链表为空表时返回falseif (i < 1)return false;//位序不合理时返回falseLNode* p = GetElem(*L, i - 1);//位序i的前驱结点if (!p)return false;//结点p为空指针时,返回falseLNode* q = p->next;//需要删除的结点if (!q)return false;//结点q为空指针时,返回falsee = q->data;//需要删除的元素存放在变量e中p->next = q->next;//前驱结点的指针域指向删除结点的后继结点free(q);//释放被删除的结点空间return true;//删除完成,返回true
}
//单链表的删除操作——指定结点
bool ListDelete(LinkList* L,LNode* p, ElemType e) {if (!L)return false;//L为空指针时返回falseif (!(*L))return false;//单链表为空表时返回falseif (!p)return false;//p为空指针时,返回falseLNode* q = (*L)->next;//指向前驱结点的指针while (q->next != p)//判断q是否为p的前驱结点{q = q->next;//向后遍历}q->next = p->next;//前驱结点指向删除结点的后继结点free(p);//释放删除结点的空间return true;//删除完成,返回true
}
结语
到这里咱们今天的内容就全部介绍完了,线性表的相关知识点也全部介绍完了,希望这些内容能帮助大家更好的学习线性表。
接下来我们将开始进入数据结构——栈、队列和数组的学习,大家记得关注哦!最后,感谢各位的翻阅,咱们下一篇再见!!!
相关文章:
【数据结构】详细剖析线性表
顺序表与链表的比较 导言一、线性表二、线性表的存储结构三、顺序表和链表的相同点四、顺序表与链表之间的差异五、存储结构的选择六、静态顺序表的基本操作七、无头结点单链表的基本操作结语 导言 大家好,很高兴又和大家见面啦!!࿰…...

通过数字证书对PDF电子文件进行数字签名/盖章
以下代码详细说明如何使用数字证书对PDF电子文件进行数字签名/盖章。PDF文件签署主要传递PDF文件,数字证书信息,签章图片3个信息。代码中需要的文件、数字证书、签章图片可访问开放签电子签章开源系统详细了解系统的实现与效果。也可通过gitee开源社区下…...

2007~2016 年税调经纬度及其所处的省市区县乡镇数据
之前给大家分享过一份税调企业经纬度及其所处的省市区县数据: 2007~2016 年税调企业地理信息数据(含经纬度及其所处的省市区县):https://rstata.duanshu.com/#/course/76d38022cd004b09b2aa09647936beb0 最近有培训班的小伙伴提出是否能根据税调企业经纬度来判断其所属的乡…...

SLAM学习入门--编程语言
文章目录 编程语言一、C/C++C 与 C++ 的区别(面向对象的特点)C++ 与 Python的区别判断struct的字节数static 作用Const 作用extern "C"的作用多态如何实现多态?虚函数虚函数怎么实现的?析构函数虚析构函数的作用virtual函数能不能用在构造函数中&#...

Go语言程序设计-第6章--方法
Go语言程序设计-第6章–方法 对象就是简单的一个值或者变量,并且拥有其方法,而方法是某种特定类型的函数。 6.1 方法的声明 方法的声明和普通函数的声明类似,只是在函数名字前面多了一个参数。这个参数把这个方法绑定到这个参数对应的类型…...
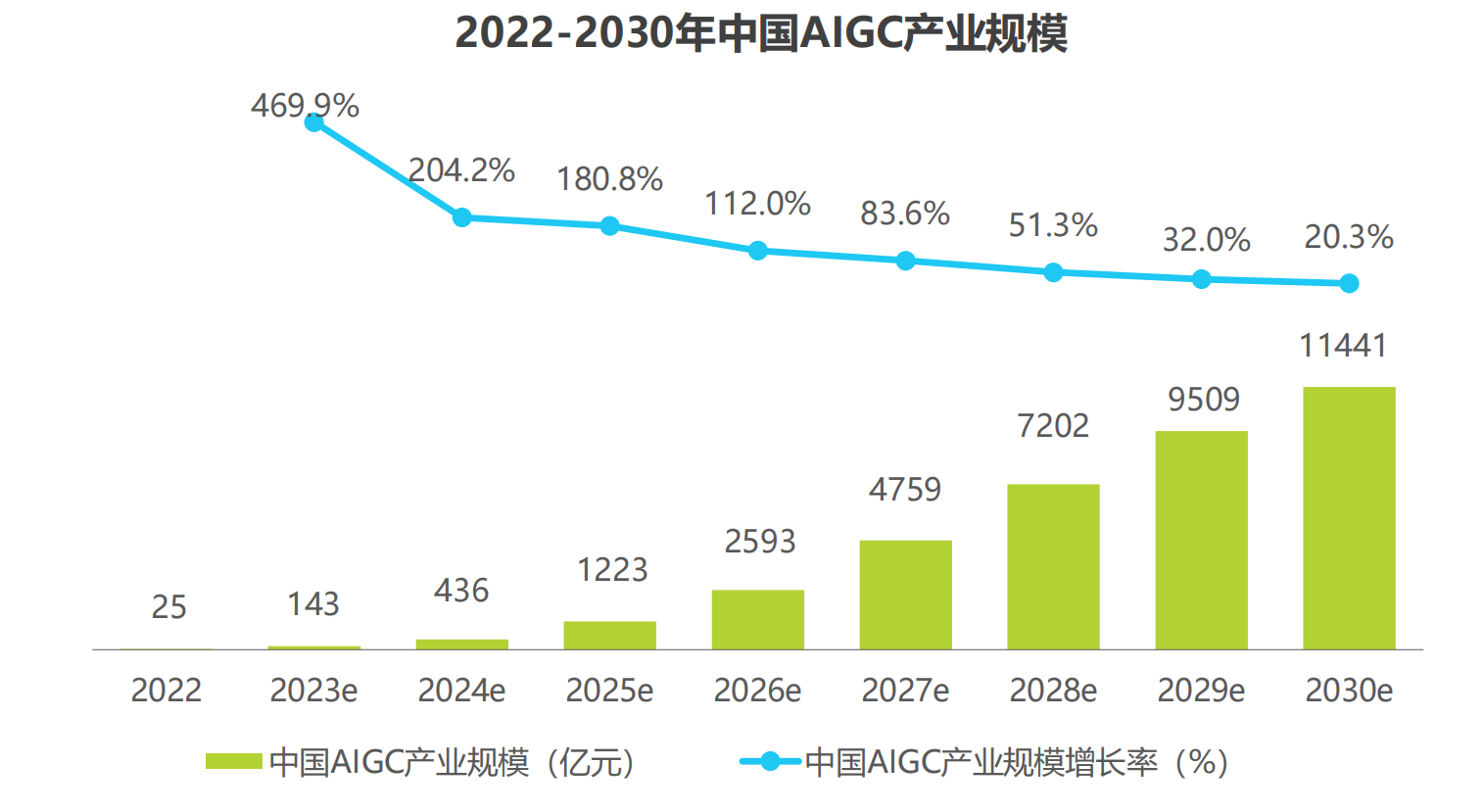
AI按理说应该最擅长理工,为啥先冲击文艺行业?
介绍 本人数据AI工程师,我的观点对全行业都有冲击,当AI大模型持续进化之时,没有一家公司能独善其身。 本文从产业架构上、论文体量、基础Pass能力、通用大模型、AI开源社区、业务属性大模型、内容消费工具、创作工具赛道、企业服务这些板块…...

蓝牙物联网移动硬件数据传输系统解决方案
随着传感器技术、网络技术和数据传输技术的不断发展,人们对智能设备的需求日渐增强,利用传感器技术可以对周围环境进行准确和全面的感知,获取到实时信息,从而在网络中进行传输和共享,再通过服务器对各种数据进行保存、分析和挖掘等…...

Linux下Web服务器工作模型及Nginx工作原理详解
文章目录 1. 工作模型概述1.1 阻塞、非阻塞、同步、异步浅析1.2 Web服务器处理并发请求的方式 2. Linux下的I/O模型2.1 常用I/O模型2.2 对比以上模型 3. Nginx工作原理3.1 Nginx基本架构3.2 Nginx代码结构3.3 Nginx工作流程3.4 Nginx缓存机制3.5 Nginx缓存工具:Memc…...

AJAX: 整理2:学习原生的AJAX,这边借助express框架
1. npm install express 终端直接安装 2. 测试案例:Hello World! 新建一个express.js的文件,写入下方的内容 // 1. 引入express const express require(express)// 2. 创建服务器 const app express()// 3.创建路由规则 // request 是对请…...

二、计算机软件及其使用-文字处理软件 Word 2016
Word 2016 的功能;Word 2016 的启动方法和工作窗口 Word 2016 的功能 编辑功能、排版功能、表格处理功能、图形与公式处理功能、文档管理功能 Word 2016 的启动方法 桌面有就单击、任务栏有就单击、开始菜单中单击 Word 2016 的工作窗口 标题栏、功能区、工作区、状…...
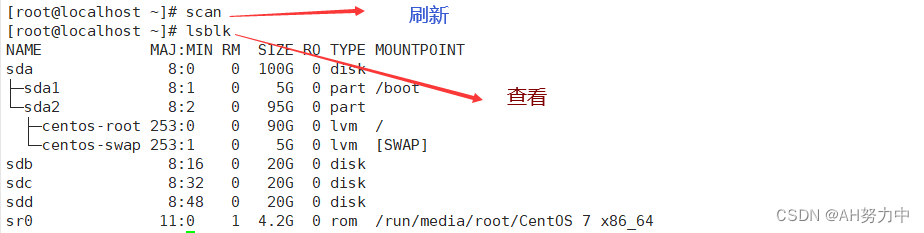
Linux LVM逻辑卷
一、LVM的定义 LVM 是 Logical Volume Manager 的简称,译为中文就是逻辑卷管理。它是 Linux 下对硬盘分区的一种管理机制。LVM 适合于管理大存储设备,并允许用户动态调整文件系统的大小。此外,LVM 的快照功能可以帮助我们快速备份数据。LVM 为…...
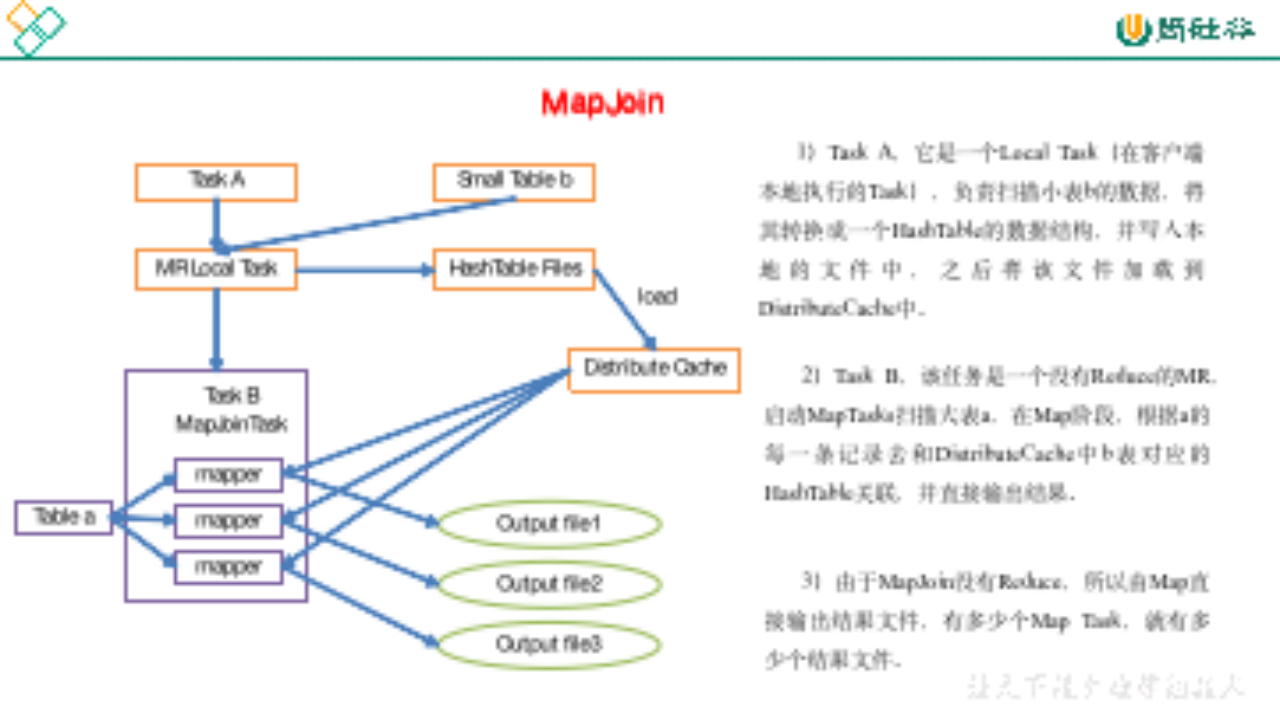
Hive生产调优介绍
1.Fetch抓取 Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。 在hive-default.xml…...

如何理解鼠标点击事件在程序中的处理
在计算机用户界面中,鼠标点击是一个常见的交互动作。那么,当你按下鼠标时,程序是如何知道这个点击是否针对它自己的按钮的呢?本文将探讨鼠标点击事件在操作系统和应用程序之间的传递过程。 鼠标点击事件的捕获 当你按下鼠标按钮…...

基于JWT的用户token验证
1. 基于session的用户验证 2. 基于token的用户身份验证 3. jwt jwt代码实现方式 1. 导包 <dependency><groupId>com.auth0</groupId><artifactId>java-jwt</artifactId><version>3.18.2</version> </dependency> 2. 在登录…...
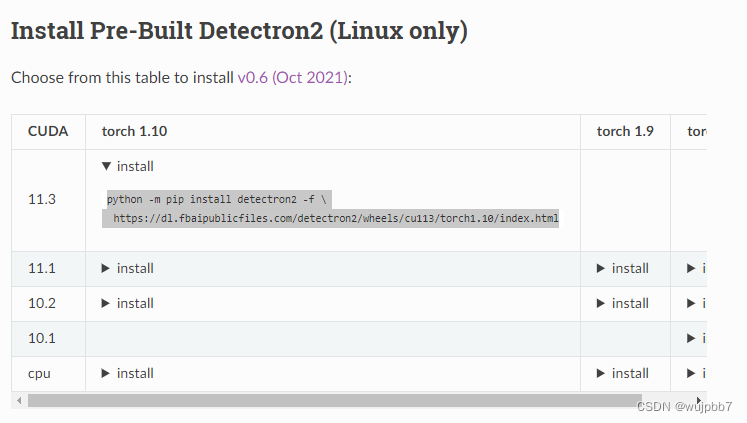
通过 conda 安装 的 detectron2
从 detectron2官网 发现预编译的版本最高支持 pytorch1.10、cuda11.3。(2023-12-26) 1、安装 conda 环境。 conda create --name detectron2 python3.8 2、安装 pytorch1.10 和 cuda11.3。 pip3 install torch1.10.0cu113 torchvision0.11.1cu113 torc…...

嵌入式开发——SPI OLED屏幕案例
学习目标 掌握移植方法掌握调试方式学习内容 需求 官方测试示例 选择对应的平台 测试示例中,找到芯片对应平台,我们选择的是STM32F407 修改例程 已知错误修改:...
ibm上电时序(视频内容)
...

如何在Vue.js中使用$emit进行组件通信
Vue.js是一个渐进式JavaScript框架,它以其简洁的数据绑定和组件系统而闻名。在构建具有多个组件层次的Vue应用时,组件间的通信成为一个关键的话题。Vue提供了一种名为$emit的方法,允许子组件向父组件发送消息。本文将详细介绍如何在Vue中使用…...

SPSS相关统计学知识精要回顾-大家都来做做
很多学生问我,学SPSS如果想深入学,那么统计学原理应该掌握到什么样的水准,我想说的是,如果真的想融会贯通,而不是短暂过关,那么应该具备一定的统计学基础,但是统计学知识也不是面面俱到都要去学…...

React Native 从类组件到函数组件
1. 发展趋势 React Native社区中的趋势是朝向使用函数组件(Functional Components)和Hooks的方向发展,而不是使用类组件(Class Components)。 React Native自推出Hooks API以来,函数组件和Hooks的使用变得…...

在Windows 10上搞定OpenPCDet:从KITTI数据集训练到自定义数据集的完整避坑指南
在Windows 10上搞定OpenPCDet:从KITTI数据集训练到自定义数据集的完整避坑指南 3D目标检测技术正在重塑自动驾驶、机器人感知等领域的发展格局。作为该领域的重要开源框架,OpenPCDet以其模块化设计和出色的性能表现吸引了大量研究者和开发者。然而&#…...

基于MCP协议构建AI工具服务器:从原理到企业级实践
1. 项目概述:一个连接上下文与工具的智能服务器最近在折腾AI应用开发,特别是想让大语言模型(LLM)能更“聪明”地使用外部工具和数据。我发现,很多项目要么是把工具调用逻辑硬编码在提示词里,要么就是搞一套…...
)
Discord服务器日活破5万后ChatGPT机器人崩了?百万级消息队列+状态分片架构设计(附GitHub星标1.2k的开源模板)
更多请点击: https://intelliparadigm.com 第一章:Discord服务器日活破5万后ChatGPT机器人崩了? 当 Discord 社区日活跃用户突破 5 万时,一个基于 OpenAI API 的 ChatGPT 机器人在高峰时段突然出现 98% 的请求超时与 429…...

基于MCP协议与本地全文检索的电子元件文档AI查询系统
1. 项目概述:为LLM构建一个本地化的电子元件文档搜索引擎如果你是一名嵌入式工程师、硬件开发者,或者像我一样,经常需要和德州仪器(TI)、意法半导体(ST)、亚德诺(ADI)这些…...

网盘下载革命:LinkSwift 如何让你在9大平台轻松获取真实下载地址
网盘下载革命:LinkSwift 如何让你在9大平台轻松获取真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云…...
)
Cheat Engine 简单使用教程(新手版)
很多人第一次打开 Cheat Engine,都会被界面吓到。 其实真没那么复杂。 如果你只是想修改一下单机游戏里的金币、血量或者资源,掌握下面这几个步骤基本就够用了。 一、先打开游戏,再启动 Cheat Engine 这一点很多新人容易搞反。 正确顺序是…...

如何通过Python快速接入Taotoken并调用多模型API完成文本生成任务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何通过Python快速接入Taotoken并调用多模型API完成文本生成任务 1. 准备工作:获取API Key与模型ID 在开始编写代码之…...

LeagueAkari游戏数据分析工具:从新手到高手的完整进阶攻略
LeagueAkari游戏数据分析工具:从新手到高手的完整进阶攻略 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾在英雄联盟游戏…...

高项通关秘籍:十大管理ITTO核心逻辑与实战速记
1. 十大管理ITTO的本质与学习误区 第一次接触高项考试的朋友,看到十大管理47个过程域的ITTO(输入、工具与技术、输出)时,往往会被密密麻麻的表格吓到。我当年备考时,整整三天都在和这些缩写词较劲,直到发现…...

终极Vim分屏体验:vim-airline轻量级状态栏与标签栏全攻略
终极Vim分屏体验:vim-airline轻量级状态栏与标签栏全攻略 【免费下载链接】vim-airline lean & mean status/tabline for vim thats light as air 项目地址: https://gitcode.com/gh_mirrors/vi/vim-airline vim-airline是一款轻量级的Vim状态栏与标签栏…...