深度学习核心技术与实践之深度学习基础篇
非书中全部内容,只是写了些自认为有收获的部分
神经网络
生物神经元的特点
(1)人体各种神经元本身的构成很相似
(2)早期的大脑损伤,其功能可能是以其他部位的神经元来代替实现的
(3)神经元具有稀疏激活性,尽管大脑具有高达五百万亿个神经元,但真正同时被激活的仅有1%~4%
神经元模型
(1)ReLu是一种特殊的Maxout函数
(2)理论上可以多种激活函数混用,但在实践中较少这样应用
感知机困境
(1)对于非线性问题,感知机只有通过人工提取特定的特征——在这些特征中将非线性的因素包含进来——使得特征仅用线性关系就可判别,才能达到目标。但这意味着非线性的引入需要靠人工完成,感知机完全帮不上忙
目标函数的选取
交叉熵的损失函数的偏导数结果简介、漂亮
初始化模型
2006年Hinton发表的Science论文提出了一种深度模型的可行训练方法,其基本思想是利用生成模型受限玻尔兹曼机一层一层地进行初始化训练,然后再利用真实数据进行参数微调
受限玻尔兹曼机(RBM)
(1)受限玻尔兹曼机由可视层和隐层构成
(2)RBM属于生成模型,用于建模观察数据和输出标签之间的联合概率分布
能量模型(EBM)
(1)系统越杂乱无序或概率分布越趋近于均匀分布,系统对应的能量越大

(2)当E(x) = -wx,EBM就是Softmax
带隐藏单元的能量模型
(1)在很多情况下,并不能直接观测到所有的x值,这时候往往需要引入隐藏变量

(2)
受限玻尔兹曼机基本原理
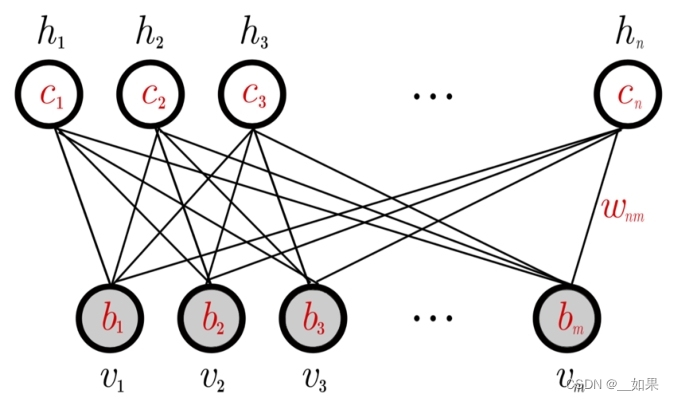
(1)玻尔兹曼机是一种特殊的对数线性马尔可夫随机场,因为其能量函数是参数的线性形式.。其隐藏单元既要依赖于观察单元,也要依赖于其他隐藏单元;观察单元可能既依赖于隐藏单元,也依赖于同层的其他观察单元
(2)受限玻尔兹曼机:同层之间不存在相互依赖关系,只有观察层和隐藏层之间存在关系
(3)能量函数:
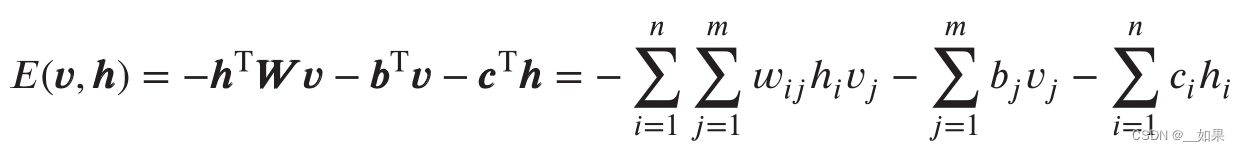
(4)从概率图的角度来看,给定所有观察变量的值时隐藏变量之间相互独立;对称的,给定所有隐藏变量的值时观察变量之间相互独立
二值RBM
(1)规定所有的观察变量v和隐藏变量h的取值范围都为(0,1)
对比散度
(1)由于隐层未知且v,h的组合空间很大,联合概率分布p(v,h)是很难计算的,因而<vh>model往往采用采样的方法
(2)一般MCMC方法需要较多的采样步数,而针对RBM训练的对比散度(CD)算法只需要较少的步数
Q:why?
A:RBM通过最大化输入数据的对数似然来进行训练,这需要计算数据的概率分布,而在高维空间中直接计算这个概率分布是非常困难的。
传统的MCMC方法在高维空间中采样时会遇到困难,因为随着维度的增加,采样点的数量呈指数增长,这使得采样过程变得非常低效。而对比散度算法是一种高效的替代方法,它不需要进行大量的采样步骤,原因如下:
(1)高效的能量梯度估计:CD算法通过在RBM中引入一个相对简单的对比能量函数来估计能量梯度的期望值。这个能量函数是基于模型在训练数据上的表现,而不是基于模型在未标记数据上的整体概率分布。因此,CD算法可以直接利用训练数据进行高效的能量梯度估计,而不需要进行耗时的MCMC采样。
(2)快速的迭代更新:由于CD算法避免了复杂的MCMC采样过程,它可以在每个训练迭代中快速地计算和更新模型参数。这使得训练过程更加高效,减少了所需的迭代步数。
(3)适应性采样:CD算法中包含了一种适应性采样技术,这种技术可以在训练过程中动态地调整采样步骤,以适应模型的学习速度。这种适应性采样确保了在训练的不同阶段都能够进行有效的采样,而不需要固定的较大采样步数。
(3)k步对比散度以训练样本为起点,执行k步吉布斯采样

自动编码器
(1)自动编码器一般由编码器网络和解码器网络组成
降噪自动编码器
(1)编码器的输入是包含噪声的,而用作解码目标的输入是去除了噪声的
(2)人为添加噪声的方法包括:添加高斯噪声、添加二维码噪声,类似于Dropout,将部分输入神经元直接置为0
栈式自动编码器
(1)叠加的自动编码器,使得第n个隐层最大程度保留第n-1个隐层的信息
(2)最后一个隐层会得到足够有效的特征
(3)可以用梯度下降之类的优化算法微调参数
深度信念网络
(1)又被称为贝叶斯网络,是一种有向无环图
(2)可以在任意叶子节点生成无偏的样本集合
(3)通过不断积累RBM形成。每当一个RBM被训练完成时,其隐藏单元又可以作为后一层RBM的输入
(4)DBN的基本思想是允许每一次RBM模型接收数据的不同表示
卷积神经网络
卷积算子
(1)在统计学中,加权的滑动平均是一种卷积
(2)在声学中,回声可以用原声与一个反映各种反射效应的函数相卷积来表示
(3)在电子工程与信号处理中,任意一个线性系统的输出都可以通过将输入信号与系统函数做卷积获得
(4)在物理学中,任何一个线性系统都存在卷积
(5)卷积核在自变量为负的区间取值为0,否则将会使用未来的读数对当前值进行加权,这种情况是超越了现实系统能力的
Q:这里找了很久都没找到为什么会时间穿越
卷积的特征
稀疏连接、参数共享、等价表达
(1)越高层的卷积层“可视野”对应到原始输入图像上的区域越大,也为提取到更高层的语义信息提供了可能
(2)虽然卷积网络单层只能看到局部信息,但是深层的卷积网络其感受野还是可以涉及全图的
(3)一个卷积核内的参数会被应用于输入的所有位置
(4)参数共享的特殊形式使得卷积层具有变换等价性——如果输入发生变化,输出会随之发生同样的变化。例如:先对图像I施以变换,再进行卷积f,结果等同于对图像I的卷积施以变换
(5)卷积网络的另一个优势在于以一种更符合逻辑的方式,利用并保持输入图像数据的三维结构:宽度、高度、深度
卷积层
(1)每个卷积核在空间中都是小尺寸的(沿宽和高),但会穿过输入集的整个深度
(2)深度对应于我们希望使用的卷积核的数量
(3)为了使用更深的卷积网络,但不希望特征图在卷积过程中尺寸下降得太快,可以做padding
池化层
(1)最大池化的超参数一般有两种选择:F=3,S=2或F=2,S=2。一般更大的池化窗口会给特征图信息带来严重的破坏
(2)平均池化被最大池化替代
(3)池化层的正向传递通常会保留最大激活单元的下标,作为反向传播时梯度的传递路径
循环神经网络
简介
(1)大脑可以处理连续的输入是因为脑神经元之间的连接允许环的存在
(2)h0通常设置为全0向量,或把h0作为一种参数,在训练过程中学习
RNN、LSTM、GRU
(1)RNN隐藏层共享同一套参数
(2)反向传播时δt+1=0,这是因为在最后一个时刻没有从下一时刻传过来的梯度
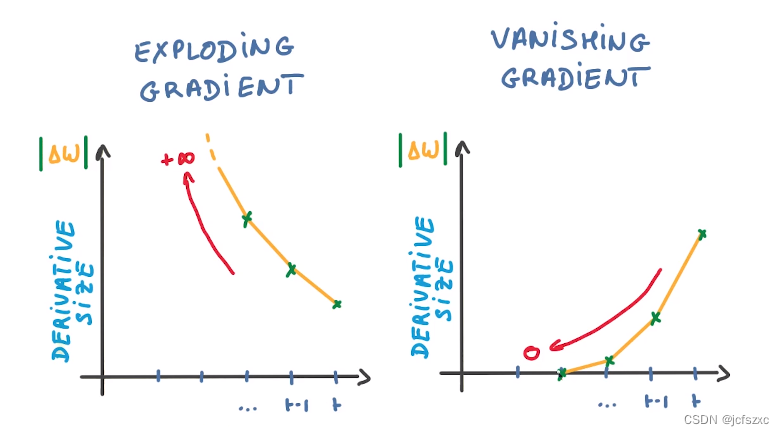
(3)梯度很多出现nan,说明很可能出现了梯度爆炸
(4)LSTM的输入门、遗忘门、输出门有形式一样的公式、共同的输入,只是参数不一样
(5)LSTM就可以自主决定当前时刻的输出是依赖于前面的较早时刻,还是前面的较晚时刻,抑或是当前时刻的输入
(6)GRU没有输出门,输出不用经过激活函数,参数更少
(7)(1-z)h'中的1-z代替了LSTM中的输入门,zht-1中的z代替了LSTM的遗忘门
(8)如果训练数据较少,推荐使用GRU
RNN语言模型
(1)n-gram,假设句子中的每个词只与其前n-1个词有关
(2)Softmax必须要加和所有词汇表的得分来计算归一化系数,会非常占内存,并且计算非常慢。我们通常采用NCE替代Softmax
深度学习优化算法
SGD
(1)有时可以用于在线学习系统,可使系统快速学到新的变化
在线学习系统是一种机器学习系统,能够在接收到新数据时动态地进行学习和更新,而不需要重新使用之前的所有数据进行训练。这种系统能够实时地从连续的数据流中学习,并随着时间的推移逐步改进自身的性能。
(2)BGD相比于SGD,不那么容易震荡,但是因为每次都需要更新整个数据集,所以BGD非常慢且无法放在内存中计算
NAG
(1)先使用动量mt计算参数θ下一个位置的近似值θ+ηmt,然后在近似位置计算梯度
(2)NAG算法会计算本轮迭代时动量到达位置的梯度,可以说它计算的是未来的梯度
NAG算法会根据此次梯度(i-1)和上一次梯度(i-2)的差值对Momentum算法得到的梯度进行修正,如果两次梯度的差值为正,证明梯度再增加,我们有理由相信下一个梯度会继续变大;相反两次梯度的差值为负,我们有理由相信下一个梯度会继续变小。
如果说Momentum算法是用一阶指数平滑,那么NGA算法则是使用了二阶指数平滑;Momentum算法类似用已得到的前一个梯度数据对当前梯度进行修正(类似一阶马尔科夫假设),NGA算法类似用已得到的前两个梯度对当前梯度进行修正(类似二阶马尔科夫假设),无疑后者得到的梯度更加准确,因此提高了算法的优化速度。
文章链接:深度解析Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam等优化器 - 知乎 (zhihu.com)
Adagrad
(1)对更新频繁且更新量大的参数,适当减小它们的步长;对不频繁的增大步长
(2)Gt是所有轮迭代的梯度平方和
(3)如果模型参数保持稳定,而分母上的Gt一直在累积,会导致梯度总体上会不断变小
RMSProp
(1)让梯度累积量G不要一直变大,而是按照一定的比率衰减
(2)此时的G更像是梯度的平均值甚至期望值
Adadelta
(1)Adagrad算法和梯度下降法相比多出来一个项目,这样更新量的“单位”就和之前不同了。为了让“单位”匹配,Adadelta选择在分子上再增加一个项目
在传统的梯度下降算法中,参数更新量通常是由当前的梯度决定的
由于Adagrad考虑了历史梯度,它的“单位”不再是单纯的梯度,而是梯度与累积历史梯度的平方根的比值
Adadelta算法在分子上增加了一个项目,即当前梯度的平方,这是为了在更新规则中同时考虑当前梯度和之前梯度的累积。这样的设计使得Adadelta可以看作是Adagrad的一种“截断”版本。
Adam
(1)基于动量的算法和基于自适应学习率的算法
(2)记录了梯度的一阶矩(梯度的期望值)和二阶矩(梯度平方的期望值)
具体来说,梯度的一阶矩和二阶矩的作用包括:
1.偏差校正:通过计算梯度的一阶矩和二阶矩,可以对梯度进行偏差校正。这种校正有助于减少梯度估计的方差,从而提高学习率的稳定性。
2.方差估计:二阶矩提供了方差估计,这有助于识别和调整那些具有较大波动性的参数。通过这种方式,Adam可以更好地适应不同参数的学习速率。
3.自适应学习率:Adam结合了RMSprop(Root Mean Square Propagation)和Momentum的方法,它使用梯度的一阶矩来近似RMSprop的累积梯度,并使用二阶矩来近似Momentum的累积梯度平方。这样,Adam能够在不同的情况下为不同的参数提供合适的学习率。
4.减少计算量:与直接计算每个参数的梯度相比,使用一阶矩和二阶矩可以减少计算量,因为它们是在累积的历史梯度上操作的。
5.改善训练动态:通过跟踪梯度的一阶矩和二阶矩,Adam可以更好地理解参数更新的历史,这有助于改善训练过程,尤其是在面对复杂的目标函数和非线性优化问题时。
(3)为了确保两个梯度积累量能够良好地估计梯度的一阶矩和二阶矩,两个积累量还需要乘一个偏置纠正系数
具体来说,偏置纠正系数的设计和作用如下:
1.偏置问题:在原始的Adam算法中,由于指数加权平均的初始化通常为0,这可能导致在早期迭代中估计的梯度矩受到偏差的影响,因为它们会被初始值拉向0。这个问题在动量和RMSprop算法中也很常见。
2.偏置纠正系数:为了解决这个问题,Adam引入了偏置纠正系数,它是对每个梯度积累量进行缩放,以消除这种偏差。偏置纠正系数通常是累积梯度平方的平方根的倒数
3.设计原因:这种设计的原因是基于数学上的推导,它确保了在算法的整个运行过程中,累积的梯度矩能够无偏差地估计实际梯度的一阶矩和二阶矩。通过这种方式,Adam能够更准确地捕捉到梯度的动态变化,从而更有效地调整学习率。
4.数值稳定性:偏置纠正系数还提高了数值稳定性,因为它避免了大梯度值对累积量的影响,从而减少了在更新过程中可能出现的数值问题。
5.算法改进:随着对Adam算法的进一步研究和改进,偏置纠正系数的引入和设计可能会有所变化,以适应不同的优化场景和提高算法的效率。
AdaMax
(1)将Adam的二阶矩修改为无穷矩
这种修改的原因和动机包括:
1.数值稳定性:在Adam算法中,二阶矩的估计是通过计算梯度平方的指数移动平均来实现的。在某些情况下,特别是当梯度非常小时,这可能导致数值不稳定,因为极小的梯度平方可能会对整体的二阶矩估计产生较大影响。无穷范数对这种数值不稳定性更为鲁棒,因为它不会对小于1的数进行平方,从而减少了梯度为零或接近零时对二阶矩估计的影响。
2.更好的泛化能力:在某些任务中,例如目标检测或机器翻译,Adam算法可能无法收敛到最优解,或者其性能可能不如传统的带有动量的SGD。这种情况下,Adamax通过使用无穷范数来估计二阶矩,可以提供更好的泛化能力和收敛性。
3.减少计算量:无穷范数通常比L2范数更容易计算,因为它不需要进行平方运算。这可以减少计算量,尤其是在处理大规模数据集时。
Nadam
(1)修改Adam的一阶矩估计值,将Nesterov算法和Adam算法结合起来
在传统的Adam算法中,梯度的一阶矩(即梯度的期望值)是通过计算梯度的一阶矩的指数移动平均来估计的。在Nadam中,这个估计值被修改为使用Nesterov预测来计算。这意味着在每个迭代中,首先根据当前的速度(动量)和之前的梯度来预测参数的更新,然后在这个预测的参数更新上计算实际的梯度。
小结
(1)优化算法分为两类,其中一类是以动量为核心的算法;另一类是以自适应为核心的算法
(2)自适应类算法在不是很复杂的优化场景下效果不是特别突出
深度学习训练技巧
数据预处理
(1)减均值适合那些各维度分布相同的数据
(2)由于各维度之间的协方差矩阵是半正定的,因此可以利用矩阵分解的方法将协方差矩阵分解,得到特征向量和对应的特征值,再将特征值从大到小排列,忽略特征值较小的维度,从而达到降维的效果。如果利用特征值进一步对特征空间的数据进行缩放,就是白化操作
权重初始化
(1)全零初始化没有打破神经元之间的对称性
(2)随机初始化将权重初始化为0附件的随机值
(3)方差校准将每个初始化值都除以根号n,其中n是输入的维度
(4)针对ReLU的方差校准应除以根号(n/2)
(5)bias占比不大,初始化一般直接采用全0或很小的数字,或者和权重向量同等对待
L1/L2参数正则化
(1)λ越小,正则化所起的作用越小,模型主要在优化原来的损失函数;λ越大,正则化越重要,参数趋向于0附近
(2)L1/L2是添加一个参数w取0附近的先验,同心圆的圆心表示数据上的最优点,等高线表示到最优点距离相同的点。先验希望参数保持在零点附近
(3)L2相当于为参数w增加了协方差的1/λ的零均值高斯分布先验;L1相当于为参数w增加了拉普拉斯先验
集成
(1)Bagging对数据进行放回重采样
(2)Boosting先针对原始数据训练一个比随机分类器性能要好一点的模型,然后用该分类器对训练数据进行预测,对预测错误的数据进行加权,从而组成一个新的训练集
Dropout
(1)Dropconnect不去掉结点,只随机放弃连接边
相关文章:
深度学习核心技术与实践之深度学习基础篇
非书中全部内容,只是写了些自认为有收获的部分 神经网络 生物神经元的特点 (1)人体各种神经元本身的构成很相似 (2)早期的大脑损伤,其功能可能是以其他部位的神经元来代替实现的 (3&#x…...

Kafka安装及简单使用介绍
🍓 简介:java系列技术分享(👉持续更新中…🔥) 🍓 初衷:一起学习、一起进步、坚持不懈 🍓 如果文章内容有误与您的想法不一致,欢迎大家在评论区指正🙏 🍓 希望这篇文章对你有所帮助,欢…...
20231229在Firefly的AIO-3399J开发板的Android11使用挖掘机的DTS配置单前后摄像头ov13850
20231229在Firefly的AIO-3399J开发板的Android11使用挖掘机的DTS配置单前后摄像头ov13850 2023/12/29 11:10 开发板:Firefly的AIO-3399J【RK3399】 SDK:rk3399-android-11-r20211216.tar.xz【Android11】 Android11.0.tar.bz2.aa【ToyBrick】 Android11.…...

九台虚拟机网站流量分析项目启动步骤
文章目录 零、操作概述一、服务器分配二、9台虚拟机相互免密登录三、Nginx(反向代理服务器)四、Tomcat(Web服务器)五、测试Nginx反向代理是否成功六、Flume集群配置七、修改LogDemo项目八、项目1703FluxStorm九、Hadoop集群十、整个集群的启动十一、部署项目十二、测试项目…...

迅软科技助力高科技防泄密:从华为事件中汲取经验教训
近期,涉及华为芯片技术被窃一事引起广泛关注。据报道,华为海思的两个高管张某、刘某离职后成立尊湃通讯,然后以支付高薪、股权支付等方式,诱导多名海思研发人员跳槽其公司,并指使这些人员在离职前通过摘抄、截屏等方式…...
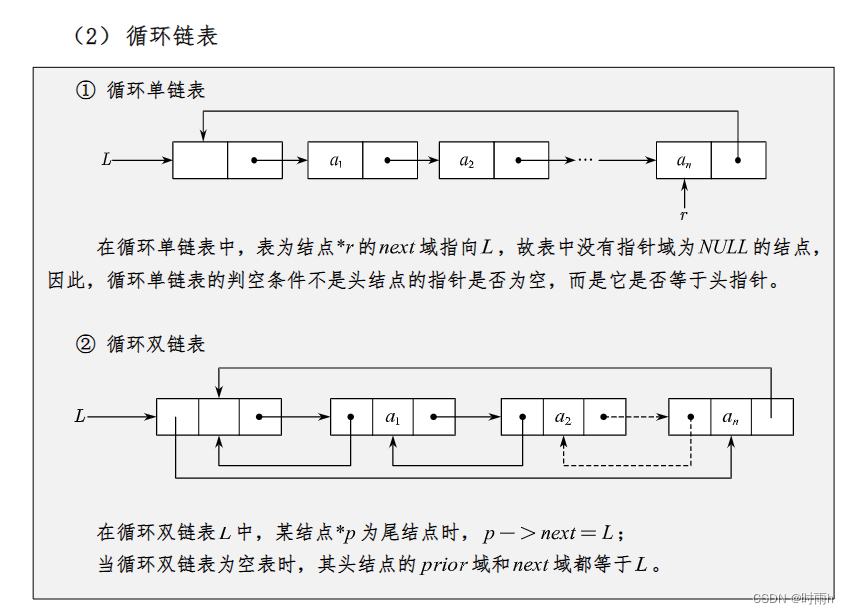
数据结构期末复习(2)链表
链表 链表(Linked List)是一种常见的数据结构,用于存储一系列具有相同类型的元素。链表由节点(Node)组成,每个节点包含两部分:数据域(存储元素值)和指针域(指…...
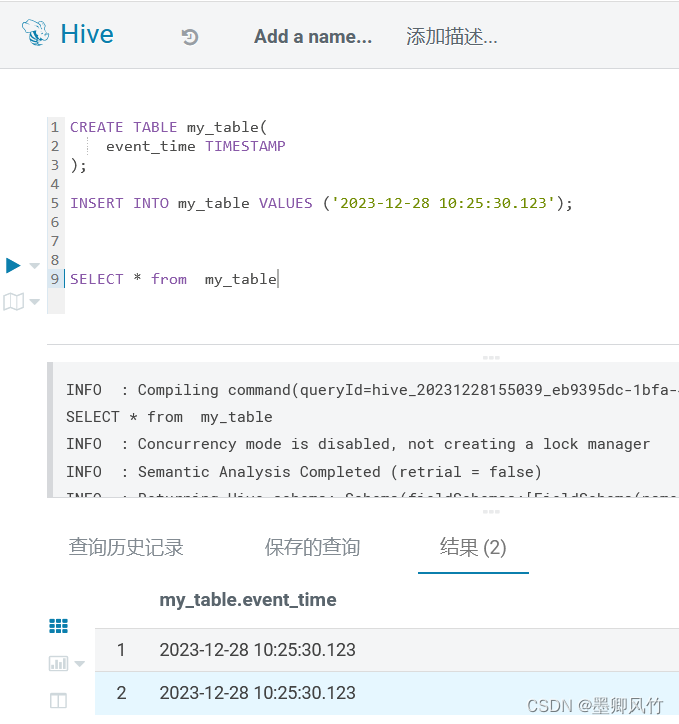
Hive中支持毫秒级别的时间精度
实际上,Hive 在较新的版本中已经支持毫秒级别的时间精度。你可以通过设置 hive.exec.default.serialization.format 和 mapred.output.value.format 属性为 1,启用 Hive 的时间精度为毫秒级。可以使用以下命令进行设置: set hive.exec.defau…...
【深度学习:Recurrent Neural Networks】循环神经网络(RNN)的简要概述
【深度学习】循环神经网络(RNN):连接过去与未来的桥梁 循环神经网络简介什么是循环神经网络 (RNN)?传统 RNN 的架构循环神经网络如何工作?常用激活函数RNN的优点和缺点RNN 的优点:RNN 的缺点: 循…...

HTML 基础
文章目录 01-标签语法标签结构 03-HTML骨架04-标签的关系05-注释06-标题标签07-段落标签08-换行和水平线09-文本格式化标签10-图像标签图像属性 11-路径相对路径绝对路径 12-超链接标签13-音频14-视频 01-标签语法 HTML 超文本标记语言——HyperText Markup Language。 超文本…...

大学物理II-作业1【题解】
1.【单选题】——考查高斯定理 下面关于高斯定理描述正确的是(D )。 A.高斯面上的电场强度是由高斯面内的电荷激发的 B.高斯面上的各点电场强度为零时,高斯面内一定没有电荷 C.通过高斯面的电通量为零时,高斯面上各点电场强度…...

Unity引擎有哪些优点
Unity引擎是一款跨平台的游戏引擎,拥有很多的优点,如跨平台支持、强大的工具和编辑器、灵活的脚本支持、丰富的资源库和强大的社区生态系统等,让他成为众多开发者选择的游戏开发引擎。下面我简单的介绍一下Unity引擎的优点。 跨平台支持 跨…...

【华为机试】2023年真题B卷(python)-猴子爬山
一、题目 题目描述: 一天一只顽猴想去从山脚爬到山顶,途中经过一个有个N个台阶的阶梯,但是这猴子有一个习惯: 每一次只能跳1步或跳3步,试问猴子通过这个阶梯有多少种不同的跳跃方式? 二、输入输出 输入描述…...

【Harmony OS - Stage应用模型】
基本概念 大类分为: Ability Module: 功能模块 、Library Module: 共享功能模块 编译时概念: Ability Module在编译时打包生成HAP(Harmony Ability Package),一个应用可能会有多个HAP…...

Java 8 中的 Stream 轻松遍历树形结构!
可能平常会遇到一些需求,比如构建菜单,构建树形结构,数据库一般就使用父id来表示,为了降低数据库的查询压力,我们可以使用Java8中的Stream流一次性把数据查出来,然后通过流式处理,我们一起来看看…...
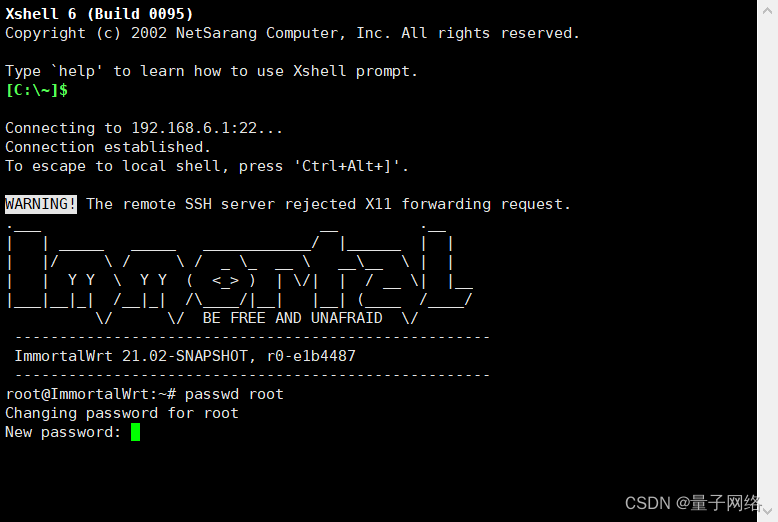
Openwrt修改Dropbear ssh root密码
使用ssh工具连接路由器 输入:passwd root 输入新密码 重复新密码 设置完成 rootImmortalWrt:~# passwd root Changing password for root New password:...

js 对象
js 对象定义 <!DOCTYPE html> <html> <body><h1>JavaScript 对象创建</h1><p id"demo1"></p> <p>new</p> <p id"demo"></p><script> // 创建对象: var persona {fi…...
【SpringBoot】常用注解
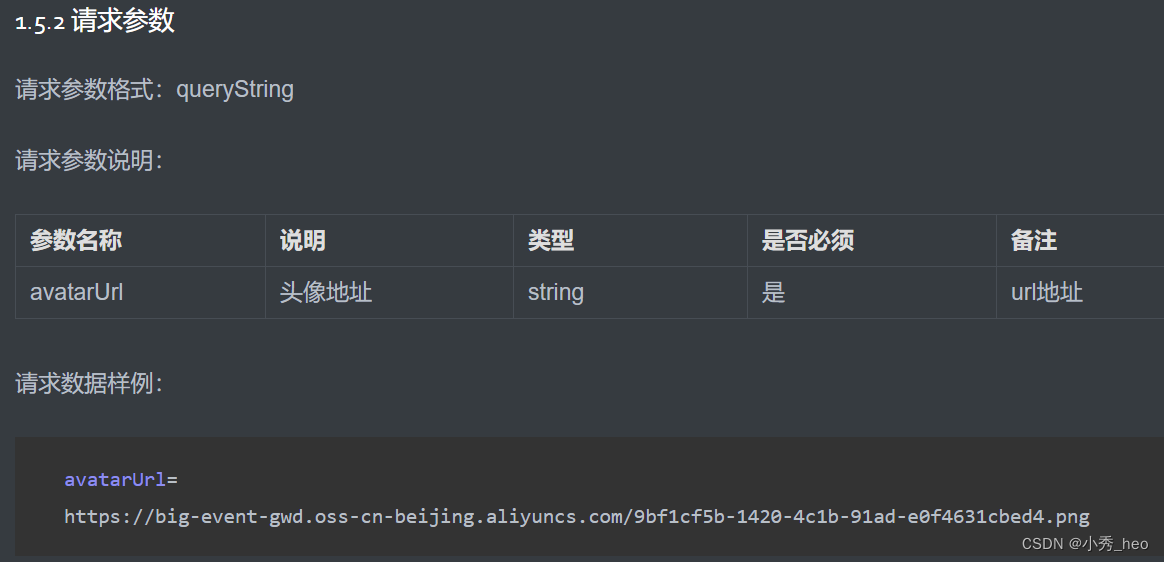
RequestBody:自动将请求体中的 json 数据转换为实体类对象。 这个例子凑巧传入的json属性键名和User键名一致,可以直接使用User实体类对象,如果键名不一致则需要用一个Map 类接收参数: PutMapping("/update")public R…...
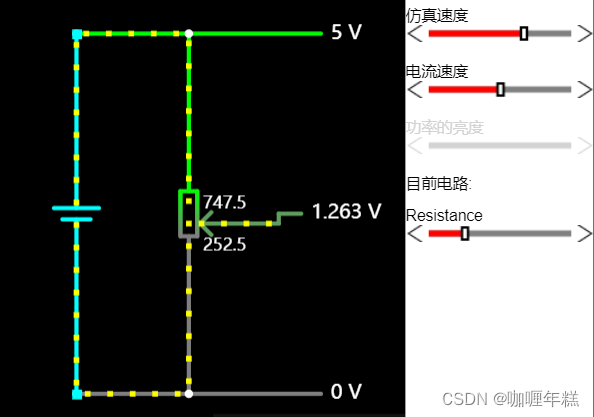
【模拟电路】软件Circuit JS
一、模拟电路软件Circuit JS 二、Circuit JS软件配置 三、Circuit JS 软件 常见的快捷键 四、Circuit JS软件基础使用 五、Circuit JS软件使用讲解 欧姆定律电阻的串联和并联电容器的充放电过程电感器和实现理想超导的概念电容阻止电压的突变,电感阻止电流的突变LR…...
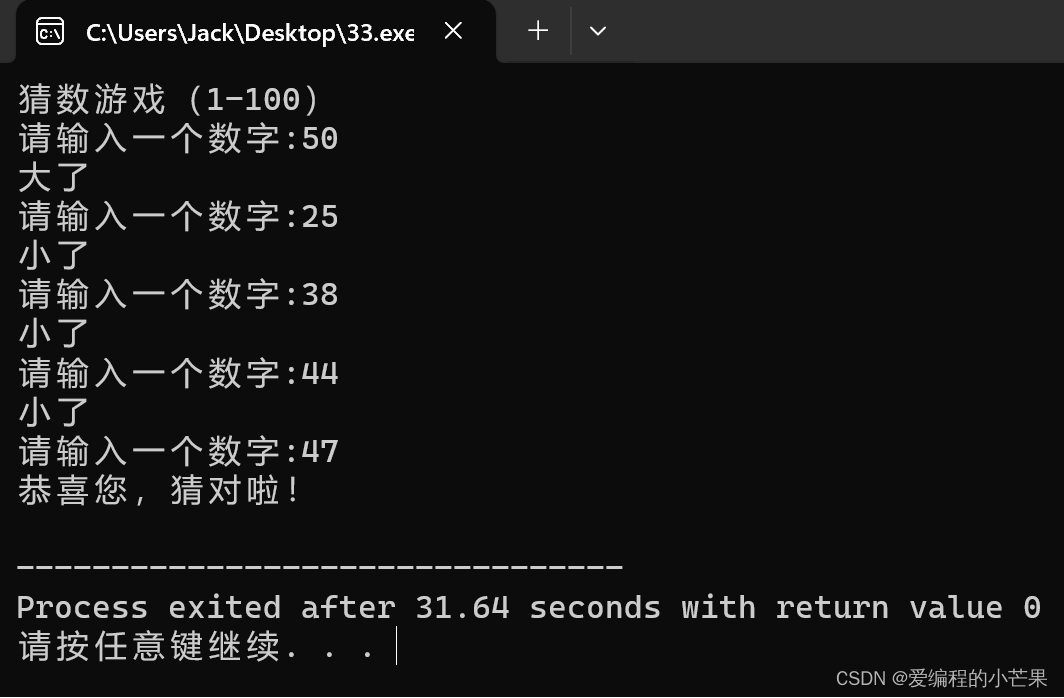
从入门到精通,30天带你学会C++【第十天:猜数游戏】
目录 Everyday English 前言 实战1——猜数游戏 综合指标 游玩方法 代码实现 最终代码 试玩时间 必胜策略 具体演示 结尾 Everyday English All good things come to those who wait. 时间不负有心人 前言 今天是2024年的第一天,新一年,新…...
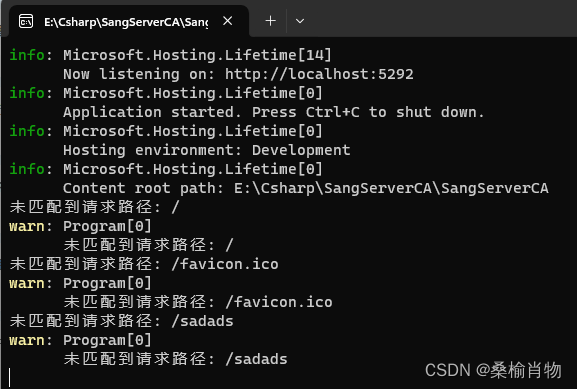
使用ASP.NET MiniAPI 调试未匹配请求路径
本文将介绍如何在使用ASP.NET MiniAPI时调试未匹配到的请求路径。我们将详细讨论使用MapFallback方法、中间件等工具来解决此类问题。 1. 引言 ASP.NET MiniAPI是一个轻量级的Web API框架,它可以让我们快速地构建和部署RESTful服务。然而,在开发过程中如…...

KubeSphere 容器平台高可用:环境搭建与可视化操作指南
Linux_k8s篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:KubeSphere 容器平台高可用:环境搭建与可视化操作指南 版本号: 1.0,0 作者: 老王要学习 日期: 2025.06.05 适用环境: Ubuntu22 文档说…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...