Langchain-Chatchat开源库使用的随笔记(一)
笔者最近在研究Langchain-Chatchat,所以本篇作为随笔记进行记录。
最近核心探索的是知识库的使用,其中关于文档如何进行分块的详细,可以参考笔者的另几篇文章:
- 大模型RAG 场景、数据、应用难点与解决(四)
- RAG 分块Chunk技术优劣、技巧、方法汇总(五)
原项目地址:
- Langchain-Chatchat
- WIKI教程(有点简单)
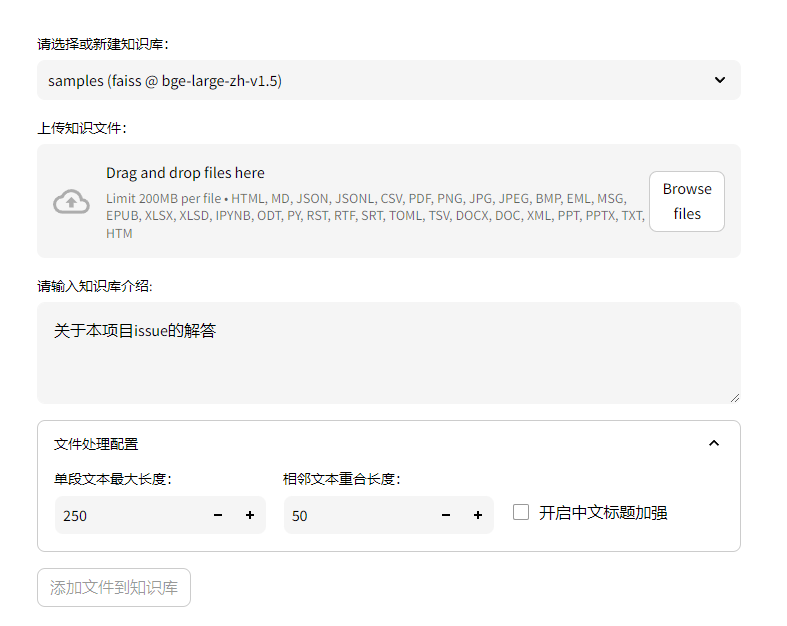
1 Chatchat项目结构
整个结构是server 启动API,然后项目内自行调用API。
API详情可见:http://xxx:7861/docs ,整个代码架构还是蛮适合深入学习
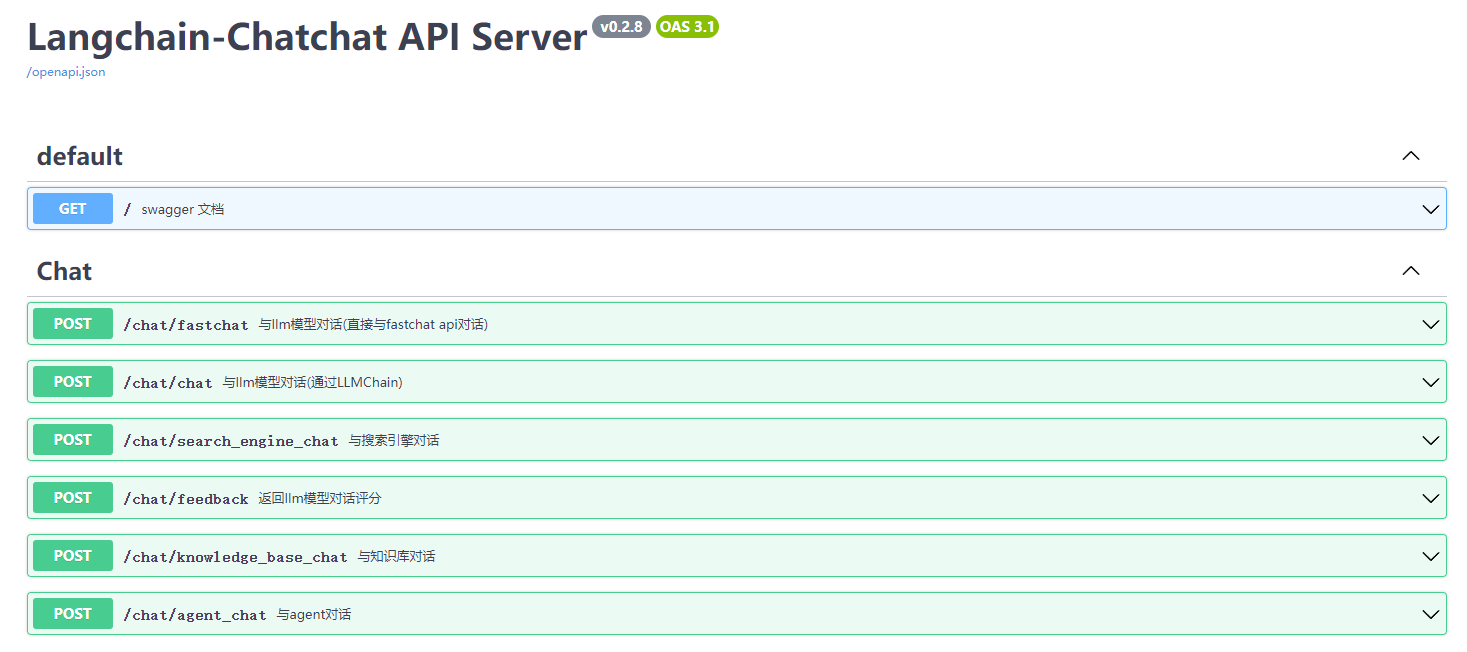
2 Chatchat一些代码学习
2.1 12个分块函数统一使用
截止 20231231 笔者看到chatchat一共有12个分chunk的函数
这12个函数如何使用、大致点评可以参考笔者的另外文章(RAG 分块Chunk技术优劣、技巧、方法汇总(五)):
CharacterTextSplitter
LatexTextSplitter
MarkdownHeaderTextSplitter
MarkdownTextSplitter
NLTKTextSplitter
PythonCodeTextSplitter
RecursiveCharacterTextSplitter
SentenceTransformersTokenTextSplitter
SpacyTextSplitterAliTextSplitter
ChineseRecursiveTextSplitter
ChineseTextSplitter
借用chatchat项目中的test/custom_splitter/test_different_splitter.py来看看一起调用make_text_splitter函数:
from langchain import document_loaders
from server.knowledge_base.utils import make_text_splitter# 使用DocumentLoader读取文件
filepath = "knowledge_base/samples/content/test_files/test.txt"
loader = document_loaders.UnstructuredFileLoader(filepath, autodetect_encoding=True)
docs = loader.load()CHUNK_SIZE = 250
OVERLAP_SIZE = 50splitter_name = 'AliTextSplitter'
text_splitter = make_text_splitter(splitter_name, CHUNK_SIZE, OVERLAP_SIZE)
if splitter_name == "MarkdownHeaderTextSplitter":docs = text_splitter.split_text(docs[0].page_content)for doc in docs:if doc.metadata:doc.metadata["source"] = os.path.basename(filepath)
else:docs = text_splitter.split_documents(docs)
for doc in docs:print(doc)2.2 知识库问答Chat的使用
本节参考chatchat开源项目的tests\api\test_stream_chat_api_thread.py 以及 tests\api\test_stream_chat_api.py
来探索一下知识库问答调用,包括:
- 流式调用
- 单次调用
- 多线程并发调用
2.2.1 流式调用
import requests
import json
import sysapi_base_url = 'http://0.0.0.0:7861'api="/chat/knowledge_base_chat"
url = f"{api_base_url}{api}"headers = {'accept': 'application/json','Content-Type': 'application/json',
}data = {"query": "如何提问以获得高质量答案","knowledge_base_name": "ZWY_V2_m3e-large","history": [{"role": "user","content": "你好"},{"role": "assistant","content": "你好,我是 ChatGLM"}],"stream": True
}
# dump_input(data, api)
response = requests.post(url, headers=headers, json=data, stream=True)
print("\n")
print("=" * 30 + api + " output" + "="*30)
for line in response.iter_content(None, decode_unicode=True):data = json.loads(line)if "answer" in data:print(data["answer"], end="", flush=True)
pprint(data)
assert "docs" in data and len(data["docs"]) > 0
assert response.status_code == 200>>>==============================/chat/knowledge_base_chat output==============================你好!提问以获得高质量答案,以下是一些建议:1. 尽可能清晰明确地表达问题:确保你的问题表述清晰、简洁、明确,以便我能够准确理解你的问题并给出恰当的回答。
2. 提供足够的上下文信息:提供相关的背景信息和上下文,以便我能够更好地理解你的问题,并给出更准确的回答。
3. 使用简洁的语言:尽量使用简单、明了的语言,以便我能够快速理解你的问题。
4. 避免使用缩写和俚语:避免使用缩写和俚语,以便我能够准确理解你的问题。
5. 分步提问:如果问题比较复杂,可以分步提问,这样我可以逐步帮助你解决问题。
6. 检查你的问题:在提问之前,请检查你的问题是否完整、清晰且准确。
7. 提供反馈:如果你对我的回答不满意,请提供反馈,以便我改进我的回答。希望这些建议能帮助你更好地提问,获得高质量的答案。结构也比较简单,call 知识库问答的URL,然后返回,通过response.iter_content来进行流式反馈。
2.2.2 正常调用以及处理并发
import requests
import json
import sysapi_base_url = 'http://0.0.0.0:7861'api="/chat/knowledge_base_chat"
url = f"{api_base_url}{api}"headers = {'accept': 'application/json','Content-Type': 'application/json',
}data = {"query": "如何提问以获得高质量答案","knowledge_base_name": "ZWY_V2_m3e-large","history": [{"role": "user","content": "你好"},{"role": "assistant","content": "你好,我是 ChatGLM"}],"stream": True
}# 正常调用并存储结果
result = []
response = requests.post(url, headers=headers, json=data, stream=True)for line in response.iter_content(None, decode_unicode=True):data = json.loads(line)result.append(data)answer = ''.join([r['answer'] for r in result[:-1]]) # 正常的结果
>>> ' 你好,很高兴为您提供帮助。以下是一些提问技巧,可以帮助您获得高质量的答案:\n\n1. 尽可能清晰明确地表达问题:确保您的问题准确、简洁、明确,以便我可以更好地理解您的问题并为您提供最佳答案。\n2. 提供足够的上下文信息:提供相关的背景信息和上下文,以便我更好地了解您的问题,并能够更准确地回答您的问题。\n3. 使用简洁的语言:尽量使用简单、明了的语言,以便我能够更好地理解您的问题。\n4. 避免使用缩写和俚语:尽量使用标准语言,以确保我能够正确理解您的问题。\n5. 分步提问:如果您有一个复杂的问题,可以将其拆分成几个简单的子问题,这样我可以更好地回答每个子问题。\n6. 检查您的拼写和语法:拼写错误和语法错误可能会使我难以理解您的问题,因此请检查您的提问,以确保它们是正确的。\n7. 指定问题类型:如果您需要特定类型的答案,请告诉我,例如数字、列表或步骤等。\n\n希望这些技巧能帮助您获得高质量的答案。如果您有其他问题,请随时问我。'refer_doc = result[-1] # 参考文献
>>> {'docs': ["<span style='color:red'>未找到相关文档,该回答为大模型自身能力解答!</span>"]}然后来看一下并发:
# 并发调用
def knowledge_chat(api="/chat/knowledge_base_chat"):url = f"{api_base_url}{api}"data = {"query": "如何提问以获得高质量答案","knowledge_base_name": "samples","history": [{"role": "user","content": "你好"},{"role": "assistant","content": "你好,我是 ChatGLM"}],"stream": True}result = []response = requests.post(url, headers=headers, json=data, stream=True)for line in response.iter_content(None, decode_unicode=True):data = json.loads(line)result.append(data)return resultfrom concurrent.futures import ThreadPoolExecutor, as_completed
import timethreads = []
times = []
pool = ThreadPoolExecutor()
start = time.time()
for i in range(10):t = pool.submit(knowledge_chat)threads.append(t)for r in as_completed(threads):end = time.time()times.append(end - start)print("\nResult:\n")pprint(r.result())print("\nTime used:\n")
for x in times:print(f"{x}")通过concurrent的ThreadPoolExecutor, as_completed进行反馈
3 知识库相关实践问题
3.1 .md格式的文件 支持非常差
我们在configs/kb_config.py可以看到:
# TextSplitter配置项,如果你不明白其中的含义,就不要修改。
text_splitter_dict = {"ChineseRecursiveTextSplitter": {"source": "huggingface", # 选择tiktoken则使用openai的方法"tokenizer_name_or_path": "",},"SpacyTextSplitter": {"source": "huggingface","tokenizer_name_or_path": "gpt2",},"RecursiveCharacterTextSplitter": {"source": "tiktoken","tokenizer_name_or_path": "cl100k_base",},"MarkdownHeaderTextSplitter": {"headers_to_split_on":[("#", "head1"),("##", "head2"),("###", "head3"),("####", "head4"),]},
}# TEXT_SPLITTER 名称
TEXT_SPLITTER_NAME = "ChineseRecursiveTextSplitter"
chatchat看上去创建新知识库的时候,仅支持一个知识库一个TEXT_SPLITTER_NAME 的方法,并不能做到不同的文件,使用不同的切块模型。
所以如果要一个知识库内,不同文件使用不同的切分方式,需要自己改整个结构代码;然后重启项目
同时,chatchat项目对markdown的源文件,支持非常差,我们来看看:
from langchain import document_loaders
from server.knowledge_base.utils import make_text_splitter# 载入
filepath = "matt/智能XXX.md"
loader = document_loaders.UnstructuredFileLoader(filepath,autodetect_encoding=True)
docs = loader.load()# 切分
splitter_name = 'ChineseRecursiveTextSplitter'
text_splitter = make_text_splitter(splitter_name, CHUNK_SIZE, OVERLAP_SIZE)
if splitter_name == "MarkdownHeaderTextSplitter":docs = text_splitter.split_text(docs[0].page_content)for doc in docs:if doc.metadata:doc.metadata["source"] = os.path.basename(filepath)
else:docs = text_splitter.split_documents(docs)
for doc in docs:print(doc)首先chatchat对.md文件读入使用的是UnstructuredFileLoader,但是没有加mode="elements"(参考:LangChain:万能的非结构化文档载入详解(一))
所以,你可以认为,读入后,#会出现丢失,于是你即使选择了MarkdownHeaderTextSplitter,也还是无法使用。
目前来看,不建议上传.md格式的文档,比较好的方法是:
- 文件改成 doc,可以带
#/##/### - 更改
configs/kb_config.py当中的TEXT_SPLITTER_NAME = "MarkdownHeaderTextSplitter"
相关文章:
Langchain-Chatchat开源库使用的随笔记(一)
笔者最近在研究Langchain-Chatchat,所以本篇作为随笔记进行记录。 最近核心探索的是知识库的使用,其中关于文档如何进行分块的详细,可以参考笔者的另几篇文章: 大模型RAG 场景、数据、应用难点与解决(四)R…...

软件体系架构复习二
呃,前面复习的忘了发了。从后面开始吧 Unit 11--18 复习Tips: 重点在于对概念的理解,概念间关系的理解。 对具体的识别方法,处理方法等根据自己的兴趣做一些了解即可 。 如:关于 软件架构脆弱性的成因 , …...

产品经理学习-策略产品指标
目录: 数据指标概述 通用指标介绍 Web端常用指标 移动端常用指标 如何选择一个合适的数据指标 数据指标概述 指标是衡量目标的一个参数,指一项活动中预期达到的指标、目标等,一般用数据表示,因此又称为数据指标;…...

【c语言】日常刷题☞有趣的题目分享❀❀
︿( ̄︶ ̄)︿hi~~ ヽ( ̄ω ̄( ̄ω ̄〃)ゝ本次刷题发现3个比较有趣的题目,分享给您,希望对您有所帮助,谢谢❀❀~ 目录 1.单词覆盖还原(单词的连续性) …...
LINUX 抓包工具Tcpdump离线安装教程
本次教程基于内网环境无法访问网络使用安装包进行安装抓包工具 1、首先给大家看下一共有6个安装包,依次进行解压,包我就放到csdn上了,需要的可以联系我进行下载 2打包然后传到服务器任意一个目录下,进入到当前目录,然后…...

c语言-string.h库函数初识
目录 前言一、库函数strlen()1.1 strlen()介绍1.2 模拟实现strlen() 二、库函数strcpy()2.1 strcpy()介绍2.2 模拟实现strcpy() 三、库函数strcmp()3.1 strcmp()介绍3.3 模拟实现strcmp() 总结 前言 本篇文章介绍c语言<string.h>头文件中的库函数,包含strlen…...
PyTorch官网demo解读——第一个神经网络(4)
上一篇:PyTorch官网demo解读——第一个神经网络(3)-CSDN博客 上一篇我们聊了手写数字识别神经网络的损失函数和梯度下降算法,这一篇我们来聊聊激活函数。 大佬说激活函数的作用是让神经网络产生非线性,类似人脑神经元…...

TCP发送和接受数据
发送数据 public class sendmessage {public static void main (String[] args) throws IOException {//创建socket对象//在创建的同时会连接服务器,若连接不上,代码会报错Socket socketnew Socket("127.0.0.1",10086);//从连接通道中获取输出流OutputStream ossock…...

SpringBoot快速集成多数据源(自动版)
有些人因为看见所以相信,有些人因为相信所以看见 有目录,不迷路 前期准备实现演示代码地址参考 最近研究了一下多数据源,这篇博客讲的是简单模式,下篇博客预计写自动切换模式 前期准备 本篇博客基于SpringBoot整合MyBatis-plus&a…...

mysql原理--Explain详解
1.概述 一条查询语句在经过 MySQL 查询优化器的各种基于成本和规则的优化会后生成一个所谓的 执行计划 ,这个执行计划展示了接下来具体执行查询的方式,比如多表连接的顺序是什么,对于每个表采用什么访问方法来具体执行查询等等。设计 MySQL 的…...

阶段五-JavaWeb综合练习-学生管理系统
一.项目说明 1.前台 (用户使用) 前端,后端 2.后台 (管理员使用) 前端,后端 3.该项目为后台管理系统 项目开发流程: 1.需求分析 1.1 登录功能 用户访问登录页面输入用户名和密码,并且输入验证码。全部输入正确后点击登录,登录成功跳转主页面;登录…...
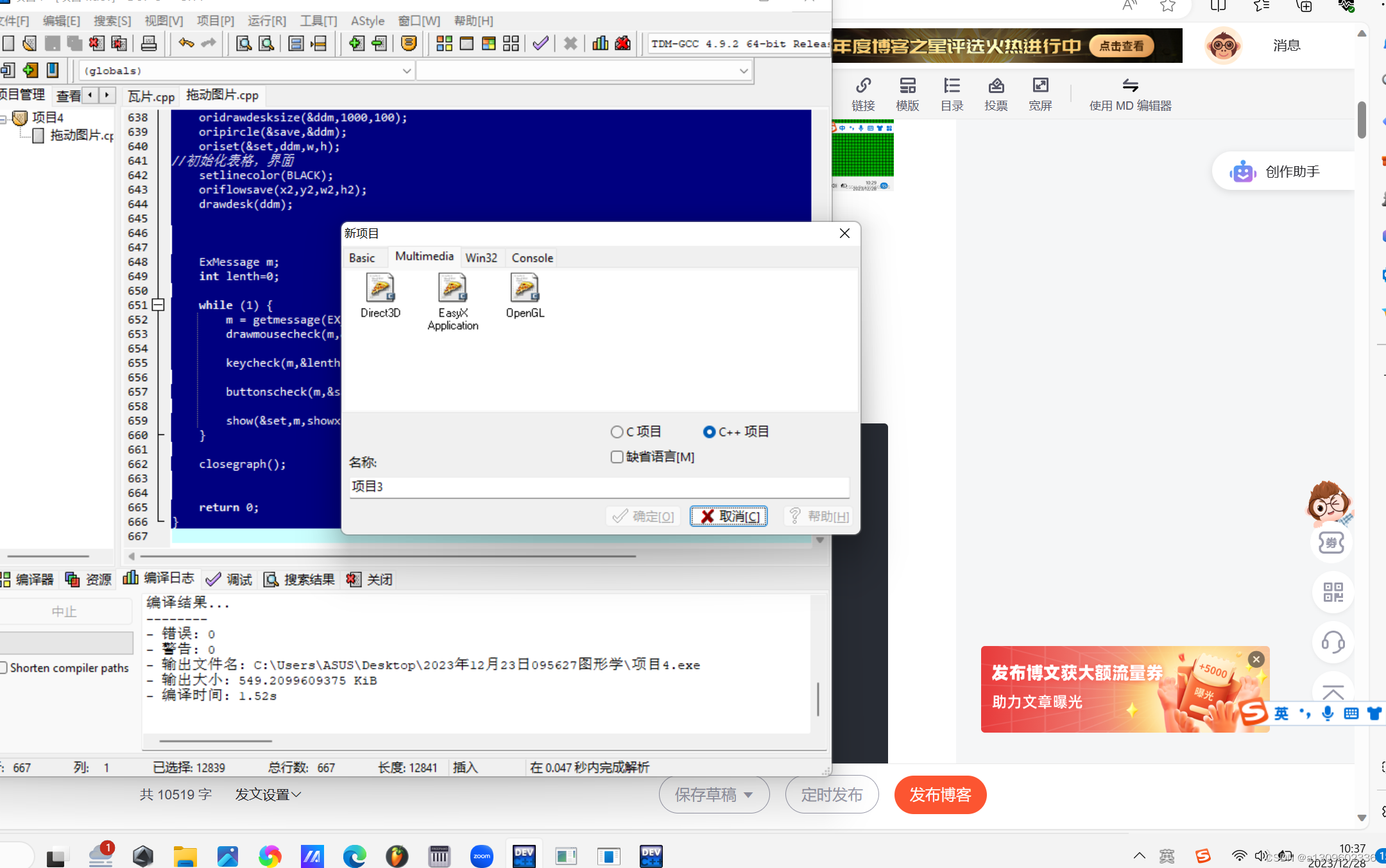
DevC++ easyx实现视口编辑--像素绘图板与贴图系统
到了最终成果阶段了,虽然中间有一些代码讲起来没有意思,纯靠debug,1-1解决贴图网格不重合问题,这次是一个分支结束。 想着就是把瓦片贴进大地图里。 延续这几篇帖子,开发时间也从2023年的4月16到了6月2号,80小时基本…...
Visual studio 2010的安装与使用
一、下载及安装 1、下载软件。 百度网盘: 链接:https://pan.baidu.com/s/115RibV7dOI_y8LUGW-94cA?pwd4hrs 提取码:4hrs 2、右键解压下载好的文件。 3、找到cn_visual_2010_……/Setup.hta,双击运行。 4、选择第三个“ Visual…...

Download Monitor Email Lock下载监控器邮件锁插件
打开Download Monitor Email Lock下载监控器邮件锁插件 Download Monitor Email Lock下载监控器邮件锁插件下载监视器的电子邮件锁定扩展允许您要求用户在获得下载访问权限之前填写他们的电子邮件地址。 Download Monitor Email Lock下载监控器邮件锁插件用法 安装扩展程序后…...
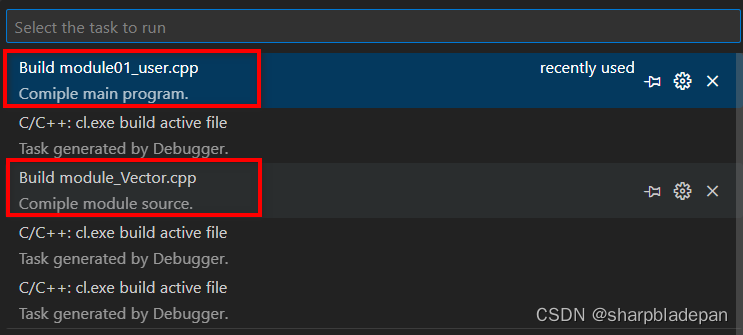
在vscode中创建任务编译module源文件
接昨天的文章 [创建并使用自己的C模块(Windows10MSVC)-CSDN博客],觉得每次编译转到命令行下paste命令过于麻烦,于是研究了一下在vscode中创建自动编译任务。 经过尝试,在task.json中增加如下代码: {"…...

element ui级连选择,lazyLoad选择地区
ui文档上直接给了一函数 先试试看效果是什么,加上let id0;不然会报错 props: {lazy: true,lazyLoad (node, resolve) {let id 0;const { level } node;setTimeout(() > {const nodes Array.from({ length: level 1 })//创建一个新数组,数组长度l…...
软件测试基础知识详解
1、黑盒测试、白盒测试、灰盒测试 1.1 黑盒测试 黑盒测试 又叫 功能测试、数据驱动测试 或 基于需求规格说明书的功能测试。该类测试注重于测试软件的功能性需求。 采用这种测试方法,测试工程师把测试对象看作一个黑盒子,完全不考虑程序内部的逻辑结构…...

Linux之进程管理
什么是进程 在linux中每个执行的程序都称为一个进程,每个进程都分配一个ID号(pid进程号)。每个进程都可能以两种方式存在,即前台和后天。前台进程就是用户目前的屏幕上可以进行操作的。后台进程则是实际在操作,但屏幕…...

动画墙纸:将视频、网页、游戏、模拟器变成windows墙纸——Lively Wallpaper
文章目录 前言下载github地址:网盘 关于VideoWebpagesYoutube和流媒体ShadersGIFs游戏和应用程序& more:Performance:多监视器支持:完结 前言 Lively Wallpaper是一款开源的视频壁纸桌面软件,类似 Wallpaper Engine,兼容 Wal…...
】阿里巴巴找黄金宝箱(I)(贪心算法-JavaPythonC++JS实现))
187.【2023年华为OD机试真题(C卷)】阿里巴巴找黄金宝箱(I)(贪心算法-JavaPythonC++JS实现)
请到本专栏顶置查阅最新的华为OD机试宝典 点击跳转到本专栏-算法之翼:华为OD机试 🚀你的旅程将在这里启航!本专栏所有题目均包含优质解题思路,高质量解题代码,详细代码讲解,助你深入学习,深度掌握! 文章目录 【2023年华为OD机试真题(C卷)】阿里巴巴找黄金宝箱(…...

Unity3D项目跨平台部署实战:从Windows到Linux的完整流程与避坑指南
1. 环境准备:搭建跨平台开发基础 跨平台部署的第一步是确保开发环境配置正确。很多开发者容易忽略这一步,结果在后续流程中遇到各种奇怪的问题。我在实际项目中遇到过多次因为环境不匹配导致的编译失败,所以特别强调环境准备的重要性。 首先需…...

HoYo.Gacha终极指南:如何轻松管理你的米哈游抽卡记录
HoYo.Gacha终极指南:如何轻松管理你的米哈游抽卡记录 【免费下载链接】HoYo.Gacha ✨ 一个非官方的工具,用于管理和分析你的 miHoYo 抽卡记录。(原神 | 崩坏:星穹铁道 | 绝区零)An unofficial tool for managing and a…...
)
从Processing到Arduino IDE:一个让硬件编程变简单的GUI故事(附STM32兼容板配置避坑)
从Processing到Arduino IDE:硬件编程的平民化革命与STM32实战指南 2005年,当Massimo Banzi在意大利伊夫雷亚交互设计学院第一次向学生们展示那块蓝色电路板时,他可能没想到这个简单的教学工具会彻底改变嵌入式开发的世界。Arduino IDE的诞生并…...
大模型面试——Transformer 中的位置编码(Positional Encoding)的意义
Transformer 中的位置编码(Positional Encoding)的意义 位置编码的存在是因为 Transformer 的核心机制 Self-Attention 是“置换不变性”的。 弥补时序信息缺失:与 RNN 不同,Transformer 放弃了递归结构以实现并行化,导致模型无法识别输入 Token 的先后顺序(即“词袋模型…...

配电箱国家标准最新解读:GB/T 7251系列关键更新与合规要点
作为低压配电系统的核心设备,配电箱的质量直接关乎电力安全与人民生命财产安全。近年来,GB/T 7251《低压成套开关设备和控制设备》系列标准持续迭代升级,为行业规范化发展提供了重要技术支撑。本文从行业观察视角,系统梳理该系列标…...

MacOS Telegram语音实时转译:本地化音频捕获与离线语音识别实践
1. 项目概述:一个为MacOS打造的Telegram语音实时转译工具如果你和我一样,经常在Telegram上参与多语言群组讨论,或者需要处理来自不同地区的语音消息,那么语言障碍绝对是一个头疼的问题。想象一下,你收到一条长达一分钟…...
)
别再只用HTTP了!用Flask-SocketIO给你的Python Web应用加上实时聊天功能(附完整前后端代码)
用Flask-SocketIO为Python Web应用注入实时交互能力 当你的博客读者提交评论后,管理员需要刷新页面才能看到新内容;当团队协作工具中的任务状态变更时,同事必须手动同步才能获取最新进展——这些传统HTTP请求带来的延迟与割裂感,正…...

考公想上岸,真的要死磕这 5 件事! 少一件,都容易陪跑[特殊字符]
1. 一定要专注备考别信 “随便学学就上岸”,每个人基础、时间、自律性完全不同。想上岸,就要全力以赴,半吊子真的很难赢。2. 能考的试尽量去考,多考多机会考公是概率题!多参加一场,就多一次上岸可能。先考上…...

RK3568开发实战:基于buildroot定制开机自启Qt应用,彻底解决全屏显示与任务栏冲突
1. RK3568开发板与buildroot固件基础 RK3568作为瑞芯微推出的高性能处理器,在工业控制和嵌入式领域应用广泛。很多开发者选择buildroot作为其轻量级Linux系统构建工具,因为它能快速生成包含Qt运行环境的定制化固件。我在实际项目中发现,直接使…...

Arduino情绪交互与Flappy Bird游戏:Tone库与状态机实战
1. 项目概述:当Arduino学会“表达情绪”与“玩游戏”在嵌入式开发的世界里,让一块小小的微控制器板子“活”起来,发出声音、显示画面并与人互动,是件充满乐趣和挑战的事。我们常常追求功能的实现,但如何让交互本身变得…...