Clojure 实战(4):编写 Hadoop MapReduce 脚本
Hadoop简介
众所周知,我们已经进入了大数据时代,每天都有PB级的数据需要处理、分析,从中提取出有用的信息。Hadoop就是这一时代背景下的产物。它是Apache基金会下的开源项目,受Google两篇论文的启发,采用分布式的文件系统HDFS,以及通用的MapReduce解决方案,能够在数千台物理节点上进行分布式并行计算。
对于Hadoop的介绍这里不再赘述,读者可以访问其官网,或阅读Hadoop权威指南。
Hadoop项目是由Java语言编写的,运行在JVM之上,因此我们可以直接使用Clojure来编写MapReduce脚本,这也是本文的主题。Hadoop集群的搭建不在本文讨论范围内,而且运行MapReduce脚本也无需搭建测试环境。
clojure-hadoop类库
Hadoop提供的API是面向Java语言的,如果不想在Clojure中过多地操作Java对象,那就需要对API进行包装(wrapper),好在已经有人为我们写好了,它就是clojure-hadoop。
从clojure-hadoop的项目介绍中可以看到,它提供了不同级别的包装,你可以选择完全规避对Hadoop类型和对象的操作,使用纯Clojure语言来编写脚本;也可以部分使用Hadoop对象,以提升性能(因为省去了类型转换过程)。这里我们选择前一种,即完全使用Clojure语言。
示例1:Wordcount
Wordcount,统计文本文件中每个单词出现的数量,可以说是数据处理领域的“Hello, world!”。这一节我们就通过它来学习如何编写MapReduce脚本。
Leiningen 2
前几章我们使用的项目管理工具lein是1.7版的,而前不久Leiningen 2已经正式发布了,因此从本章开始我们的示例都会基于新版本。新版lein的安装过程也很简单:
$ cd ~/bin
$ wget https://raw.github.com/technomancy/leiningen/stable/bin/lein
$ chmod 755 lein
$ lein repl
user=>
其中,lein repl这一步会下载lein运行时需要的文件,包括Clojure 1.4。
新建项目
$ lein new cia-hadoop
编辑project.clj文件,添加依赖项clojure-hadoop "1.4.1",尔后执行lein deps。
Map和Reduce
MapReduce,简称mapred,是Hadoop的核心概念之一。可以将其理解为处理问题的一种方式,即将大问题拆分成多个小问题来分析和解决,最终合并成一个结果。其中拆分的过程就是Map,合并的过程就是Reduce。
以Wordcount为例,将一段文字划分成一个个单词的过程就是Map。这个过程是可以并行执行的,即将文章拆分成多个段落,每个段落分别在不同的节点上执行划分单词的操作。这个过程结束后,我们便可以统计各个单词出现的次数,这也就是Reduce的过程。同样,Reduce也是可以并发执行的。整个过程如下图所示:

中间Shuffle部分的功能是将Map输出的数据按键排序,交由Reduce处理。整个过程全部由Hadoop把控,开发者只需编写Map和Reduce函数,这也是Hadoop强大之处。
编写Map函数
在本示例中,我们处理的原始数据是文本文件,Hadoop会逐行读取并调用Map函数。Map函数会接收到两个参数:key是一个长整型,表示该行在整个文件中的偏移量,很少使用;value则是该行的内容。以下是将一行文字拆分成单词的Map函数:
;; src/cia_hadoop/wordcount.clj(ns cia-hadoop.wordcount(:require [clojure-hadoop.wrap :as wrap][clojure-hadoop.defjob :as defjob])(:import [java.util StringTokenizer])(:use clojure-hadoop.job))(defn my-map [key value](map (fn [token] [token 1])(enumeration-seq (StringTokenizer. value))))
可以看到,这是一个纯粹的Clojure函数,并没有调用Hadoop的API。函数体虽然只有两行,但还是包含了很多知识点的:
(map f coll)函数的作用是将函数f应用到序列coll的每个元素上,并返回一个新的序列。如(map inc [1 2 3])会对每个元素做加1操作(参考(doc inc)),返回[2 3 4]。值得一提的是,map函数返回的是一个惰性序列(lazy sequence),即序列元素不会一次性完全生成,而是在遍历过程中逐个生成,这在处理元素较多的序列时很有优势。
map函数接收的参数自然不会只限于Clojure内部函数,我们可以将自己定义的函数传递给它:
(defn my-inc [x](+ x 1))(map my-inc [1 2 3]) ; -> [2 3 4]
我们更可以传递一个匿名函数给map。上一章提过,定义匿名函数的方式是使用fn,另外还可使用#(...)简写:
(map (fn [x] (+ x 1)) [1 2 3])
(map #(+ % 1) [1 2 3])
对于含有多个参数的情况:
((fn [x y] (+ x y)) 1 2) ; -> 3
(#(+ %1 %2) 1 2) ; -> 3
my-map中的(fn [token] [token 1])即表示接收参数token,返回一个向量[token 1],其作用等价于#(vector % 1)。为何是[token 1],是因为Hadoop的数据传输都是以键值对的形式进行的,如["apple" 1]即表示“apple”这个单词出现一次。
StringTokenizer则是用来将一行文字按空格拆分成单词的。他的返回值是Enumeration类型,Clojure提供了enumeration-seq函数,可以将其转换成序列进行操作。
所以最终my-map函数的作用就是:将一行文字按空格拆分成单词,返回一个形如[["apple" 1] ["orange" 1] ...]的序列。
编写Reduce函数
从上文的图表中可以看到,Map函数处理完成后,Hadoop会对结果按照键进行排序,并使用key, [value1 value2 ...]的形式调用Reduce函数。在clojure-hadoop中,Reduce函数的第二个参数是一个函数,其返回结果才是值的序列:
(defn my-reduce [key values-fn][[key (reduce + (values-fn))]])
和Map函数相同,Reduce函数的返回值也是一个序列,其元素是一个个[key value]。注意,函数体中的(reduce f coll)是Clojure的内置函数,其作用是:取coll序列的第1、2个元素作为参数执行函数f,将结果和coll序列的第3个元素作为参数执行函数f,依次类推。因此(reduce + [1 2 3])等价于(+ (+ 1 2) 3)。
定义脚本
有了Map和Reduce函数,我们就可以定义一个完整的脚本了:
(defjob/defjob job:map my-map:map-reader wrap/int-string-map-reader:reduce my-reduce:input-format :text:output-format :text:compress-output false:replace true:input "README.md":output "out-wordcount")
简单说明一下这些配置参数::map和:reduce分别指定Map和Reduce函数;map-reader表示读取数据文件时采用键为int、值为string的形式;:input-format至compress-output指定了输入输出的文件格式,这里采用非压缩的文本形式,方便阅览;:replace表示每次执行时覆盖上一次的结果;:input和:output则是输入的文件和输出的目录。
执行脚本
我们可以采用Clojure的测试功能来执行脚本:
;; test/cia_hadoop/wordcount_test.clj(ns cia-hadoop.wordcount-test(:use clojure.testclojure-hadoop.jobcia-hadoop.wordcount))(deftest test-wordcount(is (run job)))
尔后执行:
$ lein test cia-hadoop.wordcount-test
...
13/02/14 00:25:52 INFO mapred.JobClient: map 0% reduce 0%
..
13/02/14 00:25:58 INFO mapred.JobClient: map 100% reduce 100%
...
$ cat out-wordcount/part-r-00000
...
"java" 1
"lein" 3
"locally" 2
"on" 1
...
如果想要将MapReduce脚本放到Hadoop集群中执行,可以采用以下命令:
$ lein uberjar
$ hadoop jar target/cia-hadoop-0.1.0-SNAPSHOT-standalone.jar clojure_hadoop.job -job cia-hadoop.wordcount/job
示例2:统计浏览器类型
下面我们再来看一个更为实际的示例:从用户的访问日志中统计浏览器类型。
需求概述
用户访问网站时,页面中会有段JS请求,将用户的IP、User-Agent等信息发送回服务器,并记录成文本文件的形式:
{"stamp": "1346376858286", "ip": "58.22.113.189", "agent": "Mozilla/5.0 (iPad; CPU OS 5_0_1 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A405 Safari/7534.48.3"}
{"stamp": "1346376858354", "ip": "116.233.51.2", "agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)"}
{"stamp": "1346376858365", "ip": "222.143.28.2", "agent": "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)"}
{"stamp": "1346376858423", "ip": "123.151.144.40", "agent": "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11"}
我们要做的是从User-Agent中统计用户使用的浏览器类型所占比例,包括IE、Firefox、Chrome、Opera、Safari、以及其它。
User-Agent中的浏览器类型
由于一些历史原因,User-Agent中的信息是比较凌乱的,浏览器厂商会随意添加信息,甚至仿造其它浏览器的内容。因此在过滤时,我们需要做些额外的处理。Mozilla的这篇文章很好地概括了如何从User-Agent中获取浏览器类型,大致如下:
- IE: MSIE xyz
- Firefox: Firefox/xyz
- Chrome: Chrome/xyz
- Opera: Opera/xyz
- Safari: Safari/xyz, 且不包含 Chrome/xyz 和 Chromium/xyz
解析JSON字符串
Clojure除了内置函数之外,周边还有一个名为clojure.contrib的类库,其中囊括了各类常用功能,包括JSON处理。目前clojure.contrib中的各个组件已经分开发行,读者可以到 https://github.com/clojure 中浏览。
处理JSON字符串时,首先在项目声明文件中添加依赖项[org.clojure/data.json "0.2.1"],然后就能使用了:
user=> (require '[clojure.data.json :as json])
user=> (json/read-str "{\"a\":1,\"b\":2}")
{"a" 1, "b" 2}
user=> (json/write-str [1 2 3])
"[1,2,3]"
正则表达式
Clojure提供了一系列的内置函数来使用正则表达式,其实质上是对java.util.regex命名空间的包装。
user=> (def ptrn #"[0-9]+") ; #"..."是定义正则表达式对象的简写形式
user=> (def ptrn (re-pattern "[0-9]+")) ; 和上式等价
user=> (re-matches ptrn "123") ; 完全匹配
"123"
user=> (re-find ptrn "a123") ; 返回第一个匹配项
"123"
user=> (re-seq ptrn "a123b456") ; 返回匹配项序列(惰性序列)
("123" "456")
user=> (re-find #"([a-z]+)/([0-9]+)" "a/1") ; 子模式
["a/1" "a" "1"]
user=> (def m (re-matcher #"([a-z]+)/([0-9]+)" "a/1 b/2")) ; 返回一个Matcher对象
user=> (re-find m) ; 返回第一个匹配
["a/1" "a" "1"]
user=> (re-groups m) ; 获取当前匹配
["a/1" "a" "1"]
user=> (re-find m) ; 返回下一个匹配,或nil
["b/2" "b" "2"]
Map函数
(defn json-decode [s](try(json/read-str s)(catch Exception e)))(def rule-set {"ie" (partial re-find #"(?i)MSIE [0-9]+")"chrome" (partial re-find #"(?i)Chrome/[0-9]+")"firefox" (partial re-find #"(?i)Firefox/[0-9]+")"opera" (partial re-find #"(?i)Opera/[0-9]+")"safari" #(and (re-find #"(?i)Safari/[0-9]+" %)(not (re-find #"(?i)Chrom(e|ium)/[0-9]+" %)))})(defn get-type [ua](if-let [rule (first (filter #((second %) ua) rule-set))](first rule)"other"))(defn my-map [key value](when-let [ua (get (json-decode value) "agent")][[(get-type ua) 1]]))
json-decode函数是对json/read-str的包装,当JSON字符串无法正确解析时返回nil,而非异常终止。
rule-set是一个map类型,键是浏览器名称,值是一个函数,这里都是匿名函数。partial用于构造新的函数,(partial + 1)和#(+ 1 %)、(fn [x] (+ 1 x))是等价的,可以将其看做是为函数+的第一个参数定义了默认值。正则表达式中的(?i)表示匹配时不区分大小写。
get-type函数中,(filter #((second %) ua) rule-set)会用rule-set中的正则表达式逐一去和User-Agent字符串进行匹配,并返回第一个匹配项,也就是浏览器类型;没有匹配到的则返回other。
单元测试
我们可以编写一组单元测试来检验上述my-map函数是否正确:
;; test/cia_hadoop/browser_test.clj(ns cia-hadoop.browser-test(:use clojure.testclojure-hadoop.jobcia-hadoop.browser))(deftest test-my-map(is (= [["ie" 1]] (my-map 0 "{\"agent\":\"MSIE 6.0\"}")))(is (= [["chrome" 1]] (my-map 0 "{\"agent\":\"Chrome/20.0 Safari/6533.2\"}")))(is (= [["other" 1]] (my-map 0 "{\"agent\":\"abc\"}")))(is (nil? (my-map 0 "{"))))(deftest test-browser(is (run job)))
其中deftest和is都是clojure.test命名空间下定义的。
$ lein test cia-hadoop.browser-test
小结
本章我们简单介绍了Hadoop这一用于大数据处理的开源项目,以及如何借助clojure-hadoop类库编写MapReduce脚本,并在本地和集群上运行。Hadoop已经将大数据处理背后的种种细节都包装了起来,用户只需编写Map和Reduce函数,而借助Clojure语言,这一步也变的更为轻松和高效。Apache Hadoop是一个生态圈,其周边有很多开源项目,像Hive、HBase等,这里再推荐一个使用Clojure语言在Hadoop上执行查询的工具:cascalog。它的作者是Nathan Marz,也是我们下一章的主题——Storm实时计算框架——的作者。
本文涉及到的源码可以到 https://github.com/jizhang/blog-demo/tree/master/cia-hadoop 中查看。
相关文章:
Clojure 实战(4):编写 Hadoop MapReduce 脚本
Hadoop简介 众所周知,我们已经进入了大数据时代,每天都有PB级的数据需要处理、分析,从中提取出有用的信息。Hadoop就是这一时代背景下的产物。它是Apache基金会下的开源项目,受Google两篇论文的启发,采用分布式的文件…...
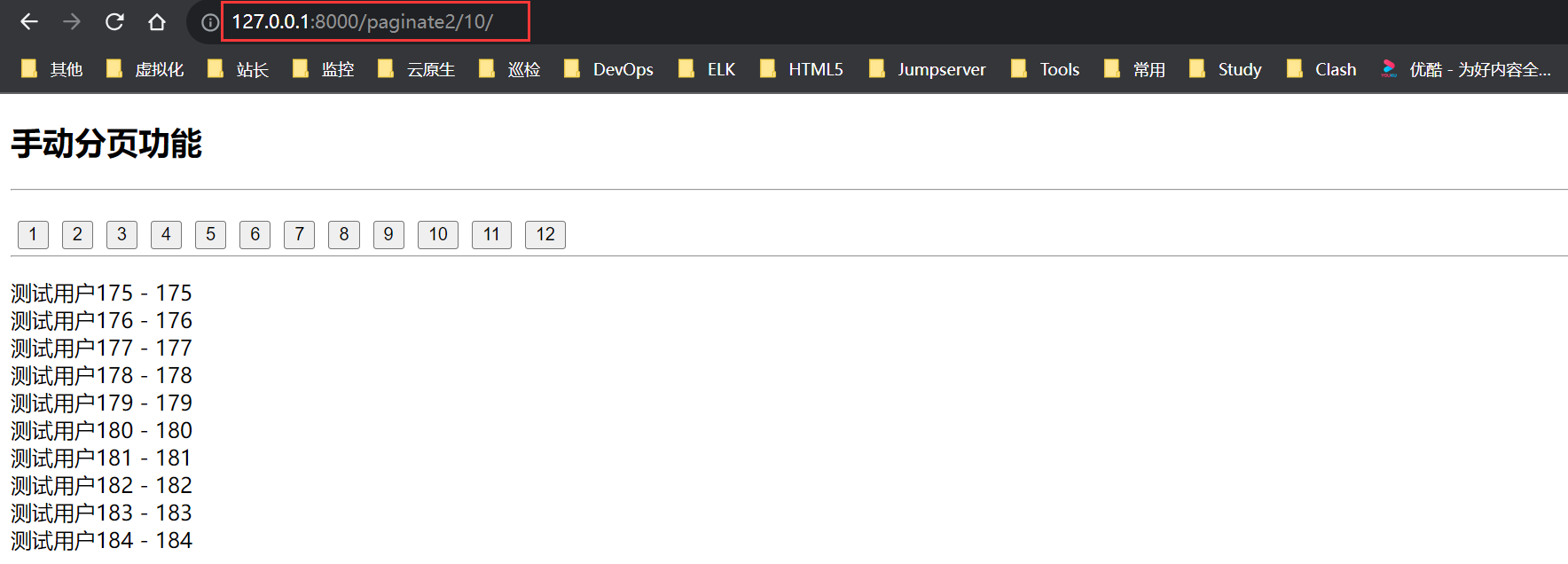
Django 分页(表单)
目录 一、手动分页二、分页器分页 一、手动分页 1、概念 页码:很容易理解,就是一本书的页码每页数量:就是一本书中某一页中的内容(数据量,比如第二页有15行内容),这 15 就是该页的数据量 每一…...
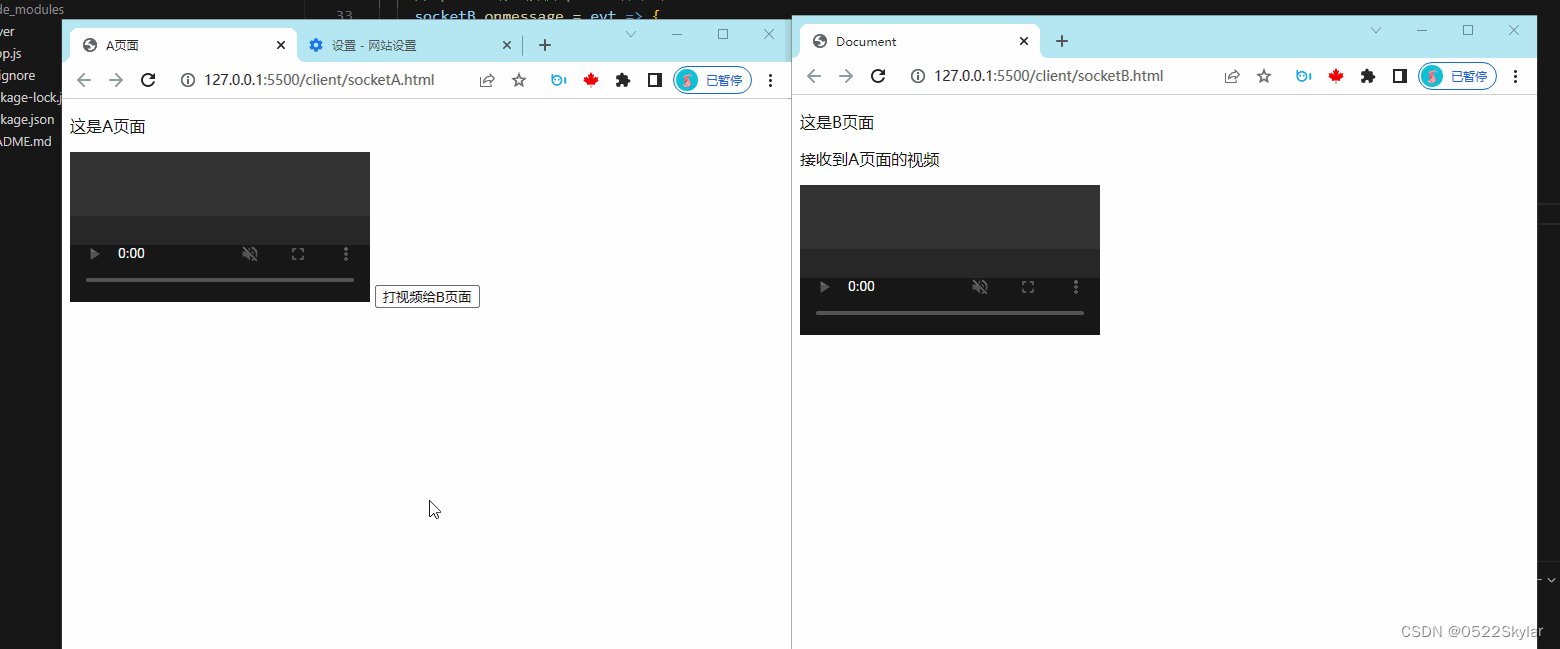
socket实现视频通话-WebRTC
最近喜欢研究视频流,所以思考了双向通信socket,接下来我们就一起来看看本地如何实现双向视频通讯的功能吧~ 客户端获取视频流 首先思考如何获取视频流呢? 其实跟录音的功能差不多,都是查询电脑上是否有媒体设备,如果…...
simulink代码生成(九)—— 串口显示数据(纸飞机联合调试)
纸飞机里面的协议是固定的,必须按照协议配置; (1)使用EasyHEX协议,测试int16数据类型 测试串口发出的数据是否符合? 串口接收数据为: 打开纸飞机绘图侧: (1)…...
——增删改查的学习(全面,详细))
Mysql数据库(中)——增删改查的学习(全面,详细)
上一篇主要对查询操作进行了详细的总结,本篇主要对增删改操作以及一些常用的函数进行总结,包括流程控制等;以下的代码可以直接复制到数据库可视化软件中,便于理解和练习; 常用的操作: #函数: S…...

test dbtest-03-对比 Liquibase、flyway、dbDeploy、dbsetup
详细对比 Liquibase、flyway、dbDeploy、dbsetup,给出对比表格 下面是一个简要的对比表格,涵盖了 Liquibase、Flyway、dbDeploy 和 DbSetup 这四个数据库变更管理工具的一些主要特点。 特点/工具LiquibaseFlywaydbDeployDbSetup开发语言Java࿰…...

力导向图与矩阵排序
Graph-layout force directed(力导向图布局)是一种用于可视化网络图的布局算法。它基于物理模型,模拟了图中节点之间的相互排斥和连接弹性,以生成具有良好可读性和美观性的图形布局。 在力导向图布局中,每个节点被视为…...

word 常用功能记录
word手册 多行文字对齐标题调整文字间距打钩方框插入三线表插入参考文献自动生成目录 多行文字对齐 标题调整文字间距 打钩方框 插入三线表 插入一个最基本的表格把整个表格设置为无框线设置上框线【实线1.5磅】设置下框线【实线1.5磅】选中第一行,设置下框线【实线…...

C#线程基础(线程启动和停止)
目录 一、关于线程 二、示例 三、生成效果 一、关于线程 在使用多线程前要先引用命名空间System.Threading,引用命名空间后就可以在需要的地方方便地创建并使用线程。 创建线程对象的构造方法中使用了ThreadStart()委托,当线程开始执行时,…...

如何利用ChatGPT来提高编程效率
如何利用ChatGPT来提高编程效率 在当今这个信息爆炸和技术快速发展的时代,程序员们面临着巨大的压力,既要保证代码的质量,又要提高工作效率。幸运的是,人工智能(AI)正在改变我们编写和维护代码的方式,而OpenAI的ChatGPT是其中的佼佼者。本文将讨论如何利用ChatGPT以及结合…...

java智慧工地源码,互联网+建筑工地,实现对工程项目内人员、车辆、安全、设备、材料等的智能化管理
智慧工地全套源码,微服务JavaSpring Cloud UniApp MySql;支持多端展示(大屏端、PC端、手机端、平板端)演示自主版权。 智慧工地概念: 智慧工地就是互联网建筑工地,是将互联网的理念和技术引入建筑工地&…...
)
创建并使用自己的C++模块(Windows10+MSVC)
module是C20种新引入的特性,关于module的介绍和好处,网上已有大量的文章,此处也不再赘述,本文仅记录在个人的环境上创建一个简单的module并使用这个module。 环境同上一篇文章( windows10,MSVC C工具链&am…...
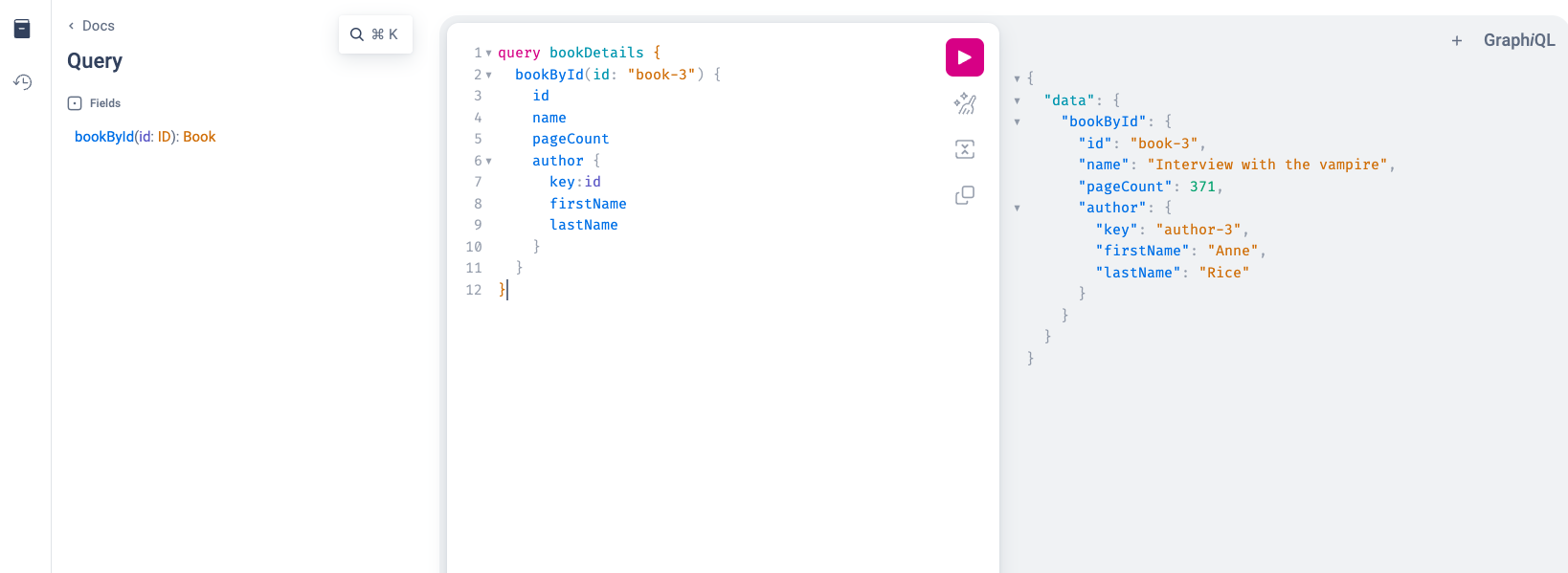
Spring Boot 2.7.11 集成 GraphQL
GraphQL介绍 GraphQL(Graph Query Language)是一种用于API的查询语言和运行时环境,由Facebook于2012年创建并在2015年公开发布。与传统的RESTful API相比,GraphQL提供了更灵活、高效和强大的数据查询和操作方式。 以下是GraphQL…...
软件工程期末总结
软件工程期末总结 软件危机出现的原因软件生命周期软件生命周期的概念生命周期的各个阶段 软件开发模型极限编程 可行性研究与项目开发计划需求分析结构化分析的方法结构化分析的图形工具软件设计的原则用户界面设计结构化软件设计面向对象面向对象建模 软件危机出现的原因 忽视…...

MidTool图文创作-GPT-4与DALL·E 3的结合
GPT-4与DALLE 3的结合 GPT-4是由OpenAI开发的最新一代语言预测模型,它在前代模型的基础上进行了大幅度的改进,不仅在文本生成的连贯性、准确性上有了显著提升,还在理解复杂语境和执行多步骤指令方面表现出了更高的能力。而DALLE 3则是一个创…...

Python将两个或多个列表合并为一个列表,并根据每个输入列表中的元素的位置将其组合在一起
将两个或多个列表合并为一个列表,并根据每个输入列表中的元素的位置将其组合在一起。 这个需求在实际开发过程中应该说非常常见,当然python也给我们内置了相关方法! zip(*iterables, strictFalse) 在多个迭代器上并行迭代,从每…...

数模混合SoC芯片中LEF2Milkyway的golden flow
在数模混合芯片中的项目中,特别是数字模块很少甚至只有一个简单的数字控制逻辑时,我们要做数字模块的后端实现时,通常模拟那边会问我们实现需要他们提供哪些数据。 通常来说,我们可以让模拟设计提供数字模块的GDS或LEF文件即可。…...

Five tips to make your essay flow
This post was written by Sydney Nicholson, a second-year master’s student in the English Department. Dear writer, Have you ever wondered what it takes to make an essay “flow”? In my time as a writing center tutor, I’ve noticed that this is one of th…...

linux驱动(二):led补
本文主要探讨s5pv210的led驱动相关知识,包括驱动主次设备注册和取消,udev(mdev)机制,静态和动态映射操作寄存器。 字符设备驱动注册 老接口(register_chrdev) static inline int register_chrdev(unsigned int major, const char *n…...

性能测试-jmeter:安装 / 基础使用
一、理解jmeter 官网-Apache JMeter-Apache JMeter™ JMeter是一款开源的性能测试工具,主要用于模拟大量用户并发访问目标服务器,以评估服务器的性能和稳定性。 JMeter可以执行以下任务序号用途描述1性能测试通过模拟多个用户在同一时间对服务器进行请…...

ARM NEON指令集:VLD3/VLD4内存加载指令详解
1. ARM SIMD指令集与VLD3/VLD4指令概述在现代处理器架构中,SIMD(单指令多数据)技术是提升计算性能的关键手段。作为ARM架构中SIMD扩展的核心,NEON技术通过宽寄存器并行处理数据,在多媒体编解码、图像处理、科学计算等领…...

5个简单步骤让猫抓浏览器扩展成为你的资源下载神器
5个简单步骤让猫抓浏览器扩展成为你的资源下载神器 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-catch)是一款功能强大的浏览器资源嗅探…...

终极Flash浏览器指南:如何在现代浏览器中畅玩经典Flash游戏
终极Flash浏览器指南:如何在现代浏览器中畅玩经典Flash游戏 【免费下载链接】CefFlashBrowser Flash浏览器 / Flash Browser 项目地址: https://gitcode.com/gh_mirrors/ce/CefFlashBrowser 你是否还在为无法玩到童年记忆中的Flash游戏而烦恼?当主…...

QMCDecode终极指南:一键解锁QQ音乐加密音频的完整解决方案
QMCDecode终极指南:一键解锁QQ音乐加密音频的完整解决方案 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默…...

如何快速构建企业级拼多多数据采集系统:3大核心优势助力电商决策
如何快速构建企业级拼多多数据采集系统:3大核心优势助力电商决策 【免费下载链接】scrapy-pinduoduo 拼多多爬虫,抓取拼多多热销商品信息和评论 项目地址: https://gitcode.com/gh_mirrors/sc/scrapy-pinduoduo 在竞争激烈的电商市场中࿰…...

VS Code本地代码评审扩展:结构化JSON存储与AI协同实践
1. 项目概述:一个纯粹本地的代码评审伴侣 如果你和我一样,日常重度依赖 VS Code,并且经常需要处理代码评审任务——无论是和同事异步协作,还是借助 AI 助手(如 Claude、GitHub Copilot、Cursor)来审查自己…...

多源视频流时空配准,搭建跨摄像机一体化轨迹推演计算平台
多源视频流时空配准,搭建跨摄像机一体化轨迹推演计算平台在数字孪生与视频孪生全域空间智能感知的建设进程中,各类管控场景普遍部署多品牌、多焦距、多布设姿态的异构摄像设备,衍生出大量编码格式各异、传输时延参差、时钟相位错位的多源异步…...

TinyML中的数据感知NAS技术解析与应用
1. TinyML与神经网络架构搜索概述在嵌入式设备和物联网终端上部署机器学习模型(TinyML)面临着严峻的资源约束问题。典型的微控制器(MCU)仅有几十KB内存和几百MHz主频,这迫使开发者必须在模型精度与资源消耗之间寻找平衡…...

深度解析Deep3D:专业级实时2D转3D视频转换技术实战指南
深度解析Deep3D:专业级实时2D转3D视频转换技术实战指南 【免费下载链接】Deep3D Real-Time end-to-end 2D-to-3D Video Conversion, based on deep learning. 项目地址: https://gitcode.com/gh_mirrors/dee/Deep3D Deep3D是一款基于深度学习的开源2D转3D视频…...

告别虚拟机卡顿:在Proxmox VE 7.0上丝滑安装中兴新支点NewStartOS 4.3.8社区版
告别虚拟机卡顿:在Proxmox VE 7.0上丝滑安装中兴新支点NewStartOS 4.3.8社区版 虚拟化技术已成为现代IT基础设施的核心组件,而Proxmox VE作为开源的虚拟化管理平台,凭借其稳定性和灵活性赢得了众多技术团队的青睐。在众多虚拟化应用场景中&am…...