linux top命令中 cpu 利用率/mem 使用率与load average平均负载计算方式
文章目录
- 1 简介
- 2 CPU% 字段
- 3 MEM% 字段
- 4 load average 平均负载
1 简介
top 命令是 Linux 上一个常用的系统监控工具,它经常用来监控 Linux 的系统状态,是常用的性能分析工具,能够显示较全的系统资源信息,包括系统负载,CPU 利用分布情况,内存使用,进程资源占用情况等。
如下示例:
top - 15:20:14 up 8 days, 2:19, 1 user, load average: 0.27, 0.16, 0.11
Tasks: 1060 total, 1 running, 1059 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.1 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 522534.9 total, 501706.3 free, 6081.8 used, 14746.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 509887.0 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6710 root 20 0 8875200 191104 62528 S 11.6 0.0 764:24.32 kubelet 4030 openvsw+ 10 -10 8359168 315392 19072 S 2.6 0.1 313:08.86 ovs-vswitchd 7172 root 20 0 9.8g 262080 105664 S 1.0 0.0 147:18.81 etcd
2601183 root 20 0 225152 8256 3648 R 0.7 0.0 0:02.56 top 13 root 20 0 0 0 0 I 0.3 0.0 14:45.23 rcu_sched 7095 root 20 0 288384 68736 9856 S 0.3 0.0 33:01.24 python
2582570 root 20 0 0 0 0 I 0.3 0.0 0:00.97 kworker/u194:2-flush-251:0 1 root 20 0 27264 16768 8448 S 0.0 0.0 0:59.07 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:03.97 kthreadd
这里主要看进程的 CPU%, MEM% 和 load averge 字段。
2 CPU% 字段
该字段指示了进程在一段时间内的 CPU 利用情况,即 cpu 使用的时间比例。
不同平台 top 命令中 cpu 利用率计算方式可能不同,不过大致逻辑是统计程序在用户态和内核态的运行时间除以从启动运行到当前时刻的时间,或者是通过采样某个时间段内任务的运行时间总和算出某个区间内的cpu利用率,下面是一种简单算法:
通过 /proc/PID/stat 读取任务在用户态的运行时间 utime,内核态运行时间 stime,任务开始运行时间 starttime,以及系统的 boot 时间 uptime。
接着根据 cpu% = (utime + stime) * 100 / (HZ * (uptime - starttime)) 计算得到一个 cpu 的利用率。
简单脚本如下:
#!/bin/bashpid=$1 # 进程 ID
uptime=$(cut -d' ' -f1 /proc/uptime) # 系统运行时间
stat=$(< /proc/$pid/stat) # 进程状态信息
utime=$(echo $stat | cut -d' ' -f14) # 进程用户态运行时间
stime=$(echo $stat | cut -d' ' -f15) # 进程内核态运行时间
starttime=$(echo $stat | cut -d' ' -f22) # 进程开始时间
echo "start time $starttime"
hz=$(getconf CLK_TCK) # 系统时钟频率
totaltime=$((utime + stime)) # 进程总运行时间
seconds=$(echo "scale=2; ($uptime - $starttime / $hz)" | bc) # 经过的秒数
cpuusage=$(echo "scale=2; 100 * $totaltime / ($hz * $seconds)" | bc) # CPU 利用率
echo "进程 $pid 的 CPU 利用率为 $cpuusage %"
测试程序:
#include <stdio.h>int main()
{while (1) {int count = 0;for (;;) {count++;if (count % 10000 == 0)break;}usleep(10);}
}进程 5764 的 CPU 利用率为 20.63 %
需要注意上述算法是一个简单算法,演示了 top 中 cpu 利用率的一个计算方式,实际代码中使用时间采样等方式获取到更加精确的 cpu 利用率。
3 MEM% 字段
该字段顾名思义统计的是任务的内存使用率,那么该值如何计算呢,又是统计的哪部份的内存占用呢?如下:
首先我们可以使用 ps aux --sort=-%mem 统计下系统中内存占用率最高的任务,ps 的统计和 top 的统计计算方式一致。
[root@node-2 ~]# ps aux --sort=-%mem
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ceph 28122 7.1 1.5 5205592 4071872 ? Ssl Jul11 125:17 /usr/bin/ceph-osd --cluster ceph -f -i 16 --setuser ceph --setgroup dis
ceph 25883 7.1 1.5 5232948 4059848 ? Ssl Jul11 124:00 /usr/bin/ceph-osd --cluster ceph -f -i 15 --setuser ceph --setgroup dis
ceph 23865 6.4 1.5 5220840 4041976 ? Ssl Jul11 111:47 /usr/bin/ceph-osd --cluster ceph -f -i 19 --setuser ceph --setgroup dis
ceph 35957 9.0 1.5 5391688 4021308 ? Ssl Jul11 158:26 /usr/bin/ceph-osd --cluster ceph -f -i 14 --setuser ceph --setgroup dis
ceph 18263 6.9 1.5 5307556 4018768 ? Ssl Jul11 120:55 /usr/bin/ceph-osd --cluster ceph -f -i 18 --setuser ceph --setgroup dis
ceph 20412 7.4 1.4 5111476 3902512 ? Ssl Jul11 129:37 /usr/bin/ceph-osd --cluster ceph -f -i 17 --setuser ceph --setgroup dis
diag 62902 20.8 1.0 36009096 2877676 ? Ssl Jul11 361:02 /bin/prometheus --web.console.templates=/etc/prometheus/consoles --web.
root 19200 0.6 0.6 2829756 1663784 ? SLl Jul11 11:44 mongod -f /etc/mongod.conf --auth
root 16180 59.3 0.6 2359060 1623320 ? Ssl Jul11 1037:53 /kube-apiserver --advertise-address=10.50.1.5 --etcd-servers=https://1
root 48824 0.4 0.5 1858596 1511388 ? Sl Jul11 7:35 ovsdb-server -vconsole:info -vsyslog:off -vfile:off --log-file=/var/log
systemd+ 48377 1.5 0.5 6644228 1378636 ? Sl Jul11 27:22 /usr/sbin/mysqld --wsrep-new-cluster
systemd+ 26533 0.5 0.4 1389572 1089968 ? Ssl Jul11 9:08 memcached -v -u memcache -p 11211 -U 0 -c 60000 -m 1024 -I 128m
ceph 20098 1.2 0.3 1558396 988656 ? Ssl Jul11 22:31 /usr/bin/ceph-mon --cluster ceph --setuser ceph --setgroup ceph -f -i n
ceph 6832 1.6 0.3 2072256 890892 ? Ssl Jul11 29:30 /usr/bin/ceph-osd --cluster ceph -f -i 20 --setuser ceph --setgroup dis
root 43596 68.5 0.3 23389276 866648 ? Sl Jul11 [root@node-3 ~]# free -htotal used free shared buff/cache available
Mem: 251Gi 237Gi 7.9Gi 4.1Gi 5.8Gi 9.6Gi
Swap: 0B 0B 0B
[root@node-3 ~]#
ps 和 top 命令中显示的内存信息来源于 /proc/pid/status 文件,该文件统计了进程使用的各类系统资源,其中 ps 和 top 显示的内存资源有 VSZ 和 RSS,对应 top 是 VIRT 和 RES,对应 ps 是 VSZ 和 RSS。
VSZ 表示的是内核申请的虚拟内存总量,status 文件中用 VmSize 表示。RSS 表示匿名映射,文件映射,常驻shmem内存(SysV shm,tmpfs和共享匿名映射)这三种映射的内存,这三种驻留在内存的数据,也就是实际的物理内存占用。
status 文件展示:
root@node-3 ~]# cat /proc/2698/status
...
NSsid: 2698
VmPeak: 140968180 kB
VmSize: 140967424 kB
VmLck: 140933516 kB
VmPin: 0 kB
VmHWM: 492836 kB
VmRSS: 492836 kB
RssAnon: 464204 kB
RssFile: 28404 kB
RssShmem: 228 kB
VmData: 463656 kB
VmStk: 208 kB
VmExe: 116 kB
VmLib: 26932 kB
VmPTE: 1864 kB
VmSwap: 0 kB
HugetlbPages: 16777216 kB
CoreDumping: 0
Threads: 97
SigQ: 3/291773
这里顺便说一下 free 命令计算空闲内存的方式:
首先是 free 的内存计算来自于 /proc/meminfo 文件,每个字段含义需要在内核文档 proc.txt 中确认:
[root@node-2 procps-ng-3.3.15]# cat /proc/meminfo
MemTotal: 535137152 kB
MemFree: 518735680 kB
MemAvailable: 518809344 kB
Buffers: 192 kB
Cached: 6451136 kB
SwapCached: 0 kB
Active: 3429760 kB
Inactive: 5747264 kB
Active(anon): 2658816 kB
Inactive(anon): 4342784 kB
Active(file): 770944 kB
Inactive(file): 1404480 kB
Unevictable: 298688 kB
Mlocked: 298688 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 512 kB
Writeback: 0 kB
AnonPages: 3027200 kB
Mapped: 907264 kB
Shmem: 4367872 kB
KReclaimable: 298752 kB
Slab: 1624704 kB
SReclaimable: 298752 kB
SUnreclaim: 1325952 kB
KernelStack: 124608 kB
PageTables: 67968 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 267568576 kB
Committed_AS: 15039744 kB
VmallocTotal: 133009506240 kB
VmallocUsed: 0 kB
VmallocChunk: 0 kB
HardwareCorrupted: 0 kB
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 524288 kB
Hugetlb: 0 kB
free 命令 Used 计算源码如下:
mem_used = kb_main_total - kb_main_free - kb_main_cached - kb_main_buffers;if (mem_used < 0)mem_used = kb_main_total - kb_main_free;kb_main_used = (unsigned long)mem_used;
整理为 meminfo 文件内容后如下:
Used = MemTotal - MemFree - Cached - SReclaimable - Buffers
(其中 SReclaimable 是 slab 中可回收内存部分)
计算例子:
正常节点:total used free shared buff/cache available
Mem: 535137152 9655488 518731584 4367872 6750080 518805248[root@node-2 procps-ng-3.3.15]# cat /proc/meminfo
MemTotal: 535137152 kB
MemFree: 518735680 kB
MemAvailable: 518809344 kB
Buffers: 192 kB
Cached: 6451136 kB
SwapCached: 0 kB
Active: 3429760 kB
Inactive: 5747264 kB
Active(anon): 2658816 kB
Inactive(anon): 4342784 kB
Active(file): 770944 kB
Inactive(file): 1404480 kB
Unevictable: 298688 kB
Mlocked: 298688 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 512 kB
Writeback: 0 kB
AnonPages: 3027200 kB
Mapped: 907264 kB
Shmem: 4367872 kB
KReclaimable: 298752 kB
Slab: 1624704 kB
SReclaimable: 298752 kB
SUnreclaim: 1325952 kB
KernelStack: 124608 kB
PageTables: 67968 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 267568576 kB
Committed_AS: 15039744 kB
VmallocTotal: 133009506240 kB
VmallocUsed: 0 kB
VmallocChunk: 0 kB
HardwareCorrupted: 0 kB
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 524288 kB
Hugetlb: 0 kB根据公式计算 Used:
Used = 535137152 - 518735680 - 6451136 - 298752 - 192 = 9651392 符合
那么 Used 包括了其他所有内存使用,包括 kernelstack,pagetable,buddy,slab 等等,基于此有另外两个公式计算总内存量:
MemTotal = MemFree+ [Slab + VmallocUsed + PageTables + KernelStack + HardwareCorrupted + Bounce + X] + [Active + Inactive + Unevictable + (HuagePage_Total * Hugepagesize)]= MemFree+ [Slab + VmallocUsed + PageTables + KernelStack + HardwareCorrupted + Bounce + X] + [Cached + AnonPages + Buffers + (HuagePage_Total * Hugepagesize)]其中 X 代表 alloc_pages/__get_free_pages 接口分配的内存,这部分不会统计到 meminfo 中。
按照上述规则计算 alloc_pages 使用量:
正常节点:518735680+ [1624704 + 0 + 67968 + 124608 + 0 + 0 + X]+ [3429760 + 5747264 + 298688 + 0] = 530028672buddy = 535137152 - 530028672 = 5108480 KB 4.87G518735680+ [1624704 + 0 + 67968 + 124608 + 0 + 0 + X]+ [6451136 + 3027200 + 192 + 0]= 530031488buddy = 535137152 - 530031488 = 5105664 KB 4.86G差不多正常节点 X = 4.87G,这部分被 alloc_pages 等使用,基本符合预期。
4 load average 平均负载
load average 字段统计了系统在 1分钟/5分钟/15分钟的平均负载,其指标根据 cpu 数量有所不同,数值反应了系统的整体负载情况,数值越高系统负载压力越大。那么如何能够更直观的理解该负载呢?通过计算方式可以很好的理解其 load average 表达的含义。
load average 值来自于 /proc/loadavg 文件前三个数值,该值来自于内核的 sched/loadavg.c calc_global_load 的计算得出,主要统计 1 分钟,5 分钟,15 分钟内的可运行任务数量 + 不可中断睡眠任务(io wait 等)总和计算的平均负载。
其计算方式采用周期衰减旧负载并累加周期内新负载,而更新周期窗口时间为 5s,即 5s 更新一次平均负载,并根据一定算法累加到 1分钟/5分钟/15分钟。
公式大致如下:
...active = atomic_long_read(&calc_load_tasks);active = active > 0 ? active * FIXED_1 : 0;// 更新 1分钟/5分钟/15分钟 平均负载avenrun[0] = calc_load(avenrun[0], EXP_1, active);avenrun[1] = calc_load(avenrun[1], EXP_5, active);avenrun[2] = calc_load(avenrun[2], EXP_15, active);
...// 其中使用的 EXP_n 为常量系数
EXP_n = 1/5/15 分钟的常量系数:
EXP_1 1884
EXP_5 2014
EXP_15 2037
FIXED_1 2048// 通过周期衰减旧负载 + 更新周期内新负载得到现在的负载
now_load = old_load(1/5/15) * (EXP_n/FIXED_1) + new_load * (1 - EXP_n/FIXED_1)即通过周期间隔时间衰减老的平均负载 + 该周期内的平均负载得到现在的平均负载(类似 pelt 算法)。
实际内核计算代码为:
/** a1 = a0 * e + a * (1 - e)*/
static inline unsigned long
calc_load(unsigned long load, unsigned long exp, unsigned long active)
{unsigned long newload;newload = load * exp + active * (FIXED_1 - exp);if (active >= load)newload += FIXED_1-1;return newload / FIXED_1;
}
其中 active 为通过周期统计采样时间内所有 cpu 的可运行任务数量 + 不可中断睡眠任务数量总和 * FIXED_1 得到的新负载,如下:
long calc_load_fold_active(struct rq *this_rq, long adjust)
{long nr_active, delta = 0;// nr_active 统计了当前 cpu 在该周期内的任务数量并累加到 calc_load_tasks 中。// 不采用 for_each_prossble_cpu 来一次性统计的原因是:// 当大型服务器上 cpu 的数量众多,for_each 方式成本过大,所以采用周期统计累加形式。nr_active = this_rq->nr_running - adjust;nr_active += (long)this_rq->nr_uninterruptible;if (nr_active != this_rq->calc_load_active) {delta = nr_active - this_rq->calc_load_active;this_rq->calc_load_active = nr_active;}return delta;
}
上述公式可以这样简单理解:
比如计算 1分钟 的平均负载,假设 old_load 为 1024,当前计算周期内有1个任务可运行和一个任务为不可中断睡眠任务(D 状态任务),那么计算方式如下:
现在的负载 = 旧负载 1024 * 衰减系数(EXP_1/FIXED_1 = 1884/2048) + 2(两个任务)* FIXED_1(2048) * (1 - EXP_1/FIXED_1)
可以看到假设如果只有一个cpu下,并且一直一个任务一直运行,那么平均负载接近 cpu 数量接近为 1,此时可以说 cpu 繁忙。
因此随着 cpu 数量的增多,平均负载繁忙的指标也会增高,并且随着负载衰减,在一个 8 核系统上,1 分钟平均负载在 5 左右可以说系统处于略微繁忙,如果负载小于 1 可以说系统处于空闲。
相关文章:

linux top命令中 cpu 利用率/mem 使用率与load average平均负载计算方式
文章目录 1 简介2 CPU% 字段3 MEM% 字段4 load average 平均负载 1 简介 top 命令是 Linux 上一个常用的系统监控工具,它经常用来监控 Linux 的系统状态,是常用的性能分析工具,能够显示较全的系统资源信息,包括系统负载ÿ…...
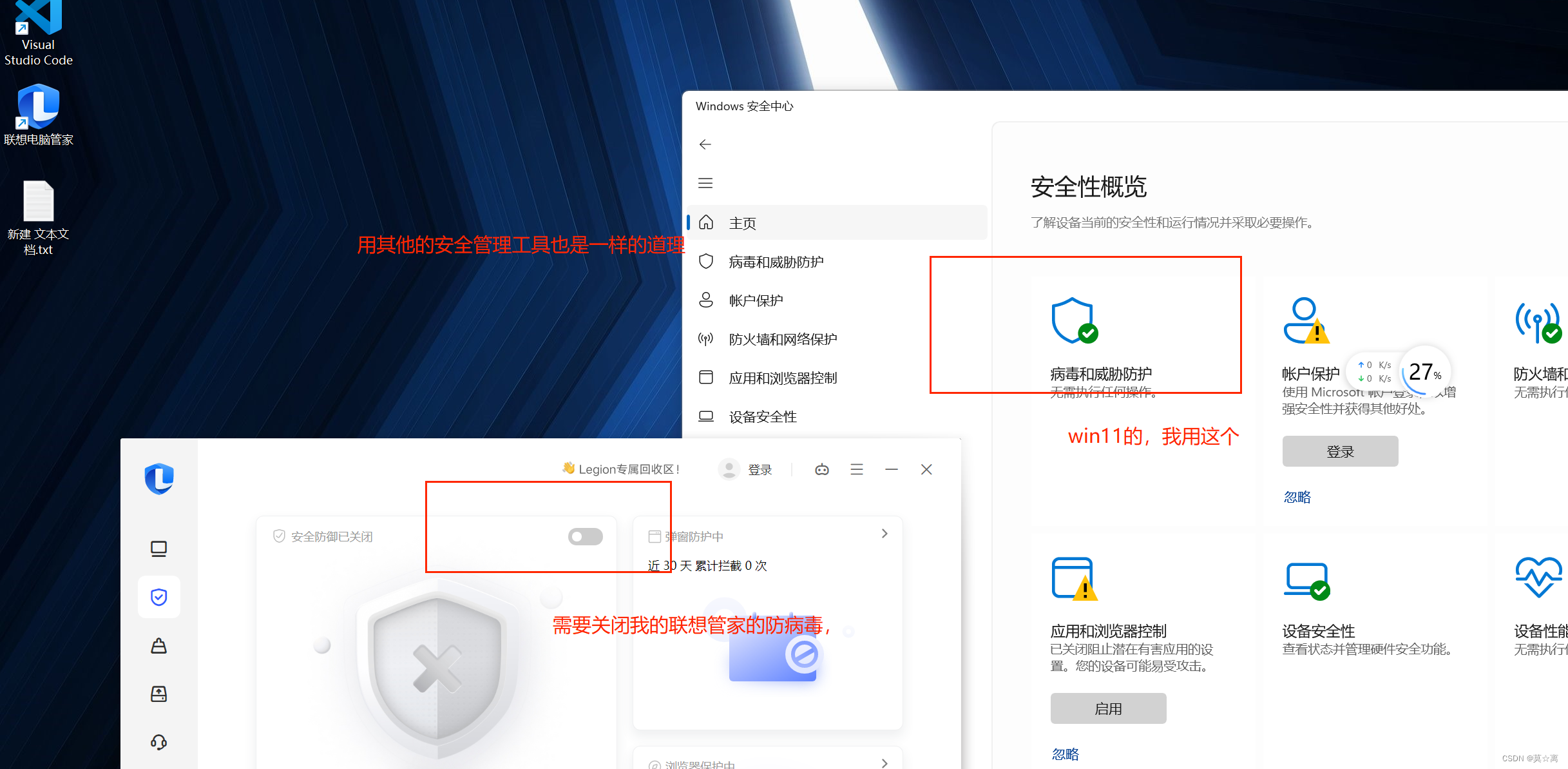
win11出现安全中心空白和IT管理员已限制对某些区域的访问(不一样的解决方式),真实的个人经历,并且解决经过
1、个人的产生问题的经历 2023年12月22日,由于我买了一块电脑的固态硬盘1T,想要扩容,原来电脑自带512G(由于个人是一个程序员,导致512G实在太古鸡肋)装好以后,想要重装一下系统,来个大清理。结果不出意料&…...

关于安卓重启设备和重启应用进程
android 重启应用进程 //多种方式重启应用进程public class MainActivity {//重启当前Applicationprivate void restartApplication(){final Intent intent getPackageManager().getLaunchIntentForPackage(getPackageName());intent.addFlags(Intent.FLAG_ACTIVITY_CLEAR_TOP…...
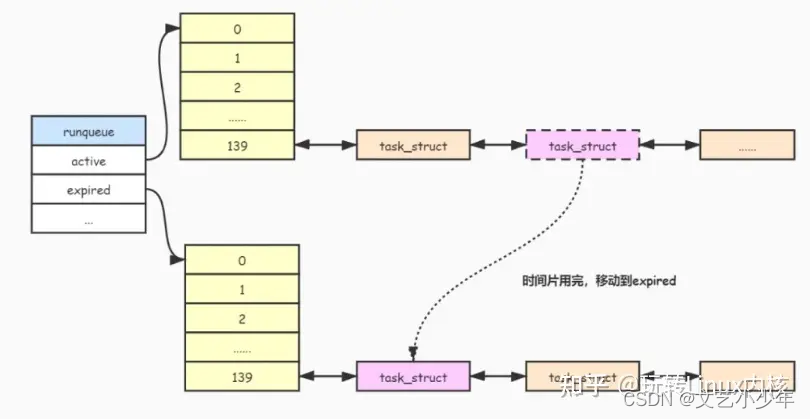
Linux内核--进程管理(十三)O(1)调度算法
目录 一、引言 二、O(1)调度算法原理 ------>2.1、prio_array 结构 ------>2.2、runqueue 结构 三、实时进程调度 四、普通进程调度 ------>4.1、运行时间片计算 五、O(1)调度算法实现 ------>5.1、时钟中断任务调度 ------>5.2、任务调度 一、引言 …...

【QT】发生的运行时错误汇总
1 、QObject::startTimer: Timers cannot be started from another thread 错误原因:QObject是可重入的,它的大多数非GUI子类,例如QTimer, QTcpSocket, QUdpSocket and QProcess都是可重入的,使得这些类可以同时用于多线程。需要…...
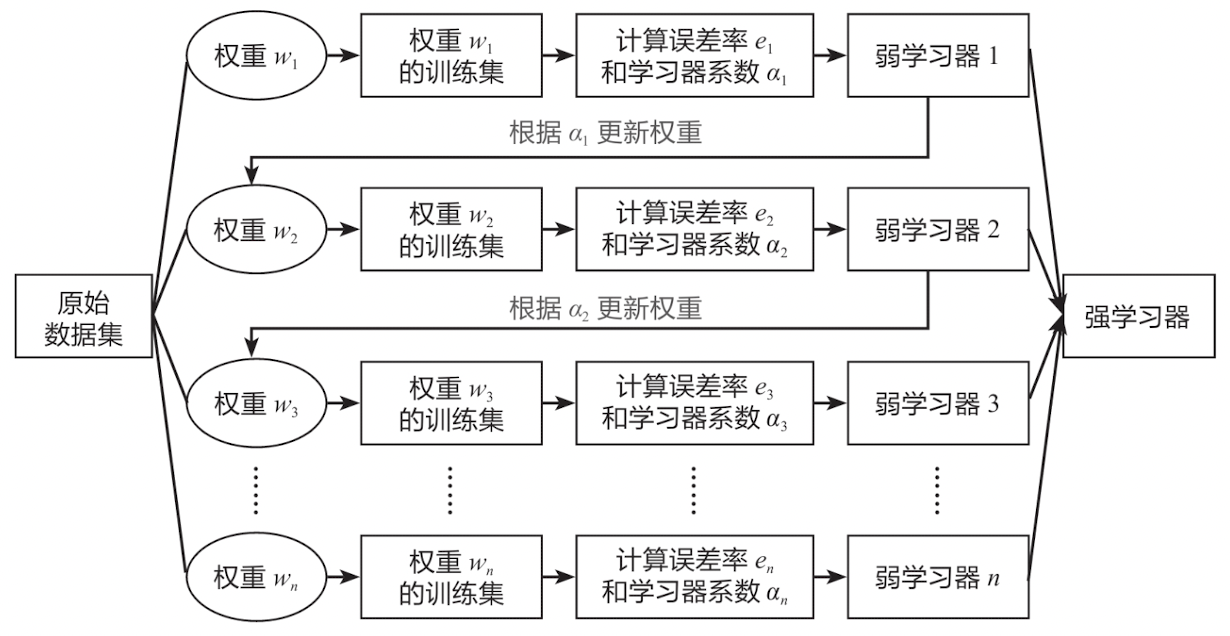
机器学习常用算法模型总结
文章目录 1.基础篇:了解机器学习1.1 什么是机器学习1.2 机器学习的场景1.2.1 模式识别1.2.2 数据挖掘1.2.3 统计学习1.2.4 自然语言处理1.2.5 计算机视觉1.2.6 语音识别 1.3 机器学习与深度学习1.4 机器学习和人工智能1.5 机器学习的数学基础特征值和特征向量的定义…...

笔记中所得(已删减)
1.交流电的一个周期内电压/电流的平均值都为0 2.电动势:电池将单位正电荷由负极搬到正极所做的功 5.额定能量:电池的额定容量乘以标称电压,以Wh为单位 6.500mAh意义是可以以500mA的电流放电1小时 7.电池容量的单位是mAh 13.实际电流源不能串联 14. 15. 16. 17. 18. 19.电…...

在Django5中使用Websocket进行通信
Docker安装Redis docker run --restartalways -p 6379:6379 --name redis -d redis:7.0.12 --requirepass zhangdapeng520安装依赖 参考文档:https://channels.readthedocs.io/en/latest/installation.html pip install "channels[daphne]"展示聊天页…...

外汇天眼:CySEC与NAGA Markets Europe达成15万欧元的和解
塞浦路斯证券交易委员会(CySEC)已经与NAGA Markets Europe达成15万欧元的和解。有关监管决定的会议于2023年3月举行,然而直到今天才公布这个决定。 该和解符合2009年塞浦路斯证券交易委员会法第37(4)条的规定,该条赋予CySEC就任何…...

Docker仓库搭建与镜像推送拉取
1.Docker镜像仓库 搭建镜像仓库可以基于Docker官方提供的DockerRegistry来实现。 官网地址:https://hub.docker.com/_/registry 1.1.简化版镜像仓库 Docker官方的Docker Registry是一个基础版本的Docker镜像仓库,具备仓库管理的完整功能,…...

最适合初学者的PHP集成环境!
如果你是一个php初学者,千万不要为了php的运行环境去浪费时间,这里我给大家推荐一款php的集成环境:phpStudy。它具备了php运行的三要素:php、apache、mysql,当然它具备的功能远不止这些。 phpstudy V8安装步骤 步骤一…...

添加 Android App Links
添加 Android App Links功能 介绍一个简单的效果Android配置Add Url intent filtersAdd logic to handle the intentAssociate website 搭建网页支持AppLinks 介绍 Android App Links 是指将用户直接转到 Android 应用内特定内容的 HTTP 网址。Android App Links 可为您的应用带…...
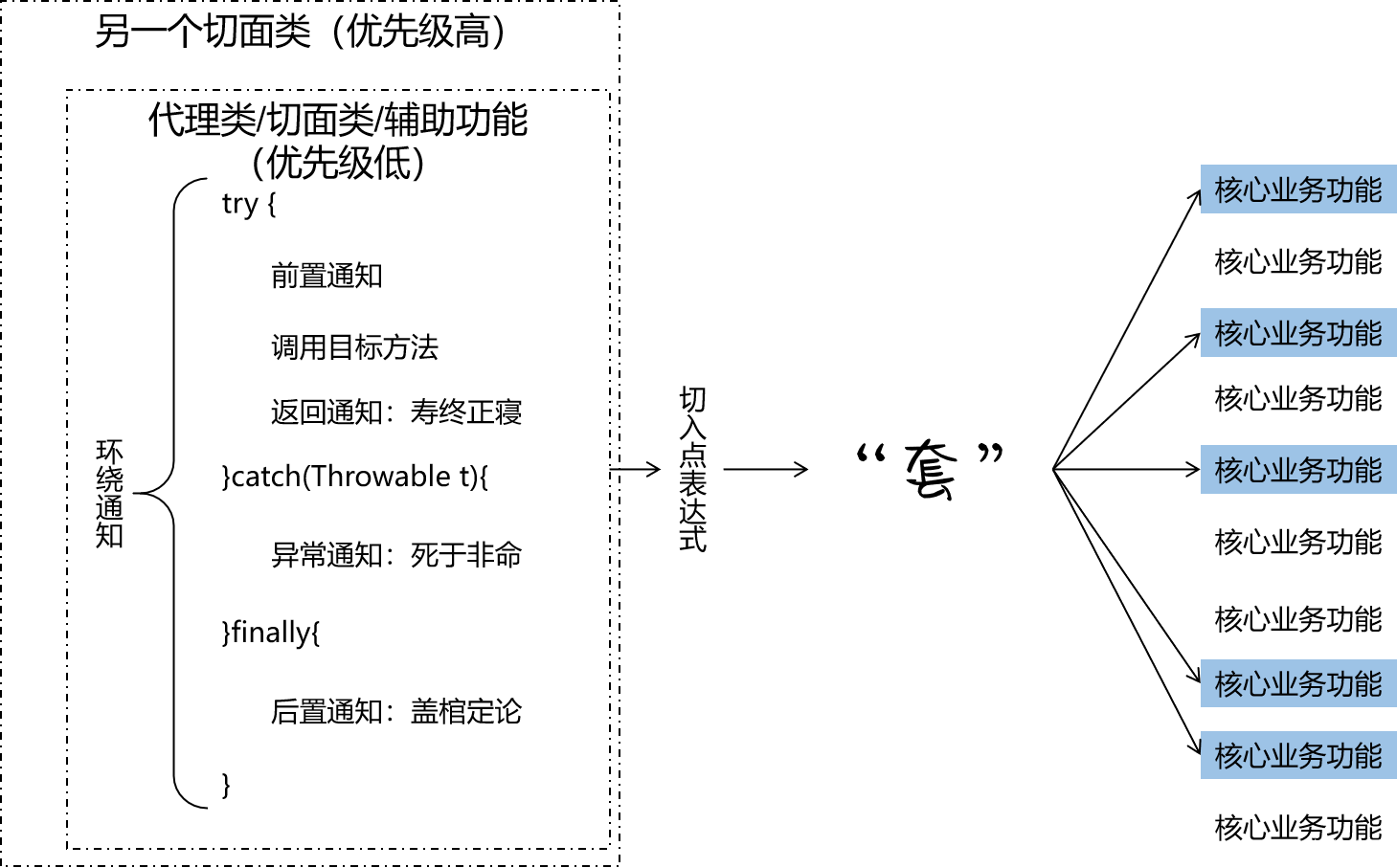
五、Spring AOP面向切面编程(基于注解方式实现和细节)
本章概要 Spring AOP底层技术组成初步实现获取通知细节信息切点表达式语法重用(提取)切点表达式环绕通知切面优先级设置CGLib动态代理生效注解实现小结 5.5.1 Spring AOP 底层技术组成 动态代理(InvocationHandler):…...

ES6 class详解
✨ 专栏介绍 在现代Web开发中,JavaScript已经成为了不可或缺的一部分。它不仅可以为网页增加交互性和动态性,还可以在后端开发中使用Node.js构建高效的服务器端应用程序。作为一种灵活且易学的脚本语言,JavaScript具有广泛的应用场景&#x…...

嵌入式固件加密的几种方式
一、利用id做软件加密 1,如果板子上有外部存储器,可以先编写一个程序,利用算法把id计算得到一些值存入外部存储器,然后再烧写真正的程序,真正的程序去校验外部存储器的数据是否合法即可 2,利用板子上按键组…...
[C#]使用onnxruntime部署Detic检测2万1千种类别的物体
【源码地址】 github地址:https://github.com/facebookresearch/Detic/tree/main 【算法介绍】 Detic论文:https://arxiv.org/abs/2201.02605v3 项目源码:https://github.com/facebookresearch/Detic 在Detic论文中,Detic提到…...
关于Spring @Transactional事务传播机制详解
Spring事务传播机制 1.什么是事务传播机制?2.Spring事务传播类型Propagation介绍3.具体案例总结 Spring事务传播机制 1.什么是事务传播机制? 举个栗子,方法A是一个事务的方法,方法A执行过程中调用了方法B,那么方法B有…...

力扣139.单词拆分
思路:动态规划,设dp[]记录当前字符能不能通过字典里的单词到达,双层循环,外层循环遍历字符串每一个字符,内层遍历当前i字符之前的所有以i字符结尾的子串 例如字符串:leetcode i遍历到了t 那么内层循环就…...

Docker 镜像命令总汇
目录 1、查看镜像列表 2、搜索镜像 3、拉取镜像 4、删除镜像 5、显示镜像详细信息 6、显示镜像历史 7、导出镜像 8、导入镜像 9、清理未使用的镜像 10、强制删除镜像 1、查看镜像列表 docker images 这个命令列出了你系统中的所有 Docker 镜像,包括镜像名…...

客户服务:助力企业抵御经济衰退的关键要素与策略
目前经济仍悬而未决是否陷入衰退。当前情况下,尽管通胀率高企,消费者支出良好,就业率也在上升,表明就业市场强劲。然而,有人认为衰退可能会在2024年第一季度发生。经济环境的不确定性可能会让人望而却步,但…...

对比按需调用与Token Plan套餐的实际支出感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按需调用与Token Plan套餐的实际支出感受 对于个人开发者或小型团队而言,在大模型API的日常使用中,成本…...
)
AI全领域热点速递(2026年5月11日)
💌 关心家人,从每日报平安开始。万年历提醒微信小程序,您值得体验。📰 每日整理AI领域核心动态,精选有价值资讯,精简可读,适合收藏备查。🤖 AI全领域热点速递(2026年5月1…...

Cangaroo:开源CAN总线分析软件架构解析与深度优化指南
Cangaroo:开源CAN总线分析软件架构解析与深度优化指南 【免费下载链接】cangaroo Open source can bus analyzer software - with support for CANable / CANable2, CANFD, and other new features 项目地址: https://gitcode.com/gh_mirrors/ca/cangaroo Ca…...

利用Taotoken的多模型能力为AIGC应用构建弹性后备方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken的多模型能力为AIGC应用构建弹性后备方案 对于开发图像生成、文案创作等AIGC应用的团队而言,服务连续性至…...

【Gemini Pro高级功能解锁指南】:20年AI工程师亲测的5个隐藏技巧,90%开发者至今未用
更多请点击: https://intelliparadigm.com 第一章:Gemini Pro高级功能解锁指南 Gemini Pro 作为 Google 推出的高性能多模态大模型,其高级功能远超基础文本生成。通过官方 API 与 SDK 的深度集成,开发者可启用结构化输出、多轮上…...

为什么你的项目需要Remix Icon?3200+免费矢量图标的完整解决方案
为什么你的项目需要Remix Icon?3200免费矢量图标的完整解决方案 【免费下载链接】RemixIcon Open source neutral style icon system 项目地址: https://gitcode.com/gh_mirrors/re/RemixIcon 你是否曾为寻找合适的图标而烦恼?设计界面时图标风格…...

通过API Key管理与审计日志功能增强企业AI应用安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过API Key管理与审计日志功能增强企业AI应用安全 在将大模型能力集成到企业业务流程时,安全与合规是首要考量。直接使…...

React 18 + Vite + Tailwind CSS 构建现代化SaaS落地页实战
1. 项目概述与设计思路最近在做一个保险科技(InsurTech)相关的概念项目,需要为这个名为“Insura”的SaaS平台打造一个现代化的落地页(Landing Page)。这个页面的核心目标很明确:向潜在客户(主要…...

在模型广场根据任务需求与预算快速筛选合适的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场根据任务需求与预算快速筛选合适的大模型 对于开发者而言,面对市场上众多的大模型,如何快速找到…...

清华PPT模板终极指南:从零开始打造专业学术演示
清华PPT模板终极指南:从零开始打造专业学术演示 【免费下载链接】THU-PPT-Theme 清华主题PPT模板 项目地址: https://gitcode.com/gh_mirrors/th/THU-PPT-Theme THU-PPT-Theme是一个专门为清华大学师生和学术工作者设计的PPT模板集合,提供了多种符…...