机器学习:贝叶斯估计在新闻分类任务中的应用
文章摘要
随着互联网的普及和发展,大量的新闻信息涌入我们的生活。然而,这些新闻信息的质量参差不齐,有些甚至包含虚假或误导性的内容。因此,对新闻进行有效的分类和筛选,以便用户能够快速获取真实、有价值的信息,成为了一个重要的课题。在这个背景下,机器学习技术应运而生,其中贝叶斯估计作为一种强大的概率推断方法,在新闻分类任务中发挥着重要作用。
在本篇文章中,使用搜狗实验室提供的新闻数据集,并且通过贝叶斯估计来对整理后的新闻数据集进行分类任务,大体流程如下:1、新闻数据集处理。2、文本分词。3、去停用词。4、构建文本特征。5、基于贝叶斯算法来完成最终的分类任务。
另外,本文除了列出了核心代码外,还给出了可执行代码以及所用到的数据源,具体看附录。
知识准备
1.朴素贝叶斯算法
输入:训练数据,其中
,是第
个样本的第
个特征,
,
是第
个特征可能取的第
个值,;;实例
输出:实例的分类,其中
代表分类的种类有多少。
为了避免极大似然估计中概率值为0的那种情况,这里引入了常数。具体地,条件概率的贝叶斯估计是
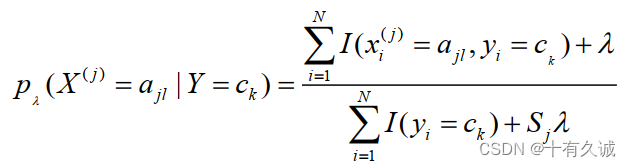
式中。等价于在随机变量各个取值的频数上赋予一个正数
。上式为一种概率分布。取常数
时,这是称为拉普拉斯平滑。显然对任何
,有
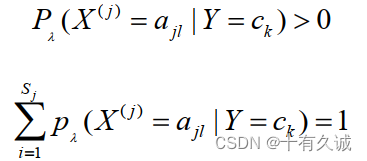
同样,先验概率的贝叶斯估计是

2.停用词(库)
这里我们得先考虑一个问题,一篇文章是什么主题应该是由其内容中的一些关键词来决定的,比如这里的‘车展’,‘跑车’,‘发动机’等,这些词我们一看就知道跟汽车相关的。但是另一类词,‘今天’,‘在’,‘3月份’等,这些词给我们的感觉好像既可以在汽车相关的文章中使用,也可以在其他类型的文章使用,就把它们称作停用词,也就是我们需要过滤的目标。在data文件夹中,给出了多个停用词库,在源码中,我使用了stopwords.txt中停用词。可以通过以下代码来读取停用词。
# 读取停用词库
#如果没有词表,也可以基于词频统计,词频越高的成为停用词的概率就越大
stopwords=pd.read_csv("stopwords.txt",index_col=False,sep="\t",quoting=3,names=['stopword'], encoding='utf-8')
stopwords.head(20)
实验步骤
1.读取数据源
# 给出属性,这里使用的是基于内容来进行分类(加上主题分类会更简单些,这里为了增加难点使用内容分类)
df_news = pd.read_table('./data/data.txt',names=['category','theme','URL','content'],encoding='utf-8')
df_news = df_news.dropna()
#查看前5条新闻
df_news.head()
# df_news.tail() 
输出结果如上图所示
标签解释:
Category:当前新闻所属的类别,一会我们要进行分别任务,这就是标签了。
Theme:新闻的主题,这个咱们先暂时不用,大家在练习的时候也可以把它当作特征。
URL:爬取的界面的链接,方便检验爬取数据是不是完整的,这个咱们暂时也不需要。
Content:新闻的内容,这些就是一篇文章了,里面的内容还是很丰富的。
2.中文分词
#用于保存结果
content_S = []
for line in content:
# line为每一篇文章 current_segment = jieba.lcut(line) #对每一篇文章进行分词 if len(current_segment) > 1 and current_segment != '\r\n': #换行符
# 该篇文章词的个数>1,而且不是简单的换行才保留下来 content_S.append(current_segment) #保存分词的结果 用pandas展示分词结果
df_content=pd.DataFrame({'content_S':content_S}) #专门展示分词后的结果
df_content.head() 前五条新闻分词结果

查看第1000条新闻分词结果
df_content.iloc[1000] ![]()
3.去停用词
def drop_stopwords(contents,stopwords): contents_clean = [] all_words = [] for line in contents: line_clean = [] for word in line: if word in stopwords:
# 如果这个词不在停用词当中,就保留这个词 continue line_clean.append(word) all_words.append(str(word)) contents_clean.append(line_clean) return contents_clean,all_words contents = df_content.content_S.values.tolist()
stopwords = stopwords.stopword.values.tolist()
contents_clean,all_words = drop_stopwords(contents,stopwords) #df_content.content_S.isin(stopwords.stopword)
#df_content=df_content[~df_content.content_S.isin(stopwords.stopword)]
#df_content.head() 用pandas过滤掉停用词的结果
df_content=pd.DataFrame({'contents_clean':contents_clean})
df_content.head() 前五天新闻过滤掉停用词的结果

4.构建文本特征
一些要考虑的问题
这里我们需要到一些问题:
问题1:特征提取要考虑到词与词之间的顺序,而不是只考虑了这个词在这句话当中出现的次数。
问题2:一般语料库的词是非常多的,比如说语料库向量长度4000;那对于每句话,也要有对应的4000维向量,但是里面很多词是没有出现的,所以4000维的向量里面很多值为0,也就是每句话对应的词向量是一个“稀疏向量”。
问题3:同义词也被认为了不同的词,但很多时候同义词在句子的意思是相同的。
用一个例子理解
from sklearn.feature_extraction.text import CountVectorizer
# 拿这四个词作为例子去理解这个计算思路
texts=["dog cat fish","dog cat cat","fish bird", 'bird'] #为了简单期间,这里4句话就当做4篇文章
cv = CountVectorizer() #词频统计
cv_fit=cv.fit_transform(texts) #转换数据 # 获得语料库
print(cv. get_feature_names_out())
# 得到每句话在每个词中出现的次数
print(cv_fit.toarray())
print(cv_fit.toarray().sum(axis=0)) 
取词频大的词
from sklearn.feature_extraction.text import CountVectorizer vec = CountVectorizer(analyzer='word',lowercase = False)
feature = vec.fit_transform(words)
feature.shape
# 结果:(3750, 85093)解释:3750为文章数;85093为语料库;每篇文章对应85093维的向量 只取词频前4000的
from sklearn.feature_extraction.text import CountVectorizer #只统计频率前4000的词,要不每篇文章对应的向量太大了
#这个操作之前需要先过滤掉停用词,要不然这里得到的都是没有意义的停用词了
vec = CountVectorizer(analyzer='word', max_features=4000, lowercase = False)
feature = vec.fit_transform(words)
feature.shape
# 结果:(3750, 4000)解释:3750为文章数,4000为给文章词频最多的数 5.通过贝叶斯预测结果
在贝叶斯模型中,选择了MultinomialNB,这里它额外做了一些平滑处理主要目的就在我们求解先验概率和条件概率的时候避免其值为0。
from sklearn.naive_bayes import MultinomialNB #贝叶斯模型
classifier = MultinomialNB()
# y_train为标签
classifier.fit(feature, y_train)
获得准确率
# 查看测试集的准确率
classifier.score(vec.transform(test_words), y_test)
结果准确率为:0.804参考文献
- 李航。 (2019). 统计学习方法[M]. 北京: 清华大学出版社。
- 凌能祥,&李声闻。 (2014). 数理统计[M]. 北京: 中国科学技术大学出版社。
附录(代码)
本文用到的所有可执行代码和数据源在下面链接给出
Machine_learning: 机器学习用到的方法
相关文章:
机器学习:贝叶斯估计在新闻分类任务中的应用
文章摘要 随着互联网的普及和发展,大量的新闻信息涌入我们的生活。然而,这些新闻信息的质量参差不齐,有些甚至包含虚假或误导性的内容。因此,对新闻进行有效的分类和筛选,以便用户能够快速获取真实、有价值的信息&…...

[C#]基于deskew算法实现图像文本倾斜校正
【算法介绍】 让我们开始讨论Deskeweing算法的一般概念。我们的主要目标是将旋转的图像分成文本块,并确定它们的角度。为了让您详细了解我将使用的方法: 照常-将图像转换为灰度。应用轻微的模糊以减少图像中的噪点。现在,我们的目标是找到带…...

Qt通过pos()获取坐标信息
背景:这是一个QWidget窗体,里面是各种布局的组合,一层套一层。 我希望得到绿色部分的坐标信息(x,y) QPoint get_pos(QWidget* w, QWidget* parent) {if ((QWidget*)w->parent() parent) {return w->pos();}else {QPoint pos(w->po…...

【Webpack】资源输入输出 - 配置资源出口
所有与出口相关的配置都集中在 output对象里 output对象里可以包含数十个配置项,这里介绍几个常用的 filename 顾名思义,filename的作用是控制输出资源的文件名,其形式为字符串,如: module.exports {entry: ./src/a…...

【XR806开发板试用】XR806串口驱动CM32M对小厨宝的控制实验
一.说明 非常感谢基于安谋科技STAR-MC1的全志XR806 Wi-FiBLE开源鸿蒙开发板试用活动,并获得开发板试用。 XR806是全志科技旗下子公司广州芯之联研发设计的一款支持WiFi和BLE的高集成度无线MCU芯片,支持OpenHarmony minisystem和FreeRTOS,具有集成度高、…...

中介者模式-Mediator Pattern-1
如果在一个系统中对象之间的联系呈现为网状结构, 对象之间存在大量的多对多联系,将导致系统非常复杂。 这些对象既会影响别的对象,也会被别的对象所影响。 这些对象称为同事对象,它们之间通过彼此的相互作用实现系统的行为。 在网…...

ASP.NET Core基础之图片文件(一)-WebApi图片文件上传到文件夹
阅读本文你的收获: 了解WebApi项目保存上传图片的三种方式学习在WebApi项目中如何上传图片到指定文件夹中 在ASP.NET Core基础之图片文件(一)-WebApi访问静态图片文章中,学习了如何获取WebApi中的静态图片,本文继续分享如何上传图片。 那么…...

精准掌控 Git 忽略规则:定制化 .gitignore 指南
🧙♂️ 诸位好,吾乃诸葛妙计,编程界之翘楚,代码之大师。算法如流水,逻辑如棋局。 📜 吾之笔记,内含诸般技术之秘诀。吾欲以此笔记,传授编程之道,助汝解技术难题。 &…...

Harmony 开始支持 Flutter ,聊聊 Harmony 和 Flutter 之间的因果
原创作者:恋猫de小郭 相信大家都已经听说过,明年的 Harmony Next 版本将正式剥离 AOSP 支持 ,基于这个话题我已经做过一期问题汇总 ,当时在 现有 App 如何兼容 Harmony Next 问题上提到过: 华为内部也主导适配目前的主…...

k8s 之7大CNI 网络插件
一、介绍 网络架构是Kubernetes中较为复杂、让很多用户头疼的方面之一。Kubernetes网络模型本身对某些特定的网络功能有一定要求,但在实现方面也具有一定的灵活性。因此,业界已有不少不同的网络方案,来满足特定的环境和要求。 CNI意为容器网络…...

stable diffusion 人物高级提示词(一)头部篇
一、女生发型 prompt描述推荐用法Long hair长发一定不要和 high ponytail 一同使用Short hair短发-Curly hair卷发-Straight hair直发-Ponytail马尾high ponytail 高马尾,一定不要和 long hair一起使用,会冲突Pigtails2条辫子-Braid辫子只写braid也会生…...

限制哪些IP能连接postgre
打开C:\Program Files\PostgreSQL\9.4\data\pg_hba.conf 以下代表本机能连,172.16.73.xx都能连(/24就代表最后一位是0-255),如果是172.16.73.11/32那就是限制了172.16.73.11才能连(实际我设置/32是无效的)&…...

可狱可囚的爬虫系列课程 08:新闻数据爬取实战
前言 本篇文章中我带大家针对前面所学 Requests 和 BeautifulSoup4 进行一个实操检验。 相信大家平时或多或少都有看新闻的习惯,那么我们今天所要爬取的网站便是新闻类型的:中国新闻网,我们先来使用爬虫爬取一些具有明显规则或规律的信息&am…...

mysql2pgsql
使用pgloader进行迁移 pgloader是一个强大的数据迁移工具,专为将不同数据库之间的数据迁移到PostgreSQL而设计。它支持从MySQL到PostgreSQL的迁移,并提供了一种简单且灵活的方式来转移数据。 安装pgloader 使用pgloader迁移数据 1、命令行方式 2、脚…...
设计模式-流接口模式
设计模式专栏 模式介绍模式特点应用场景流接口模式和工厂模式的区别代码示例Java实现流接口模式Python实现流接口模式 流接口模式在spring中的应用 模式介绍 流接口模式是一种面向对象的编程模式,它可以使代码更具可读性和流畅性。流接口模式的核心思想是采用链式调…...

Java 堆与栈的作用与区别
栈是运行时的单位,而堆是存储的单位,栈解决程序的运行问题,堆解决数据存储的问题。 一个线程对应一个线程栈,栈是运行单位,里面存储的信息都是跟当前线程相关的信息,包括局部变量、程序运行状态、方法返回…...

再谈小米汽车
文章目录 1. 外观2. 电机3. 电池4. 风阻5. 强度6. 智能驾驶 我在两年前分析过小米造车的形势,大家可以 点击这里查看。今天小米官宣传了新汽车。看一下它公布的主要信息: 1. 外观 汽车外观是向保时捷致敬,因此它的外观特别像保时捷。不过外…...
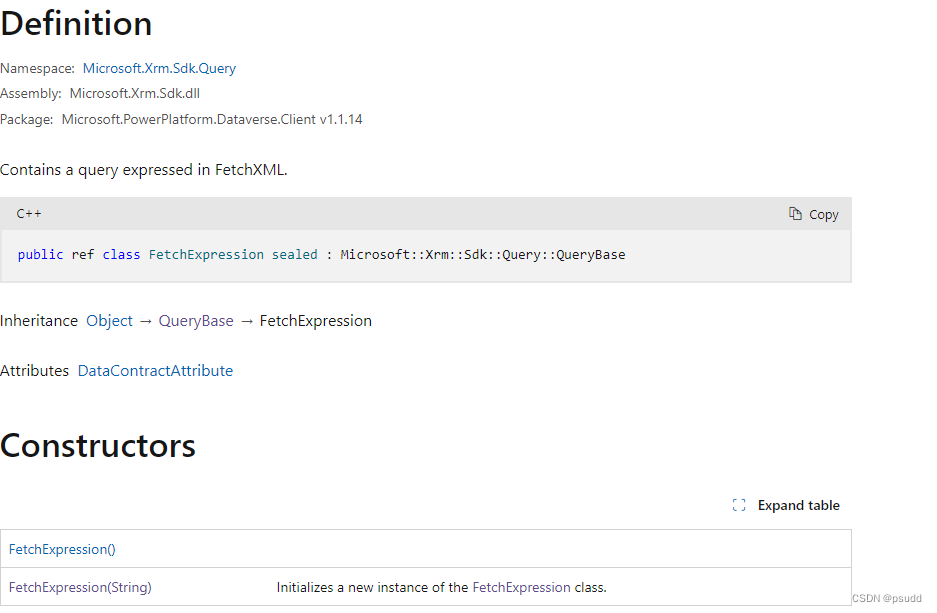
Power Apps 学习笔记 - IOrganizationService Interface
文章目录 1. IOrganization Interface1.1 基本介绍1.2 方法分析 2. Entity对象2.1 Constructor2.2 Properties2.3 Methods 3. 相关方法3.1 单行查询 Retrive3.2 多行查询 RetriveMultiple3.3 增加 Create3.4 删除 Delete3.5 修改 Update 4. 数据查询的不同实现方式4.1 QueryExp…...
)
常见函数的4种类型(js的问题)
• 匿名函数 • 回调函数 • 递归函数 • 构造函数 1、匿名函数 定义时候没有任何变量引用的函数 匿名函数自调:函数只执行一次 (function(a, b){console.log(a b);} )(1, 2);// 等价于 function foo (a, b){console.log(a b); }foo(1, …...
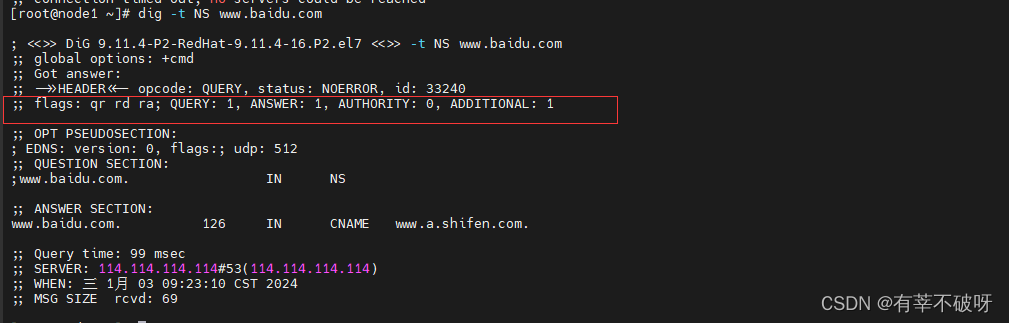
DNS主从服务器、转发(缓存)服务器
一、主从服务器 1、基本含义 DNS辅助服务器是一种容错设计,考虑的是一旦DNS主服务器出现故障或因负载太重无法及时响应客户机请求,辅助服务器将挺身而出为主服务器排忧解难。辅助服务器的区域数据都是从主服务器复制而来,因此辅助服务器的数…...

【Unity3D】从零打造动态天空盒:Cubemap生成与实时环境映射实战
1. 动态天空盒的核心原理与场景价值 第一次在Unity里看到动态天空盒效果时,我盯着屏幕愣了三秒——云层在头顶流动,夕阳的光影实时投射在建筑表面,整个场景瞬间有了生命力。这种魔法般的体验,其实都建立在立方体贴图(C…...

Auto-Photoshop-StableDiffusion-Plugin:在Photoshop中无缝集成AI图像生成的技术实现方案
Auto-Photoshop-StableDiffusion-Plugin:在Photoshop中无缝集成AI图像生成的技术实现方案 【免费下载链接】Auto-Photoshop-StableDiffusion-Plugin A user-friendly plug-in that makes it easy to generate stable diffusion images inside Photoshop using eithe…...

Tailwind CSS在Vue3+Vite项目中的实战应用:从零到响应式按钮
Tailwind CSS在Vue3Vite项目中的实战应用:从零到响应式按钮 如果你正在使用Vue3和Vite构建现代Web应用,却对传统CSS的维护成本感到头疼,那么Tailwind CSS可能会成为你的新宠。这个实用优先的CSS框架彻底改变了我们编写样式的方式——不再需要…...

HackRF玩家必备:PortaPack H2固件刷写与Mayhem固件配置全攻略
HackRF玩家进阶指南:PortaPack H2固件刷写与Mayhem实战配置 无线电爱好者们对HackRF的探索从未停止,而PortaPack H2扩展板的出现让这款开源SDR设备真正实现了"口袋实验室"的愿景。不同于市面上简单的使用说明,本文将带你深入理解Po…...

虚幻引擎C++实战:用TSharedPtr管理资源时90%人会犯的3个内存错误
虚幻引擎C实战:用TSharedPtr管理资源时90%人会犯的3个内存错误 在虚幻引擎的C开发中,智能指针系统是资源管理的核心工具之一。TSharedPtr作为UE提供的引用计数智能指针,其设计初衷是为了简化内存管理,但实际开发中却常常成为内存泄…...

新手避坑指南:安捷伦/是德示波器探头选1MΩ还是50Ω?实测对比告诉你差别有多大
示波器探头阻抗选择实战手册:1MΩ与50Ω的黄金法则 第一次接触示波器时,我犯了个低级错误——用1MΩ探头直接测量射频电路,结果不仅波形畸变成锯齿状,还差点烧毁前端放大器。这个价值3000元的教训让我深刻认识到:探头…...

5分钟集成Android条码扫描:Barcode Scanner库完全指南
5分钟集成Android条码扫描:Barcode Scanner库完全指南 【免费下载链接】barcodescanner Barcode Scanner Libraries for Android 项目地址: https://gitcode.com/gh_mirrors/ba/barcodescanner 在移动应用开发中,条码扫描功能已成为许多应用的核心…...

5个痛点解决:ComfyUI-KJNodes让工作流效率提升60%的实战指南
5个痛点解决:ComfyUI-KJNodes让工作流效率提升60%的实战指南 【免费下载链接】ComfyUI-KJNodes Various custom nodes for ComfyUI 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-KJNodes ComfyUI-KJNodes是一套功能强大的ComfyUI自定义节点集合&…...

推荐系统优化秘籍:如何用Metric Learning解决冷启动问题?
推荐系统优化秘籍:如何用Metric Learning解决冷启动问题? 在推荐系统领域,冷启动问题一直是困扰算法工程师和产品经理的核心挑战之一。新用户缺乏历史行为数据,新商品没有足够的曝光记录,传统协同过滤方法在这些场景下…...

嵌入式开发必备:rootfs.img镜像修改的5个常见问题与解决方案
嵌入式开发实战:rootfs.img镜像修改的五大核心问题与深度解决方案 在嵌入式Linux开发中,rootfs.img镜像的修改是每个开发者绕不开的关键环节。无论是添加自定义配置文件、更新系统组件,还是优化启动流程,对根文件系统的调整都直接…...