爬取豆瓣电影top250的电影名称(完整代码与解释)
在爬取豆瓣电影top250的电影名称之前,需要在安装两个第三方库requests和bs4,方法是在终端输入:
pip install requestspip install bs4
截几张关键性图片:


豆瓣top250电影网页
运行结果
测试html文件标签的各个方法的作用:
# import requests# response = requests.get("https://movie.douban.com/top250")# print(response)import requests
#引入模块 requestsfrom bs4 import BeautifulSoup
# 从模块bs4中引入类 BeautifulSoup
# beautifulsoup4 是一个可以从HTML,XML文件中提取数据的库
# beautifulsoup:是一个解析器,可以特定的解析出内容,省去了我们编写正则表达式的麻烦。headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0"
}# User-Agent:它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本,浏览器及版本等信息,在做爬虫时加上此信息,
# 可以伪装成浏览器;如果不加很可能被识别出为爬虫# 由于豆瓣不对程序进行回应,故要伪装成浏览器进行请求,方法是在浏览器中随便打开一个网页,右击鼠标,点击
# 检查,出现页面后,刷新一下网页,随便点击一个请求报文,查看"User-Agent":后面的信息,并且复制该信息到
# headers中的"User-Agent":后,这就可以伪装成浏览器发送的请求response = requests.get(f"https://movie.douban.com/top250", headers = headers)# requests的get方法返回的是一个包含服务器资源的Response对象,包含了从服务器返回的所有的相关资源。
# response响应的属性:
# response.status_code 响应的状态码
# response.headers:响应头信息
# response.encoding 编码格式信息
# response.cookies cookies信息
# response.url 响应的url信息
# response.text 文本类型,通常是html文本
# response.content bytes型也就是二级制数据,如图片/视频/音频等print(response)
print(response.status_code)#print(response.text)html = response.text
soup = BeautifulSoup(html, "html.parser")
# soup=beautifulsoup(解析内容,解析器)
# 常用解析器:html.parser,lxml,Xml,html5lib# [BeautifulSoup默认支持Pythonl的标准HTML解析库,但是它也支持一些第三方的解析库:如图]
# (https://s2.51cto.com/images/blog/202104/05/d369a62192f243f59879d10173b68e86.png?x-oss-process=image/format,webp)all_titles = soup.find_all("span", attrs = {"class" : "title"})
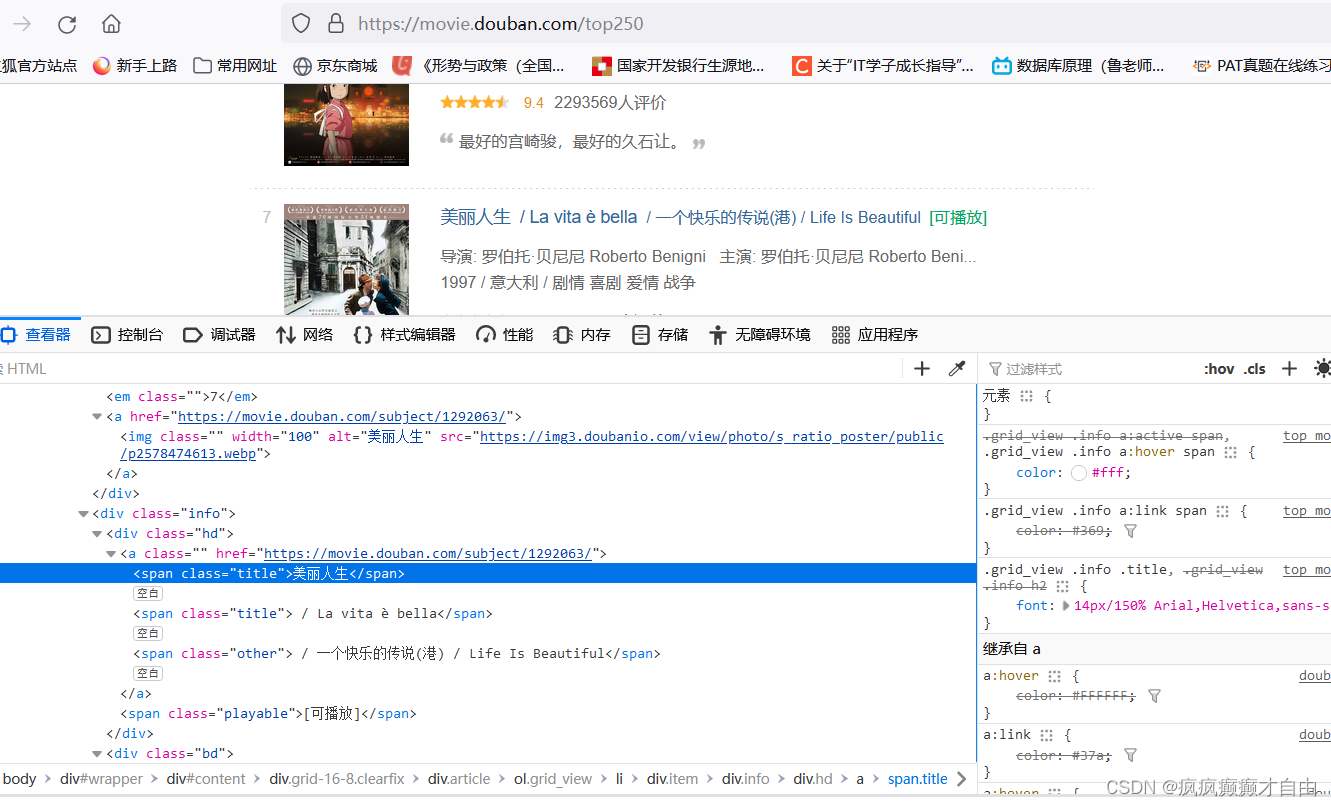
# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title";# 使用find和find_all方式
# find(name,attrs,recursive,text,**kwargs)
# 根据参数来找出对应的标签,但只返回第一个符合条件的结果。
# find_all(name, attrs, recursive, text, **kwargs)
# 根据参数来找出对应的标签,但只返回所有符合条件的结果。
# BeautifulSoup对象的find_all()方法返回的是一个由匹配的标签元素组成的列表。如果没有匹配的元素,返回一个空列表# 筛选条件参数介绍:
# name:为标签名,根据标签名来筛选标签
# attrs:为属性,根据属性键值对来筛选标签,赋值方式可以为:属性名=值,attrs={属性名:值}(但由于class是python关键字,需要使用class_)
# text:为文本内容,根据指定文本内容来筛选出标签,单独使用text作为筛选条件,只会返回text,所以一般与其他条件配合使用.
# recursive:指定筛选是否递归,当为Falsel时,不会在子结点的后代结点中查找,只会查找子结点。cnt = 0;
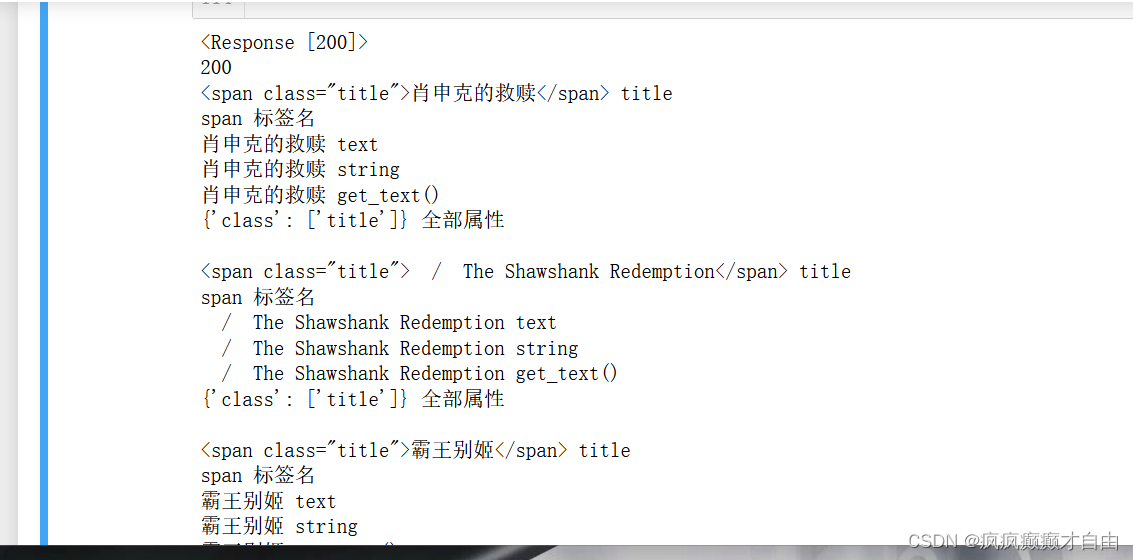
for title in all_titles:print(title, "title")print(title.name, "标签名")print(title.text, "text")print(title.string, "string")print(title.get_text(), "get_text()")print(title.attrs, "全部属性")print("")title_string = title.stringcnt += 1if(cnt >= 3):break#由于all_titles 是find_all的返回内容,他是一个列表,列表中的每个元素就是html文件中的一行,就相当于一个标签# 一.使用标签名查找# 1)使用标签名来获取结点:
# Soup.标签名# 2)使用标签名来获取结点标签名(这个重点是name,主要用于非标签名式筛选时,获取结果的标签名):
# soup.标签.name# 3)使用标签名来获取结点属性:
# soup.标签.attrs(获取全部属性)
# soup.标签.attrs[属性名](获取指定属性)
# soup.标签[属性名](获取指定属性)
# soup.标签.get(属性名)# 二.使用标签名来获取结点的文本内容:
# soup.标签.text
# soup.标签.string
# soup.标签.get text()# if "/" not in title_string:
# print(title_string)# 由于我们只想要电影中文名,所以我们将不符合条件的字符串不打印出来,
# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title",不难发现,就在中文电影名的下面有一个原版的
# 电影名,或者英文,或者其他国家的语言,但是我们不想要,再仔细观察会发现原版电影名前有一个字符 '/',而中文电影名没有字符'/';
# 所以可以用一个if 语句判断是否打印字符;二。爬取豆瓣电影top250的电影名称完整代码与解析:
解释全在代码中:
import requests
#引入模块 requests
# requests模块作用,发送http请求,获取响应数据from bs4 import BeautifulSoup
# 从模块bs4中引入类 BeautifulSoup
# beautifulsoup4 是一个可以从HTML,XML文件中提取数据的库
# beautifulsoup:是一个解析器,可以特定的解析出内容,省去了我们编写正则表达式的麻烦。headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:121.0) Gecko/20100101 Firefox/121.0"
}# User-Agent:它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本,浏览器及版本等信息,在做爬虫时加上此信息,
# 可以伪装成浏览器;如果不加很可能被识别出为爬虫# 由于豆瓣不对程序进行回应,故要伪装成浏览器进行请求,方法是在浏览器中随便打开一个网页,右击鼠标,点击
# 检查,出现页面后,刷新一下网页,随便点击一个请求报文,查看"User-Agent":后面的信息,并且复制该信息到
# headers中的"User-Agent":后,这就可以伪装成浏览器发送的请求for start_num in range(0, 250, 25):response = requests.get(f"https://movie.douban.com/top250?start={start_num}", headers = headers)# 由于一个页面只展示25个电影,所以要爬取250个电影名字要爬取多个页面,用一个for循环结合range函数便可实现;if(start_num == 0):print(response.status_code, "status_code")print(response.headers, "headers")print(response.encoding, "encoding")print(response.cookies, "cookies")print(response.url, "url")# print(response.text, "text") #text 和 content信息太多,暂时不打印# print(response.content, "content")# requests的get方法返回的是一个包含服务器资源的Response对象,包含了从服务器返回的所有的相关资源。
# response响应的属性:
# response.status_code 响应的状态码
# response.headers:响应头信息
# response.encoding 编码格式信息
# response.cookies cookies信息
# response.url 响应的url信息
# response.text 文本类型,通常是html文本
# response.content bytes型也就是二级制数据,如图片/视频/音频等print(response , "这是什么")#response本身是Response对象,并包含返回状态码,Response对象含有从服务器返回的所有的相关资源。html = response.textsoup = BeautifulSoup(html, "html.parser")
# soup=beautifulsoup(解析内容,解析器)
# 常用解析器:html.parser,lxml,Xml,html5lib# [BeautifulSoup默认支持Pythonl的标准HTML解析库,但是它也支持一些第三方的解析库:如图]
# (https://s2.51cto.com/images/blog/202104/05/d369a62192f243f59879d10173b68e86.png?x-oss-process=image/format,webp)# all_titles = soup.find_all("span", attrs = {"class" : "title"})all_titles = soup.findAll("span", attrs = {"class" : "title"})
#这两句find函数都可行# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title";# 使用find和find_all方式
# find(name,attrs,recursive,text,**kwargs)
# 根据参数来找出对应的标签,但只返回第一个符合条件的结果。
# find_all(name, attrs, recursive, text, **kwargs)
# 根据参数来找出对应的标签,但只返回所有符合条件的结果。
# BeautifulSoup对象的find_all()方法返回的是一个由匹配的标签元素组成的列表。如果没有匹配的元素,返回一个空列表# 筛选条件参数介绍:
# name:为标签名,根据标签名来筛选标签
# attrs:为属性,根据属性键值对来筛选标签,赋值方式可以为:属性名=值,attrs={属性名:值}(但由于class是python关键字,需要使用class_)
# text:为文本内容,根据指定文本内容来筛选出标签,单独使用text作为筛选条件,只会返回text,所以一般与其他条件配合使用.
# recursive:指定筛选是否递归,当为Falsel时,不会在子结点的后代结点中查找,只会查找子结点。for title in all_titles:title_string = title.string # 提取为字符串#由于all_titles 是find_all的返回内容,他是一个列表,列表中的每个元素就是html文件中的一行,就相当于一个标签# 一.使用标签名查找# 1)使用标签名来获取结点:
# Soup.标签名# 2)使用标签名来获取结点标签名(这个重点是name,主要用于非标签名式筛选时,获取结果的标签名):
# soup.标签.name# 3)使用标签名来获取结点属性:
# soup.标签.attrs(获取全部属性)
# soup.标签.attrs[属性名](获取指定属性)
# soup.标签[属性名](获取指定属性)
# soup.标签.get(属性名)# 二.使用标签名来获取结点的文本内容:
# soup.标签.text
# soup.标签.string
# soup.标签.get text()if "/" not in title_string:print(title_string)# 由于我们只想要电影中文名,所以我们将不符合条件的字符串不打印出来,
# 打开https://movie.douban.com/top250页面,右击鼠标点击检查,点击左上角的箭头指标,点击网页中的电影名,可以发现在html文件
# 中对应的电影名被 span标签包裹住了,并且名字前面有一个键值对 "class" = "title",不难发现,就在中文电影名的下面有一个原版的
# 电影名,或者英文,或者其他国家的语言,但是我们不想要,再仔细观察会发现原版电影名前有一个字符 '/',而中文电影名没有字符'/';
# 所以可以用一个if 语句判断是否打印字符;参考文献:
爬虫基础篇_headers = {'user-agent': 'mozilla/5.0 (windows nt -CSDN博客
python爬虫之Beautifulsoup模块用法详解_51CTO博客_python爬虫模块
相关文章:
爬取豆瓣电影top250的电影名称(完整代码与解释)
在爬取豆瓣电影top250的电影名称之前,需要在安装两个第三方库requests和bs4,方法是在终端输入: pip install requestspip install bs4 截几张关键性图片: 豆瓣top250电影网页 运行结果 测试html文件标签的各个方法的作用…...

tidb 集成 flyway 报错 denied to user for table global_variables
报错内容: Caused by: java.sql.SQLException: connection disabled at com.alibaba.druid.pool.DruidPooledConnection.checkStateInternal(DruidPooledConnection.java:1181) at com.alibaba.druid.pool.DruidPooledConnection.checkState(DruidPooledConnection.jav…...

很实用的ChatGPT网站—在线编程模块增补篇
很实用的ChatGPT网站(http://chat-zh.com/)——增补篇 今天介绍一个好兄弟开发的ChatGPT网站,网址[http://chat-zh.com/]。这个网站功能模块很多,包含生活、学习、医疗、法律、经济等很多方面。今天跟大家分享一下,新…...

A股风格因子看板 (2024.01第01期)
该因子看板跟踪A股风格因子,该因子主要解释沪深两市的市场收益、刻画市场风格趋势的系列风格因子,用以分析市场风格切换、组合风格暴 露等。 今日为该因子跟踪第1期,指数组合数据截止日2024-12-01,要点如下 近1年A股风格因子检验统…...

基于gamma矫正的照片亮度调整(python和opencv实现)
import cv2 import numpy as npdef adjust_gamma(image, gamma1.0):invGamma 1.0 / gammatable np.array([((i / 255.0) ** invGamma) * 255 for i in np.arange(0, 256)]).astype("uint8")return cv2.LUT(image, table)# 读取图像 original cv2.imread("tes…...

LeetCode-Java(29)
29. 两数相除 结果肯定落在dividend上,于是对这个区间每一个数进行二分查找,判断方法就是 while (l < r) {long mid l r 1 >> 1;if (mul(mid, y) < x) {l mid;} else {r mid - 1;}} 其中mul是一个要定义的快速乘法。 完整代码如下 …...

腾讯云导入导出镜像官方文档
制作与导出 Linux 镜像 https://cloud.tencent.com/document/product/213/17814 制作与导出 Windows 镜像 https://cloud.tencent.com/document/product/213/17815 云服务器 导出镜像-操作指南-文档中心-腾讯云 (tencent.com) 轻量应用服务器 管理共享镜像-操作指…...

keras 深度学习框架实现 手写数字识别
阅读本文之前,请先参考--------win10搭建keras深度学习框架 安装运行环境 阅读本文之前,请先参考--------keras人工智能框架 MNIST 数据集 随机展示 查看训练图片 完整代码如下图: 在sublimeText中 使用ctrlB运行代码,结果如…...

SELinux策略语法以及示例策略
首发公号:Rand_cs 本文来讲述 SELinux 策略常用的语法,然后解读一下 SELinux 这个项目中给出的示例策略 安全上下文 首先来看一下安全上下文的格式: user : role : type : level每一个主体和客体都有一个安全上下文,通常也称安…...
电路笔记 :自激振荡电路笔记 电弧打火机
三极管相关 三极管的形象描述 二极管 简单求解(理想) 优先导通(理想) 恒压降 稳压管(二极管plus) 基础工作模块 理想稳压管的工作特性 晶体管之三极管(“两个二极管的组合” ) 电弧打火机电路 1.闭合开…...
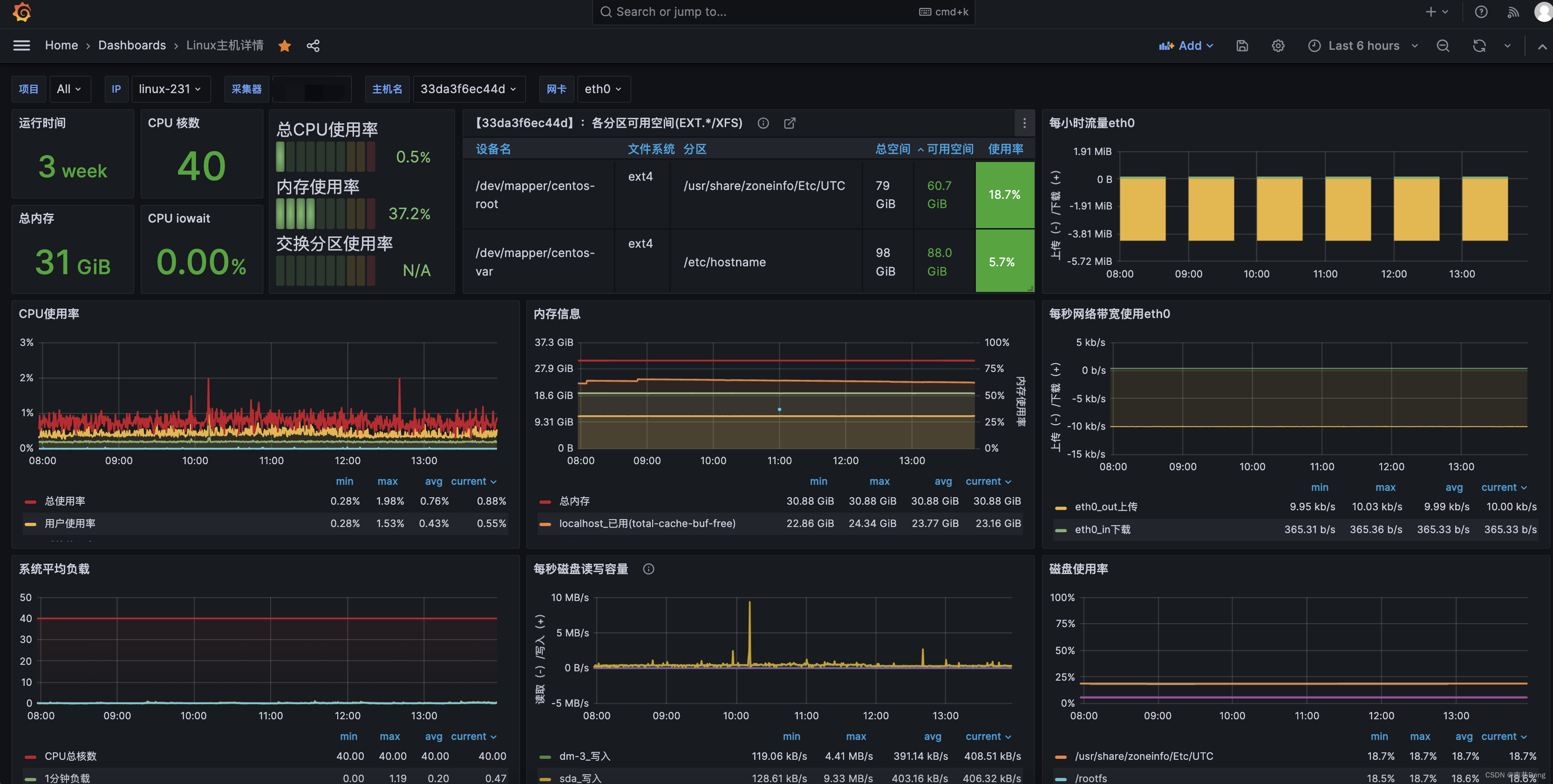
prometheus grafana linux服务器监控
文章目录 前传node-exporter安装配置promethues监控node节点grafana操作查看监控:外传 前传 prometheus grafana的安装使用:https://nanxiang.blog.csdn.net/article/details/135384541 本文说下监控nginx,prometheus grafana linux 安装配…...

有哪些有用的工作技巧?
有效沟通免去麻烦 说起职场的工作技巧,首先不得不提的便是有效沟通。高效的职场沟通不仅能显著提高工作效率,通过清晰准确地传递信息,减少误解和错误,还能促进团队间的紧密合作,建立起相互信任和理解的环境。在面临挑…...
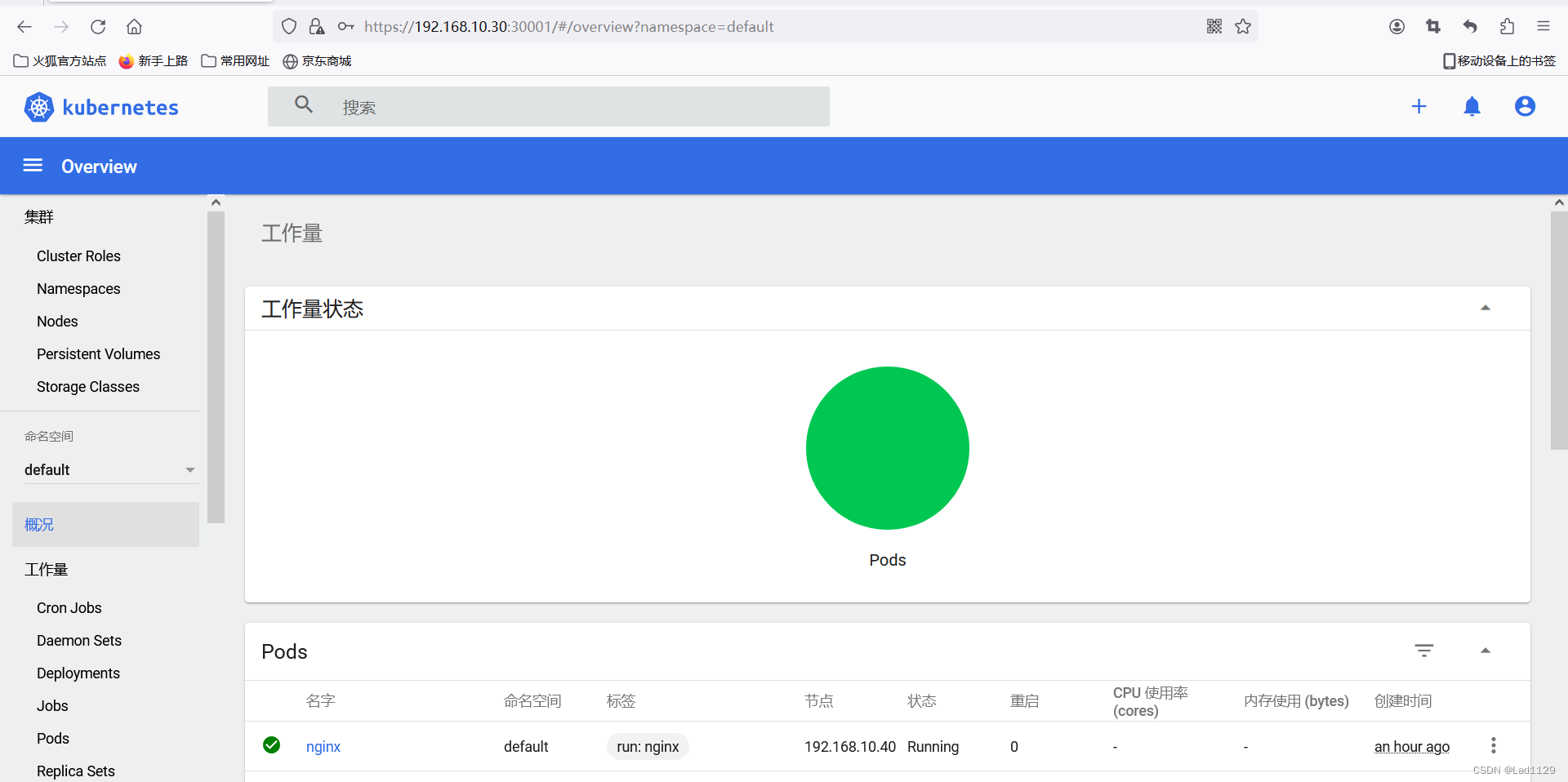
k8s的网络类型
部署 CNI 网络组件 部署 flannel K8S 中 Pod 网络通信: Pod 内容器与容器之间的通信 在同一个 Pod 内的容器(Pod 内的容器是不会跨宿主机的)共享同一个网络命名空间, 相当于它们在同一台机器上一样,可以用 localho…...

《元宇宙2086》团队发布AI创作的元宇宙之歌
《元宇宙2086》团队发布AI创作的元宇宙之歌 数字科技领域著名IP——《元宇宙2086》的团队发布AI创作的《元宇宙之歌》,歌词是AI与人共同完成,作曲、混音、人声合成全部由AI完成并且演唱,歌曲描绘了未来的元宇宙世界。 “踏入元宇宙的奇境&am…...

【数据结构】数组实现队列(详细版)
目录 队列的定义 普通顺序队列的劣势——与链队列相比 顺序队列实现方法: 一、动态增长队列 1、初始化队列 2、元素入队 3、判断队列是否为空 4、元素出队 5、获取队首元素 6、获取队尾元素 7、获取队列元素个数 8、销毁队列 总结: 动态增长队列…...
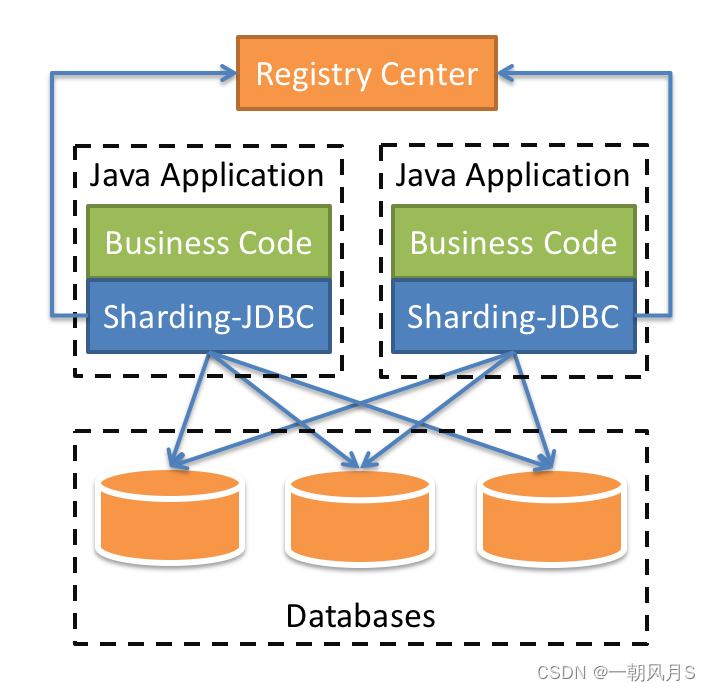
Sharding-JDBC快速使用【笔记】
1 引言 最近在使用Sharding-JDBC实现项目中数据分片、读写分离需求,参考官方文档(Sharding官方文档)感觉内容庞杂不够有条理,重复内容比较多;现结合项目应用整理笔记如下供大家参考和自己回忆使用; 在…...

总结MySQL 的一些知识点:MySQL 排序
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

Linux中经常使用的相关命令
查看硬盘存储容量使用情况: df -lh 列出 /bin 目录中的 5 个最大文件: ls -lSh /bin | head -5 删除文件和文件夹 在Linux中,要删除文件的命令是rm。你可以使用以下命令来删除一个文件: rm file_name如果要删除多个文件,可…...

2022-2023年度广东省职业院校学生专业技能大赛“软件测试”赛项性能测试题目-Jmeter
性能测试-JM 1、脚本添加: 脚本文件名称:SuppAndComp,测试计划名称:SuppAndComp。测试计划下添加两个线程组: (1)线程组一操作内容:系统管理员登录、进行新增供应商操作。 线程组名称SuppAdd。具体要求如下: 登录操作存放到仅一次控制器中,供应商名称前4位为固定…...
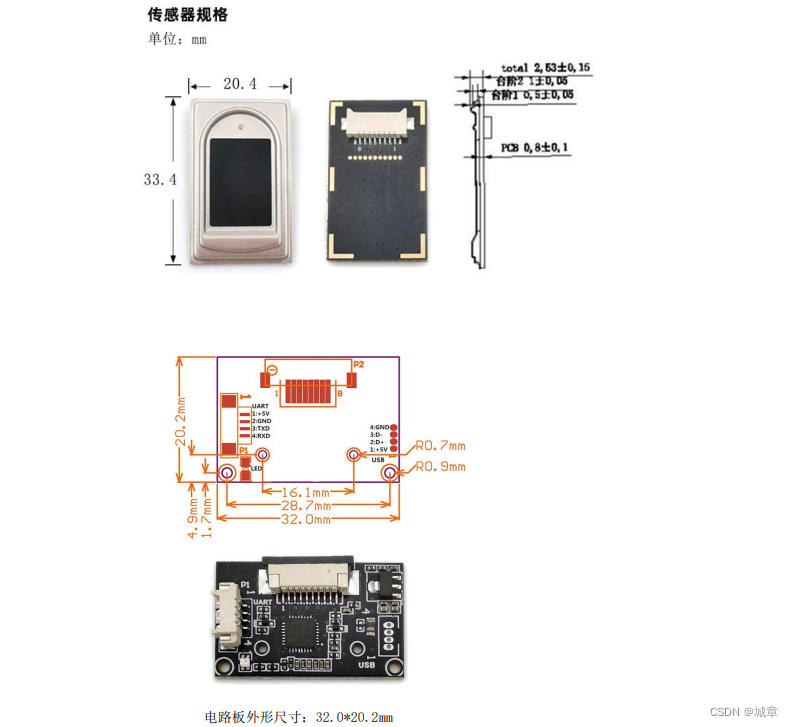
R304S 指纹识别模块的硬件接口说明
一.外部接口尺寸图 二.串行通讯 R304S 指纹模块通讯接口定义: 引脚号名称定义描述15V电源输入电源正输入端 DC 4.2--6V2GND电源和信号地电源和信号地3TXD数据发送串行数据输出,TTL 逻辑电平4RXD数据接收串行数据输入,TTL 逻辑电平 三.USB通…...

AI Agent安全扫描:基于MCP协议构建实时防护中间件
1. 项目概述:一个为AI智能体打造的“安全扫描仪”最近在折腾AI Agent(智能体)的开发,尤其是在尝试将多个不同功能的Agent串联起来,构建一个能自主完成复杂任务的系统时,遇到一个很实际的问题:如…...
交易活跃度升温)
粮食安全政策托底,农业ETF(562900.SH)交易活跃度升温
5月14日,A股农业板块迎来温和上行,易方达农业ETF(562900.SH)收报0.756元,涨幅0.93%,跑赢跟踪标的中证现代农业指数0.85%的涨幅。数据显示,该ETF当日量比为1.13,换手率达9.54%&#x…...

英雄联盟智能助手:3分钟上手,让你的游戏体验提升300%
英雄联盟智能助手:3分钟上手,让你的游戏体验提升300% 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄选择犹…...

从‘听个响’到‘看出门道’:手把手教你用S-TOOLS 4.0分析WAV音频的隐写容量与波形变化
从‘听个响’到‘看出门道’:手把手教你用S-TOOLS 4.0分析WAV音频的隐写容量与波形变化 在数字信息时代,音频文件不仅是声音的载体,更可能成为隐藏秘密信息的"数字信封"。想象一下,你收到一段看似普通的音乐文件&#x…...

2010-2024年省级农村居⺠消费价格指数
本数据为国家统计局编制的官方统计数据,具体编制方法参考国家统计局CPI调查方案及《中国统计年鉴》。农村居民消费价格指数(Consumer Price Index for Rural Residents,简称农村CPI)是综合反映农村居民家庭所购买的生活消费品价格…...

AI编程伴侣:基于LLM的IDE集成开发助手设计与实战
1. 项目概述:一个为开发者定制的AI编程伴侣如果你是一名开发者,每天在IDE里敲代码的时间超过8小时,那你一定对“上下文切换”带来的效率损耗深有体会。你正全神贯注地写一个复杂的业务逻辑,突然需要查一个API的用法,于…...

【C++】C/C++ 内存管理从入门到进阶
【相关题目】 代码语言:javascript AI代码解释 int globalVar 1;static int staticGlobalVar 1;void Test(){static int staticVar 1;int localVar 1;int num1[10] {1, 2, 3, 4};char char2[] "abcd";const char* pChar3 "abcd";int*…...

Topit:为什么你的Mac需要这个窗口置顶神器?
Topit:为什么你的Mac需要这个窗口置顶神器? 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 你是否曾经在写代码时需要参考API文档&#…...

NotebookLM企业许可陷阱全解析,合同里没写的5个自动续费条款正在吞噬你的IT预算
更多请点击: https://intelliparadigm.com 第一章:NotebookLM定价性价比分析 NotebookLM 是 Google 推出的面向研究与知识整合的 AI 笔记工具,其核心价值在于对用户上传文档(PDF、TXT 等)进行语义理解并生成上下文精准…...

Go语言内存键值存储引擎MemVault:轻量级缓存与状态管理实践
1. 项目概述:一个轻量级的内存键值存储引擎最近在折腾一些需要快速读写中间数据的项目,比如实时排行榜、会话缓存,或者是一些临时的配置管理。用 Redis 吧,感觉有点“杀鸡用牛刀”,尤其是在一些资源受限的边缘计算或者…...