机器学习(四) -- 模型评估(2)
系列文章目录
机器学习(一) -- 概述
机器学习(二) -- 数据预处理(1-3)
机器学习(三) -- 特征工程(1-2)
机器学习(四) -- 模型评估(1-4)
未完待续……
目录
系列文章目录
前言
三、分类模型评估指标
1、错误率与精度
2、查准率(精确率)、查全率(召回率)与F1值(F1_score)
2.1、混淆矩阵(confusion matrix)
2.2、查准率(precision,精确率)
2.3、查全率(recall,召回率)
2.4、P-R图
2.5、F1值(F1_score)
2.6、其他
3、ROC与AUC
4、分类报告
机器学习(四) -- 模型评估(1)
前言
tips:这里只是总结,不是教程哈。
“***”开头的是给好奇心重的宝宝看的,其实不太重要可以跳过。
此处以下所有内容均为暂定,因为我还没找到一个好的,让小白(我自己)也能容易理解(更系统、嗯应该是宏观)的讲解顺序与方式。
第一文主要简述了一下机器学习大致有哪些东西(当然远远不止这些),对大体框架有了一定了解。接着我们根据机器学习的流程一步步来学习吧,掐掉其他不太用得上我们的步骤,精练起来就4步(数据预处理,特征工程,训练模型,模型评估),其中训练模型则是我们的重头戏,基本上所有算法也都是这一步,so,这个最后写,先把其他三个讲了,然后,在结合这三步来进行算法的学习,兴许会好点(个人拙见)。
衡量模型泛化能力的评价标准就是性能度量(模型评估指标、模型评价标准),而针对不同的任务有不同的评价指标。按照数据集的目标值不同,可以把模型评估分为分类模型评估、回归模型评估和聚类模型评估。
三、分类模型评估指标
错误率与精度(准确率)、混淆矩阵、查准率(精确率)、查全率(召回率)与F1值(F1_score)、PR曲线、ROC与AUC
1、错误率与精度
概述里面就说过了,这是分类任务中最常用的两种性能度量。
错误率(error rate):分类错误的样本数/样本总数
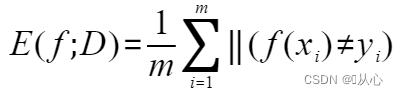
(公式还是要知道的,Ⅱ(*)是指示函数,在*为真(假)时取值为1(0))
精度(accuracy):1-错误率=分类正确的样本数/样本总数
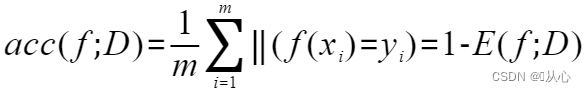
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split# 引入数据集
iris = load_iris()# 划分数据集以及模型训练
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=134)# 模型训练
model = DecisionTreeClassifier()
model.fit(x_train, y_train)
模型训练那一部分可以先不用管,我们现在主要是了解性能度量。
from sklearn.metrics import accuracy_score
# 精度
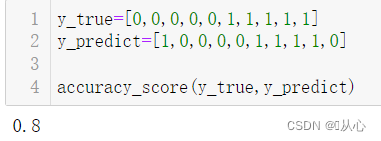
accuracy_score(y_test, model.predict(x_test)) 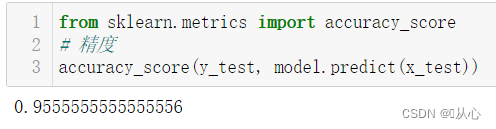
为了更形象一点,我们直接使用自制数据。
2、查准率(精确率)、查全率(召回率)与F1值(F1_score)
2.1、混淆矩阵(confusion matrix)
混淆矩阵是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。如下是一个二分类问题结果的混淆矩阵。
| 真实情况 | 预测结果 | |
|---|---|---|
| P(正例) | N(反例) | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
预测结果是我们看到的,也就是经过模型计算出来的结果,TP+FP+TN+FN=样例总数。
API:
from sklearn.metrics import confusion_matrix还是用刚才的自制数据来看哈,就很明了了。

三分类问题在用混淆矩阵时,得到的是一个 3 X 3 的矩阵。此时预测结果和真实情况不再以正例、反例命名,而是数据集真实的分类结果。用鸢尾花结果来看。

2.2、查准率(precision,精确率)
分类正确的正样本个数占预测结果为正的样本个数的比例。
API:
from sklearn.metrics import precision_score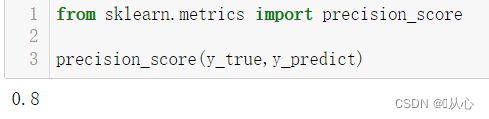
2.3、查全率(recall,召回率)
分类正确的正样本个数占真实值为正的样本个数的比例。
API:
from sklearn.metrics import recall_score
!!!注意:precision_score 和 recall_score 方法默认用来计算二分类问题,若要计算多分类问题,则需要设置 average 参数。
average:评价值的平均值的计算方式。
可以接收[None, 'binary' (default), 'micro', 'macro', 'weighted']
'micro', 'macro':微和宏,下面会说到。
' weighted ' : 相当于类间带权重。各类别的P × 该类别的样本数量(实际值而非预测值)/ 样本总数量
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
2.4、P-R图
( P-R 曲线只能用于二分类问题)以查准率为纵轴、查全率为横轴作图,就得到查准率-查全率曲线,简称“P-R 曲线”,显示该曲线的图称为“P-R”图。
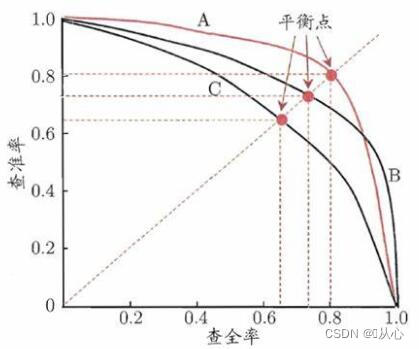
若一个学习器的 P-R 曲线被另一个学习器的 P-R 曲线完全“包住”,则可断言后者的性能优于前者。
若两个学习器的 P-R 曲线发生了交叉,例如学习器 A 与 B,则难以一般性地断言两者孰优孰劣,只能在具体的查准率或查全率条件下进行比较。
平衡点(Break-Even Point,简称 BEP):查准率=查全率时的取值。综合考虑查准率、查全率的性能度量,基于该方法则可断言学习器 A 优于学习器 B。
2.5、F1值(F1_score)
F1值是基于查准率与查全率的调和平均(harmonic mean)定义的:
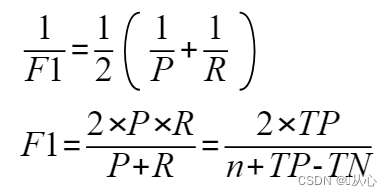
n为样例总数。
在一些应用中,对查准率和查全率的重视程度有所不同,会相应地添加权重。
Fβ则是加权调和平均定义:

其中β>0 度量了查全率对查准率的相对重要性。
β=1时退化为标准的 F1;
β>1 时查全率有更大影响;
β<1 时查准率有更大影响。
API
from sklearn.metrics import f1_score
from sklearn.metrics import fbeta_scorefrom sklearn.metrics import f1_scoref1_score(y_true,y_predict)from sklearn.metrics import fbeta_scoreprint(fbeta_score(y_test, model.predict(x_test), beta=1, average='weighted'))# 查全率有更大影响
print(fbeta_score(y_test, model.predict(x_test), beta=2, average='weighted'))# 查准率有更大影响
print(fbeta_score(y_test, model.predict(x_test), beta=0.5, average='weighted'))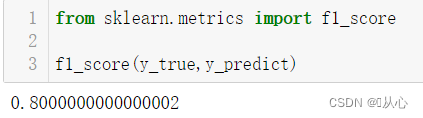

2.6、其他
很多时候我们有多个二分类混淆矩阵,需要进行多次训练/测试,每次得到一个混淆矩阵;或是在多个数据集上进行训练/测试,希望估计算法的“全局”性能,甚或是执行多分类任务,每两两类别的组合都对应一个混淆矩阵。总之,希望在 n 个二分类混淆矩阵上综合考察查准率和查全率。
所以就有了
宏查准率(macro-P)、宏查全率(macro-R)和宏F1(macro-F1)
微查准率(micro-P)、微查全率(micro-R)和微F1(micro-F1)
宏:先计算再平均

微:先平均再计算

print(f1_score(y_test, model.predict(x_test), average='macro'))print(f1_score(y_test, model.predict(x_test), average='micro'))
3、ROC与AUC
很多学习器为测试样本产生一个实值或概率预测,然后将这个预测值与一个“分类阈值”进行比较,大于阈值则分为正类,否则为负类。
分类阈值也就是截断点(cut point)。分类过程就相当于在排序中以某个“截断点”将样本分为两部分,前一部分判作正例,后一部分则判作反例。
在不同的应用任务中,可根据任务需求来采用不同的截断点。
查准率:选择排序中靠前的位置进行截断。
查全率:选择排序中靠后的位置进行截断。
ROC 全称是“受试者工作特征”(Receiver Operating Characteristic)曲线。根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,以“真正例率(True Positive Rate,简称 TPR)”为纵轴,以“假正例率(False Positive Rate,简称 FPR)”为横轴作图,就得到了“ROC曲线”。

API:
from sklearn.metrics import roc_curvefrom sklearn.metrics import roc_curve
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = 'SimHei' # 设置字体为SimHei # 显示中文
plt.rcParams['axes.unicode_minus']=False # 修复负号问题fpr,tpr,thresholds=roc_curve(y_true,y_predict)plt.plot(fpr, tpr)
plt.axis("square")
plt.xlabel("假正例率/False positive rate")
plt.ylabel("正正例率/True positive rate")
plt.title("ROC curve")
plt.show()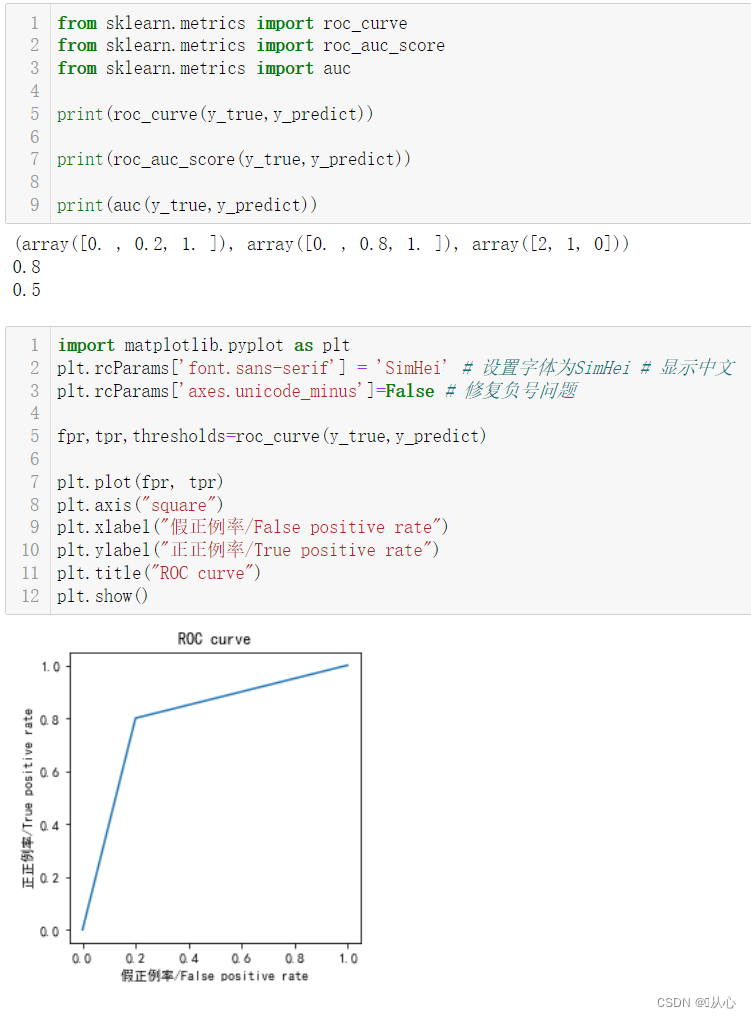
AUC(Area Under ROC Curve): ROC 曲线下的面积大小。该值能够量化地反映基于 ROC 曲线衡量出的模型性能。
!!!注意:roc_curve() 同 precision_recall_curve(),都只能用于二分类问题,但 roc_auc_score() 方法支持计算多分类问题的 auc 面积。
4、分类报告
scikit-learn 中提供了一个非常方便的工具,可以给出对分类问题的评估报告,Classification_report() 方法能够给出精确率(precision)、召回率(recall)、F1 值(F1-score)和样本数目(support)。
API:
from sklearn.metrics import classification_reportfrom sklearn.metrics import classification_report# 自制数据
print(classification_report(y_true,y_predict))# 鸢尾花数据
print(classification_report(y_test, model.predict(x_test)))
相关文章:
机器学习(四) -- 模型评估(2)
系列文章目录 机器学习(一) -- 概述 机器学习(二) -- 数据预处理(1-3) 机器学习(三) -- 特征工程(1-2) 机器学习(四) -- 模型评估…...

泊松分布与二项分布的可加性
泊松分布与二项分布的可加性 泊松分布的可加性 例 : 设 X , Y X,Y X,Y 相互独立 , X ∼ P ( λ 1 ) X\sim P(\lambda_1) X∼P(λ1) , Y ∼ P ( λ 2 ) Y\sim P(\lambda_2) Y∼P(λ2) , 求证 Z X Y ZXY ZXY 服从参数为 λ 1 λ 2 \lambda_1 \lambda_2 λ1λ2 …...

【PostgreSQL】约束-排他约束
【PostgreSQL】约束链接 检查 唯一 主键 外键 排他 排他约束 排他约束是一种数据库约束,用于确保某一列或多个列中的值在每一条记录中都是唯一的。这意味着任何两条记录都不能具有相同的值。 排他约束可以在数据库中创建唯一索引或唯一约束来实现。当尝试插入或更…...

Java重修第一天—学习数组
1. 认识数组 建议1.5倍速学习,并且关闭弹幕。 数组的定义:数组是一个容器,用来存储一批同种类型的数据。 下述图:是生成数字数组和字符串数组。 为什么有了变量还需要定义数组呢?为了解决在某些场景下,变…...
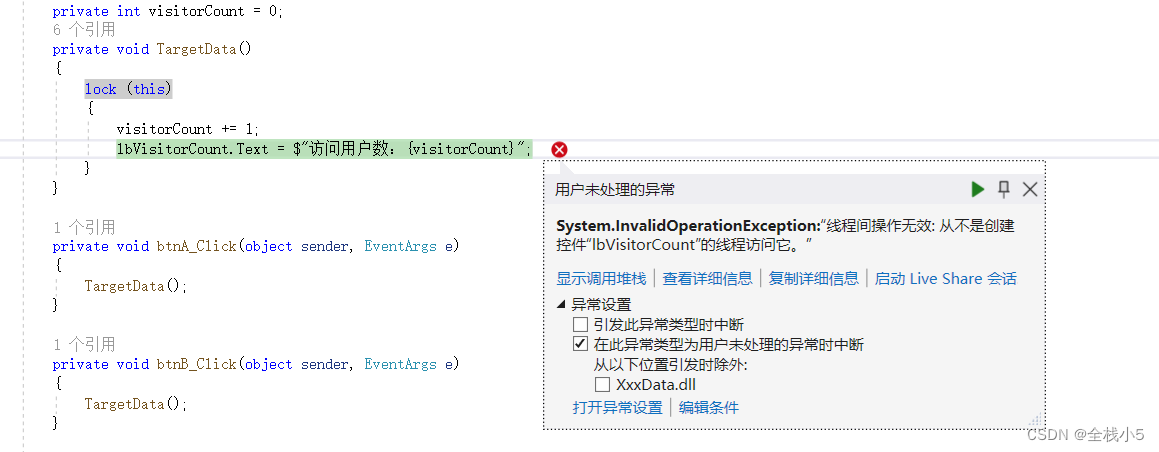
【C#】知识点实践序列之Lock的锁定代码块
大家好,我是全栈小5,欢迎来到《小5讲堂之知识点实践序列》文章。 2024年第1篇文章,此篇文章是C#知识点实践序列之Lock知识点,博主能力有限,理解水平有限,若有不对之处望指正! 本篇验证Lock锁定代…...
)
StringBad ditto (motto)
第12章 类和动态内存分配 StringBad ditto (motto): // calls StringBad (comst StringBad &) StringBad metoo - motto: // calls StringBad (const StringBad &) StringBad also StringBad (motto): // calls StringBad (const StringBad &) StringBad * pStri…...

Redis缓存击穿、缓存雪崩、缓存穿透
缓存击穿(某个热点key缓存失效) 概念 缓存中没有但数据库中有的数据,假如是热点数据,那key在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力增大和缓存雪崩的…...

【PCB专题】Allegro封装更新焊盘
在PCB封装的绘制中,有时会出现需要更新焊盘的情况。比如在制作封装的过程中发现焊盘做的不对而使用PAD_Designer重新更新了焊盘。 那在PCB中如何更新已经修改过的焊盘呢? 打开封装,选择Tools->Padstack->Refresh... 选择Refresh all …...

ES6之Reflect详解
✨ 专栏介绍 在现代Web开发中,JavaScript已经成为了不可或缺的一部分。它不仅可以为网页增加交互性和动态性,还可以在后端开发中使用Node.js构建高效的服务器端应用程序。作为一种灵活且易学的脚本语言,JavaScript具有广泛的应用场景&#x…...

文件监控-IT安全管理软件
文件监控和IT安全管理软件是用于保护企业数据和网络安全的工具。这些工具可以帮助企业监控文件的变化,防止未经授权的访问和修改,并确保数据的安全性和完整性。 一、具有哪些功能 文件监控软件可以实时监控文件系统的活动,包括文件的创建、修…...
达梦数据库安装超详细教程(小白篇)
文章目录 达梦数据库一、达梦数据库简介二、达梦数据库下载三、达梦数据库安装1. 解压2. 安装 四、初始化数据库五、DM管理工具 达梦数据库 一、达梦数据库简介 达梦数据库管理系统是达梦公司推出的具有完全自主知识产权的高性能数据库管理系统,简称DM。 达梦数…...
算法篇)
复试 || 就业day09(2024.01.04)算法篇
文章目录 前言验证外星语词典在长度 2N 的数组中找出重复 N 次的元素找到小镇的法官查找共用字符数组的相对排序分发饼干分发糖果区间选点(AcWing)最大不相交区间数量(AcWing)无重叠区间关于重写小于号 前言 💫你好,我是辰chen,本文旨在准备考…...
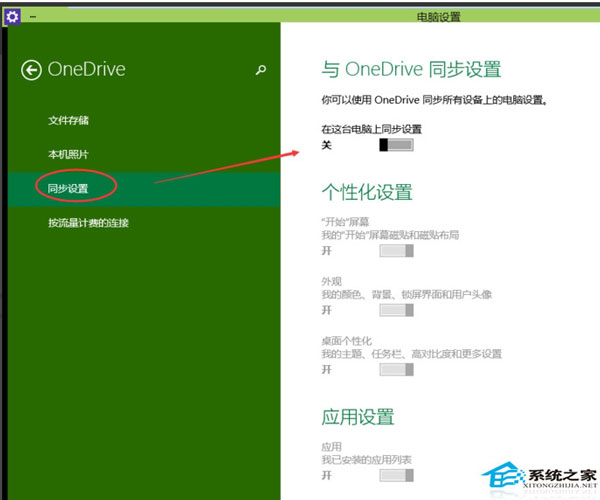
Win10电脑关闭OneDrive自动同步的方法
在Win10电脑操作过程中,用户想要关闭OneDrive的自动同步功能,但不知道具体要怎么操作?首先用户需要打开OneDrive,然后点击关闭默认情况下将文档保存到OneDrive选项保存,最后关闭在这台电脑上同步设置保存就好了。接下来…...

linux(centos)相关
文件架构: bin--binary--二进制命令,可直接执行 sbin systembin系统二进制命令,超级管理员 lib 库目录 类似dll文件 lib64 64位系统相关的库文件 usr 用户文件 boot 引导分区的文件,链接,系统启动等 dev device设备目录…...

外贸网站显示不安全警告怎么办?消除网站不安全警告超全指南
外贸网站显示不安全警告怎么办?当用户访问你的网站,而您的网站没有部署SSL证书实现HTTPS加密时,网站就会显示不安全警告,这种警告,不仅有可能阻止用户继续浏览网站,影响网站声誉,还有可能影响网…...

Java:HeapMemory和DirectMemory配置与使用介绍
目录 一、Heap内存 1、查看Heap内存配置的最大值 2、配置Heap内存最大值的方式 3、配置Heap内存最小值的方式 4、查看已使用Heap内存的方式 5、查看未使用Heap内存的方式 二、Direct内存 1、查看Direct内存配置的最大值 2、配置Direct内存最大值的方式 3、获取Direct…...

记 -bash: docker-compose: command not found 的问题解决
docker-compose: command not found 错误表明系统无法找到 docker-compose 命令。这可能是因为 docker-compose 并未正确安装,或者其可执行文件的路径未包含在系统的 PATH 变量中。 以下是我遇到时解决方法: 确保 Docker 和 Docker Compose 已安装&…...
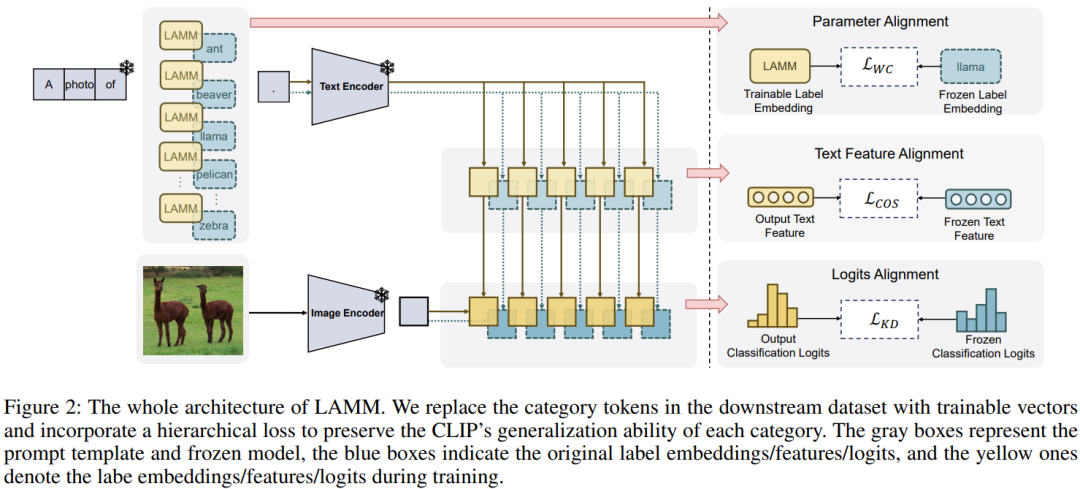
分享10篇优秀论文,涉及图神经网络、大模型优化、表格分析
引言 第38届AAAI人工智能年度会议将于2024年2月在加拿大温哥华举行。今天给大家分享十篇AAAI2024论文,主要涉及图神经网络,大模型幻觉、中文书法文字生成、表格数据分析、KGs错误检测、多模态Prompt、思维图生成等。 论文获取方式,回复&am…...

Ubuntu 24.04 Preview 版安装 libtinfo5
Ubuntu 24.04 Preview 版安装 libtinfo5 0. 背景1. 安装 libtinfo52. 安装 cuda 0. 背景 Ubuntu 24.04 Preview 版安装 Cuda 时报确实 libtinfo5 的错误。 1. 安装 libtinfo5 wget http://archive.ubuntu.com/ubuntu/pool/universe/n/ncurses/libtinfo5_6.4-2_amd64.deb dpk…...
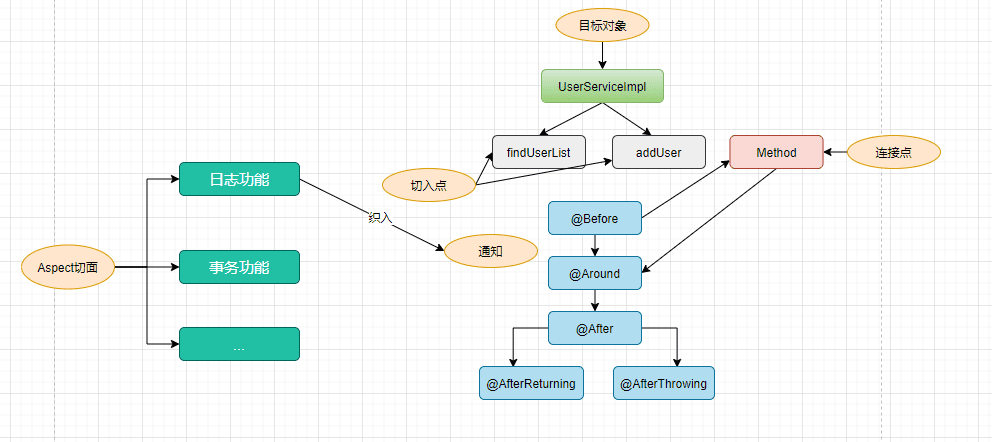
Spring AOP<一>简介与基础使用
spring AOP 基础定义 含义使用切面组织多个Advice,Advice放在切面中定义。也就是说是定义通知的自定义类。自定义的AOP类Aspect连接点方法调用,异常抛出可以增强的点JoinPoint :也就是**被增强的方法的总称,可以获取具体方法的信息ÿ…...

Intel Stratix 10 SoC:三层异构计算架构与ARM Cortex-A53的工程实践
1. 项目概述:Altera Stratix 10 SoC的“秘密武器”2013年,当Altera(现为Intel PSG)在EE Times上揭开其Stratix 10片上系统(SoC)的神秘面纱时,整个嵌入式与高性能计算领域都为之侧目。核心的爆点…...
)
STM32+RS485实战:用Modbus RTU协议读取液压传感器数据(附自动收发电路避坑)
STM32与RS485实战:从电路设计到Modbus RTU协议解析 液压传感器数据采集在工业自动化领域有着广泛应用,而RS485总线因其抗干扰能力强、传输距离远等优势成为首选通信方式。本文将深入探讨如何基于STM32微控制器搭建RS485硬件电路,并通过Modbus…...

如何在JavaScript中快速生成专业的PowerPoint演示文稿
如何在JavaScript中快速生成专业的PowerPoint演示文稿 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS PptxGenJS是一个功能强大…...

告别Surface“幽灵触控”:从现象溯源到一劳永逸的修复指南
1. 什么是Surface"幽灵触控"? 如果你正在使用Surface设备,突然发现屏幕某个区域莫名其妙地自动点击,或者部分触控功能完全失灵,恭喜你遇到了传说中的"幽灵触控"问题。这个现象最早在Surface Pro 4上被大量报告…...

NLTK数据包高效部署与下载加速实战
1. NLTK数据包下载慢?这些方法让你效率翻倍 第一次用NLTK跑自然语言处理项目时,我在数据包下载环节卡了整整三小时。看着进度条像蜗牛爬行,我甚至怀疑是不是网络断了。后来才发现,这是所有NLTK初学者都会遇到的经典问题——由于默…...

用Arduino和MAX30102做个心率血氧仪,从硬件连线到算法调试全流程避坑
从零构建Arduino心率血氧仪:MAX30102实战指南 开篇:为什么选择MAX30102? 在可穿戴健康设备爆发的时代,心率血氧监测已成为智能手环的标配功能。而MAX30102这颗高度集成的光学传感器,正以医用级精度和低功耗特性成为创客…...

Windows风扇控制终极指南:FanControl让你5分钟实现专业级散热管理
Windows风扇控制终极指南:FanControl让你5分钟实现专业级散热管理 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_…...

5分钟掌握全能文档下载神器:告别付费壁垒,解放你的知识获取能力
5分钟掌握全能文档下载神器:告别付费壁垒,解放你的知识获取能力 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档&#x…...

2003年那颗用砂纸磨出来的“中国芯“,毁掉了之后10年国产芯片人的口碑
大家好,我是写代码的篮球球痴。最近这一个多月,我连着写了一串国产芯片创始人——严晓浪、戚肖宁、张建辉、陈志坚、朱一明、王春华。这些人的共同点是:真在干活。有的是熬了20年才把生态做出来,有的是百万年薪不要去创业…...

QMCDecode终极指南:如何快速解锁QQ音乐加密文件实现跨设备播放
QMCDecode终极指南:如何快速解锁QQ音乐加密文件实现跨设备播放 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录ÿ…...