随机森林 3(代码)
通过随机森林 1和随机森林 2 的介绍,相信大家对理论已经了解的很透彻,接下来带大家敲一下代码,不懂得可以加我入群讨论。
第一份代码是比较原始的代码,第二份代码是第一段代码中引用的primitive_plot,第三份代码是使用 sklearn 包实现的代码,第四份代码是 sklearn 使用第一份代码数据集的实现代码。
import primitive_plotfrom math import log
import operatordef createDataSet():"""dataSet = [[0, 0, 0, 0, 'a'],[1, 0, 0, 0, 'b'],[1, 1, 0, 0, 'e'],[1, 2, 0, 0, 'f'],[2, 0, 0, 0, 'c'],[3, 0, 0, 0, 'd']]"""labels = ['A', 'B', 'C', 'D']return dataSet, labels# 创建树,参数分别是数据集,数据集对应的标签,特征标签(用于构建树,可以理解为当前的树结构)
def createTree(dataset, labels):classList = [example[-1] for example in dataset]if classList.count(classList[0]) == len(classList):# classList 全部是一个类别return classList[0]if len(dataset[0]) == 1:# dataset 只剩 label 标签,说明分类完成return majorityCnt(classList)# 选出最佳特征bestFeature = chooseBestFeatureToSplit(dataset)bestFeatureLabel = labels[bestFeature]myTree = {bestFeatureLabel: {}}print("A", myTree)# 在 labels 中删除最佳特征del labels[bestFeature]# 提取最佳特征在数据集中的取值featureList = [data[bestFeature] for data in dataset]# 去重uniqueFeatureList = set(featureList)#遍历最佳特征的每个取值,以上当做固定条件后,创建树for uniqueFeature in uniqueFeatureList:sublabels = labels[:]print("S", sublabels, uniqueFeature)myTree[bestFeatureLabel][uniqueFeature] = createTree(splitDataSet(dataset, bestFeature, uniqueFeature), sublabels)print("B", myTree)print("C", myTree)return myTree# 返回分类数量最多类的数量值
def majorityCnt(classList):classCount = {}for vote in classList:if vote not in classCount.keys():classCount[vote] = 0classCount[vote] += 1sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)print(sortedClassCount)return sortedClassCount[0][0]# 选出这个数据集中信息增益最大的特征
def chooseBestFeatureToSplit(dataset):numFeatures = len(dataset[0]) - 1baseEntropy = calcShannonEnt(dataset)bestinfoGain = 0bestFeature = -1for i in range(numFeatures):featureList = [data[i] for data in dataset]# 去重uniqueFeatureList = set(featureList)newEntropy = 0for uniqueFeature in uniqueFeatureList:# 两个 for 循环遍历每个特征的每个值,计算每个特征的信息增益subDataSet = splitDataSet(dataset, i, uniqueFeature)prob = len(subDataSet) / float(len(dataset))newEntropy += prob * calcShannonEnt(subDataSet)infoGain = baseEntropy - newEntropyif (infoGain > bestinfoGain):bestinfoGain = infoGainbestFeature = ireturn bestFeature# 选取在某个特征上某个取值的数据集
def splitDataSet(dataset, axis, val):# 创建一个空列表,用于存储划分后的子集retDataSet = []# 遍历数据集中的每个特征向量(一行数据)for featVec in dataset:# 如果特征向量在指定轴上的值等于给定的特征值(val)if featVec[axis] == val:# 则将该特征向量在指定轴上的值剔除,形成新的特征向量reducedFeatVec = featVec[:axis]reducedFeatVec.extend(featVec[axis + 1:])# 将新的特征向量添加到划分后的子集中retDataSet.append(reducedFeatVec)return retDataSet# 计算熵
def calcShannonEnt(dataset):datasize = len(dataset)labelCounts = {}for data in dataset:label = data[-1]if label not in labelCounts.keys():labelCounts[label] = 0labelCounts[label] += 1shannonEnt = 0for key in labelCounts:prop = float(labelCounts[key]) / datasizeshannonEnt -= prop * log(prop, 2)return shannonEntif __name__ == '__main__':dataset, labels = createDataSet()myTree = createTree(dataset, labels)primitive_plot.createPlot(myTree)
import matplotlib.pyplot as plt# 能够显示中文
#matplotlib.rcParams['font.sans-serif'] = ['SimHei']
#matplotlib.rcParams['font.serif'] = ['SimHei']# 分叉节点,也就是决策节点 创建字典
decisionNode = dict(boxstyle="sawtooth", fc="0.8")# 叶子节点
leafNode = dict(boxstyle="round4", fc="0.8")# 箭头样式
arrow_args = dict(arrowstyle="<-")def plotNode(nodeTxt, centerPt, parentPt, nodeType):"""绘制一个节点:param nodeTxt: 描述该节点的文本信息:param centerPt: 文本的坐标:param parentPt: 点的坐标,这里也是指父节点的坐标:param nodeType: 节点类型,分为叶子节点和决策节点:return:"""createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',xytext=centerPt, textcoords='axes fraction',va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)def getNumLeafs(myTree):"""获取叶节点的数目:param myTree::return:"""# 统计叶子节点的总数numLeafs = 0# 得到当前第一个key,也就是根节点firstStr = list(myTree.keys())[0]# 得到第一个key对应的内容secondDict = myTree[firstStr]# 递归遍历叶子节点for key in secondDict.keys():# 如果key对应的是一个字典,就递归调用if type(secondDict[key]).__name__ == 'dict':numLeafs += getNumLeafs(secondDict[key])# 不是的话,说明此时是一个叶子节点else:numLeafs += 1return numLeafsdef getTreeDepth(myTree):"""得到树的深度层数:param myTree::return:"""# 用来保存最大层数maxDepth = 0# 得到根节点firstStr = list(myTree.keys())[0]# 得到key对应的内容secondDic = myTree[firstStr]# 遍历所有子节点for key in secondDic.keys():# 如果该节点是字典,就递归调用if type(secondDic[key]).__name__ == 'dict':# 子节点的深度加1thisDepth = 1 + getTreeDepth(secondDic[key])# 说明此时是叶子节点else:thisDepth = 1# 替换最大层数if thisDepth > maxDepth:maxDepth = thisDepthreturn maxDepthdef plotMidText(cntrPt, parentPt, txtString):"""计算出父节点和子节点的中间位置,填充信息:param cntrPt: 子节点坐标:param parentPt: 父节点坐标:param txtString: 填充的文本信息:return:"""# 计算x轴的中间位置xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]# 计算y轴的中间位置yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]# 进行绘制createPlot.ax1.text(xMid, yMid, txtString)def plotTree(myTree, parentPt, nodeTxt):"""绘制出树的所有节点,递归绘制:param myTree: 树:param parentPt: 父节点的坐标:param nodeTxt: 节点的文本信息:return:"""# 计算叶子节点数numLeafs = getNumLeafs(myTree=myTree)# 计算树的深度depth = getTreeDepth(myTree=myTree)# 得到根节点的信息内容firstStr = list(myTree.keys())[0]# 计算出当前根节点在所有子节点的中间坐标,也就是当前x轴的偏移量加上计算出来的根节点的中心位置作为x轴(比如说第一次:初始的x偏移量为:-1/2W,计算出来的根节点中心位置为:(1+W)/2W,相加得到:1/2),当前y轴偏移量作为y轴cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)# 绘制该节点与父节点的联系plotMidText(cntrPt, parentPt, nodeTxt)# 绘制该节点plotNode(firstStr, cntrPt, parentPt, decisionNode)# 得到当前根节点对应的子树secondDict = myTree[firstStr]# 计算出新的y轴偏移量,向下移动1/D,也就是下一层的绘制y轴plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD# 循环遍历所有的keyfor key in secondDict.keys():# 如果当前的key是字典的话,代表还有子树,则递归遍历if isinstance(secondDict[key], dict):plotTree(secondDict[key], cntrPt, str(key))else:# 计算新的x轴偏移量,也就是下个叶子绘制的x轴坐标向右移动了1/WplotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW# 打开注释可以观察叶子节点的坐标变化# print((plotTree.xOff, plotTree.yOff), secondDict[key])# 绘制叶子节点plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)# 绘制叶子节点和父节点的中间连线内容plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))# 返回递归之前,需要将y轴的偏移量增加,向上移动1/D,也就是返回去绘制上一层的y轴plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalDdef createPlot(inTree):"""需要绘制的决策树:param inTree: 决策树字典:return:"""# 创建一个图像fig = plt.figure(1, facecolor='white')fig.clf()axprops = dict(xticks=[], yticks=[])createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)# 计算出决策树的总宽度plotTree.totalW = float(getNumLeafs(inTree))# 计算出决策树的总深度plotTree.totalD = float(getTreeDepth(inTree))# 初始的x轴偏移量,也就是-1/2W,每次向右移动1/W,也就是第一个叶子节点绘制的x坐标为:1/2W,第二个:3/2W,第三个:5/2W,最后一个:(W-1)/2WplotTree.xOff = -0.5 / plotTree.totalW# 初始的y轴偏移量,每次向下或者向上移动1/DplotTree.yOff = 1.0# 调用函数进行绘制节点图像plotTree(inTree, (0.5, 1.0), '')# 绘制plt.show()# 导入所需的库
from sklearn.datasets import load_iris # 用于加载鸢尾花数据集
from sklearn.model_selection import train_test_split # 用于拆分数据集为训练集和测试集
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.metrics import accuracy_score # 用于计算分类准确性# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征矩阵
y = iris.target # 目标标签# 将数据集拆分为训练集和测试集
# train_test_split: 这是 scikit-learn 库中用于将数据集划分为训练集和测试集的函数。
# X: 特征矩阵,包含了所有的样本和特征。
# y: 目标标签,包含了样本的类别信息。
# test_size: 测试集的比例。在这个例子中,test_size=0.3 表示将 30% 的数据用作测试集,而 70% 的数据用作训练集。
# random_state: 随机数生成器的种子。设置了 random_state=42 可以使每次运行代码时都得到相同的随机划分,保证结果的可重复性。
# 返回的四个变量:
# X_train: 训练集的特征矩阵。
# X_test: 测试集的特征矩阵。
# y_train: 训练集的目标标签。
# y_test: 测试集的目标标签。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建随机森林分类器模型
rf_model = RandomForestClassifier(n_estimators=10, random_state=42)
# 参数说明:
# - n_estimators: 决策树的数量,这里设置为 10
# - random_state: 随机数生成器的种子,用于保证结果的可重现性# 在训练集上训练模型
rf_model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = rf_model.predict(X_test)# 计算模型的准确性
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")# 输出每个特征的重要性
feature_importances = rf_model.feature_importances_
print("\nFeature Importances:")
for feature, importance in zip(iris.feature_names, feature_importances):print(f"{feature}: {importance:.4f}")
# 解释:
# zip(iris.feature_names, feature_importances): 这个函数将两个可迭代对象(iris.feature_names 和 feature_importances)逐一配对,创建一个由元组组成的迭代器。
# 在这里,它将每个特征的名称与其对应的重要性值配对在一起。
# - feature_importances_: 随机森林模型中每个特征的重要性
# - iris.feature_names: 鸢尾花数据集中特征的名称
# 导入所需的库
from sklearn.model_selection import train_test_split # 用于拆分数据集为训练集和测试集
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.metrics import accuracy_score # 用于计算分类准确性# 加载鸢尾花数据集
X = [[0, 0, 0, 0],[1, 0, 0, 0],[1, 1, 0, 0],[1, 2, 0, 0],[2, 0, 0, 0],[3, 0, 0, 0]] # 特征矩阵
y = ['a', 'a', 'c', 'a', 'a', 'f'] # 目标标签X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)# 创建随机森林分类器模型
rf_model = RandomForestClassifier(n_estimators=10, random_state=42)# 在训练集上训练模型
rf_model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = rf_model.predict(X_test)# 计算模型的准确性
accuracy = accuracy_score(y_test, y_pred)
print("Model Accuracy:", accuracy)想加微信算法交流群的朋友可以先扫码加我微信,我拉你进群。

相关文章:
随机森林 3(代码)
通过随机森林 1和随机森林 2 的介绍,相信大家对理论已经了解的很透彻,接下来带大家敲一下代码,不懂得可以加我入群讨论。 第一份代码是比较原始的代码,第二份代码是第一段代码中引用的primitive_plot,第三份代码是使用…...

勒索事件急剧增长,亚信安全发布《勒索家族和勒索事件监控报告》
近期(12.15-12.21)态势快速感知 近期全球共发生了247起攻击和勒索事件,勒索事件数量急剧增长。 近期需要重点关注的除了仍然流行的勒索家族lockbit3以外,还有本周top1勒索组织toufan。toufan是一个新兴勒索组织,本周共发起了108起勒索攻击&a…...

LeetCode1523. Count Odd Numbers in an Interval Range
文章目录 一、题目二、题解 一、题目 Given two non-negative integers low and high. Return the count of odd numbers between low and high (inclusive). Example 1: Input: low 3, high 7 Output: 3 Explanation: The odd numbers between 3 and 7 are [3,5,7]. Exam…...

E中国铜金属行业需求前景及未来发展机遇分析报告2024-2030年
E中国铜金属行业需求前景及未来发展机遇分析报告2024-2030年 &&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&& 《报告编号》: BG471816 《出…...

python SVM 保存和加载模型参数
在 Python 中,你可以使用 scikit-learn 库中的 joblib 或 pickle 模块来保存和加载 SVM 模型的参数。以下是一个简单的示例代码,演示了如何使用 joblib 模块保存和加载 SVM 模型的参数: 保存模型参数: from sklearn import svm …...

JAVA进化史: JDK12特性及说明
JDK 12于2019年3月发布。这个版本相对于之前的版本来说规模较小,主要集中在一些改进和实验性的特性上。以下是JDK 12的一些主要特性: 引入了实验性的Shenandoah垃圾收集器 JDK 12引入了实验性的Shenandoah垃圾收集器,旨在实现极低的暂停时间…...
Databend 的算力可扩展性
作者:尚卓燃(PsiACE) 澳门科技大学在读硕士,Databend 研发工程师实习生 Apache OpenDAL(Incubating) Committer PsiACE (Chojan Shang) GitHub 对于大规模分布式数据处理系统,为了更好应对数据、流量、和复杂性的增长…...

「解析」Windows 如何优雅使用 Terminal
所谓工欲善其事必先利其器,对于开发人员 Linux可能是首选,但是在家学习的时候,我还是更喜欢使用 Windows系统,首先是稳定,其次是习惯了。当然了,我还有一台专门安装 Linux系统的小主机用于学习Linux使用&am…...
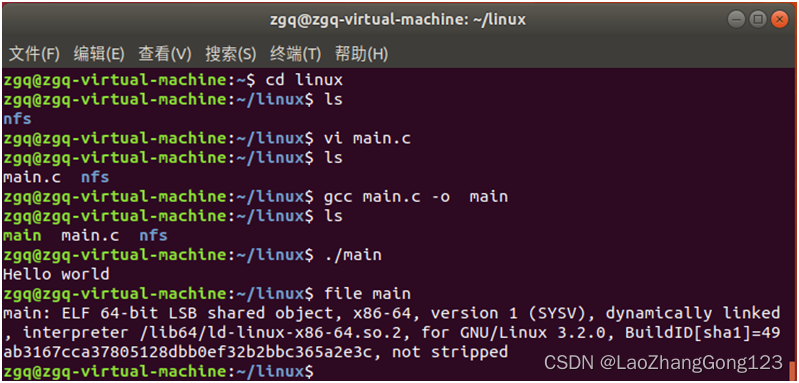
Linux第18步_安装“Ubuntu系统下的C语言编译器GCC”
Ubuntu系统没有提供C/C的编译环境,因此还需要手动安装build-essential软件包,它包含了 GNU 编辑器,GNU 调试器,和其他编译软件所必需的开发库和工具。本节用于重点介绍安装“Ubuntu系统下的C语言编译器GC&a…...

【Linux】Linux 基础命令 crontab命令
1.crontab命令 crond 是linux下用来周期性的执行某种任务或等待处理某些事件的一个守护进程,与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务 工具,并且会自动启动crond进程,crond进程每分钟会定期检查是否有要执行的任务,如果有要执行的任务,则自动…...
14:00面试,14:08就出来了,问的问题过于变态了。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到10月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40…...

Ubuntu envs setting
1. change the chmod of folders sudo chown -R $USER:$USER /home/anaconda3 2. torch.cuda.is_available()返回false change conda installation to pip. zai qi ta huan jing pei zhi dou mei wen ti de qing kuang xia , zai shi shi zhe ge fang fa. # CUDA 11.7 con…...
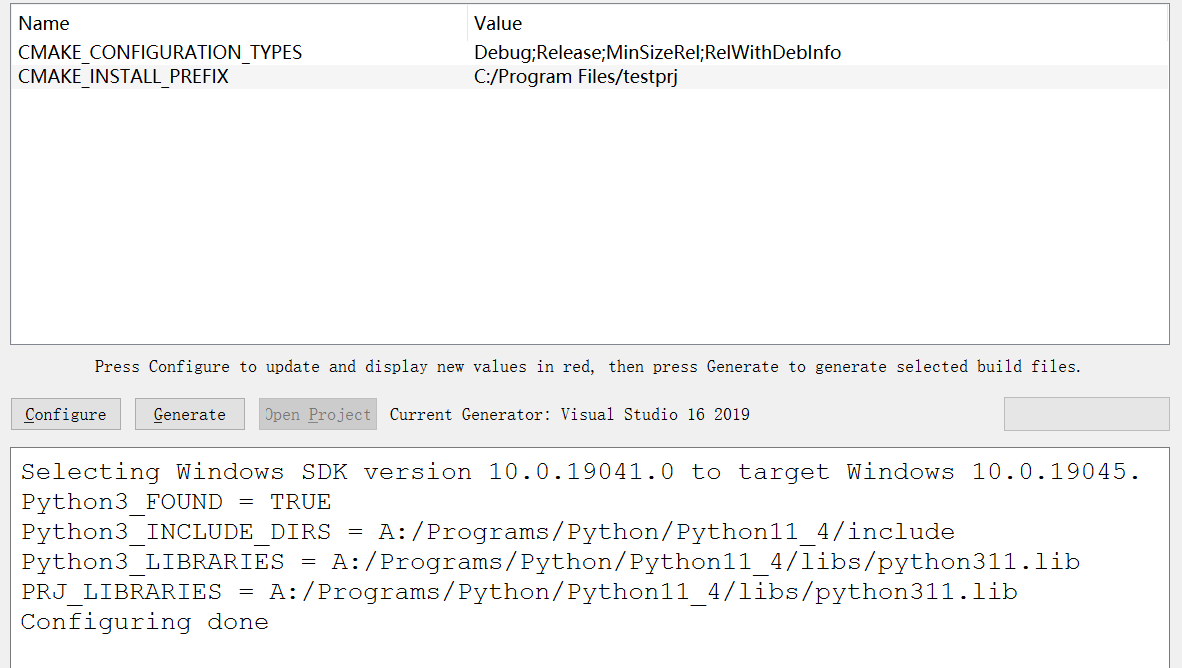
Windows 下用 C++ 调用 Python
文章目录 Part.I IntroductionChap.I InformationChap.II 预备知识 Part.II 语法Chap.I PyRun_SimpleStringChap.II C / Python 变量之间的相互转换 Part.III 实例Chap.I 文件内容Chap.II 基于 Visual Studio IDEChap.III 基于 cmakeChap.IV 运行结果 Part.IV 可能出现的问题Ch…...

九州金榜|家庭教育一招孩子不在任性
有一次和朋友一块聚餐,邻座是一位妈妈、和她大概七八岁的儿子,小男孩长得很帅气,没有像同龄人那样调皮捣乱,而是和妈妈很温馨的就餐。 看的出来一家人的素质很高,就餐过程中桌面保持的很整洁,交流声音也不…...

爬虫案列 --抖音视频批量爬取
""" 项目名称: 唯品会商品数据爬取 项目描述: 通过requests框架获取网页数据 项目环境: pycharm && python3.8 作者所属: 几许1. 对主页抓包 , 鼠标移动到视频位置视频自动播放获得视频数据包 2. 对视频数据包地址进行解析 , 复制链接 , 进行检索 3. 获…...

【React系列】React中的CSS
本文来自#React系列教程:https://mp.weixin.qq.com/mp/appmsgalbum?__bizMzg5MDAzNzkwNA&actiongetalbum&album_id1566025152667107329) 一. React中的css方案 1.1. react 中的 css 事实上,css 一直是 React 的痛点,也是被很多开发…...
基于Kettle开发的web版数据集成开源工具(data-integration)-应用篇
目录 📚第一章 基本流程梳理📗页面基本操作📗对应后台服务流程 📚第二章 二开思路📗前端📗后端 🔼上一集:基于Kettle开发的web版数据集成开源工具(data-integration)-介绍篇 *️⃣主…...

51单片机三种编译模式的相互关系
51单片机三种编译模式的相互关系 编译模式默认存储类型RAM使用规模变量使用特点SAMLLdata128B片内RAM使用规模CPU访问数据速度快,但存储容量较小COMPACTpdata258B片外分页RAM速度和容量介于上下两者之间LARGExdata64KB片外RAMCPU访问数据的速度较慢,但存…...

java 千帆大模型 流式返回
聊天有两个接口,第一个是获取token, 第二个是聊天接口,具体参照官方文档 下面是流式调用聊天接口,单次的,不含上下文 Value("${qianfan.apiKey}")private String apiKey;Value("${qianfan.secretKey}")private String secretKey;Value("${qianfan.to…...

全新互联网洗衣洗鞋小程序平台新模式
互联网洗衣洗鞋新模式, 全新软件升级 对接各大平台 扩大营销渠道,增加效益!...

为AI编程助手注入Go语言最佳实践:golang-skills技能包实战指南
1. 项目概述:为AI编程助手注入Go语言“肌肉记忆” 如果你和我一样,日常开发重度依赖像Cursor、Claude Code这类AI编程助手,那你肯定也遇到过类似的困扰:生成的Go代码虽然语法正确,但总感觉“味儿”不对。要么是错误处理…...

Rails AI上下文管理引擎:构建LLM友好的业务操作上下文
1. 项目概述:一个AI驱动的Rails上下文管理引擎最近在重构一个历史悠久的Rails项目时,我遇到了一个典型的老问题:业务逻辑散落在各个控制器、模型和Service对象里,一个简单的用户操作背后要追踪七八个文件才能理清完整的上下文。更…...

表面贴装TVS二极管选型与应用全解析
1. 表面贴装功率TVS二极管的核心优势解析在电信基站、工业控制系统等关键电力应用中,一次意外的浪涌事件可能导致数万元设备损坏和数小时系统宕机。传统通孔封装的TVS二极管虽然能提供基础保护,但实测数据显示其引线电感导致的额外电压尖峰可达60V以上。…...
)
Xilinx VCU方案深度体验:除了低延时,开发者还需要面对这些挑战(GStreamer/FPGA/稳定性)
Xilinx VCU方案实战解析:低延时光环下的工程化挑战 在专业视频处理领域,低延时编解码一直是皇冠上的明珠。Xilinx Zynq UltraScale MPSoC凭借其VCU硬核确实交出了一份漂亮的参数答卷——4K60帧H.265编解码仅2帧延时的成绩单。但当我们真正将其引入工业视…...

Awesome List Creator:基于规则引擎的自动化资源清单生成工具
1. 项目概述:一个清单的“引擎”在信息过载的时代,无论是开发者寻找工具库,还是学习者梳理知识体系,一份结构清晰、内容精选的“Awesome List”(优质资源清单)都堪称无价之宝。然而,维护一份高质…...
)
一文读懂添加产品展示模块后,但模块不显示产品价格,如何解决(附实操教程)
关于这个问题,很多商家都不太清楚。今天来详细解答。一、问题背景在实际运营小程序商城的过程中,不少商家会遇到:添加产品展示模块后,但模块不显示产品价格,如何解决二、详细解答请按下图操作查看是否未勾选展示的内容…...

别再手动下载了!用Chocolatey在Windows上一键安装Zookeeper 3.8.0
告别繁琐配置:用Chocolatey在Windows上极速部署Zookeeper 每次在Windows环境下部署Zookeeper,你是否还在重复下载压缩包、配置环境变量、修改配置文件的传统流程?对于追求效率的开发者而言,这种手动操作不仅耗时耗力,还…...

内存数据库eXtremeDB核心技术解析与实践指南
1. 内存数据库技术概述在传统数据库系统中,磁盘I/O往往是性能瓶颈所在。每次数据查询都需要从磁盘读取数据到内存缓冲区,这个过程中涉及机械寻道、旋转延迟等物理限制。而内存数据库(IMDS)通过直接在内存中存储和处理数据,彻底绕过了这个瓶颈…...

FinalShell不止是SSH客户端:挖掘它的云端同步、命令补全和服务器管理隐藏功能
FinalShell进阶指南:解锁云端同步、智能补全与高效运维的隐藏技巧 如果你已经用FinalShell完成了基础的SSH连接操作,那么是时候探索这个工具更强大的另一面了。作为一款被低估的一体化运维工具,FinalShell在高效命令操作、多设备协同和服务器…...
)
Google Docs接入Gemini后,这6类高频写作场景效率飙升210%(附可复制Prompt库)
更多请点击: https://intelliparadigm.com 第一章:Gemini深度集成Google Docs的底层机制解析 Gemini 与 Google Docs 的深度集成并非简单的 API 调用叠加,而是依托 Google 的统一 AI 基础设施(AISI)和文档实时协作协议…...